 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inapplicable Actions Learning for Knowledge Transfer in Reinforcement Learning
Nov 28, 2022
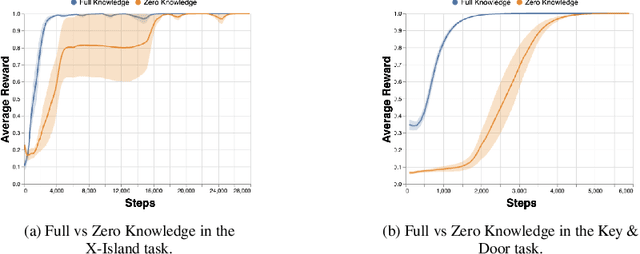
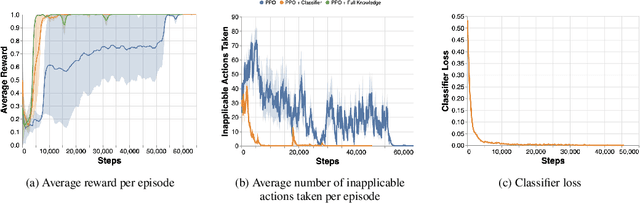
Reinforcement Learning (RL) algorithms are known to scale poorly to environments with many available actions, requiring numerous samples to learn an optimal policy. The traditional approach of considering the same fixed action space in every possible state implies that the agent must understand, while also learning to maximize its reward, to ignore irrelevant actions such as $\textit{inapplicable actions}$ (i.e. actions that have no effect on the environment when performed in a given state). Knowing this information can help reduce the sample complexity of RL algorithms by masking the inapplicable actions from the policy distribution to only explore actions relevant to finding an optimal policy. This is typically done in an ad-hoc manner with hand-crafted domain logic added to the RL algorithm. In this paper, we propose a more systematic approach to introduce this knowledge into the algorithm. We (i) standardize the way knowledge can be manually specified to the agent; and (ii) present a new framework to autonomously learn these state-dependent action constraints jointly with the policy. We show experimentally that learning inapplicable actions greatly improves the sample efficiency of the algorithm by providing a reliable signal to mask out irrelevant actions. Moreover, we demonstrate that thanks to the transferability of the knowledge acquired, it can be reused in other tasks to make the learning process more efficient.
Higher-order Knowledge Transfer for Dynamic Community Detection with Great Changes
Nov 28, 2022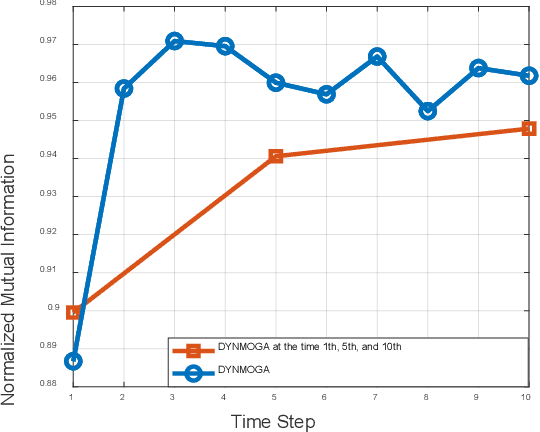
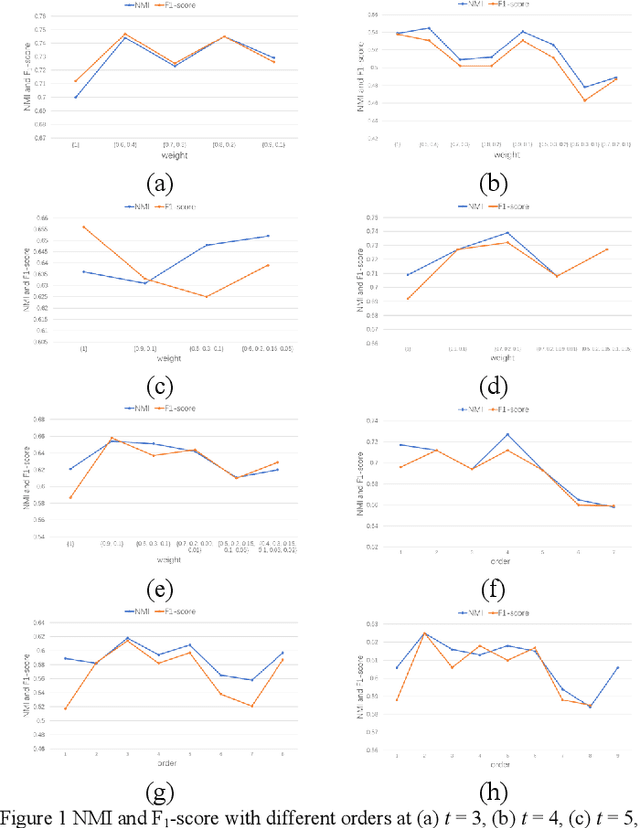
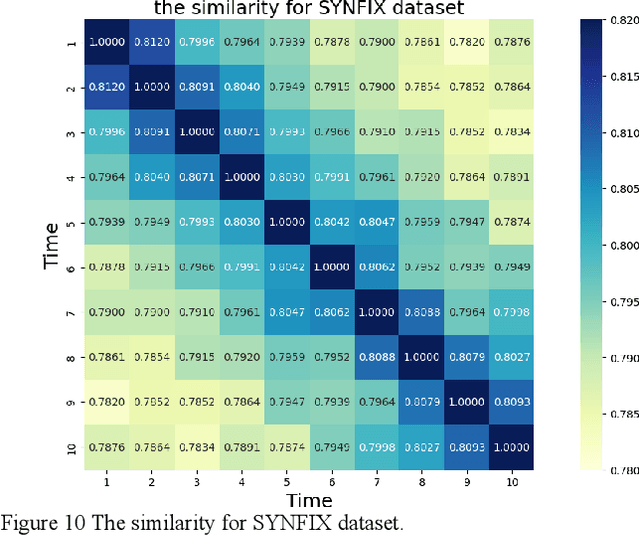
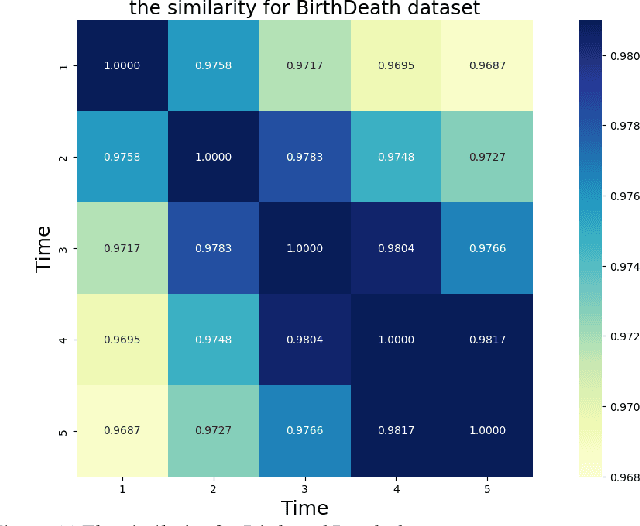
Network structure evolves with time in the real world, and the discovery of changing communities in dynamic networks is an important research topic that poses challenging tasks. Most existing methods assume that no significant change in the network occurs; namely, the difference between adjacent snapshots is slight. However, great change exists in the real world usually. The great change in the network will result in the community detection algorithms are difficulty obtaining valuable information from the previous snapshot, leading to negative transfer for the next time steps. This paper focuses on dynamic community detection with substantial changes by integrating higher-order knowledge from the previous snapshots to aid the subsequent snapshots. Moreover, to improve search efficiency, a higher-order knowledge transfer strategy is designed to determine first-order and higher-order knowledge by detecting the similarity of the adjacency matrix of snapshots. In this way, our proposal can better keep the advantages of previous community detection results and transfer them to the next task. We conduct the experiments on four real-world networks, including the networks with great or minor changes. Experimental results in the low-similarity datasets demonstrate that higher-order knowledge is more valuable than first-order knowledge when the network changes significantly and keeps the advantage even if handling the high-similarity datasets. Our proposal can also guide other dynamic optimization problems with great changes.
Statistical Feature-based Personal Information Detection in Mobile Network Traffic
Dec 23, 2021

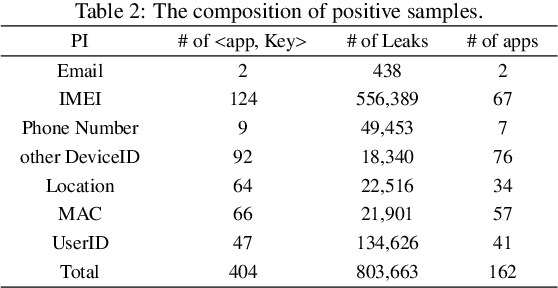
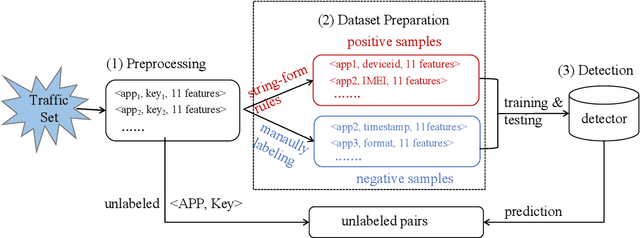
With the popularity of smartphones, mobile applications (apps) have penetrated the daily life of people. Although apps provide rich functionalities, they also access a large amount of personal information simultaneously. As a result, privacy concerns are raised. To understand what personal information the apps collect, many solutions are presented to detect privacy leaks in apps. Recently, the traffic monitoring-based privacy leak detection method has shown promising performance and strong scalability. However, it still has some shortcomings. Firstly, it suffers from detecting the leakage of personal information with obfuscation. Secondly, it cannot discover the privacy leaks of undefined type. Aiming at solving the above problems, a new personal information detection method based on traffic monitoring is proposed in this paper. In this paper, statistical features of personal information are designed to depict the occurrence patterns of personal information in the traffic, including local patterns and global patterns. Then a detector is trained based on machine learning algorithms to discover potential personal information with similar patterns. Since the statistical features are independent of the value and type of personal information, the trained detector is capable of identifying various types of privacy leaks and obfuscated privacy leaks. As far as we know, this is the first work that detects personal information based on statistical features. Finally, the experimental results show that the proposed method could achieve better performance than the state-of-the-art.
Perceive, Represent, Generate: Translating Multimodal Information to Robotic Motion Trajectories
Apr 06, 2022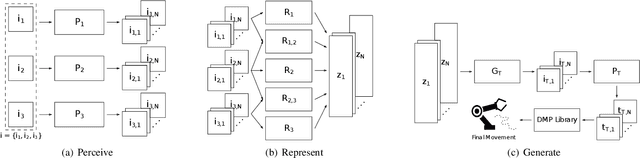



We present Perceive-Represent-Generate (PRG), a novel three-stage framework that maps perceptual information of different modalities (e.g., visual or sound), corresponding to a sequence of instructions, to an adequate sequence of movements to be executed by a robot. In the first stage, we perceive and pre-process the given inputs, isolating individual commands from the complete instruction provided by a human user. In the second stage we encode the individual commands into a multimodal latent space, employing a deep generative model. Finally, in the third stage we convert the multimodal latent values into individual trajectories and combine them into a single dynamic movement primitive, allowing its execution in a robotic platform. We evaluate our pipeline in the context of a novel robotic handwriting task, where the robot receives as input a word through different perceptual modalities (e.g., image, sound), and generates the corresponding motion trajectory to write it, creating coherent and readable handwritten words.
Top-K Ranking Deep Contextual Bandits for Information Selection Systems
Jan 28, 2022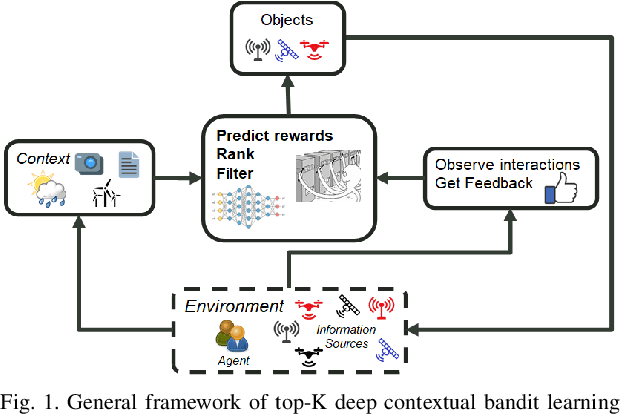

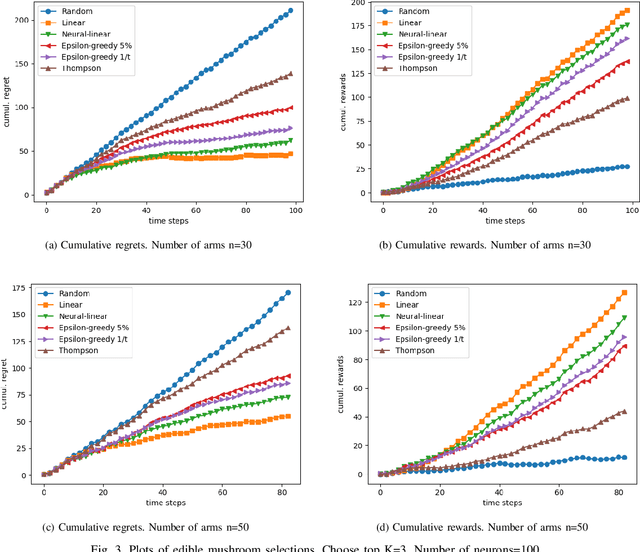
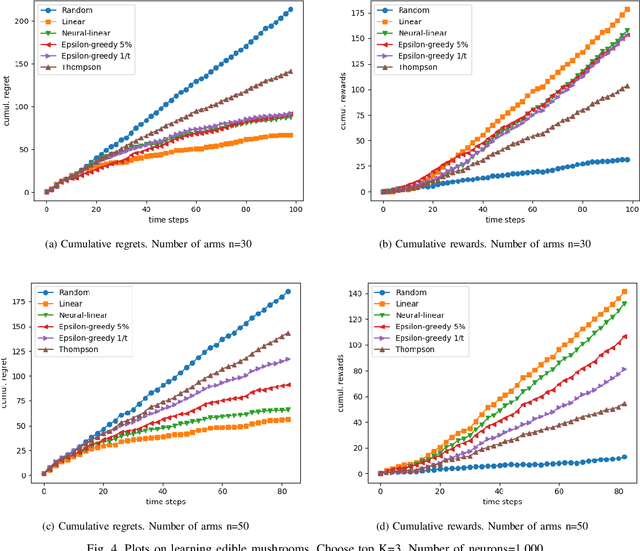
In today's technology environment, information is abundant, dynamic, and heterogeneous in nature. Automated filtering and prioritization of information is based on the distinction between whether the information adds substantial value toward one's goal or not. Contextual multi-armed bandit has been widely used for learning to filter contents and prioritize according to user interest or relevance. Learn-to-Rank technique optimizes the relevance ranking on items, allowing the contents to be selected accordingly. We propose a novel approach to top-K rankings under the contextual multi-armed bandit framework. We model the stochastic reward function with a neural network to allow non-linear approximation to learn the relationship between rewards and contexts. We demonstrate the approach and evaluate the the performance of learning from the experiments using real world data sets in simulated scenarios. Empirical results show that this approach performs well under the complexity of a reward structure and high dimensional contextual features.
Artificial Intelligence and Natural Language Processing and Understanding in Space: Four ESA Case Studies
Oct 07, 2022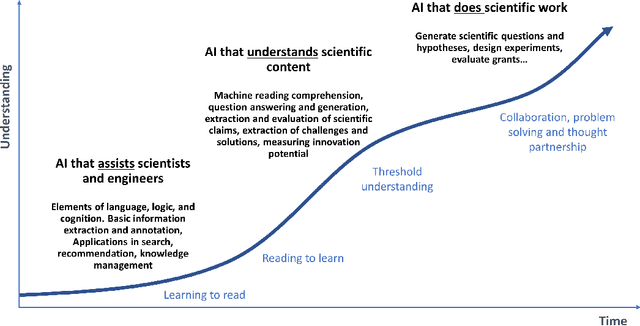
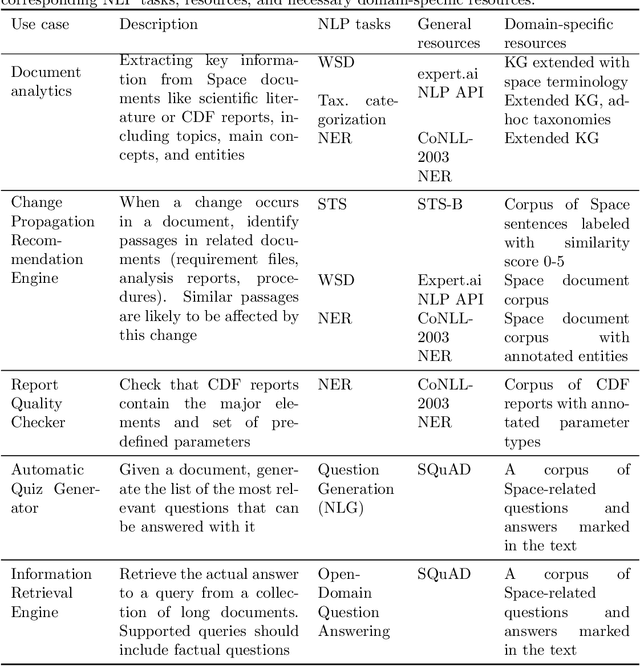
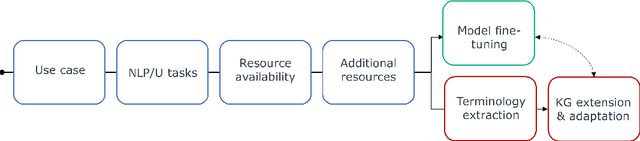
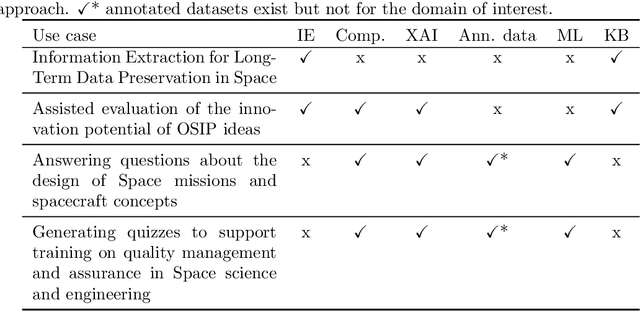
The European Space Agency is well known as a powerful force for scientific discovery in numerous areas related to Space. The amount and depth of the knowledge produced throughout the different missions carried out by ESA and their contribution to scientific progress is enormous, involving large collections of documents like scientific publications, feasibility studies, technical reports, and quality management procedures, among many others. Through initiatives like the Open Space Innovation Platform, ESA also acts as a hub for new ideas coming from the wider community across different challenges, contributing to a virtuous circle of scientific discovery and innovation. Handling such wealth of information, of which large part is unstructured text, is a colossal task that goes beyond human capabilities, hence requiring automation. In this paper, we present a methodological framework based on artificial intelligence and natural language processing and understanding to automatically extract information from Space documents, generating value from it, and illustrate such framework through several case studies implemented across different functional areas of ESA, including Mission Design, Quality Assurance, Long-Term Data Preservation, and the Open Space Innovation Platform. In doing so, we demonstrate the value of these technologies in several tasks ranging from effortlessly searching and recommending Space information to automatically determining how innovative an idea can be, answering questions about Space, and generating quizzes regarding quality procedures. Each of these accomplishments represents a step forward in the application of increasingly intelligent AI systems in Space, from structuring and facilitating information access to intelligent systems capable to understand and reason with such information.
Data Converter Design Space Exploration for IoT Applications: An Overview of Challenges and Future Directions
Nov 03, 2022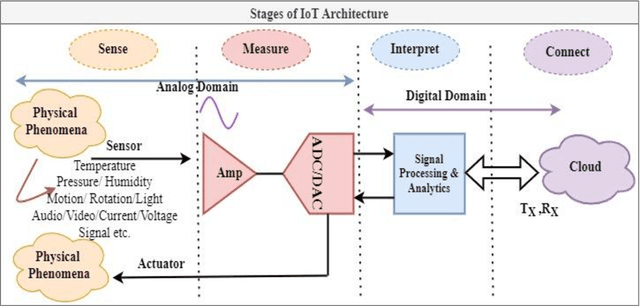
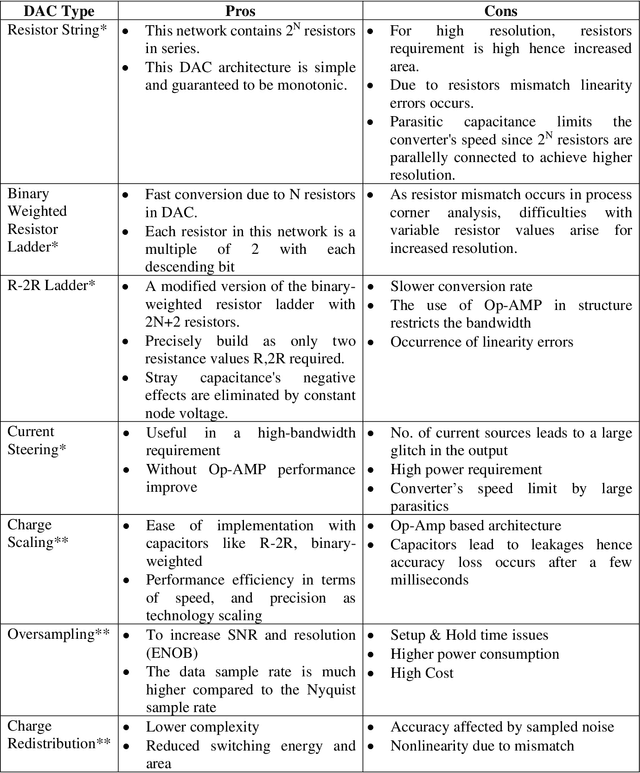
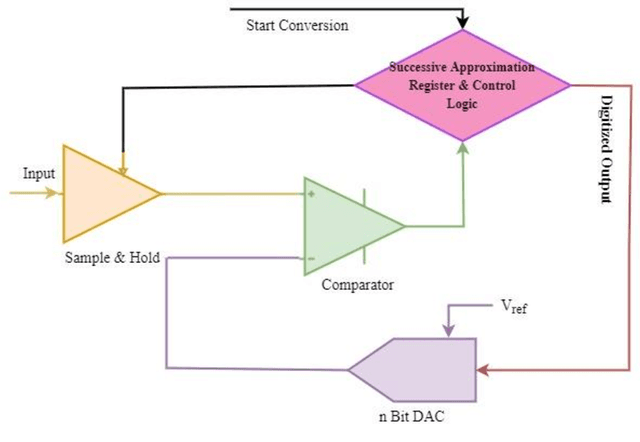
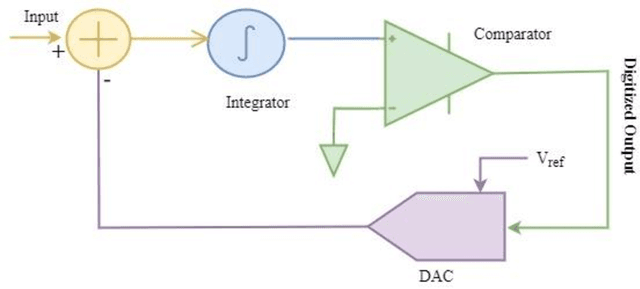
Human lives are improving with the widespread use of cutting-edge digital technology like the Internet of Things (IoT). Recently, the pandemic has shown the demand for more digitally advanced IoT-based devices. International Data Corporation (IDC) forecasts that by 2025, there will be approximately 42 billion of these devices in use, capable of producing around 80 ZB (zettabytes) of data. So data acquisition, processing, communication, and visualization are necessary from a functional standpoint. Indicating sensors & data converters are the key components for IoT-based applications. The efficiency of such applications is truly measured in terms of latency, power, and resolution of data converters motivating designers to perform efficiently. Sensors capture and covert physical features from their chosen environment into detectable quantities. Data converter gives meaningful information and connects the real analog world to the digital component of the devices. The received data is interpreted and analyzed with the digital processing circuitry. Ultimately, it is used as information by a network of internet-connected smart devices. Because IoT technologies are adaptable to nearly any technology that may provide its operational activity and environmental conditions. But the challenges occur with power consumption as the complete IoT framework is battery operated and replacing a battery is a daunting task. So the goal of this chapter is to unveil the requirements to design energy-efficient data converters for IoT applications.
Temporal Consistency Learning of inter-frames for Video Super-Resolution
Nov 03, 2022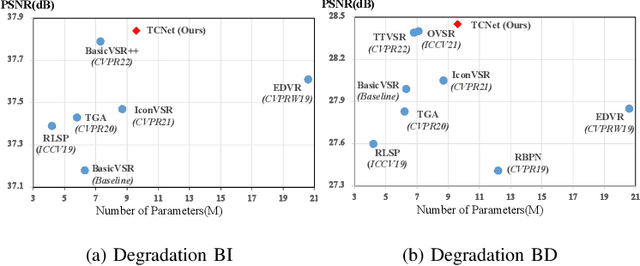
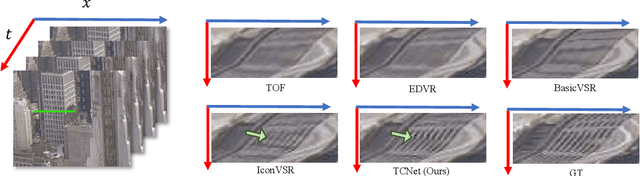


Video super-resolution (VSR) is a task that aims to reconstruct high-resolution (HR) frames from the low-resolution (LR) reference frame and multiple neighboring frames. The vital operation is to utilize the relative misaligned frames for the current frame reconstruction and preserve the consistency of the results. Existing methods generally explore information propagation and frame alignment to improve the performance of VSR. However, few studies focus on the temporal consistency of inter-frames. In this paper, we propose a Temporal Consistency learning Network (TCNet) for VSR in an end-to-end manner, to enhance the consistency of the reconstructed videos. A spatio-temporal stability module is designed to learn the self-alignment from inter-frames. Especially, the correlative matching is employed to exploit the spatial dependency from each frame to maintain structural stability. Moreover, a self-attention mechanism is utilized to learn the temporal correspondence to implement an adaptive warping operation for temporal consistency among multi-frames. Besides, a hybrid recurrent architecture is designed to leverage short-term and long-term information. We further present a progressive fusion module to perform a multistage fusion of spatio-temporal features. And the final reconstructed frames are refined by these fused features. Objective and subjective results of various experiments demonstrate that TCNet has superior performance on different benchmark datasets, compared to several state-of-the-art methods.
An Empirical Study on Finding Spans
Oct 14, 2022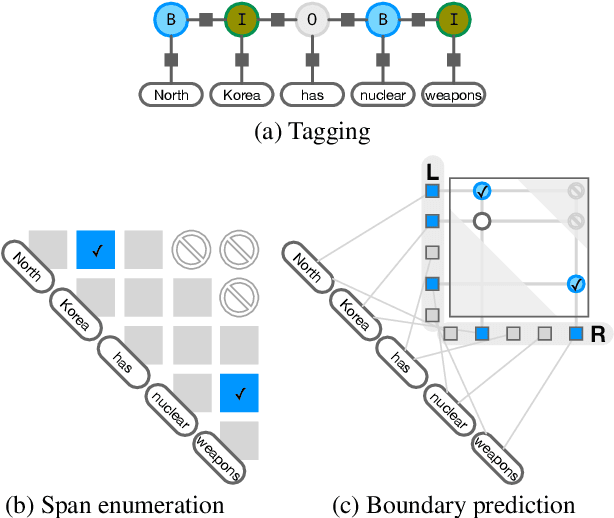
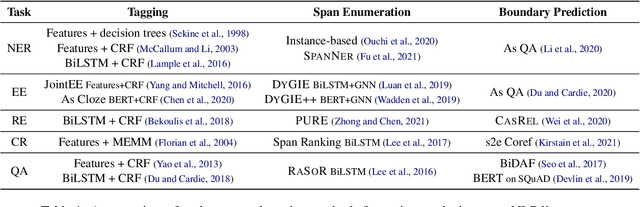
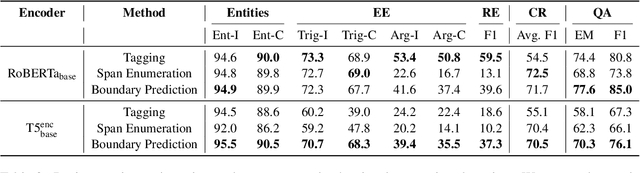
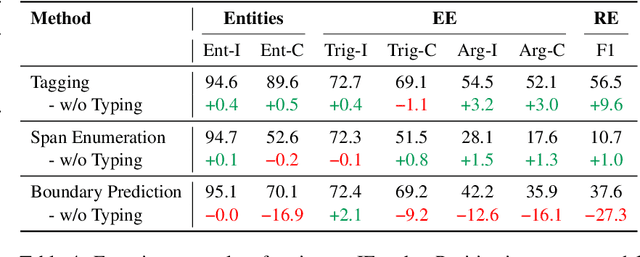
We present an empirical study on methods for span finding, the selection of consecutive tokens in text for some downstream tasks. We focus on approaches that can be employed in training end-to-end information extraction systems, and find there is no definitive solution without considering task properties, and provide our observations to help with future design choices: 1) a tagging approach often yields higher precision while span enumeration and boundary prediction provide higher recall; 2) span type information can benefit a boundary prediction approach; 3) additional contextualization does not help span finding in most cases.
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models
Oct 06, 2022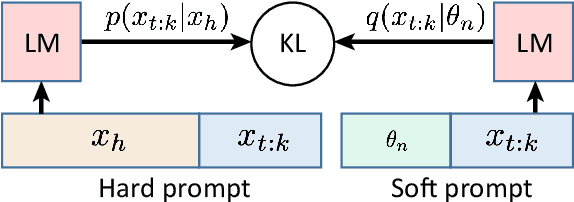

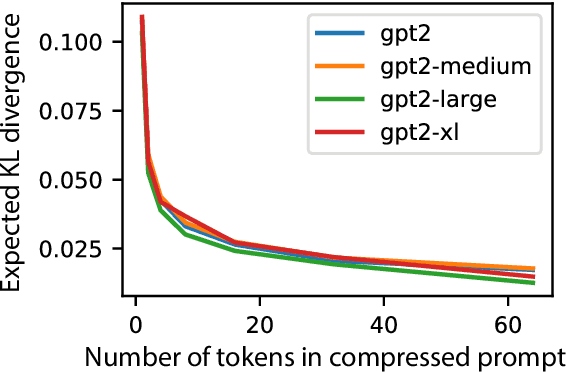
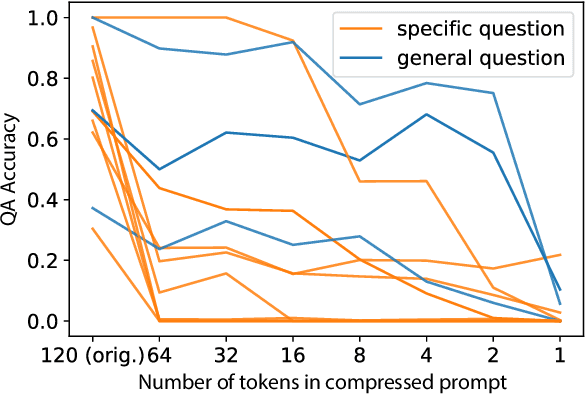
We explore the idea of compressing the prompts used to condition language models, and show that compressed prompts can retain a substantive amount of information about the original prompt. For severely compressed prompts, while fine-grained information is lost, abstract information and general sentiments can be retained with surprisingly few parameters, which can be useful in the context of decode-time algorithms for controllability and toxicity reduction. We explore contrastive conditioning to steer language model generation towards desirable text and away from undesirable text, and find that some complex prompts can be effectively compressed into a single token to guide generation. We also show that compressed prompts are largely compositional, and can be constructed such that they can be used to control independent aspects of generated text.