 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ham2Pose: Animating Sign Language Notation into Pose Sequences
Nov 24, 2022

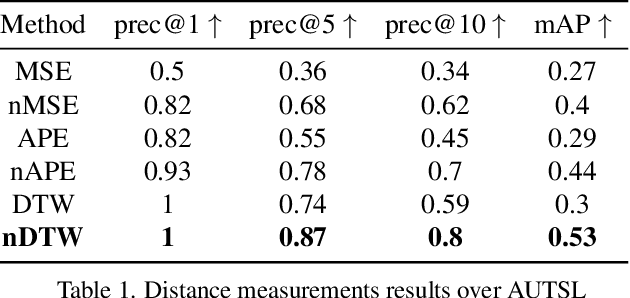

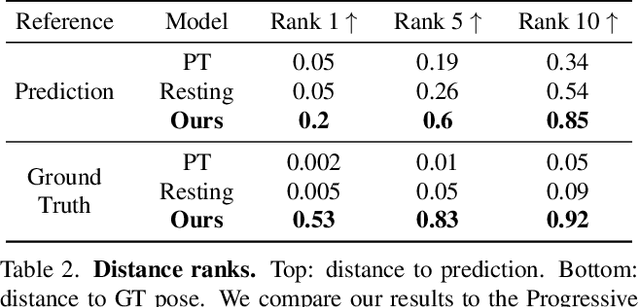
Translating spoken languages into Sign languages is necessary for open communication between the hearing and hearing-impaired communities. To achieve this goal, we propose the first method for animating a text written in HamNoSys, a lexical Sign language notation, into signed pose sequences. As HamNoSys is universal, our proposed method offers a generic solution invariant to the target Sign language. Our method gradually generates pose predictions using transformer encoders that create meaningful representations of the text and poses while considering their spatial and temporal information. We use weak supervision for the training process and show that our method succeeds in learning from partial and inaccurate data. Additionally, we offer a new distance measurement for pose sequences, normalized Dynamic Time Warping (nDTW), based on DTW over normalized keypoints trajectories, and validate its correctness using AUTSL, a large-scale Sign language dataset. We show that it measures the distance between pose sequences more accurately than existing measurements and use it to assess the quality of our generated pose sequences. Code for the data pre-processing, the model, and the distance measurement is publicly released for future research.
Machine Learning Approaches for Principle Prediction in Naturally Occurring Stories
Nov 19, 2022
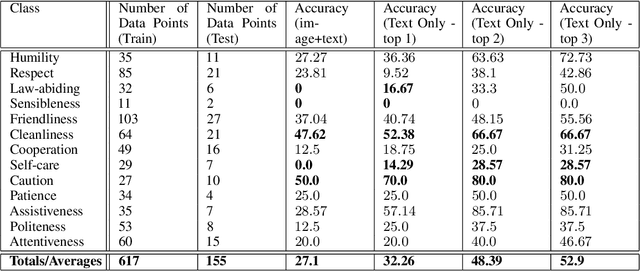

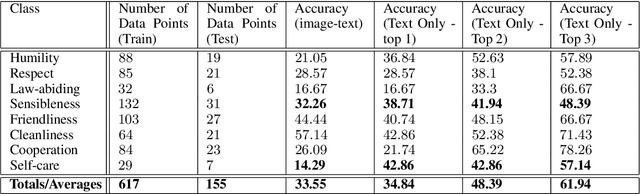
Value alignment is the task of creating autonomous systems whose values align with those of humans. Past work has shown that stories are a potentially rich source of information on human values; however, past work has been limited to considering values in a binary sense. In this work, we explore the use of machine learning models for the task of normative principle prediction on naturally occurring story data. To do this, we extend a dataset that has been previously used to train a binary normative classifier with annotations of moral principles. We then use this dataset to train a variety of machine learning models, evaluate these models and compare their results against humans who were asked to perform the same task. We show that while individual principles can be classified, the ambiguity of what "moral principles" represent, poses a challenge for both human participants and autonomous systems which are faced with the same task.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022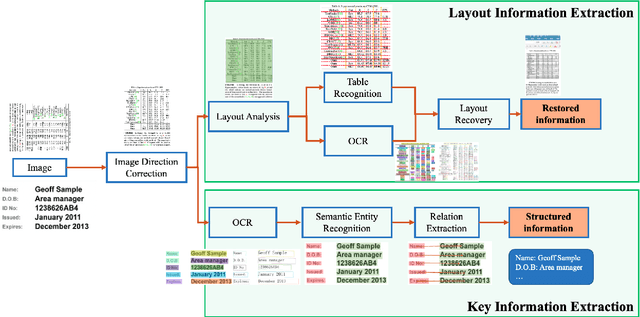



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Oct 25, 2022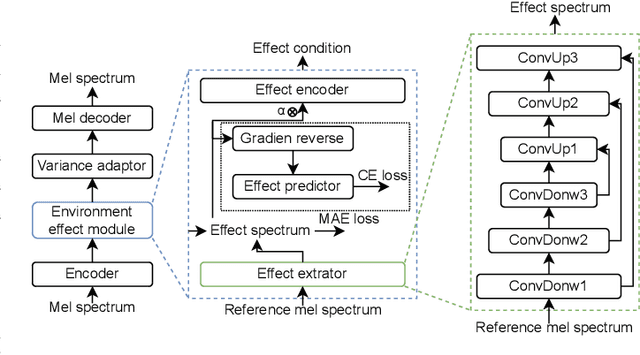
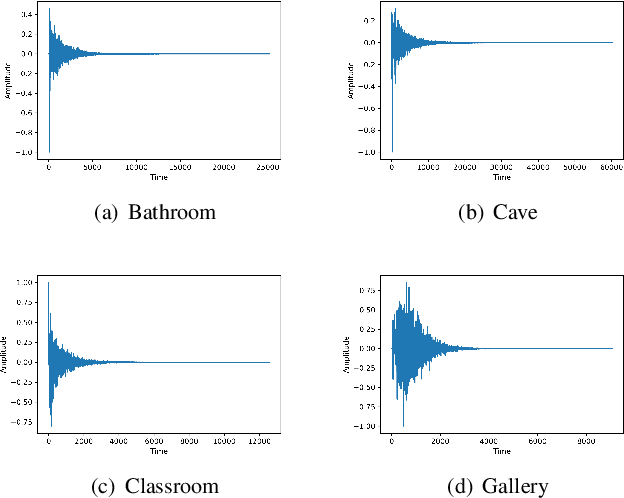
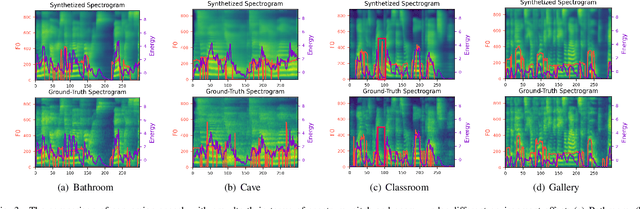
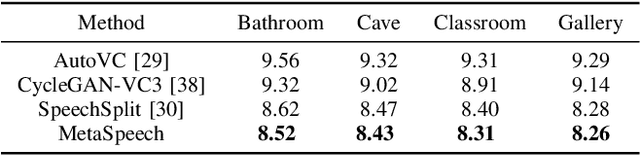
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly connected and entered. Voice is an indispensable communication medium in the real world and Metaverse. Fusion of the voice with environment effects is important for user immersion in Metaverse. In this paper, we proposed using the voice conversion based method for the conversion of target environment effect speech. The proposed method was named MetaSpeech, which introduces an environment effect module containing an effect extractor to extract the environment information and an effect encoder to encode the environment effect condition, in which gradient reversal layer was used for adversarial training to keep the speech content and speaker information while disentangling the environmental effects. From the experiment results on the public dataset of LJSpeech with four environment effects, the proposed model could complete the specific environment effect conversion and outperforms the baseline methods from the voice conversion task.
PMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration
Mar 16, 2022
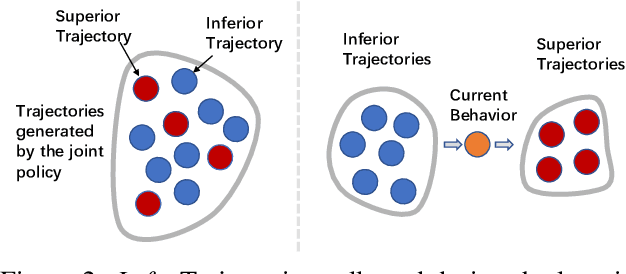
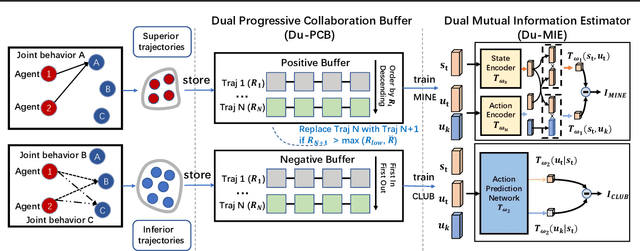
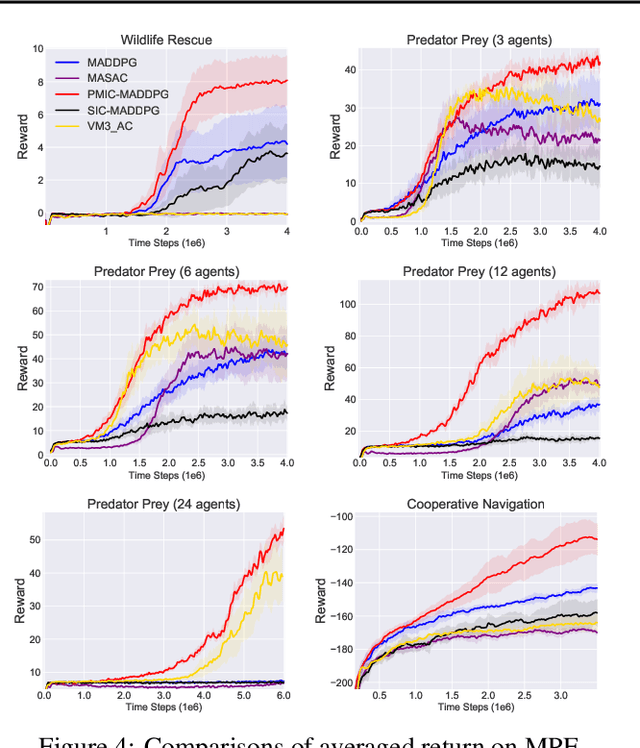
Learning to collaborate is critical in multi-agent reinforcement learning (MARL). A number of previous works promote collaboration by maximizing the correlation of agents' behaviors, which is typically characterised by mutual information (MI) in different forms. However, in this paper, we reveal that strong correlation can emerge from sub-optimal collaborative behaviors, and simply maximizing the MI can, surprisingly, hinder the learning towards better collaboration. To address this issue, we propose a novel MARL framework, called Progressive Mutual Information Collaboration (PMIC), for more effective MI-driven collaboration. In PMIC, we use a new collaboration criterion measured by the MI between global states and joint actions. Based on the criterion, the key idea of PMIC is maximizing the MI associated with superior collaborative behaviors and minimizing the MI associated with inferior ones. The two MI objectives play complementary roles by facilitating learning towards better collaborations while avoiding falling into sub-optimal ones. Specifically, PMIC stores and progressively maintains sets of superior and inferior interaction experiences, from which dual MI neural estimators are established. Experiments on a wide range of MARL benchmarks show the superior performance of PMIC compared with other algorithms.
Space-time design for deep joint source channel coding of images Over MIMO channels
Oct 30, 2022
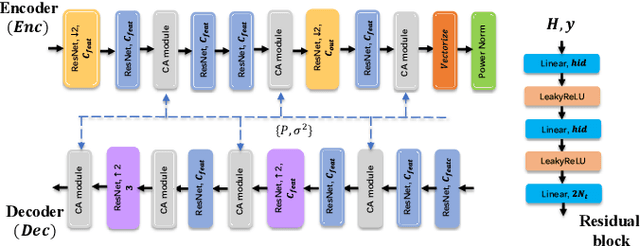
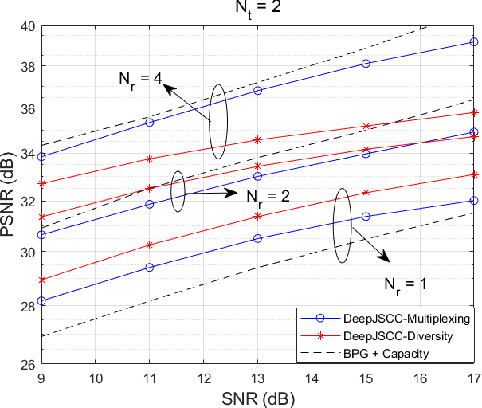
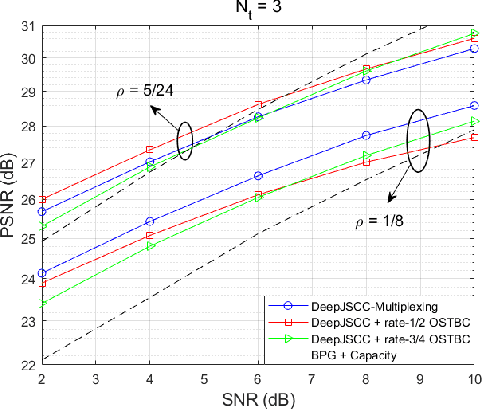
We propose novel deep joint source-channel coding (DeepJSCC) algorithms for wireless image transmission over multi-input multi-output (MIMO) Rayleigh fading channels, when channel state information (CSI) is available only at the receiver. We consider two different transmission schemes; one exploiting spatial diversity and the other one exploiting spatial multiplexing of the MIMO channel. In the diversity scheme, we utilize an orthogonal space-time block code (OSTBC) to achieve full diversity which increases the robustness of transmission against channel variations. The multiplexing scheme, on the other hand, allows the user to directly map the codeword to the antennas, where the additional degree-of-freedom is used to send more information about the source signal. Simulation results show that the diversity scheme outperforms the multiplexing scheme at lower signal-to-noise ratio (SNR) values and smaller number of receive antennas at the AP. When the number of transmit antennas is greater than two, however, the full-diversity scheme becomes less beneficial. We also show that both the diversity and multiplexing scheme can achieve comparable performance with the state-of-the-art BPG algorithm delivered at the MIMO capacity in the considered scenarios.
CAD 3D Model classification by Graph Neural Networks: A new approach based on STEP format
Oct 30, 2022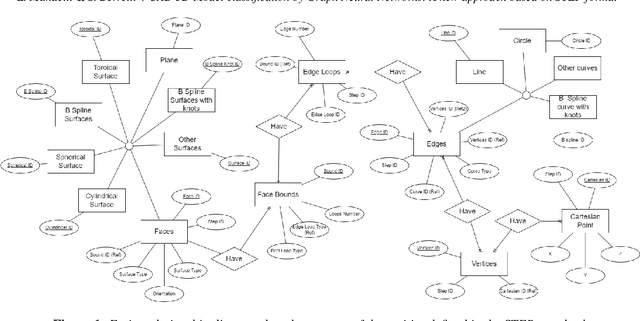
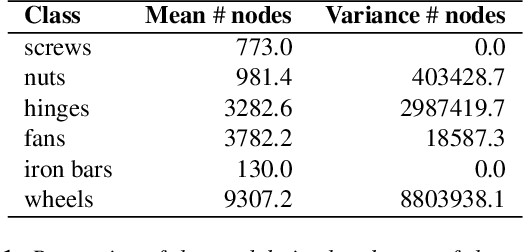
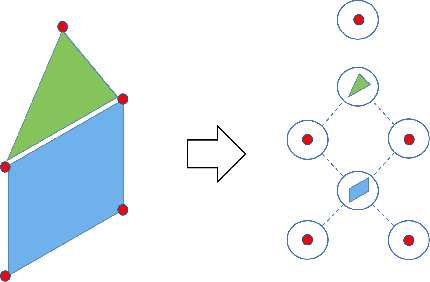
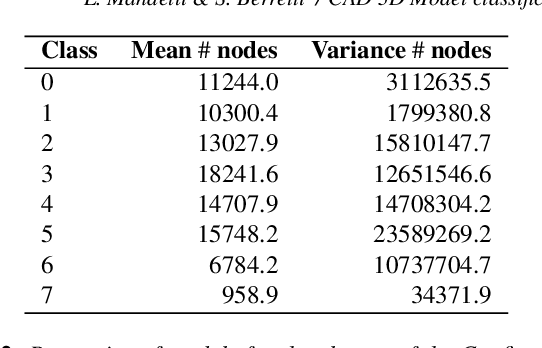
In this paper, we introduce a new approach for retrieval and classification of 3D models that directly performs in the Computer-Aided Design (CAD) format without any conversion to other representations like point clouds or meshes, thus avoiding any loss of information. Among the various CAD formats, we consider the widely used STEP extension, which represents a standard for product manufacturing information. This particular format represents a 3D model as a set of primitive elements such as surfaces and vertices linked together. In our approach, we exploit the linked structure of STEP files to create a graph in which the nodes are the primitive elements and the arcs are the connections between them. We then use Graph Neural Networks (GNNs) to solve the problem of model classification. Finally, we created two datasets of 3D models in native CAD format, respectively, by collecting data from the Traceparts model library and from the Configurators software modeling company. We used these datasets to test and compare our approach with respect to state-of-the-art methods that consider other 3D formats. Our code is available at https://github.com/divanoLetto/3D_STEP_Classification
Multi-latent Space Alignments for Unsupervised Domain Adaptation in Multi-view 3D Object Detection
Nov 30, 2022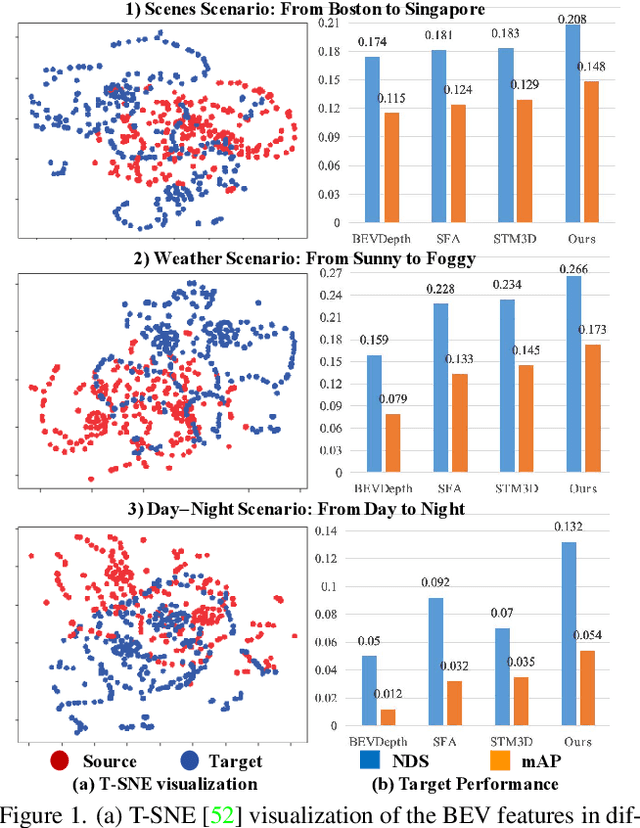
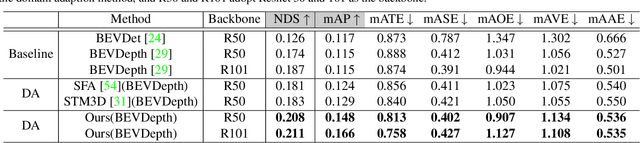
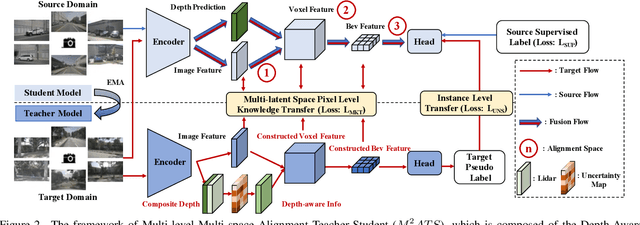
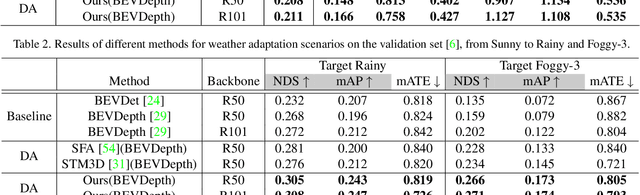
Vision-Centric Bird-Eye-View (BEV) perception has shown promising potential and attracted increasing attention in autonomous driving. Recent works mainly focus on improving efficiency or accuracy but neglect the domain shift problem, resulting in severe degradation of transfer performance. With extensive observations, we figure out the significant domain gaps existing in the scene, weather, and day-night changing scenarios and make the first attempt to solve the domain adaption problem for multi-view 3D object detection. Since BEV perception approaches are usually complicated and contain several components, the domain shift accumulation on multi-latent spaces makes BEV domain adaptation challenging. In this paper, we propose a novel Multi-level Multi-space Alignment Teacher-Student ($M^{2}ATS$) framework to ease the domain shift accumulation, which consists of a Depth-Aware Teacher (DAT) and a Multi-space Feature Aligned (MFA) student model. Specifically, DAT model adopts uncertainty guidance to sample reliable depth information in target domain. After constructing domain-invariant BEV perception, it then transfers pixel and instance-level knowledge to student model. To further alleviate the domain shift at the global level, MFA student model is introduced to align task-relevant multi-space features of two domains. To verify the effectiveness of $M^{2}ATS$, we conduct BEV 3D object detection experiments on four cross domain scenarios and achieve state-of-the-art performance (e.g., +12.6% NDS and +9.1% mAP on Day-Night). Code and dataset will be released.
Attention-based Depth Distillation with 3D-Aware Positional Encoding for Monocular 3D Object Detection
Nov 30, 2022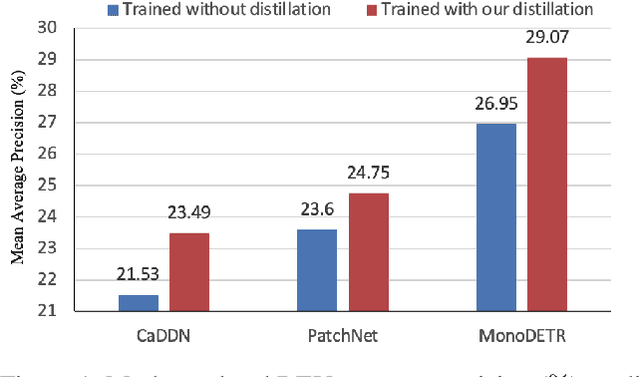
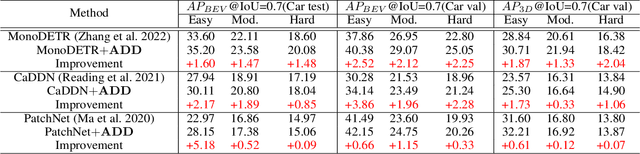
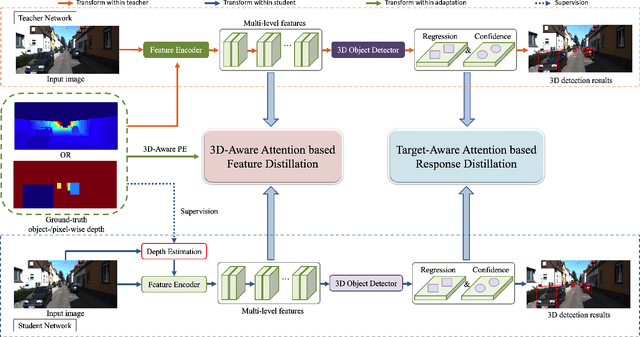
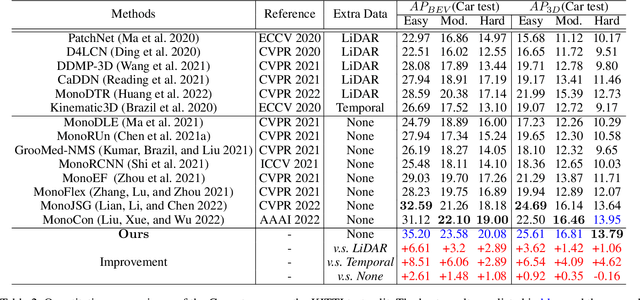
Monocular 3D object detection is a low-cost but challenging task, as it requires generating accurate 3D localization solely from a single image input. Recent developed depth-assisted methods show promising results by using explicit depth maps as intermediate features, which are either precomputed by monocular depth estimation networks or jointly evaluated with 3D object detection. However, inevitable errors from estimated depth priors may lead to misaligned semantic information and 3D localization, hence resulting in feature smearing and suboptimal predictions. To mitigate this issue, we propose ADD, an Attention-based Depth knowledge Distillation framework with 3D-aware positional encoding. Unlike previous knowledge distillation frameworks that adopt stereo- or LiDAR-based teachers, we build up our teacher with identical architecture as the student but with extra ground-truth depth as input. Credit to our teacher design, our framework is seamless, domain-gap free, easily implementable, and is compatible with object-wise ground-truth depth. Specifically, we leverage intermediate features and responses for knowledge distillation. Considering long-range 3D dependencies, we propose \emph{3D-aware self-attention} and \emph{target-aware cross-attention} modules for student adaptation. Extensive experiments are performed to verify the effectiveness of our framework on the challenging KITTI 3D object detection benchmark. We implement our framework on three representative monocular detectors, and we achieve state-of-the-art performance with no additional inference computational cost relative to baseline models. Our code is available at https://github.com/rockywind/ADD.
Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization
Mar 23, 2022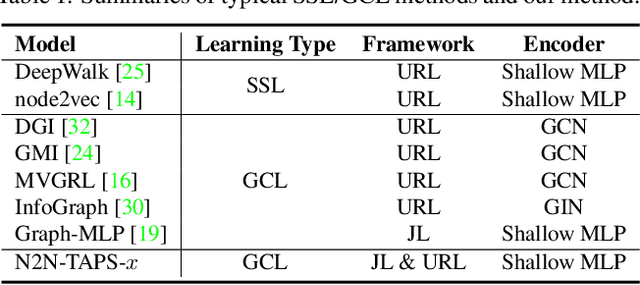
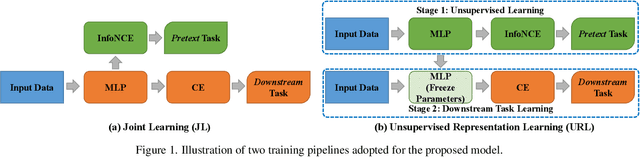
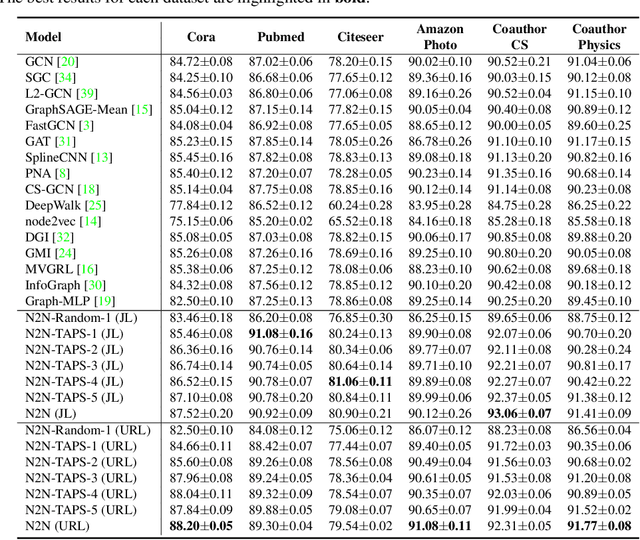
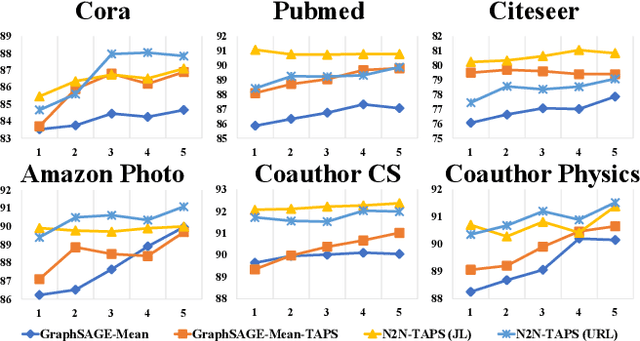
The key towards learning informative node representations in graphs lies in how to gain contextual information from the neighbourhood. In this work, we present a simple-yet-effective self-supervised node representation learning strategy via directly maximizing the mutual information between the hidden representations of nodes and their neighbourhood, which can be theoretically justified by its link to graph smoothing. Following InfoNCE, our framework is optimized via a surrogate contrastive loss, where the positive selection underpins the quality and efficiency of representation learning. To this end, we propose a topology-aware positive sampling strategy, which samples positives from the neighbourhood by considering the structural dependencies between nodes and thus enables positive selection upfront. In the extreme case when only one positive is sampled, we fully avoid expensive neighbourhood aggregation. Our methods achieve promising performance on various node classification datasets. It is also worth mentioning by applying our loss function to MLP based node encoders, our methods can be orders of faster than existing solutions. Our codes and supplementary materials are available at https://github.com/dongwei156/n2n.