 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fuzzy clustering for the within-season estimation of cotton phenology
Nov 30, 2022
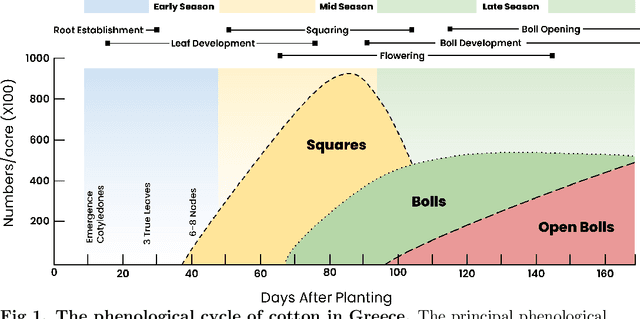

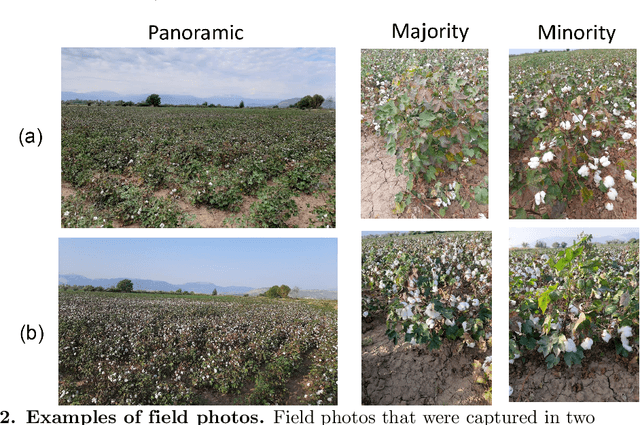
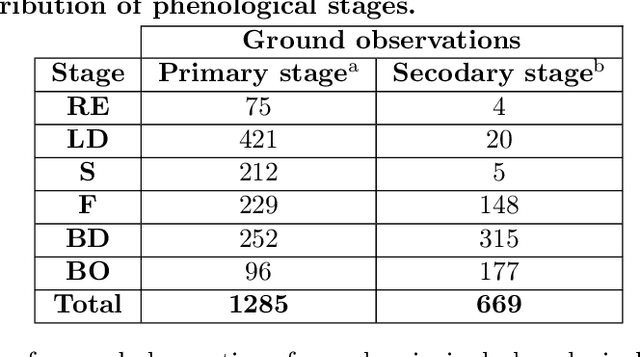
Crop phenology is crucial information for crop yield estimation and agricultural management. Traditionally, phenology has been observed from the ground; however Earth observation, weather and soil data have been used to capture the physiological growth of crops. In this work, we propose a new approach for the within-season phenology estimation for cotton at the field level. For this, we exploit a variety of Earth observation vegetation indices (derived from Sentinel-2) and numerical simulations of atmospheric and soil parameters. Our method is unsupervised to address the ever-present problem of sparse and scarce ground truth data that makes most supervised alternatives impractical in real-world scenarios. We applied fuzzy c-means clustering to identify the principal phenological stages of cotton and then used the cluster membership weights to further predict the transitional phases between adjacent stages. In order to evaluate our models, we collected 1,285 crop growth ground observations in Orchomenos, Greece. We introduced a new collection protocol, assigning up to two phenology labels that represent the primary and secondary growth stage in the field and thus indicate when stages are transitioning. Our model was tested against a baseline model that allowed to isolate the random agreement and evaluate its true competence. The results showed that our model considerably outperforms the baseline one, which is promising considering the unsupervised nature of the approach. The limitations and the relevant future work are thoroughly discussed. The ground observations are formatted in an ready-to-use dataset and will be available at https://github.com/Agri-Hub/cotton-phenology-dataset upon publication.
Predicting Drug Repurposing Candidates and Their Mechanisms from A Biomedical Knowledge Graph
Nov 30, 2022
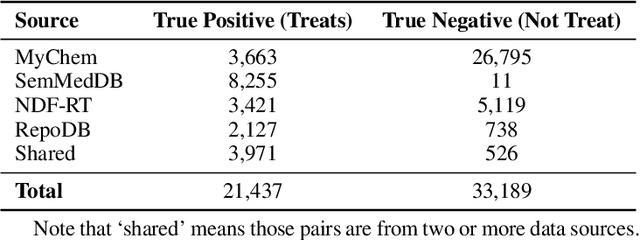
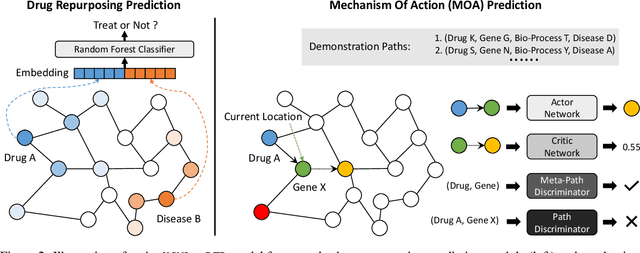
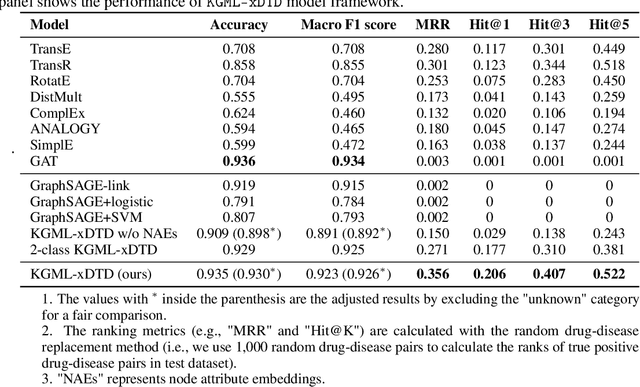
Computational drug repurposing is a cost- and time-efficient method to identify new indications of approved or experimental drugs/compounds. It is especially critical for emerging and/or orphan diseases due to its cheaper investment and shorter research cycle compared with traditional wet-lab drug discovery approaches. However, the underlying mechanisms of action between repurposed drugs and their target diseases remain largely unknown, which is still an unsolved issue in existing repurposing methods. As such, computational drug repurposing has not been widely adopted in clinical settings. In this work, based on a massive biomedical knowledge graph, we propose a computational drug repurposing framework that not only predicts the treatment probabilities between drugs and diseases but also predicts the path-based, testable mechanisms of action (MOAs) as their biomedical explanations. Specifically, we utilize the GraphSAGE model in an unsupervised manner to integrate each entity's neighborhood information and employ a Random Forest model to predict the treatment probabilities between pairs of drugs and diseases. Moreover, we train an adversarial actor-critic reinforcement learning model to predict the potential MOA for explaining drug purposing. To encourage the model to find biologically reasonable paths, we utilize the curated molecular interactions of drugs and a PubMed-publication-based concept distance to extract potential drug MOA paths from the knowledge graph as "demonstration paths" to guide the model during the process of path-finding. Comprehensive experiments and case studies show that the proposed framework outperforms state-of-the-art baselines in both predictive performance of drug repurposing and explanatory performance of recapitulating human-curated DrugMechDB-based paths.
Robust Task-Specific Beamforming with Low-Resolution ADCs for Power-Efficient Hybrid MIMO Receivers
Nov 30, 2022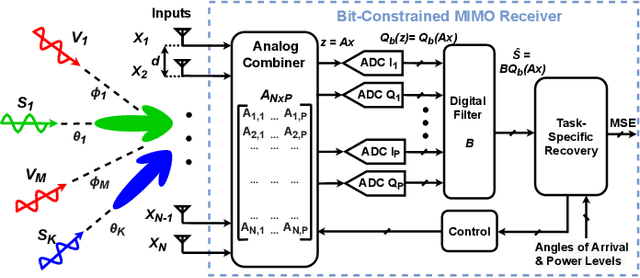
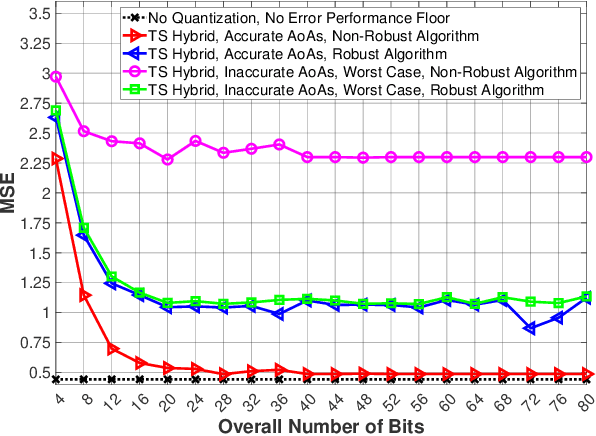
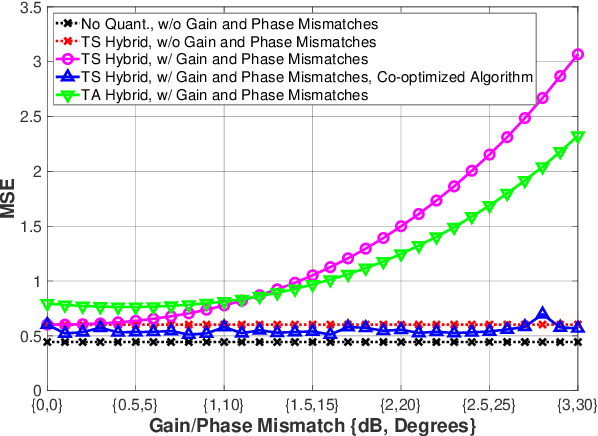
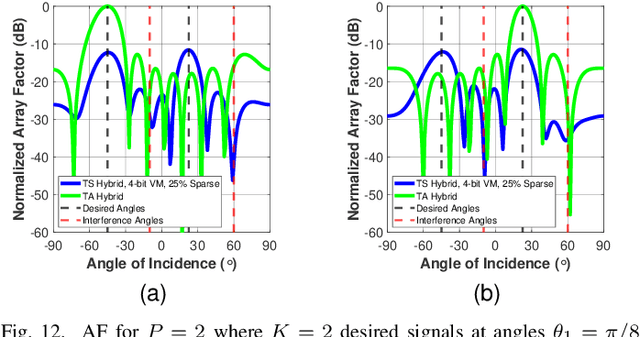
Multiple-input multiple-output (MIMO) systems exploit spatial diversity to facilitate multi-user communications with high spectral efficiency by beamforming. As MIMO systems utilize multiple antennas and radio frequency (RF) chains, they are typically costly to implement and consume high power. A common method to reduce the cost of MIMO receivers is utilizing less RF chains than antennas by employing hybrid analog/digital beamforming (HBF). However, the added analog circuitry involves active components whose consumed power may surpass that saved in RF chain reduction. An additional method to realize power-efficient MIMO systems is to use low-resolution analog-to-digital converters (ADCs), which typically compromises signal recovery accuracy. In this work, we propose a power-efficient hybrid MIMO receiver with low-quantization rate ADCs, by jointly optimizing the analog and digital processing in a hardware-oriented manner using task-specific quantization techniques. To mitigate power consumption on the analog front-end, we utilize efficient analog hardware architecture comprised of sparse low-resolution vector modulators, while accounting for their properties in design to maintain recovery accuracy and mitigate interferers in congested environments. To account for common mismatches induced by non-ideal hardware and inaccurate channel state information, we propose a robust mismatch aware design. Supported by numerical simulations and power analysis, our power-efficient MIMO receiver achieves comparable signal recovery performance to power-hungry fully-digital MIMO receivers using high-resolution ADCs. Furthermore, our receiver outperforms the task-agnostic HBF receivers with low-rate ADCs in recovery accuracy at lower power and successfully copes with hardware mismatches.
Controllable Fake Document Infilling for Cyber Deception
Oct 18, 2022
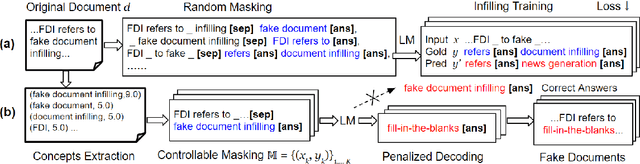

Recent works in cyber deception study how to deter malicious intrusion by generating multiple fake versions of a critical document to impose costs on adversaries who need to identify the correct information. However, existing approaches are context-agnostic, resulting in sub-optimal and unvaried outputs. We propose a novel context-aware model, Fake Document Infilling (FDI), by converting the problem to a controllable mask-then-infill procedure. FDI masks important concepts of varied lengths in the document, then infills a realistic but fake alternative considering both the previous and future contexts. We conduct comprehensive evaluations on technical documents and news stories. Results show that FDI outperforms the baselines in generating highly believable fakes with moderate modification to protect critical information and deceive adversaries.
Learning from the Best: Contrastive Representations Learning Across Sensor Locations for Wearable Activity Recognition
Oct 04, 2022
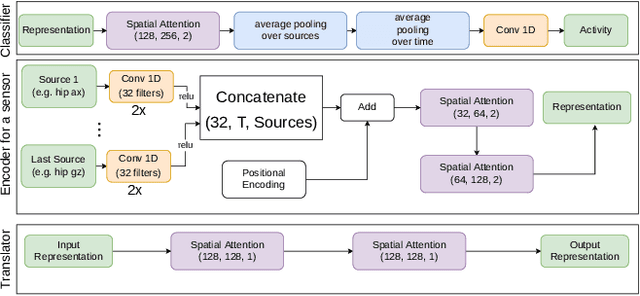
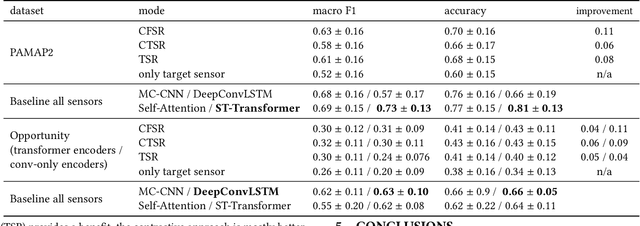
We address the well-known wearable activity recognition problem of having to work with sensors that are non-optimal in terms of information they provide but have to be used due to wearability/usability concerns (e.g. the need to work with wrist-worn IMUs because they are embedded in most smart watches). To mitigate this problem we propose a method that facilitates the use of information from sensors that are only present during the training process and are unavailable during the later use of the system. The method transfers information from the source sensors to the latent representation of the target sensor data through contrastive loss that is combined with the classification loss during joint training. We evaluate the method on the well-known PAMAP2 and Opportunity benchmarks for different combinations of source and target sensors showing average (over all activities) F1 score improvements of between 5% and 13% with the improvement on individual activities, particularly well suited to benefit from the additional information going up to between 20% and 40%.
Quantitative Evidence on Overlooked Aspects of Enrollment Speaker Embeddings for Target Speaker Separation
Oct 26, 2022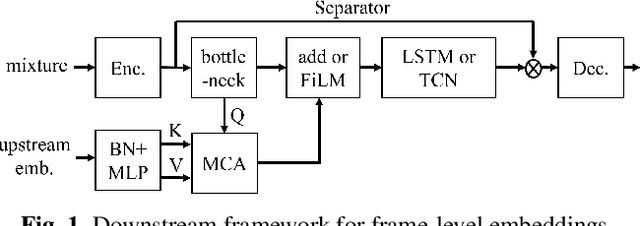
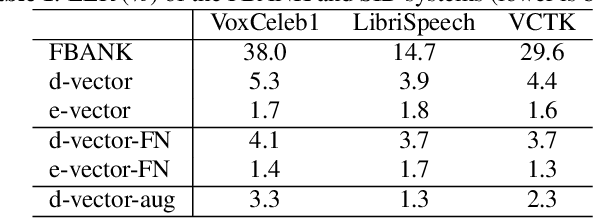
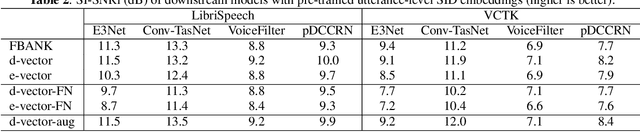

Single channel target speaker separation (TSS) aims at extracting a speaker's voice from a mixture of multiple talkers given an enrollment utterance of that speaker. A typical deep learning TSS framework consists of an upstream model that obtains enrollment speaker embeddings and a downstream model that performs the separation conditioned on the embeddings. In this paper, we look into several important but overlooked aspects of the enrollment embeddings, including the suitability of the widely used speaker identification embeddings, the introduction of the log-mel filterbank and self-supervised embeddings, and the embeddings' cross-dataset generalization capability. Our results show that the speaker identification embeddings could lose relevant information due to a sub-optimal metric, training objective, or common pre-processing. In contrast, both the filterbank and the self-supervised embeddings preserve the integrity of the speaker information, but the former consistently outperforms the latter in a cross-dataset evaluation. The competitive separation and generalization performance of the previously overlooked filterbank embedding is consistent across our study, which calls for future research on better upstream features.
LDL: A Defense for Label-Based Membership Inference Attacks
Dec 03, 2022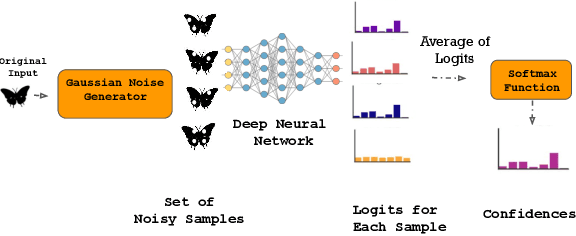
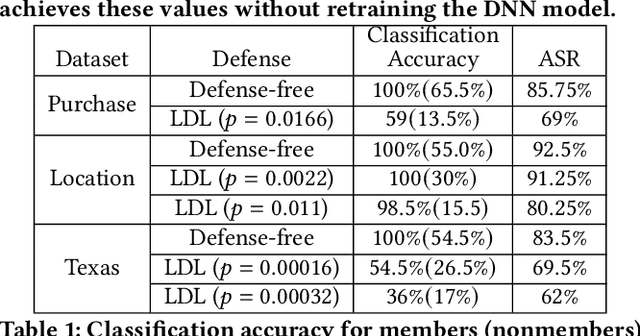
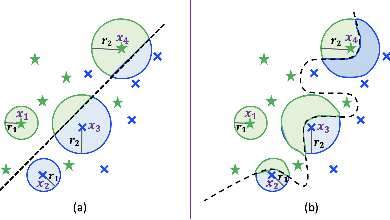
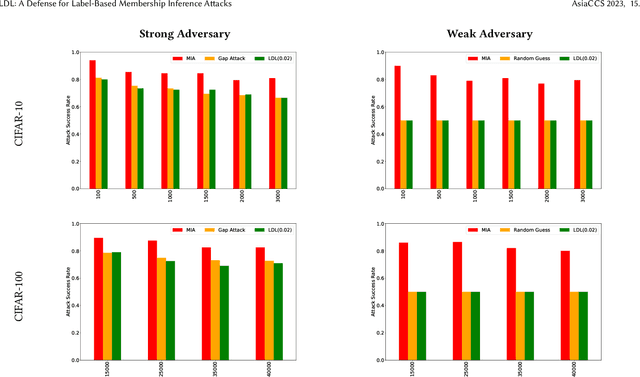
The data used to train deep neural network (DNN) models in applications such as healthcare and finance typically contain sensitive information. A DNN model may suffer from overfitting. Overfitted models have been shown to be susceptible to query-based attacks such as membership inference attacks (MIAs). MIAs aim to determine whether a sample belongs to the dataset used to train a classifier (members) or not (nonmembers). Recently, a new class of label based MIAs (LAB MIAs) was proposed, where an adversary was only required to have knowledge of predicted labels of samples. Developing a defense against an adversary carrying out a LAB MIA on DNN models that cannot be retrained remains an open problem. We present LDL, a light weight defense against LAB MIAs. LDL works by constructing a high-dimensional sphere around queried samples such that the model decision is unchanged for (noisy) variants of the sample within the sphere. This sphere of label-invariance creates ambiguity and prevents a querying adversary from correctly determining whether a sample is a member or a nonmember. We analytically characterize the success rate of an adversary carrying out a LAB MIA when LDL is deployed, and show that the formulation is consistent with experimental observations. We evaluate LDL on seven datasets -- CIFAR-10, CIFAR-100, GTSRB, Face, Purchase, Location, and Texas -- with varying sizes of training data. All of these datasets have been used by SOTA LAB MIAs. Our experiments demonstrate that LDL reduces the success rate of an adversary carrying out a LAB MIA in each case. We empirically compare LDL with defenses against LAB MIAs that require retraining of DNN models, and show that LDL performs favorably despite not needing to retrain the DNNs.
Precise Energy Consumption Measurements of Heterogeneous Artificial Intelligence Workloads
Dec 03, 2022

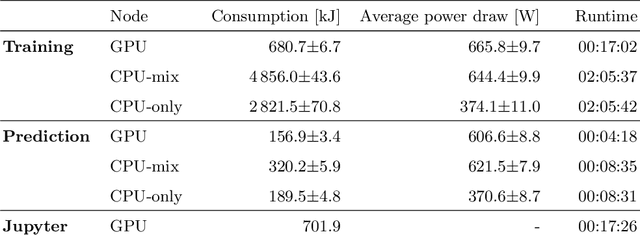
With the rise of AI in recent years and the increase in complexity of the models, the growing demand in computational resources is starting to pose a significant challenge. The need for higher compute power is being met with increasingly more potent accelerators and the use of large compute clusters. However, the gain in prediction accuracy from large models trained on distributed and accelerated systems comes at the price of a substantial increase in energy demand, and researchers have started questioning the environmental friendliness of such AI methods at scale. Consequently, energy efficiency plays an important role for AI model developers and infrastructure operators alike. The energy consumption of AI workloads depends on the model implementation and the utilized hardware. Therefore, accurate measurements of the power draw of AI workflows on different types of compute nodes is key to algorithmic improvements and the design of future compute clusters and hardware. To this end, we present measurements of the energy consumption of two typical applications of deep learning models on different types of compute nodes. Our results indicate that 1. deriving energy consumption directly from runtime is not accurate, but the consumption of the compute node needs to be considered regarding its composition; 2. neglecting accelerator hardware on mixed nodes results in overproportional inefficiency regarding energy consumption; 3. energy consumption of model training and inference should be considered separately - while training on GPUs outperforms all other node types regarding both runtime and energy consumption, inference on CPU nodes can be comparably efficient. One advantage of our approach is that the information on energy consumption is available to all users of the supercomputer, enabling an easy transfer to other workloads alongside a raise in user-awareness of energy consumption.
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
Nov 22, 2022
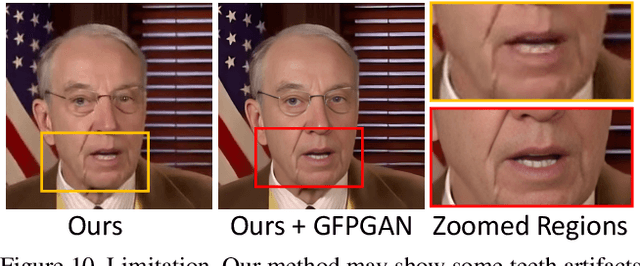
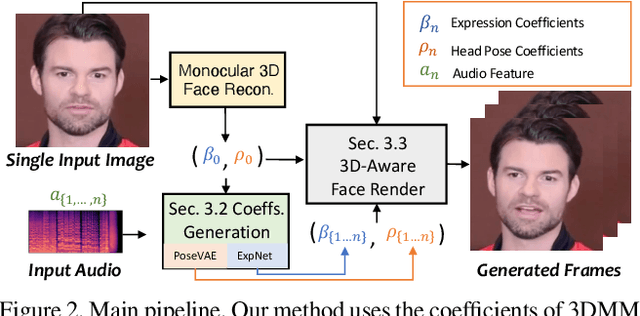
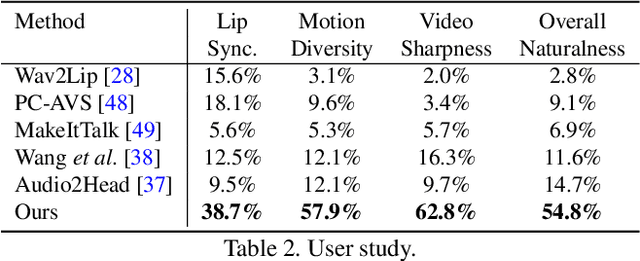
Generating talking head videos through a face image and a piece of speech audio still contains many challenges. ie, unnatural head movement, distorted expression, and identity modification. We argue that these issues are mainly because of learning from the coupled 2D motion fields. On the other hand, explicitly using 3D information also suffers problems of stiff expression and incoherent video. We present SadTalker, which generates 3D motion coefficients (head pose, expression) of the 3DMM from audio and implicitly modulates a novel 3D-aware face render for talking head generation. To learn the realistic motion coefficients, we explicitly model the connections between audio and different types of motion coefficients individually. Precisely, we present ExpNet to learn the accurate facial expression from audio by distilling both coefficients and 3D-rendered faces. As for the head pose, we design PoseVAE via a conditional VAE to synthesize head motion in different styles. Finally, the generated 3D motion coefficients are mapped to the unsupervised 3D keypoints space of the proposed face render, and synthesize the final video. We conduct extensive experiments to show the superior of our method in terms of motion and video quality.
Re-thinking Knowledge Graph Completion Evaluation from an Information Retrieval Perspective
May 09, 2022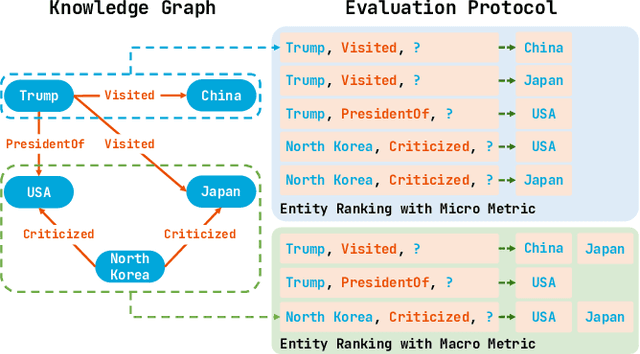
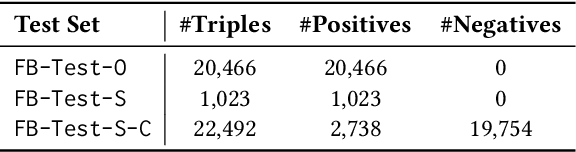
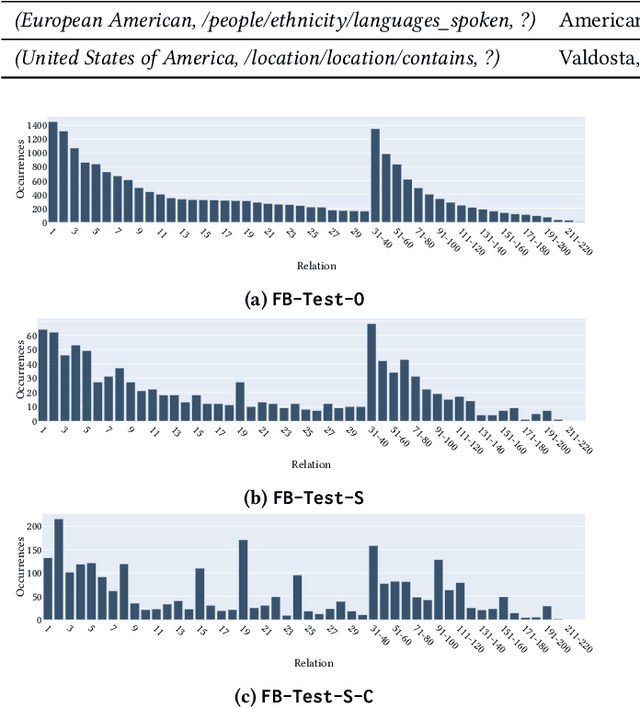

Knowledge graph completion (KGC) aims to infer missing knowledge triples based on known facts in a knowledge graph. Current KGC research mostly follows an entity ranking protocol, wherein the effectiveness is measured by the predicted rank of a masked entity in a test triple. The overall performance is then given by a micro(-average) metric over all individual answer entities. Due to the incomplete nature of the large-scale knowledge bases, such an entity ranking setting is likely affected by unlabelled top-ranked positive examples, raising questions on whether the current evaluation protocol is sufficient to guarantee a fair comparison of KGC systems. To this end, this paper presents a systematic study on whether and how the label sparsity affects the current KGC evaluation with the popular micro metrics. Specifically, inspired by the TREC paradigm for large-scale information retrieval (IR) experimentation, we create a relatively "complete" judgment set based on a sample from the popular FB15k-237 dataset following the TREC pooling method. According to our analysis, it comes as a surprise that switching from the original labels to our "complete" labels results in a drastic change of system ranking of a variety of 13 popular KGC models in terms of micro metrics. Further investigation indicates that the IR-like macro(-average) metrics are more stable and discriminative under different settings, meanwhile, less affected by label sparsity. Thus, for KGC evaluation, we recommend conducting TREC-style pooling to balance between human efforts and label completeness, and reporting also the IR-like macro metrics to reflect the ranking nature of the KGC task.