 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proprioceptive Sensing of Soft Tentacles with Model Based Reconstruction for Controller Optimization
Nov 24, 2022
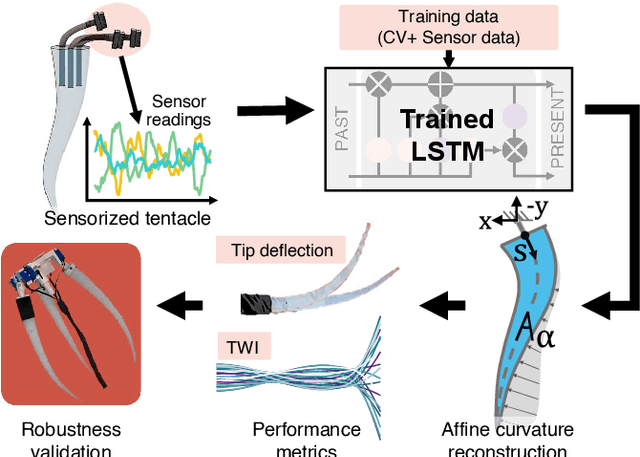
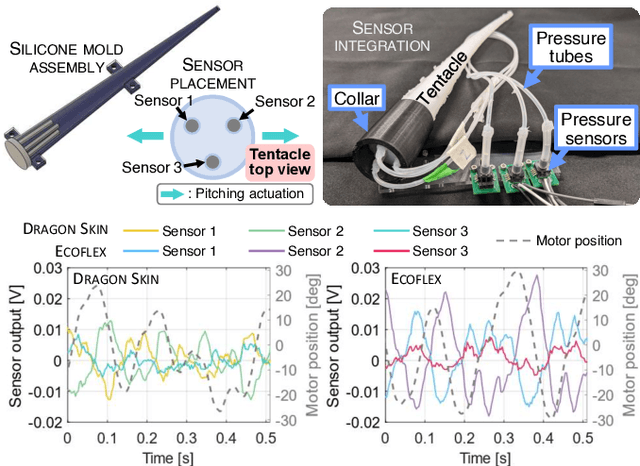
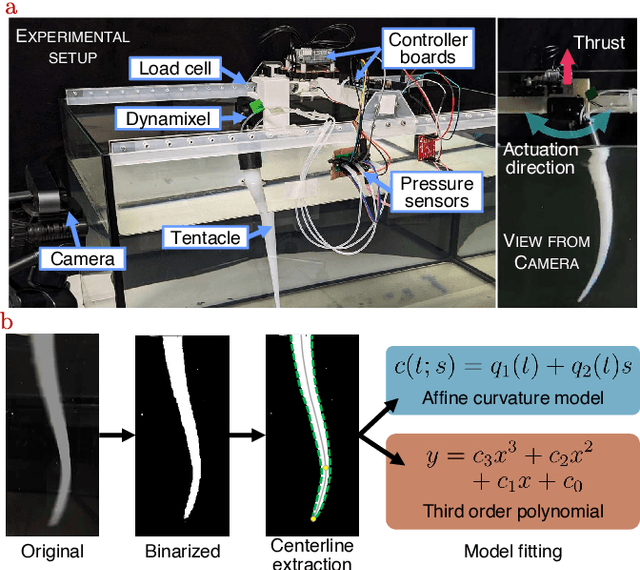
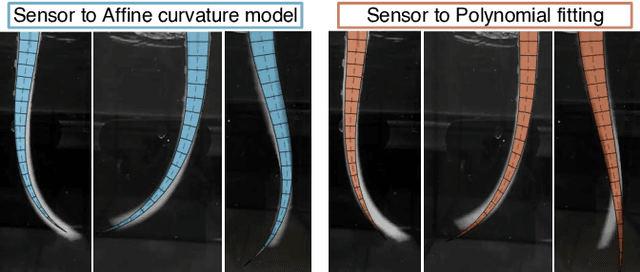
The success of soft robots in displaying emergent behaviors is tightly linked to the compliant interaction with the environment. However, to exploit such phenomena, proprioceptive sensing methods which do not hinder their softness are needed. In this work we propose a new sensing approach for soft underwater slender structures based on embedded pressure sensors and use a learning-based pipeline to link the sensor readings to the shape of the soft structure. Using two different modeling techniques, we compare the pose reconstruction accuracy and identify the optimal approach. Using the proprioceptive sensing capabilities we show how this information can be used to assess the swimming performance over a number of metrics, namely swimming thrust, tip deflection, and the traveling wave index. We conclude by demonstrating the robustness of the embedded sensor on a free swimming soft robotic squid swimming at a maximum velocity of 9.5 cm/s, with the absolute tip deflection being predicted within an error less than 9% without the aid of external sensors.
UMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022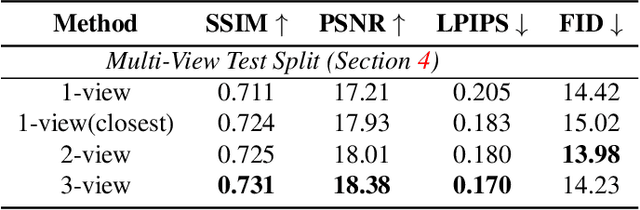
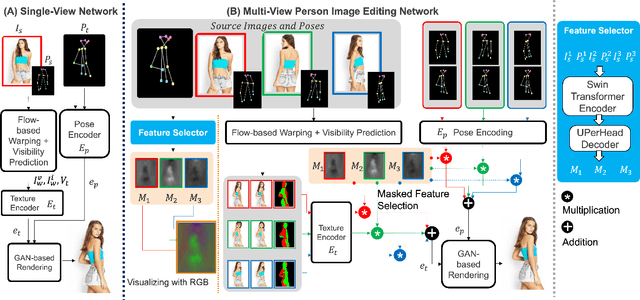
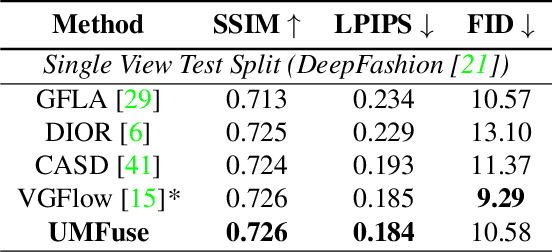
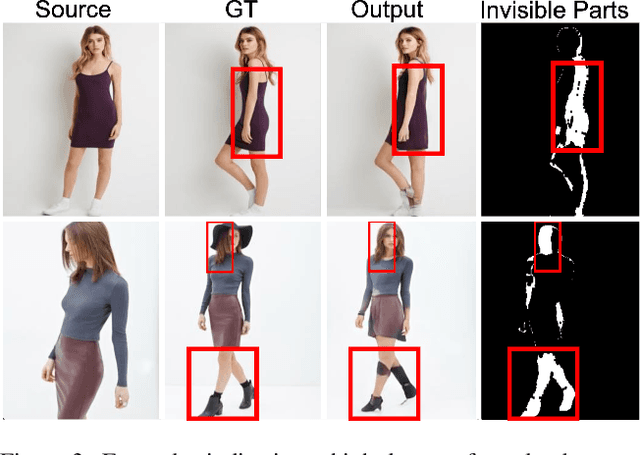
The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
A Topological Deep Learning Framework for Neural Spike Decoding
Dec 01, 2022
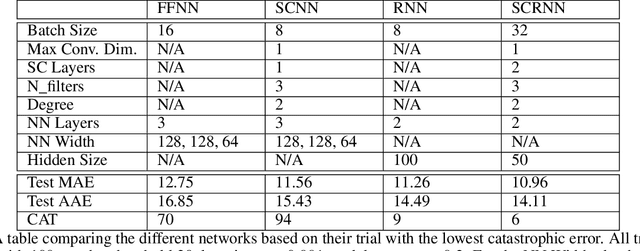
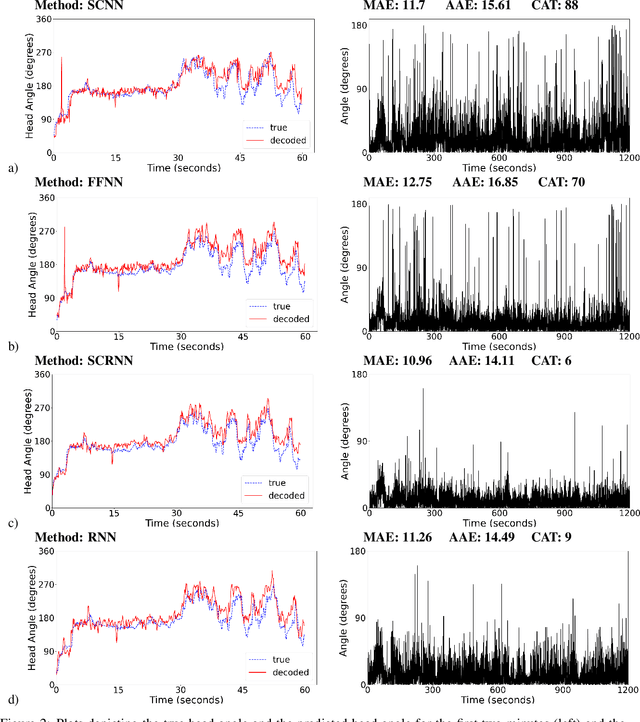
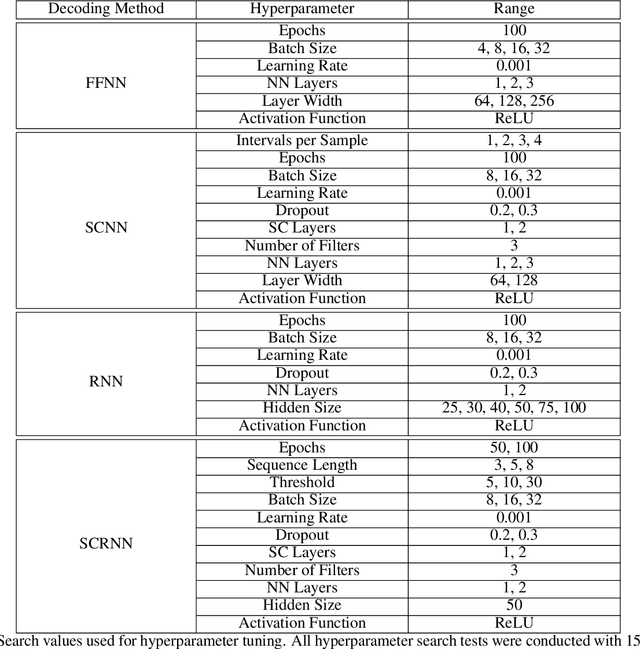
The brain's spatial orientation system uses different neuron ensembles to aid in environment-based navigation. One of the ways brains encode spatial information is through grid cells, layers of decked neurons that overlay to provide environment-based navigation. These neurons fire in ensembles where several neurons fire at once to activate a single grid. We want to capture this firing structure and use it to decode grid cell data. Understanding, representing, and decoding these neural structures require models that encompass higher order connectivity than traditional graph-based models may provide. To that end, in this work, we develop a topological deep learning framework for neural spike train decoding. Our framework combines unsupervised simplicial complex discovery with the power of deep learning via a new architecture we develop herein called a simplicial convolutional recurrent neural network (SCRNN). Simplicial complexes, topological spaces that use not only vertices and edges but also higher-dimensional objects, naturally generalize graphs and capture more than just pairwise relationships. Additionally, this approach does not require prior knowledge of the neural activity beyond spike counts, which removes the need for similarity measurements. The effectiveness and versatility of the SCRNN is demonstrated on head direction data to test its performance and then applied to grid cell datasets with the task to automatically predict trajectories.
Deep Kernel Learning for Mortality Prediction in the Face of Temporal Shift
Dec 01, 2022Neural models, with their ability to provide novel representations, have shown promising results in prediction tasks in healthcare. However, patient demographics, medical technology, and quality of care change over time. This often leads to drop in the performance of neural models for prospective patients, especially in terms of their calibration. The deep kernel learning (DKL) framework may be robust to such changes as it combines neural models with Gaussian processes, which are aware of prediction uncertainty. Our hypothesis is that out-of-distribution test points will result in probabilities closer to the global mean and hence prevent overconfident predictions. This in turn, we hypothesise, will result in better calibration on prospective data. This paper investigates DKL's behaviour when facing a temporal shift, which was naturally introduced when an information system that feeds a cohort database was changed. We compare DKL's performance to that of a neural baseline based on recurrent neural networks. We show that DKL indeed produced superior calibrated predictions. We also confirm that the DKL's predictions were indeed less sharp. In addition, DKL's discrimination ability was even improved: its AUC was 0.746 (+- 0.014 std), compared to 0.739 (+- 0.028 std) for the baseline. The paper demonstrated the importance of including uncertainty in neural computing, especially for their prospective use.
Slack-based tunable damping leads to a trade-off between robustness and efficiency in legged locomotion
Dec 01, 2022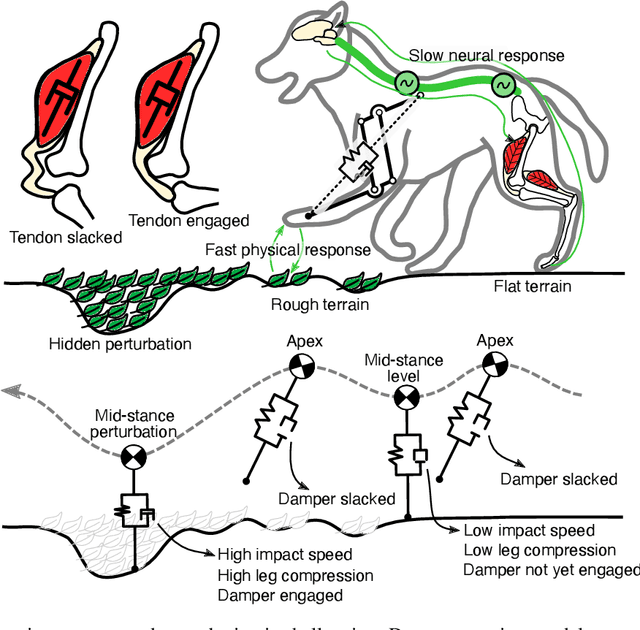
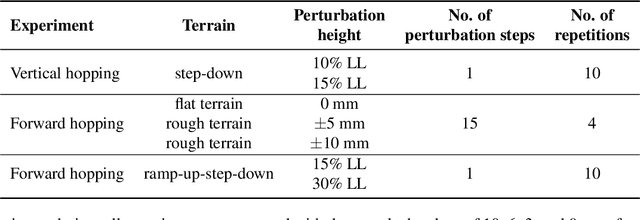
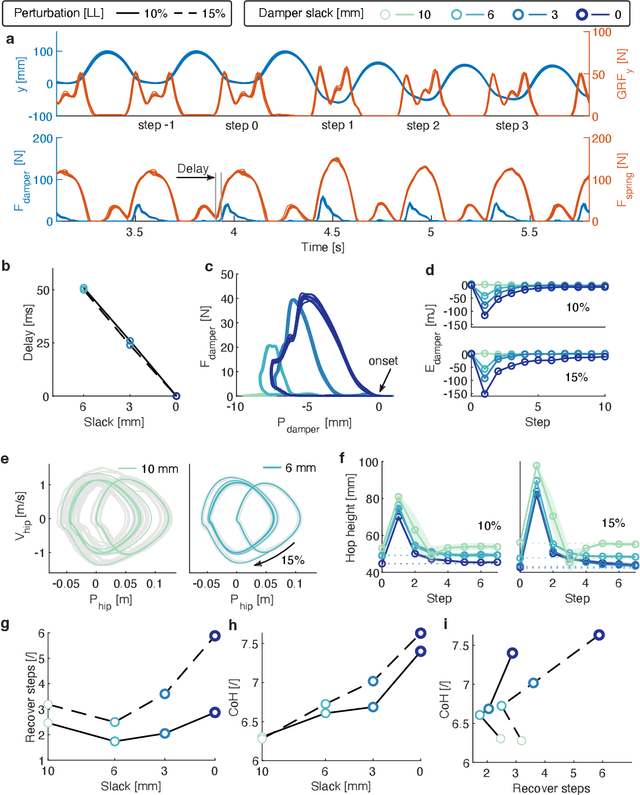
Animals run robustly in diverse terrain. This locomotion robustness is puzzling because axon conduction velocity is limited to a few ten meters per second. If reflex loops deliver sensory information with significant delays, one would expect a destabilizing effect on sensorimotor control. Hence, an alternative explanation describes a hierarchical structure of low-level adaptive mechanics and high-level sensorimotor control to help mitigate the effects of transmission delays. Motivated by the concept of an adaptive mechanism triggering an immediate response, we developed a tunable physical damper system. Our mechanism combines a tendon with adjustable slackness connected to a physical damper. The slack damper allows adjustment of damping force, onset timing, effective stroke, and energy dissipation. We characterize the slack damper mechanism mounted to a legged robot controlled in open-loop mode. The robot hops vertically and planar over varying terrains and perturbations. During forward hopping, slack-based damping improves faster perturbation recovery (up to 170%) at higher energetic cost (27%). The tunable slack mechanism auto-engages the damper during perturbations, leading to a perturbation-trigger damping, improving robustness at minimum energetic cost. With the results from the slack damper mechanism, we propose a new functional interpretation of animals' redundant muscle tendons as tunable dampers.
Joint Secure Transmit Beamforming Designs for Integrated Sensing and Communication Systems
Dec 01, 2022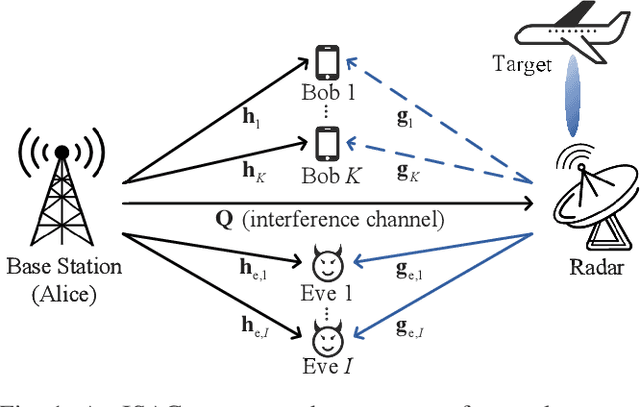
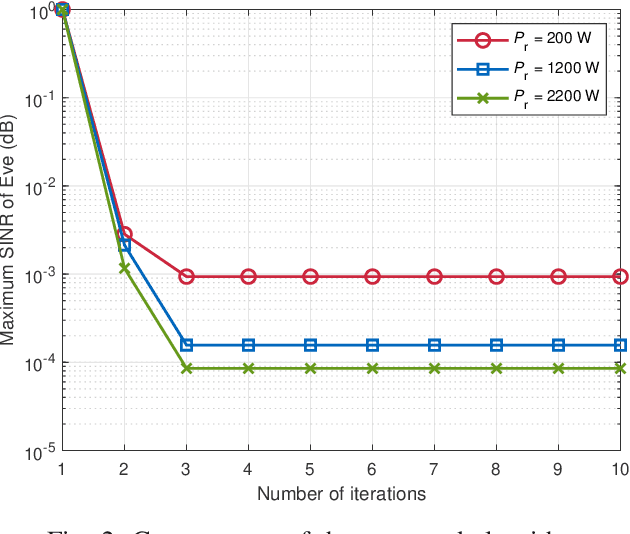
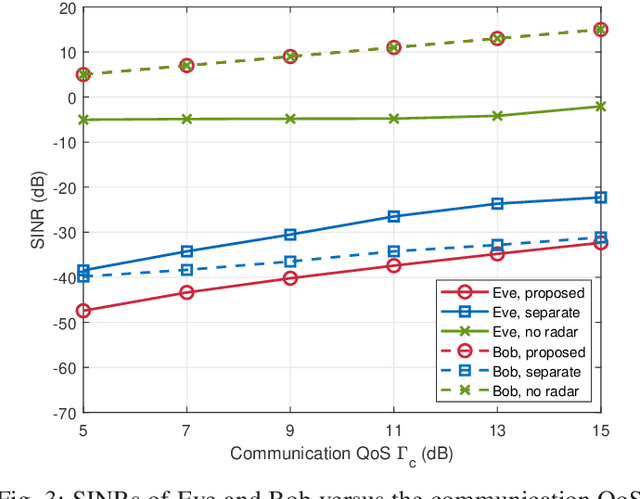
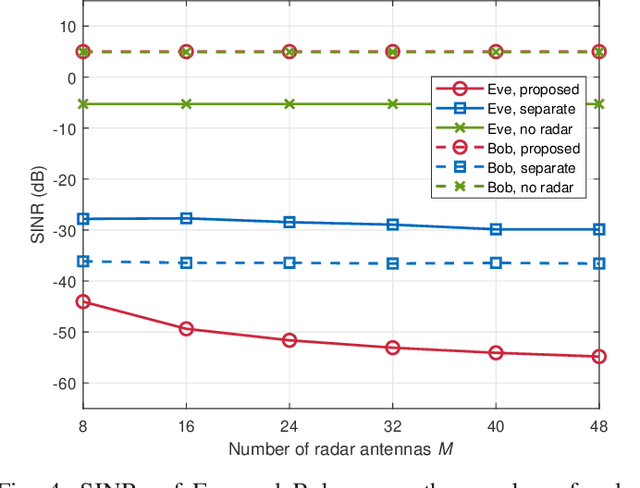
Integrated sensing and communication (ISAC), which allows individual radar and communication systems to share the same spectrum bands, is an emerging and promising technique for alleviating spectrum congestion problems. In this paper, we investigate how to exploit the inherent interference from strong radar signals to ensure the physical layer security (PLS) for the considered multi-user multi-input single-output (MU-MISO) communication and colocated multi-input multi-output (MIMO) radar coexistence system. In particular, with known eavesdroppers' channel state information (CSI), we propose to jointly design the transmit beamformers of communication and radar systems to minimize the maximum eavesdropping signal-to-interference-plus-noise ratio (SINR) on multiple legitimate users, while guaranteeing the communication quality-of-service (QoS) of legitimate transmissions, the requirement of radar detection performance, and the transmit power constraints of both radar and communication systems. When eavesdroppers' CSI is unavailable, we develop a joint artificial noise (AN)-aided transmit beamforming design scheme, which utilizes residual available power to generate AN for disrupting malicious receptions as well as satisfying the requirements of both legitimate transmissions and radar target detection. Extensive simulations verify the advantages of the proposed joint beamforming designs for ISAC systems on secure transmissions and the effectiveness of the developed algorithms.
Automatic Extraction of Materials and Properties from Superconductors Scientific Literature
Oct 26, 2022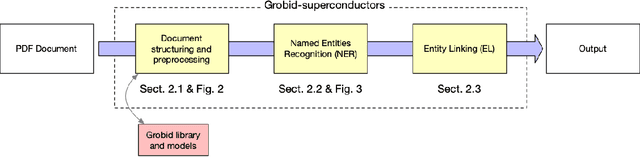
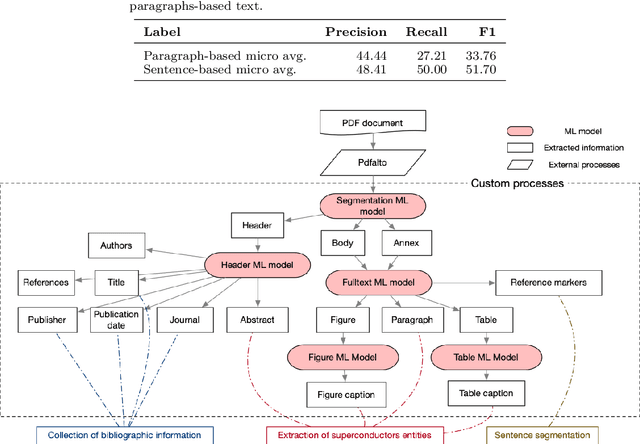


The automatic extraction of materials and related properties from the scientific literature is gaining attention in data-driven materials science (Materials Informatics). In this paper, we discuss Grobid-superconductors, our solution for automatically extracting superconductor material names and respective properties from text. Built as a Grobid module, it combines machine learning and heuristic approaches in a multi-step architecture that supports input data as raw text or PDF documents. Using Grobid-superconductors, we built SuperCon2, a database of 40324 materials and properties records from 37700 papers. The material (or sample) information is represented by name, chemical formula, and material class, and is characterized by shape, doping, substitution variables for components, and substrate as adjoined information. The properties include the Tc superconducting critical temperature and, when available, applied pressure with the Tc measurement method.
WebFormer: The Web-page Transformer for Structure Information Extraction
Feb 01, 2022



Structure information extraction refers to the task of extracting structured text fields from web pages, such as extracting a product offer from a shopping page including product title, description, brand and price. It is an important research topic which has been widely studied in document understanding and web search. Recent natural language models with sequence modeling have demonstrated state-of-the-art performance on web information extraction. However, effectively serializing tokens from unstructured web pages is challenging in practice due to a variety of web layout patterns. Limited work has focused on modeling the web layout for extracting the text fields. In this paper, we introduce WebFormer, a Web-page transFormer model for structure information extraction from web documents. First, we design HTML tokens for each DOM node in the HTML by embedding representations from their neighboring tokens through graph attention. Second, we construct rich attention patterns between HTML tokens and text tokens, which leverages the web layout for effective attention weight computation. We conduct an extensive set of experiments on SWDE and Common Crawl benchmarks. Experimental results demonstrate the superior performance of the proposed approach over several state-of-the-art methods.
Time-rEversed diffusioN tEnsor Transformer: A new TENET of Few-Shot Object Detection
Oct 30, 2022In this paper, we tackle the challenging problem of Few-shot Object Detection. Existing FSOD pipelines (i) use average-pooled representations that result in information loss; and/or (ii) discard position information that can help detect object instances. Consequently, such pipelines are sensitive to large intra-class appearance and geometric variations between support and query images. To address these drawbacks, we propose a Time-rEversed diffusioN tEnsor Transformer (TENET), which i) forms high-order tensor representations that capture multi-way feature occurrences that are highly discriminative, and ii) uses a transformer that dynamically extracts correlations between the query image and the entire support set, instead of a single average-pooled support embedding. We also propose a Transformer Relation Head (TRH), equipped with higher-order representations, which encodes correlations between query regions and the entire support set, while being sensitive to the positional variability of object instances. Our model achieves state-of-the-art results on PASCAL VOC, FSOD, and COCO.
Parameter-free Online Linear Optimization with Side Information via Universal Coin Betting
Feb 04, 2022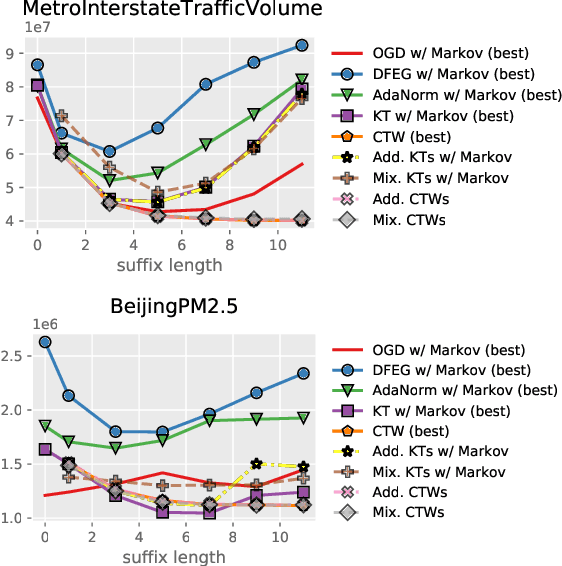
A class of parameter-free online linear optimization algorithms is proposed that harnesses the structure of an adversarial sequence by adapting to some side information. These algorithms combine the reduction technique of Orabona and P{\'a}l (2016) for adapting coin betting algorithms for online linear optimization with universal compression techniques in information theory for incorporating sequential side information to coin betting. Concrete examples are studied in which the side information has a tree structure and consists of quantized values of the previous symbols of the adversarial sequence, including fixed-order and variable-order Markov cases. By modifying the context-tree weighting technique of Willems, Shtarkov, and Tjalkens (1995), the proposed algorithm is further refined to achieve the best performance over all adaptive algorithms with tree-structured side information of a given maximum order in a computationally efficient manner.