 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heterogenous Ensemble of Models for Molecular Property Prediction
Nov 20, 2022
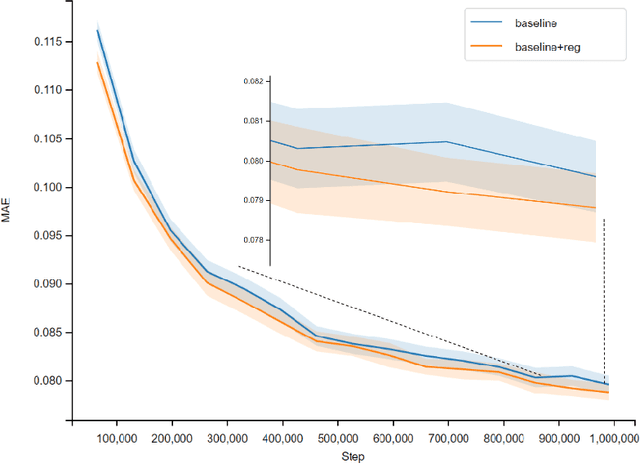
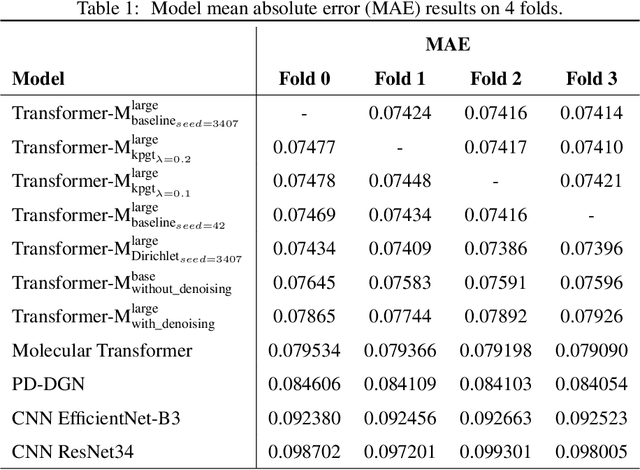
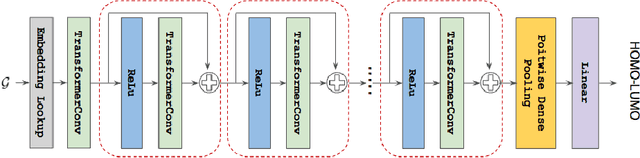
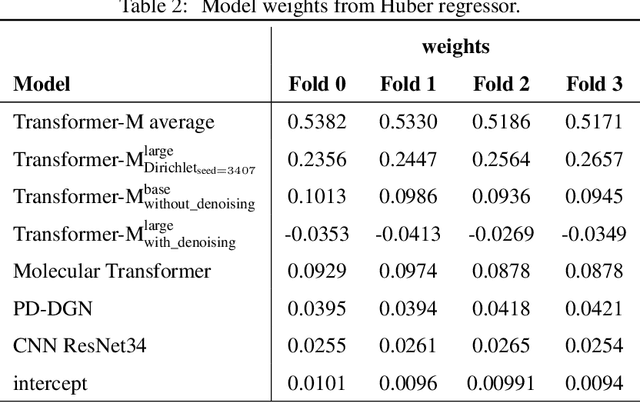
Previous works have demonstrated the importance of considering different modalities on molecules, each of which provide a varied granularity of information for downstream property prediction tasks. Our method combines variants of the recent TransformerM architecture with Transformer, GNN, and ResNet backbone architectures. Models are trained on the 2D data, 3D data, and image modalities of molecular graphs. We ensemble these models with a HuberRegressor. The models are trained on 4 different train/validation splits of the original train + valid datasets. This yields a winning solution to the 2\textsuperscript{nd} edition of the OGB Large-Scale Challenge (2022) on the PCQM4Mv2 molecular property prediction dataset. Our proposed method achieves a test-challenge MAE of $0.0723$ and a validation MAE of $0.07145$. Total inference time for our solution is less than 2 hours. We open-source our code at https://github.com/jfpuget/NVIDIA-PCQM4Mv2.
MMGA: Multimodal Learning with Graph Alignment
Oct 18, 2022Multimodal pre-training breaks down the modality barriers and allows the individual modalities to be mutually augmented with information, resulting in significant advances in representation learning. However, graph modality, as a very general and important form of data, cannot be easily interacted with other modalities because of its non-regular nature. In this paper, we propose MMGA (Multimodal learning with Graph Alignment), a novel multimodal pre-training framework to incorporate information from graph (social network), image and text modalities on social media to enhance user representation learning. In MMGA, a multi-step graph alignment mechanism is proposed to add the self-supervision from graph modality to optimize the image and text encoders, while using the information from the image and text modalities to guide the graph encoder learning. We conduct experiments on the dataset crawled from Instagram. The experimental results show that MMGA works well on the dataset and improves the fans prediction task's performance. We release our dataset, the first social media multimodal dataset with graph, of 60,000 users labeled with specific topics based on 2 million posts to facilitate future research.
Unified Multi-View Orthonormal Non-Negative Graph Based Clustering Framework
Nov 03, 2022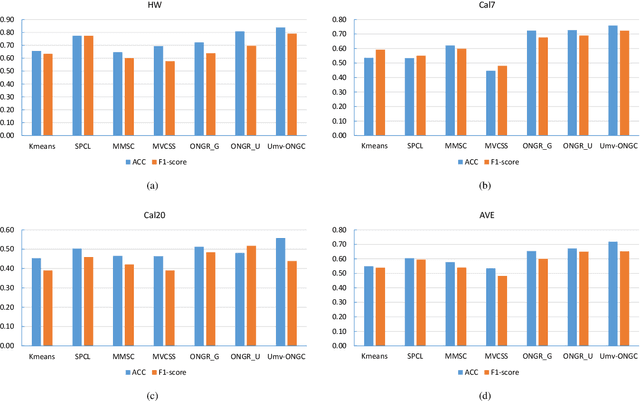
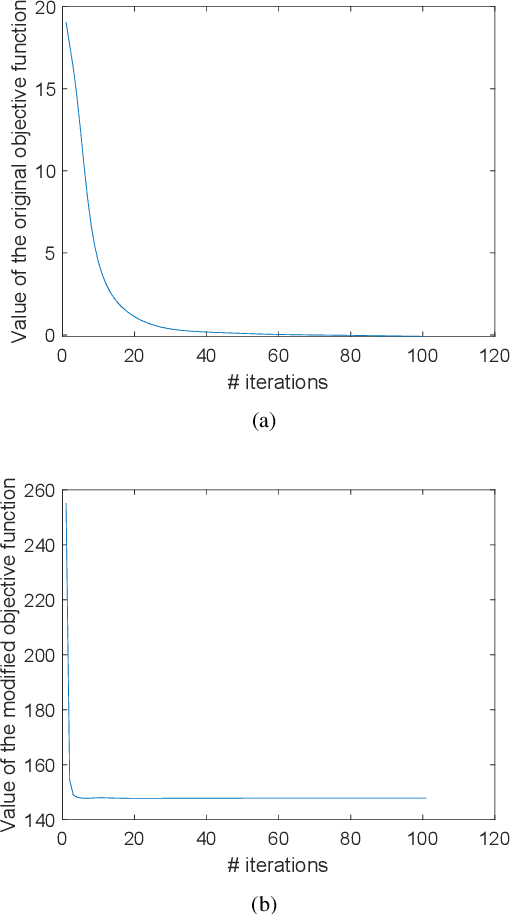
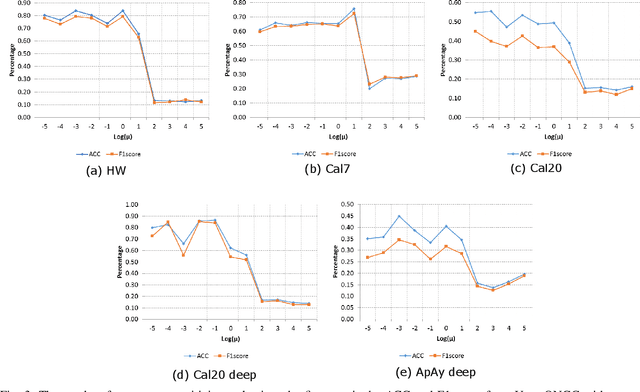
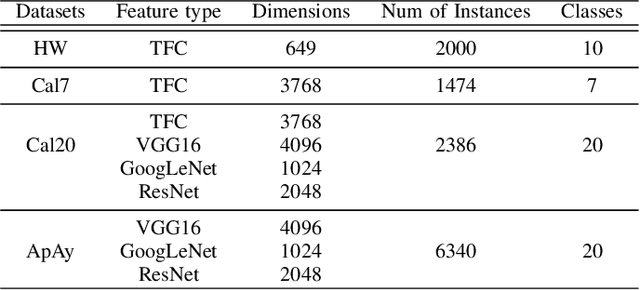
Spectral clustering is an effective methodology for unsupervised learning. Most traditional spectral clustering algorithms involve a separate two-step procedure and apply the transformed new representations for the final clustering results. Recently, much progress has been made to utilize the non-negative feature property in real-world data and to jointly learn the representation and clustering results. However, to our knowledge, no previous work considers a unified model that incorporates the important multi-view information with those properties, which severely limits the performance of existing methods. In this paper, we formulate a novel clustering model, which exploits the non-negative feature property and, more importantly, incorporates the multi-view information into a unified joint learning framework: the unified multi-view orthonormal non-negative graph based clustering framework (Umv-ONGC). Then, we derive an effective three-stage iterative solution for the proposed model and provide analytic solutions for the three sub-problems from the three stages. We also explore, for the first time, the multi-model non-negative graph-based approach to clustering data based on deep features. Extensive experiments on three benchmark data sets demonstrate the effectiveness of the proposed method.
Imitation Learning-based Implicit Semantic-aware Communication Networks: Multi-layer Representation and Collaborative Reasoning
Oct 28, 2022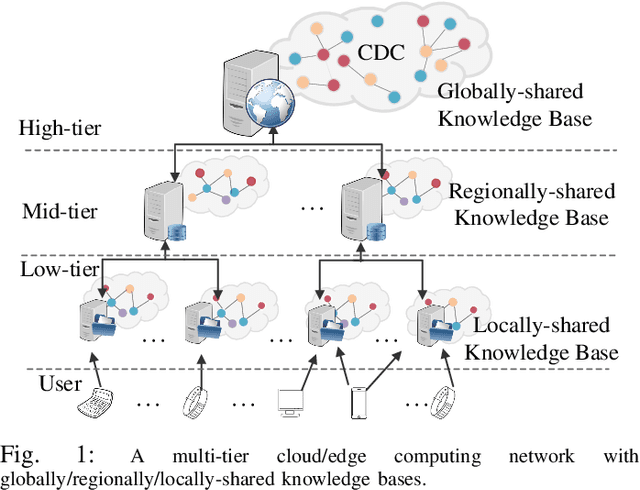
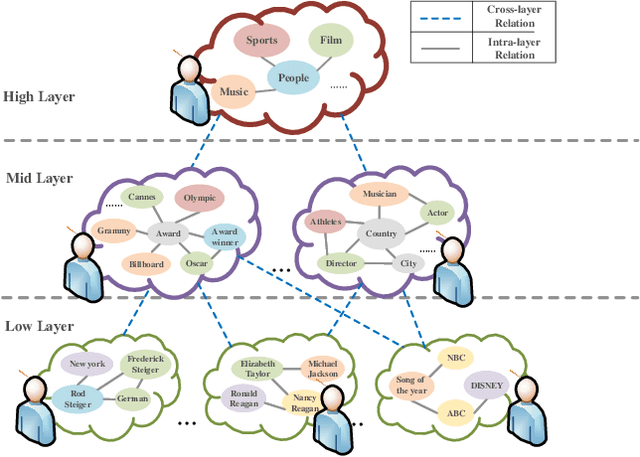
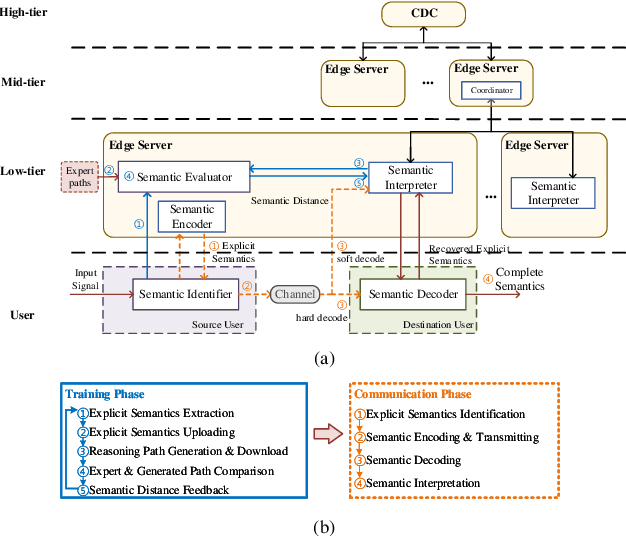

Semantic communication has recently attracted significant interest from both industry and academia due to its potential to transform the existing data-focused communication architecture towards a more generally intelligent and goal-oriented semantic-aware networking system. Despite its promising potential, semantic communications and semantic-aware networking are still at their infancy. Most existing works focus on transporting and delivering the explicit semantic information, e.g., labels or features of objects, that can be directly identified from the source signal. The original definition of semantics as well as recent results in cognitive neuroscience suggest that it is the implicit semantic information, in particular the hidden relations connecting different concepts and feature items that plays the fundamental role in recognizing, communicating, and delivering the real semantic meanings of messages. Motivated by this observation, we propose a novel reasoning-based implicit semantic-aware communication network architecture that allows multiple tiers of CDC and edge servers to collaborate and support efficient semantic encoding, decoding, and interpretation for end-users. We introduce a new multi-layer representation of semantic information taking into consideration both the hierarchical structure of implicit semantics as well as the personalized inference preference of individual users. We model the semantic reasoning process as a reinforcement learning process and then propose an imitation-based semantic reasoning mechanism learning (iRML) solution for the edge servers to leaning a reasoning policy that imitates the inference behavior of the source user. A federated GCN-based collaborative reasoning solution is proposed to allow multiple edge servers to jointly construct a shared semantic interpretation model based on decentralized knowledge datasets.
Sketching for First Order Method: Efficient Algorithm for Low-Bandwidth Channel and Vulnerability
Oct 15, 2022
Sketching is one of the most fundamental tools in large-scale machine learning. It enables runtime and memory saving via randomly compressing the original large problem onto lower dimensions. In this paper, we propose a novel sketching scheme for the first order method in large-scale distributed learning setting, such that the communication costs between distributed agents are saved while the convergence of the algorithms is still guaranteed. Given gradient information in a high dimension $d$, the agent passes the compressed information processed by a sketching matrix $R\in \R^{s\times d}$ with $s\ll d$, and the receiver de-compressed via the de-sketching matrix $R^\top$ to ``recover'' the information in original dimension. Using such a framework, we develop algorithms for federated learning with lower communication costs. However, such random sketching does not protect the privacy of local data directly. We show that the gradient leakage problem still exists after applying the sketching technique by showing a specific gradient attack method. As a remedy, we prove rigorously that the algorithm will be differentially private by adding additional random noises in gradient information, which results in a both communication-efficient and differentially private first order approach for federated learning tasks. Our sketching scheme can be further generalized to other learning settings and might be of independent interest itself.
Towards Mitigating the Problem of Insufficient and Ambiguous Supervision in Online Crowdsourcing Annotation
Oct 20, 2022
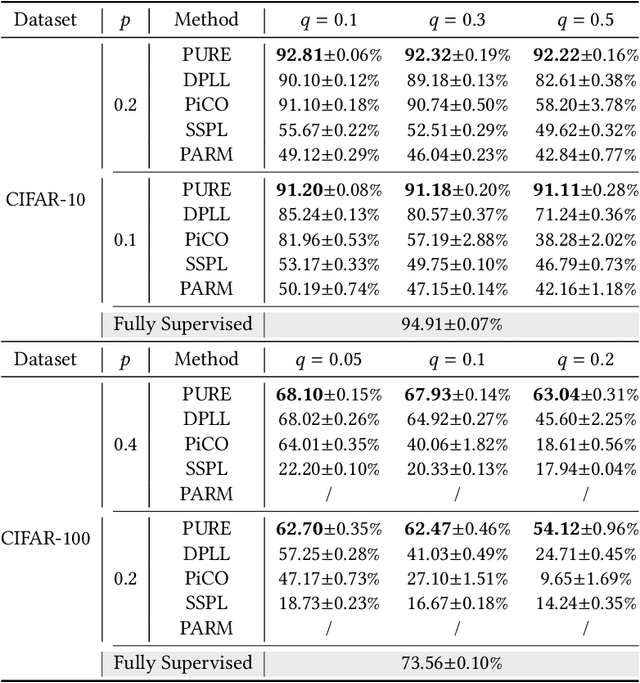

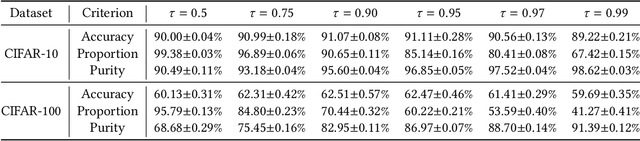
In real-world crowdsourcing annotation systems, due to differences in user knowledge and cultural backgrounds, as well as the high cost of acquiring annotation information, the supervision information we obtain might be insufficient and ambiguous. To mitigate the negative impacts, in this paper, we investigate a more general and broadly applicable learning problem, i.e. \emph{semi-supervised partial label learning}, and propose a novel method based on pseudo-labeling and contrastive learning. Following the key inventing principle, our method facilitate the partial label disambiguation process with unlabeled data and at the same time assign reliable pseudo-labels to weakly supervised examples. Specifically, our method learns from the ambiguous labeling information via partial cross-entropy loss. Meanwhile, high-accuracy pseudo-labels are generated for both partial and unlabeled examples through confidence-based thresholding and contrastive learning is performed in a hybrid unsupervised and supervised manner for more discriminative representations, while its supervision increases curriculumly. The two main components systematically work as a whole and reciprocate each other. In experiments, our method consistently outperforms all comparing methods by a significant margin and set up the first state-of-the-art performance for semi-supervised partial label learning on image benchmarks.
Toward Knowledge-Driven Speech-Based Models of Depression: Leveraging Spectrotemporal Variations in Speech Vowels
Oct 05, 2022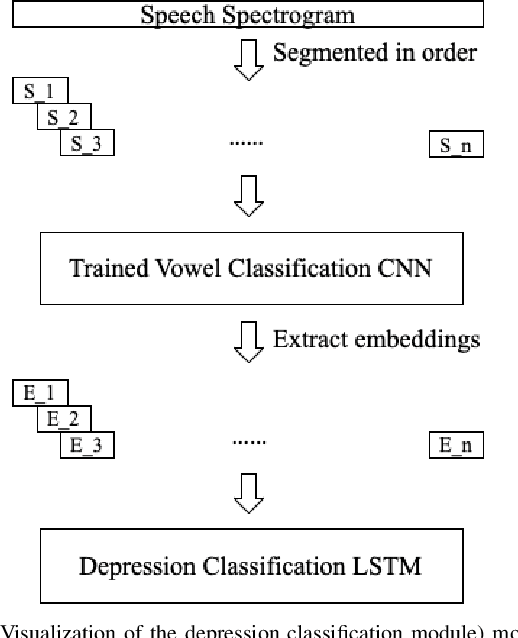
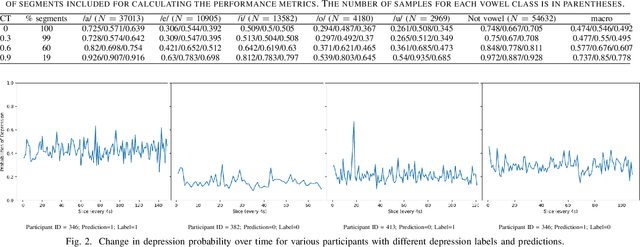


Psychomotor retardation associated with depression has been linked with tangible differences in vowel production. This paper investigates a knowledge-driven machine learning (ML) method that integrates spectrotemporal information of speech at the vowel-level to identify the depression. Low-level speech descriptors are learned by a convolutional neural network (CNN) that is trained for vowel classification. The temporal evolution of those low-level descriptors is modeled at the high-level within and across utterances via a long short-term memory (LSTM) model that takes the final depression decision. A modified version of the Local Interpretable Model-agnostic Explanations (LIME) is further used to identify the impact of the low-level spectrotemporal vowel variation on the decisions and observe the high-level temporal change of the depression likelihood. The proposed method outperforms baselines that model the spectrotemporal information in speech without integrating the vowel-based information, as well as ML models trained with conventional prosodic and spectrotemporal features. The conducted explainability analysis indicates that spectrotemporal information corresponding to non-vowel segments less important than the vowel-based information. Explainability of the high-level information capturing the segment-by-segment decisions is further inspected for participants with and without depression. The findings from this work can provide the foundation toward knowledge-driven interpretable decision-support systems that can assist clinicians to better understand fine-grain temporal changes in speech data, ultimately augmenting mental health diagnosis and care.
IntegratedPIFu: Integrated Pixel Aligned Implicit Function for Single-view Human Reconstruction
Nov 15, 2022We propose IntegratedPIFu, a new pixel aligned implicit model that builds on the foundation set by PIFuHD. IntegratedPIFu shows how depth and human parsing information can be predicted and capitalised upon in a pixel-aligned implicit model. In addition, IntegratedPIFu introduces depth oriented sampling, a novel training scheme that improve any pixel aligned implicit model ability to reconstruct important human features without noisy artefacts. Lastly, IntegratedPIFu presents a new architecture that, despite using less model parameters than PIFuHD, is able to improves the structural correctness of reconstructed meshes. Our results show that IntegratedPIFu significantly outperforms existing state of the arts methods on single view human reconstruction. Our code has been made available online.
CrossPyramid: Neural Ordinary Differential Equations Architecture for Partially-observed Time-series
Dec 07, 2022
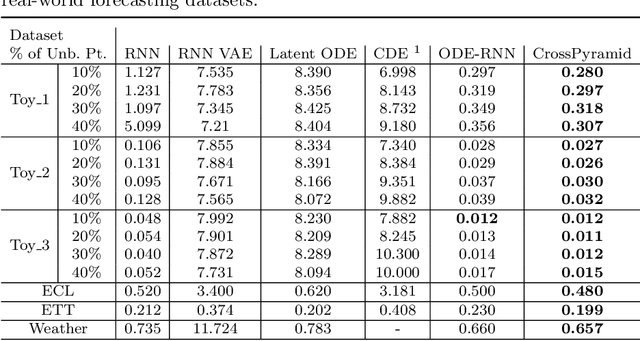
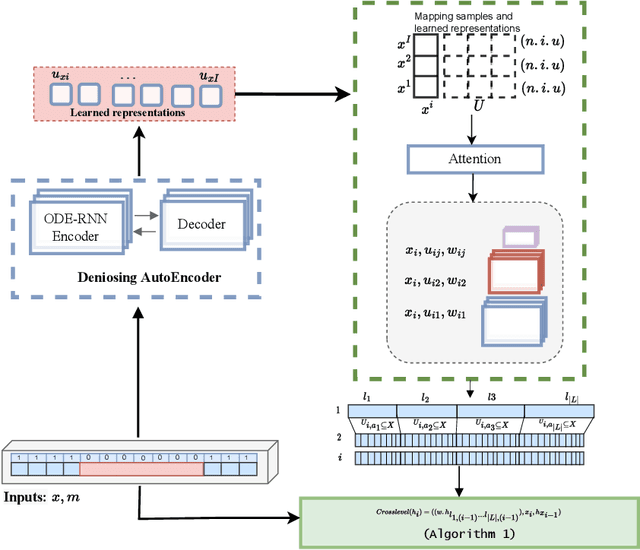
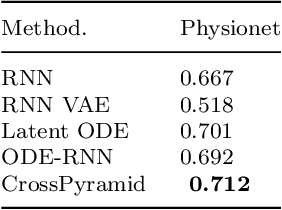
Ordinary Differential Equations (ODE)-based models have become popular foundation models to solve many time-series problems. Combining neural ODEs with traditional RNN models has provided the best representation for irregular time series. However, ODE-based models require the trajectory of hidden states to be defined based on the initial observed value or the last available observation. This fact raises questions about how long the generated hidden state is sufficient and whether it is effective when long sequences are used instead of the typically used shorter sequences. In this article, we introduce CrossPyramid, a novel ODE-based model that aims to enhance the generalizability of sequences representation. CrossPyramid does not rely only on the hidden state from the last observed value; it also considers ODE latent representations learned from other samples. The main idea of our proposed model is to define the hidden state for the unobserved values based on the non-linear correlation between samples. Accordingly, CrossPyramid is built with three distinctive parts: (1) ODE Auto-Encoder to learn the best data representation. (2) Pyramidal attention method to categorize the learned representations (hidden state) based on the relationship characteristics between samples. (3) Cross-level ODE-RNN to integrate the previously learned information and provide the final latent state for each sample. Through extensive experiments on partially-observed synthetic and real-world datasets, we show that the proposed architecture can effectively model the long gaps in intermittent series and outperforms state-of-the-art approaches. The results show an average improvement of 10\% on univariate and multivariate datasets for both forecasting and classification tasks.
Towards Explainable Motion Prediction using Heterogeneous Graph Representations
Dec 07, 2022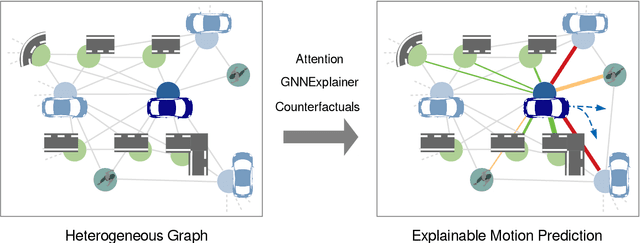
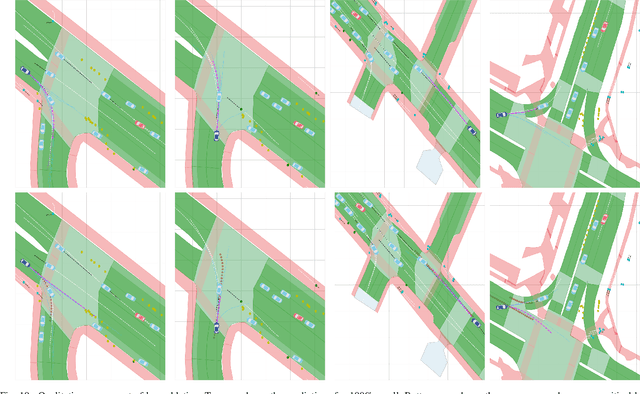
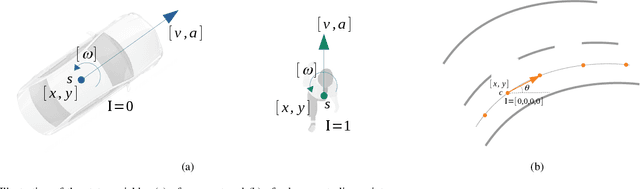
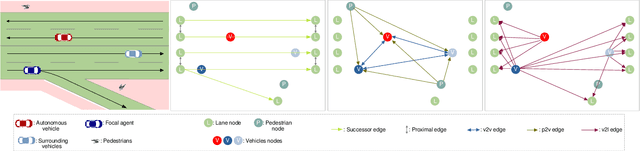
Motion prediction systems aim to capture the future behavior of traffic scenarios enabling autonomous vehicles to perform safe and efficient planning. The evolution of these scenarios is highly uncertain and depends on the interactions of agents with static and dynamic objects in the scene. GNN-based approaches have recently gained attention as they are well suited to naturally model these interactions. However, one of the main challenges that remains unexplored is how to address the complexity and opacity of these models in order to deal with the transparency requirements for autonomous driving systems, which includes aspects such as interpretability and explainability. In this work, we aim to improve the explainability of motion prediction systems by using different approaches. First, we propose a new Explainable Heterogeneous Graph-based Policy (XHGP) model based on an heterograph representation of the traffic scene and lane-graph traversals, which learns interaction behaviors using object-level and type-level attention. This learned attention provides information about the most important agents and interactions in the scene. Second, we explore this same idea with the explanations provided by GNNExplainer. Third, we apply counterfactual reasoning to provide explanations of selected individual scenarios by exploring the sensitivity of the trained model to changes made to the input data, i.e., masking some elements of the scene, modifying trajectories, and adding or removing dynamic agents. The explainability analysis provided in this paper is a first step towards more transparent and reliable motion prediction systems, important from the perspective of the user, developers and regulatory agencies. The code to reproduce this work is publicly available at https://github.com/sancarlim/Explainable-MP/tree/v1.1.