 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Weakly-supervised detection of AMD-related lesions in color fundus images using explainable deep learning
Dec 04, 2022
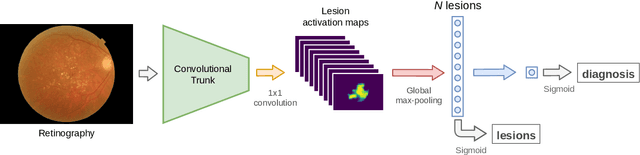
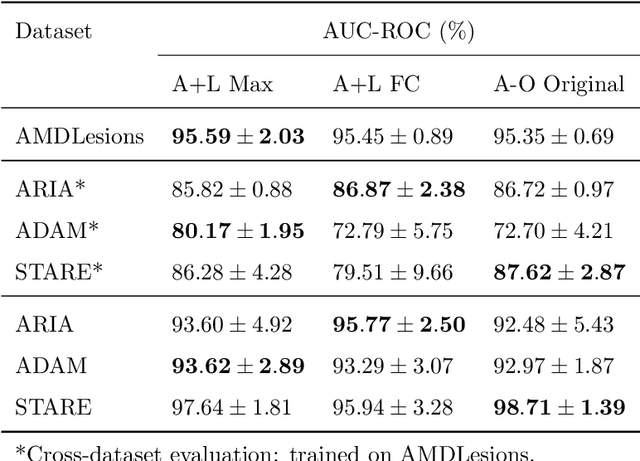
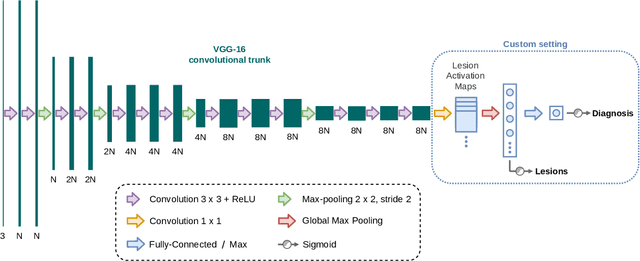
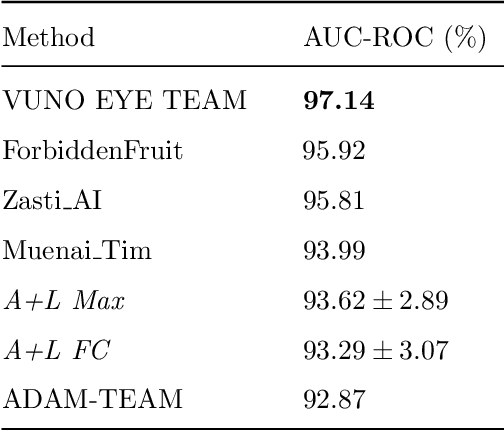
Age-related macular degeneration (AMD) is a degenerative disorder affecting the macula, a key area of the retina for visual acuity. Nowadays, it is the most frequent cause of blindness in developed countries. Although some promising treatments have been developed, their effectiveness is low in advanced stages. This emphasizes the importance of large-scale screening programs. Nevertheless, implementing such programs for AMD is usually unfeasible, since the population at risk is large and the diagnosis is challenging. All this motivates the development of automatic methods. In this sense, several works have achieved positive results for AMD diagnosis using convolutional neural networks (CNNs). However, none incorporates explainability mechanisms, which limits their use in clinical practice. In that regard, we propose an explainable deep learning approach for the diagnosis of AMD via the joint identification of its associated retinal lesions. In our proposal, a CNN is trained end-to-end for the joint task using image-level labels. The provided lesion information is of clinical interest, as it allows to assess the developmental stage of AMD. Additionally, the approach allows to explain the diagnosis from the identified lesions. This is possible thanks to the use of a CNN with a custom setting that links the lesions and the diagnosis. Furthermore, the proposed setting also allows to obtain coarse lesion segmentation maps in a weakly-supervised way, further improving the explainability. The training data for the approach can be obtained without much extra work by clinicians. The experiments conducted demonstrate that our approach can identify AMD and its associated lesions satisfactorily, while providing adequate coarse segmentation maps for most common lesions.
Semantic Guided Level-Category Hybrid Prediction Network for Hierarchical Image Classification
Nov 22, 2022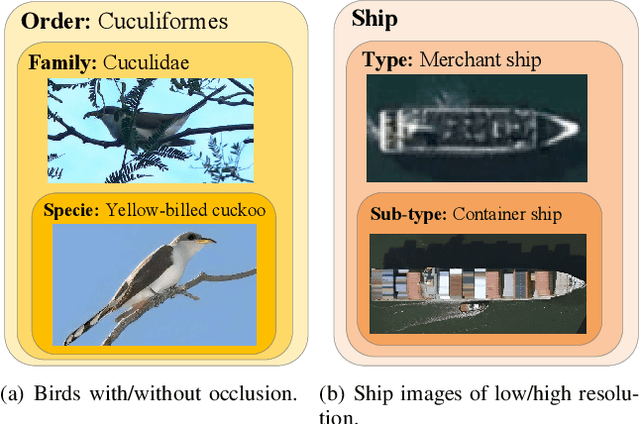

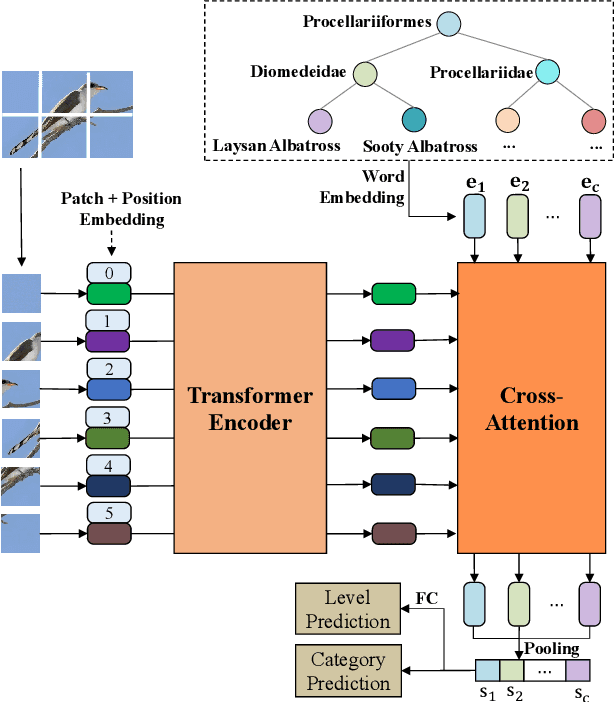
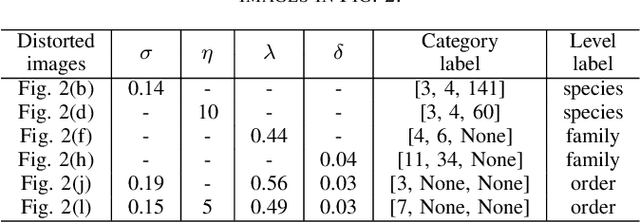
Hierarchical classification (HC) assigns each object with multiple labels organized into a hierarchical structure. The existing deep learning based HC methods usually predict an instance starting from the root node until a leaf node is reached. However, in the real world, images interfered by noise, occlusion, blur, or low resolution may not provide sufficient information for the classification at subordinate levels. To address this issue, we propose a novel semantic guided level-category hybrid prediction network (SGLCHPN) that can jointly perform the level and category prediction in an end-to-end manner. SGLCHPN comprises two modules: a visual transformer that extracts feature vectors from the input images, and a semantic guided cross-attention module that uses categories word embeddings as queries to guide learning category-specific representations. In order to evaluate the proposed method, we construct two new datasets in which images are at a broad range of quality and thus are labeled to different levels (depths) in the hierarchy according to their individual quality. Experimental results demonstrate the effectiveness of our proposed HC method.
Motif-aware temporal GCN for fraud detection in signed cryptocurrency trust networks
Nov 22, 2022

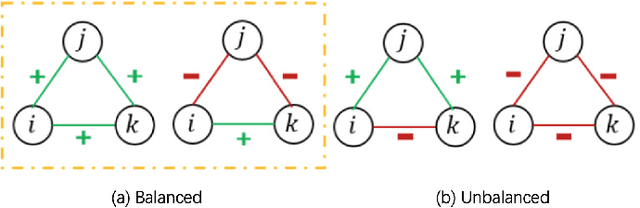
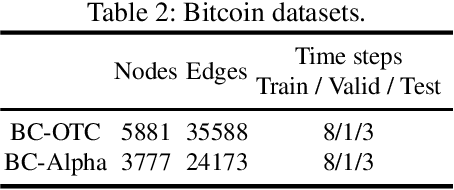
Graph convolutional networks (GCNs) is a class of artificial neural networks for processing data that can be represented as graphs. Since financial transactions can naturally be constructed as graphs, GCNs are widely applied in the financial industry, especially for financial fraud detection. In this paper, we focus on fraud detection on cryptocurrency truct networks. In the literature, most works focus on static networks. Whereas in this study, we consider the evolving nature of cryptocurrency networks, and use local structural as well as the balance theory to guide the training process. More specifically, we compute motif matrices to capture the local topological information, then use them in the GCN aggregation process. The generated embedding at each snapshot is a weighted average of embeddings within a time window, where the weights are learnable parameters. Since the trust networks is signed on each edge, balance theory is used to guide the training process. Experimental results on bitcoin-alpha and bitcoin-otc datasets show that the proposed model outperforms those in the literature.
A Cross-Residual Learning for Image Recognition
Nov 22, 2022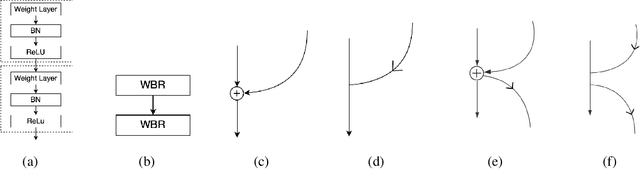
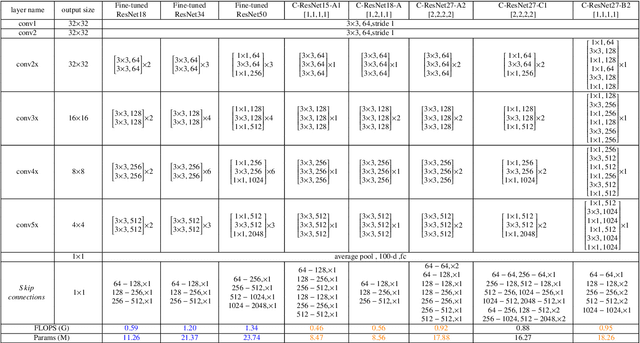
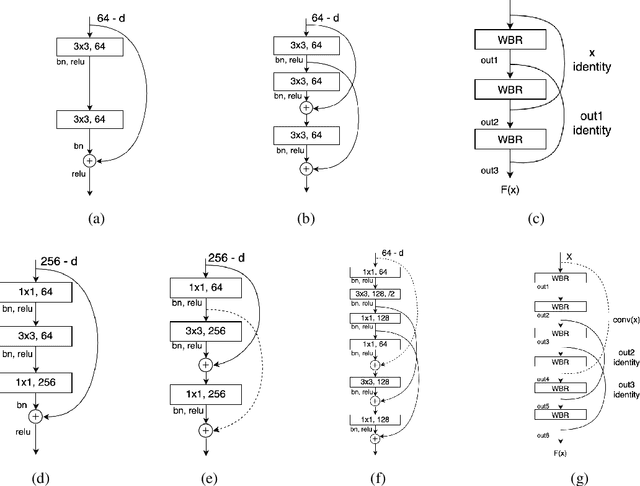
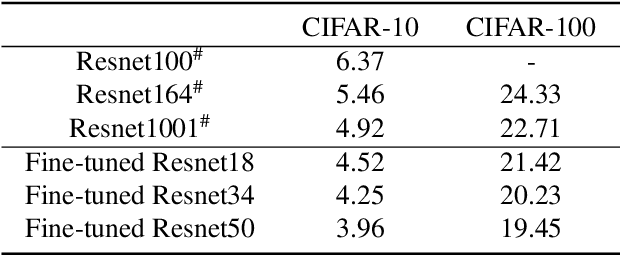
ResNets and its variants play an important role in various fields of image recognition. This paper gives another variant of ResNets, a kind of cross-residual learning networks called C-ResNets, which has less computation and parameters than ResNets. C-ResNets increases the information interaction between modules by densifying jumpers and enriches the role of jumpers. In addition, some meticulous designs on jumpers and channels counts can further reduce the resource consumption of C-ResNets and increase its classification performance. In order to test the effectiveness of C-ResNets, we use the same hyperparameter settings as fine-tuned ResNets in the experiments. We test our C-ResNets on datasets MNIST, FashionMnist, CIFAR-10, CIFAR-100, CALTECH-101 and SVHN. Compared with fine-tuned ResNets, C-ResNets not only maintains the classification performance, but also enormously reduces the amount of calculations and parameters which greatly save the utilization rate of GPUs and GPU memory resources. Therefore, our C-ResNets is competitive and viable alternatives to ResNets in various scenarios. Code is available at https://github.com/liangjunhello/C-ResNet
Device-Agnostic Millimeter Wave Beam Selection using Machine Learning
Nov 22, 2022
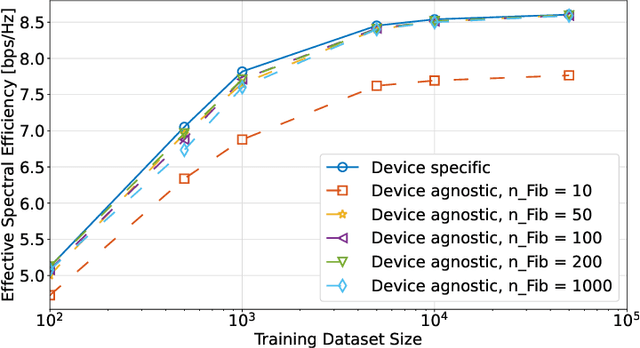
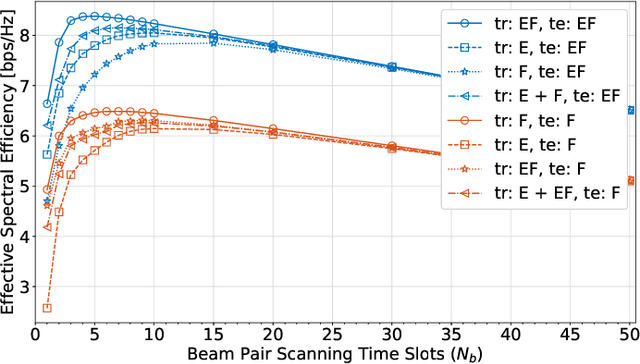
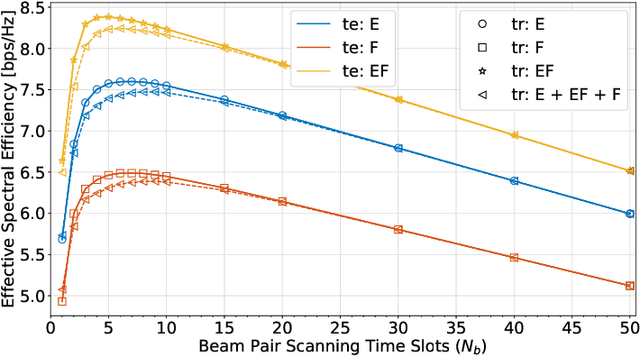
Most research in the area of machine learning-based user beam selection considers a structure where the model proposes appropriate user beams. However, this design requires a specific model for each user-device beam codebook, where a model learned for a device with a particular codebook can not be reused for another device with a different codebook. Moreover, this design requires training and test samples for each antenna placement configuration/codebook. This paper proposes a device-agnostic beam selection framework that leverages context information to propose appropriate user beams using a generic model and a post processing unit. The generic neural network predicts the potential angles of arrival, and the post processing unit maps these directions to beams based on the specific device's codebook. The proposed beam selection framework works well for user devices with antenna configuration/codebook unseen in the training dataset. Also, the proposed generic network has the option to be trained with a dataset mixed of samples with different antenna configurations/codebooks, which significantly eases the burden of effective model training.
Continuous Emotion Recognition using Visual-audio-linguistic information: A Technical Report for ABAW3
Mar 30, 2022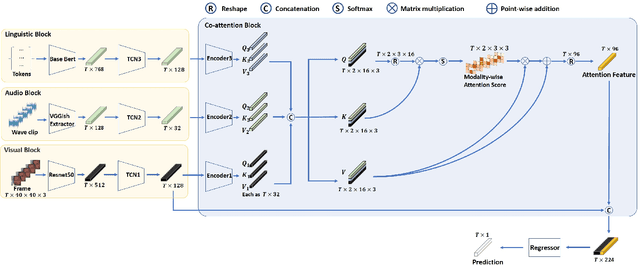
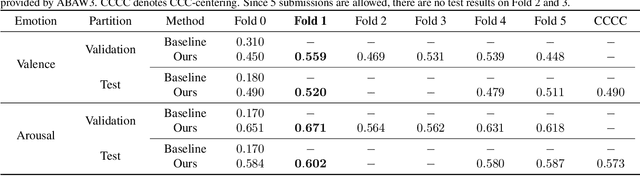
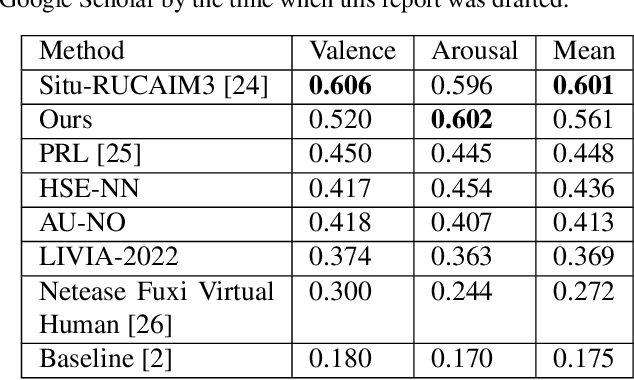
We propose a cross-modal co-attention model for continuous emotion recognition using visual-audio-linguistic information. The model consists of four blocks. The visual, audio, and linguistic blocks are used to learn the spatial-temporal features of the multi-modal input. A co-attention block is designed to fuse the learned features with the multi-head co-attention mechanism. The visual encoding from the visual block is concatenated with the attention feature to emphasize the visual information. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. The achieved CCC on the test set is $0.520$ for valence and $0.602$ for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.180 and 0.170 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW3.
MyoPS-Net: Myocardial Pathology Segmentation with Flexible Combination of Multi-Sequence CMR Images
Nov 06, 2022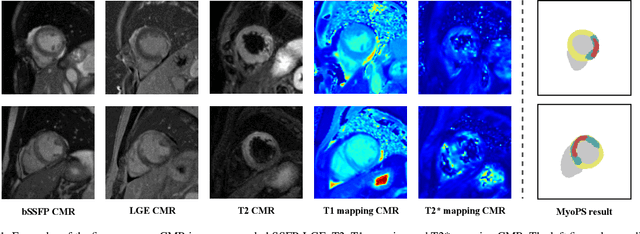

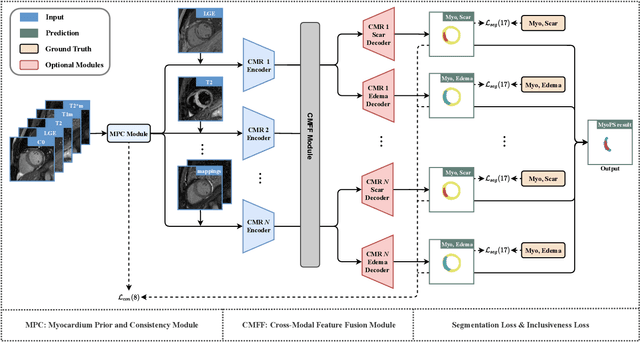
Myocardial pathology segmentation (MyoPS) can be a prerequisite for the accurate diagnosis and treatment planning of myocardial infarction. However, achieving this segmentation is challenging, mainly due to the inadequate and indistinct information from an image. In this work, we develop an end-to-end deep neural network, referred to as MyoPS-Net, to flexibly combine five-sequence cardiac magnetic resonance (CMR) images for MyoPS. To extract precise and adequate information, we design an effective yet flexible architecture to extract and fuse cross-modal features. This architecture can tackle different numbers of CMR images and complex combinations of modalities, with output branches targeting specific pathologies. To impose anatomical knowledge on the segmentation results, we first propose a module to regularize myocardium consistency and localize the pathologies, and then introduce an inclusiveness loss to utilize relations between myocardial scars and edema. We evaluated the proposed MyoPS-Net on two datasets, i.e., a private one consisting of 50 paired multi-sequence CMR images and a public one from MICCAI2020 MyoPS Challenge. Experimental results showed that MyoPS-Net could achieve state-of-the-art performance in various scenarios. Note that in practical clinics, the subjects may not have full sequences, such as missing LGE CMR or mapping CMR scans. We therefore conducted extensive experiments to investigate the performance of the proposed method in dealing with such complex combinations of different CMR sequences. Results proved the superiority and generalizability of MyoPS-Net, and more importantly, indicated a practical clinical application.
Depth-based Sampling and Steering Constraints for Memoryless Local Planners
Nov 06, 2022

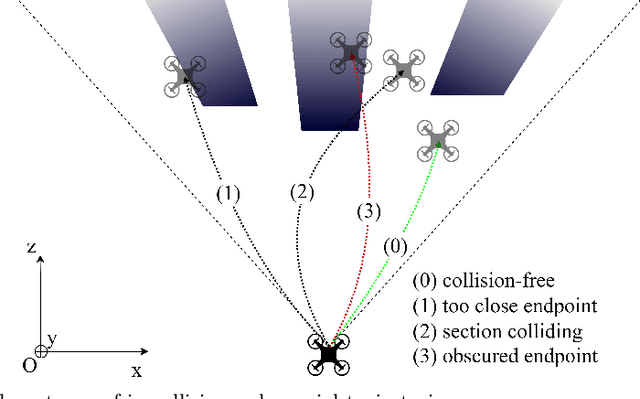
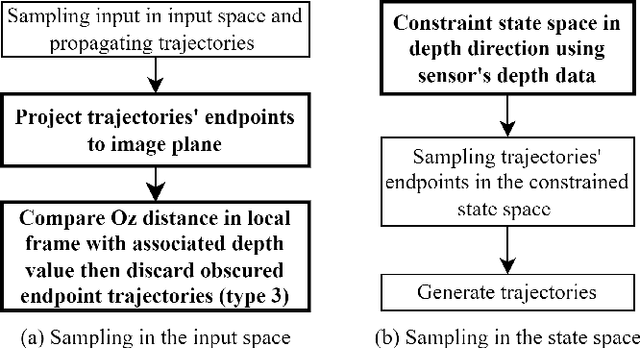
By utilizing only depth information, the paper introduces a novel but efficient local planning approach that enhances not only computational efficiency but also planning performances for memoryless local planners. The sampling is first proposed to be based on the depth data which can identify and eliminate a specific type of in-collision trajectories in the sampled motion primitive library. More specifically, all the obscured primitives' endpoints are found through querying the depth values and excluded from the sampled set, which can significantly reduce the computational workload required in collision checking. On the other hand, we furthermore propose a steering mechanism also based on the depth information to effectively prevent an autonomous vehicle from getting stuck when facing a large convex obstacle, providing a higher level of autonomy for a planning system. Our steering technique is theoretically proved to be complete in scenarios of convex obstacles. To evaluate effectiveness of the proposed DEpth based both Sampling and Steering (DESS) methods, we implemented them in the synthetic environments where a quadrotor was simulated flying through a cluttered region with multiple size-different obstacles. The obtained results demonstrate that the proposed approach can considerably decrease computing time in local planners, where more trajectories can be evaluated while the best path with much lower cost can be found. More importantly, the success rates calculated by the fact that the robot successfully navigated to the destinations in different testing scenarios are always higher than 99.6% on average.
Confidence-Ranked Reconstruction of Census Microdata from Published Statistics
Nov 06, 2022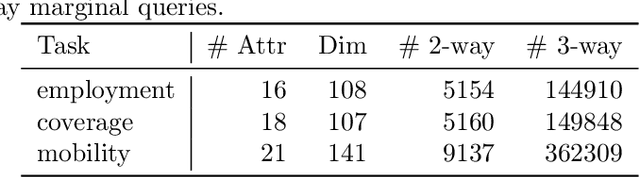
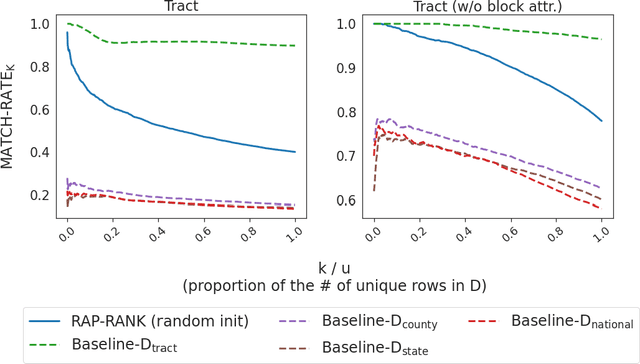
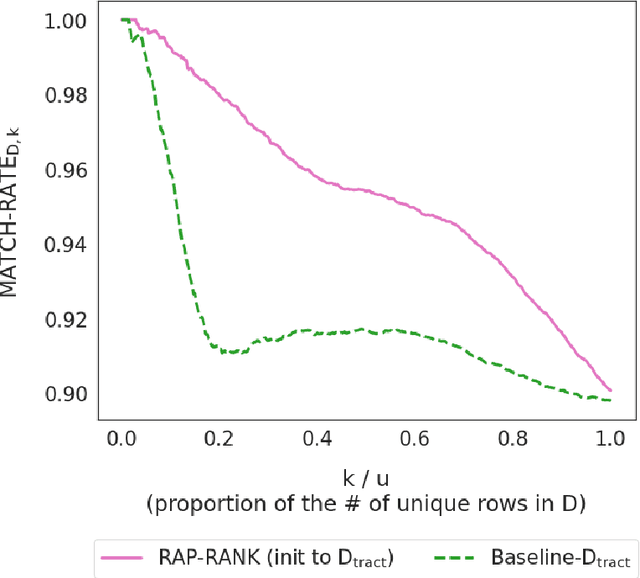

A reconstruction attack on a private dataset $D$ takes as input some publicly accessible information about the dataset and produces a list of candidate elements of $D$. We introduce a new class of data reconstruction attacks based on randomized methods for non-convex optimization. We empirically demonstrate that our attacks can not only reconstruct full rows of $D$ from aggregate query statistics $Q(D)\in \mathbb{R}^m$, but can do so in a way that reliably ranks reconstructed rows by their odds of appearing in the private data, providing a signature that could be used for prioritizing reconstructed rows for further actions such as identify theft or hate crime. We also design a sequence of baselines for evaluating reconstruction attacks. Our attacks significantly outperform those that are based only on access to a public distribution or population from which the private dataset $D$ was sampled, demonstrating that they are exploiting information in the aggregate statistics $Q(D)$, and not simply the overall structure of the distribution. In other words, the queries $Q(D)$ are permitting reconstruction of elements of this dataset, not the distribution from which $D$ was drawn. These findings are established both on 2010 U.S. decennial Census data and queries and Census-derived American Community Survey datasets. Taken together, our methods and experiments illustrate the risks in releasing numerically precise aggregate statistics of a large dataset, and provide further motivation for the careful application of provably private techniques such as differential privacy.
Music Instrument Classification Reprogrammed
Nov 15, 2022
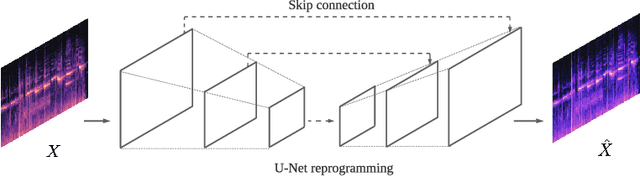
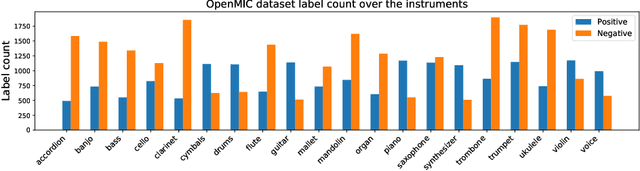
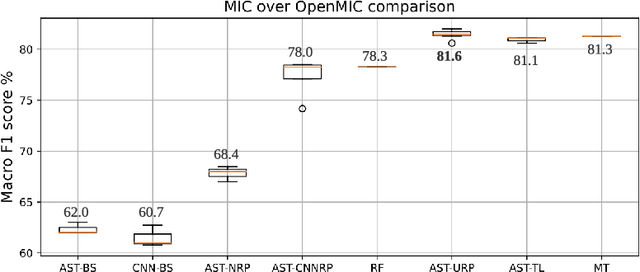
The performance of approaches to Music Instrument Classification, a popular task in Music Information Retrieval, is often impacted and limited by the lack of availability of annotated data for training. We propose to address this issue with "reprogramming," a technique that utilizes pre-trained deep and complex neural networks originally targeting a different task by modifying and mapping both the input and output of the pre-trained model. We demonstrate that reprogramming can effectively leverage the power of the representation learned for a different task and that the resulting reprogrammed system can perform on par or even outperform state-of-the-art systems at a fraction of training parameters. Our results, therefore, indicate that reprogramming is a promising technique potentially applicable to other tasks impeded by data scarcity.