 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accidental Learners: Spoken Language Identification in Multilingual Self-Supervised Models
Nov 09, 2022
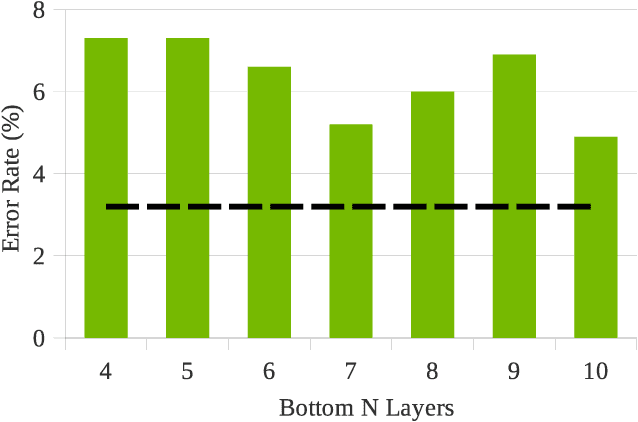
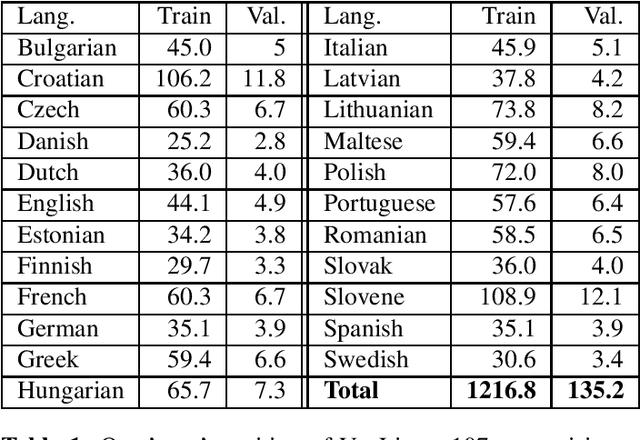
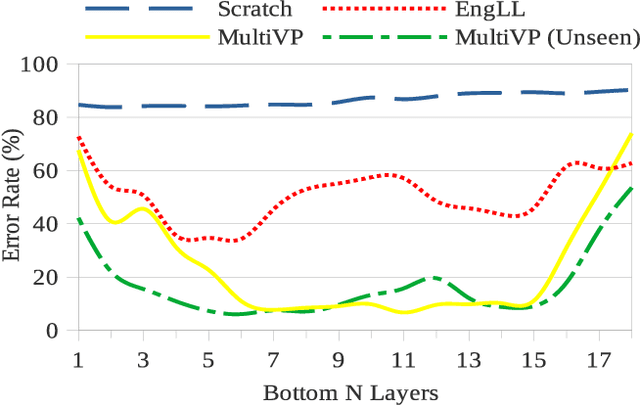
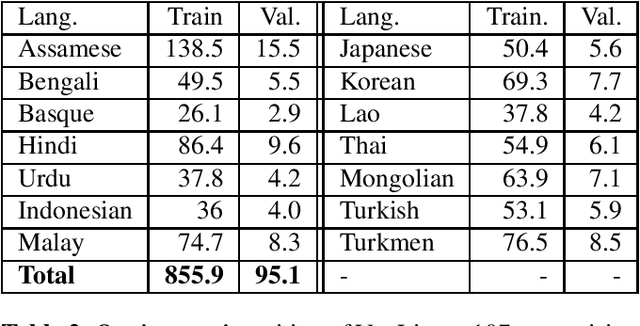
In this paper, we extend previous self-supervised approaches for language identification by experimenting with Conformer based architecture in a multilingual pre-training paradigm. We find that pre-trained speech models optimally encode language discriminatory information in lower layers. Further, we demonstrate that the embeddings obtained from these layers are significantly robust to classify unseen languages and different acoustic environments without additional training. After fine-tuning a pre-trained Conformer model on the VoxLingua107 dataset, we achieve results similar to current state-of-the-art systems for language identification. More, our model accomplishes this with 5x less parameters. We open-source the model through the NVIDIA NeMo toolkit.
Extracting, Visualizing, and Learning from Dynamic Data: Perfusion in Surgical Video for Tissue Characterization
Nov 09, 2022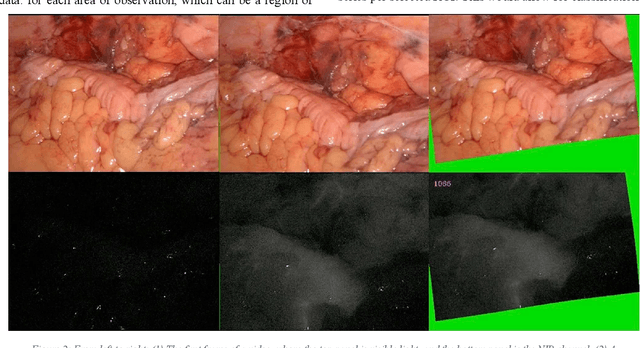
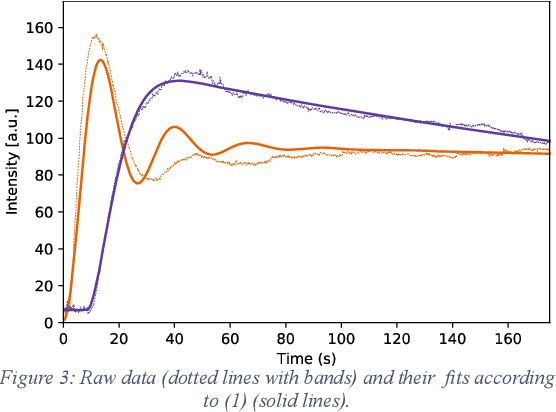
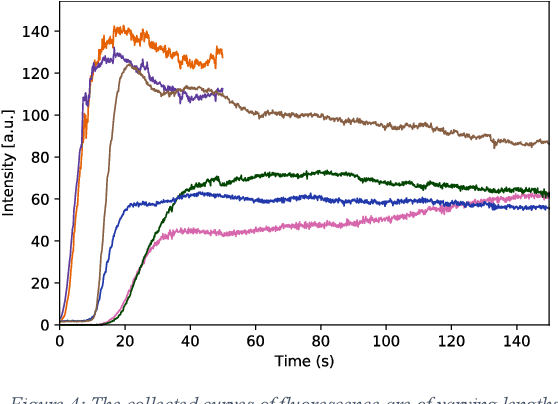
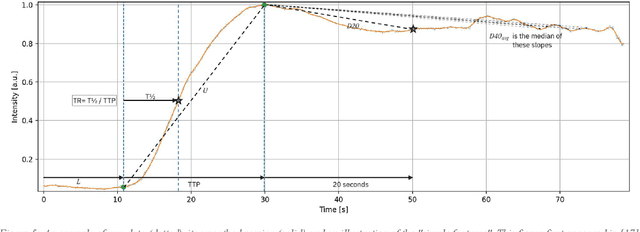
Intraoperative assessment of tissue can be guided through fluorescence imaging which involves systemic dosing with a fluorophore and subsequent examination of the tissue region of interest with a near-infrared camera. This typically involves administering indocyanine green (ICG) hours or even days before surgery and intraoperative visualization at the time predicted for steady-state signal-to-background status. Here, we describe our efforts to capture and utilize the information contained in the first few minutes after ICG administration from the perspective of both signal processing and surgical practice. We prove a method for characterization of cancerous versus benign rectal lesions now undergoing further development and validation via multicenter clinical phase studies.
* Presented and published at IEEE International Conference on Digital Health (ICDH) 2022
Dynamic Interactional And Cooperative Network For Shield Machine
Nov 17, 2022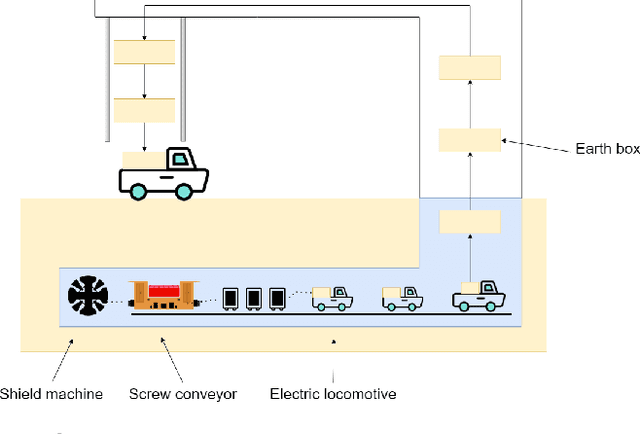
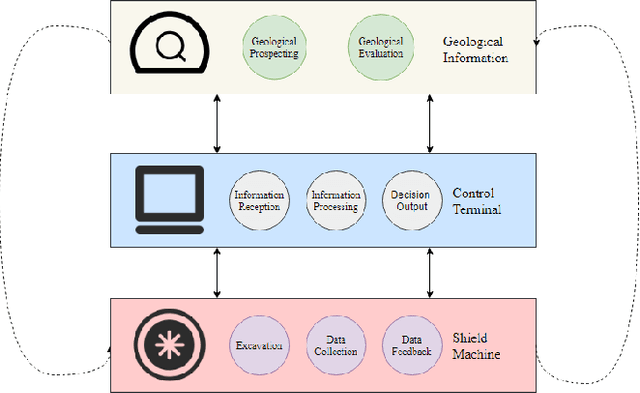
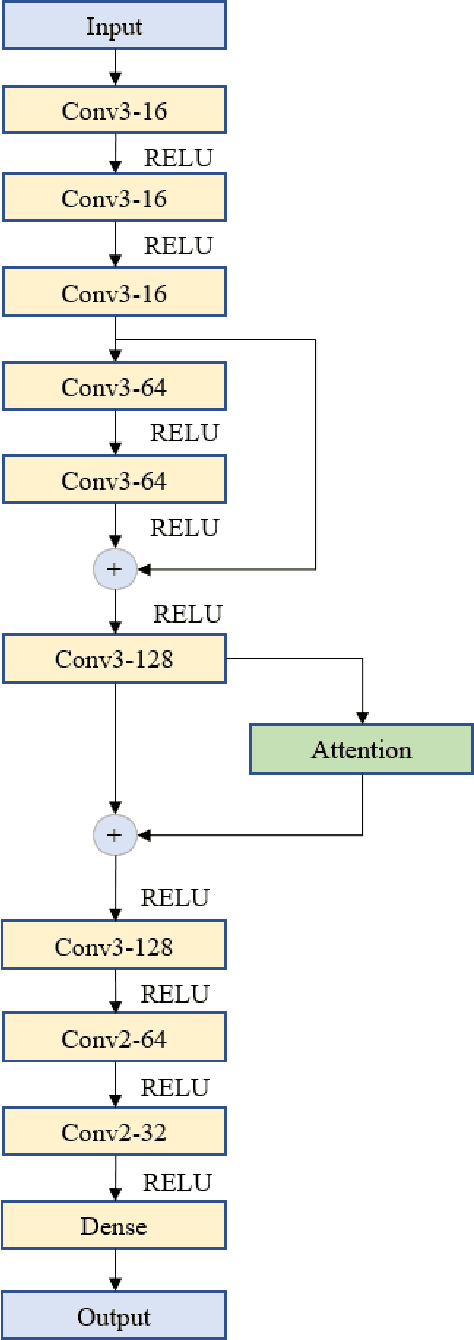
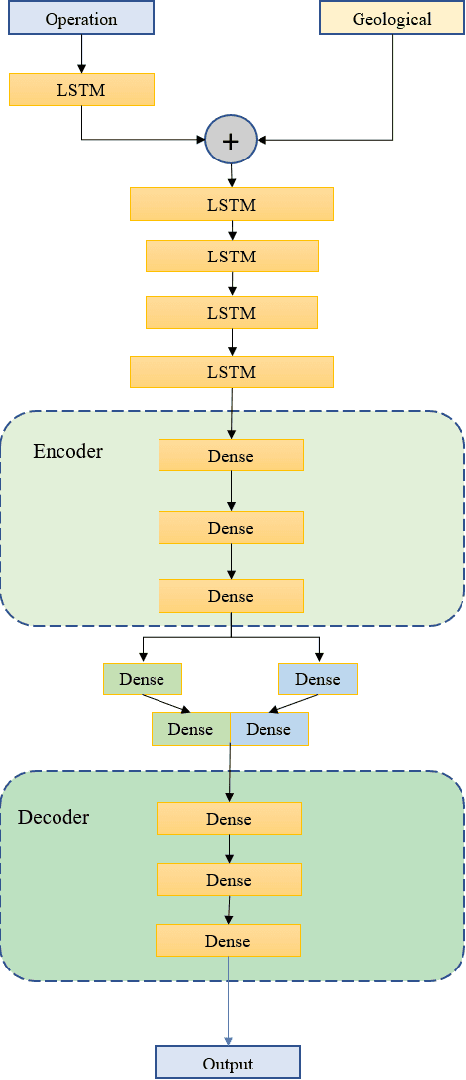
The shield machine (SM) is a complex mechanical device used for tunneling. However, the monitoring and deciding were mainly done by artificial experience during traditional construction, which brought some limitations, such as hidden mechanical failures, human operator error, and sensor anomalies. To deal with these challenges, many scholars have studied SM intelligent methods. Most of these methods only take SM into account but do not consider the SM operating environment. So, this paper discussed the relationship among SM, geological information, and control terminals. Then, according to the relationship, models were established for the control terminal, including SM rate prediction and SM anomaly detection. The experimental results show that compared with baseline models, the proposed models in this paper perform better. In the proposed model, the R2 and MSE of rate prediction can reach 92.2\%, and 0.0064 respectively. The abnormal detection rate of anomaly detection is up to 98.2\%.
Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
Nov 21, 2022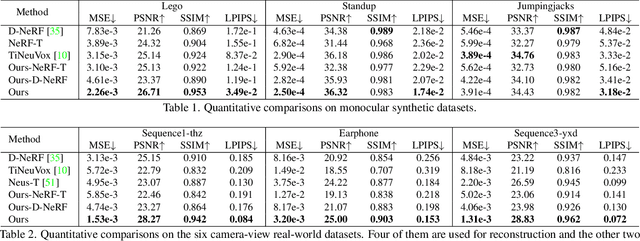
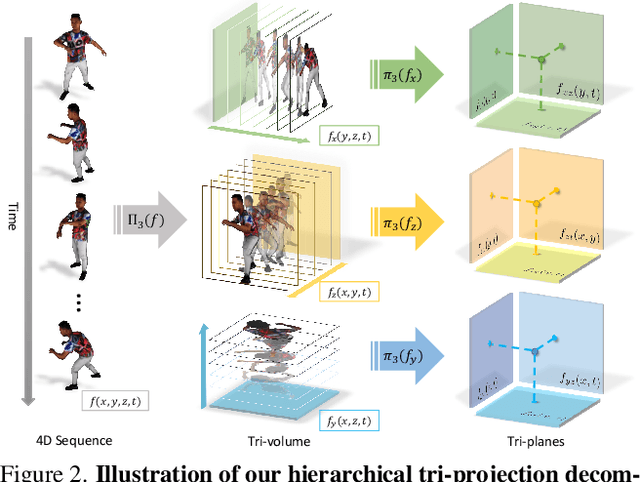
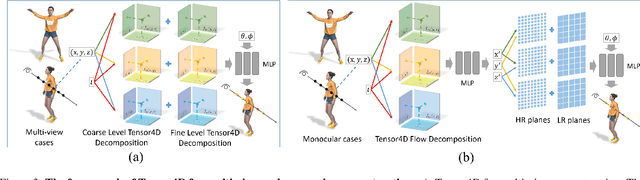
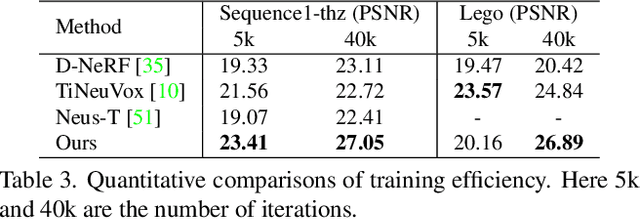
We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. The code and dataset will be released at https://liuyebin.com/tensor4d/tensor4d.html.
Self-training of Machine Learning Models for Liver Histopathology: Generalization under Clinical Shifts
Nov 14, 2022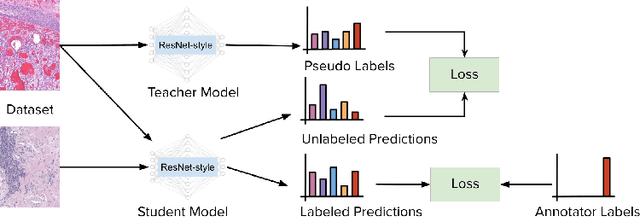
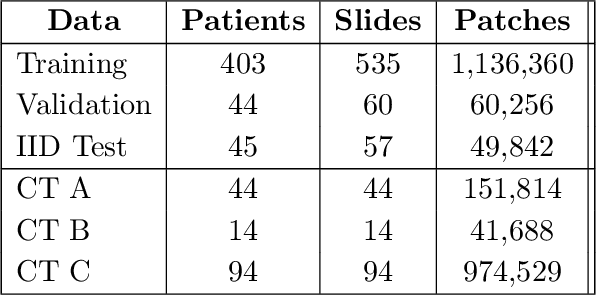
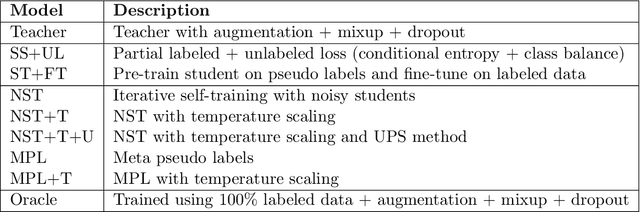
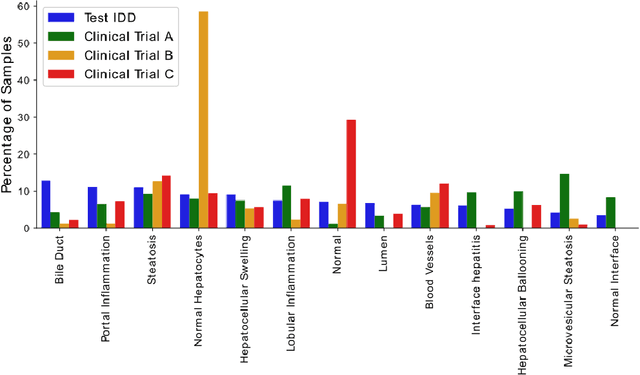
Histopathology images are gigapixel-sized and include features and information at different resolutions. Collecting annotations in histopathology requires highly specialized pathologists, making it expensive and time-consuming. Self-training can alleviate annotation constraints by learning from both labeled and unlabeled data, reducing the amount of annotations required from pathologists. We study the design of teacher-student self-training systems for Non-alcoholic Steatohepatitis (NASH) using clinical histopathology datasets with limited annotations. We evaluate the models on in-distribution and out-of-distribution test data under clinical data shifts. We demonstrate that through self-training, the best student model statistically outperforms the teacher with a $3\%$ absolute difference on the macro F1 score. The best student model also approaches the performance of a fully supervised model trained with twice as many annotations.
MR-NOM: Multi-scale Resolution of Neuronal cells in Nissl-stained histological slices via deliberate Over-segmentation and Merging
Nov 14, 2022

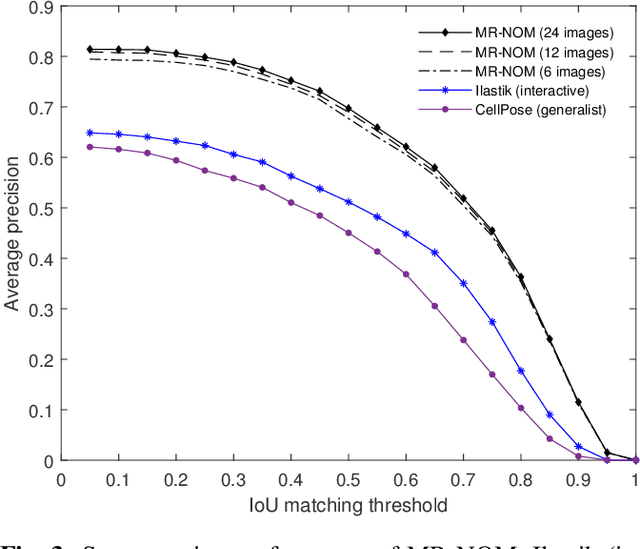
In comparative neuroanatomy, the characterization of brain cytoarchitecture is critical to a better understanding of brain structure and function, as it helps to distill information on the development, evolution, and distinctive features of different populations. The automatic segmentation of individual brain cells is a primary prerequisite and yet remains challenging. A new method (MR-NOM) was developed for the instance segmentation of cells in Nissl-stained histological images of the brain. MR-NOM exploits a multi-scale approach to deliberately over-segment the cells into superpixels and subsequently merge them via a classifier based on shape, structure, and intensity features. The method was tested on images of the cerebral cortex, proving successful in dealing with cells of varying characteristics that partially touch or overlap, showing better performance than two state-of-the-art methods.
DCDetector: An IoT terminal vulnerability mining system based on distributed deep ensemble learning under source code representation
Dec 03, 2022

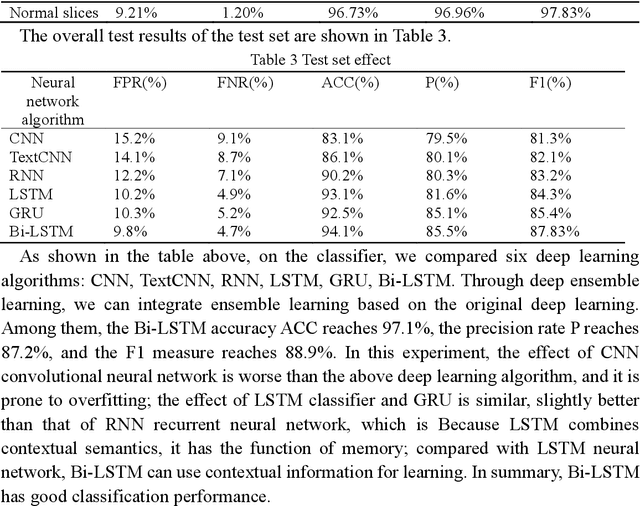
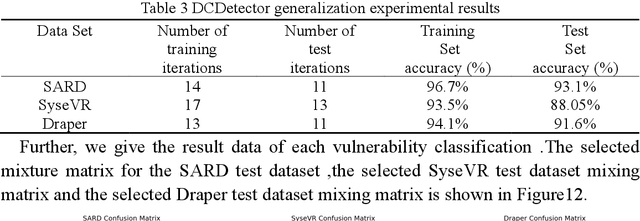
Context: The IoT system infrastructure platform facility vulnerability attack has become the main battlefield of network security attacks. Most of the traditional vulnerability mining methods rely on vulnerability detection tools to realize vulnerability discovery. However, due to the inflexibility of tools and the limitation of file size, its scalability It is relatively low and cannot be applied to large-scale power big data fields. Objective: The goal of the research is to intelligently detect vulnerabilities in source codes of high-level languages such as C/C++. This enables us to propose a code representation of sensitive sentence-related slices of source code, and to detect vulnerabilities by designing a distributed deep ensemble learning model. Method: In this paper, a new directional vulnerability mining method of parallel ensemble learning is proposed to solve the problem of large-scale data vulnerability mining. By extracting sensitive functions and statements, a sensitive statement library of vulnerable codes is formed. The AST stream-based vulnerability code slice with higher granularity performs doc2vec sentence vectorization on the source code through the random sampling module, obtains different classification results through distributed training through the Bi-LSTM trainer, and obtains the final classification result by voting. Results: This method designs and implements a distributed deep ensemble learning system software vulnerability mining system called DCDetector. It can make accurate predictions by using the syntactic information of the code, and is an effective method for analyzing large-scale vulnerability data. Conclusion: Experiments show that this method can reduce the false positive rate of traditional static analysis and improve the performance and accuracy of machine learning.
Distributionally robust risk evaluation with causality constraint and structural information
Mar 20, 2022
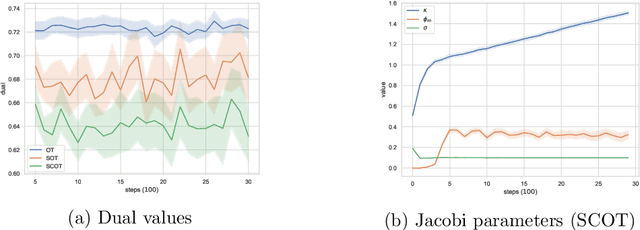
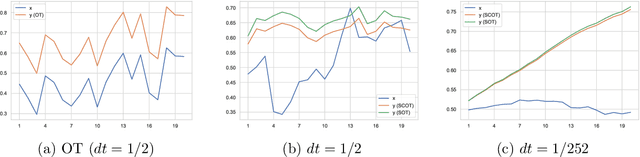
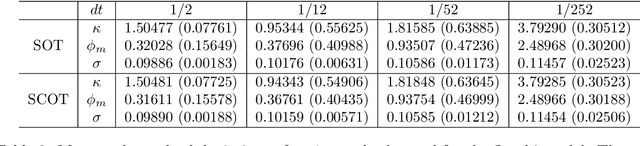
This work studies distributionally robust evaluation of expected function values over temporal data. A set of alternative measures is characterized by the causal optimal transport. We prove the strong duality and recast the causality constraint as minimization over an infinite-dimensional test function space. We approximate test functions by neural networks and prove the sample complexity with Rademacher complexity. Moreover, when structural information is available to further restrict the ambiguity set, we prove the dual formulation and provide efficient optimization methods. Simulation on stochastic volatility and empirical analysis on stock indices demonstrate that our framework offers an attractive alternative to the classic optimal transport formulation.
SDCL: Self-Distillation Contrastive Learning for Chinese Spell Checking
Nov 07, 2022
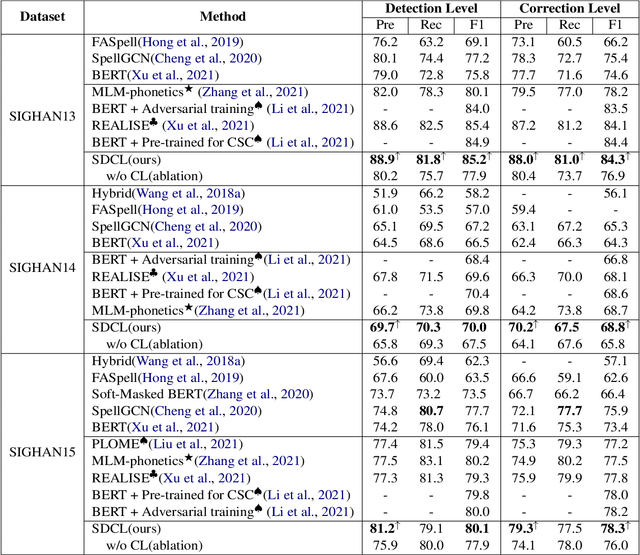
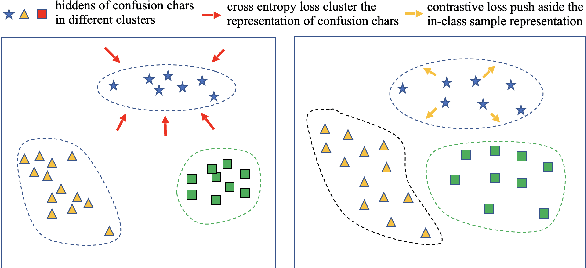
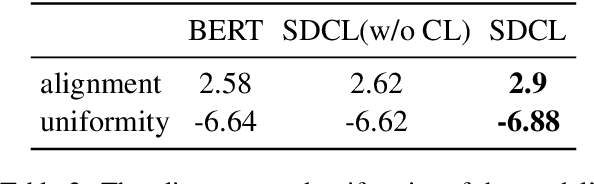
Due to the ambiguity of homophones, Chinese Spell Checking (CSC) has widespread applications. Existing systems typically utilize BERT for text encoding. However, CSC requires the model to account for both phonetic and graphemic information. To adapt BERT to the CSC task, we propose a token-level self-distillation contrastive learning method. We employ BERT to encode both the corrupted and corresponding correct sentence. Then, we use contrastive learning loss to regularize corrupted tokens' hidden states to be closer to counterparts in the correct sentence. On three CSC datasets, we confirmed our method provides a significant improvement above baselines.
Re-thinking Knowledge Graph Completion Evaluation from an Information Retrieval Perspective
May 09, 2022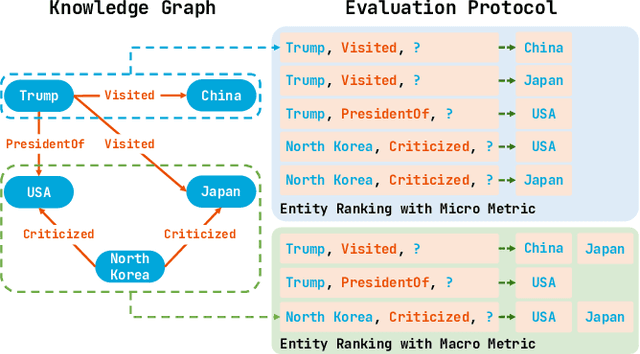
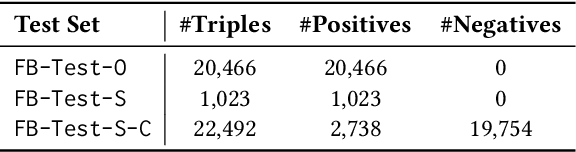
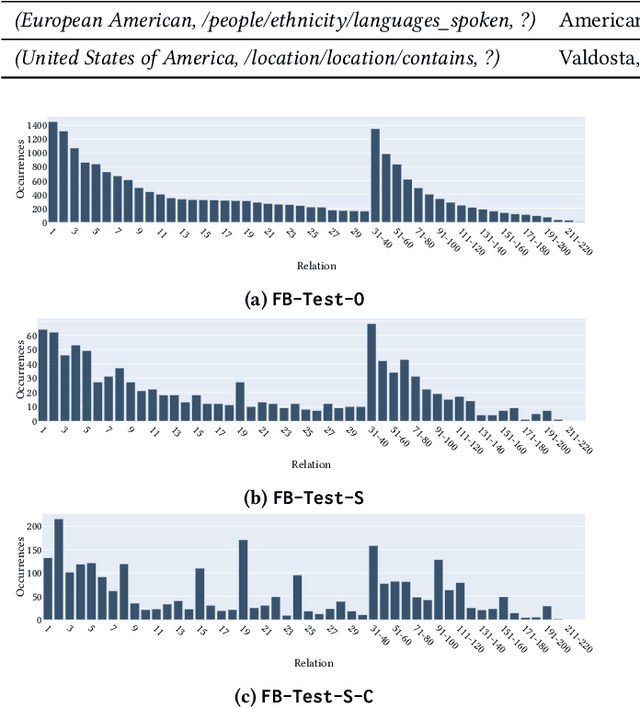

Knowledge graph completion (KGC) aims to infer missing knowledge triples based on known facts in a knowledge graph. Current KGC research mostly follows an entity ranking protocol, wherein the effectiveness is measured by the predicted rank of a masked entity in a test triple. The overall performance is then given by a micro(-average) metric over all individual answer entities. Due to the incomplete nature of the large-scale knowledge bases, such an entity ranking setting is likely affected by unlabelled top-ranked positive examples, raising questions on whether the current evaluation protocol is sufficient to guarantee a fair comparison of KGC systems. To this end, this paper presents a systematic study on whether and how the label sparsity affects the current KGC evaluation with the popular micro metrics. Specifically, inspired by the TREC paradigm for large-scale information retrieval (IR) experimentation, we create a relatively "complete" judgment set based on a sample from the popular FB15k-237 dataset following the TREC pooling method. According to our analysis, it comes as a surprise that switching from the original labels to our "complete" labels results in a drastic change of system ranking of a variety of 13 popular KGC models in terms of micro metrics. Further investigation indicates that the IR-like macro(-average) metrics are more stable and discriminative under different settings, meanwhile, less affected by label sparsity. Thus, for KGC evaluation, we recommend conducting TREC-style pooling to balance between human efforts and label completeness, and reporting also the IR-like macro metrics to reflect the ranking nature of the KGC task.