 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Linear Coding for Gaussian Two-Way Channels
Oct 29, 2022
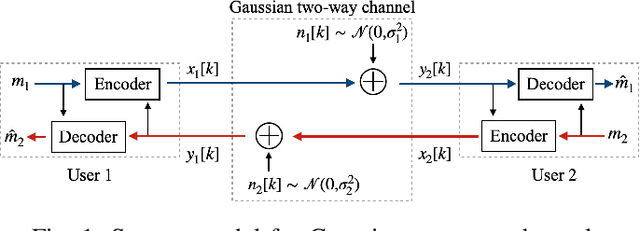
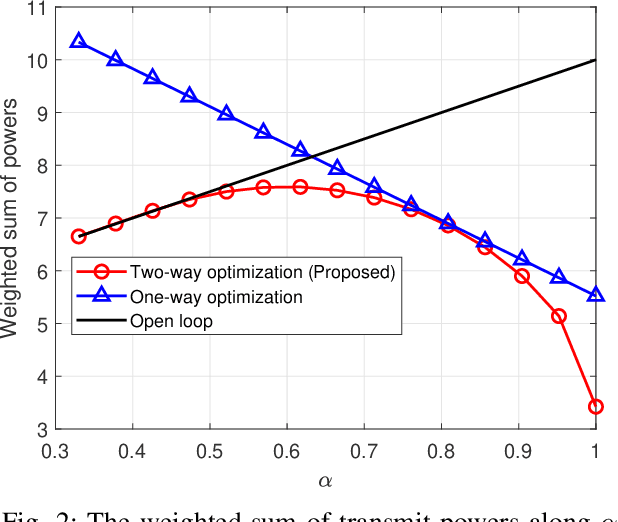
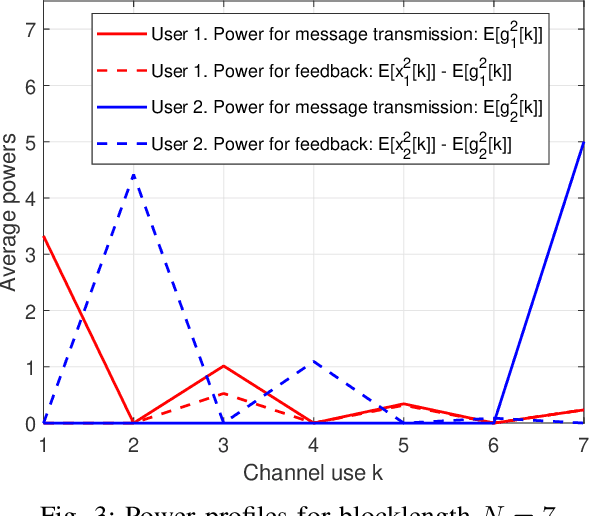
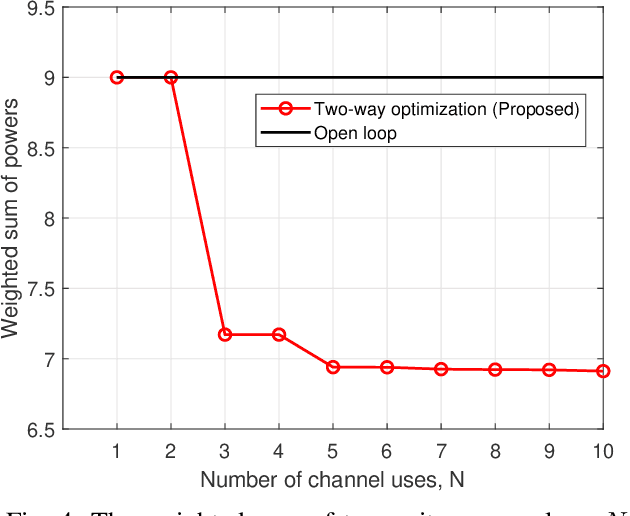
We consider linear coding for Gaussian two-way channels (GTWCs), in which each user generates the transmit symbols by linearly encoding both its message and the past received symbols (i.e., the feedback information) from the other user. In Gaussian one-way channels (GOWCs), Butman has proposed a well-developed model for linear encoding that encapsulates feedback information into transmit signals. However, such a model for GTWCs has not been well studied since the coupling of the encoding processes at the users in GTWCs renders the encoding design non-trivial and challenging. In this paper, we aim to fill this gap in the literature by extending the existing signal models in GOWCs to GTWCs. With our developed signal model for GTWCs, we formulate an optimization problem to jointly design the encoding/decoding schemes for both the users, aiming to minimize the weighted sum of their transmit powers under signal-to-noise ratio constraints. First, we derive an optimal form of the linear decoding schemes under any arbitrary encoding schemes employed at the users. Further, we provide new insights on the encoding design for GTWCs. In particular, we show that it is optimal that one of the users (i) does not transmit the feedback information to the other user at the last channel use, and (ii) transmits its message only over the last channel use. With these solution behaviors, we further simplify the problem and solve it via an iterative two-way optimization scheme. We numerically demonstrate that our proposed scheme for GTWCs achieves a better performance in terms of the transmit power compared to the existing counterparts, such as the non-feedback scheme and one-way optimization scheme.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 22, 2022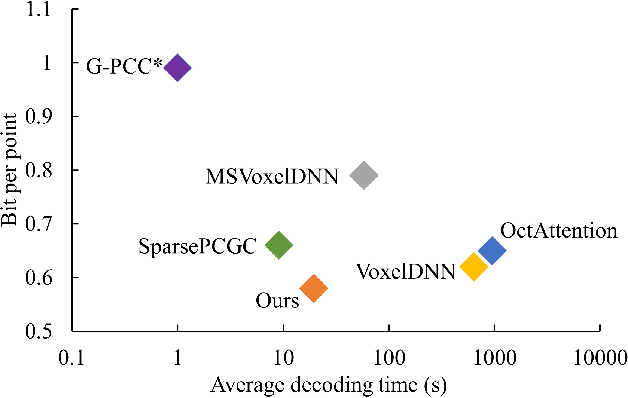
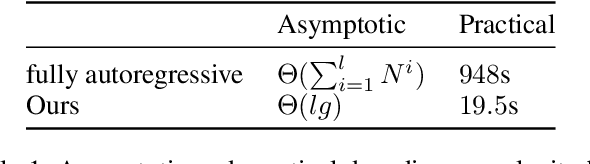
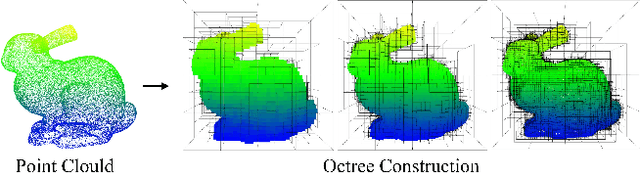
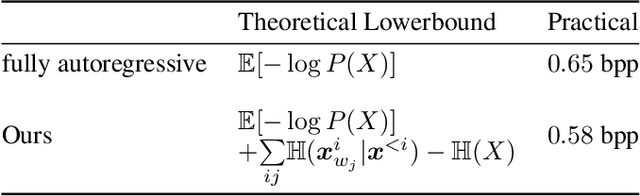
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
Nov 22, 2022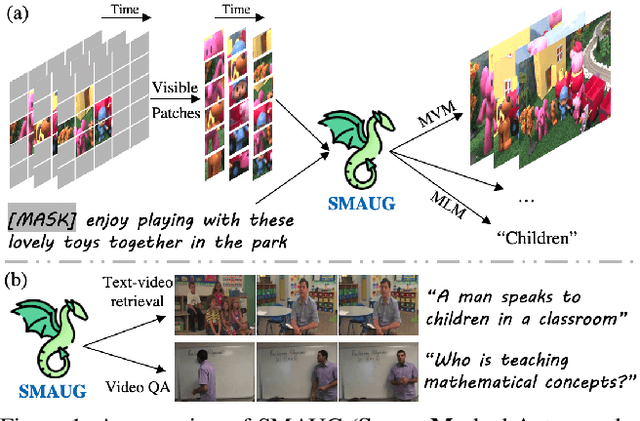
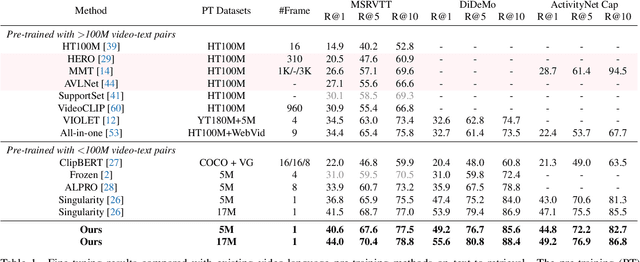
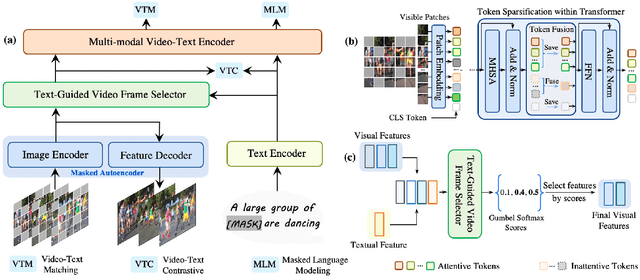
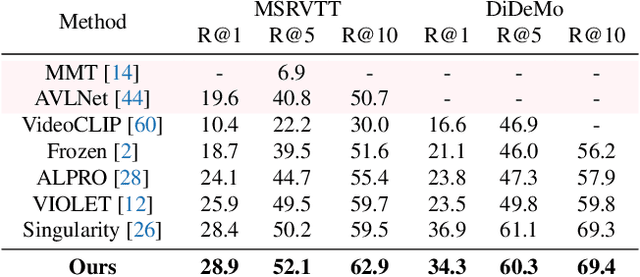
Video-language pre-training is crucial for learning powerful multi-modal representation. However, it typically requires a massive amount of computation. In this paper, we develop SMAUG, an efficient pre-training framework for video-language models. The foundation component in SMAUG is masked autoencoders. Different from prior works which only mask textual inputs, our masking strategy considers both visual and textual modalities, providing a better cross-modal alignment and saving more pre-training costs. On top of that, we introduce a space-time token sparsification module, which leverages context information to further select only "important" spatial regions and temporal frames for pre-training. Coupling all these designs allows our method to enjoy both competitive performances on text-to-video retrieval and video question answering tasks, and much less pre-training costs by 1.9X or more. For example, our SMAUG only needs about 50 NVIDIA A6000 GPU hours for pre-training to attain competitive performances on these two video-language tasks across six popular benchmarks.
Decision-making with Imaginary Opponent Models
Nov 22, 2022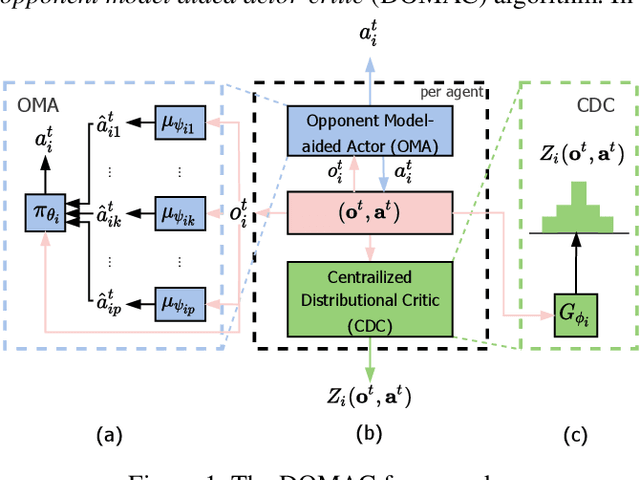

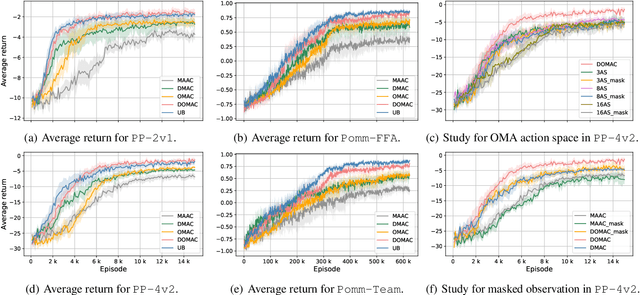
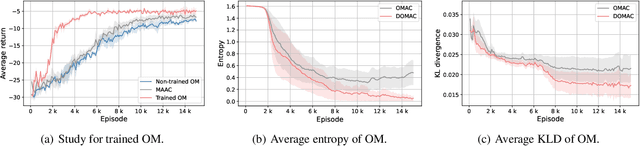
Opponent modeling has benefited a controlled agent's decision-making by constructing models of other agents. Existing methods commonly assume access to opponents' observations and actions, which is infeasible when opponents' behaviors are unobservable or hard to obtain. We propose a novel multi-agent distributional actor-critic algorithm to achieve imaginary opponent modeling with purely local information (i.e., the controlled agent's observations, actions, and rewards). Specifically, the actor maintains a speculated belief of the opponents, which we call the \textit{imaginary opponent models}, to predict opponents' actions using local observations and makes decisions accordingly. Further, the distributional critic models the return distribution of the policy. It reflects the quality of the actor and thus can guide the training of the imaginary opponent model that the actor relies on. Extensive experiments confirm that our method successfully models opponents' behaviors without their data and delivers superior performance against baseline methods with a faster convergence speed.
#Secim2023: First Public Dataset for Studying Turkish General Election
Nov 22, 2022
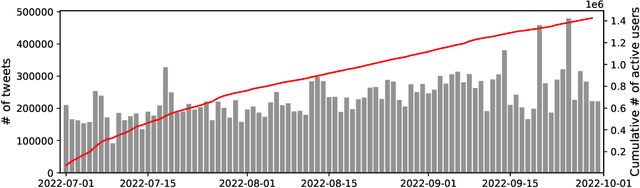
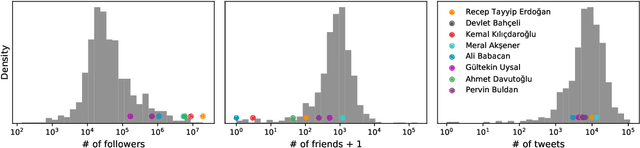
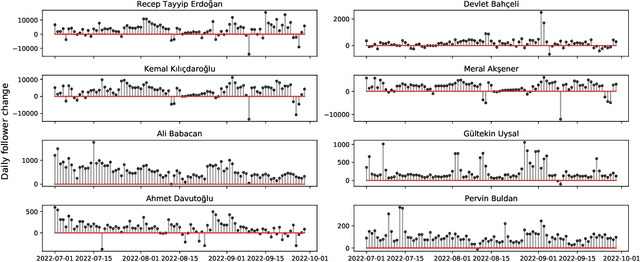
In the context of Turkey's upcoming parliamentary and presidential elections ("se\c{c}im" in Turkish), social media is playing an important role in shaping public debate. The increasing engagement of citizens on social media platforms has led to the growing use of social media by political actors. It is of utmost importance to capture the upcoming Turkish elections, as social media is becoming an essential component of election propaganda, political debates, smear campaigns, and election manipulation by domestic and international actors. We provide a comprehensive dataset for social media researchers to study the upcoming election, develop tools to prevent online manipulation, and gather novel information to inform the public. We are committed to continually improving the data collection and updating it regularly leading up to the election. Using the Secim2023 dataset, researchers can examine the social and communication networks between political actors, track current trends, and investigate emerging threats to election integrity. Our dataset is available at: https://github.com/ViralLab/Secim2023_Dataset
Geometric Knowledge Distillation: Topology Compression for Graph Neural Networks
Oct 24, 2022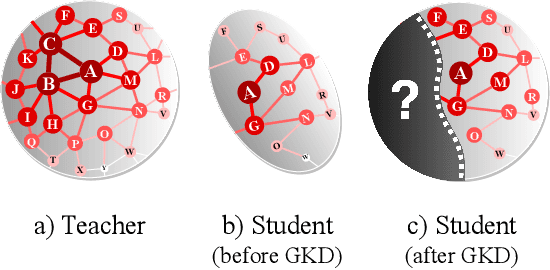
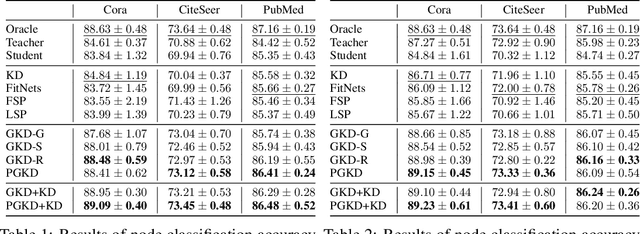
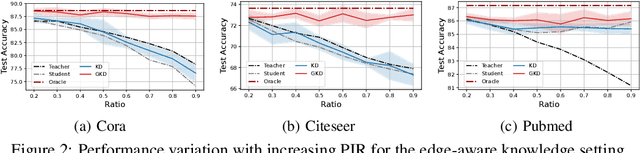

We study a new paradigm of knowledge transfer that aims at encoding graph topological information into graph neural networks (GNNs) by distilling knowledge from a teacher GNN model trained on a complete graph to a student GNN model operating on a smaller or sparser graph. To this end, we revisit the connection between thermodynamics and the behavior of GNN, based on which we propose Neural Heat Kernel (NHK) to encapsulate the geometric property of the underlying manifold concerning the architecture of GNNs. A fundamental and principled solution is derived by aligning NHKs on teacher and student models, dubbed as Geometric Knowledge Distillation. We develop non- and parametric instantiations and demonstrate their efficacy in various experimental settings for knowledge distillation regarding different types of privileged topological information and teacher-student schemes.
IRS-Assistance with Outdated CSI: Element subset selection for secrecy performance enhancement
Nov 16, 2022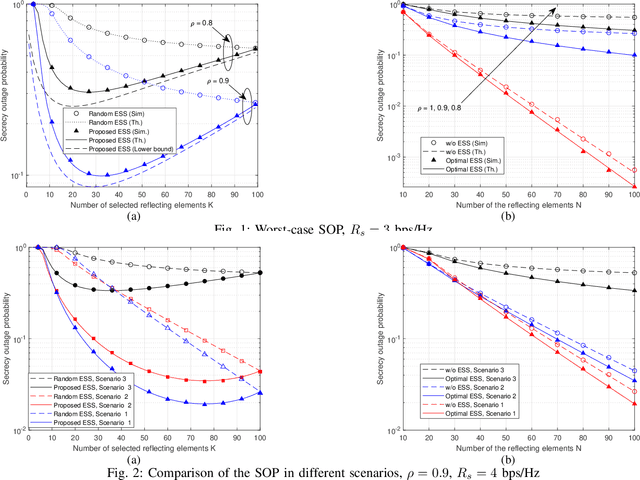
In this work, we investigate the secrecy performance in an intelligent reflecting surface (IRS)-assisted downlink system. In particular, we consider a base station (BS)-side IRS and as such, the BS-IRS channel is assumed to be known perfectly. Of more importance, we consider the case, in which only outdated channel state information (CSI) of the IRS-user channel is available. We study the impact of outdated CSI on the secrecy performance numerically and analytically. Furthermore, we propose an element subset selection (ESS) method in order to improve the secrecy performance. A key observation is that minimal secrecy outage probability (SOP) can be achieved using a subset of the IRS, and the optimal number of selected reflecting elements can be effectively found by closed-form expressions.
Fast Online Hashing with Multi-Label Projection
Dec 03, 2022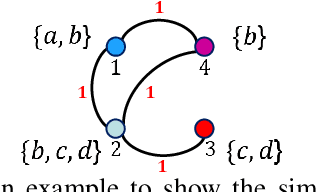
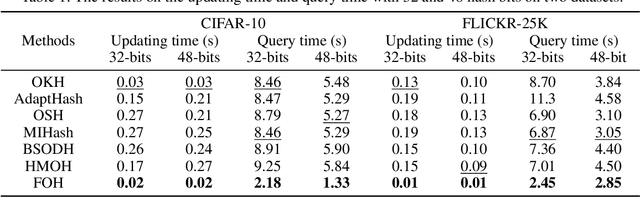
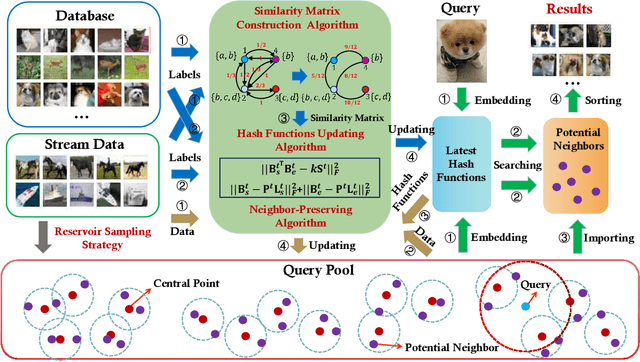

Hashing has been widely researched to solve the large-scale approximate nearest neighbor search problem owing to its time and storage superiority. In recent years, a number of online hashing methods have emerged, which can update the hash functions to adapt to the new stream data and realize dynamic retrieval. However, existing online hashing methods are required to update the whole database with the latest hash functions when a query arrives, which leads to low retrieval efficiency with the continuous increase of the stream data. On the other hand, these methods ignore the supervision relationship among the examples, especially in the multi-label case. In this paper, we propose a novel Fast Online Hashing (FOH) method which only updates the binary codes of a small part of the database. To be specific, we first build a query pool in which the nearest neighbors of each central point are recorded. When a new query arrives, only the binary codes of the corresponding potential neighbors are updated. In addition, we create a similarity matrix which takes the multi-label supervision information into account and bring in the multi-label projection loss to further preserve the similarity among the multi-label data. The experimental results on two common benchmarks show that the proposed FOH can achieve dramatic superiority on query time up to 6.28 seconds less than state-of-the-art baselines with competitive retrieval accuracy.
Modeling Label Correlations for Ultra-Fine Entity Typing with Neural Pairwise Conditional Random Field
Dec 03, 2022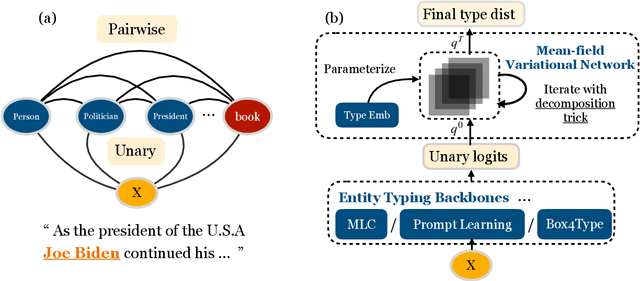

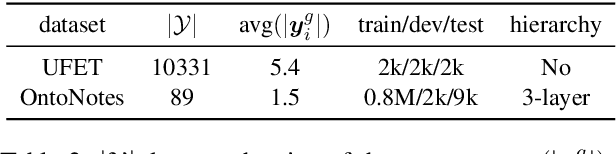
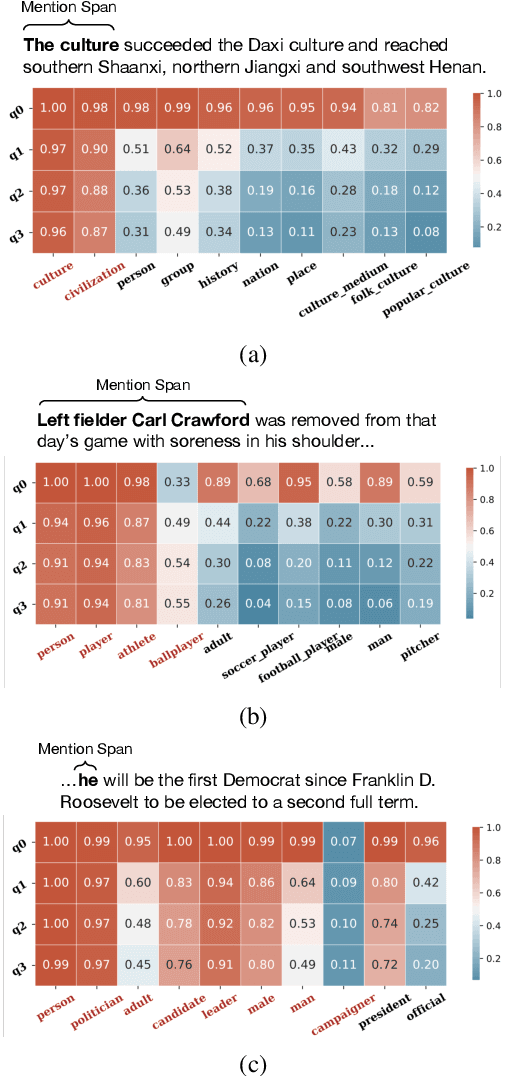
Ultra-fine entity typing (UFET) aims to predict a wide range of type phrases that correctly describe the categories of a given entity mention in a sentence. Most recent works infer each entity type independently, ignoring the correlations between types, e.g., when an entity is inferred as a president, it should also be a politician and a leader. To this end, we use an undirected graphical model called pairwise conditional random field (PCRF) to formulate the UFET problem, in which the type variables are not only unarily influenced by the input but also pairwisely relate to all the other type variables. We use various modern backbones for entity typing to compute unary potentials, and derive pairwise potentials from type phrase representations that both capture prior semantic information and facilitate accelerated inference. We use mean-field variational inference for efficient type inference on very large type sets and unfold it as a neural network module to enable end-to-end training. Experiments on UFET show that the Neural-PCRF consistently outperforms its backbones with little cost and results in a competitive performance against cross-encoder based SOTA while being thousands of times faster. We also find Neural- PCRF effective on a widely used fine-grained entity typing dataset with a smaller type set. We pack Neural-PCRF as a network module that can be plugged onto multi-label type classifiers with ease and release it in https://github.com/modelscope/adaseq/tree/master/examples/NPCRF.
On the power of foundation models
Nov 29, 2022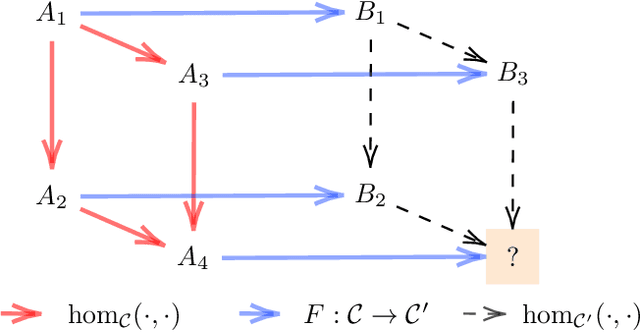
With infinitely many high-quality data points, infinite computational power, an infinitely large foundation model with a perfect training algorithm and guaranteed zero generalization error on the pretext task, can the model be used for everything? This question cannot be answered by the existing theory of representation, optimization or generalization, because the issues they mainly investigate are assumed to be nonexistent here. In this paper, we show that category theory provides powerful machinery to answer this question. We have proved three results. The first one limits the power of prompt-based learning, saying that the model can solve a downstream task with prompts if and only if the task is representable. The second one says fine tuning does not have this limit, as a foundation model with the minimum power (up to symmetry) can theoretically solve downstream tasks with fine tuning and enough resources. Our final result can be seen as a new type of generalization theorem, showing that the foundation model can generate unseen objects from the target category (e.g., images) using the structural information from the source category (e.g., texts). Along the way, we provide a categorical framework for supervised and self-supervised learning, which might be of independent interest.