 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DPANET:Dual Pooling Attention Network for Semantic Segmentation
Oct 11, 2022
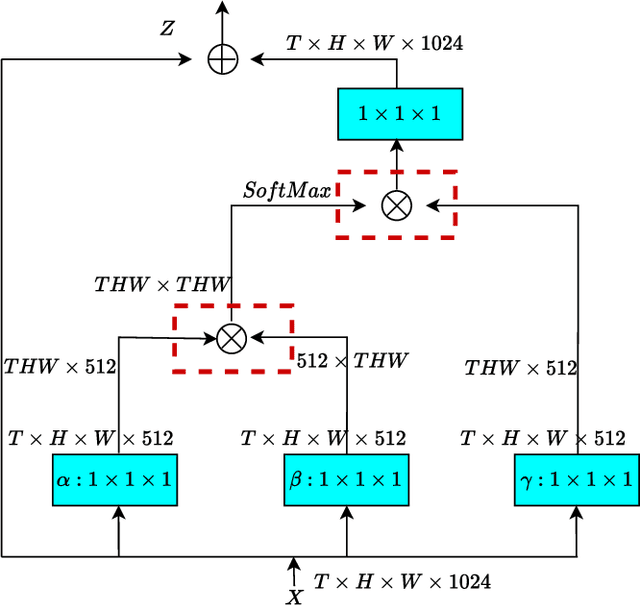
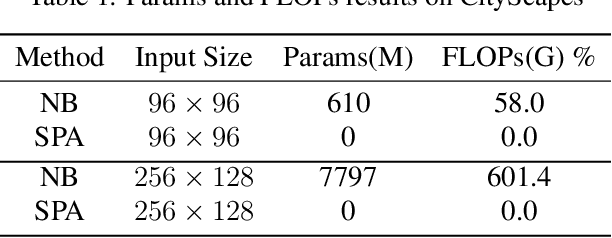
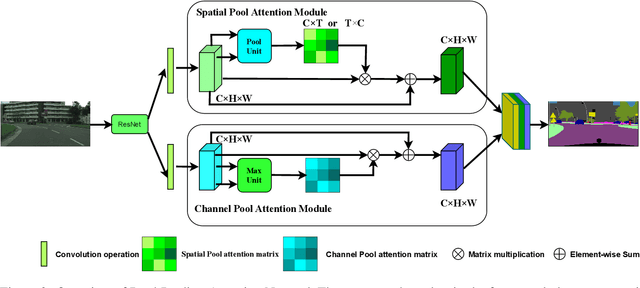

Image segmentation is a historic and significant computer vision task. With the help of deep learning techniques, image semantic segmentation has made great progresses. Over recent years, based on guidance of attention mechanism compared with CNN which overcomes the problems of lacking of interaction between different channels, and effective capturing and aggregating contextual information. However, the massive operations generated by the attention mechanism lead to its extremely high complexity and high demand for GPU memory. For this purpose, we propose a lightweight and flexible neural network named Dual Pool Attention Network(DPANet). The most important is that all modules in DPANet generate \textbf{0} parameters. The first component is spatial pool attention module, we formulate an easy and powerful method densely to extract contextual characteristics and reduce the amount of calculation and complexity dramatically.Meanwhile, it demonstrates the power of even and large kernel size. The second component is channel pool attention module. It is known that the computation process of CNN incorporates the information of spatial and channel dimensions. So, the aim of this module is stripping them out, in order to construct relationship of all channels and heighten different channels semantic information selectively. Moreover, we experiments on segmentation datasets, which shows our method simple and effective with low parameters and calculation complexity.
Prototype as Query for Few Shot Semantic Segmentation
Nov 27, 2022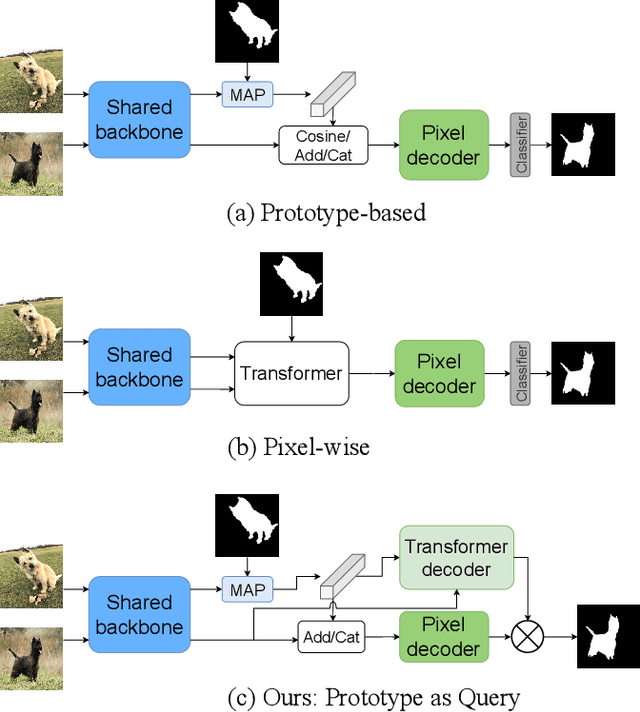
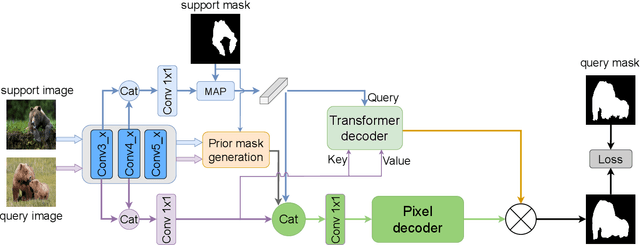
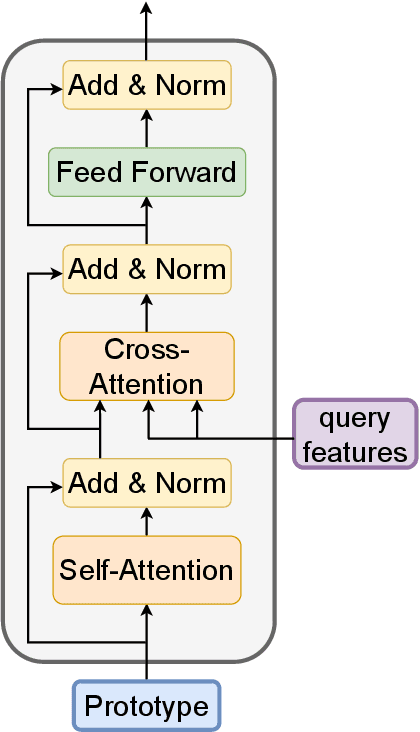

Few-shot Semantic Segmentation (FSS) was proposed to segment unseen classes in a query image, referring to only a few annotated examples named support images. One of the characteristics of FSS is spatial inconsistency between query and support targets, e.g., texture or appearance. This greatly challenges the generalization ability of methods for FSS, which requires to effectively exploit the dependency of the query image and the support examples. Most existing methods abstracted support features into prototype vectors and implemented the interaction with query features using cosine similarity or feature concatenation. However, this simple interaction may not capture spatial details in query features. To alleviate this limitation, a few methods utilized all pixel-wise support information via computing the pixel-wise correlations between paired query and support features implemented with the attention mechanism of Transformer. These approaches suffer from heavy computation on the dot-product attention between all pixels of support and query features. In this paper, we propose a simple yet effective framework built upon Transformer termed as ProtoFormer to fully capture spatial details in query features. It views the abstracted prototype of the target class in support features as Query and the query features as Key and Value embeddings, which are input to the Transformer decoder. In this way, the spatial details can be better captured and the semantic features of target class in the query image can be focused. The output of the Transformer-based module can be viewed as semantic-aware dynamic kernels to filter out the segmentation mask from the enriched query features. Extensive experiments on PASCAL-$5^{i}$ and COCO-$20^{i}$ show that our ProtoFormer significantly advances the state-of-the-art methods.
A Sequence Agnostic Multimodal Preprocessing for Clogged Blood Vessel Detection in Alzheimer's Diagnosis
Nov 06, 2022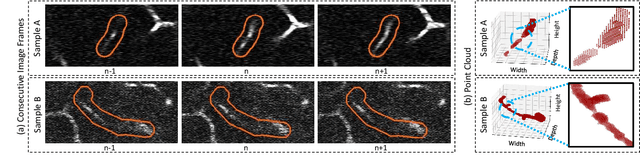
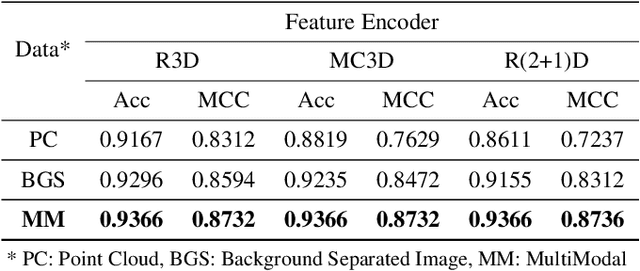

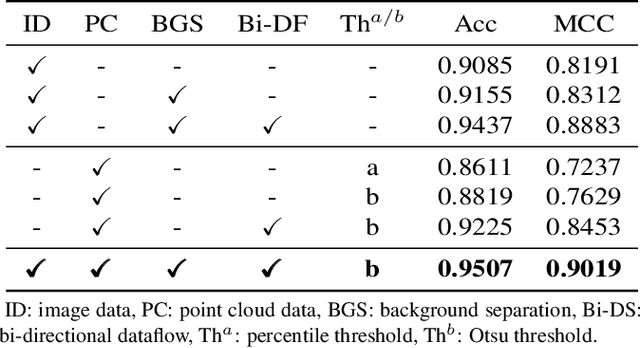
Successful identification of blood vessel blockage is a crucial step for Alzheimer's disease diagnosis. These blocks can be identified from the spatial and time-depth variable Two-Photon Excitation Microscopy (TPEF) images of the brain blood vessels using machine learning methods. In this study, we propose several preprocessing schemes to improve the performance of these methods. Our method includes 3D-point cloud data extraction from image modality and their feature-space fusion to leverage complementary information inherent in different modalities. We also enforce the learned representation to be sequence-order invariant by utilizing bi-direction dataflow. Experimental results on The Clog Loss dataset show that our proposed method consistently outperforms the state-of-the-art preprocessing methods in stalled and non-stalled vessel classification.
Noisy Channel for Automatic Text Simplification
Nov 06, 2022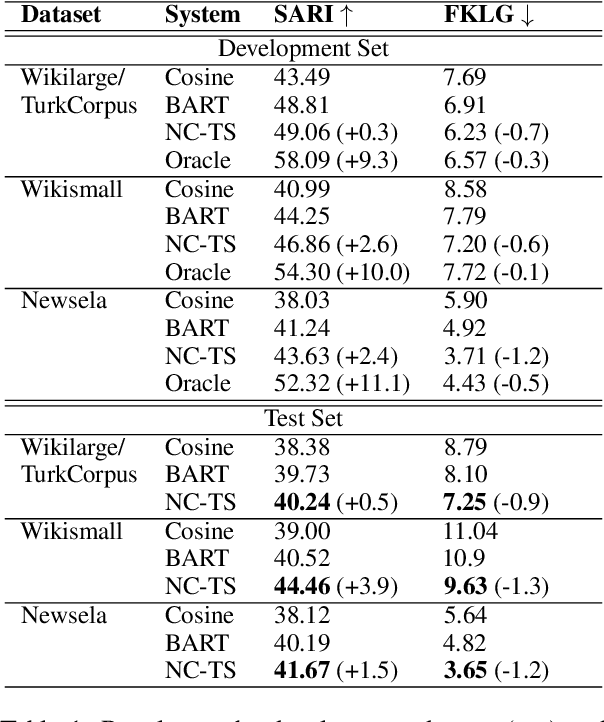

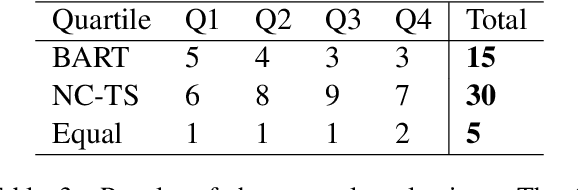
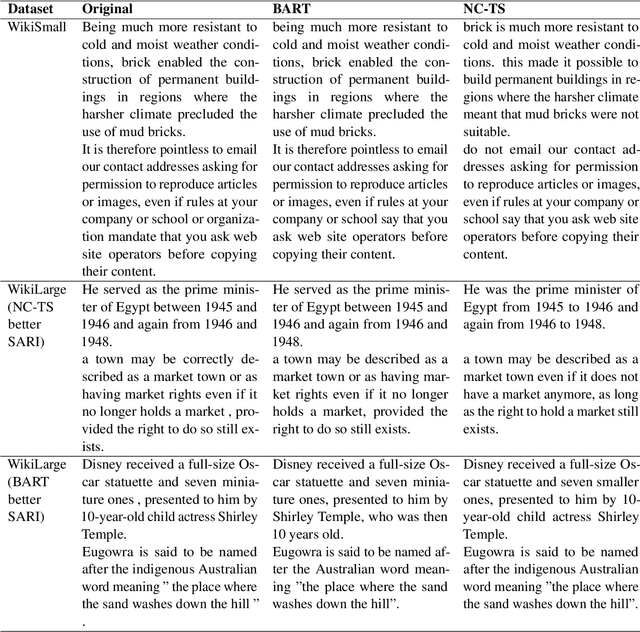
In this paper we present a simple re-ranking method for Automatic Sentence Simplification based on the noisy channel scheme. Instead of directly computing the best simplification given a complex text, the re-ranking method also considers the probability of the simple sentence to produce the complex counterpart, as well as the probability of the simple text itself, according to a language model. Our experiments show that combining these scores outperform the original system in three different English datasets, yielding the best known result in one of them. Adopting the noisy channel scheme opens new ways to infuse additional information into ATS systems, and thus to control important aspects of them, a known limitation of end-to-end neural seq2seq generative models.
Multistep feature aggregation framework for salient object detection
Nov 12, 2022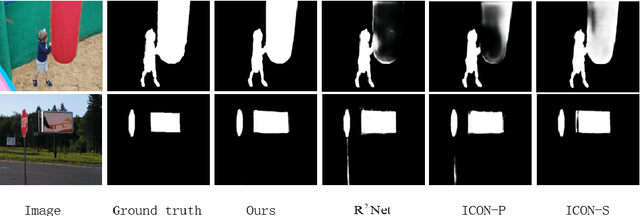



Recent works on salient object detection have made use of multi-scale features in a way such that high-level features and low-level features can collaborate in locating salient objects. Many of the previous methods have achieved great performance in salient object detection. By merging the high-level and low-level features, a large number of feature information can be extracted. Generally, they are doing these in a one-way framework, and interweaving the variable features all the way to the final feature output. Which may cause some blurring or inaccurate localization of saliency maps. To overcome these difficulties, we introduce a multistep feature aggregation (MSFA) framework for salient object detection, which is composed of three modules, including the Diverse Reception (DR) module, multiscale interaction (MSI) module and Feature Enhancement (FE) module to accomplish better multi-level feature fusion. Experimental results on six benchmark datasets demonstrate that MSFA achieves state-of-the-art performance.
Formalizing the presumption of independence
Nov 12, 2022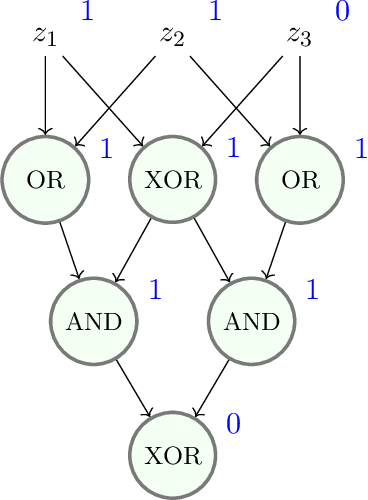
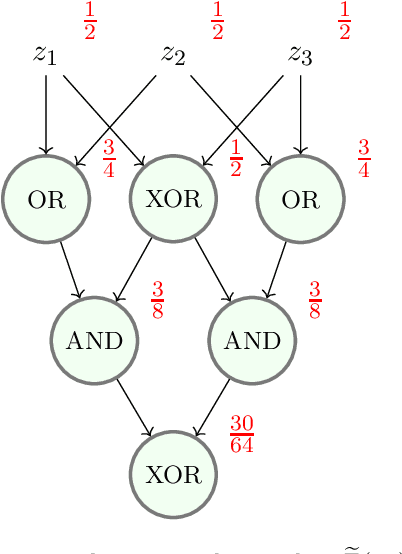
Mathematical proof aims to deliver confident conclusions, but a very similar process of deduction can be used to make uncertain estimates that are open to revision. A key ingredient in such reasoning is the use of a "default" estimate of $\mathbb{E}[XY] = \mathbb{E}[X] \mathbb{E}[Y]$ in the absence of any specific information about the correlation between $X$ and $Y$, which we call *the presumption of independence*. Reasoning based on this heuristic is commonplace, intuitively compelling, and often quite successful -- but completely informal. In this paper we introduce the concept of a heuristic estimator as a potential formalization of this type of defeasible reasoning. We introduce a set of intuitively desirable coherence properties for heuristic estimators that are not satisfied by any existing candidates. Then we present our main open problem: is there a heuristic estimator that formalizes intuitively valid applications of the presumption of independence without also accepting spurious arguments?
A unified one-shot prosody and speaker conversion system with self-supervised discrete speech units
Nov 12, 2022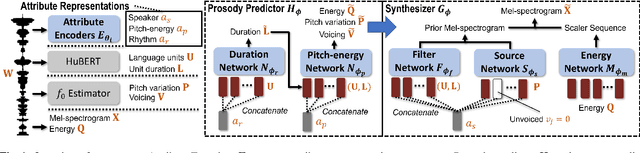
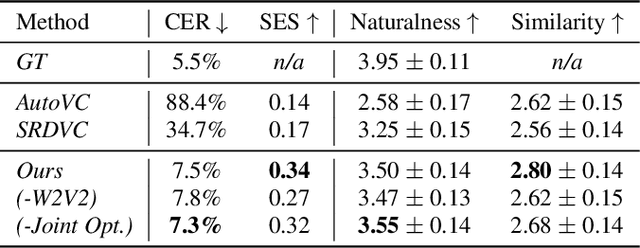
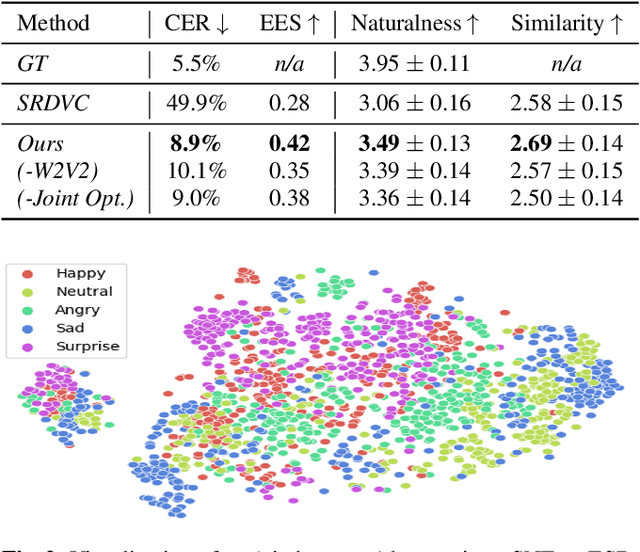
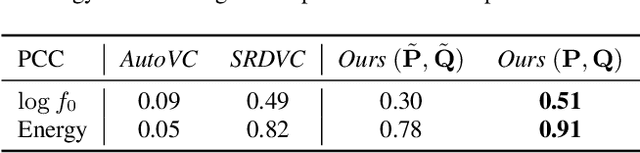
We present a unified system to realize one-shot voice conversion (VC) on the pitch, rhythm, and speaker attributes. Existing works generally ignore the correlation between prosody and language content, leading to the degradation of naturalness in converted speech. Additionally, the lack of proper language features prevents these systems from accurately preserving language content after conversion. To address these issues, we devise a cascaded modular system leveraging self-supervised discrete speech units as language representation. These discrete units provide duration information essential for rhythm modeling. Our system first extracts utterance-level prosody and speaker representations from the raw waveform. Given the prosody representation, a prosody predictor estimates pitch, energy, and duration for each discrete unit in the utterance. A synthesizer further reconstructs speech based on the predicted prosody, speaker representation, and discrete units. Experiments show that our system outperforms previous approaches in naturalness, intelligibility, speaker transferability, and prosody transferability. Code and samples are publicly available.
ImLiDAR: Cross-Sensor Dynamic Message Propagation Network for 3D Object Detection
Nov 17, 2022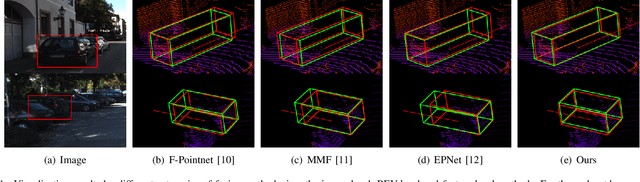
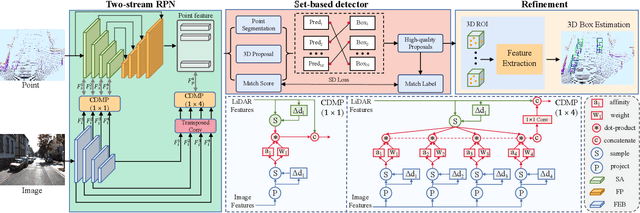
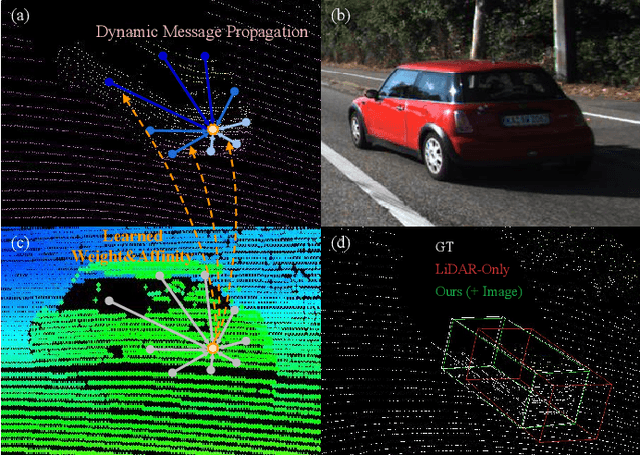
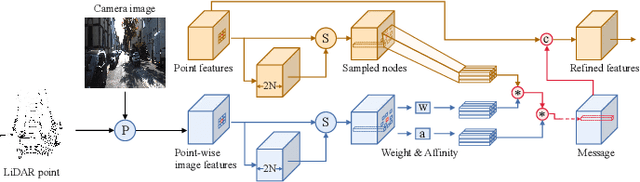
LiDAR and camera, as two different sensors, supply geometric (point clouds) and semantic (RGB images) information of 3D scenes. However, it is still challenging for existing methods to fuse data from the two cross sensors, making them complementary for quality 3D object detection (3OD). We propose ImLiDAR, a new 3OD paradigm to narrow the cross-sensor discrepancies by progressively fusing the multi-scale features of camera Images and LiDAR point clouds. ImLiDAR enables to provide the detection head with cross-sensor yet robustly fused features. To achieve this, two core designs exist in ImLiDAR. First, we propose a cross-sensor dynamic message propagation module to combine the best of the multi-scale image and point features. Second, we raise a direct set prediction problem that allows designing an effective set-based detector to tackle the inconsistency of the classification and localization confidences, and the sensitivity of hand-tuned hyperparameters. Besides, the novel set-based detector can be detachable and easily integrated into various detection networks. Comparisons on both the KITTI and SUN-RGBD datasets show clear visual and numerical improvements of our ImLiDAR over twenty-three state-of-the-art 3OD methods.
Active Learning with Expected Error Reduction
Nov 17, 2022
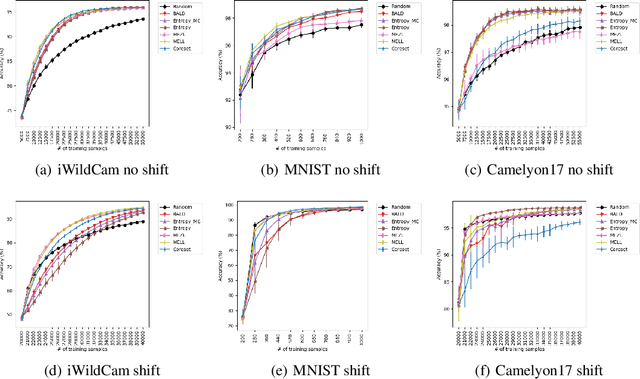
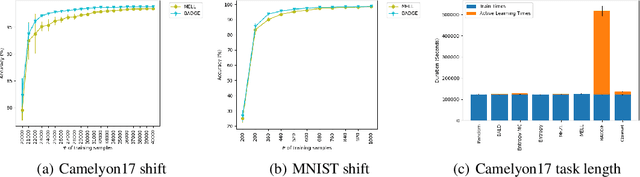

Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) (Roy and McCallum) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as arXiv:1506.02142). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (arXiv:2012.07421). The results indicate that our method outperforms all other methods except one in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (arXiv:1906.03671).
Multimodal Remote Sensing Image Registration Based on Adaptive Multi-scale PIIFD
Nov 09, 2022

In recent years, due to the wide application of multi-sensor vision systems, multimodal image acquisition technology has continued to develop, and the registration problem based on multimodal images has gradually emerged. Most of the existing multimodal image registration methods are only suitable for two modalities, and cannot uniformly register multiple modal image data. Therefore, this paper proposes a multimodal remote sensing image registration method based on adaptive multi-scale PIIFD(AM-PIIFD). This method extracts KAZE features, which can effectively retain edge feature information while filtering noise. Then adaptive multi-scale PIIFD is calculated for matching. Finally, the mismatch is removed through the consistency of the feature main direction, and the image alignment transformation is realized. The qualitative and quantitative comparisons with other three advanced methods shows that our method can achieve excellent performance in multimodal remote sensing image registration.