 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hand Guided High Resolution Feature Enhancement for Fine-Grained Atomic Action Segmentation within Complex Human Assemblies
Nov 24, 2022
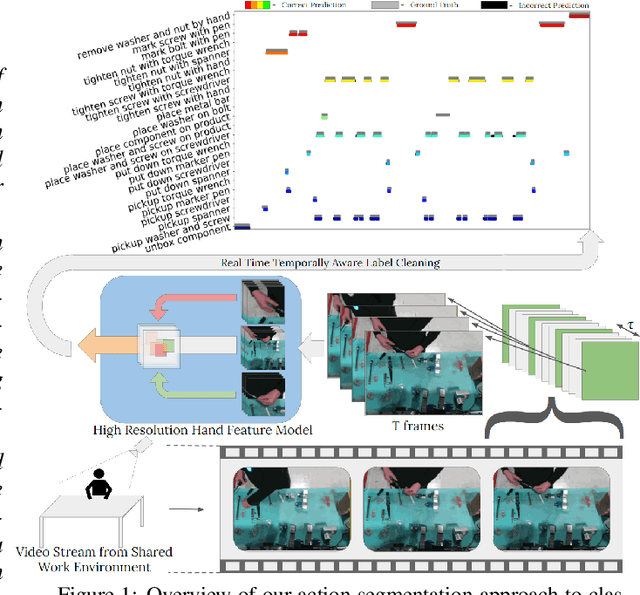
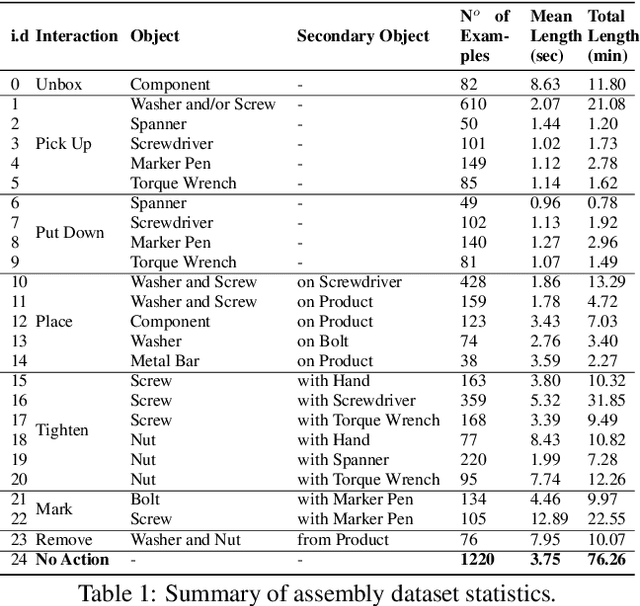
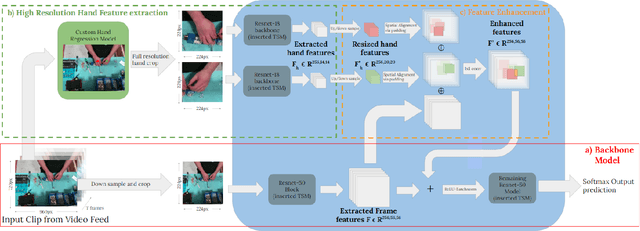
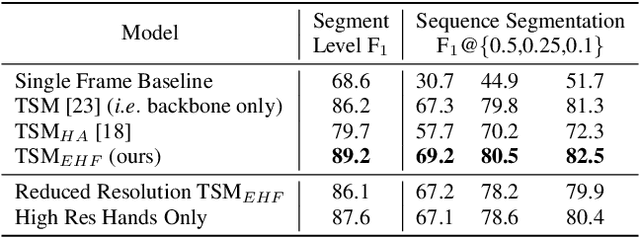
Due to the rapid temporal and fine-grained nature of complex human assembly atomic actions, traditional action segmentation approaches requiring the spatial (and often temporal) down sampling of video frames often loose vital fine-grained spatial and temporal information required for accurate classification within the manufacturing domain. In order to fully utilise higher resolution video data (often collected within the manufacturing domain) and facilitate real time accurate action segmentation - required for human robot collaboration - we present a novel hand location guided high resolution feature enhanced model. We also propose a simple yet effective method of deploying offline trained action recognition models for real time action segmentation on temporally short fine-grained actions, through the use of surround sampling while training and temporally aware label cleaning at inference. We evaluate our model on a novel action segmentation dataset containing 24 (+background) atomic actions from video data of a real world robotics assembly production line. Showing both high resolution hand features as well as traditional frame wide features improve fine-grained atomic action classification, and that though temporally aware label clearing our model is capable of surpassing similar encoder/decoder methods, while allowing for real time classification.
Reduction Algorithms for Persistence Diagrams of Networks: CoralTDA and PrunIT
Nov 24, 2022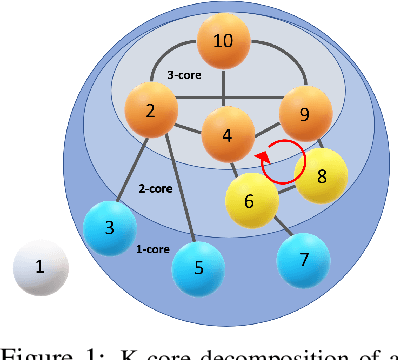


Topological data analysis (TDA) delivers invaluable and complementary information on the intrinsic properties of data inaccessible to conventional methods. However, high computational costs remain the primary roadblock hindering the successful application of TDA in real-world studies, particularly with machine learning on large complex networks. Indeed, most modern networks such as citation, blockchain, and online social networks often have hundreds of thousands of vertices, making the application of existing TDA methods infeasible. We develop two new, remarkably simple but effective algorithms to compute the exact persistence diagrams of large graphs to address this major TDA limitation. First, we prove that $(k+1)$-core of a graph $\mathcal{G}$ suffices to compute its $k^{th}$ persistence diagram, $PD_k(\mathcal{G})$. Second, we introduce a pruning algorithm for graphs to compute their persistence diagrams by removing the dominated vertices. Our experiments on large networks show that our novel approach can achieve computational gains up to 95%. The developed framework provides the first bridge between the graph theory and TDA, with applications in machine learning of large complex networks. Our implementation is available at https://github.com/cakcora/PersistentHomologyWithCoralPrunit
Explaining Image Classifiers with Multiscale Directional Image Representation
Nov 24, 2022
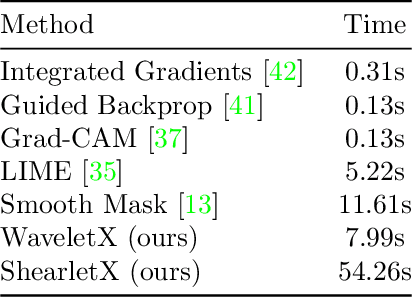


Image classifiers are known to be difficult to interpret and therefore require explanation methods to understand their decisions. We present ShearletX, a novel mask explanation method for image classifiers based on the shearlet transform -- a multiscale directional image representation. Current mask explanation methods are regularized by smoothness constraints that protect against undesirable fine-grained explanation artifacts. However, the smoothness of a mask limits its ability to separate fine-detail patterns, that are relevant for the classifier, from nearby nuisance patterns, that do not affect the classifier. ShearletX solves this problem by avoiding smoothness regularization all together, replacing it by shearlet sparsity constraints. The resulting explanations consist of a few edges, textures, and smooth parts of the original image, that are the most relevant for the decision of the classifier. To support our method, we propose a mathematical definition for explanation artifacts and an information theoretic score to evaluate the quality of mask explanations. We demonstrate the superiority of ShearletX over previous mask based explanation methods using these new metrics, and present exemplary situations where separating fine-detail patterns allows explaining phenomena that were not explainable before.
Online Learning for Non-monotone Submodular Maximization: From Full Information to Bandit Feedback
Aug 16, 2022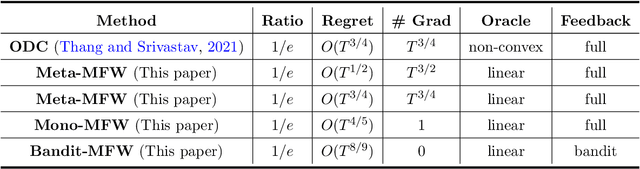
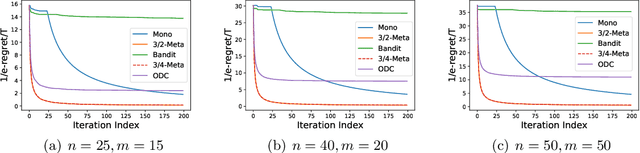
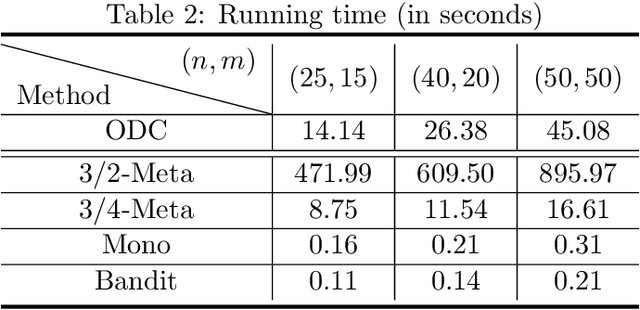
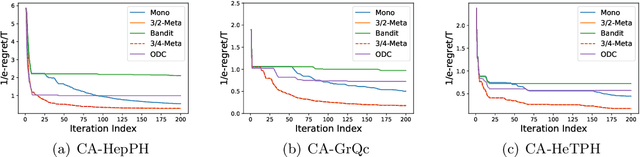
In this paper, we revisit the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, which finds wide real-world applications in the domain of machine learning, economics, and operations research. At first, we present the Meta-MFW algorithm achieving a $1/e$-regret of $O(\sqrt{T})$ at the cost of $T^{3/2}$ stochastic gradient evaluations per round. As far as we know, Meta-MFW is the first algorithm to obtain $1/e$-regret of $O(\sqrt{T})$ for the online non-monotone continuous DR-submodular maximization problem over a down-closed convex set. Furthermore, in sharp contrast with ODC algorithm \citep{thang2021online}, Meta-MFW relies on the simple online linear oracle without discretization, lifting, or rounding operations. Considering the practical restrictions, we then propose the Mono-MFW algorithm, which reduces the per-function stochastic gradient evaluations from $T^{3/2}$ to 1 and achieves a $1/e$-regret bound of $O(T^{4/5})$. Next, we extend Mono-MFW to the bandit setting and propose the Bandit-MFW algorithm which attains a $1/e$-regret bound of $O(T^{8/9})$. To the best of our knowledge, Mono-MFW and Bandit-MFW are the first sublinear-regret algorithms to explore the one-shot and bandit setting for online non-monotone continuous DR-submodular maximization problem over a down-closed convex set, respectively. Finally, we conduct numerical experiments on both synthetic and real-world datasets to verify the effectiveness of our methods.
Attention-based Depth Distillation with 3D-Aware Positional Encoding for Monocular 3D Object Detection
Nov 30, 2022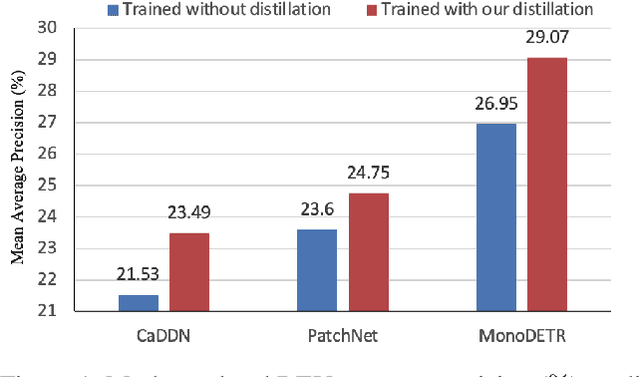
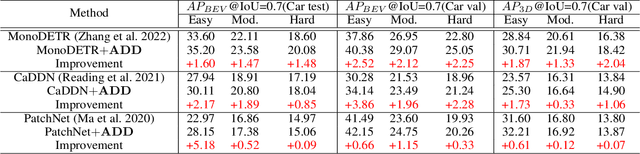
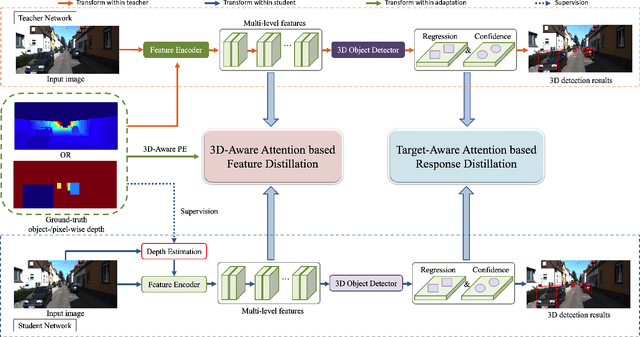
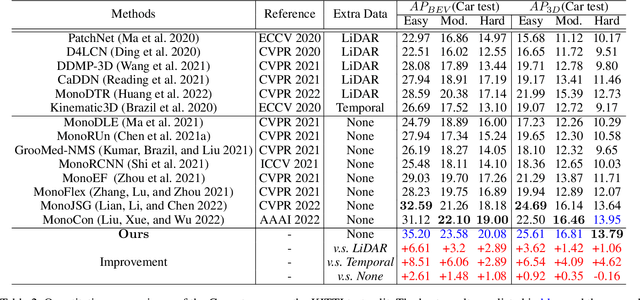
Monocular 3D object detection is a low-cost but challenging task, as it requires generating accurate 3D localization solely from a single image input. Recent developed depth-assisted methods show promising results by using explicit depth maps as intermediate features, which are either precomputed by monocular depth estimation networks or jointly evaluated with 3D object detection. However, inevitable errors from estimated depth priors may lead to misaligned semantic information and 3D localization, hence resulting in feature smearing and suboptimal predictions. To mitigate this issue, we propose ADD, an Attention-based Depth knowledge Distillation framework with 3D-aware positional encoding. Unlike previous knowledge distillation frameworks that adopt stereo- or LiDAR-based teachers, we build up our teacher with identical architecture as the student but with extra ground-truth depth as input. Credit to our teacher design, our framework is seamless, domain-gap free, easily implementable, and is compatible with object-wise ground-truth depth. Specifically, we leverage intermediate features and responses for knowledge distillation. Considering long-range 3D dependencies, we propose \emph{3D-aware self-attention} and \emph{target-aware cross-attention} modules for student adaptation. Extensive experiments are performed to verify the effectiveness of our framework on the challenging KITTI 3D object detection benchmark. We implement our framework on three representative monocular detectors, and we achieve state-of-the-art performance with no additional inference computational cost relative to baseline models. Our code is available at https://github.com/rockywind/ADD.
Multi-latent Space Alignments for Unsupervised Domain Adaptation in Multi-view 3D Object Detection
Nov 30, 2022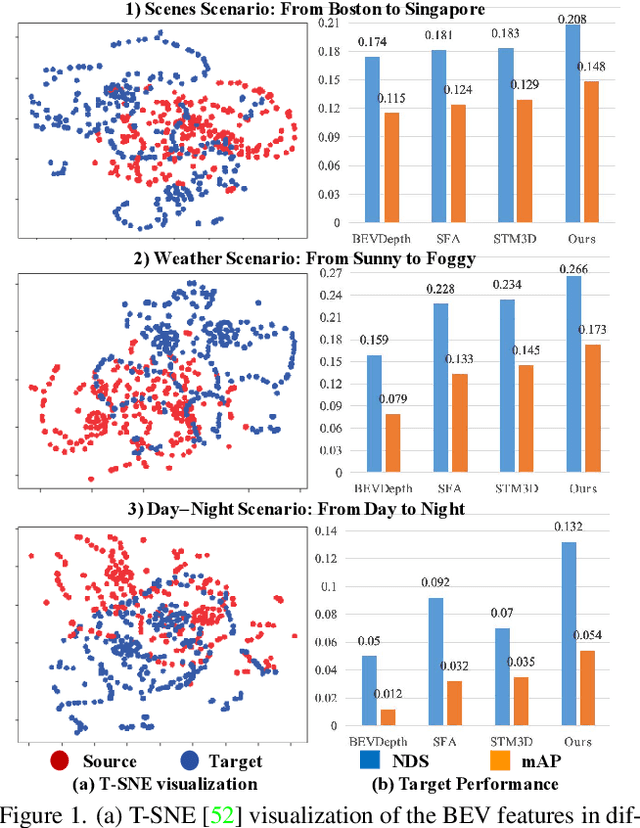
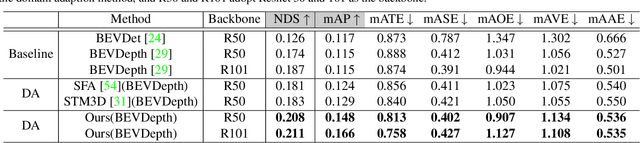
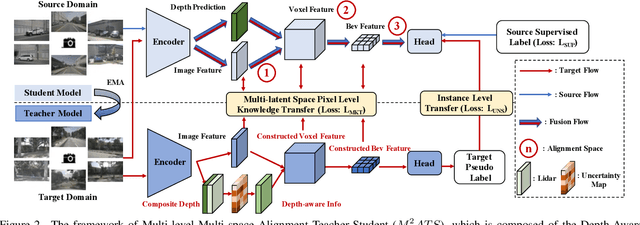
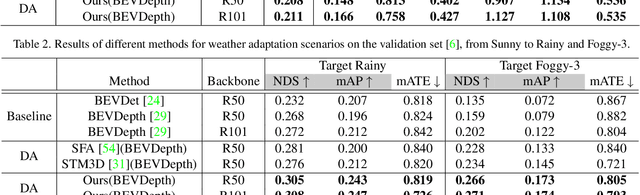
Vision-Centric Bird-Eye-View (BEV) perception has shown promising potential and attracted increasing attention in autonomous driving. Recent works mainly focus on improving efficiency or accuracy but neglect the domain shift problem, resulting in severe degradation of transfer performance. With extensive observations, we figure out the significant domain gaps existing in the scene, weather, and day-night changing scenarios and make the first attempt to solve the domain adaption problem for multi-view 3D object detection. Since BEV perception approaches are usually complicated and contain several components, the domain shift accumulation on multi-latent spaces makes BEV domain adaptation challenging. In this paper, we propose a novel Multi-level Multi-space Alignment Teacher-Student ($M^{2}ATS$) framework to ease the domain shift accumulation, which consists of a Depth-Aware Teacher (DAT) and a Multi-space Feature Aligned (MFA) student model. Specifically, DAT model adopts uncertainty guidance to sample reliable depth information in target domain. After constructing domain-invariant BEV perception, it then transfers pixel and instance-level knowledge to student model. To further alleviate the domain shift at the global level, MFA student model is introduced to align task-relevant multi-space features of two domains. To verify the effectiveness of $M^{2}ATS$, we conduct BEV 3D object detection experiments on four cross domain scenarios and achieve state-of-the-art performance (e.g., +12.6% NDS and +9.1% mAP on Day-Night). Code and dataset will be released.
Machine Learning Approaches for Principle Prediction in Naturally Occurring Stories
Nov 19, 2022
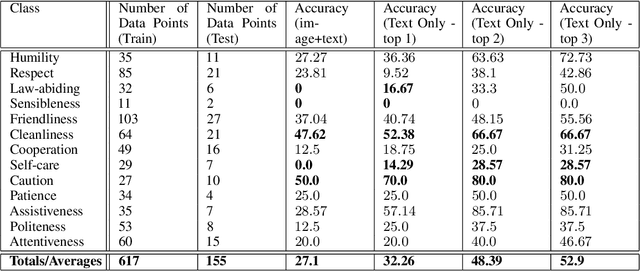

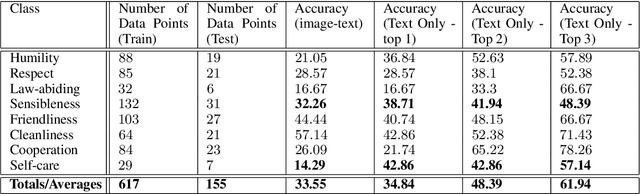
Value alignment is the task of creating autonomous systems whose values align with those of humans. Past work has shown that stories are a potentially rich source of information on human values; however, past work has been limited to considering values in a binary sense. In this work, we explore the use of machine learning models for the task of normative principle prediction on naturally occurring story data. To do this, we extend a dataset that has been previously used to train a binary normative classifier with annotations of moral principles. We then use this dataset to train a variety of machine learning models, evaluate these models and compare their results against humans who were asked to perform the same task. We show that while individual principles can be classified, the ambiguity of what "moral principles" represent, poses a challenge for both human participants and autonomous systems which are faced with the same task.
Towards a Responsible AI Development Lifecycle: Lessons From Information Security
Mar 06, 2022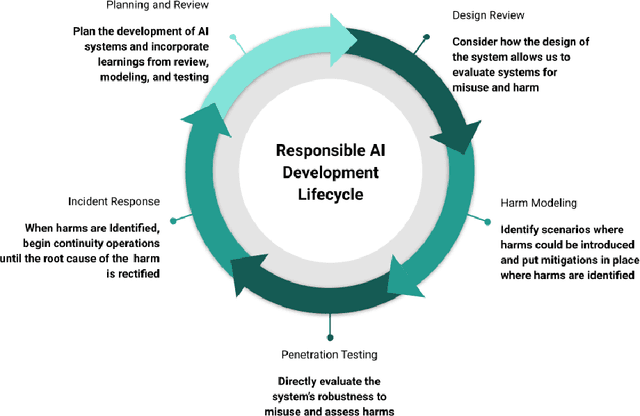
Legislation and public sentiment throughout the world have promoted fairness metrics, explainability, and interpretability as prescriptions for the responsible development of ethical artificial intelligence systems. Despite the importance of these three pillars in the foundation of the field, they can be challenging to operationalize and attempts to solve the problems in production environments often feel Sisyphean. This difficulty stems from a number of factors: fairness metrics are computationally difficult to incorporate into training and rarely alleviate all of the harms perpetrated by these systems. Interpretability and explainability can be gamed to appear fair, may inadvertently reduce the privacy of personal information contained in training data, and increase user confidence in predictions -- even when the explanations are wrong. In this work, we propose a framework for responsibly developing artificial intelligence systems by incorporating lessons from the field of information security and the secure development lifecycle to overcome challenges associated with protecting users in adversarial settings. In particular, we propose leveraging the concepts of threat modeling, design review, penetration testing, and incident response in the context of developing AI systems as ways to resolve shortcomings in the aforementioned methods.
On the Role of Visual Context in Enriching Music Representations
Oct 28, 2022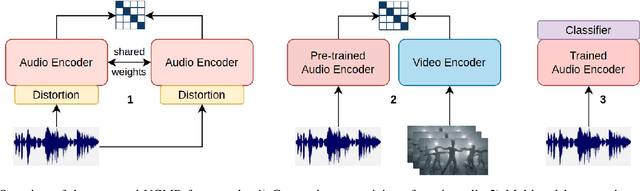
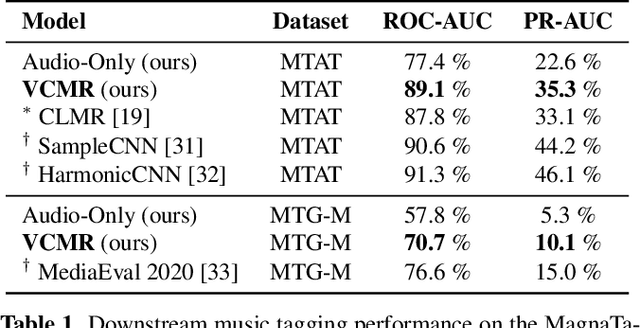
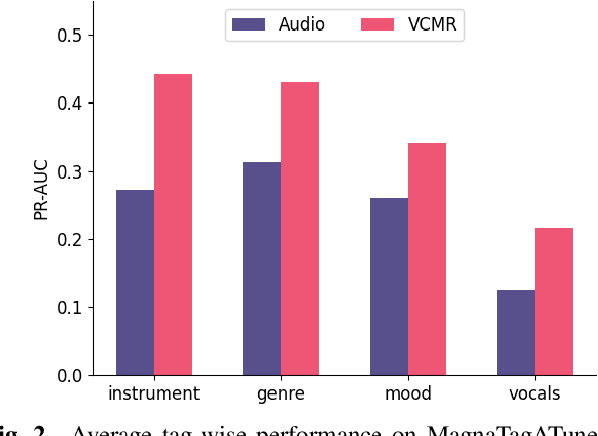
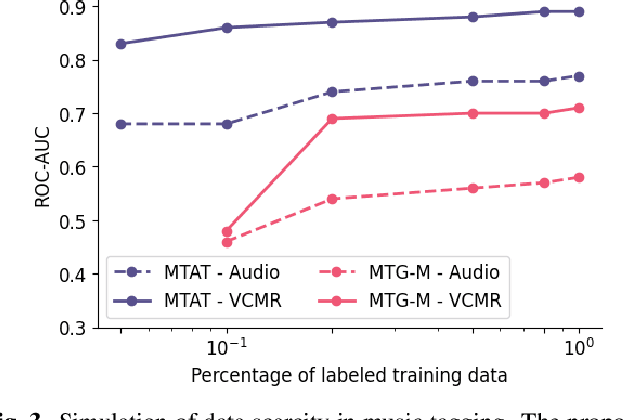
Human perception and experience of music is highly context-dependent. Contextual variability contributes to differences in how we interpret and interact with music, challenging the design of robust models for information retrieval. Incorporating multimodal context from diverse sources provides a promising approach toward modeling this variability. Music presented in media such as movies and music videos provide rich multimodal context that modulates underlying human experiences. However, such context modeling is underexplored, as it requires large amounts of multimodal data along with relevant annotations. Self-supervised learning can help address these challenges by automatically extracting rich, high-level correspondences between different modalities, hence alleviating the need for fine-grained annotations at scale. In this study, we propose VCMR -- Video-Conditioned Music Representations, a contrastive learning framework that learns music representations from audio and the accompanying music videos. The contextual visual information enhances representations of music audio, as evaluated on the downstream task of music tagging. Experimental results show that the proposed framework can contribute additive robustness to audio representations and indicates to what extent musical elements are affected or determined by visual context.
Federated Learning for 5G Base Station Traffic Forecasting
Nov 28, 2022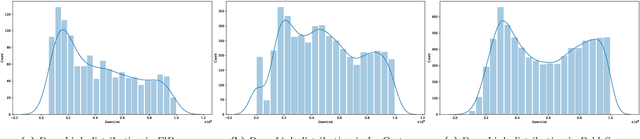
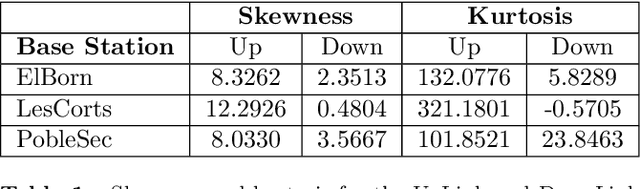
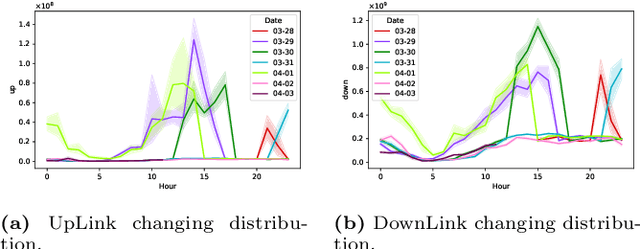
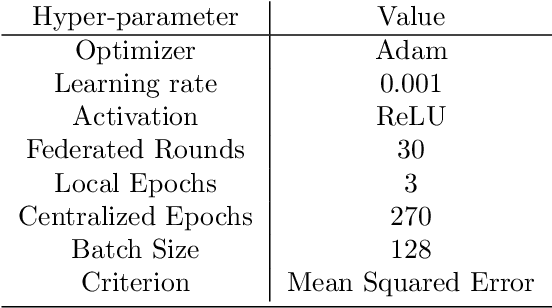
Mobile traffic prediction is of great importance on the path of enabling 5G mobile networks to perform smart and efficient infrastructure planning and management. However, available data are limited to base station logging information. Hence, training methods for generating high-quality predictions that can generalize to new observations on different parties are in demand. Traditional approaches require collecting measurements from different base stations and sending them to a central entity, followed by performing machine learning operations using the received data. The dissemination of local observations raises privacy, confidentiality, and performance concerns, hindering the applicability of machine learning techniques. Various distributed learning methods have been proposed to address this issue, but their application to traffic prediction has yet to be explored. In this work, we study the effectiveness of federated learning applied to raw base station aggregated LTE data for time-series forecasting. We evaluate one-step predictions using 5 different neural network architectures trained with a federated setting on non-iid data. The presented algorithms have been submitted to the Global Federated Traffic Prediction for 5G and Beyond Challenge. Our results show that the learning architectures adapted to the federated setting achieve equivalent prediction error to the centralized setting, pre-processing techniques on base stations lead to higher forecasting accuracy, while state-of-the-art aggregators do not outperform simple approaches.