 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UGformer for Robust Left Atrium and Scar Segmentation Across Scanners
Oct 11, 2022

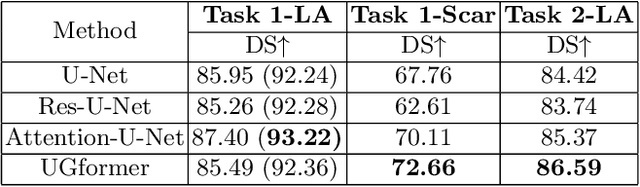
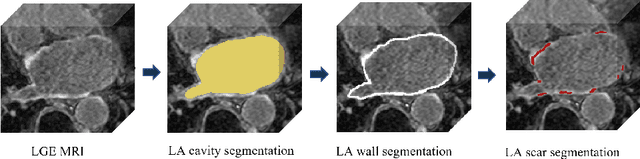
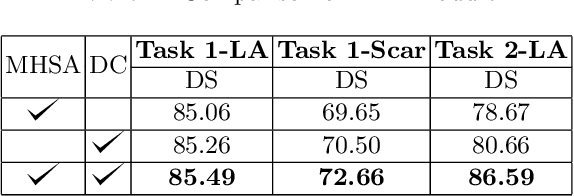
Thanks to the capacity for long-range dependencies and robustness to irregular shapes, vision transformers and deformable convolutions are emerging as powerful vision techniques of segmentation.Meanwhile, Graph Convolution Networks (GCN) optimize local features based on global topological relationship modeling. Particularly, they have been proved to be effective in addressing issues in medical imaging segmentation tasks including multi-domain generalization for low-quality images. In this paper, we present a novel, effective, and robust framework for medical image segmentation, namely, UGformer. It unifies novel transformer blocks, GCN bridges, and convolution decoders originating from U-Net to predict left atriums (LAs) and LA scars. We have identified two appealing findings of the proposed UGformer: 1). an enhanced transformer module with deformable convolutions to improve the blending of the transformer information with convolutional information and help predict irregular LAs and scar shapes. 2). Using a bridge incorporating GCN to further overcome the difficulty of capturing condition inconsistency across different Magnetic Resonance Images scanners with various inconsistent domain information. The proposed UGformer model exhibits outstanding ability to segment the left atrium and scar on the LAScarQS 2022 dataset, outperforming several recent state-of-the-arts.
Unifying Graph Contrastive Learning with Flexible Contextual Scopes
Oct 17, 2022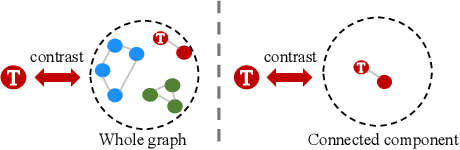
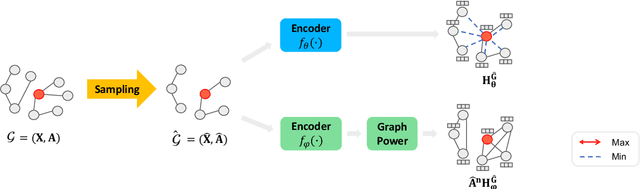
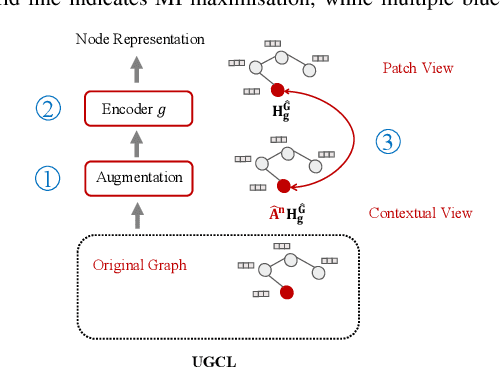
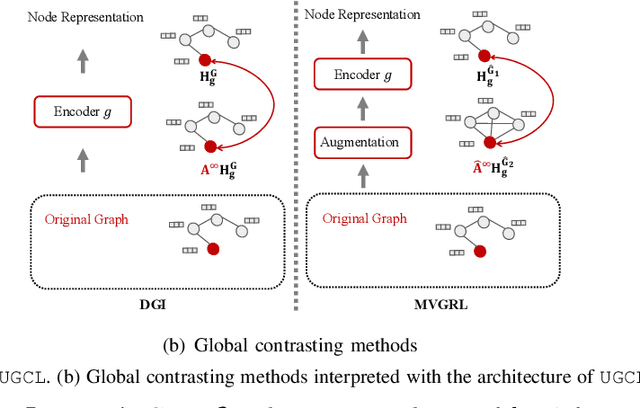
Graph contrastive learning (GCL) has recently emerged as an effective learning paradigm to alleviate the reliance on labelling information for graph representation learning. The core of GCL is to maximise the mutual information between the representation of a node and its contextual representation (i.e., the corresponding instance with similar semantic information) summarised from the contextual scope (e.g., the whole graph or 1-hop neighbourhood). This scheme distils valuable self-supervision signals for GCL training. However, existing GCL methods still suffer from limitations, such as the incapacity or inconvenience in choosing a suitable contextual scope for different datasets and building biased contrastiveness. To address aforementioned problems, we present a simple self-supervised learning method termed Unifying Graph Contrastive Learning with Flexible Contextual Scopes (UGCL for short). Our algorithm builds flexible contextual representations with tunable contextual scopes by controlling the power of an adjacency matrix. Additionally, our method ensures contrastiveness is built within connected components to reduce the bias of contextual representations. Based on representations from both local and contextual scopes, UGCL optimises a very simple contrastive loss function for graph representation learning. Essentially, the architecture of UGCL can be considered as a general framework to unify existing GCL methods. We have conducted intensive experiments and achieved new state-of-the-art performance in six out of eight benchmark datasets compared with self-supervised graph representation learning baselines. Our code has been open-sourced.
Adversarial Graph Contrastive Learning with Information Regularization
Feb 14, 2022
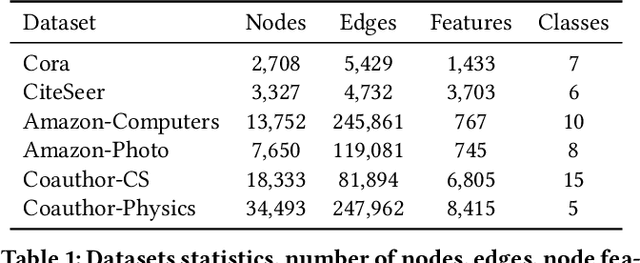
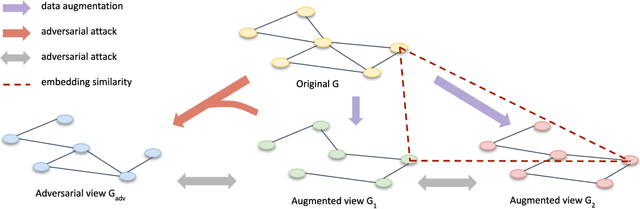
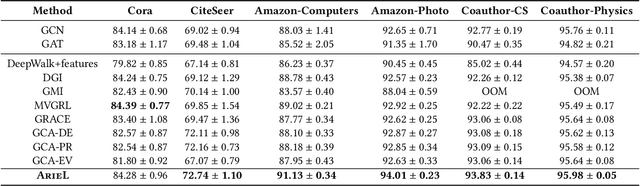
Contrastive learning is an effective unsupervised method in graph representation learning. Recently, the data augmentation based contrastive learning method has been extended from images to graphs. However, most prior works are directly adapted from the models designed for images. Unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which are the key to the performance of contrastive learning models. This leaves much space for improvement over the existing graph contrastive learning frameworks. In this work, by introducing an adversarial graph view and an information regularizer, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within a reasonable constraint. It consistently outperforms the current graph contrastive learning methods in the node classification task over various real-world datasets and further improves the robustness of graph contrastive learning.
A Stream Learning Approach for Real-Time Identification of False Data Injection Attacks in Cyber-Physical Power Systems
Oct 13, 2022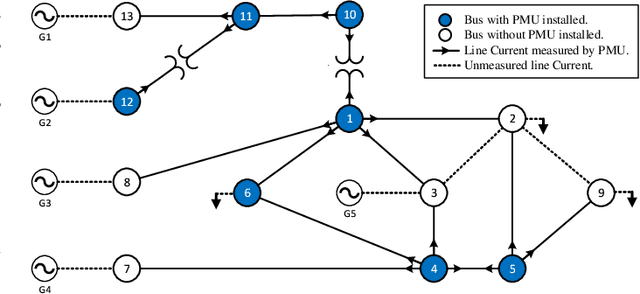
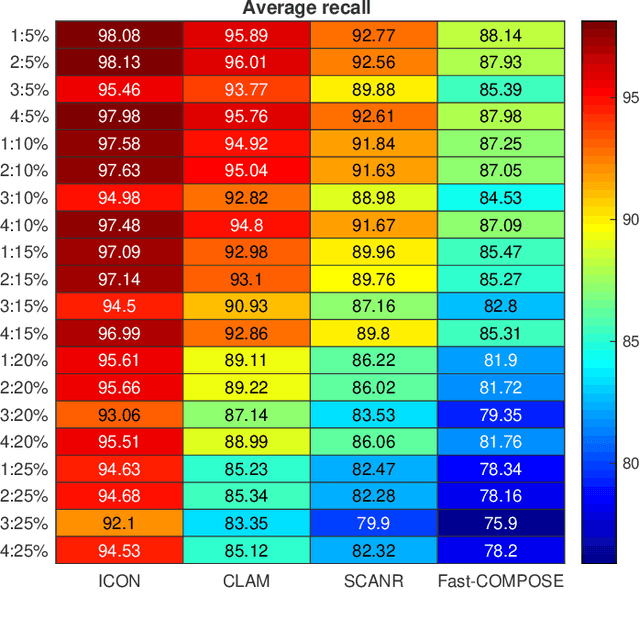
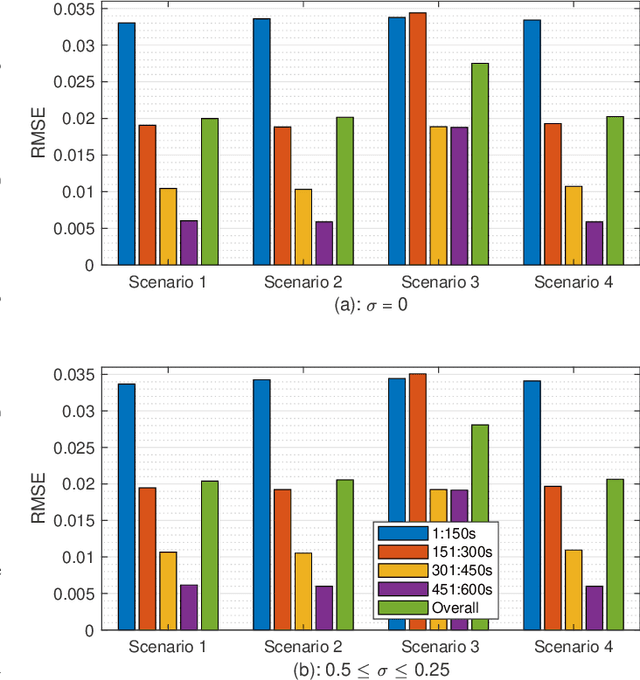
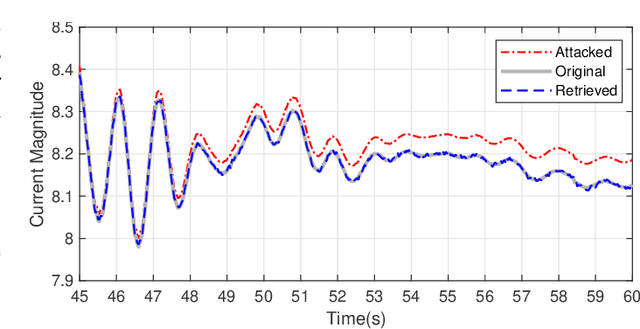
This paper presents a novel data-driven framework to aid in system state estimation when the power system is under unobservable false data injection attacks. The proposed framework dynamically detects and classifies false data injection attacks. Then, it retrieves the control signal using the acquired information. This process is accomplished in three main modules, with novel designs, for detection, classification, and control signal retrieval. The detection module monitors historical changes in phasor measurements and captures any deviation pattern caused by an attack on a complex plane. This approach can help to reveal characteristics of the attacks including the direction, magnitude, and ratio of the injected false data. Using this information, the signal retrieval module can easily recover the original control signal and remove the injected false data. Further information regarding the attack type can be obtained through the classifier module. The proposed ensemble learner is compatible with harsh learning conditions including the lack of labeled data, concept drift, concept evolution, recurring classes, and independence from external updates. The proposed novel classifier can dynamically learn from data and classify attacks under all these harsh learning conditions. The introduced framework is evaluated w.r.t. real-world data captured from the Central New York Power System. The obtained results indicate the efficacy and stability of the proposed framework.
DCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Oct 13, 2022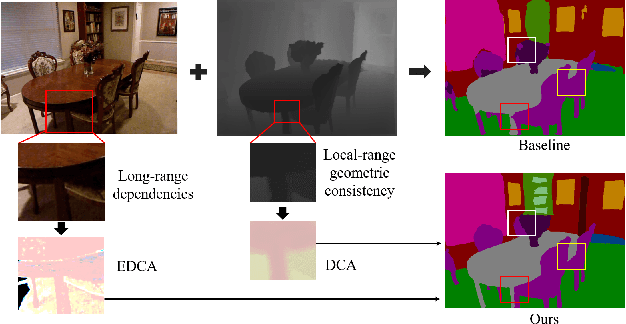
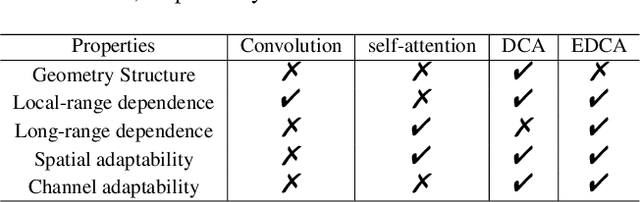
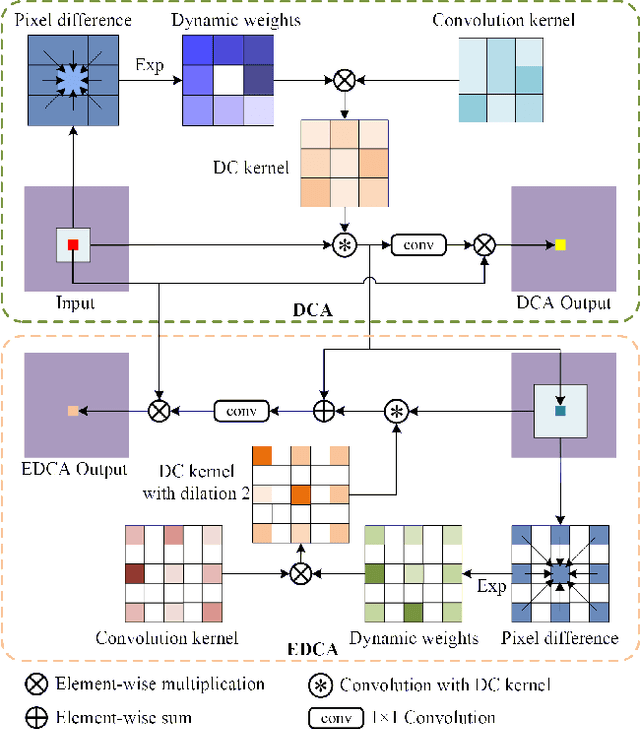
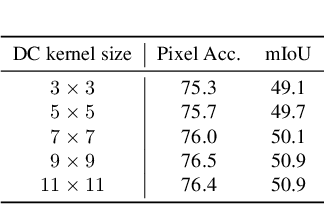
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.
How Does Pseudo-Labeling Affect the Generalization Error of the Semi-Supervised Gibbs Algorithm?
Oct 15, 2022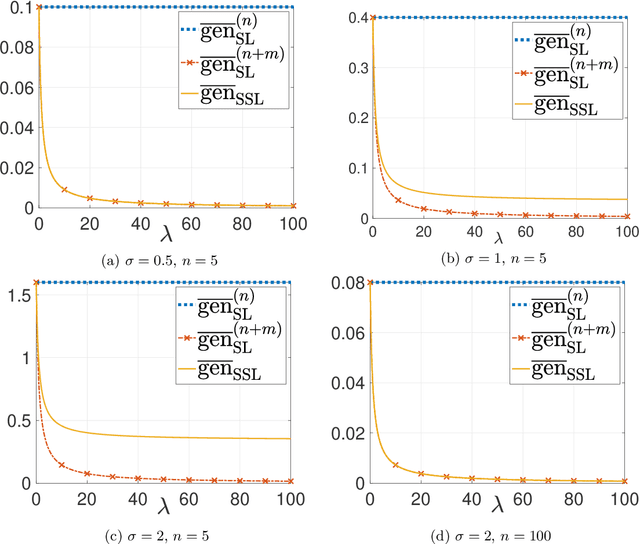
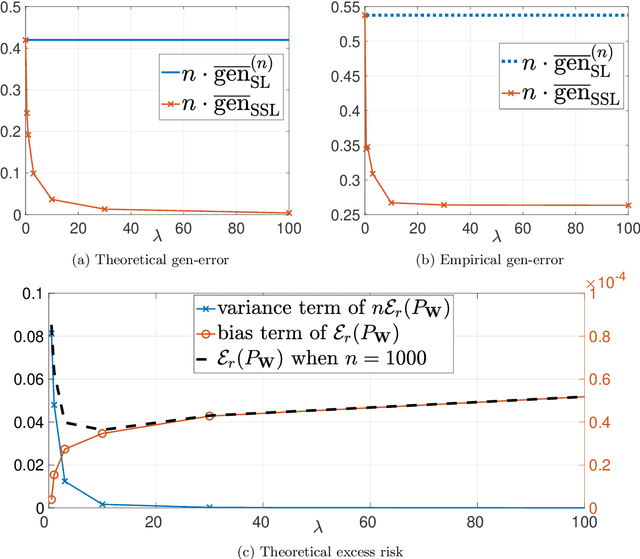
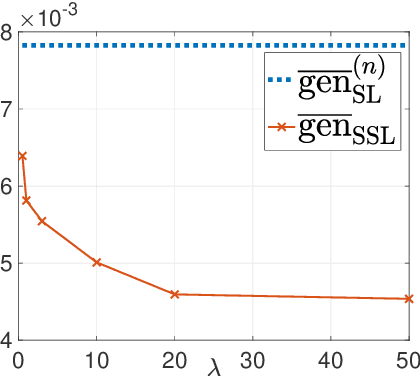
This paper provides an exact characterization of the expected generalization error (gen-error) for semi-supervised learning (SSL) with pseudo-labeling via the Gibbs algorithm. This characterization is expressed in terms of the symmetrized KL information between the output hypothesis, the pseudo-labeled dataset, and the labeled dataset. It can be applied to obtain distribution-free upper and lower bounds on the gen-error. Our findings offer new insights that the generalization performance of SSL with pseudo-labeling is affected not only by the information between the output hypothesis and input training data but also by the information {\em shared} between the {\em labeled} and {\em pseudo-labeled} data samples. To deepen our understanding, we further explore two examples -- mean estimation and logistic regression. In particular, we analyze how the ratio of the number of unlabeled to labeled data $\lambda$ affects the gen-error under both scenarios. As $\lambda$ increases, the gen-error for mean estimation decreases and then saturates at a value larger than when all the samples are labeled, and the gap can be quantified {\em exactly} with our analysis, and is dependent on the \emph{cross-covariance} between the labeled and pseudo-labeled data sample. In logistic regression, the gen-error and the variance component of the excess risk also decrease as $\lambda$ increases.
XDBERT: Distilling Visual Information to BERT from Cross-Modal Systems to Improve Language Understanding
Apr 29, 2022
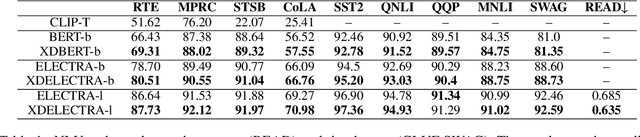
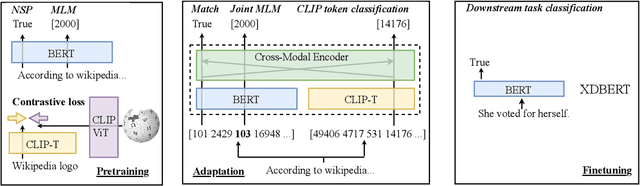

Transformer-based models are widely used in natural language understanding (NLU) tasks, and multimodal transformers have been effective in visual-language tasks. This study explores distilling visual information from pretrained multimodal transformers to pretrained language encoders. Our framework is inspired by cross-modal encoders' success in visual-language tasks while we alter the learning objective to cater to the language-heavy characteristics of NLU. After training with a small number of extra adapting steps and finetuned, the proposed XDBERT (cross-modal distilled BERT) outperforms pretrained-BERT in general language understanding evaluation (GLUE), situations with adversarial generations (SWAG) benchmarks, and readability benchmarks. We analyze the performance of XDBERT on GLUE to show that the improvement is likely visually grounded.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022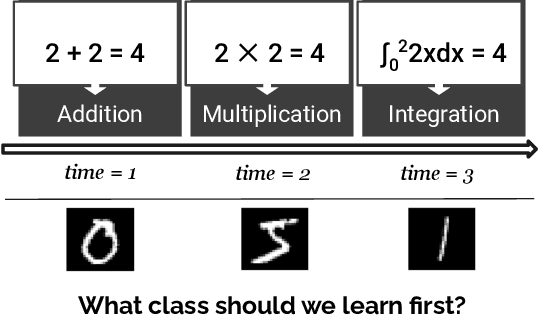
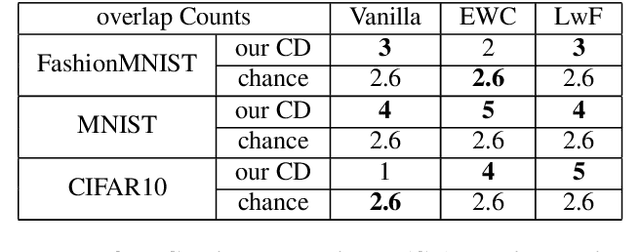
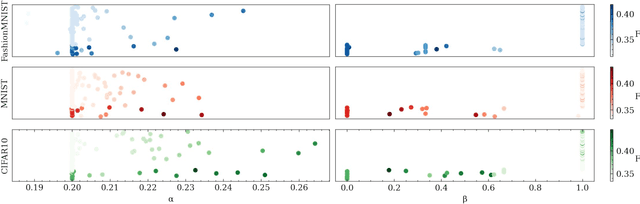
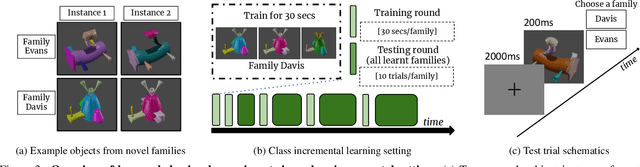
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
Graph Neural Networks for Breast Cancer Data Integration
Nov 28, 2022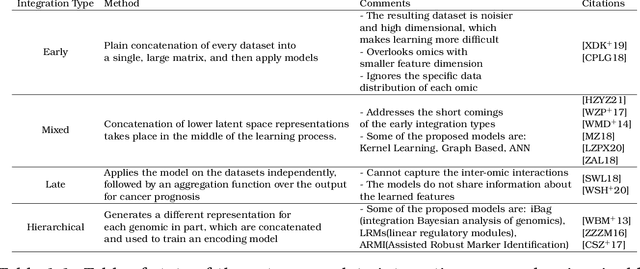
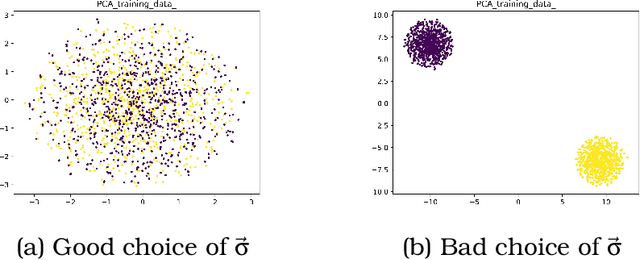
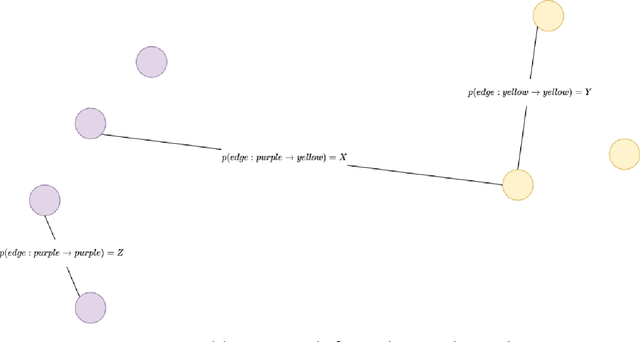
International initiatives such as METABRIC (Molecular Taxonomy of Breast Cancer International Consortium) have collected several multigenomic and clinical data sets to identify the undergoing molecular processes taking place throughout the evolution of various cancers. Numerous Machine Learning and statistical models have been designed and trained to analyze these types of data independently, however, the integration of such differently shaped and sourced information streams has not been extensively studied. To better integrate these data sets and generate meaningful representations that can ultimately be leveraged for cancer detection tasks could lead to giving well-suited treatments to patients. Hence, we propose a novel learning pipeline comprising three steps - the integration of cancer data modalities as graphs, followed by the application of Graph Neural Networks in an unsupervised setting to generate lower-dimensional embeddings from the combined data, and finally feeding the new representations on a cancer sub-type classification model for evaluation. The graph construction algorithms are described in-depth as METABRIC does not store relationships between the patient modalities, with a discussion of their influence over the quality of the generated embeddings. We also present the models used to generate the lower-latent space representations: Graph Neural Networks, Variational Graph Autoencoders and Deep Graph Infomax. In parallel, the pipeline is tested on a synthetic dataset to demonstrate that the characteristics of the underlying data, such as homophily levels, greatly influence the performance of the pipeline, which ranges between 51\% to 98\% accuracy on artificial data, and 13\% and 80\% on METABRIC. This project has the potential to improve cancer data understanding and encourages the transition of regular data sets to graph-shaped data.
N2-SAGE: Narrow-beam Near-field SAGE Algorithm for Channel Parameter Estimation in mmWave and THz Direction-scan Measurements
Nov 28, 2022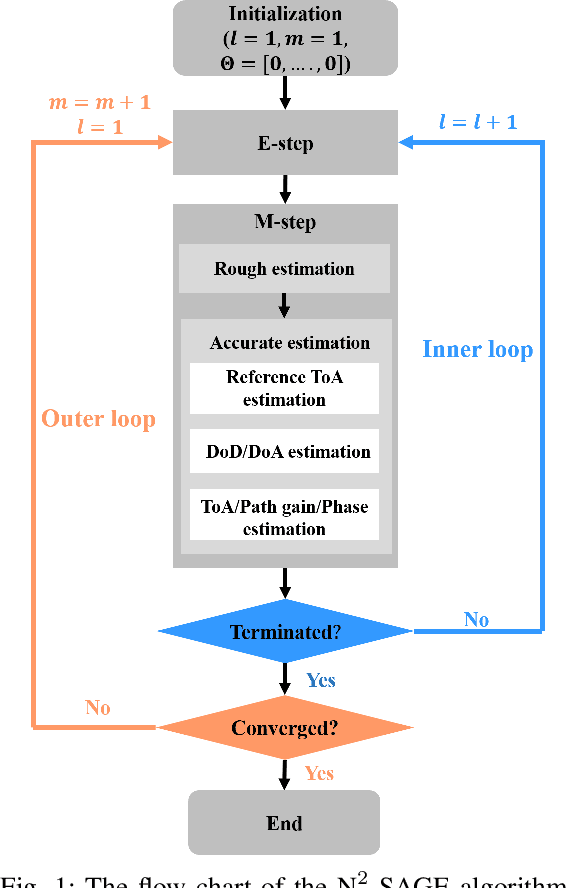
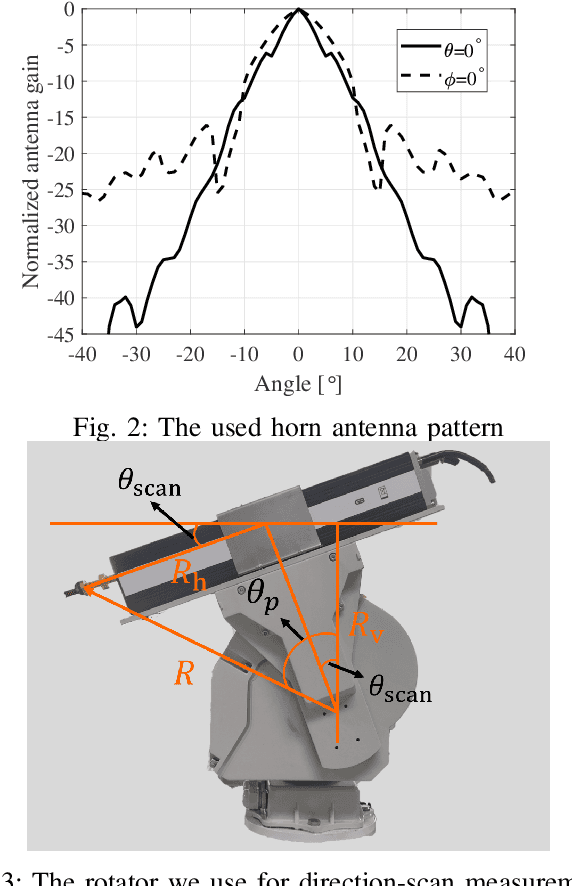
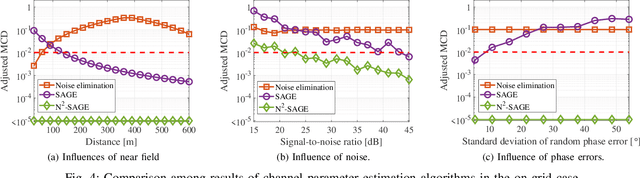
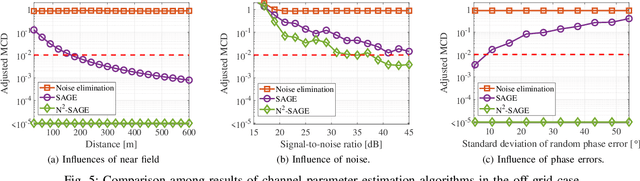
To extract channel characteristics and conduct channel modeling in millimeter-wave (mmWave) and Terahertz (THz) bands, accurate estimations of multi-path component (MPC) parameters in measured results are fundamental. However, due to high frequency and narrow antenna beams in mmWave and THz direction-scan measurements, existing channel parameter estimation algorithms are no longer effective. In this paper, a novel narrow-beam near-field space-alternating generalized expectation-maximization (N2-SAGE) algorithm is proposed, which is derived by carefully considering the features of mmWave and THz direction-scan measurement campaigns, such as near field propagation, narrow antenna beams as well as asynchronous measurements in different scanning directions. The delays of MPCs are calculated using spherical wave front (SWF), which depends on delay and angles of MPCs, resulting in a high-dimensional estimation problem. To overcome this, a novel two-phase estimation process is proposed, including a rough estimation phase and an accurate estimation phase. Moreover, considering the narrow antenna beams used for mmWave and THz direction-scan measurements, the usage of partial information alleviates influence of background noises. Additionally, the phases of MPCs in different scanning directions are treated as random variables, which are estimated and reused during the estimation process, making the algorithm immune to possible phase errors. Furthermore, performance of the proposed N2-SAGE algorithm is validated and compared with existing channel parameter estimation algorithms, based on simulations and measured data. Results show that the proposed N2-SAGE algorithm greatly outperforms existing channel parameter estimation algorithms in terms of estimation accuracy. By using the N2-SAGE algorithm, the channel is characterized more correctly and reasonably.