 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatial-Temporal Attention Network for Open-Set Fine-Grained Image Recognition
Nov 25, 2022

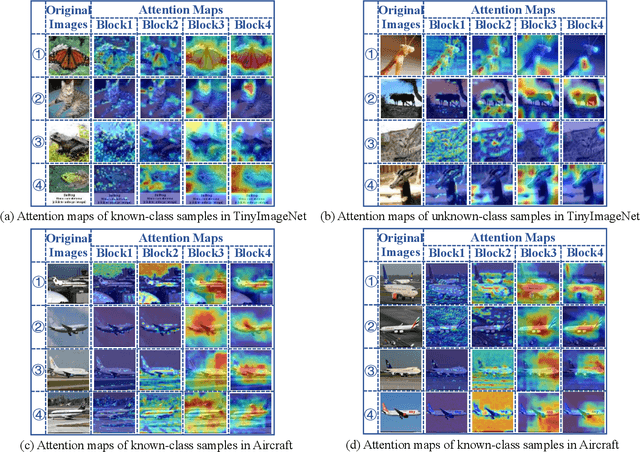
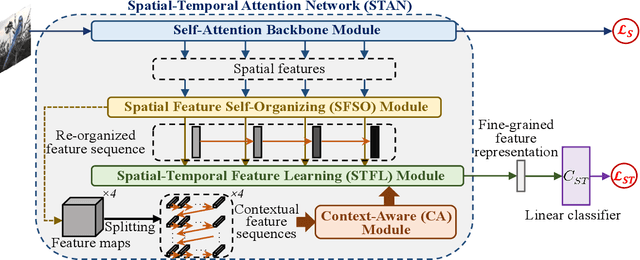
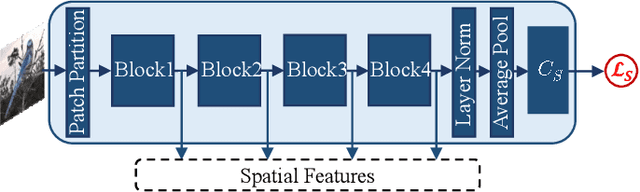
Triggered by the success of transformers in various visual tasks, the spatial self-attention mechanism has recently attracted more and more attention in the computer vision community. However, we empirically found that a typical vision transformer with the spatial self-attention mechanism could not learn accurate attention maps for distinguishing different categories of fine-grained images. To address this problem, motivated by the temporal attention mechanism in brains, we propose a spatial-temporal attention network for learning fine-grained feature representations, called STAN, where the features learnt by implementing a sequence of spatial self-attention operations corresponding to multiple moments are aggregated progressively. The proposed STAN consists of four modules: a self-attention backbone module for learning a sequence of features with self-attention operations, a spatial feature self-organizing module for facilitating the model training, a spatial-temporal feature learning module for aggregating the re-organized features via a Long Short-Term Memory network, and a context-aware module that is implemented as the forget block of the spatial-temporal feature learning module for preserving/forgetting the long-term memory by utilizing contextual information. Then, we propose a STAN-based method for open-set fine-grained recognition by integrating the proposed STAN network with a linear classifier, called STAN-OSFGR. Extensive experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that the proposed STAN-OSFGR outperforms 9 state-of-the-art open-set recognition methods significantly in most cases.
Removing grid structure in angle-resolved photoemission spectra via deep learning method
Oct 20, 2022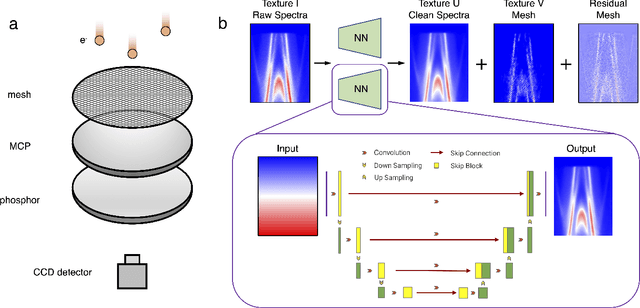
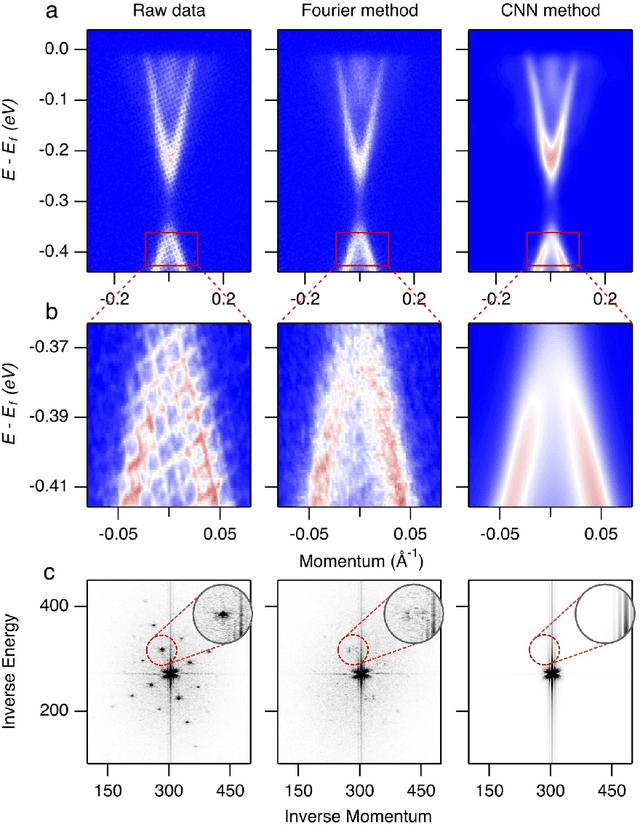
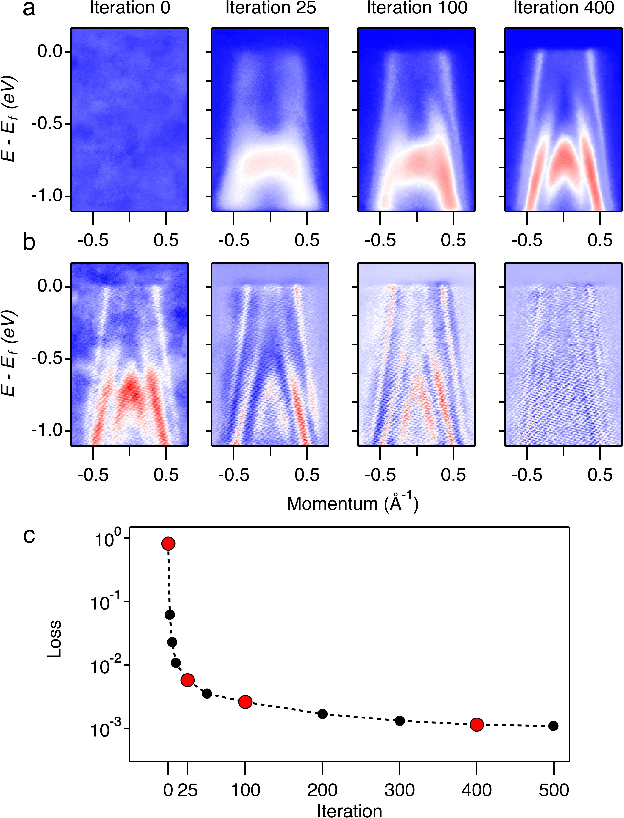
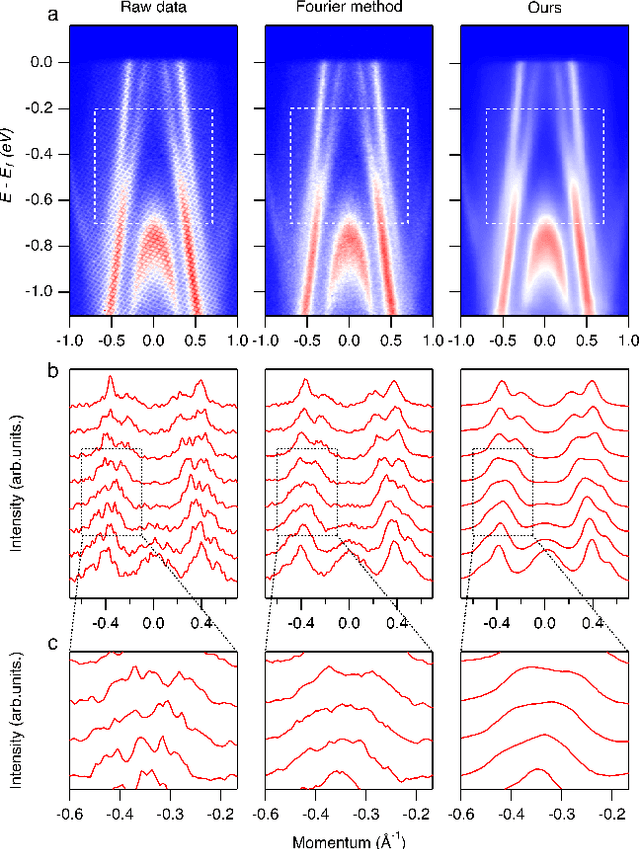
Spectroscopic data may often contain unwanted extrinsic signals. For example, in ARPES experiment, a wire mesh is typically placed in front of the CCD to block stray photo-electrons, but could cause a grid-like structure in the spectra during quick measurement mode. In the past, this structure was often removed using the mathematical Fourier filtering method by erasing the periodic structure. However, this method may lead to information loss and vacancies in the spectra because the grid structure is not strictly linearly superimposed. Here, we propose a deep learning method to effectively overcome this problem. Our method takes advantage of the self-correlation information within the spectra themselves and can greatly optimize the quality of the spectra while removing the grid structure and noise simultaneously. It has the potential to be extended to all spectroscopic measurements to eliminate other extrinsic signals and enhance the spectral quality based on the self-correlation of the spectra solely.
Private Algorithms with Private Predictions
Oct 20, 2022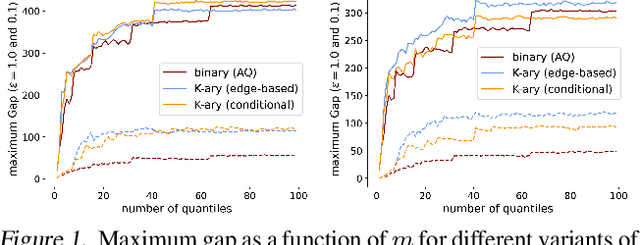
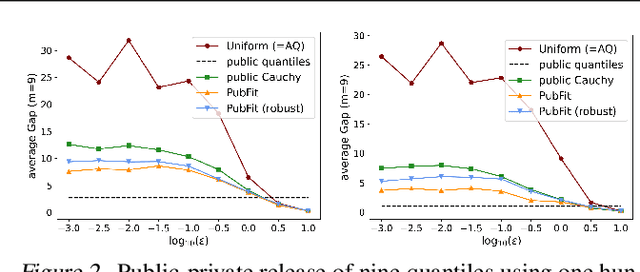
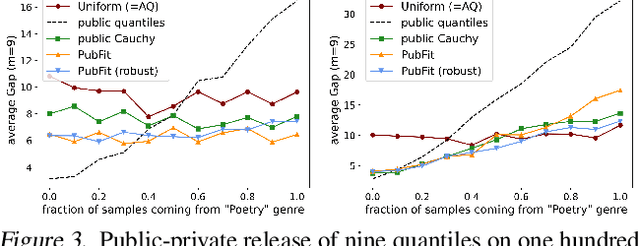
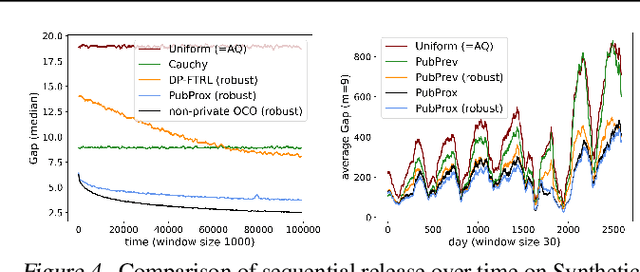
When applying differential privacy to sensitive data, a common way of getting improved performance is to use external information such as other sensitive data, public data, or human priors. We propose to use the algorithms with predictions framework -- previously applied largely to improve time complexity or competitive ratios -- as a powerful way of designing and analyzing privacy-preserving methods that can take advantage of such external information to improve utility. For four important tasks -- quantile release, its extension to multiple quantiles, covariance estimation, and data release -- we construct prediction-dependent differentially private methods whose utility scales with natural measures of prediction quality. The analyses enjoy several advantages, including minimal assumptions about the data, natural ways of adding robustness to noisy predictions, and novel "meta" algorithms that can learn predictions from other (potentially sensitive) data. Overall, our results demonstrate how to enable differentially private algorithms to make use of and learn noisy predictions, which holds great promise for improving utility while preserving privacy across a variety of tasks.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
Oct 20, 2022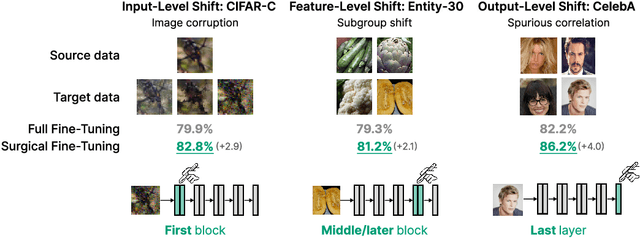
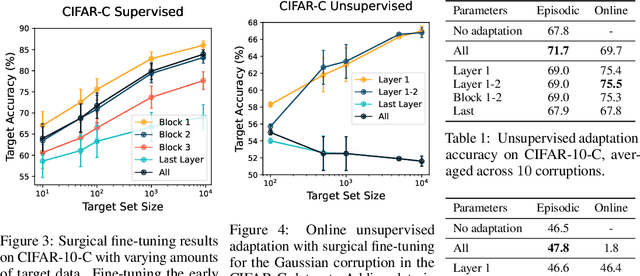
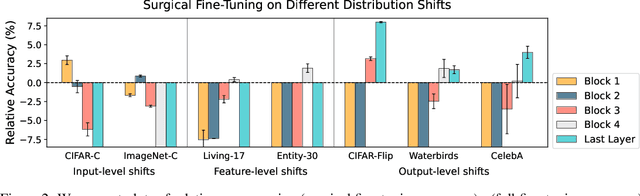
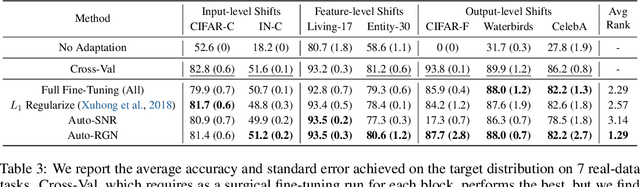
A common approach to transfer learning under distribution shift is to fine-tune the last few layers of a pre-trained model, preserving learned features while also adapting to the new task. This paper shows that in such settings, selectively fine-tuning a subset of layers (which we term surgical fine-tuning) matches or outperforms commonly used fine-tuning approaches. Moreover, the type of distribution shift influences which subset is more effective to tune: for example, for image corruptions, fine-tuning only the first few layers works best. We validate our findings systematically across seven real-world data tasks spanning three types of distribution shifts. Theoretically, we prove that for two-layer neural networks in an idealized setting, first-layer tuning can outperform fine-tuning all layers. Intuitively, fine-tuning more parameters on a small target dataset can cause information learned during pre-training to be forgotten, and the relevant information depends on the type of shift.
EmoFake: An Initial Dataset for Emotion Fake Audio Detection
Nov 11, 2022
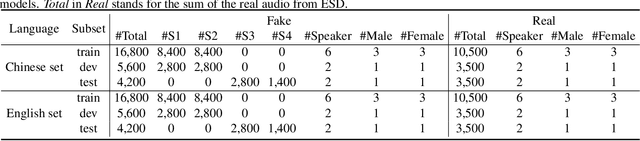
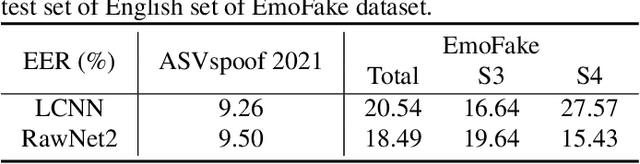
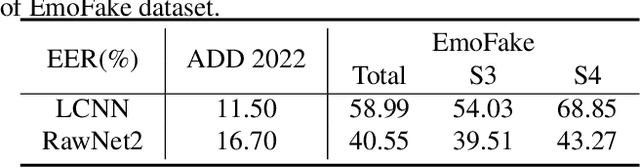
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.
Control Transformer: Robot Navigation in Unknown Environments through PRM-Guided Return-Conditioned Sequence Modeling
Nov 11, 2022
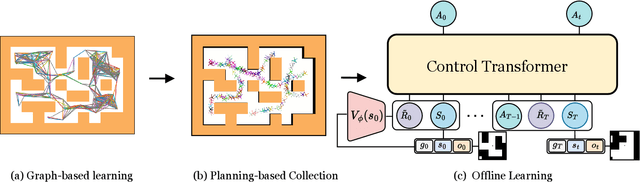
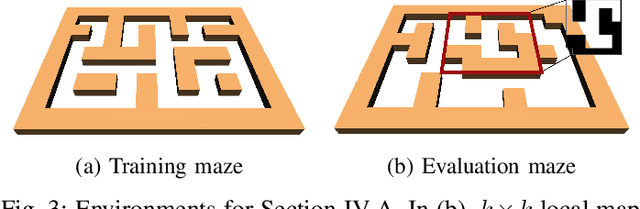
Learning long-horizon tasks such as navigation has presented difficult challenges for successfully applying reinforcement learning. However, from another perspective, under a known environment model, methods such as sampling-based planning can robustly find collision-free paths in environments without learning. In this work, we propose Control Transformer which models return-conditioned sequences from low-level policies guided by a sampling-based Probabilistic Roadmap (PRM) planner. Once trained, we demonstrate that our framework can solve long-horizon navigation tasks using only local information. We evaluate our approach on partially-observed maze navigation with MuJoCo robots, including Ant, Point, and Humanoid, and show that Control Transformer can successfully navigate large mazes and generalize to new, unknown environments. Additionally, we apply our method to a differential drive robot (Turtlebot3) and show zero-shot sim2real transfer under noisy observations.
PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework
Nov 21, 2022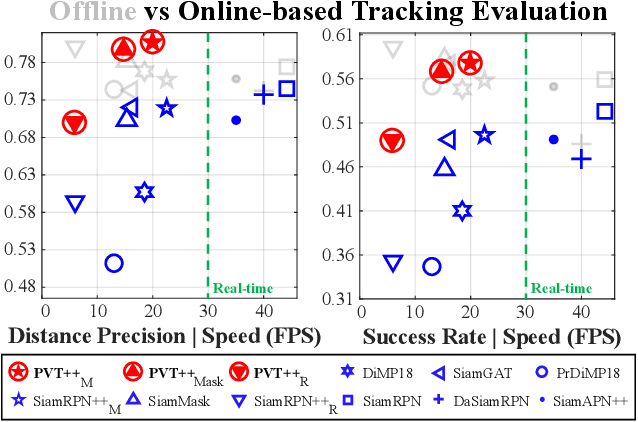
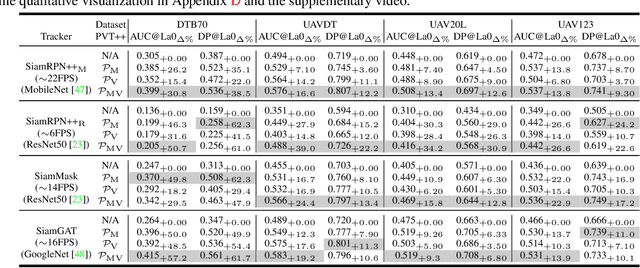
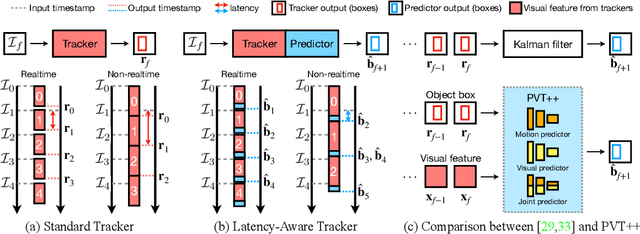

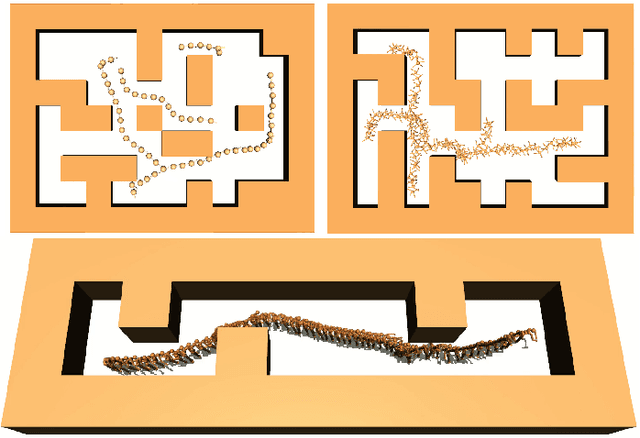
Visual object tracking is an essential capability of intelligent robots. Most existing approaches have ignored the online latency that can cause severe performance degradation during real-world processing. Especially for unmanned aerial vehicle, where robust tracking is more challenging and onboard computation is limited, latency issue could be fatal. In this work, we present a simple framework for end-to-end latency-aware tracking, i.e., end-to-end predictive visual tracking (PVT++). PVT++ is capable of turning most leading-edge trackers into predictive trackers by appending an online predictor. Unlike existing solutions that use model-based approaches, our framework is learnable, such that it can take not only motion information as input but it can also take advantage of visual cues or a combination of both. Moreover, since PVT++ is end-to-end optimizable, it can further boost the latency-aware tracking performance by joint training. Additionally, this work presents an extended latency-aware evaluation benchmark for assessing an any-speed tracker in the online setting. Empirical results on robotic platform from aerial perspective show that PVT++ can achieve up to 60% performance gain on various trackers and exhibit better robustness than prior model-based solution, largely mitigating the degradation brought by latency. Code and models will be made public.
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022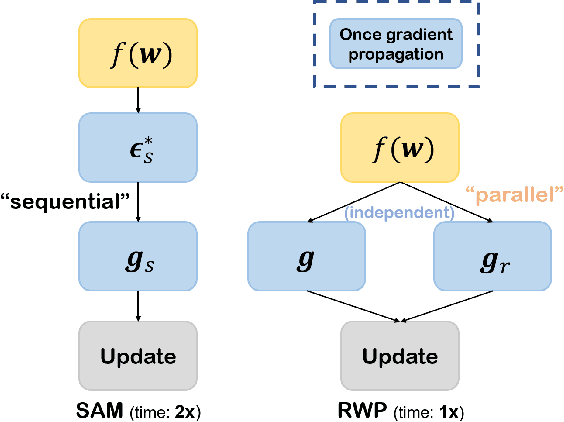
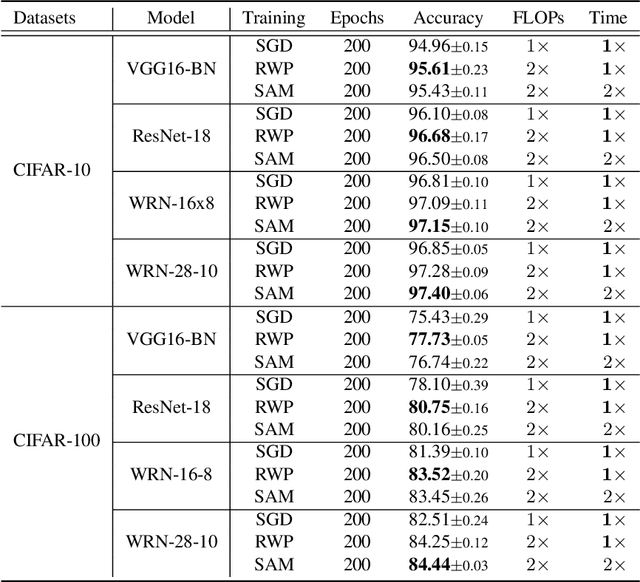
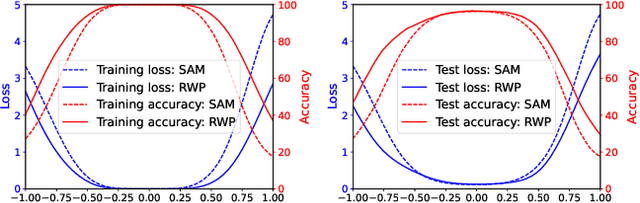
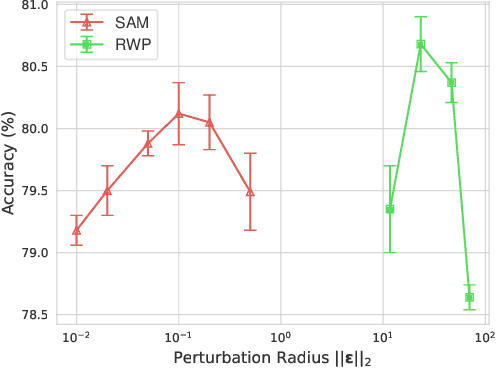
To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
Multi-Level Knowledge Distillation for Out-of-Distribution Detection in Text
Nov 21, 2022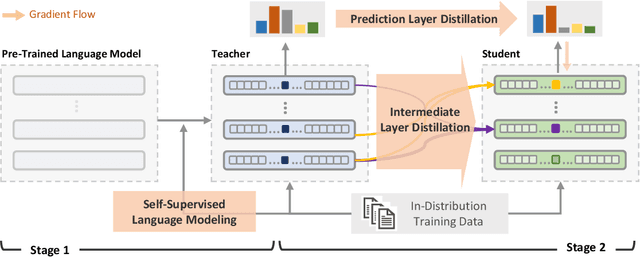
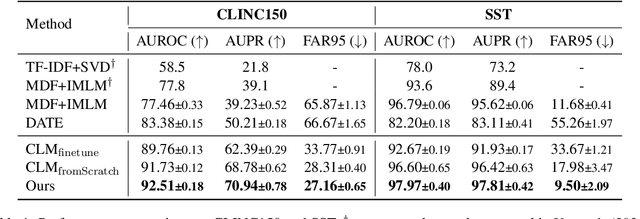
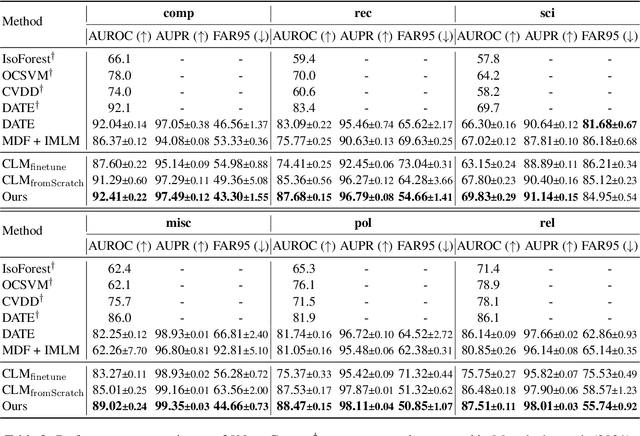
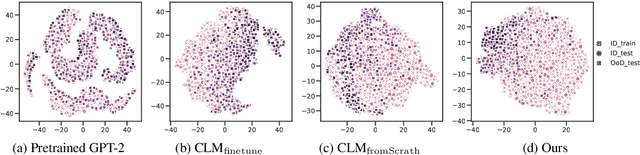
Self-supervised representation learning has proved to be a valuable component for out-of-distribution (OoD) detection with only the texts of in-distribution (ID) examples. These approaches either train a language model from scratch or fine-tune a pre-trained language model using ID examples, and then take perplexity as output by the language model as OoD scores. In this paper, we analyse the complementary characteristics of both OoD detection methods and propose a multi-level knowledge distillation approach to integrate their strengths, while mitigating their limitations. Specifically, we use a fine-tuned model as the teacher to teach a randomly initialized student model on the ID examples. Besides the prediction layer distillation, we present a similarity-based intermediate layer distillation method to facilitate the student's awareness of the information flow inside the teacher's layers. In this way, the derived student model gains the teacher's rich knowledge about the ID data manifold due to pre-training, while benefiting from seeing only ID examples during parameter learning, which promotes more distinguishable features for OoD detection. We conduct extensive experiments over multiple benchmark datasets, i.e., CLINC150, SST, 20 NewsGroups, and AG News; showing that the proposed method yields new state-of-the-art performance.
Deep learning based automatic detection of offshore oil slicks using SAR data and contextual information
Apr 13, 2022Ocean surface monitoring, especially oil slick detection, has become mandatory due to its importance for oil exploration and risk prevention on ecosystems. For years, the detection task has been performed manually by photo-interpreters using Synthetic Aperture Radar (SAR) images with the help of contextual data such as wind. This tedious manual work cannot handle the increasing amount of data collected by the available sensors and thus requires automation. Literature reports conventional and semi-automated detection methods that generally focus either on oil slicks originating from anthropogenic (spills) or natural (seeps) sources on limited data collections. As an extension, this paper presents the automation of offshore oil slicks on an extensive database with both kinds of slicks. It builds upon the slick annotations of specialized photo-interpreters on Sentinel-1 SAR data for 4 years over 3 exploration and monitoring areas worldwide. All the considered SAR images and related annotation relate to real oil slick monitoring scenarios. Further, wind estimation is systematically computed to enrich the data collection. Paper contributions are the following : (i) a performance comparison of two deep learning approaches: semantic segmentation using FC-DenseNet and instance segmentation using Mask-RCNN. (ii) the introduction of meteorological information (wind speed) is deemed valuable for oil slick detection in the performance evaluation. The main results of this study show the effectiveness of slick detection by deep learning approaches, in particular FC-DenseNet, which captures more than 92% of oil instances in our test set. Furthermore, a strong correlation between model performances and contextual information such as slick size and wind speed is demonstrated in the performance evaluation. This work opens perspectives to design models that can fuse SAR and wind information to reduce the false alarm rate.