 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Field Transformer for Diabetic Retinopathy Grading on Two-field Fundus Images
Dec 01, 2022
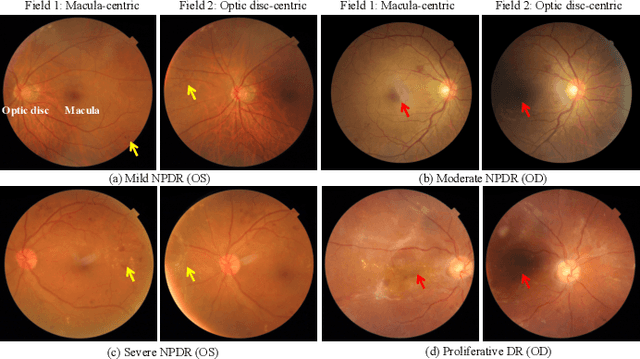
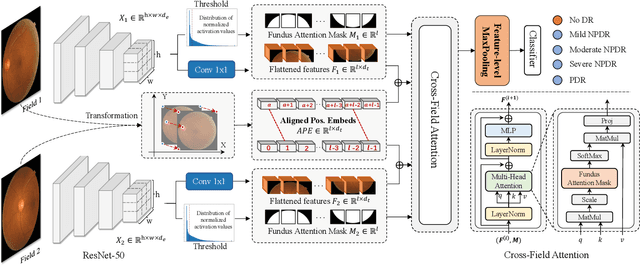
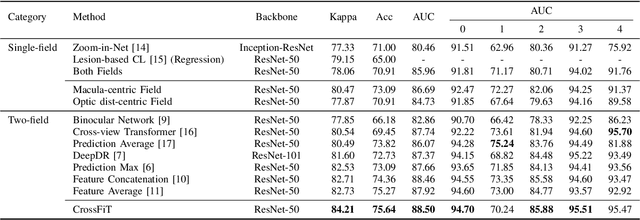
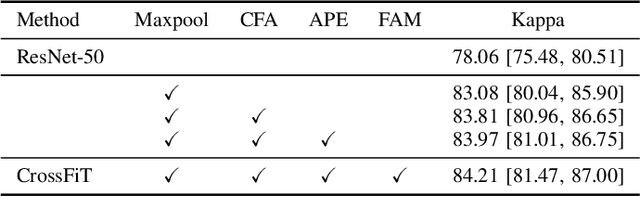
Automatic diabetic retinopathy (DR) grading based on fundus photography has been widely explored to benefit the routine screening and early treatment. Existing researches generally focus on single-field fundus images, which have limited field of view for precise eye examinations. In clinical applications, ophthalmologists adopt two-field fundus photography as the dominating tool, where the information from each field (i.e.,macula-centric and optic disc-centric) is highly correlated and complementary, and benefits comprehensive decisions. However, automatic DR grading based on two-field fundus photography remains a challenging task due to the lack of publicly available datasets and effective fusion strategies. In this work, we first construct a new benchmark dataset (DRTiD) for DR grading, consisting of 3,100 two-field fundus images. To the best of our knowledge, it is the largest public DR dataset with diverse and high-quality two-field images. Then, we propose a novel DR grading approach, namely Cross-Field Transformer (CrossFiT), to capture the correspondence between two fields as well as the long-range spatial correlations within each field. Considering the inherent two-field geometric constraints, we particularly define aligned position embeddings to preserve relative consistent position in fundus. Besides, we perform masked cross-field attention during interaction to flter the noisy relations between fields. Extensive experiments on our DRTiD dataset and a public DeepDRiD dataset demonstrate the effectiveness of our CrossFiT network. The new dataset and the source code of CrossFiT will be publicly available at https://github.com/FDU-VTS/DRTiD.
All You Need Is Hashing: Defending Against Data Reconstruction Attack in Vertical Federated Learning
Dec 01, 2022
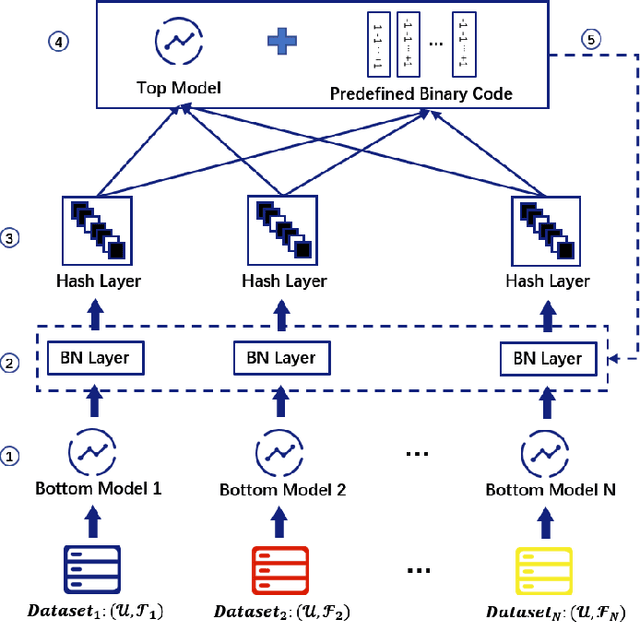
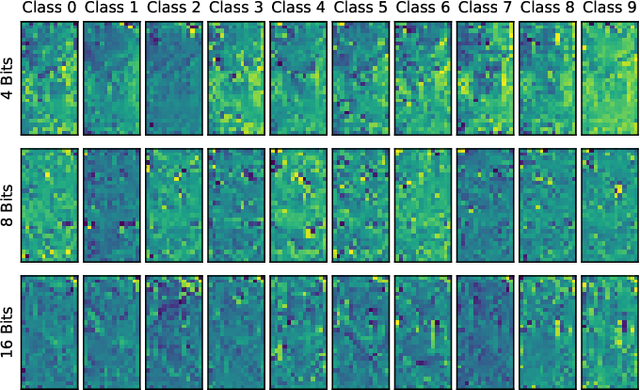
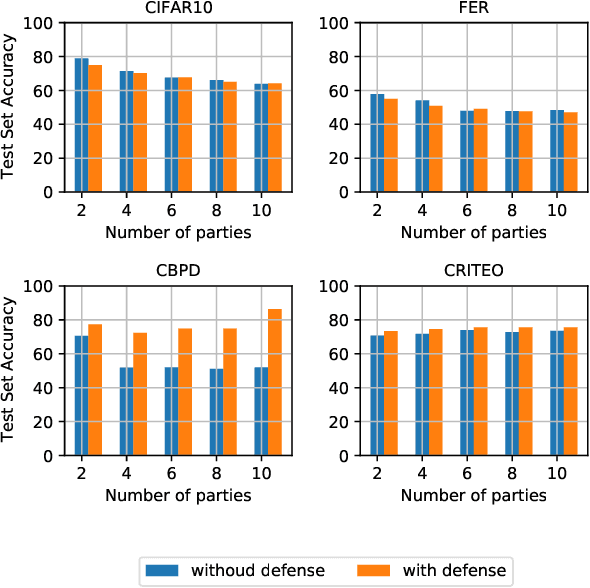
Vertical federated learning is a trending solution for multi-party collaboration in training machine learning models. Industrial frameworks adopt secure multi-party computation methods such as homomorphic encryption to guarantee data security and privacy. However, a line of work has revealed that there are still leakage risks in VFL. The leakage is caused by the correlation between the intermediate representations and the raw data. Due to the powerful approximation ability of deep neural networks, an adversary can capture the correlation precisely and reconstruct the data. To deal with the threat of the data reconstruction attack, we propose a hashing-based VFL framework, called \textit{HashVFL}, to cut off the reversibility directly. The one-way nature of hashing allows our framework to block all attempts to recover data from hash codes. However, integrating hashing also brings some challenges, e.g., the loss of information. This paper proposes and addresses three challenges to integrating hashing: learnability, bit balance, and consistency. Experimental results demonstrate \textit{HashVFL}'s efficiency in keeping the main task's performance and defending against data reconstruction attacks. Furthermore, we also analyze its potential value in detecting abnormal inputs. In addition, we conduct extensive experiments to prove \textit{HashVFL}'s generalization in various settings. In summary, \textit{HashVFL} provides a new perspective on protecting multi-party's data security and privacy in VFL. We hope our study can attract more researchers to expand the application domains of \textit{HashVFL}.
Experimental Observations of the Topology of Convolutional Neural Network Activations
Dec 01, 2022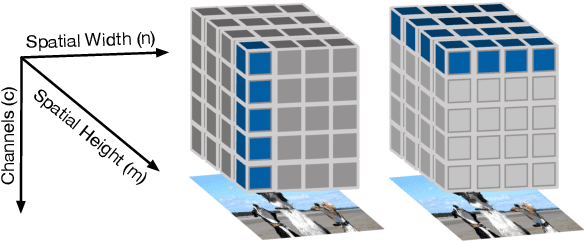
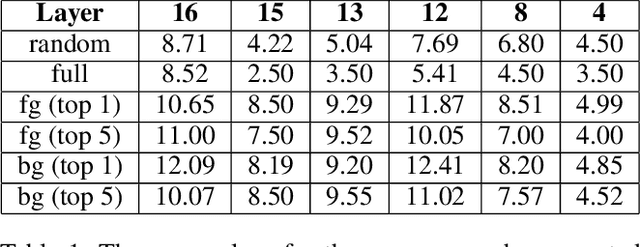
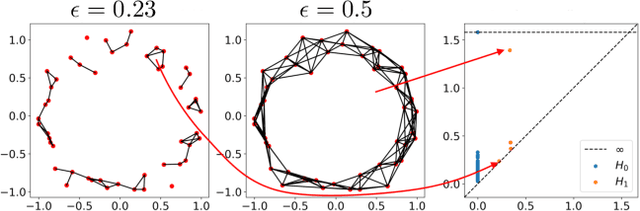
Topological data analysis (TDA) is a branch of computational mathematics, bridging algebraic topology and data science, that provides compact, noise-robust representations of complex structures. Deep neural networks (DNNs) learn millions of parameters associated with a series of transformations defined by the model architecture, resulting in high-dimensional, difficult-to-interpret internal representations of input data. As DNNs become more ubiquitous across multiple sectors of our society, there is increasing recognition that mathematical methods are needed to aid analysts, researchers, and practitioners in understanding and interpreting how these models' internal representations relate to the final classification. In this paper, we apply cutting edge techniques from TDA with the goal of gaining insight into the interpretability of convolutional neural networks used for image classification. We use two common TDA approaches to explore several methods for modeling hidden-layer activations as high-dimensional point clouds, and provide experimental evidence that these point clouds capture valuable structural information about the model's process. First, we demonstrate that a distance metric based on persistent homology can be used to quantify meaningful differences between layers, and we discuss these distances in the broader context of existing representational similarity metrics for neural network interpretability. Second, we show that a mapper graph can provide semantic insight into how these models organize hierarchical class knowledge at each layer. These observations demonstrate that TDA is a useful tool to help deep learning practitioners unlock the hidden structures of their models.
Perceptual Grouping in Vision-Language Models
Oct 18, 2022
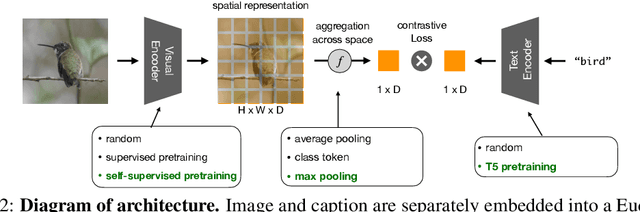
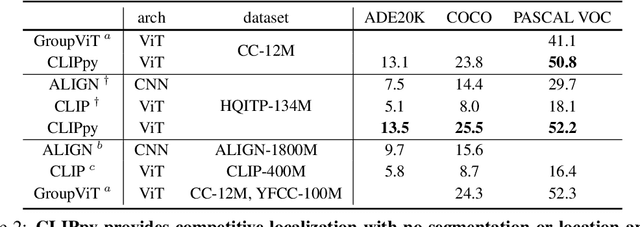
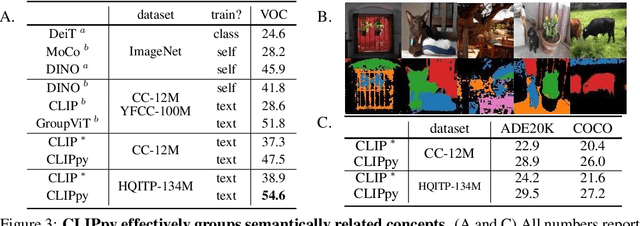
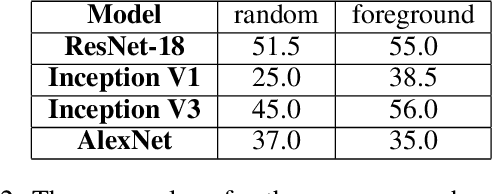
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.
Proficiency assessment of L2 spoken English using wav2vec 2.0
Oct 24, 2022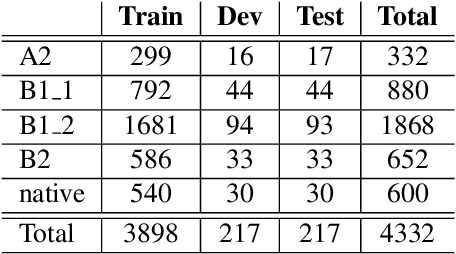
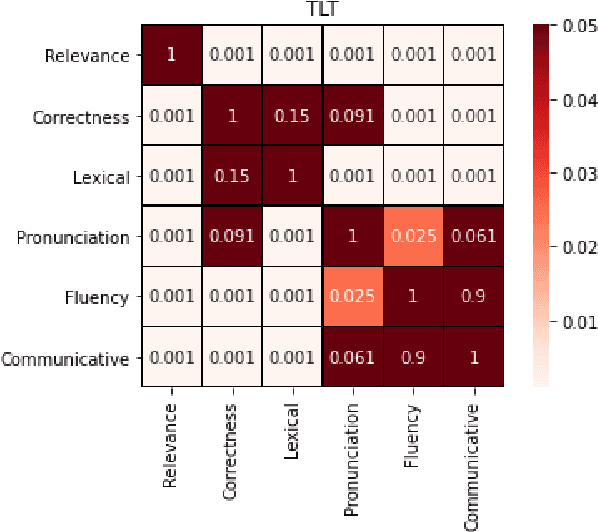
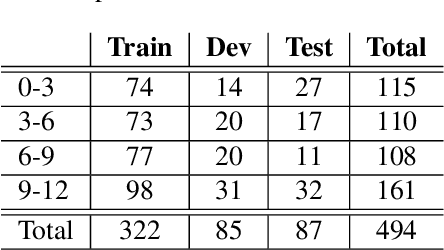
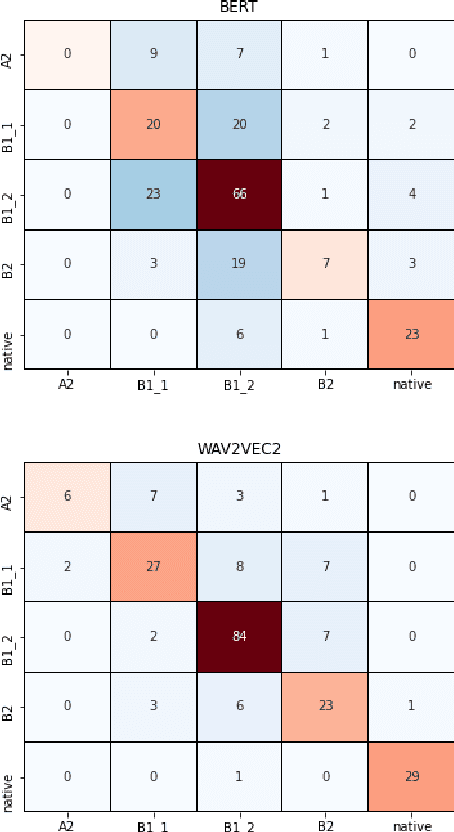
The increasing demand for learning English as a second language has led to a growing interest in methods for automatically assessing spoken language proficiency. Most approaches use hand-crafted features, but their efficacy relies on their particular underlying assumptions and they risk discarding potentially salient information about proficiency. Other approaches rely on transcriptions produced by ASR systems which may not provide a faithful rendition of a learner's utterance in specific scenarios (e.g., non-native children's spontaneous speech). Furthermore, transcriptions do not yield any information about relevant aspects such as intonation, rhythm or prosody. In this paper, we investigate the use of wav2vec 2.0 for assessing overall and individual aspects of proficiency on two small datasets, one of which is publicly available. We find that this approach significantly outperforms the BERT-based baseline system trained on ASR and manual transcriptions used for comparison.
FAF: A novel multimodal emotion recognition approach integrating face, body and text
Nov 20, 2022

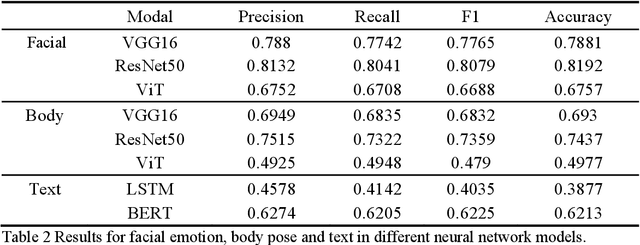
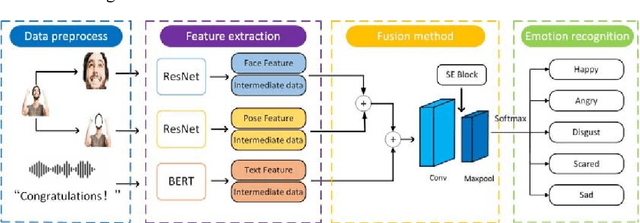
Multimodal emotion analysis performed better in emotion recognition depending on more comprehensive emotional clues and multimodal emotion dataset. In this paper, we developed a large multimodal emotion dataset, named "HED" dataset, to facilitate the emotion recognition task, and accordingly propose a multimodal emotion recognition method. To promote recognition accuracy, "Feature After Feature" framework was used to explore crucial emotional information from the aligned face, body and text samples. We employ various benchmarks to evaluate the "HED" dataset and compare the performance with our method. The results show that the five classification accuracy of the proposed multimodal fusion method is about 83.75%, and the performance is improved by 1.83%, 9.38%, and 21.62% respectively compared with that of individual modalities. The complementarity between each channel is effectively used to improve the performance of emotion recognition. We had also established a multimodal online emotion prediction platform, aiming to provide free emotion prediction to more users.
RHCO: A Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning for Large-scale Graphs
Nov 20, 2022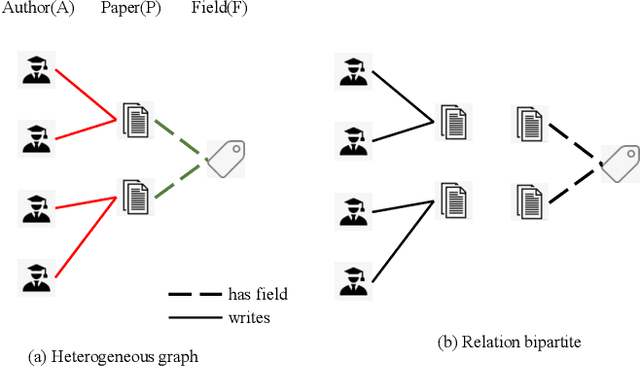
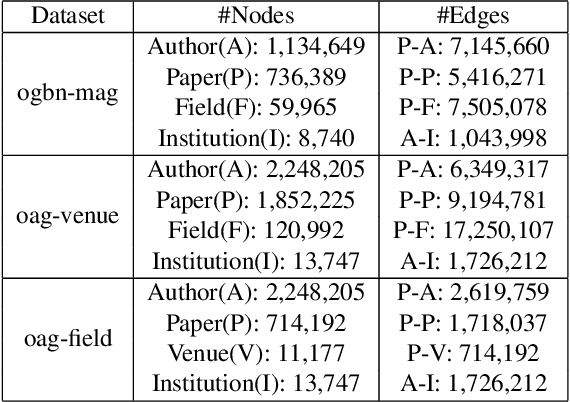
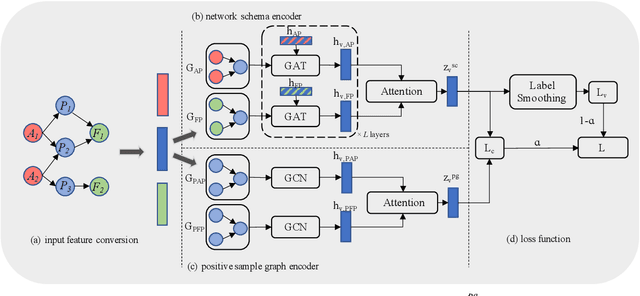
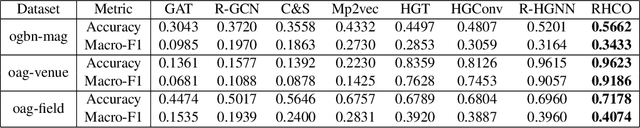
Heterogeneous graph neural networks (HGNNs) have been widely applied in heterogeneous information network tasks, while most HGNNs suffer from poor scalability or weak representation when they are applied to large-scale heterogeneous graphs. To address these problems, we propose a novel Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning (RHCO) for large-scale heterogeneous graph representation learning. Unlike traditional heterogeneous graph neural networks, we adopt the contrastive learning mechanism to deal with the complex heterogeneity of large-scale heterogeneous graphs. We first learn relation-aware node embeddings under the network schema view. Then we propose a novel positive sample selection strategy to choose meaningful positive samples. After learning node embeddings under the positive sample graph view, we perform a cross-view contrastive learning to obtain the final node representations. Moreover, we adopt the label smoothing technique to boost the performance of RHCO. Extensive experiments on three large-scale academic heterogeneous graph datasets show that RHCO achieves best performance over the state-of-the-art models.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 20, 2022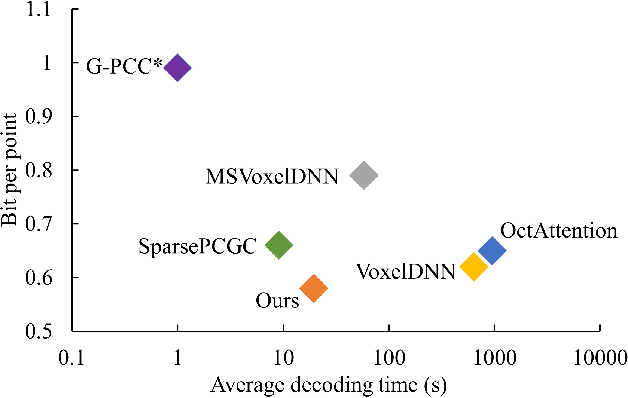
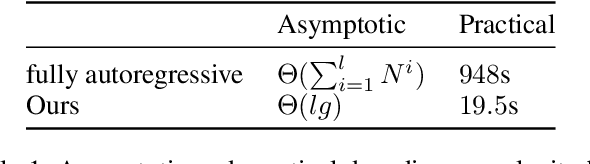
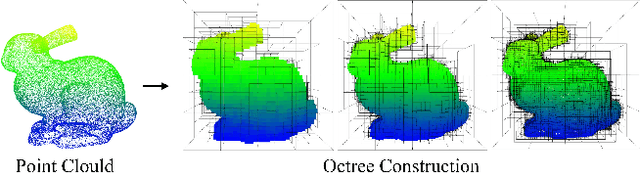
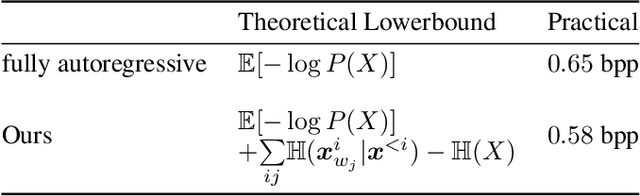
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
ThreshNet: Segmentation Refinement Inspired by Region-Specific Thresholding
Nov 20, 2022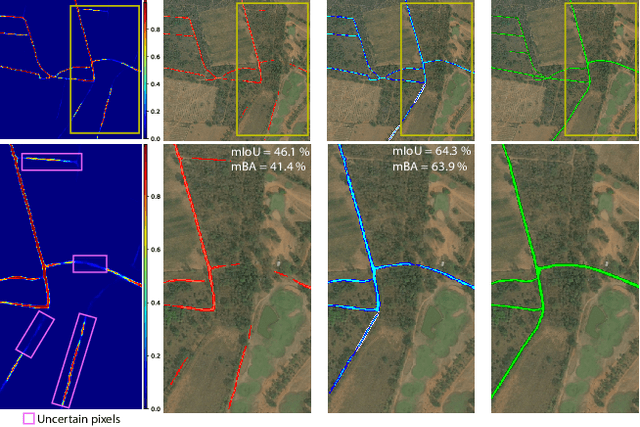
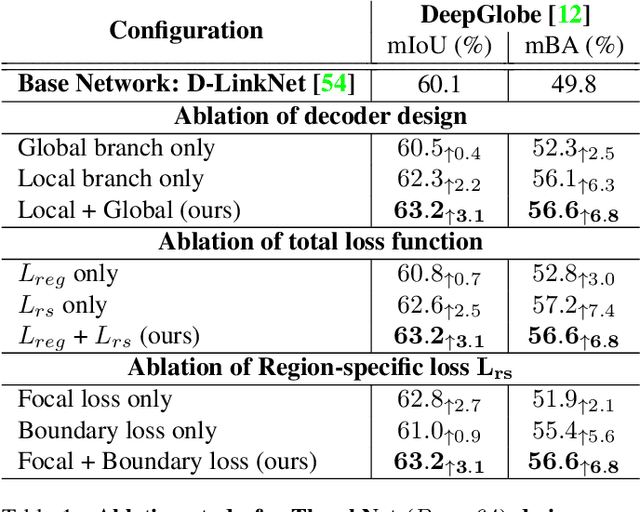
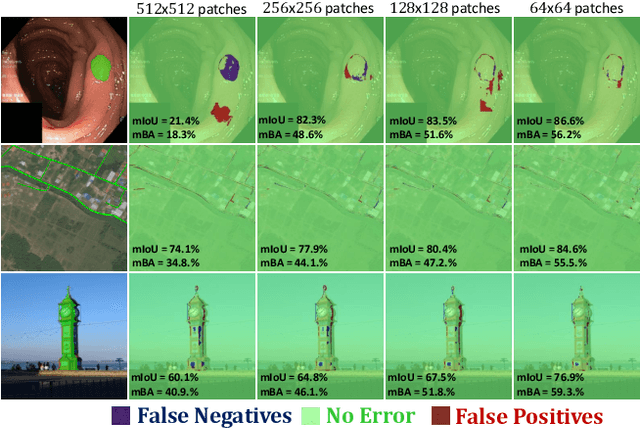
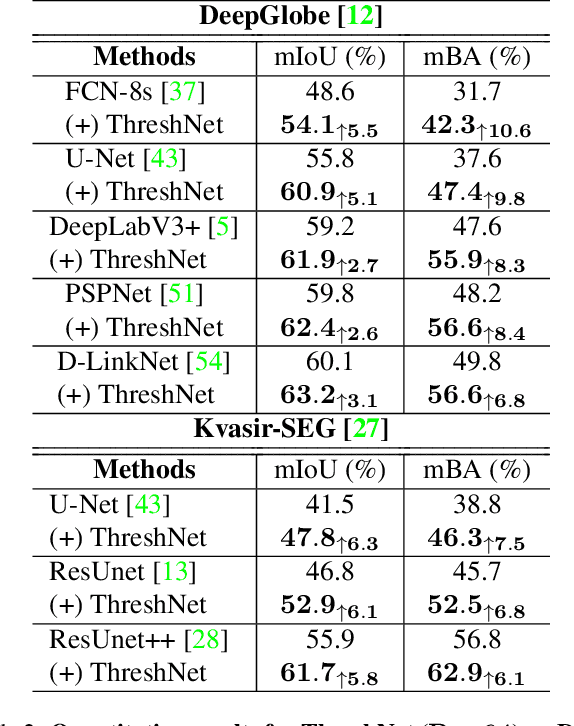
We present ThreshNet, a post-processing method to refine the output of neural networks designed for binary segmentation tasks. ThreshNet uses the confidence map produced by a base network along with global and local patch information to significantly improve the performance of even state-of-the-art methods. Binary segmentation models typically convert confidence maps into predictions by thresholding the confidence scores at 0.5 (or some other fixed number). However, we observe that the best threshold is image-dependent and often even region-specific -- different parts of the image benefit from using different thresholds. Thus ThreshNet takes a trained segmentation model and learns to correct its predictions by using a memory-efficient post-processing architecture that incorporates region-specific thresholds as part of the training mechanism. Our experiments show that ThreshNet consistently improves over current the state-of-the-art methods in binary segmentation and saliency detection, typically by 3 to 5% in mIoU and mBA.
Training Deep Learning Models for Massive MIMO CSI Feedback with Small Datasets in New Environments
Nov 27, 2022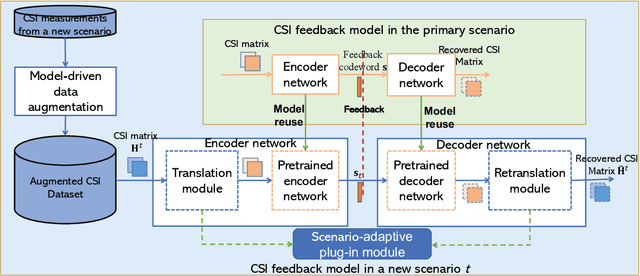
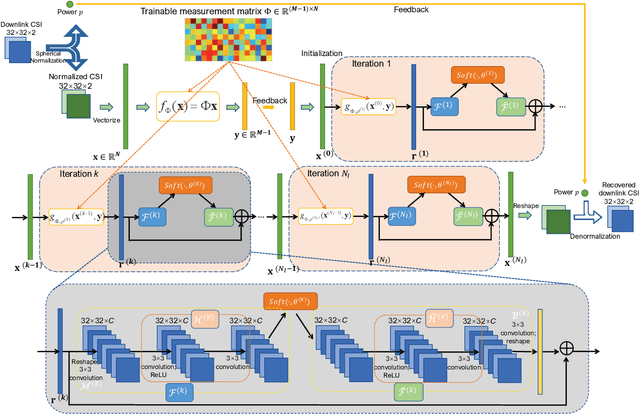
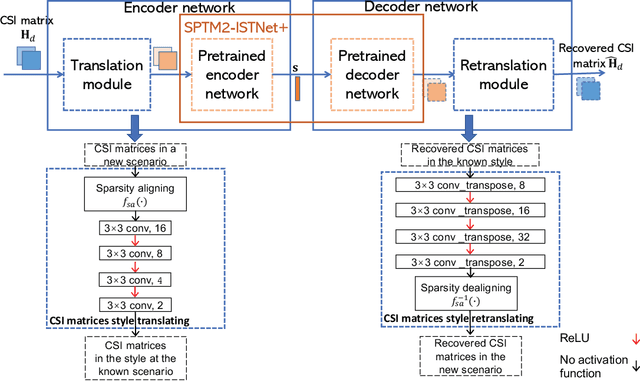
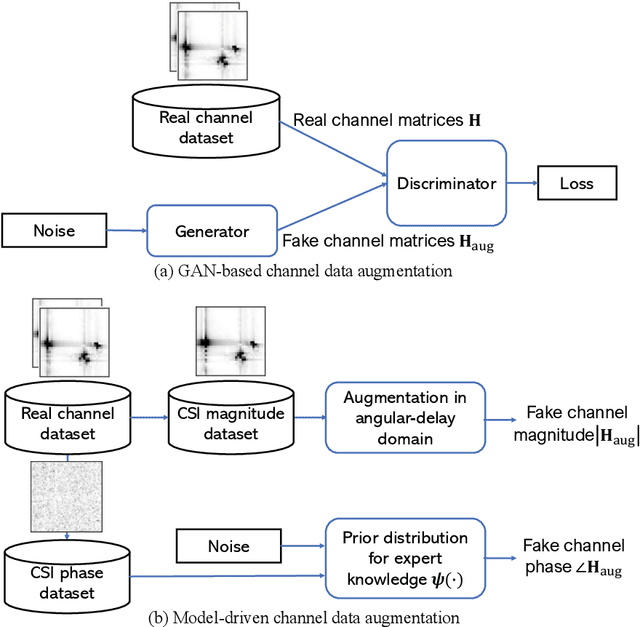
Deep learning (DL)-based channel state information (CSI) feedback has shown promising potential to improve spectrum efficiency in massive MIMO systems. However, practical DL approaches require a sizeable CSI dataset for each scenario, and require large storage for multiple learned models. To overcome this costly barrier, we develop a solution for efficient training and deployment enhancement of DL-based CSI feedback by exploiting a lightweight translation model to cope with new CSI environments and by proposing novel dataset augmentation based on domain knowledge. Specifically, we first develop a deep unfolding CSI feedback network, SPTM2-ISTANet+, which employs spherical normalization to address the challenge of path loss variation. We also introduce an integration of a trainable measurement matrix and residual CSI recovery blocks within SPTM2-ISTANet+ to improve efficiency and accuracy. Using SPTM2-ISTANet+ as the anchor feedback model, we propose an efficient scenario-adaptive CSI feedback architecture. This new CSI-TransNet exploits a plug-in module for CSI translation consisting of a sparsity aligning function and lightweight DL module to reuse pretrained models in unseen environments. To work with small datasets, we propose a lightweight and general augmentation strategy based on domain knowledge. Test results demonstrate the efficacy and efficiency of the proposed solution for accurate CSI feedback given limited measurements for unseen CSI environments.