 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022


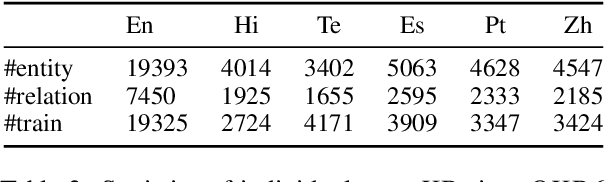
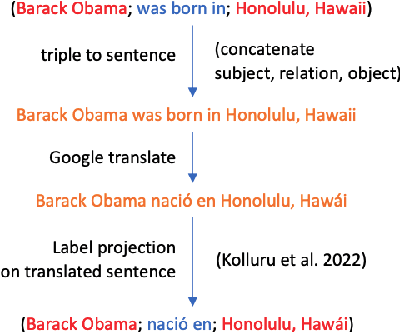
Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
Digital Twin-Assisted Collaborative Transcoding for Better User Satisfaction in Live Streaming
Nov 13, 2022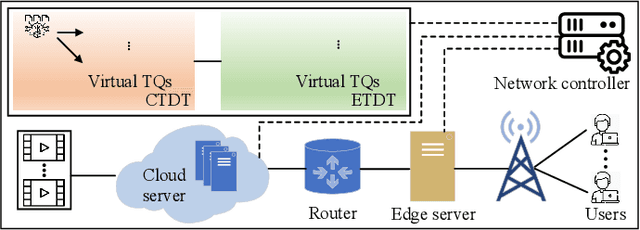
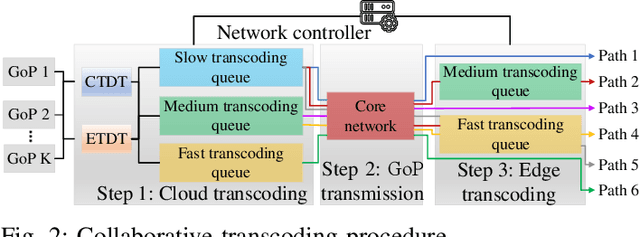
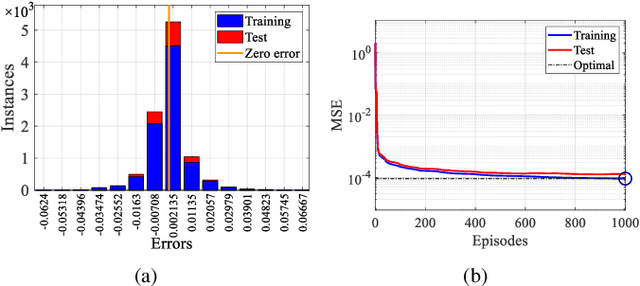
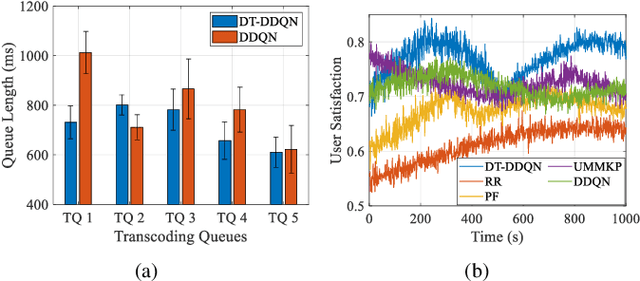
In this paper, we propose a digital twin (DT)-assisted cloud-edge collaborative transcoding scheme to enhance user satisfaction in live streaming. We first present a DT-assisted transcoding workload estimation (TWE) model for the cloud-edge collaborative transcoding. Particularly, two DTs are constructed for emulating the cloud-edge collaborative transcoding process by analyzing spatial-temporal information of individual videos and transcoding configurations of transcoding queues, respectively. Two light-weight Bayesian neural networks are adopted to fit the TWE models in DTs, respectively. We then formulate a transcoding-path selection problem to maximize long-term user satisfaction within an average service delay threshold, taking into account the dynamics of video arrivals and video requests. The problem is transformed into a standard Markov decision process by using the Lyapunov optimization and solved by a deep reinforcement learning algorithm. Simulation results based on the real-world dataset demonstrate that the proposed scheme can effectively enhance user satisfaction compared with benchmark schemes.
A Scalable Graph Neural Network Decoder for Short Block Codes
Nov 13, 2022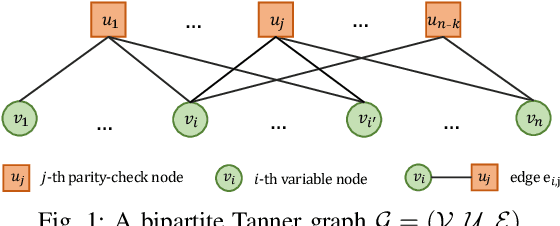
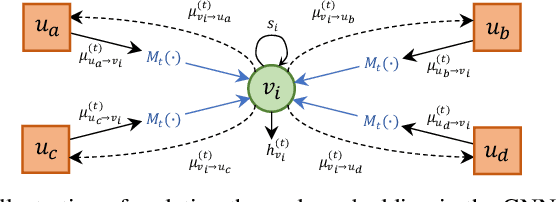
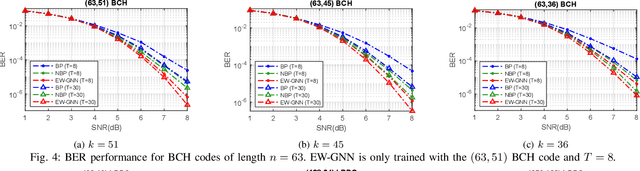
In this work, we propose a novel decoding algorithm for short block codes based on an edge-weighted graph neural network (EW-GNN). The EW-GNN decoder operates on the Tanner graph with an iterative message-passing structure, which algorithmically aligns with the conventional belief propagation (BP) decoding method. In each iteration, the "weight" on the message passed along each edge is obtained from a fully connected neural network that has the reliability information from nodes/edges as its input. Compared to existing deep-learning-based decoding schemes, the EW-GNN decoder is characterised by its scalability, meaning that 1) the number of trainable parameters is independent of the codeword length, and 2) an EW-GNN decoder trained with shorter/simple codes can be directly used for longer/sophisticated codes of different code rates. Furthermore, simulation results show that the EW-GNN decoder outperforms the BP and deep-learning-based BP methods from the literature in terms of the decoding error rate.
DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation
Nov 18, 2022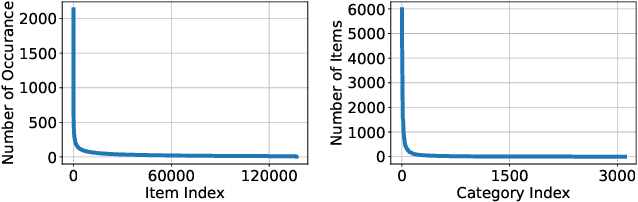
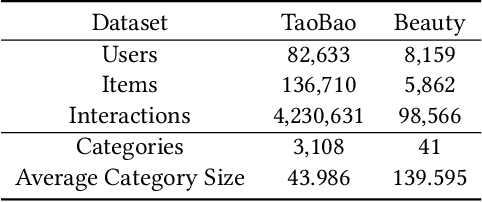

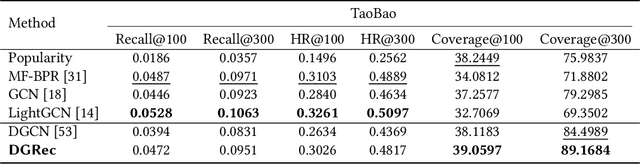
Graph Neural Network (GNN) based recommender systems have been attracting more and more attention in recent years due to their excellent performance in accuracy. Representing user-item interactions as a bipartite graph, a GNN model generates user and item representations by aggregating embeddings of their neighbors. However, such an aggregation procedure often accumulates information purely based on the graph structure, overlooking the redundancy of the aggregated neighbors and resulting in poor diversity of the recommended list. In this paper, we propose diversifying GNN-based recommender systems by directly improving the embedding generation procedure. Particularly, we utilize the following three modules: submodular neighbor selection to find a subset of diverse neighbors to aggregate for each GNN node, layer attention to assign attention weights for each layer, and loss reweighting to focus on the learning of items belonging to long-tail categories. Blending the three modules into GNN, we present DGRec(Diversified GNN-based Recommender System) for diversified recommendation. Experiments on real-world datasets demonstrate that the proposed method can achieve the best diversity while keeping the accuracy comparable to state-of-the-art GNN-based recommender systems.
EMOFAKE: An Initial Dataset For Emotion Fake Audio Detection
Nov 10, 2022
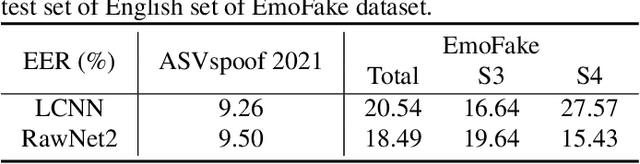
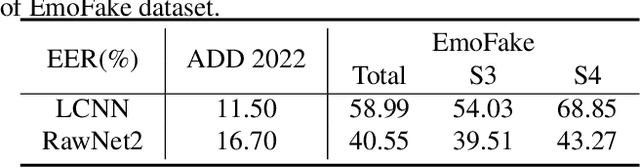
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.
Learning the shape of protein micro-environments with a holographic convolutional neural network
Nov 05, 2022Proteins play a central role in biology from immune recognition to brain activity. While major advances in machine learning have improved our ability to predict protein structure from sequence, determining protein function from structure remains a major challenge. Here, we introduce Holographic Convolutional Neural Network (H-CNN) for proteins, which is a physically motivated machine learning approach to model amino acid preferences in protein structures. H-CNN reflects physical interactions in a protein structure and recapitulates the functional information stored in evolutionary data. H-CNN accurately predicts the impact of mutations on protein function, including stability and binding of protein complexes. Our interpretable computational model for protein structure-function maps could guide design of novel proteins with desired function.
Contextual Learning in Fourier Complex Field for VHR Remote Sensing Images
Oct 28, 2022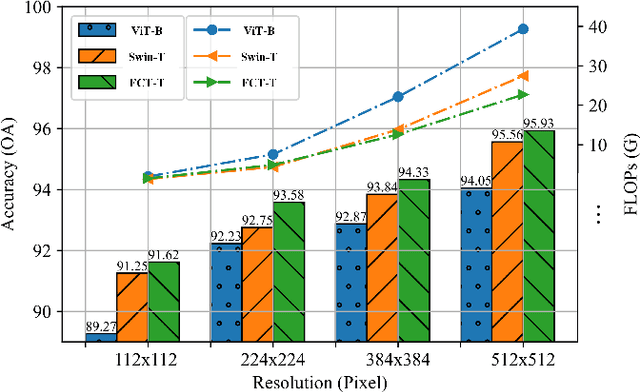
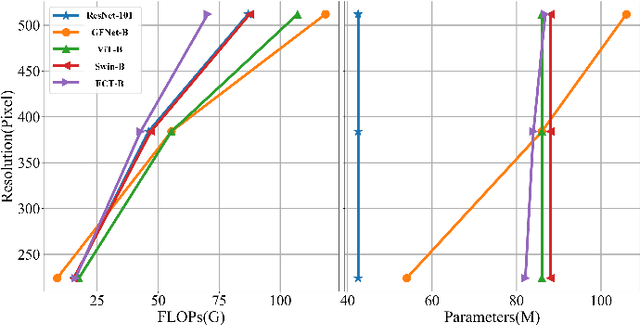
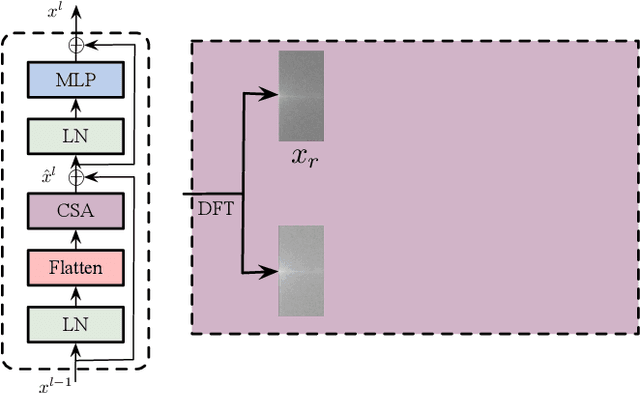
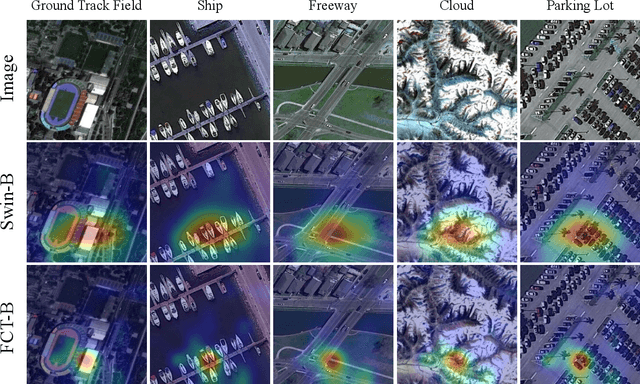
Very high-resolution (VHR) remote sensing (RS) image classification is the fundamental task for RS image analysis and understanding. Recently, transformer-based models demonstrated outstanding potential for learning high-order contextual relationships from natural images with general resolution (224x224 pixels) and achieved remarkable results on general image classification tasks. However, the complexity of the naive transformer grows quadratically with the increase in image size, which prevents transformer-based models from VHR RS image (500x500 pixels) classification and other computationally expensive downstream tasks. To this end, we propose to decompose the expensive self-attention (SA) into real and imaginary parts via discrete Fourier transform (DFT) and therefore propose an efficient complex self-attention (CSA) mechanism. Benefiting from the conjugated symmetric property of DFT, CSA is capable to model the high-order contextual information with less than half computations of naive SA. To overcome the gradient explosion in Fourier complex field, we replace the Softmax function with the carefully designed Logmax function to normalize the attention map of CSA and stabilize the gradient propagation. By stacking various layers of CSA blocks, we propose the Fourier Complex Transformer (FCT) model to learn global contextual information from VHR aerial images following the hierarchical manners. Universal experiments conducted on commonly used RS classification data sets demonstrate the effectiveness and efficiency of FCT, especially on very high-resolution RS images.
How to Describe Images in a More Funny Way? Towards a Modular Approach to Cross-Modal Sarcasm Generation
Nov 20, 2022
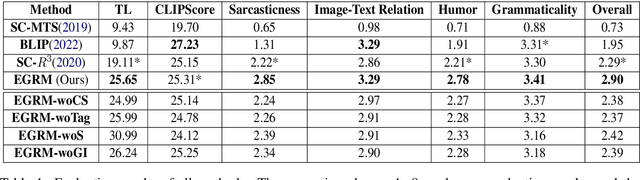
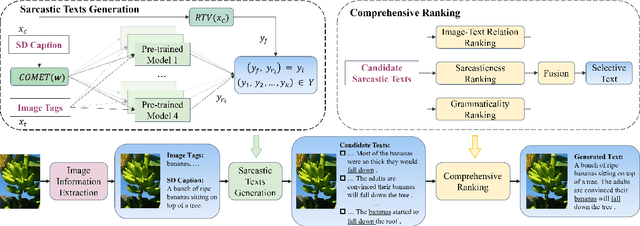

Sarcasm generation has been investigated in previous studies by considering it as a text-to-text generation problem, i.e., generating a sarcastic sentence for an input sentence. In this paper, we study a new problem of cross-modal sarcasm generation (CMSG), i.e., generating a sarcastic description for a given image. CMSG is challenging as models need to satisfy the characteristics of sarcasm, as well as the correlation between different modalities. In addition, there should be some inconsistency between the two modalities, which requires imagination. Moreover, high-quality training data is insufficient. To address these problems, we take a step toward generating sarcastic descriptions from images without paired training data and propose an Extraction-Generation-Ranking based Modular method (EGRM) for cross-model sarcasm generation. Specifically, EGRM first extracts diverse information from an image at different levels and uses the obtained image tags, sentimental descriptive caption, and commonsense-based consequence to generate candidate sarcastic texts. Then, a comprehensive ranking algorithm, which considers image-text relation, sarcasticness, and grammaticality, is proposed to select a final text from the candidate texts. Human evaluation at five criteria on a total of 1200 generated image-text pairs from eight systems and auxiliary automatic evaluation show the superiority of our method.
Leveraging per Image-Token Consistency for Vision-Language Pre-training
Nov 20, 2022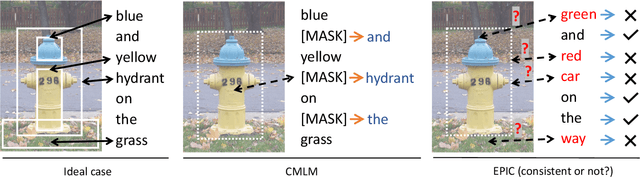
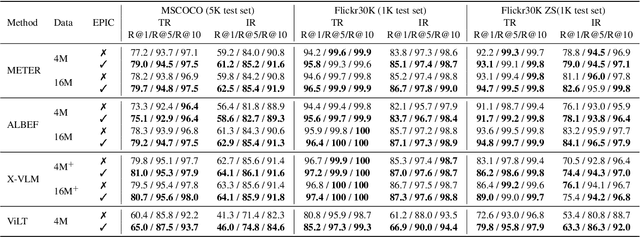
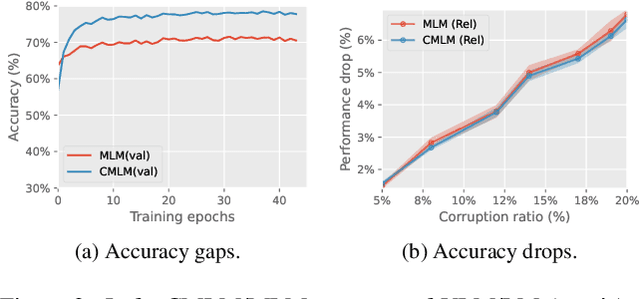
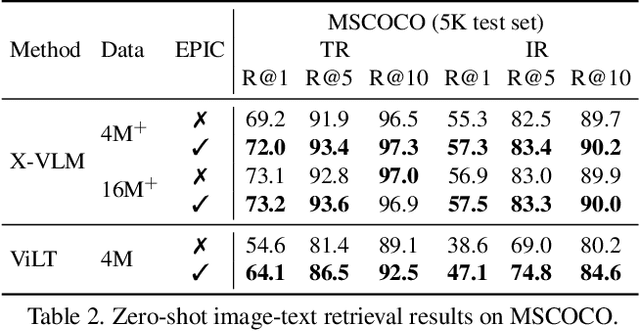
Most existing vision-language pre-training (VLP) approaches adopt cross-modal masked language modeling (CMLM) to learn vision-language associations. However, we find that CMLM is insufficient for this purpose according to our observations: (1) Modality bias: a considerable amount of masked tokens in CMLM can be recovered with only the language information, ignoring the visual inputs. (2) Under-utilization of the unmasked tokens: CMLM primarily focuses on the masked token but it cannot simultaneously leverage other tokens to learn vision-language associations. To handle those limitations, we propose EPIC (lEveraging Per Image-Token Consistency for vision-language pre-training). In EPIC, for each image-sentence pair, we mask tokens that are salient to the image (i.e., Saliency-based Masking Strategy) and replace them with alternatives sampled from a language model (i.e., Inconsistent Token Generation Procedure), and then the model is required to determine for each token in the sentence whether they are consistent with the image (i.e., Image-Text Consistent Task). The proposed EPIC method is easily combined with pre-training methods. Extensive experiments show that the combination of the EPIC method and state-of-the-art pre-training approaches, including ViLT, ALBEF, METER, and X-VLM, leads to significant improvements on downstream tasks.
Invisible Backdoor Attack with Dynamic Triggers against Person Re-identification
Nov 20, 2022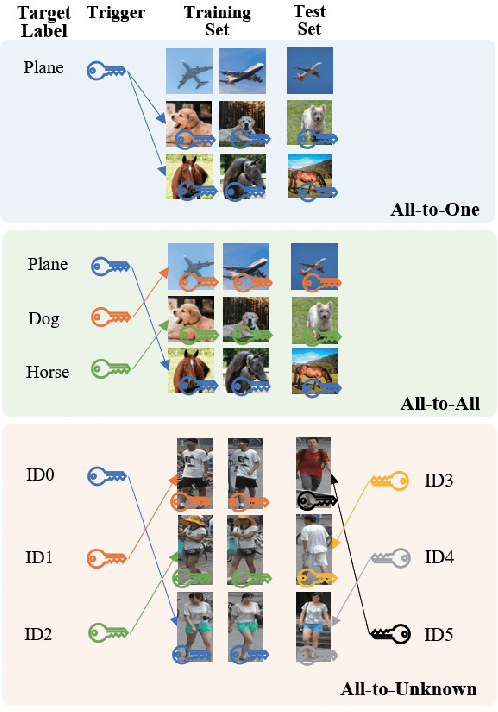
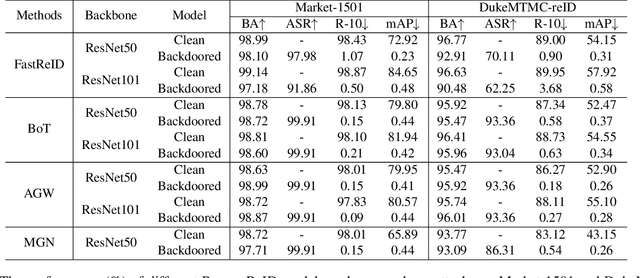
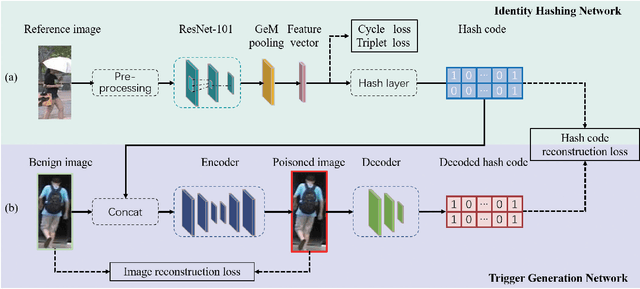
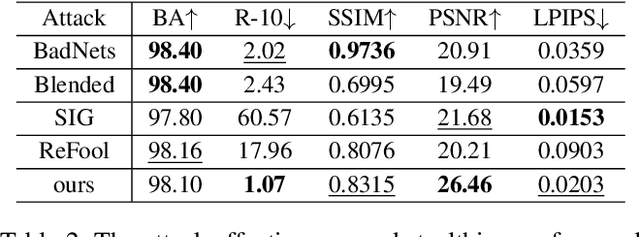
In recent years, person Re-identification (ReID) has rapidly progressed with wide real-world applications, but also poses significant risks of adversarial attacks. In this paper, we focus on the backdoor attack on deep ReID models. Existing backdoor attack methods follow an all-to-one/all attack scenario, where all the target classes in the test set have already been seen in the training set. However, ReID is a much more complex fine-grained open-set recognition problem, where the identities in the test set are not contained in the training set. Thus, previous backdoor attack methods for classification are not applicable for ReID. To ameliorate this issue, we propose a novel backdoor attack on deep ReID under a new all-to-unknown scenario, called Dynamic Triggers Invisible Backdoor Attack (DT-IBA). Instead of learning fixed triggers for the target classes from the training set, DT-IBA can dynamically generate new triggers for any unknown identities. Specifically, an identity hashing network is proposed to first extract target identity information from a reference image, which is then injected into the benign images by image steganography. We extensively validate the effectiveness and stealthiness of the proposed attack on benchmark datasets, and evaluate the effectiveness of several defense methods against our attack.