 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Auto-Focus Contrastive Learning for Image Manipulation Detection
Nov 20, 2022
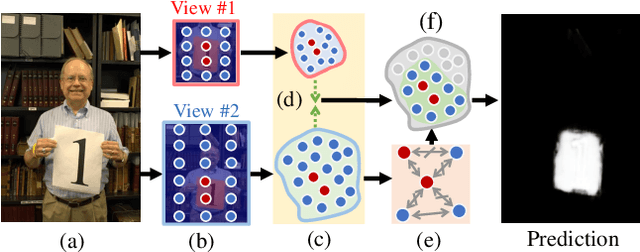
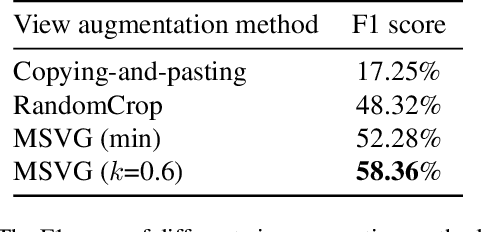


Generally, current image manipulation detection models are simply built on manipulation traces. However, we argue that those models achieve sub-optimal detection performance as it tends to: 1) distinguish the manipulation traces from a lot of noisy information within the entire image, and 2) ignore the trace relations among the pixels of each manipulated region and its surroundings. To overcome these limitations, we propose an Auto-Focus Contrastive Learning (AF-CL) network for image manipulation detection. It contains two main ideas, i.e., multi-scale view generation (MSVG) and trace relation modeling (TRM). Specifically, MSVG aims to generate a pair of views, each of which contains the manipulated region and its surroundings at a different scale, while TRM plays a role in modeling the trace relations among the pixels of each manipulated region and its surroundings for learning the discriminative representation. After learning the AF-CL network by minimizing the distance between the representations of corresponding views, the learned network is able to automatically focus on the manipulated region and its surroundings and sufficiently explore their trace relations for accurate manipulation detection. Extensive experiments demonstrate that, compared to the state-of-the-arts, AF-CL provides significant performance improvements, i.e., up to 2.5%, 7.5%, and 0.8% F1 score, on CAISA, NIST, and Coverage datasets, respectively.
Traceable and Authenticable Image Tagging for Fake News Detection
Nov 20, 2022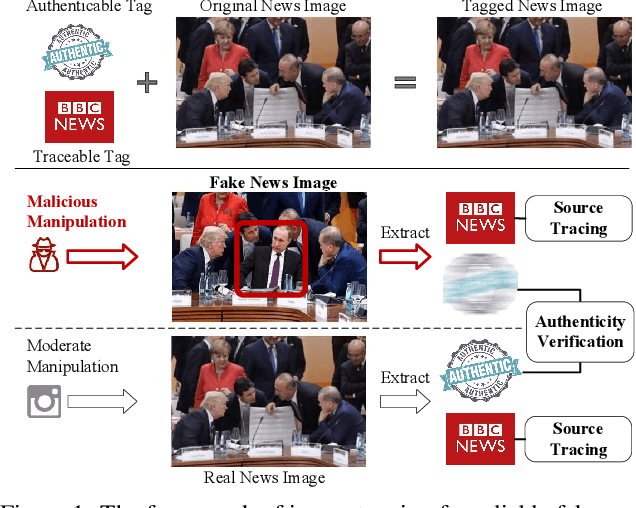

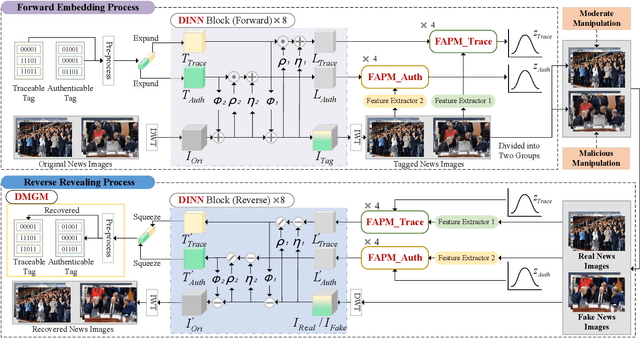
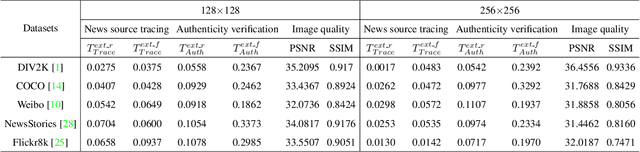
To prevent fake news images from misleading the public, it is desirable not only to verify the authenticity of news images but also to trace the source of fake news, so as to provide a complete forensic chain for reliable fake news detection. To simultaneously achieve the goals of authenticity verification and source tracing, we propose a traceable and authenticable image tagging approach that is based on a design of Decoupled Invertible Neural Network (DINN). The designed DINN can simultaneously embed the dual-tags, \textit{i.e.}, authenticable tag and traceable tag, into each news image before publishing, and then separately extract them for authenticity verification and source tracing. Moreover, to improve the accuracy of dual-tags extraction, we design a parallel Feature Aware Projection Model (FAPM) to help the DINN preserve essential tag information. In addition, we define a Distance Metric-Guided Module (DMGM) that learns asymmetric one-class representations to enable the dual-tags to achieve different robustness performances under malicious manipulations. Extensive experiments, on diverse datasets and unseen manipulations, demonstrate that the proposed tagging approach achieves excellent performance in the aspects of both authenticity verification and source tracing for reliable fake news detection and outperforms the prior works.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022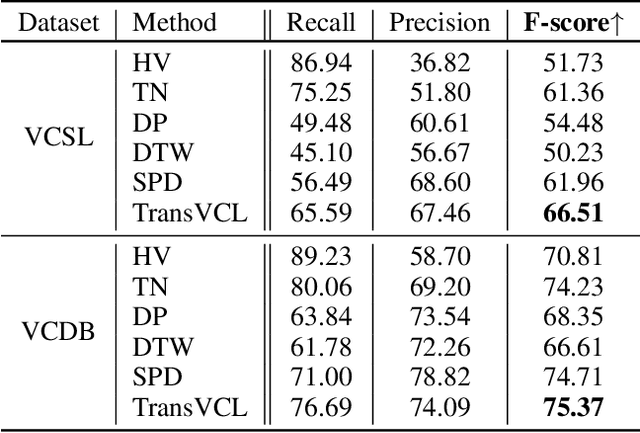
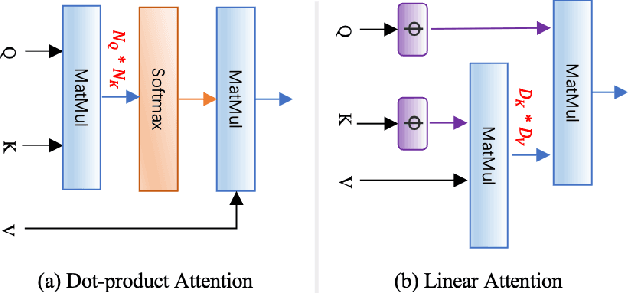

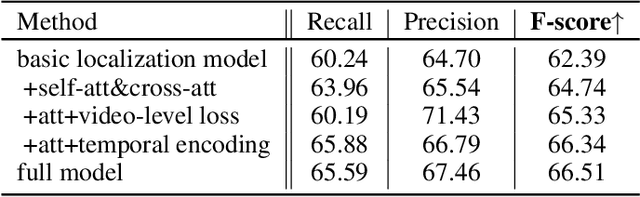
Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
CasFusionNet: A Cascaded Network for Point Cloud Semantic Scene Completion by Dense Feature Fusion
Nov 24, 2022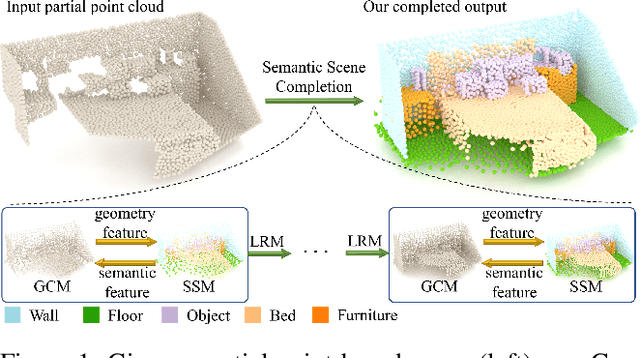
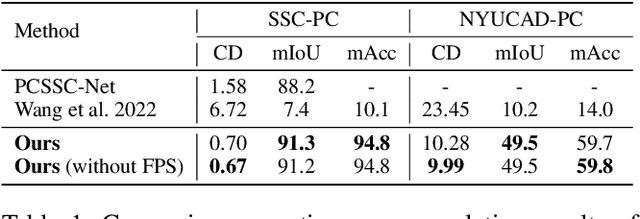
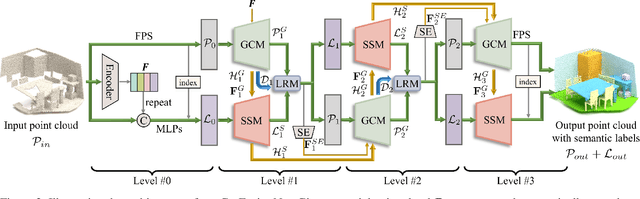
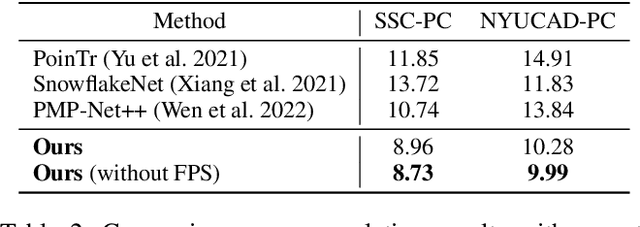
Semantic scene completion (SSC) aims to complete a partial 3D scene and predict its semantics simultaneously. Most existing works adopt the voxel representations, thus suffering from the growth of memory and computation cost as the voxel resolution increases. Though a few works attempt to solve SSC from the perspective of 3D point clouds, they have not fully exploited the correlation and complementarity between the two tasks of scene completion and semantic segmentation. In our work, we present CasFusionNet, a novel cascaded network for point cloud semantic scene completion by dense feature fusion. Specifically, we design (i) a global completion module (GCM) to produce an upsampled and completed but coarse point set, (ii) a semantic segmentation module (SSM) to predict the per-point semantic labels of the completed points generated by GCM, and (iii) a local refinement module (LRM) to further refine the coarse completed points and the associated labels from a local perspective. We organize the above three modules via dense feature fusion in each level, and cascade a total of four levels, where we also employ feature fusion between each level for sufficient information usage. Both quantitative and qualitative results on our compiled two point-based datasets validate the effectiveness and superiority of our CasFusionNet compared to state-of-the-art methods in terms of both scene completion and semantic segmentation. The codes and datasets are available at: https://github.com/JinfengX/CasFusionNet.
STAGE: Span Tagging and Greedy Inference Scheme for Aspect Sentiment Triplet Extraction
Nov 29, 2022
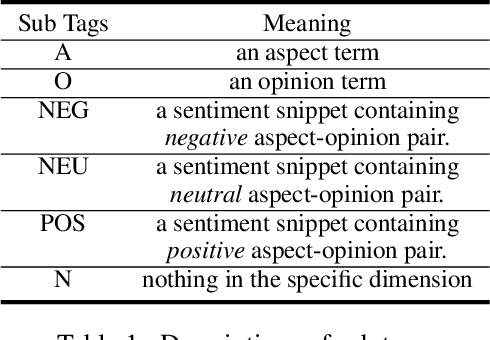
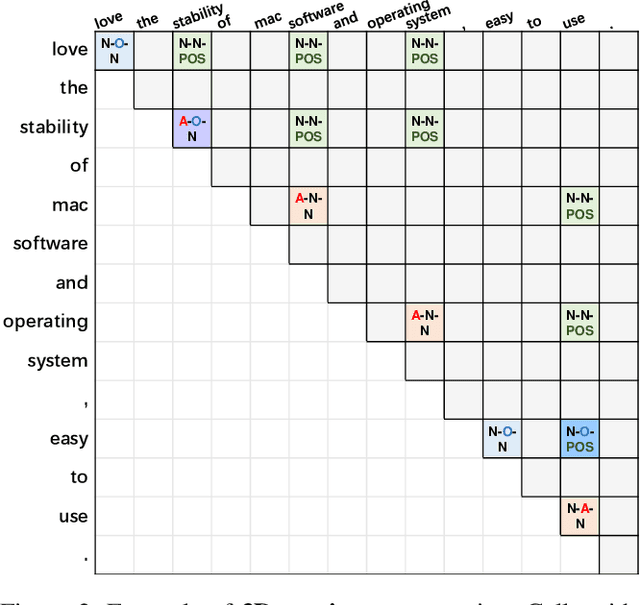
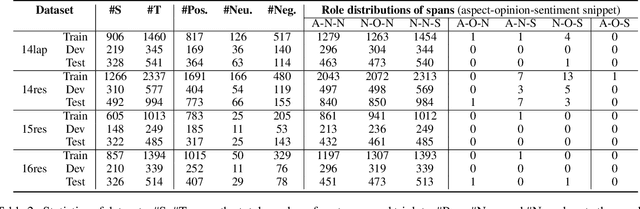
Aspect Sentiment Triplet Extraction (ASTE) has become an emerging task in sentiment analysis research, aiming to extract triplets of the aspect term, its corresponding opinion term, and its associated sentiment polarity from a given sentence. Recently, many neural networks based models with different tagging schemes have been proposed, but almost all of them have their limitations: heavily relying on 1) prior assumption that each word is only associated with a single role (e.g., aspect term, or opinion term, etc. ) and 2) word-level interactions and treating each opinion/aspect as a set of independent words. Hence, they perform poorly on the complex ASTE task, such as a word associated with multiple roles or an aspect/opinion term with multiple words. Hence, we propose a novel approach, Span TAgging and Greedy infErence (STAGE), to extract sentiment triplets in span-level, where each span may consist of multiple words and play different roles simultaneously. To this end, this paper formulates the ASTE task as a multi-class span classification problem. Specifically, STAGE generates more accurate aspect sentiment triplet extractions via exploring span-level information and constraints, which consists of two components, namely, span tagging scheme and greedy inference strategy. The former tag all possible candidate spans based on a newly-defined tagging set. The latter retrieves the aspect/opinion term with the maximum length from the candidate sentiment snippet to output sentiment triplets. Furthermore, we propose a simple but effective model based on the STAGE, which outperforms the state-of-the-arts by a large margin on four widely-used datasets. Moreover, our STAGE can be easily generalized to other pair/triplet extraction tasks, which also demonstrates the superiority of the proposed scheme STAGE.
Time and Cost-Efficient Bathymetric Mapping System using Sparse Point Cloud Generation and Automatic Object Detection
Oct 19, 2022
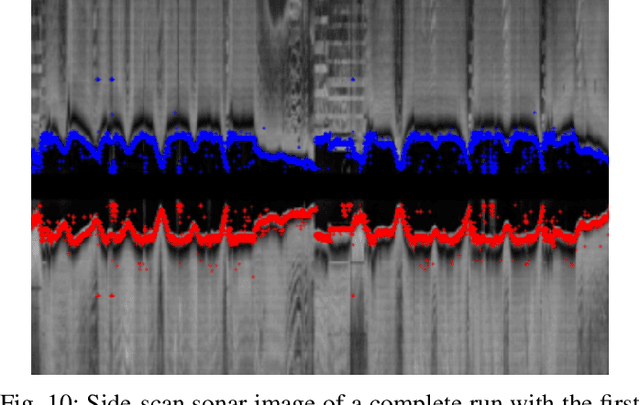
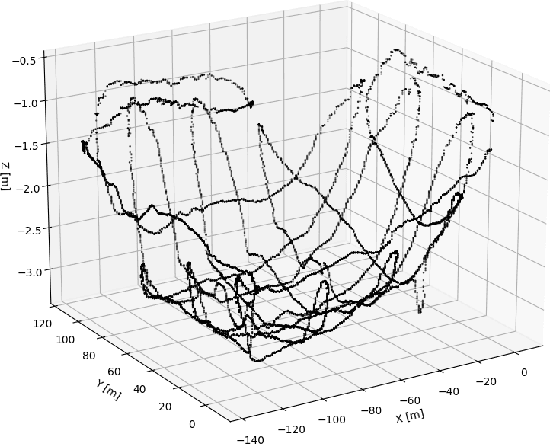
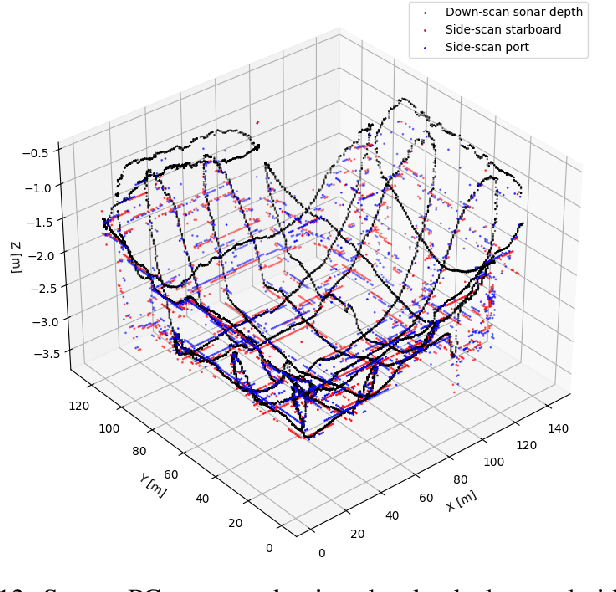
Generating 3D point cloud (PC) data from noisy sonar measurements is a problem that has potential applications for bathymetry mapping, artificial object inspection, mapping of aquatic plants and fauna as well as underwater navigation and localization of vehicles such as submarines. Side-scan sonar sensors are available in inexpensive cost ranges, especially in fish-finders, where the transducers are usually mounted to the bottom of a boat and can approach shallower depths than the ones attached to an Uncrewed Underwater Vehicle (UUV) can. However, extracting 3D information from side-scan sonar imagery is a difficult task because of its low signal-to-noise ratio and missing angle and depth information in the imagery. Since most algorithms that generate a 3D point cloud from side-scan sonar imagery use Shape from Shading (SFS) techniques, extracting 3D information is especially difficult when the seafloor is smooth, is slowly changing in depth, or does not have identifiable objects that make acoustic shadows. This paper introduces an efficient algorithm that generates a sparse 3D point cloud from side-scan sonar images. This computation is done in a computationally efficient manner by leveraging the geometry of the first sonar return combined with known positions provided by GPS and down-scan sonar depth measurement at each data point. Additionally, this paper implements another algorithm that uses a Convolutional Neural Network (CNN) using transfer learning to perform object detection on side-scan sonar images collected in real life and generated with a simulation. The algorithm was tested on both real and synthetic images to show reasonably accurate anomaly detection and classification.
Minimizing the Accumulated Trajectory Error to Improve Dataset Distillation
Nov 22, 2022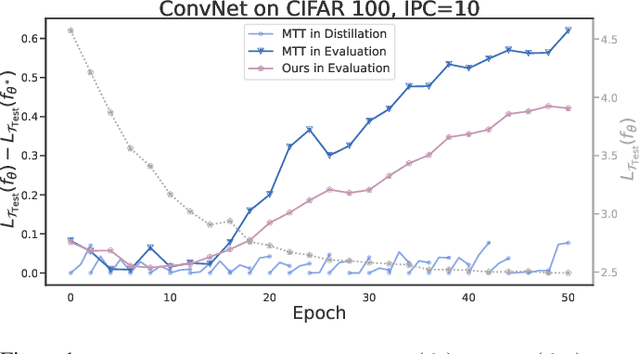
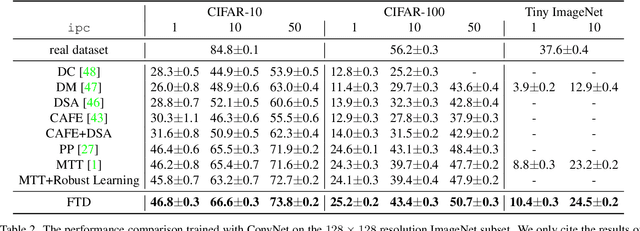
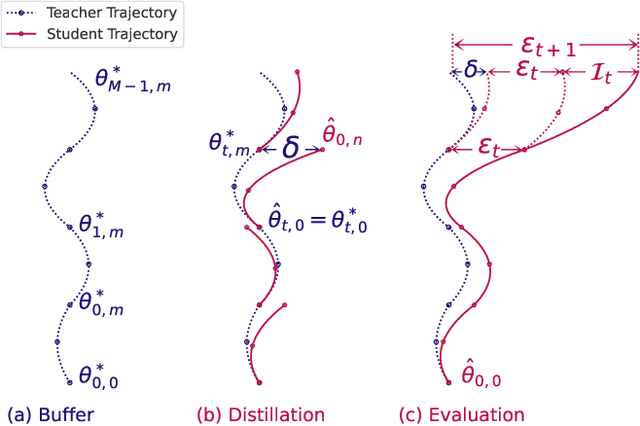

Model-based deep learning has achieved astounding successes due in part to the availability of large-scale realworld data. However, processing such massive amounts of data comes at a considerable cost in terms of computations, storage, training and the search for good neural architectures. Dataset distillation has thus recently come to the fore. This paradigm involves distilling information from large real-world datasets into tiny and compact synthetic datasets such that processing the latter yields similar performances as the former. State-of-the-art methods primarily rely on learning the synthetic dataset by matching the gradients obtained during training between the real and synthetic data. However, these gradient-matching methods suffer from the accumulated trajectory error caused by the discrepancy between the distillation and subsequent evaluation. To alleviate the adverse impact of this accumulated trajectory error, we propose a novel approach that encourages the optimization algorithm to seek a flat trajectory. We show that the weights trained on synthetic data are robust against the accumulated errors perturbations with the regularization towards the flat trajectory. Our method, called Flat Trajectory Distillation (FTD), is shown to boost the performance of gradient-matching methods by up to 4.7% on a subset of images of the ImageNet dataset with higher resolution images. We also validate the effectiveness and generalizability of our method with datasets of different resolutions and demonstrate its applicability to neural architecture search.
A Review of Intelligent Music Generation Systems
Nov 22, 2022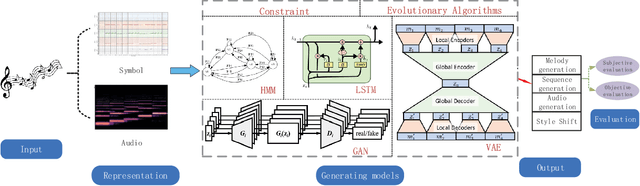

Intelligent music generation, one of the most popular subfields of computer creativity, can lower the creative threshold for non-specialists and increase the efficiency of music creation. In the last five years, the quality of algorithm-based automatic music generation has increased significantly, motivated by the use of modern generative algorithms to learn the patterns implicit within a piece of music based on rule constraints or a musical corpus, thus generating music samples in various styles. Some of the available literature reviews lack a systematic benchmark of generative models and are traditional and conservative in their perspective, resulting in a vision of the future development of the field that is not deeply integrated with the current rapid scientific progress. In this paper, we conduct a comprehensive survey and analysis of recent intelligent music generation techniques,provide a critical discussion, explicitly identify their respective characteristics, and present them in a general table. We first introduce how music as a stream of information is encoded and the relevant datasets, then compare different types of generation algorithms, summarize their strengths and weaknesses, and discuss existing methods for evaluation. Finally, the development of artificial intelligence in composition is studied, especially by comparing the different characteristics of music generation techniques in the East and West and analyzing the development prospects in this field.
Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring
Nov 22, 2022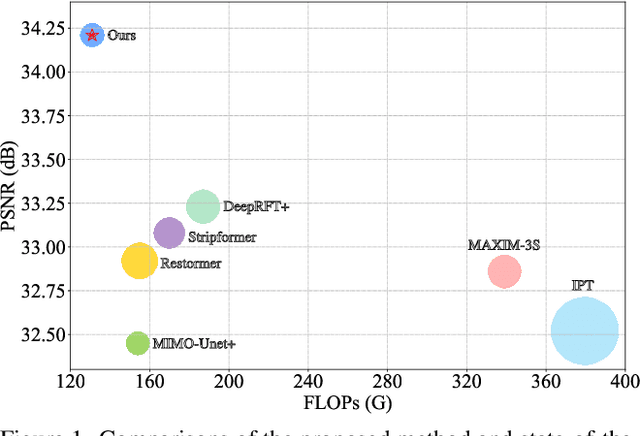
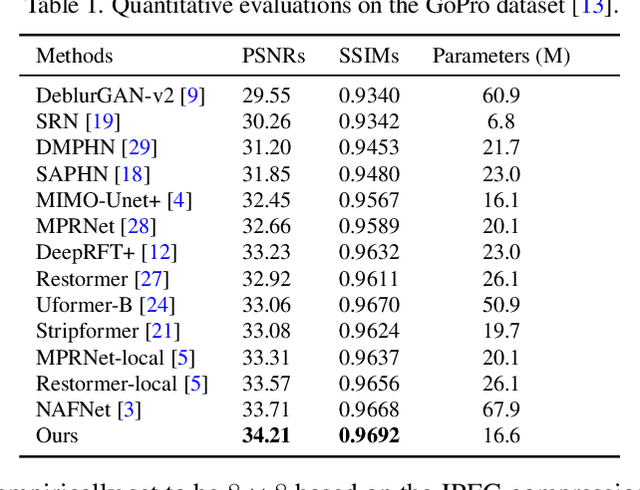
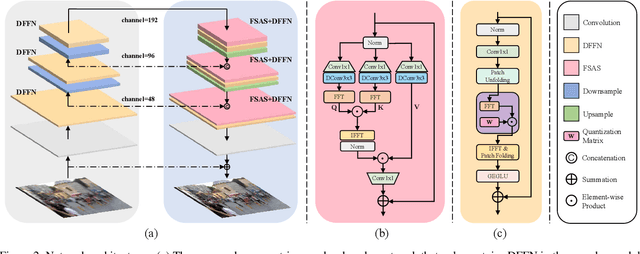
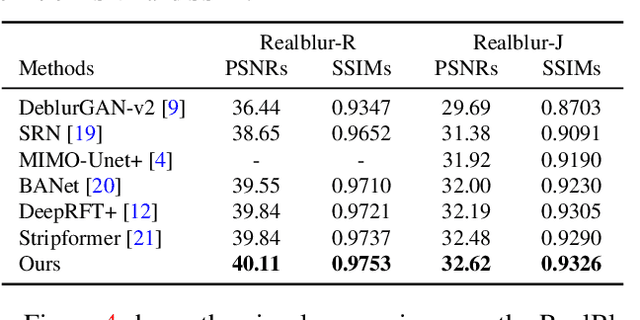
We present an effective and efficient method that explores the properties of Transformers in the frequency domain for high-quality image deblurring. Our method is motivated by the convolution theorem that the correlation or convolution of two signals in the spatial domain is equivalent to an element-wise product of them in the frequency domain. This inspires us to develop an efficient frequency domain-based self-attention solver (FSAS) to estimate the scaled dot-product attention by an element-wise product operation instead of the matrix multiplication in the spatial domain. In addition, we note that simply using the naive feed-forward network (FFN) in Transformers does not generate good deblurred results. To overcome this problem, we propose a simple yet effective discriminative frequency domain-based FFN (DFFN), where we introduce a gated mechanism in the FFN based on the Joint Photographic Experts Group (JPEG) compression algorithm to discriminatively determine which low- and high-frequency information of the features should be preserved for latent clear image restoration. We formulate the proposed FSAS and DFFN into an asymmetrical network based on an encoder and decoder architecture, where the FSAS is only used in the decoder module for better image deblurring. Experimental results show that the proposed method performs favorably against the state-of-the-art approaches. Code will be available at \url{https://github.com/kkkls/FFTformer}.
Iterative autoregression: a novel trick to improve your low-latency speech enhancement model
Nov 03, 2022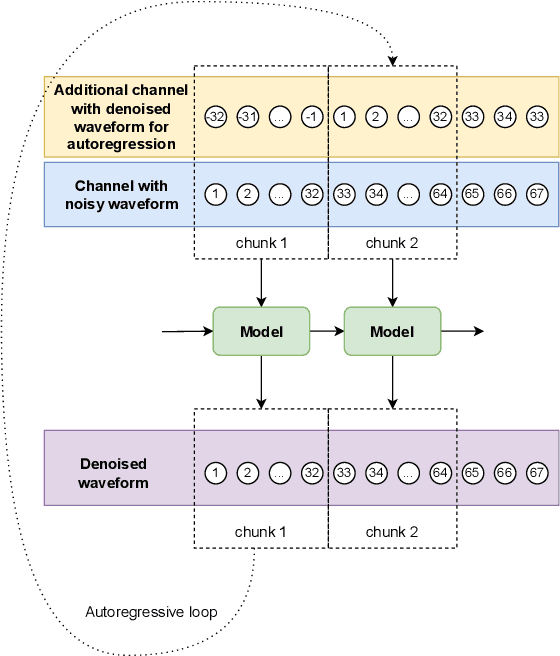
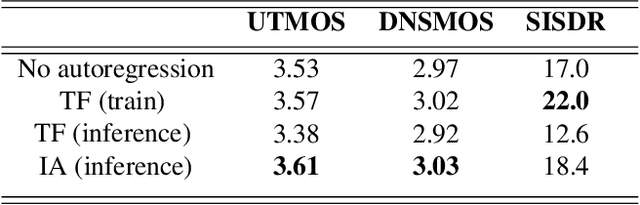
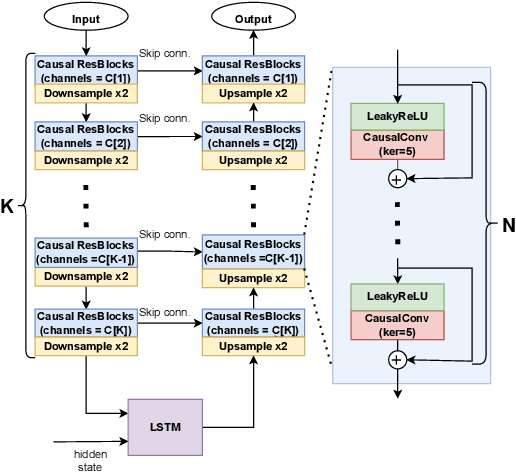
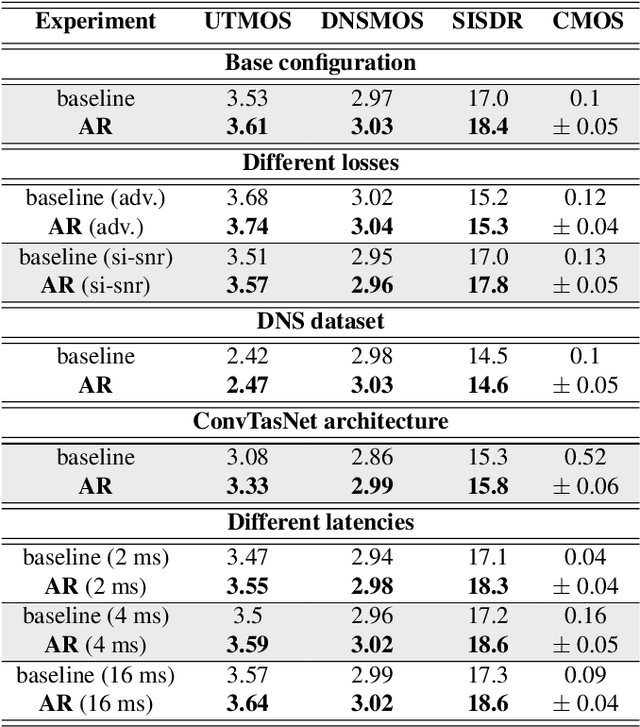
Streaming models are an essential component of real-time speech enhancement tools. The streaming regime constrains speech enhancement models to use only a tiny context of future information, thus, the low-latency streaming setup is generally assumed to be challenging and has a significant negative effect on the model quality. However, due to the sequential nature of streaming generation, it provides a natural possibility for autoregression, i.e., using previous predictions when making current ones. In this paper, we present a simple, yet effective trick for training of autoregressive low-latency speech enhancement models. We demonstrate that the proposed technique leads to stable improvement across different architectures and training scenarios.