 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Array Configuration-Agnostic Personalized Speech Enhancement using Long-Short-Term Spatial Coherence
Nov 16, 2022
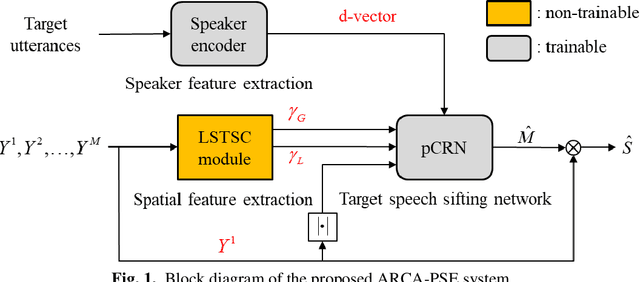
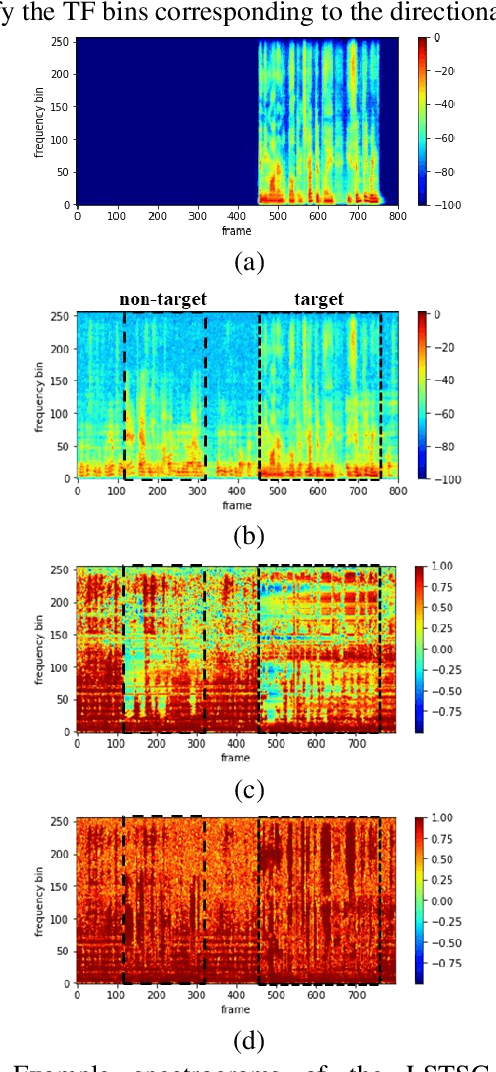
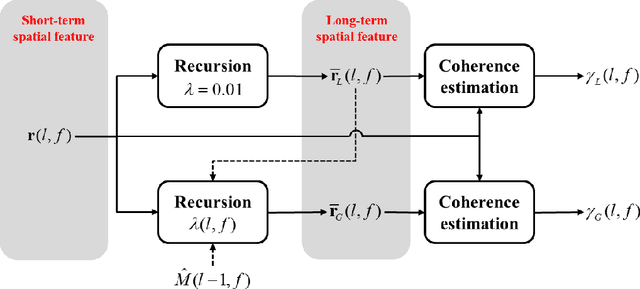
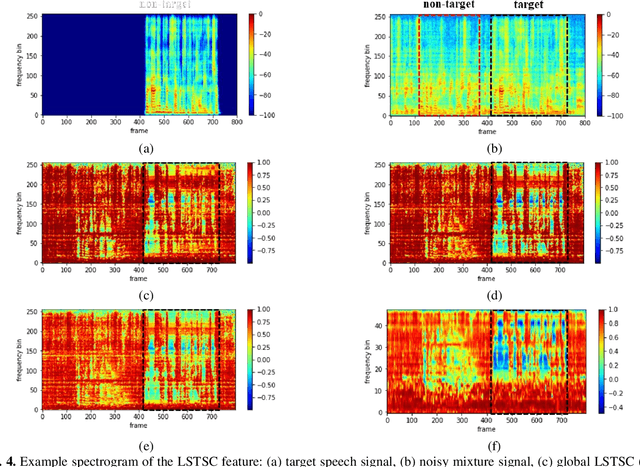
Personalized speech enhancement has been a field of active research for suppression of speechlike interferers such as competing speakers or TV dialogues. Compared with single channel approaches, multichannel PSE systems can be more effective in adverse acoustic conditions by leveraging the spatial information in microphone signals. However, the implementation of multichannel PSEs to accommodate a wide range of array topology in household applications can be challenging. To develop an array configuration agnostic PSE system, we define a spatial feature termed the long short term spatial coherence as the input feature to a convolutional recurrent network to monitor the voice activity of the target speaker. As another refinement, an equivalent rectangular bandwidth scaled LSTSC feature can be used to reduce the computational cost. Experiments were conducted to compare the proposed PSE systems, including the complete and the simplified versions with two baselines using unseen room responses and array configurations in the presence of TV noise and competing speakers. The results demonstrated that the proposed multichannel PSE network trained with the LSTSC feature achieved superior enhancement performance without precise knowledge of the array configurations and room responses.
ReaRev: Adaptive Reasoning for Question Answering over Knowledge Graphs
Oct 24, 2022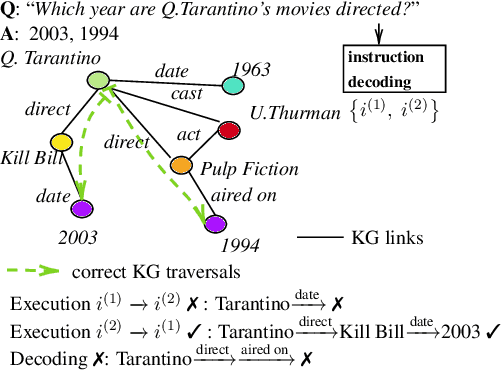
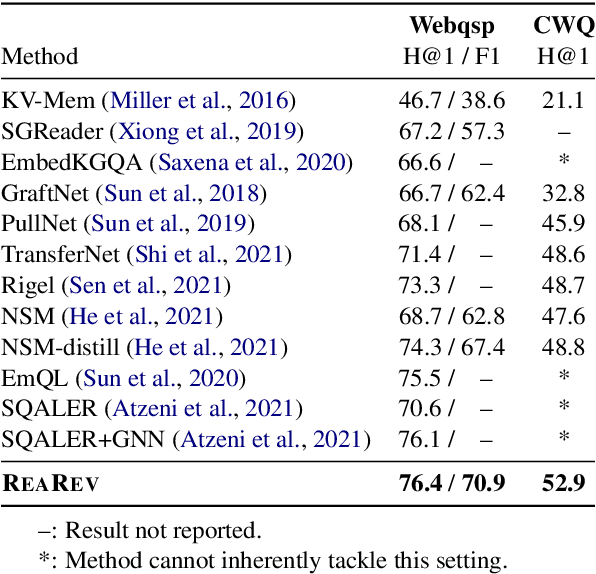
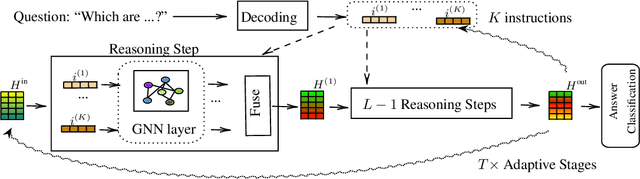
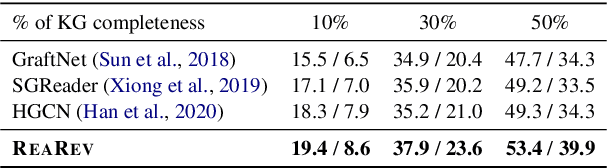
Knowledge Graph Question Answering (KGQA) involves retrieving entities as answers from a Knowledge Graph (KG) using natural language queries. The challenge is to learn to reason over question-relevant KG facts that traverse KG entities and lead to the question answers. To facilitate reasoning, the question is decoded into instructions, which are dense question representations used to guide the KG traversals. However, if the derived instructions do not exactly match the underlying KG information, they may lead to reasoning under irrelevant context. Our method, termed ReaRev, introduces a new way to KGQA reasoning with respect to both instruction decoding and execution. To improve instruction decoding, we perform reasoning in an adaptive manner, where KG-aware information is used to iteratively update the initial instructions. To improve instruction execution, we emulate breadth-first search (BFS) with graph neural networks (GNNs). The BFS strategy treats the instructions as a set and allows our method to decide on their execution order on the fly. Experimental results on three KGQA benchmarks demonstrate the ReaRev's effectiveness compared with previous state-of-the-art, especially when the KG is incomplete or when we tackle complex questions. Our code is publicly available at https://github.com/cmavro/ReaRev_KGQA.
Unlocking the potential of two-point cells for energy-efficient training of deep nets
Oct 24, 2022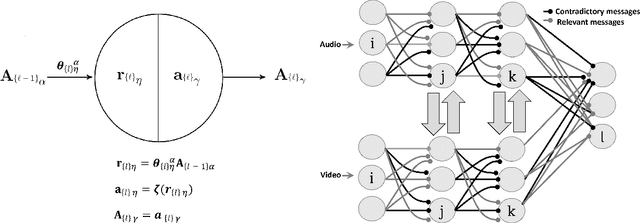
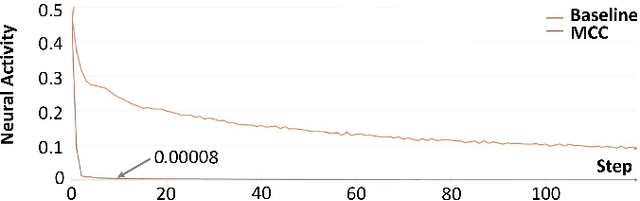
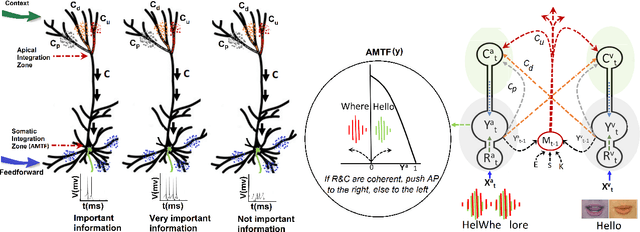
Context-sensitive two-point layer 5 pyramidal cells (L5PC) were discovered as long ago as 1999. However, the potential of this discovery to provide useful neural computation has yet to be demonstrated. Here we show for the first time how a transformative L5PC-driven deep neural network (DNN), termed the multisensory cooperative computing (MCC) architecture, can effectively process large amounts of heterogeneous real-world audio-visual (AV) data, using far less energy compared to best available `point' neuron-driven DNNs. A novel highly-distributed parallel implementation on a Xilinx UltraScale+ MPSoC device estimates energy savings up to $245759 \times 50000$ $\mu$J (i.e., $62\%$ less than the baseline model in a semi-supervised learning setup) where a single synapse consumes $8e^{-5}\mu$J. In a supervised learning setup, the energy-saving can potentially reach up to 1250x less (per feedforward transmission) than the baseline model. This remarkable performance in pilot experiments demonstrates the embodied neuromorphic intelligence of our proposed L5PC based MCC architecture that contextually selects the most salient and relevant information for onward transmission, from overwhelmingly large multimodal information utilised at the early stages of on-chip training. Our proposed approach opens new cross-disciplinary avenues for future on-chip DNN training implementations and posits a radical shift in current neuromorphic computing paradigms.
Evaluating Long-Term Memory in 3D Mazes
Oct 24, 2022
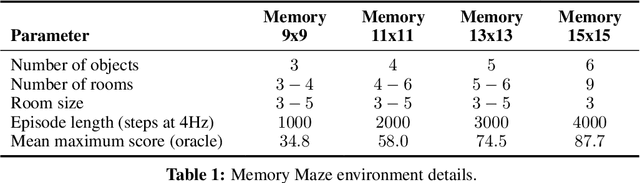
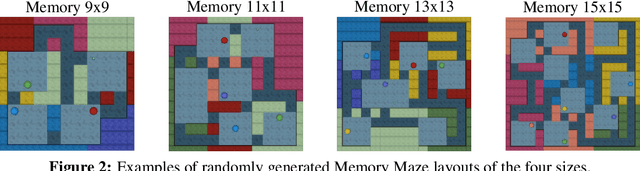
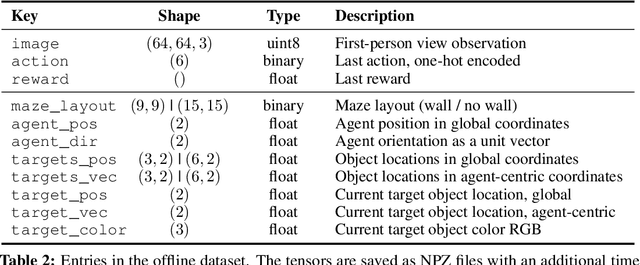
Intelligent agents need to remember salient information to reason in partially-observed environments. For example, agents with a first-person view should remember the positions of relevant objects even if they go out of view. Similarly, to effectively navigate through rooms agents need to remember the floor plan of how rooms are connected. However, most benchmark tasks in reinforcement learning do not test long-term memory in agents, slowing down progress in this important research direction. In this paper, we introduce the Memory Maze, a 3D domain of randomized mazes specifically designed for evaluating long-term memory in agents. Unlike existing benchmarks, Memory Maze measures long-term memory separate from confounding agent abilities and requires the agent to localize itself by integrating information over time. With Memory Maze, we propose an online reinforcement learning benchmark, a diverse offline dataset, and an offline probing evaluation. Recording a human player establishes a strong baseline and verifies the need to build up and retain memories, which is reflected in their gradually increasing rewards within each episode. We find that current algorithms benefit from training with truncated backpropagation through time and succeed on small mazes, but fall short of human performance on the large mazes, leaving room for future algorithmic designs to be evaluated on the Memory Maze.
Photonic Quantum Computing For Polymer Classification
Nov 22, 2022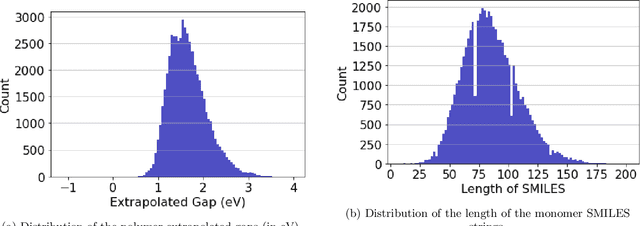
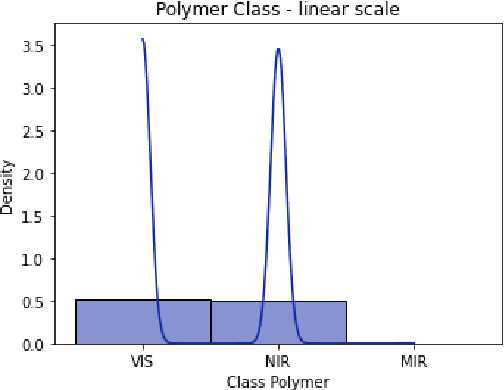
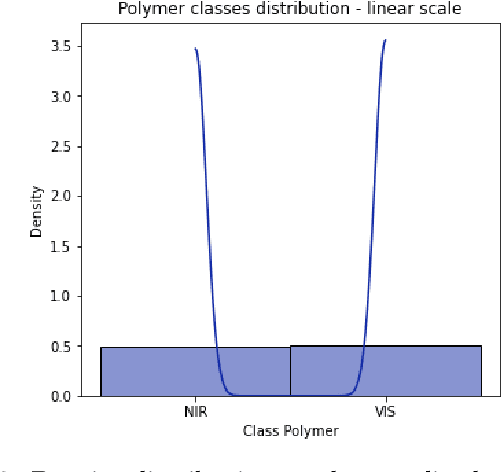
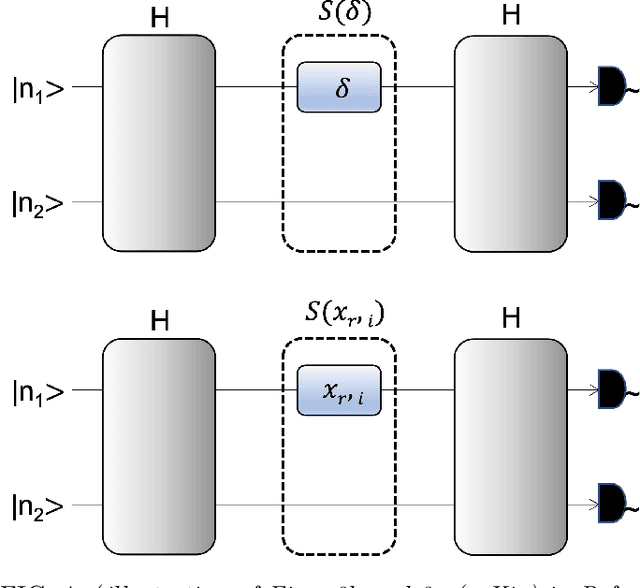
We present a hybrid classical-quantum approach to the binary classification of polymer structures. Two polymer classes visual (VIS) and near-infrared (NIR) are defined based on the size of the polymer gaps. The hybrid approach combines one of the three methods, Gaussian Kernel Method, Quantum-Enhanced Random Kitchen Sinks or Variational Quantum Classifier, implemented by linear quantum photonic circuits (LQPCs), with a classical deep neural network (DNN) feature extractor. The latter extracts from the classical data information about samples chemical structure. It also reduces the data dimensions yielding compact 2-dimensional data vectors that are then fed to the LQPCs. We adopt the photonic-based data-embedding scheme, proposed by Gan et al. [EPJ Quantum Technol. 9, 16 (2022)] to embed the classical 2-dimensional data vectors into the higher-dimensional Fock space. This hybrid classical-quantum strategy permits to obtain accurate noisy intermediate-scale quantum-compatible classifiers by leveraging Fock states with only a few photons. The models obtained using either of the three hybrid methods successfully classified the VIS and NIR polymers. Their accuracy is comparable as measured by their scores ranging from 0.86 to 0.88. These findings demonstrate that our hybrid approach that uses photonic quantum computing captures chemistry and structure-property correlation patterns in real polymer data. They also open up perspectives of employing quantum computing to complex chemical structures when a larger number of logical qubits is available.
Predicting adverse outcomes following catheter ablation treatment for atrial fibrillation
Nov 22, 2022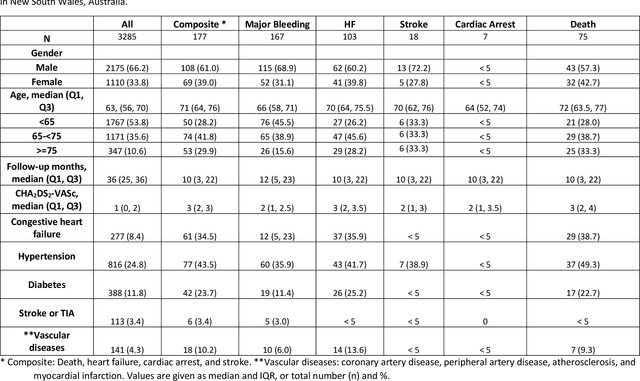
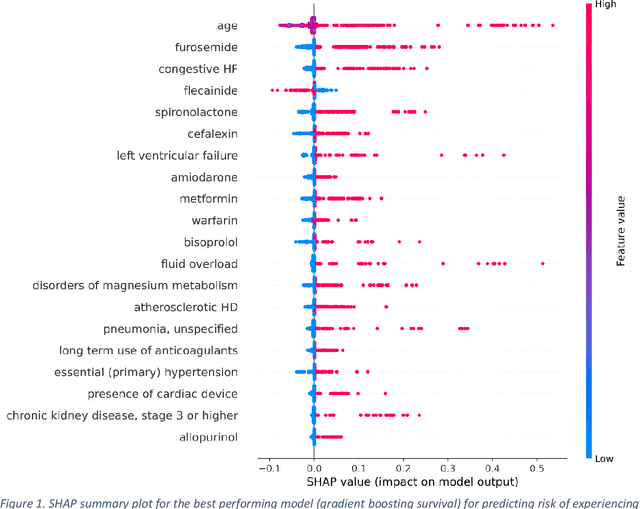
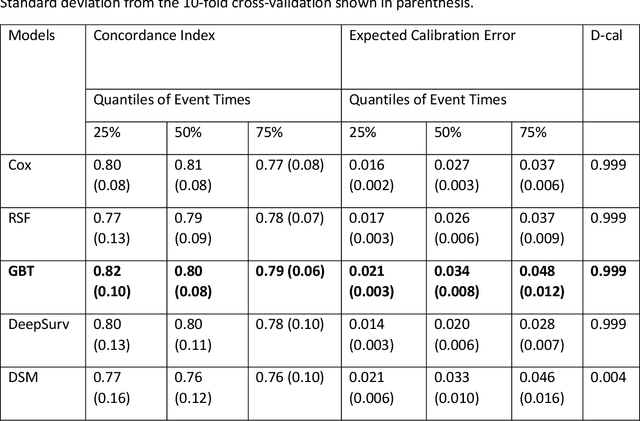
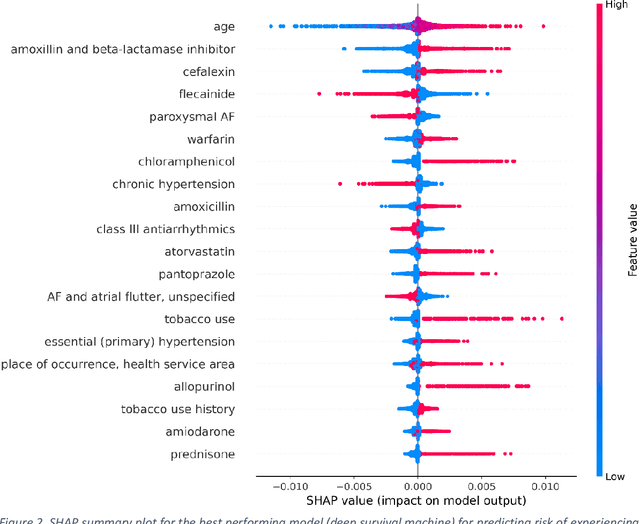
Objective: To develop prognostic survival models for predicting adverse outcomes after catheter ablation treatment for non-valvular atrial fibrillation (AF). Methods: We used a linked dataset including hospital administrative data, prescription medicine claims, emergency department presentations, and death registrations of patients in New South Wales, Australia. The cohort included patients who received catheter ablation for AF. Traditional and deep survival models were trained to predict major bleeding events and a composite of heart failure, stroke, cardiac arrest, and death. Results: Out of a total of 3285 patients in the cohort, 177 (5.3%) experienced the composite outcomeheart failure, stroke, cardiac arrest, deathand 167 (5.1%) experienced major bleeding events after catheter ablation treatment. Models predicting the composite outcome had high risk discrimination accuracy, with the best model having a concordance index > 0.79 at the evaluated time horizons. Models for predicting major bleeding events had poor risk discrimination performance, with all models having a concordance index < 0.66. The most impactful features for the models predicting higher risk were comorbidities indicative of poor health, older age, and therapies commonly used in sicker patients to treat heart failure and AF. Conclusions: Diagnosis and medication history did not contain sufficient information for precise risk prediction of experiencing major bleeding events. The models for predicting the composite outcome have the potential to enable clinicians to identify and manage high-risk patients following catheter ablation proactively. Future research is needed to validate the usefulness of these models in clinical practice.
GDPR Compliant Collection of Therapist-Patient-Dialogues
Nov 22, 2022According to the Global Burden of Disease list provided by the World Health Organization (WHO), mental disorders are among the most debilitating disorders.To improve the diagnosis and the therapy effectiveness in recent years, researchers have tried to identify individual biomarkers. Gathering neurobiological data however, is costly and time-consuming. Another potential source of information, which is already part of the clinical routine, are therapist-patient dialogues. While there are some pioneering works investigating the role of language as predictors for various therapeutic parameters, for example patient-therapist alliance, there are no large-scale studies. A major obstacle to conduct these studies is the availability of sizeable datasets, which are needed to train machine learning models. While these conversations are part of the daily routine of clinicians, gathering them is usually hindered by various ethical (purpose of data usage), legal (data privacy) and technical (data formatting) limitations. Some of these limitations are particular to the domain of therapy dialogues, like the increased difficulty in anonymisation, or the transcription of the recordings. In this paper, we elaborate on the challenges we faced in starting our collection of therapist-patient dialogues in a psychiatry clinic under the General Data Privacy Regulation of the European Union with the goal to use the data for Natural Language Processing (NLP) research. We give an overview of each step in our procedure and point out the potential pitfalls to motivate further research in this field.
On the Transferability of Visual Features in Generalized Zero-Shot Learning
Nov 22, 2022
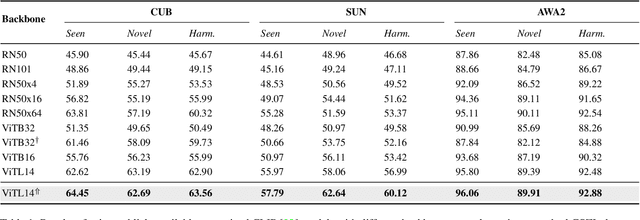
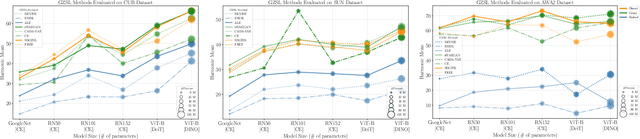
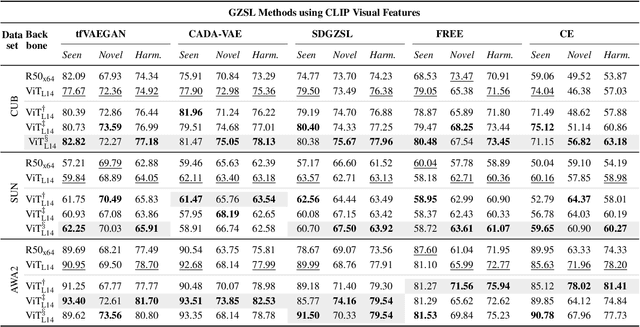
Generalized Zero-Shot Learning (GZSL) aims to train a classifier that can generalize to unseen classes, using a set of attributes as auxiliary information, and the visual features extracted from a pre-trained convolutional neural network. While recent GZSL methods have explored various techniques to leverage the capacity of these features, there has been an extensive growth of representation learning techniques that remain under-explored. In this work, we investigate the utility of different GZSL methods when using different feature extractors, and examine how these models' pre-training objectives, datasets, and architecture design affect their feature representation ability. Our results indicate that 1) methods using generative components for GZSL provide more advantages when using recent feature extractors; 2) feature extractors pre-trained using self-supervised learning objectives and knowledge distillation provide better feature representations, increasing up to 15% performance when used with recent GZSL techniques; 3) specific feature extractors pre-trained with larger datasets do not necessarily boost the performance of GZSL methods. In addition, we investigate how GZSL methods fare against CLIP, a more recent multi-modal pre-trained model with strong zero-shot performance. We found that GZSL tasks still benefit from generative-based GZSL methods along with CLIP's internet-scale pre-training to achieve state-of-the-art performance in fine-grained datasets. We release a modular framework for analyzing representation learning issues in GZSL here: https://github.com/uvavision/TV-GZSL
Unsupervised 3D Pose Transfer with Cross Consistency and Dual Reconstruction
Nov 18, 2022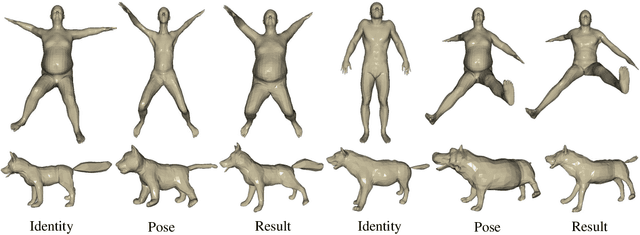
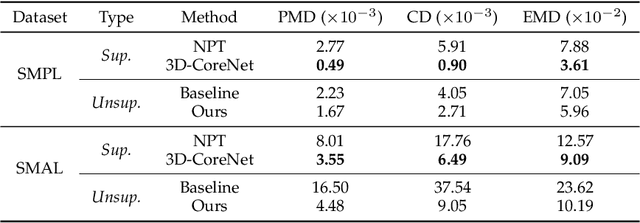
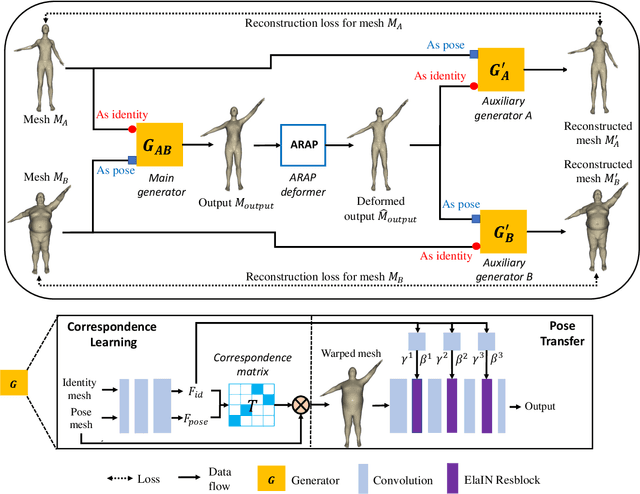
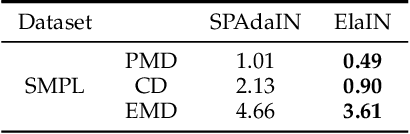
The goal of 3D pose transfer is to transfer the pose from the source mesh to the target mesh while preserving the identity information (e.g., face, body shape) of the target mesh. Deep learning-based methods improved the efficiency and performance of 3D pose transfer. However, most of them are trained under the supervision of the ground truth, whose availability is limited in real-world scenarios. In this work, we present X-DualNet, a simple yet effective approach that enables unsupervised 3D pose transfer. In X-DualNet, we introduce a generator $G$ which contains correspondence learning and pose transfer modules to achieve 3D pose transfer. We learn the shape correspondence by solving an optimal transport problem without any key point annotations and generate high-quality meshes with our elastic instance normalization (ElaIN) in the pose transfer module. With $G$ as the basic component, we propose a cross consistency learning scheme and a dual reconstruction objective to learn the pose transfer without supervision. Besides that, we also adopt an as-rigid-as-possible deformer in the training process to fine-tune the body shape of the generated results. Extensive experiments on human and animal data demonstrate that our framework can successfully achieve comparable performance as the state-of-the-art supervised approaches.
Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
Nov 18, 2022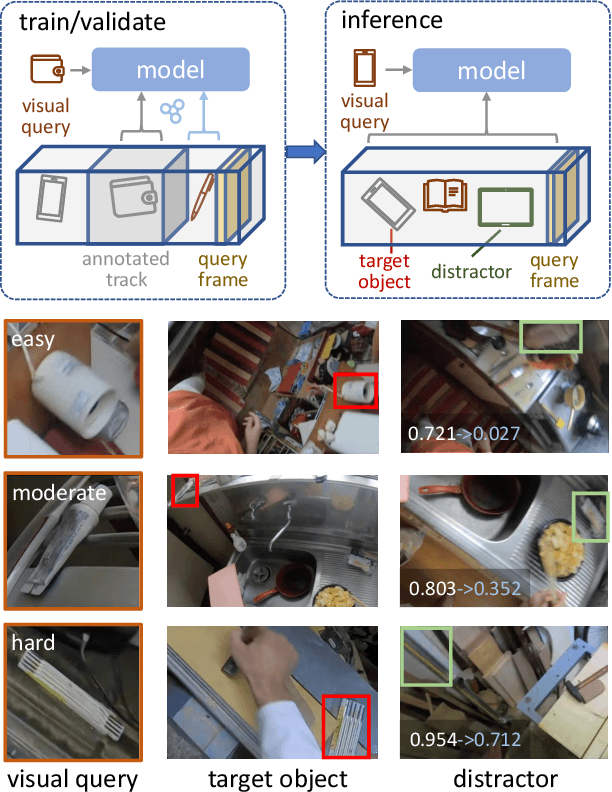
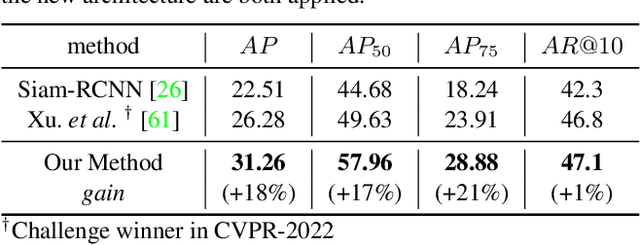
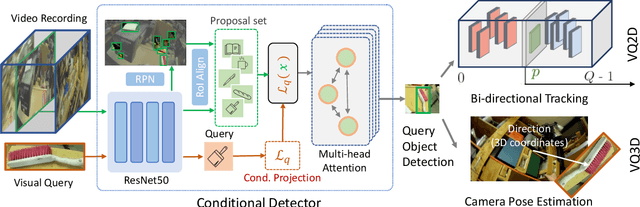
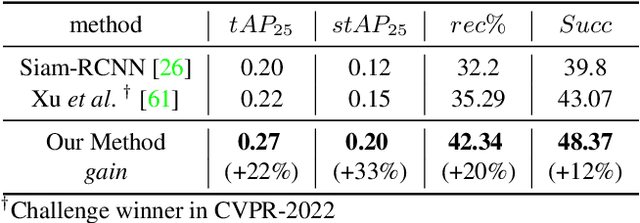
This paper deals with the problem of localizing objects in image and video datasets from visual exemplars. In particular, we focus on the challenging problem of egocentric visual query localization. We first identify grave implicit biases in current query-conditioned model design and visual query datasets. Then, we directly tackle such biases at both frame and object set levels. Concretely, our method solves these issues by expanding limited annotations and dynamically dropping object proposals during training. Additionally, we propose a novel transformer-based module that allows for object-proposal set context to be considered while incorporating query information. We name our module Conditioned Contextual Transformer or CocoFormer. Our experiments show the proposed adaptations improve egocentric query detection, leading to a better visual query localization system in both 2D and 3D configurations. Thus, we are able to improve frame-level detection performance from 26.28% to 31.26 in AP, which correspondingly improves the VQ2D and VQ3D localization scores by significant margins. Our improved context-aware query object detector ranked first and second in the VQ2D and VQ3D tasks in the 2nd Ego4D challenge. In addition to this, we showcase the relevance of our proposed model in the Few-Shot Detection (FSD) task, where we also achieve SOTA results. Our code is available at https://github.com/facebookresearch/vq2d_cvpr.