 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data Converter Design Space Exploration for IoT Applications: An Overview of Challenges and Future Directions
Nov 03, 2022
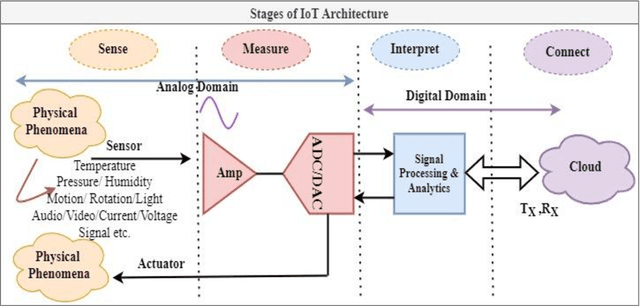
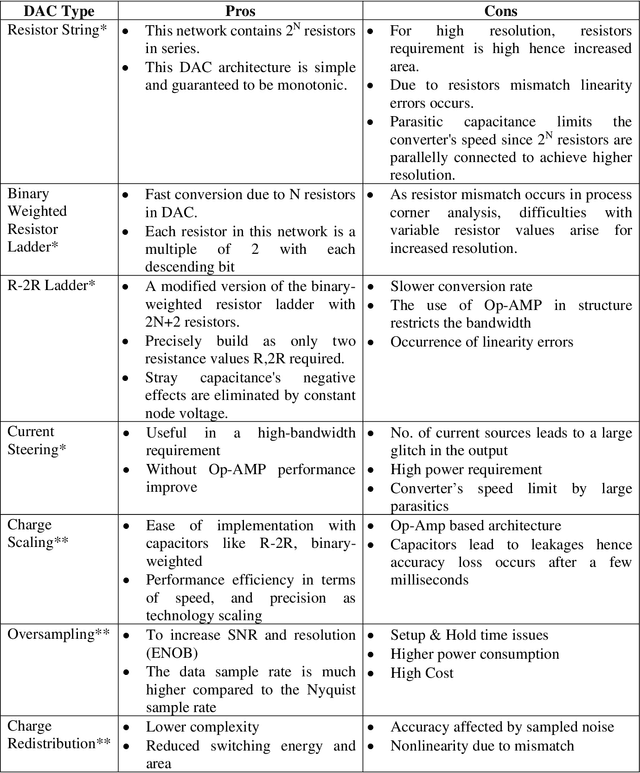
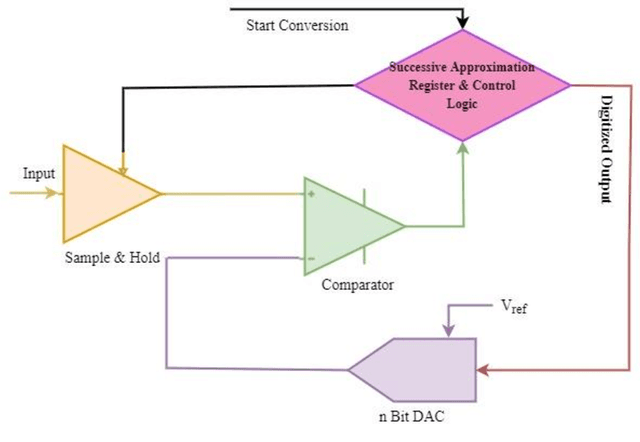
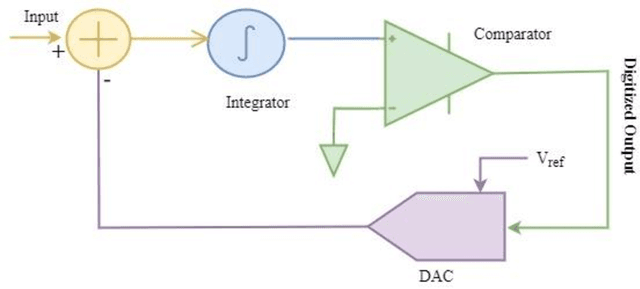
Human lives are improving with the widespread use of cutting-edge digital technology like the Internet of Things (IoT). Recently, the pandemic has shown the demand for more digitally advanced IoT-based devices. International Data Corporation (IDC) forecasts that by 2025, there will be approximately 42 billion of these devices in use, capable of producing around 80 ZB (zettabytes) of data. So data acquisition, processing, communication, and visualization are necessary from a functional standpoint. Indicating sensors & data converters are the key components for IoT-based applications. The efficiency of such applications is truly measured in terms of latency, power, and resolution of data converters motivating designers to perform efficiently. Sensors capture and covert physical features from their chosen environment into detectable quantities. Data converter gives meaningful information and connects the real analog world to the digital component of the devices. The received data is interpreted and analyzed with the digital processing circuitry. Ultimately, it is used as information by a network of internet-connected smart devices. Because IoT technologies are adaptable to nearly any technology that may provide its operational activity and environmental conditions. But the challenges occur with power consumption as the complete IoT framework is battery operated and replacing a battery is a daunting task. So the goal of this chapter is to unveil the requirements to design energy-efficient data converters for IoT applications.
Temporal Consistency Learning of inter-frames for Video Super-Resolution
Nov 03, 2022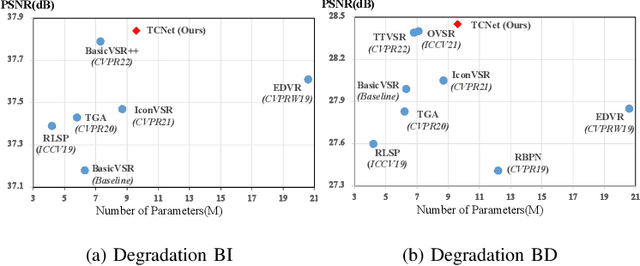
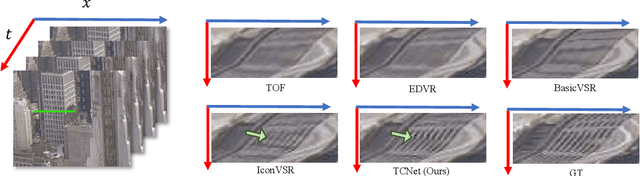


Video super-resolution (VSR) is a task that aims to reconstruct high-resolution (HR) frames from the low-resolution (LR) reference frame and multiple neighboring frames. The vital operation is to utilize the relative misaligned frames for the current frame reconstruction and preserve the consistency of the results. Existing methods generally explore information propagation and frame alignment to improve the performance of VSR. However, few studies focus on the temporal consistency of inter-frames. In this paper, we propose a Temporal Consistency learning Network (TCNet) for VSR in an end-to-end manner, to enhance the consistency of the reconstructed videos. A spatio-temporal stability module is designed to learn the self-alignment from inter-frames. Especially, the correlative matching is employed to exploit the spatial dependency from each frame to maintain structural stability. Moreover, a self-attention mechanism is utilized to learn the temporal correspondence to implement an adaptive warping operation for temporal consistency among multi-frames. Besides, a hybrid recurrent architecture is designed to leverage short-term and long-term information. We further present a progressive fusion module to perform a multistage fusion of spatio-temporal features. And the final reconstructed frames are refined by these fused features. Objective and subjective results of various experiments demonstrate that TCNet has superior performance on different benchmark datasets, compared to several state-of-the-art methods.
Accidental Learners: Spoken Language Identification in Multilingual Self-Supervised Models
Nov 09, 2022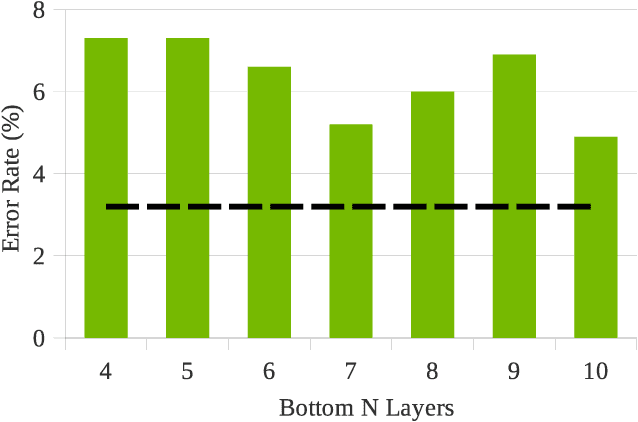
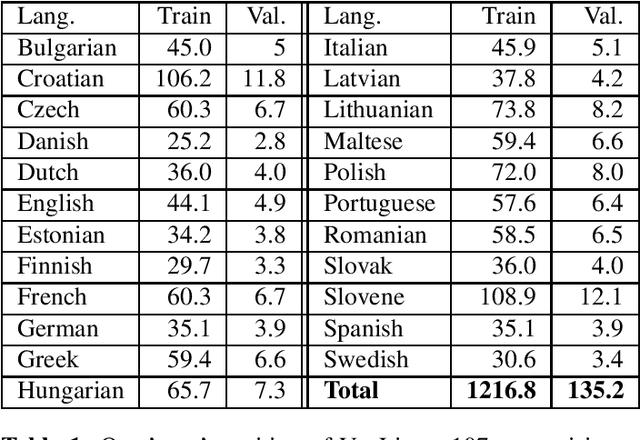
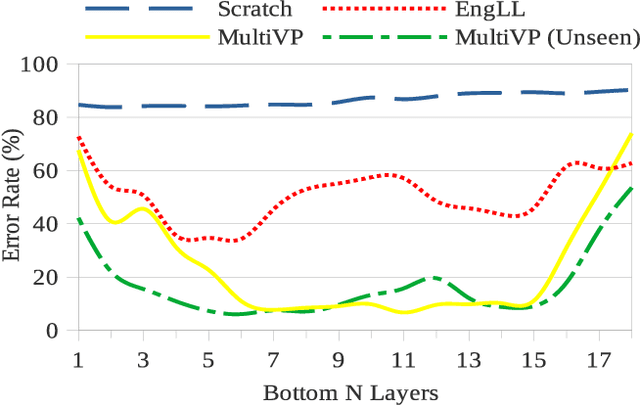
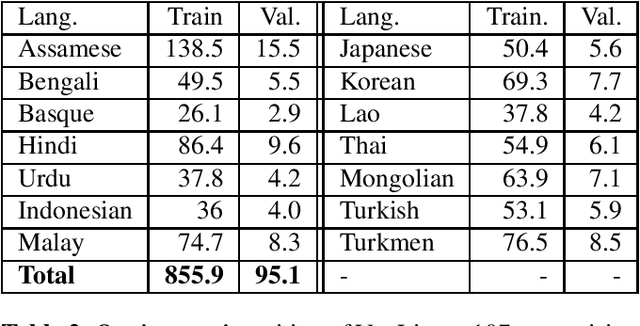
In this paper, we extend previous self-supervised approaches for language identification by experimenting with Conformer based architecture in a multilingual pre-training paradigm. We find that pre-trained speech models optimally encode language discriminatory information in lower layers. Further, we demonstrate that the embeddings obtained from these layers are significantly robust to classify unseen languages and different acoustic environments without additional training. After fine-tuning a pre-trained Conformer model on the VoxLingua107 dataset, we achieve results similar to current state-of-the-art systems for language identification. More, our model accomplishes this with 5x less parameters. We open-source the model through the NVIDIA NeMo toolkit.
Extracting, Visualizing, and Learning from Dynamic Data: Perfusion in Surgical Video for Tissue Characterization
Nov 09, 2022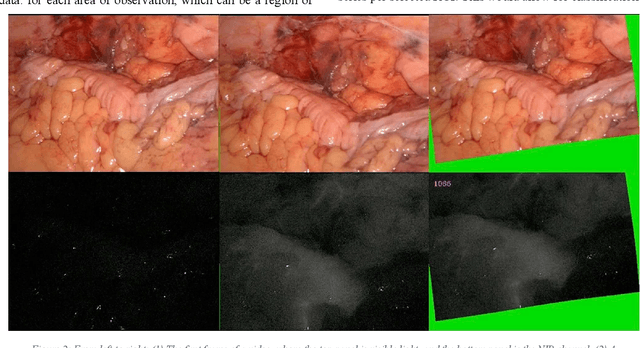
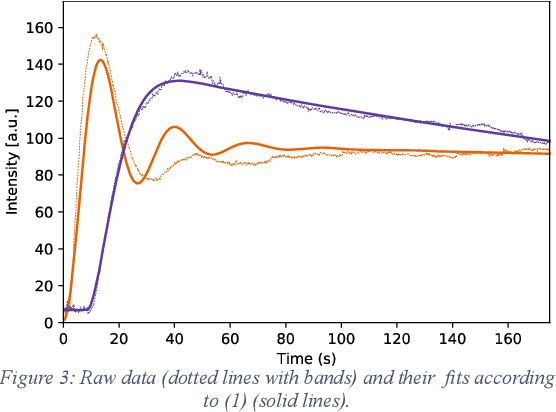
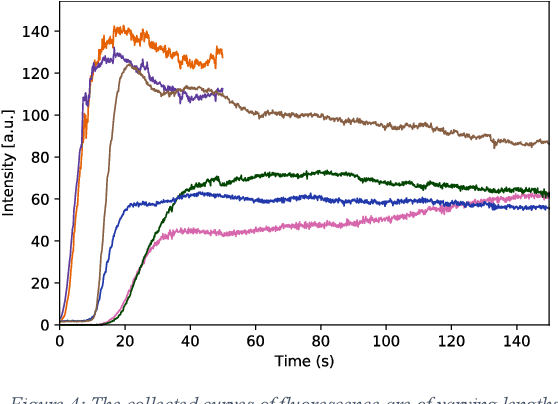
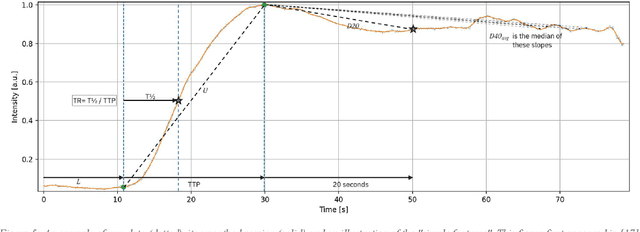
Intraoperative assessment of tissue can be guided through fluorescence imaging which involves systemic dosing with a fluorophore and subsequent examination of the tissue region of interest with a near-infrared camera. This typically involves administering indocyanine green (ICG) hours or even days before surgery and intraoperative visualization at the time predicted for steady-state signal-to-background status. Here, we describe our efforts to capture and utilize the information contained in the first few minutes after ICG administration from the perspective of both signal processing and surgical practice. We prove a method for characterization of cancerous versus benign rectal lesions now undergoing further development and validation via multicenter clinical phase studies.
* Presented and published at IEEE International Conference on Digital Health (ICDH) 2022
Scientific Paper Classification Based on Graph Neural Network with Hypergraph Self-attention Mechanism
Oct 07, 2022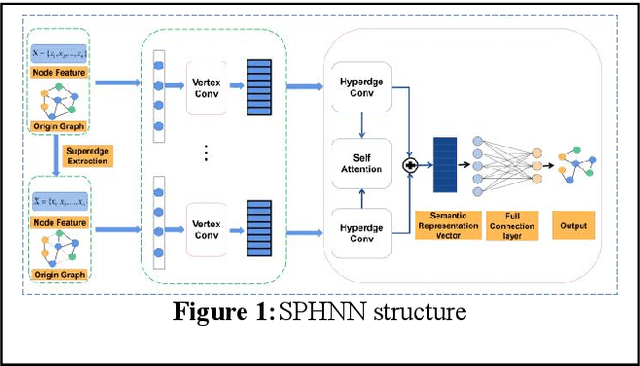
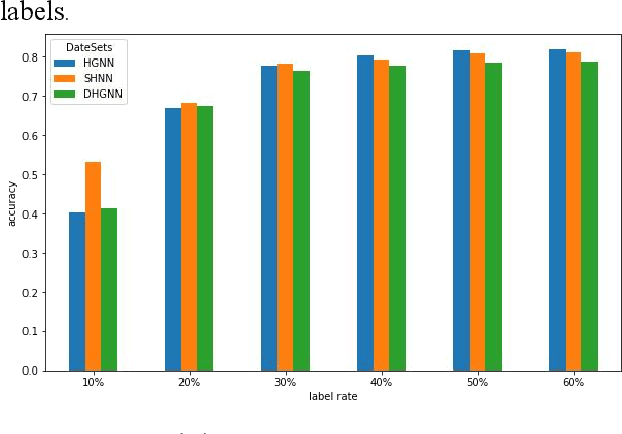
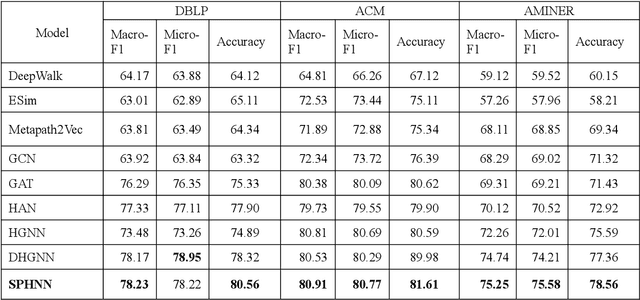
The number of scientific papers has increased rapidly in recent years. How to make good use of scientific papers for research is very important. Through the high-quality classification of scientific papers, researchers can quickly find the resource content they need from the massive scientific resources. The classification of scientific papers will effectively help researchers filter redundant information, obtain search results quickly and accurately, and improve the search quality, which is necessary for scientific resource management. This paper proposed a science-technique paper classification method based on hypergraph neural network(SPHNN). In the heterogeneous information network of scientific papers, the repeated high-order subgraphs are modeled as hyperedges composed of multiple related nodes. Then the whole heterogeneous information network is transformed into a hypergraph composed of different hyperedges. The graph convolution operation is carried out on the hypergraph structure, and the hyperedges self-attention mechanism is introduced to aggregate different types of nodes in the hypergraph, so that the final node representation can effectively maintain high-order nearest neighbor relationships and complex semantic information. Finally, by comparing with other methods, we proved that the model proposed in this paper has improved its performance.
Masked Autoencoding for Scalable and Generalizable Decision Making
Nov 23, 2022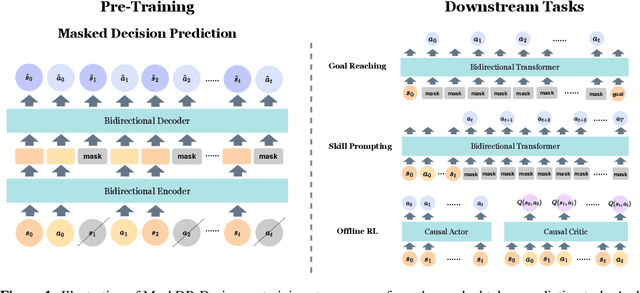

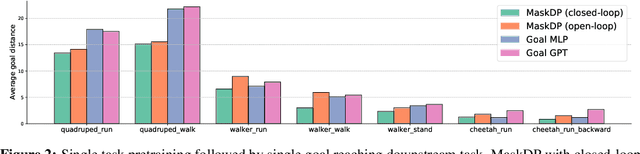
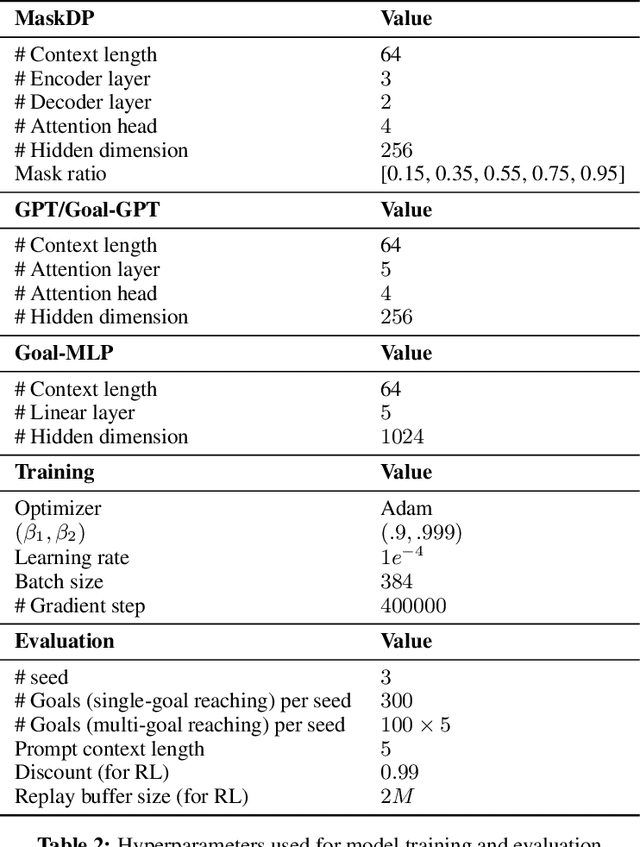
We are interested in learning scalable agents for reinforcement learning that can learn from large-scale, diverse sequential data similar to current large vision and language models. To this end, this paper presents masked decision prediction (MaskDP), a simple and scalable self-supervised pretraining method for reinforcement learning (RL) and behavioral cloning (BC). In our MaskDP approach, we employ a masked autoencoder (MAE) to state-action trajectories, wherein we randomly mask state and action tokens and reconstruct the missing data. By doing so, the model is required to infer masked-out states and actions and extract information about dynamics. We find that masking different proportions of the input sequence significantly helps with learning a better model that generalizes well to multiple downstream tasks. In our empirical study, we find that a MaskDP model gains the capability of zero-shot transfer to new BC tasks, such as single and multiple goal reaching, and it can zero-shot infer skills from a few example transitions. In addition, MaskDP transfers well to offline RL and shows promising scaling behavior w.r.t. to model size. It is amenable to data-efficient finetuning, achieving competitive results with prior methods based on autoregressive pretraining.
Low Rank Quaternion Matrix Completion Based on Quaternion QR Decomposition and Sparse Regularizer
Nov 23, 2022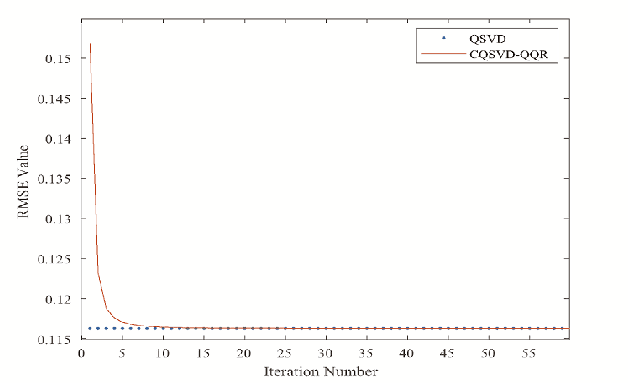

Matrix completion is one of the most challenging problems in computer vision. Recently, quaternion representations of color images have achieved competitive performance in many fields. Because it treats the color image as a whole, the coupling information between the three channels of the color image is better utilized. Due to this, low-rank quaternion matrix completion (LRQMC) algorithms have gained considerable attention from researchers. In contrast to the traditional quaternion matrix completion algorithms based on quaternion singular value decomposition (QSVD), we propose a novel method based on quaternion Qatar Riyal decomposition (QQR). In the first part of the paper, a novel method for calculating an approximate QSVD based on iterative QQR is proposed (CQSVD-QQR), whose computational complexity is lower than that of QSVD. The largest $r \ (r>0)$ singular values of a given quaternion matrix can be computed by using CQSVD-QQR. Then, we propose a new quaternion matrix completion method based on CQSVD-QQR which combines low-rank and sparse priors of color images. Experimental results on color images and color medical images demonstrate that our model outperforms those state-of-the-art methods.
ProstAttention-Net: A deep attention model for prostate cancer segmentation by aggressiveness in MRI scans
Nov 23, 2022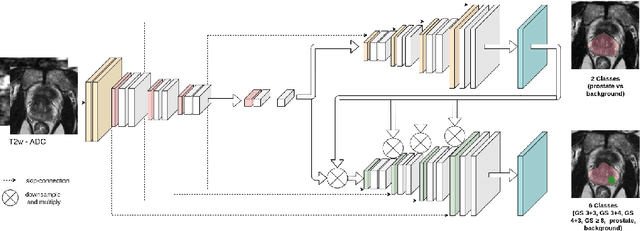
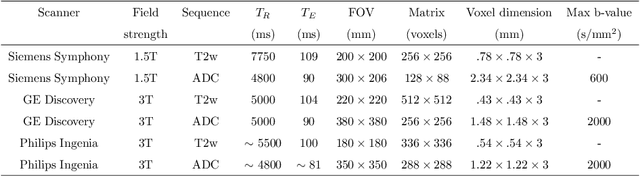
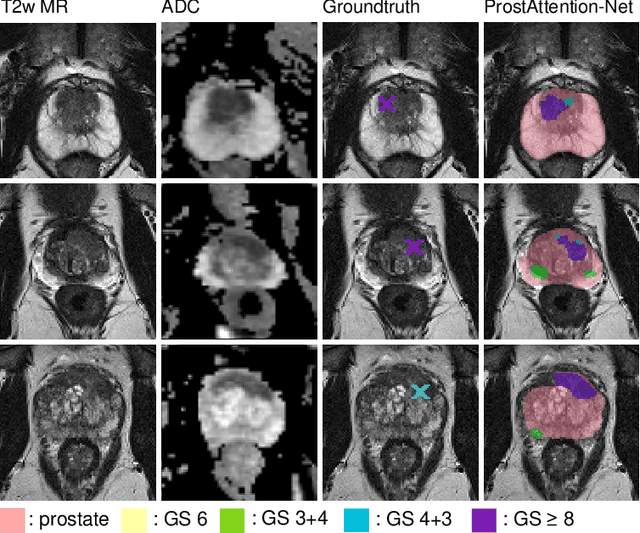

Multiparametric magnetic resonance imaging (mp-MRI) has shown excellent results in the detection of prostate cancer (PCa). However, characterizing prostate lesions aggressiveness in mp-MRI sequences is impossible in clinical practice, and biopsy remains the reference to determine the Gleason score (GS). In this work, we propose a novel end-to-end multi-class network that jointly segments the prostate gland and cancer lesions with GS group grading. After encoding the information on a latent space, the network is separated in two branches: 1) the first branch performs prostate segmentation 2) the second branch uses this zonal prior as an attention gate for the detection and grading of prostate lesions. The model was trained and validated with a 5-fold cross-validation on an heterogeneous series of 219 MRI exams acquired on three different scanners prior prostatectomy. In the free-response receiver operating characteristics (FROC) analysis for clinically significant lesions (defined as GS > 6) detection, our model achieves 69.0% $\pm$14.5% sensitivity at 2.9 false positive per patient on the whole prostate and 70.8% $\pm$14.4% sensitivity at 1.5 false positive when considering the peripheral zone (PZ) only. Regarding the automatic GS group
Navigation with Tactile Sensor for Natural Human-Robot Interaction
Nov 23, 2022
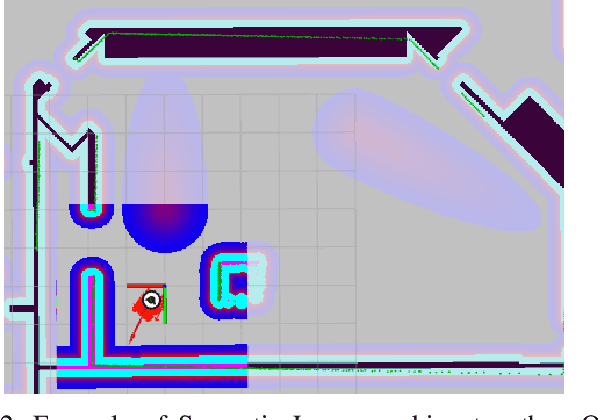

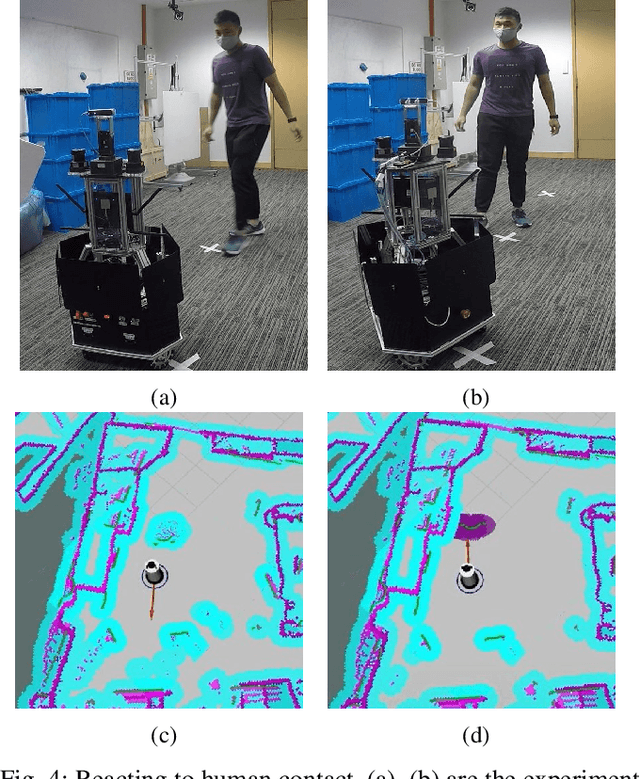
Tactile sensors have been introduced to a wide range of robotic tasks such as robot manipulation to mimic the sense of human touch. However, there has only been a few works that integrate tactile sensing into robot navigation. This paper describes a navigation system which allows robots to operate in crowded human-dense environments and behave with socially acceptable reactions by utilizing semantic and force information collected by embedded tactile sensors, RGB-D camera and LiDAR. Compliance control is implemented based on artificial potential fields considering not only laser scan but also force reading from tactile sensors which promises a fast and reliable response to any possible collision. In contrast to cameras, LiDAR and other non-contact sensors, tactile sensors can directly interact with humans and can be used to accept social cues akin to natural human behavior under the same situation. Furthermore, leveraging semantic segmentation from vision module, the robot is able to identify and, therefore assign varying social cost to different groups of humans enabling for socially conscious path planning. At the end of this paper, the proposed control strategy was validated successfully by testing several scenarios on an omni-directional robot in real world.
Stackelberg Meta-Learning for Strategic Guidance in Multi-Robot Trajectory Planning
Nov 23, 2022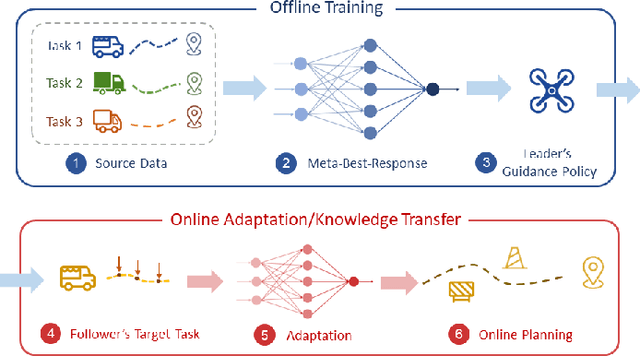

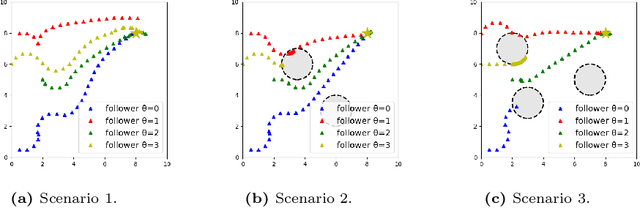
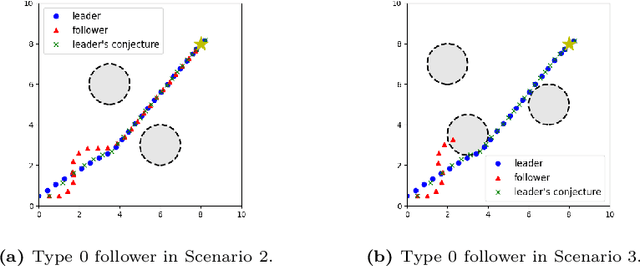
Guided cooperation is a common task in many multi-agent teaming applications. The planning of the cooperation is difficult when the leader robot has incomplete information about the follower, and there is a need to learn, customize, and adapt the cooperation plan online. To this end, we develop a learning-based Stackelberg game-theoretic framework to address this challenge to achieve optimal trajectory planning for heterogeneous robots. We first formulate the guided trajectory planning problem as a dynamic Stackelberg game and design the cooperation plans using open-loop Stackelberg equilibria. We leverage meta-learning to deal with the unknown follower in the game and propose a Stackelberg meta-learning framework to create online adaptive trajectory guidance plans, where the leader robot learns a meta-best-response model from a prescribed set of followers offline and then fast adapts to a specific online trajectory guidance task using limited learning data. We use simulations in three different scenarios to elaborate on the effectiveness of our framework. Comparison with other learning approaches and no guidance cases show that our framework provides a more time- and data-efficient planning method in trajectory guidance tasks.