 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Automatic SOAP Classification System Using Weakly Supervision And Transfer Learning
Nov 26, 2022

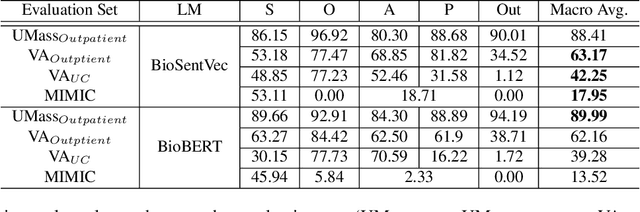
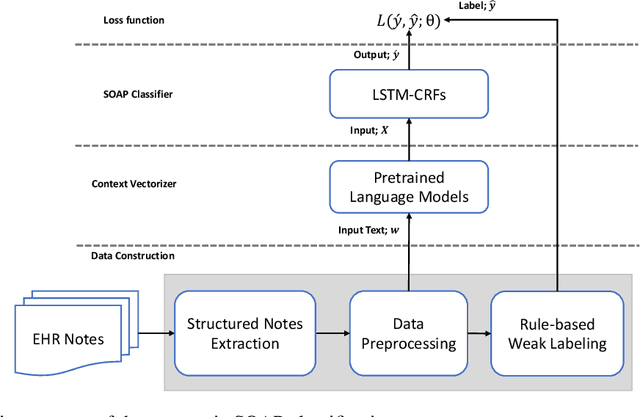
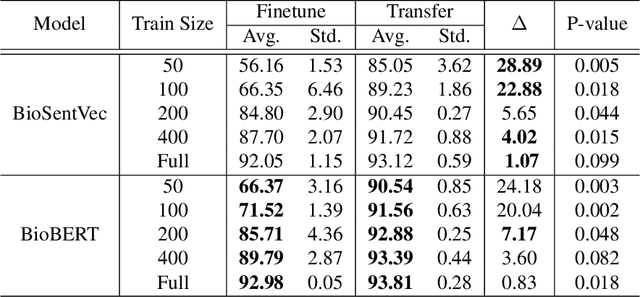
In this paper, we introduce a comprehensive framework for developing a machine learning-based SOAP (Subjective, Objective, Assessment, and Plan) classification system without manually SOAP annotated training data or with less manually SOAP annotated training data. The system is composed of the following two parts: 1) Data construction, 2) A neural network-based SOAP classifier, and 3) Transfer learning framework. In data construction, since a manual construction of a large size training dataset is expensive, we propose a rule-based weak labeling method utilizing the structured information of an EHR note. Then, we present a SOAP classifier composed of a pre-trained language model and bi-directional long-short term memory with conditional random field (Bi-LSTM-CRF). Finally, we propose a transfer learning framework that re-uses the trained parameters of the SOAP classifier trained with the weakly labeled dataset for datasets collected from another hospital. The proposed weakly label-based learning model successfully performed SOAP classification (89.99 F1-score) on the notes collected from the target hospital. Otherwise, in the notes collected from other hospitals and departments, the performance dramatically decreased. Meanwhile, we verified that the transfer learning framework is advantageous for inter-hospital adaptation of the model increasing the models' performance in every cases. In particular, the transfer learning approach was more efficient when the manually annotated data size was smaller. We showed that SOAP classification models trained with our weakly labeling algorithm can perform SOAP classification without manually annotated data on the EHR notes from the same hospital. The transfer learning framework helps SOAP classification model's inter-hospital migration with a minimal size of the manually annotated dataset.
Deep Fake Detection, Deterrence and Response: Challenges and Opportunities
Nov 26, 2022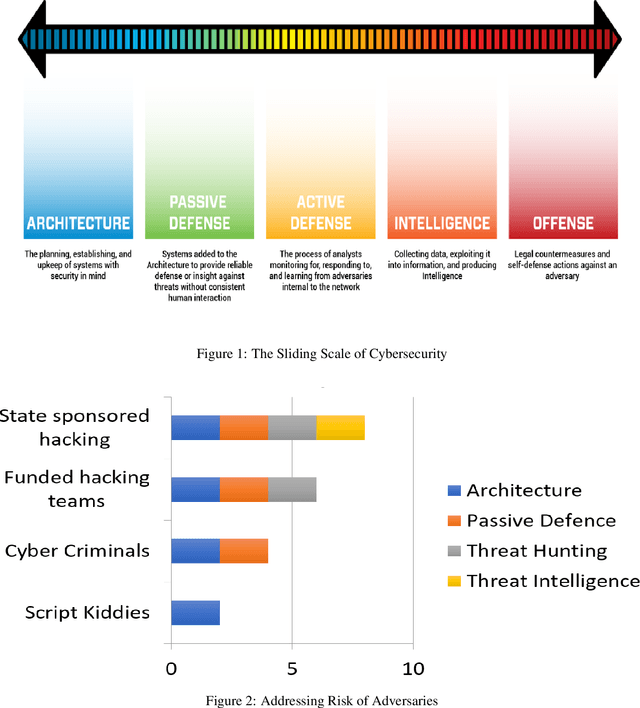
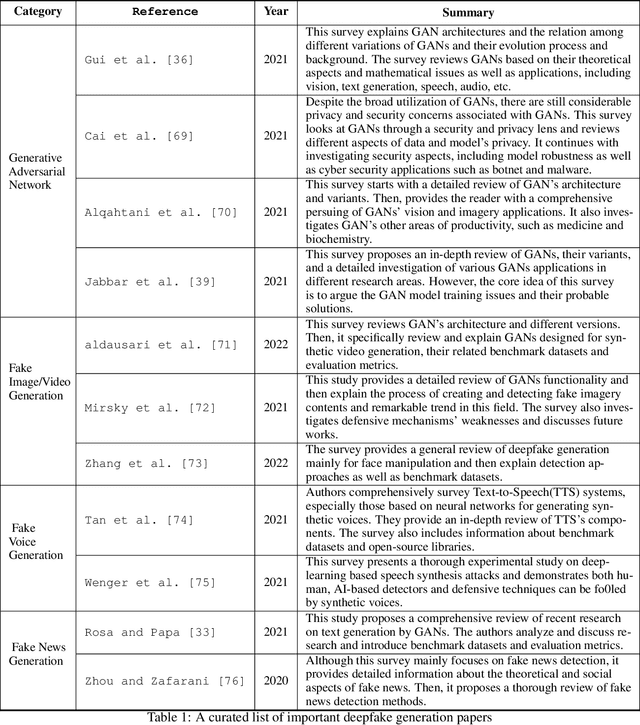
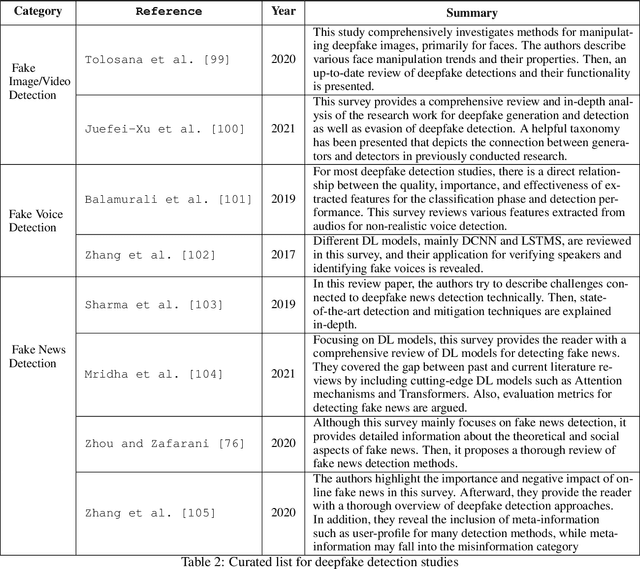
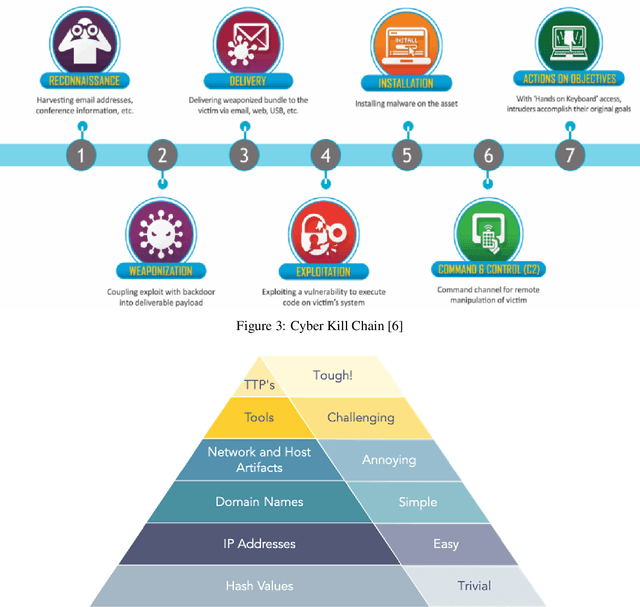
According to the 2020 cyber threat defence report, 78% of Canadian organizations experienced at least one successful cyberattack in 2020. The consequences of such attacks vary from privacy compromises to immersing damage costs for individuals, companies, and countries. Specialists predict that the global loss from cybercrime will reach 10.5 trillion US dollars annually by 2025. Given such alarming statistics, the need to prevent and predict cyberattacks is as high as ever. Our increasing reliance on Machine Learning(ML)-based systems raises serious concerns about the security and safety of these systems. Especially the emergence of powerful ML techniques to generate fake visual, textual, or audio content with a high potential to deceive humans raised serious ethical concerns. These artificially crafted deceiving videos, images, audio, or texts are known as Deepfakes garnered attention for their potential use in creating fake news, hoaxes, revenge porn, and financial fraud. Diversity and the widespread of deepfakes made their timely detection a significant challenge. In this paper, we first offer background information and a review of previous works on the detection and deterrence of deepfakes. Afterward, we offer a solution that is capable of 1) making our AI systems robust against deepfakes during development and deployment phases; 2) detecting video, image, audio, and textual deepfakes; 3) identifying deepfakes that bypass detection (deepfake hunting); 4) leveraging available intelligence for timely identification of deepfake campaigns launched by state-sponsored hacking teams; 5) conducting in-depth forensic analysis of identified deepfake payloads. Our solution would address important elements of the Canada National Cyber Security Action Plan(2019-2024) in increasing the trustworthiness of our critical services.
Homogeneous Multi-modal Feature Fusion and Interaction for 3D Object Detection
Oct 18, 2022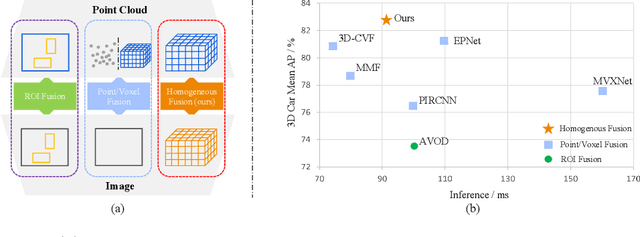
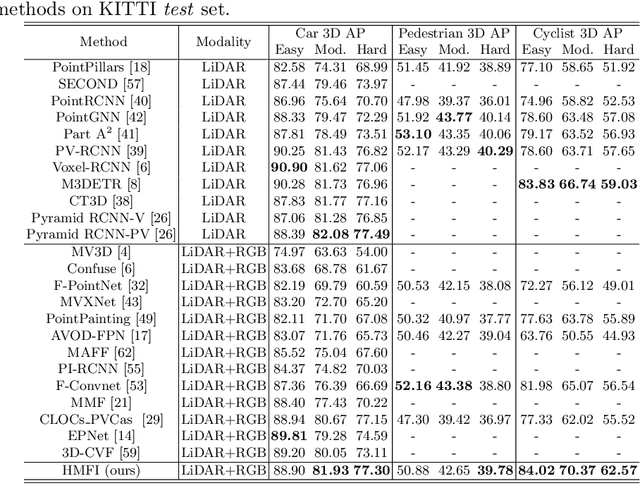
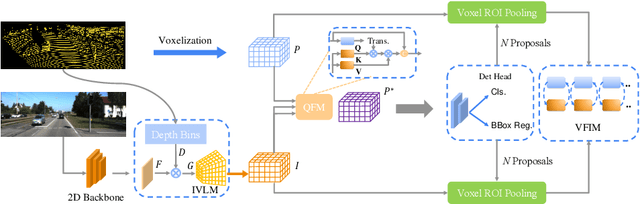
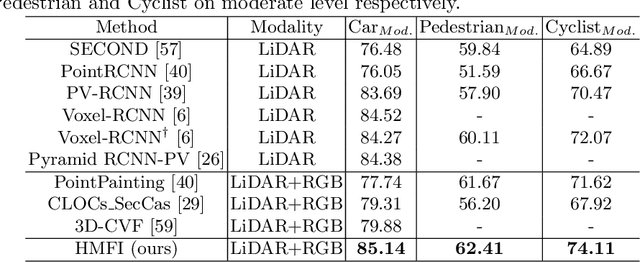
Multi-modal 3D object detection has been an active research topic in autonomous driving. Nevertheless, it is non-trivial to explore the cross-modal feature fusion between sparse 3D points and dense 2D pixels. Recent approaches either fuse the image features with the point cloud features that are projected onto the 2D image plane or combine the sparse point cloud with dense image pixels. These fusion approaches often suffer from severe information loss, thus causing sub-optimal performance. To address these problems, we construct the homogeneous structure between the point cloud and images to avoid projective information loss by transforming the camera features into the LiDAR 3D space. In this paper, we propose a homogeneous multi-modal feature fusion and interaction method (HMFI) for 3D object detection. Specifically, we first design an image voxel lifter module (IVLM) to lift 2D image features into the 3D space and generate homogeneous image voxel features. Then, we fuse the voxelized point cloud features with the image features from different regions by introducing the self-attention based query fusion mechanism (QFM). Next, we propose a voxel feature interaction module (VFIM) to enforce the consistency of semantic information from identical objects in the homogeneous point cloud and image voxel representations, which can provide object-level alignment guidance for cross-modal feature fusion and strengthen the discriminative ability in complex backgrounds. We conduct extensive experiments on the KITTI and Waymo Open Dataset, and the proposed HMFI achieves better performance compared with the state-of-the-art multi-modal methods. Particularly, for the 3D detection of cyclist on the KITTI benchmark, HMFI surpasses all the published algorithms by a large margin.
On the Utility of Self-supervised Models for Prosody-related Tasks
Oct 13, 2022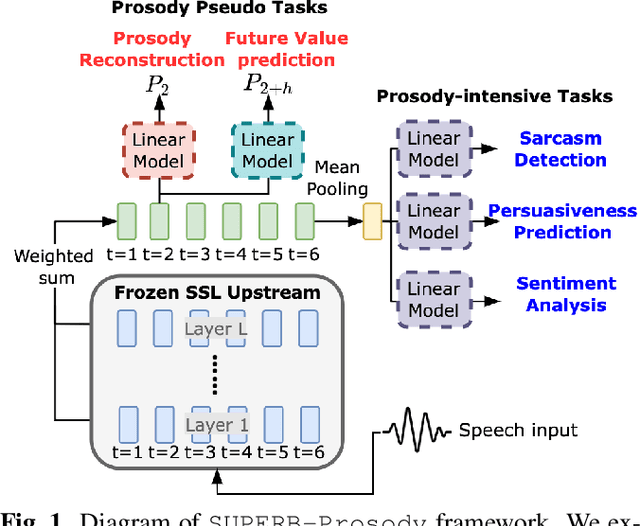
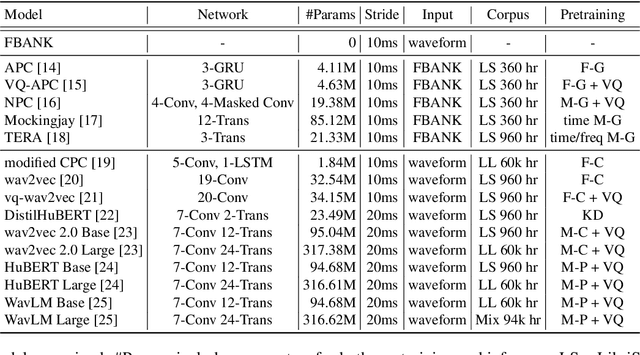
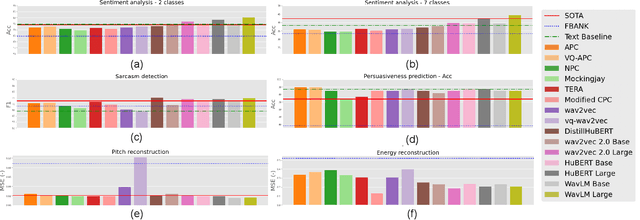
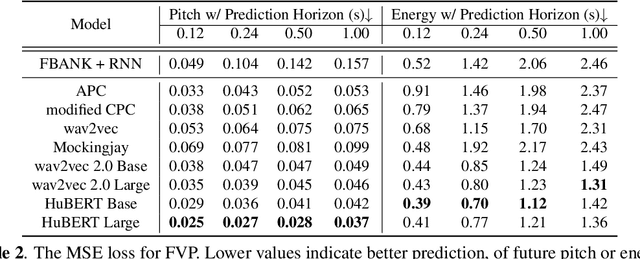
Self-Supervised Learning (SSL) from speech data has produced models that have achieved remarkable performance in many tasks, and that are known to implicitly represent many aspects of information latently present in speech signals. However, relatively little is known about the suitability of such models for prosody-related tasks or the extent to which they encode prosodic information. We present a new evaluation framework, SUPERB-prosody, consisting of three prosody-related downstream tasks and two pseudo tasks. We find that 13 of the 15 SSL models outperformed the baseline on all the prosody-related tasks. We also show good performance on two pseudo tasks: prosody reconstruction and future prosody prediction. We further analyze the layerwise contributions of the SSL models. Overall we conclude that SSL speech models are highly effective for prosody-related tasks.
Seq2Seq-SC: End-to-End Semantic Communication Systems with Pre-trained Language Model
Oct 27, 2022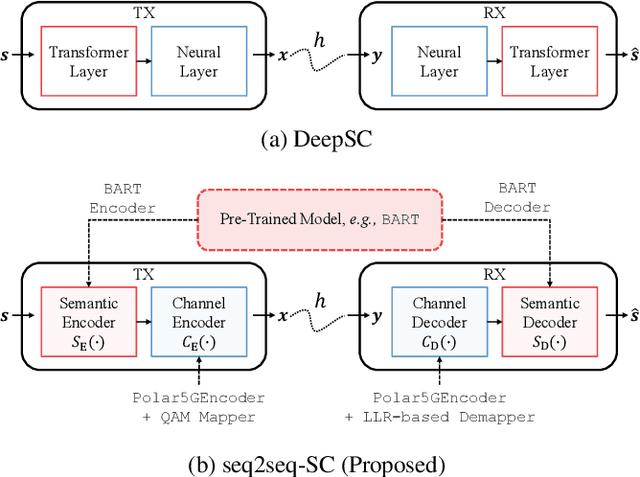
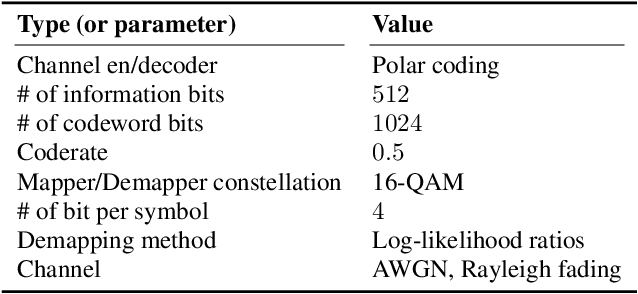
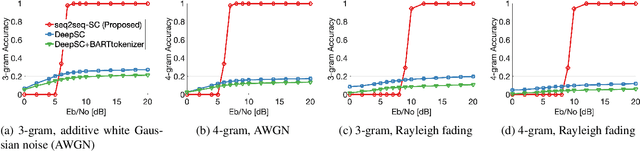

While semantic communication is expected to bring unprecedented communication efficiency in comparison to classical communication, many challenges must be resolved to realize its potential. In this work, we provide a realistic semantic network dubbed seq2seq-SC, which is compatible to 5G NR and can work with generalized text dataset utilizing pre-trained language model. We also utilize a performance metric (SBERT) which can accurately measure semantic similarity and show that seq2seq-SC achieves superior performance while extracting semantically meaningful information.
ZS4IE: A toolkit for Zero-Shot Information Extraction with simple Verbalizations
Mar 28, 2022
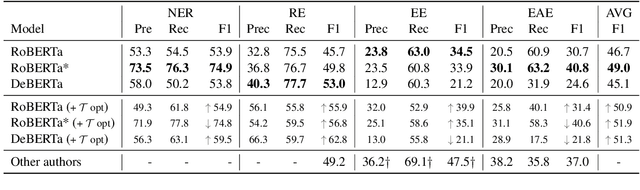
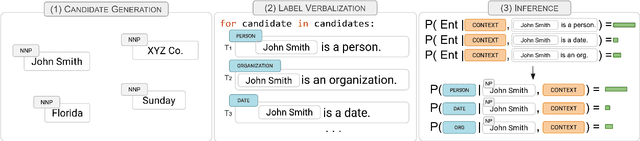

The current workflow for Information Extraction (IE) analysts involves the definition of the entities/relations of interest and a training corpus with annotated examples. In this demonstration we introduce a new workflow where the analyst directly verbalizes the entities/relations, which are then used by a Textual Entailment model to perform zero-shot IE. We present the design and implementation of a toolkit with a user interface, as well as experiments on four IE tasks that show that the system achieves very good performance at zero-shot learning using only 5--15 minutes per type of a user's effort. Our demonstration system is open-sourced at https://github.com/BBN-E/ZS4IE . A demonstration video is available at https://vimeo.com/676138340 .
Learning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022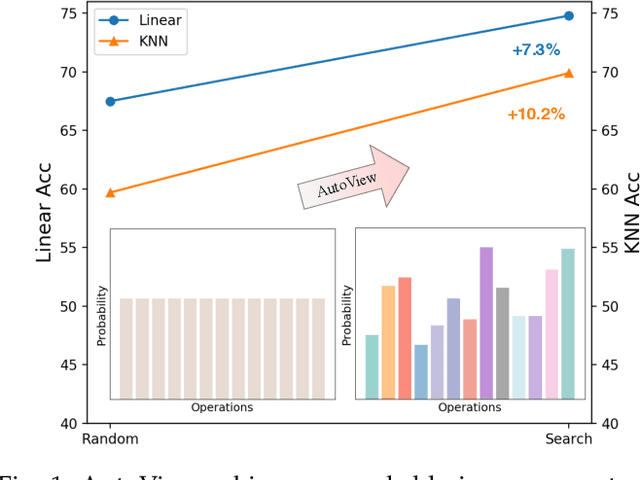
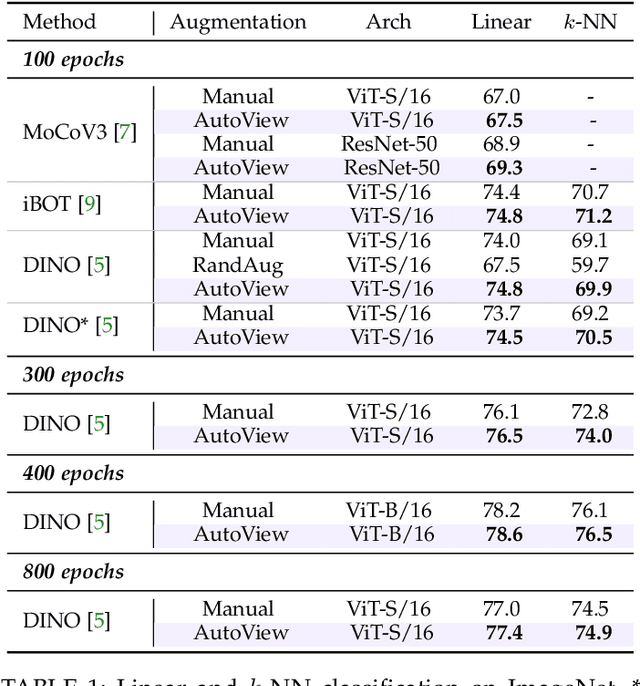
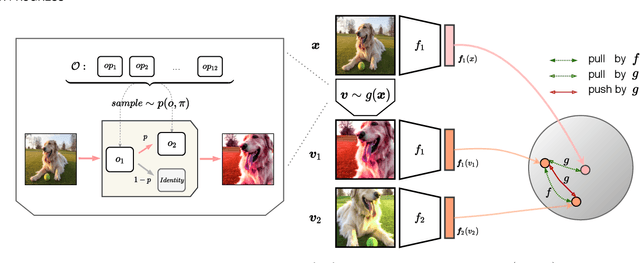

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022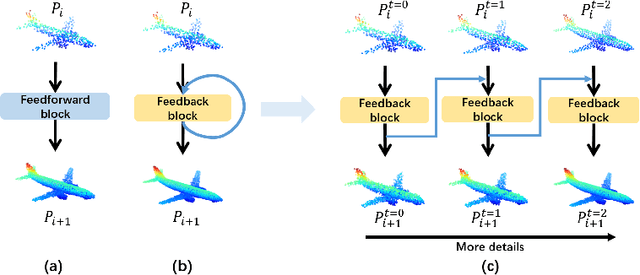
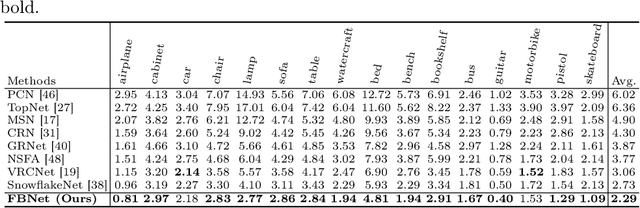
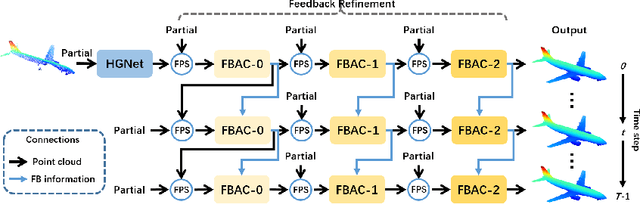
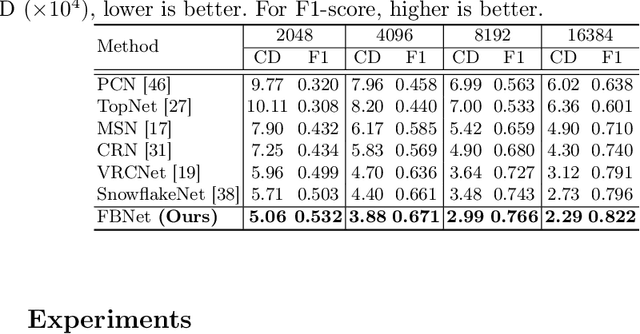
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.
Bird-Eye Transformers for Text Generation Models
Oct 08, 2022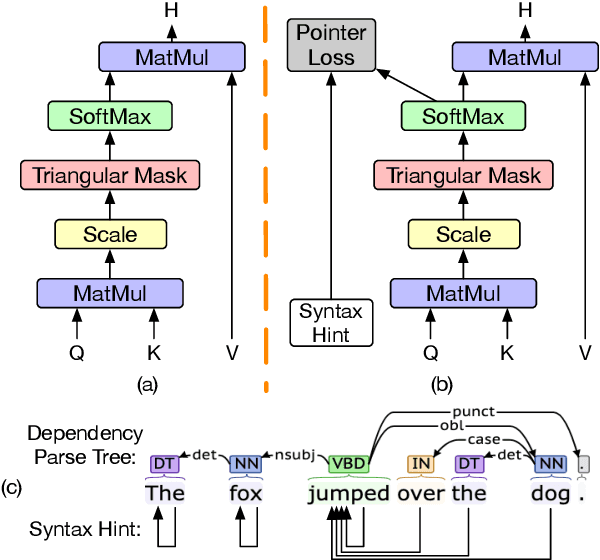
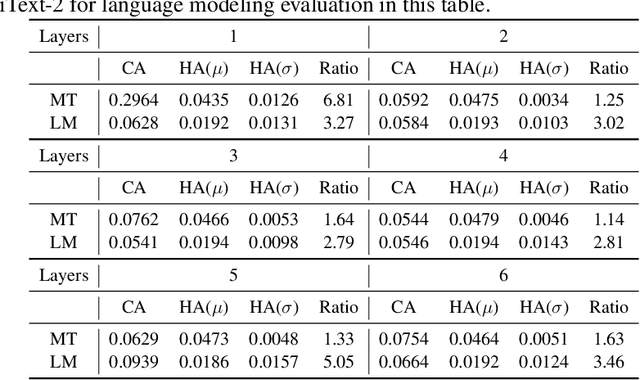
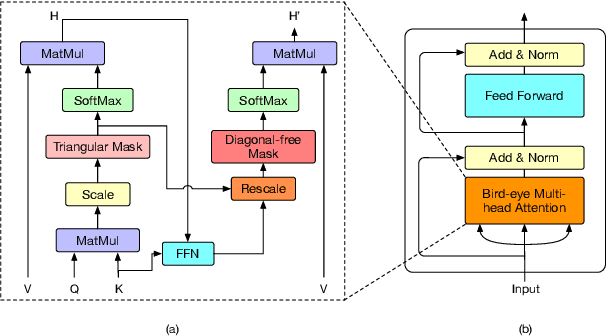
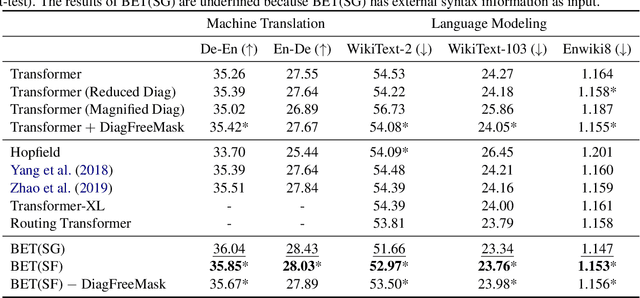
Transformers have become an indispensable module for text generation models since their great success in machine translation. Previous works attribute the~success of transformers to the query-key-value dot-product attention, which provides a robust inductive bias by the fully connected token graphs. However, we found that self-attention has a severe limitation. When predicting the (i+1)-th token, self-attention only takes the i-th token as an information collector, and it tends to give a high attention weight to those tokens similar to itself. Therefore, most of the historical information that occurred before the i-th token is not taken into consideration. Based on this observation, in this paper, we propose a new architecture, called bird-eye transformer(BET), which goes one step further to improve the performance of transformers by reweighting self-attention to encourage it to focus more on important historical information. We have conducted experiments on multiple text generation tasks, including machine translation (2 datasets) and language models (3 datasets). These experimental~results show that our proposed model achieves a better performance than the baseline transformer architectures on~all~datasets. The code is released at: \url{https://sites.google.com/view/bet-transformer/home}.
On the Importance of Image Encoding in Automated Chest X-Ray Report Generation
Nov 24, 2022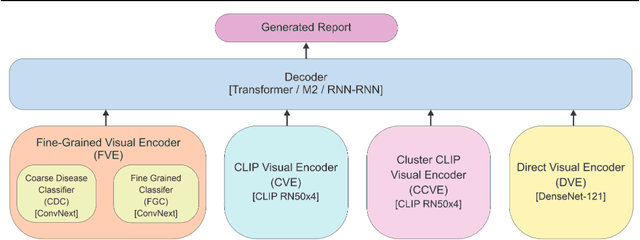
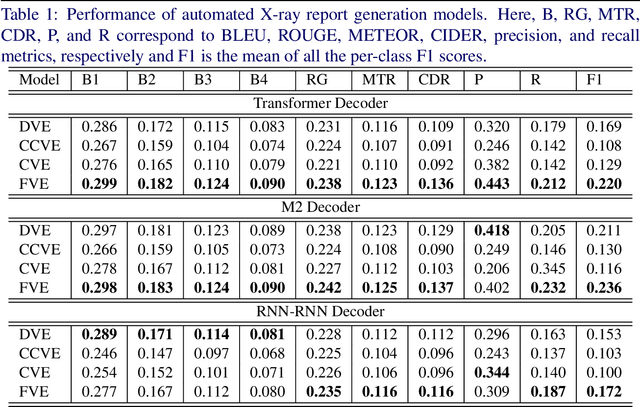
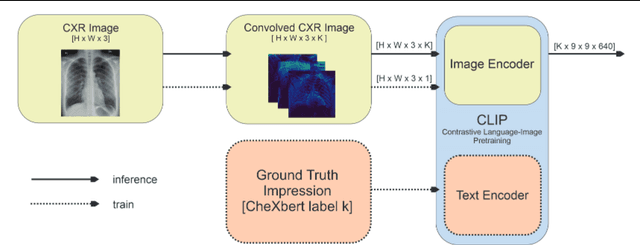
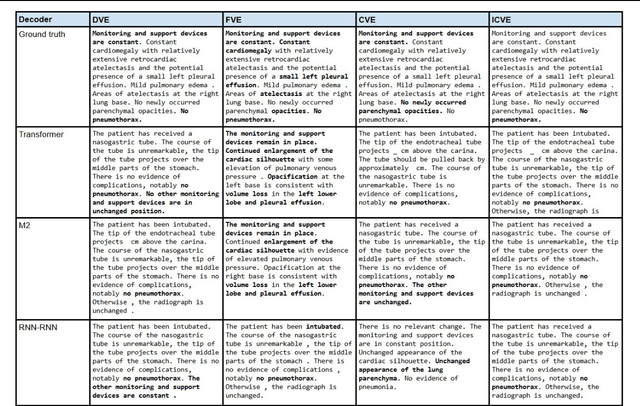
Chest X-ray is one of the most popular medical imaging modalities due to its accessibility and effectiveness. However, there is a chronic shortage of well-trained radiologists who can interpret these images and diagnose the patient's condition. Therefore, automated radiology report generation can be a very helpful tool in clinical practice. A typical report generation workflow consists of two main steps: (i) encoding the image into a latent space and (ii) generating the text of the report based on the latent image embedding. Many existing report generation techniques use a standard convolutional neural network (CNN) architecture for image encoding followed by a Transformer-based decoder for medical text generation. In most cases, CNN and the decoder are trained jointly in an end-to-end fashion. In this work, we primarily focus on understanding the relative importance of encoder and decoder components. Towards this end, we analyze four different image encoding approaches: direct, fine-grained, CLIP-based, and Cluster-CLIP-based encodings in conjunction with three different decoders on the large-scale MIMIC-CXR dataset. Among these encoders, the cluster CLIP visual encoder is a novel approach that aims to generate more discriminative and explainable representations. CLIP-based encoders produce comparable results to traditional CNN-based encoders in terms of NLP metrics, while fine-grained encoding outperforms all other encoders both in terms of NLP and clinical accuracy metrics, thereby validating the importance of image encoder to effectively extract semantic information. GitHub repository: https://github.com/mudabek/encoding-cxr-report-gen