 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022
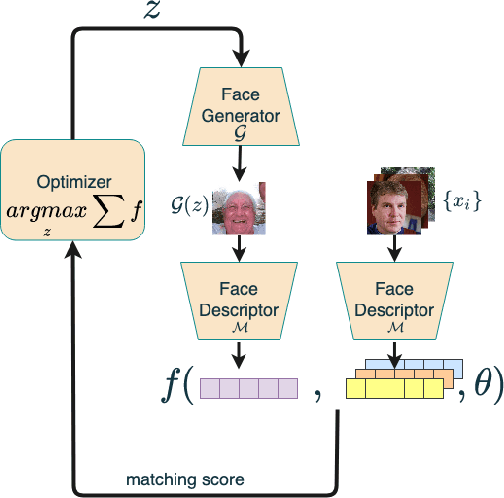
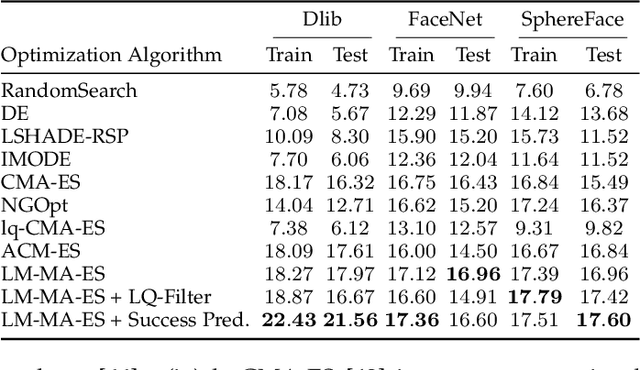
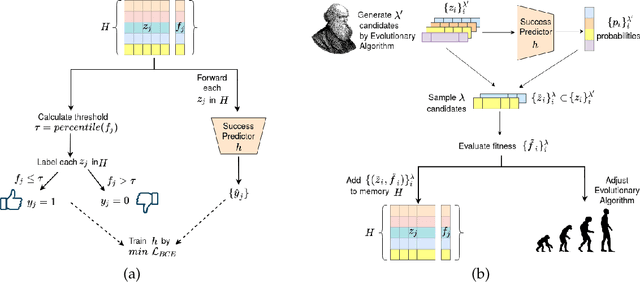
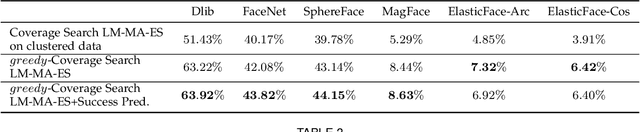
A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
Long-tail Cross Modal Hashing
Nov 28, 2022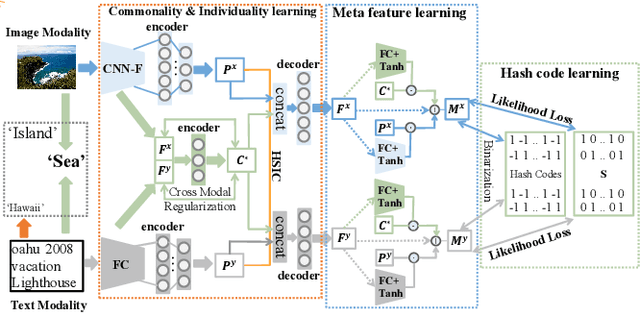

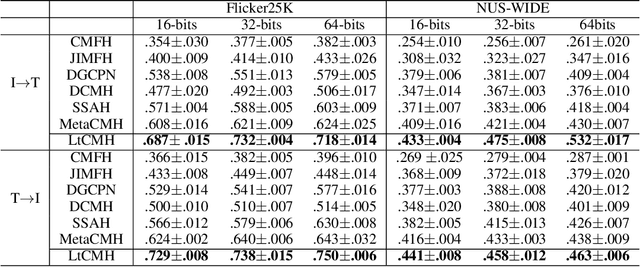
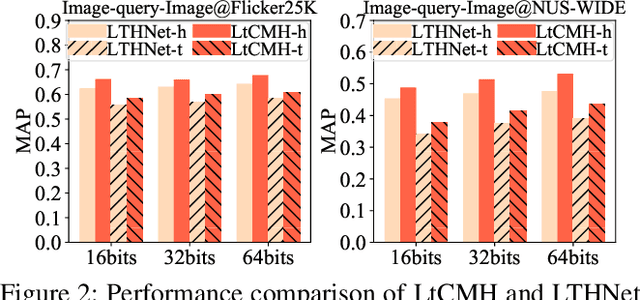
Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
SLAN: Self-Locator Aided Network for Cross-Modal Understanding
Nov 28, 2022
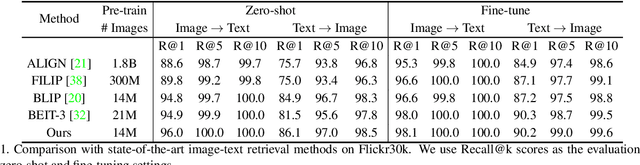
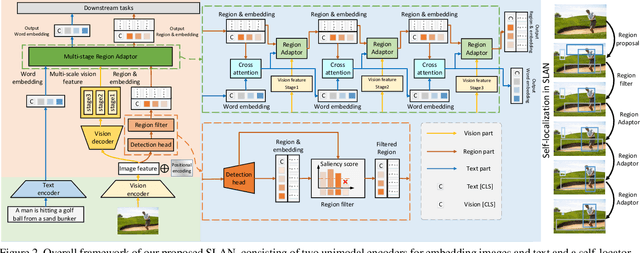
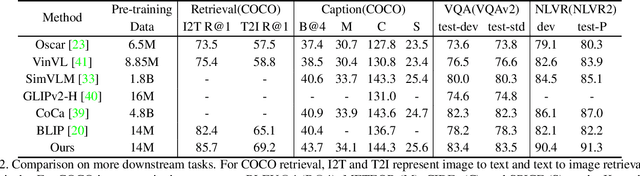
Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.
Open-vocabulary Attribute Detection
Nov 23, 2022
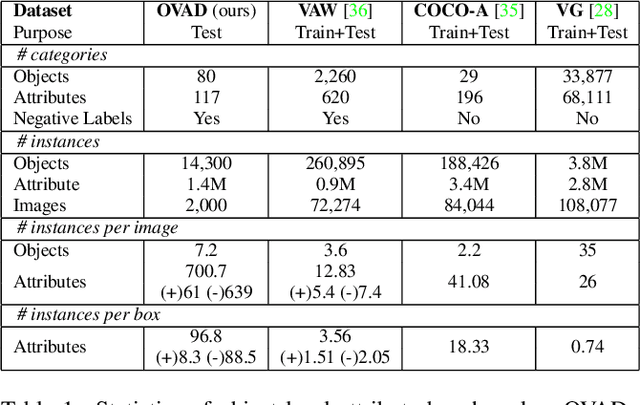

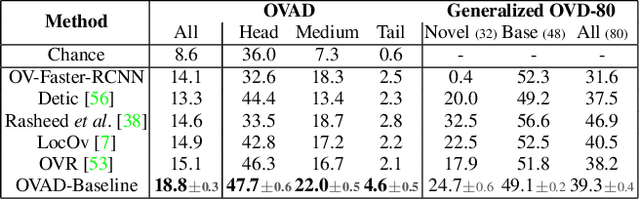
Vision-language modeling has enabled open-vocabulary tasks where predictions can be queried using any text prompt in a zero-shot manner. Existing open-vocabulary tasks focus on object classes, whereas research on object attributes is limited due to the lack of a reliable attribute-focused evaluation benchmark. This paper introduces the Open-Vocabulary Attribute Detection (OVAD) task and the corresponding OVAD benchmark. The objective of the novel task and benchmark is to probe object-level attribute information learned by vision-language models. To this end, we created a clean and densely annotated test set covering 117 attribute classes on the 80 object classes of MS COCO. It includes positive and negative annotations, which enables open-vocabulary evaluation. Overall, the benchmark consists of 1.4 million annotations. For reference, we provide a first baseline method for open-vocabulary attribute detection. Moreover, we demonstrate the benchmark's value by studying the attribute detection performance of several foundation models. Project page https://ovad-benchmark.github.io/
Completing point cloud from few points by Wasserstein GAN and Transformers
Nov 23, 2022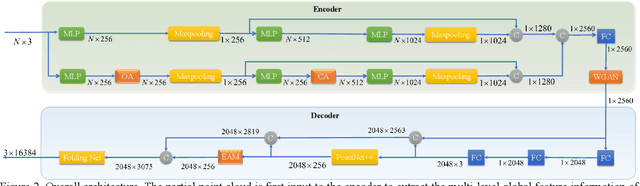
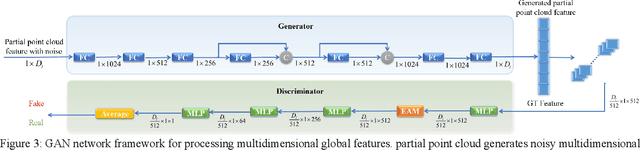
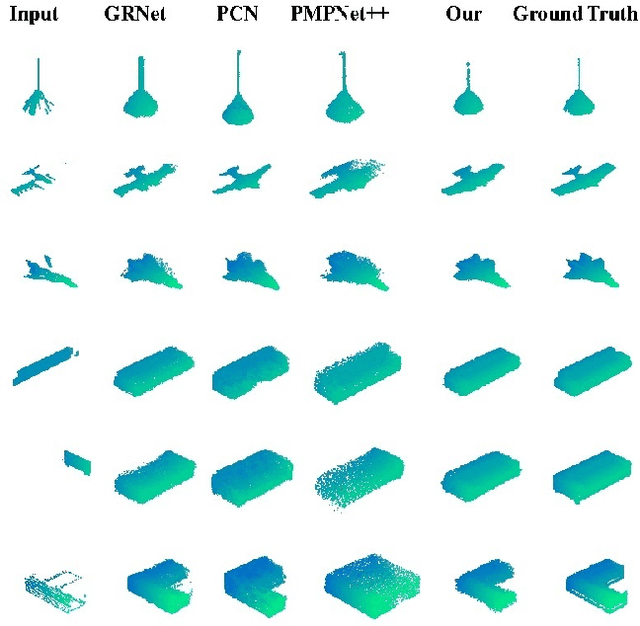
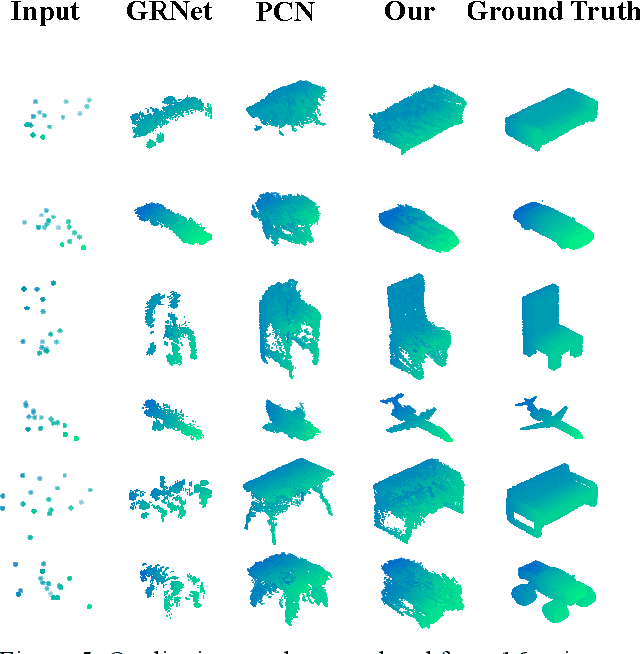
In many vision and robotics applications, it is common that the captured objects are represented by very few points. Most of the existing completion methods are designed for partial point clouds with many points, and they perform poorly or even fail completely in the case of few points. However, due to the lack of detail information, completing objects from few points faces a huge challenge. Inspired by the successful applications of GAN and Transformers in the image-based vision task, we introduce GAN and Transformer techniques to address the above problem. Firstly, the end-to-end encoder-decoder network with Transformers and the Wasserstein GAN with Transformer are pre-trained, and then the overall network is fine-tuned. Experimental results on the ShapeNet dataset show that our method can not only improve the completion performance for many input points, but also keep stable for few input points. Our source code is available at https://github.com/WxfQjh/Stability-point-recovery.git.
Data-driven Feature Tracking for Event Cameras
Nov 23, 2022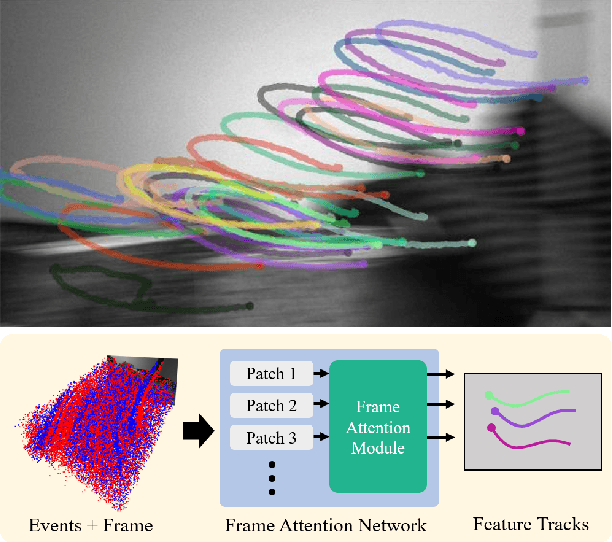
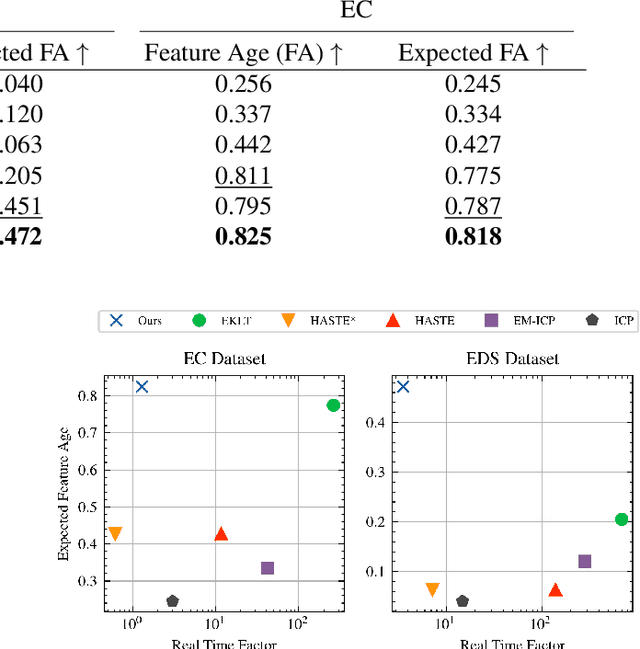
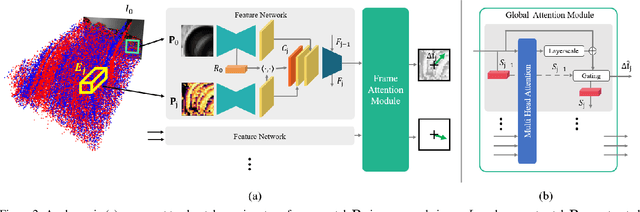
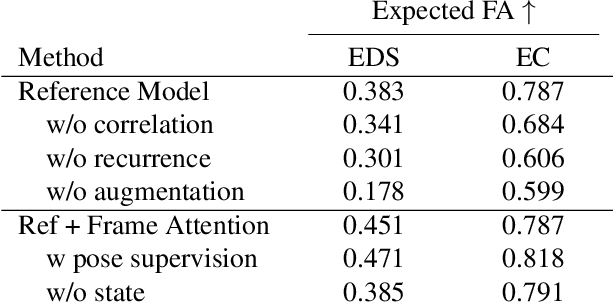
Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
Mitigating Data Sparsity for Short Text Topic Modeling by Topic-Semantic Contrastive Learning
Nov 23, 2022
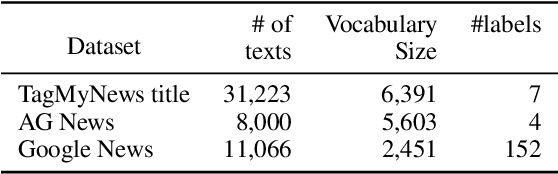
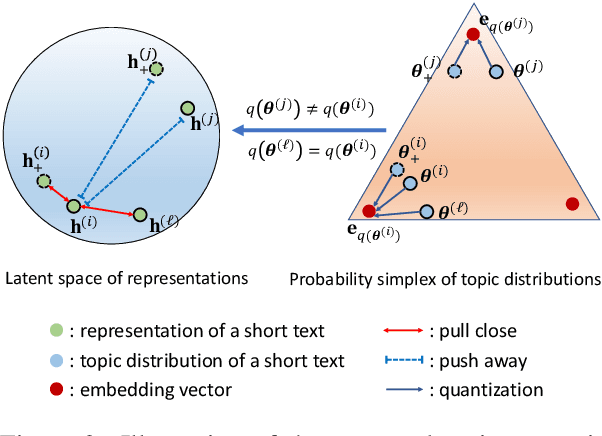
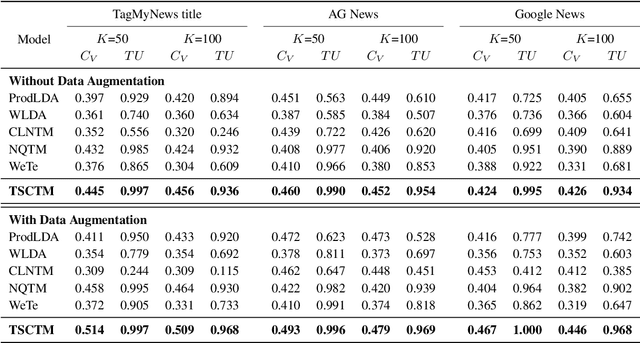
To overcome the data sparsity issue in short text topic modeling, existing methods commonly rely on data augmentation or the data characteristic of short texts to introduce more word co-occurrence information. However, most of them do not make full use of the augmented data or the data characteristic: they insufficiently learn the relations among samples in data, leading to dissimilar topic distributions of semantically similar text pairs. To better address data sparsity, in this paper we propose a novel short text topic modeling framework, Topic-Semantic Contrastive Topic Model (TSCTM). To sufficiently model the relations among samples, we employ a new contrastive learning method with efficient positive and negative sampling strategies based on topic semantics. This contrastive learning method refines the representations, enriches the learning signals, and thus mitigates the sparsity issue. Extensive experimental results show that our TSCTM outperforms state-of-the-art baselines regardless of the data augmentation availability, producing high-quality topics and topic distributions.
PANeRF: Pseudo-view Augmentation for Improved Neural Radiance Fields Based on Few-shot Inputs
Nov 23, 2022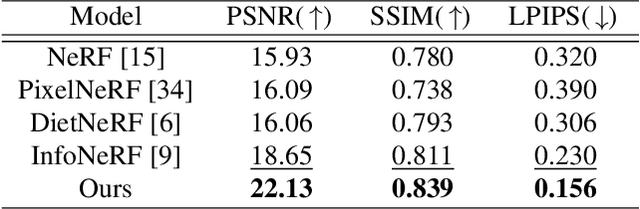
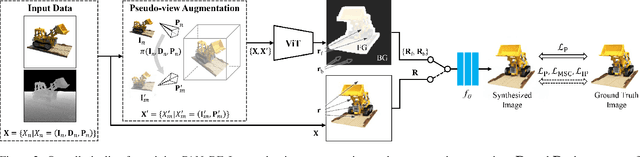

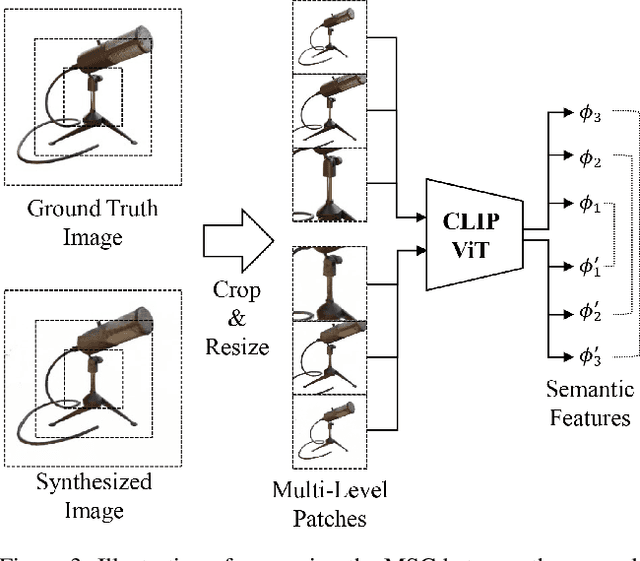
The method of neural radiance fields (NeRF) has been developed in recent years, and this technology has promising applications for synthesizing novel views of complex scenes. However, NeRF requires dense input views, typically numbering in the hundreds, for generating high-quality images. With a decrease in the number of input views, the rendering quality of NeRF for unseen viewpoints tends to degenerate drastically. To overcome this challenge, we propose pseudo-view augmentation of NeRF, a scheme that expands a sufficient amount of data by considering the geometry of few-shot inputs. We first initialized the NeRF network by leveraging the expanded pseudo-views, which efficiently minimizes uncertainty when rendering unseen views. Subsequently, we fine-tuned the network by utilizing sparse-view inputs containing precise geometry and color information. Through experiments under various settings, we verified that our model faithfully synthesizes novel-view images of superior quality and outperforms existing methods for multi-view datasets.
Hyperbolic Curvature Graph Neural Network
Dec 04, 2022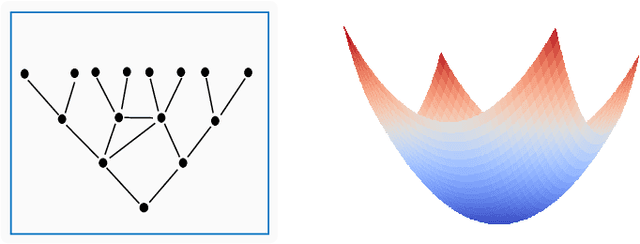
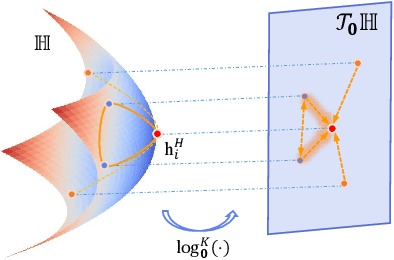
Hyperbolic space is emerging as a promising learning space for representation learning, owning to its exponential growth volume. Compared with the flat Euclidean space, the curved hyperbolic space is far more ambient and embeddable, particularly for datasets with implicit tree-like architectures, such as hierarchies and power-law distributions. On the other hand, the structure of a real-world network is usually intricate, with some regions being tree-like, some being flat, and others being circular. Directly embedding heterogeneous structural networks into a homogeneous embedding space unavoidably brings inductive biases and distortions. Inspiringly, the discrete curvature can well describe the local structure of a node and its surroundings, which motivates us to investigate the information conveyed by the network topology explicitly in improving geometric learning. To this end, we explore the properties of the local discrete curvature of graph topology and the continuous global curvature of embedding space. Besides, a Hyperbolic Curvature-aware Graph Neural Network, HCGNN, is further proposed. In particular, HCGNN utilizes the discrete curvature to lead message passing of the surroundings and adaptively adjust the continuous curvature simultaneously. Extensive experiments on node classification and link prediction tasks show that the proposed method outperforms various competitive models by a large margin in both high and low hyperbolic graph data. Case studies further illustrate the efficacy of discrete curvature in finding local clusters and alleviating the distortion caused by hyperbolic geometry.
High-Resolution Channel Sounding and Parameter Estimation in Multi-Site Cellular Networks
Nov 17, 2022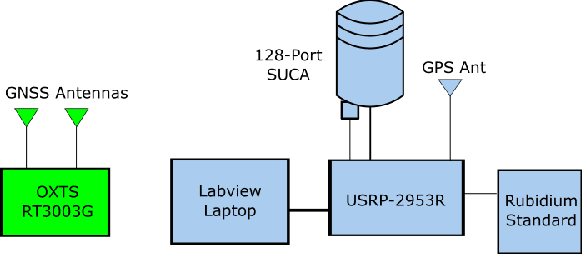

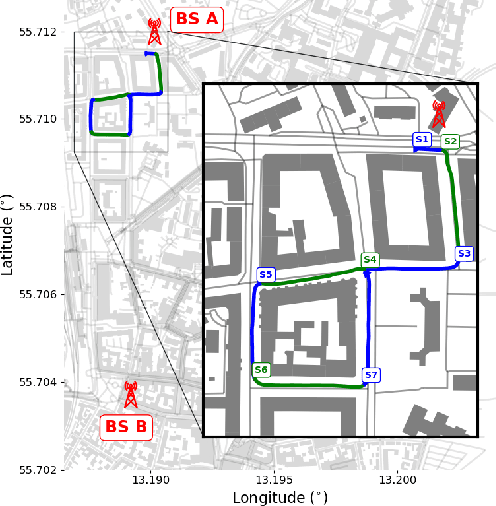
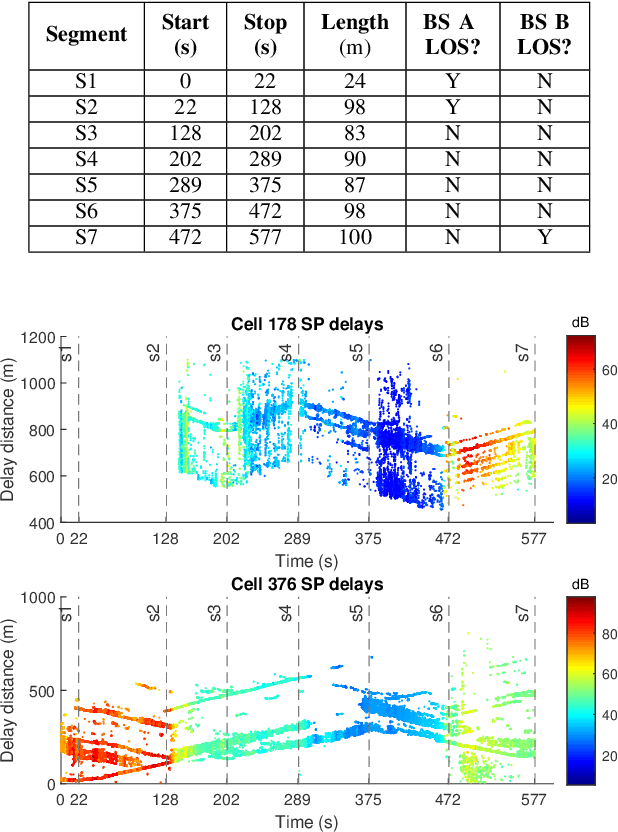
Accurate understanding of electromagnetic propagation properties in real environments is necessary for efficient design and deployment of cellular systems. In this paper, we show a method to estimate high-resolution channel parameters with a massive antenna array in real network deployments. An antenna array mounted on a vehicle is used to receive downlink long-term evolution (LTE) reference signals from neighboring base stations (BS) with mutual interference. Delay and angular information of multipath components is estimated with a novel inter-cell interference cancellation algorithm and an extension of the RIMAX algorithm. The estimated high-resolution channel parameters are consistent with the movement pattern of the vehicle and the geometry of the environment and allow for refined channel modeling and precise cellular positioning.