 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022
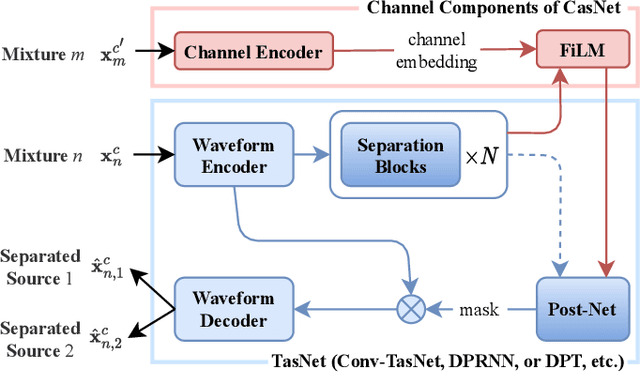
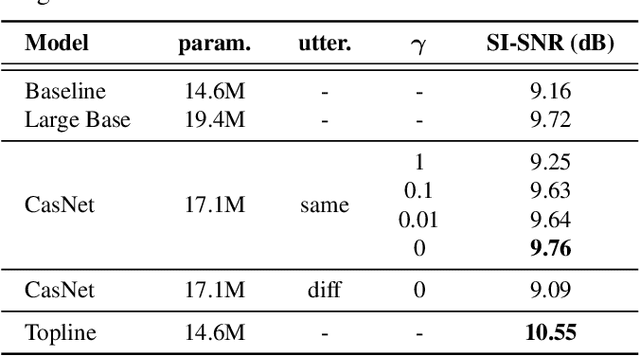
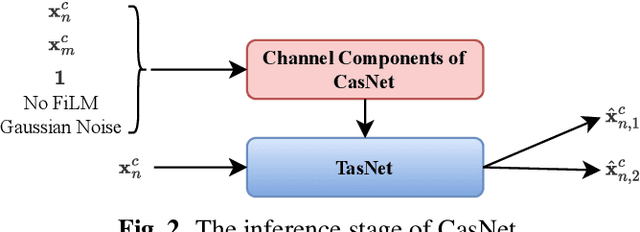
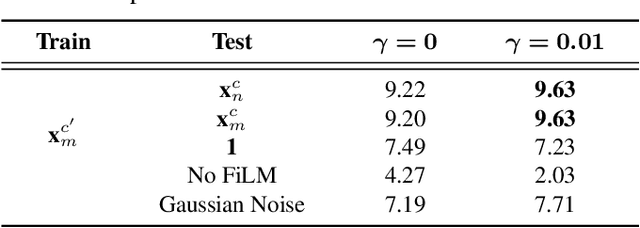
Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.
Super-Resolution Based Patch-Free 3D Medical Image Segmentation with Self-Supervised Guidance
Oct 26, 2022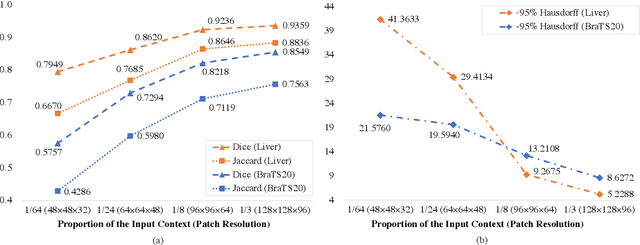
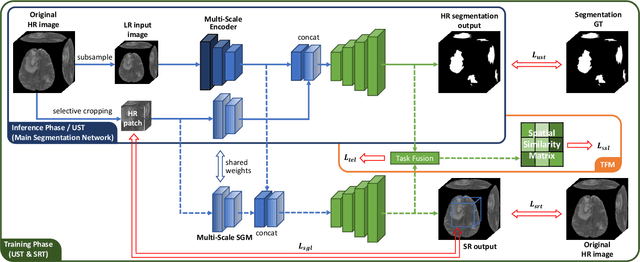
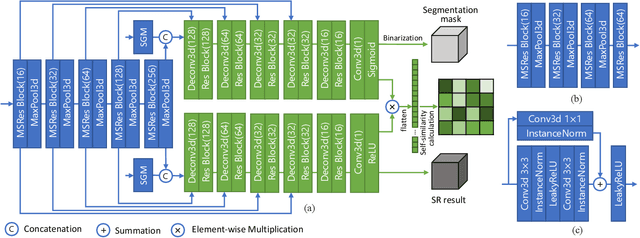
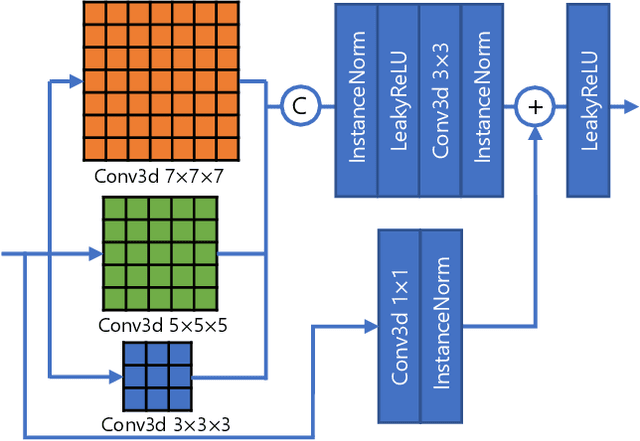
High resolution (HR) 3D medical image segmentation plays an important role in clinical diagnoses. However, HR images are difficult to be directly processed by mainstream graphical cards due to limited video memory. Therefore, most existing 3D medical image segmentation methods use patch-based models, which ignores global context information that is useful in accurate segmentation and has low inference efficiency. To address these problems, we propose a super-resolution (SR) guided patch-free 3D medical image segmentation framework that can realize HR segmentation with global information of low-resolution (LR) input. The framework contains two tasks: semantic segmentation (main task) and super resolution (auxiliary task). To balance the information loss with the LR input, we introduce a Self-Supervised Guidance Module (SGM), which employs a selective search method to crop a HR patch from the original image as restoration guidance. Multi-scale convolutional layers are used to mitigate the scale-inconsistency between the HR guidance features and the LR features. Moreover, we propose a Task-Fusion Module (TFM) to exploit the inter connections between segmentation and SR task. This module can also be used for Test Phase Fine-tuning (TPF), leading to a better model generalization ability. When predicting, only the main segmentation task is needed, while other modules can be removed to accelerate the inference. The experiments results on two different datasets show that our framework outperforms current patch-based and patch-free models. Our model also has a four times higher inference speed compared to traditional patch-based methods. Our codes are available at: https://github.com/Dootmaan/PFSeg-Full.
Vision-based navigation and obstacle avoidance via deep reinforcement learning
Nov 09, 2022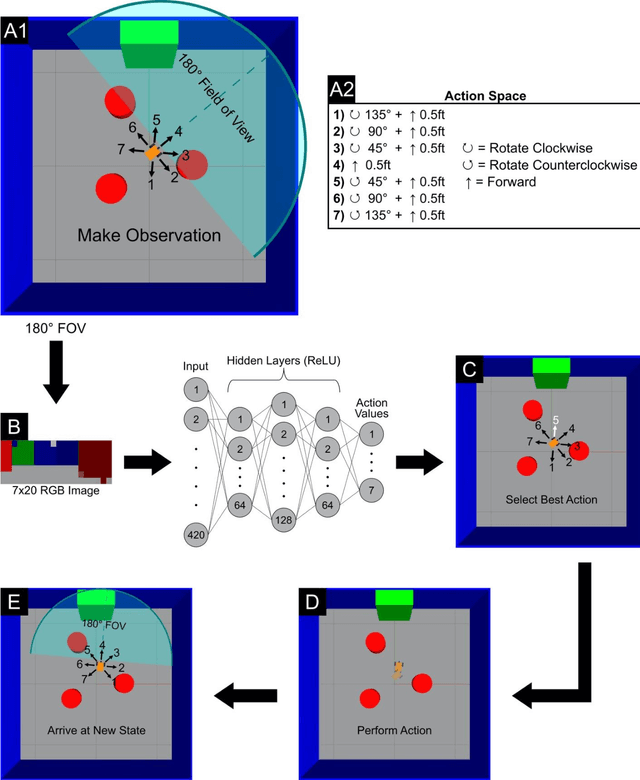

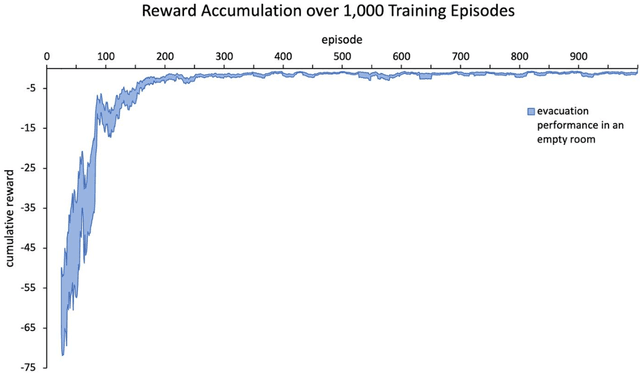
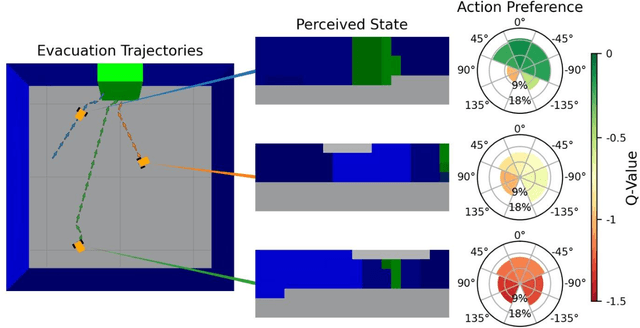
Development of navigation algorithms is essential for the successful deployment of robots in rapidly changing hazardous environments for which prior knowledge of configuration is often limited or unavailable. Use of traditional path-planning algorithms, which are based on localization and require detailed obstacle maps with goal locations, is not possible. In this regard, vision-based algorithms hold great promise, as visual information can be readily acquired by a robot's onboard sensors and provides a much richer source of information from which deep neural networks can extract complex patterns. Deep reinforcement learning has been used to achieve vision-based robot navigation. However, the efficacy of these algorithms in environments with dynamic obstacles and high variation in the configuration space has not been thoroughly investigated. In this paper, we employ a deep Dyna-Q learning algorithm for room evacuation and obstacle avoidance in partially observable environments based on low-resolution raw image data from an onboard camera. We explore the performance of a robotic agent in environments containing no obstacles, convex obstacles, and concave obstacles, both static and dynamic. Obstacles and the exit are initialized in random positions at the start of each episode of reinforcement learning. Overall, we show that our algorithm and training approach can generalize learning for collision-free evacuation of environments with complex obstacle configurations. It is evident that the agent can navigate to a goal location while avoiding multiple static and dynamic obstacles, and can escape from a concave obstacle while searching for and navigating to the exit.
Non-Contrastive Self-supervised Learning for Utterance-Level Information Extraction from Speech
Aug 10, 2022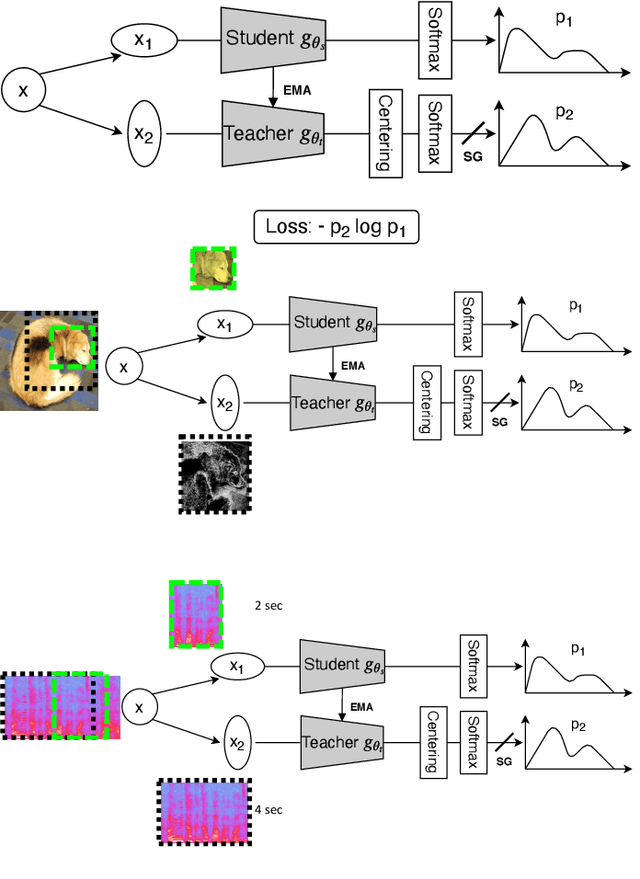
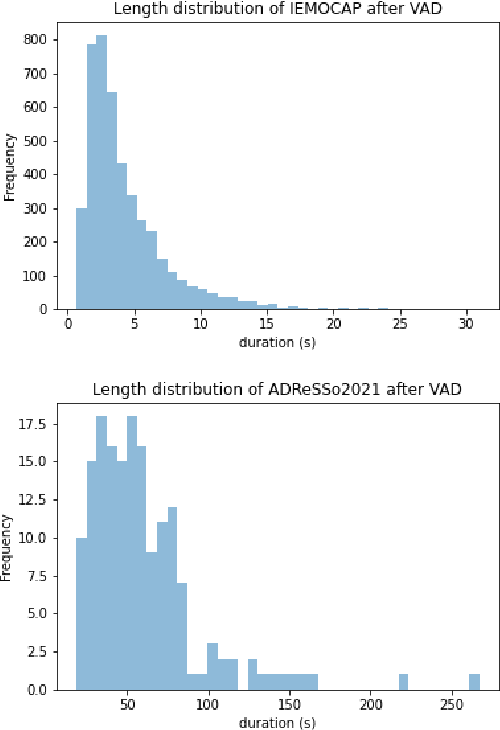
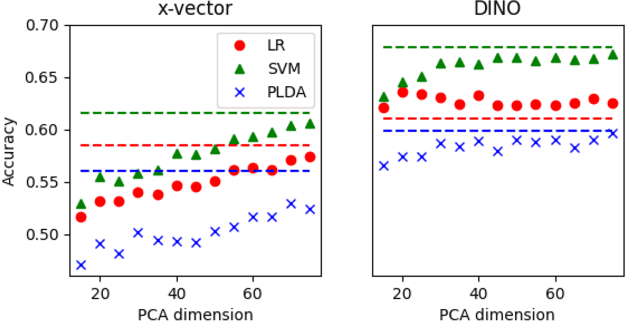
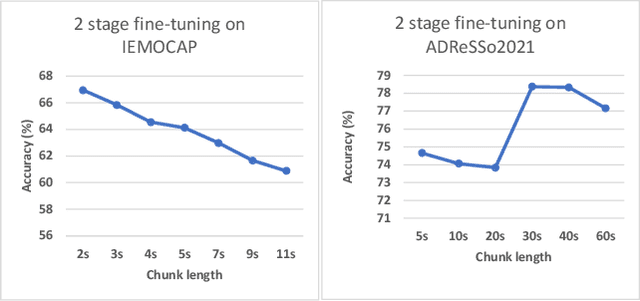
In recent studies, self-supervised pre-trained models tend to outperform supervised pre-trained models in transfer learning. In particular, self-supervised learning (SSL) of utterance-level speech representation can be used in speech applications that require discriminative representation of consistent attributes within an utterance: speaker, language, emotion, and age. Existing frame-level self-supervised speech representation, e.g., wav2vec, can be used as utterance-level representation with pooling, but the models are usually large. There are also SSL techniques to learn utterance-level representation. One of the most successful is a contrastive method, which requires negative sampling: selecting alternative samples to contrast with the current sample (anchor). However, this does not ensure that all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised method to learn utterance-level embeddings. We adapted DIstillation with NO labels (DINO) from computer vision to speech. Unlike contrastive methods, DINO does not require negative sampling. We compared DINO to x-vector trained in a supervised manner. When transferred to down-stream tasks (speaker verification, speech emotion recognition (SER), and Alzheimer's disease detection), DINO outperformed x-vector. We studied the influence of several aspects during transfer learning such as dividing the fine-tuning process into steps, chunk lengths, or augmentation. During fine-tuning, tuning the last affine layers first and then the whole network surpassed fine-tuning all at once. Using shorter chunk lengths, although they generate more diverse inputs, did not necessarily improve performance, implying speech segments at least with a specific length are required for better performance per application. Augmentation was helpful in SER.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022
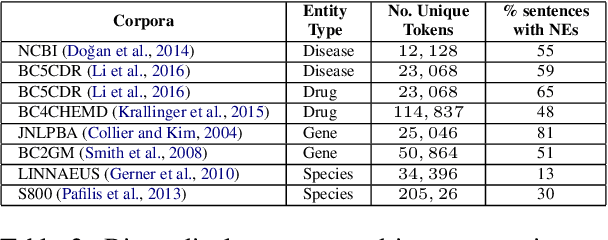
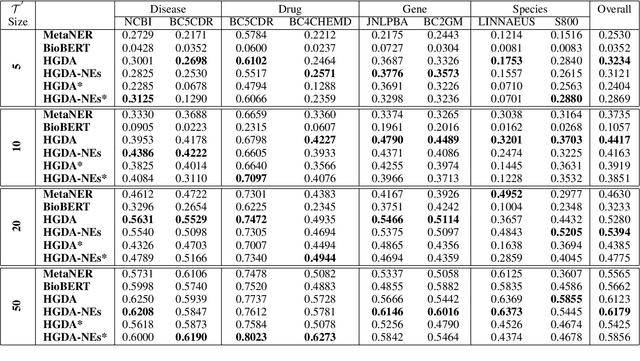
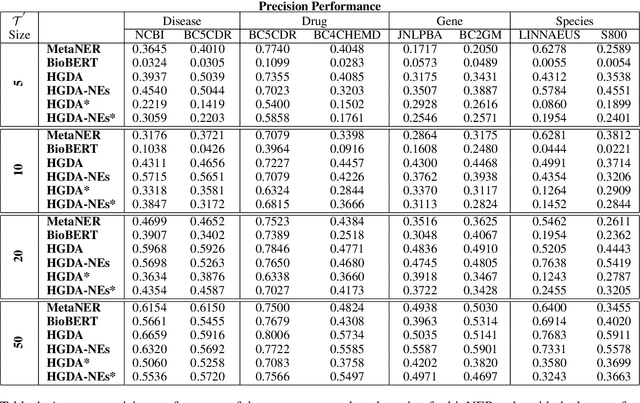
Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model
Relational Symmetry based Knowledge Graph Contrastive Learning
Nov 25, 2022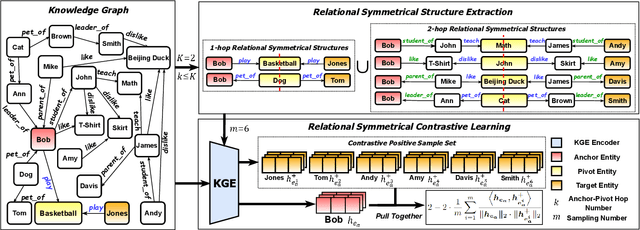

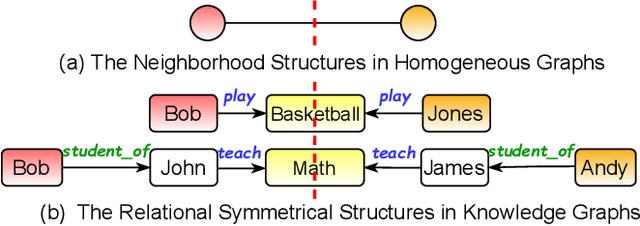
Knowledge graph embedding (KGE) aims to learn powerful representations to benefit various artificial intelligence applications, such as question answering and recommendations. Meanwhile, contrastive learning (CL), as an effective mechanism to enhance the discriminative capacity of the learned representations, has been leveraged in different fields, especially graph-based models. However, since the structures of knowledge graphs (KGs) are usually more complicated compared to homogeneous graphs, it is hard to construct appropriate contrastive sample pairs. In this paper, we find that the entities within a symmetrical structure are usually more similar and correlated. This key property can be utilized to construct contrastive positive pairs for contrastive learning. Following the ideas above, we propose a relational symmetrical structure based knowledge graph contrastive learning framework, termed KGE-SymCL, which leverages the symmetrical structure information in KGs to enhance the discriminative ability of KGE models. Concretely, a plug-and-play approach is designed by taking the entities in the relational symmetrical positions as the positive samples. Besides, a self-supervised alignment loss is used to pull together the constructed positive sample pairs for contrastive learning. Extensive experimental results on benchmark datasets have verified the good generalization and superiority of the proposed framework.
Learning with Silver Standard Data for Zero-shot Relation Extraction
Nov 25, 2022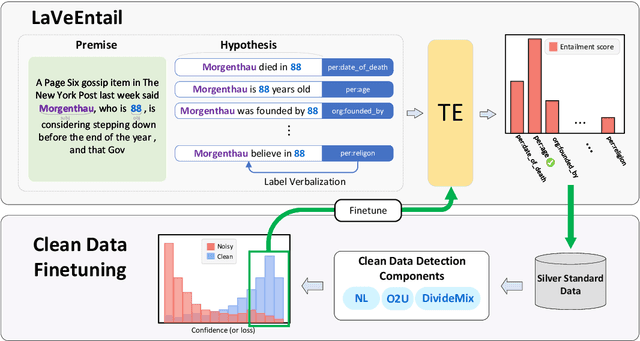
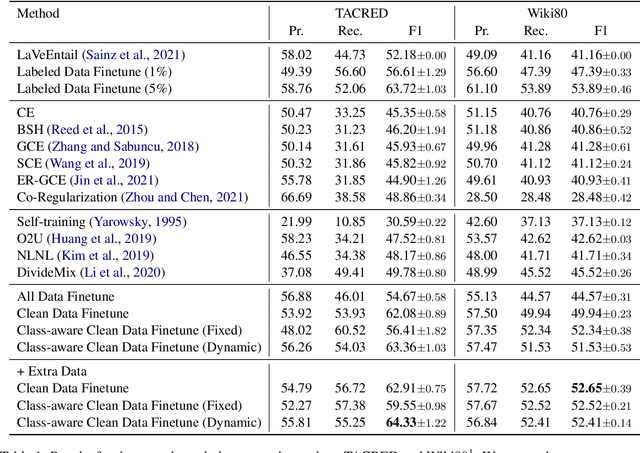
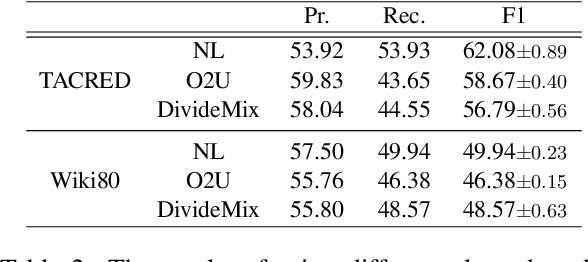
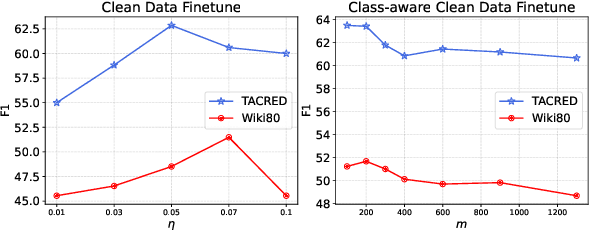
The superior performance of supervised relation extraction (RE) methods heavily relies on a large amount of gold standard data. Recent zero-shot relation extraction methods converted the RE task to other NLP tasks and used off-the-shelf models of these NLP tasks to directly perform inference on the test data without using a large amount of RE annotation data. A potentially valuable by-product of these methods is the large-scale silver standard data. However, there is no further investigation on the use of potentially valuable silver standard data. In this paper, we propose to first detect a small amount of clean data from silver standard data and then use the selected clean data to finetune the pretrained model. We then use the finetuned model to infer relation types. We also propose a class-aware clean data detection module to consider class information when selecting clean data. The experimental results show that our method can outperform the baseline by 12% and 11% on TACRED and Wiki80 dataset in the zero-shot RE task. By using extra silver standard data of different distributions, the performance can be further improved.
Efficient Graph Neural Network Inference at Large Scale
Nov 05, 2022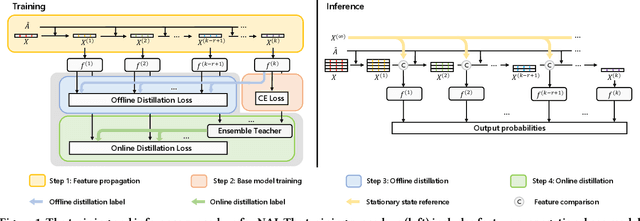
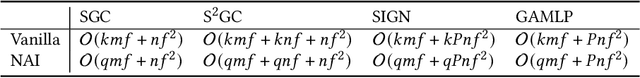
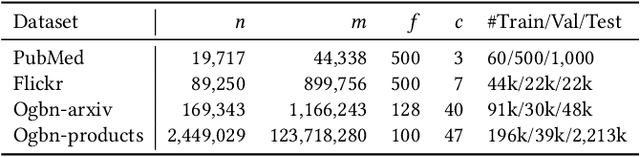
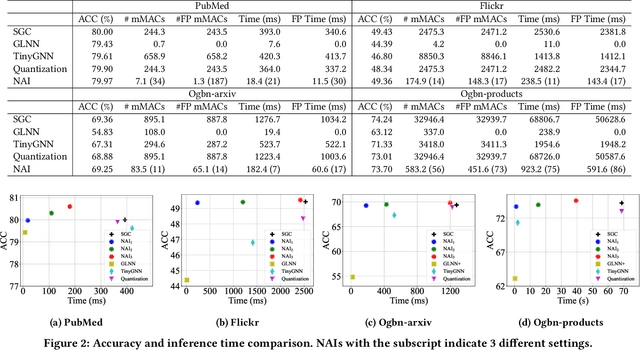
Graph neural networks (GNNs) have demonstrated excellent performance in a wide range of applications. However, the enormous size of large-scale graphs hinders their applications under real-time inference scenarios. Although existing scalable GNNs leverage linear propagation to preprocess the features and accelerate the training and inference procedure, these methods still suffer from scalability issues when making inferences on unseen nodes, as the feature preprocessing requires the graph is known and fixed. To speed up the inference in the inductive setting, we propose a novel adaptive propagation order approach that generates the personalized propagation order for each node based on its topological information. This could successfully avoid the redundant computation of feature propagation. Moreover, the trade-off between accuracy and inference latency can be flexibly controlled by simple hyper-parameters to match different latency constraints of application scenarios. To compensate for the potential inference accuracy loss, we further propose Inception Distillation to exploit the multi scale reception information and improve the inference performance. Extensive experiments are conducted on four public datasets with different scales and characteristics, and the experimental results show that our proposed inference acceleration framework outperforms the SOTA graph inference acceleration baselines in terms of both accuracy and efficiency. In particular, the advantage of our proposed method is more significant on larger-scale datasets, and our framework achieves $75\times$ inference speedup on the largest Ogbn-products dataset.
Design of Reconfigurable Intelligent Surface-Aided Cross-Media Communications
Nov 05, 2022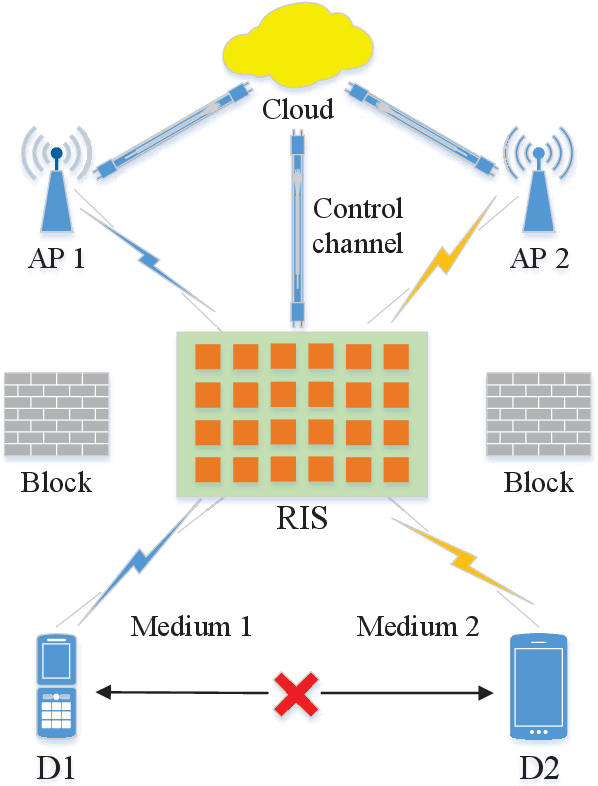
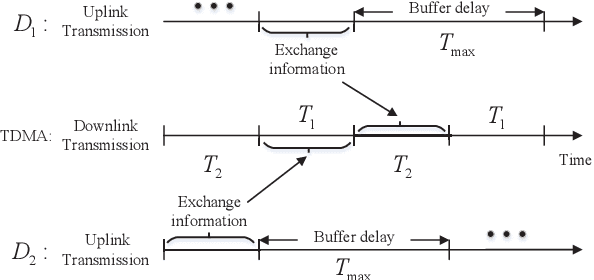
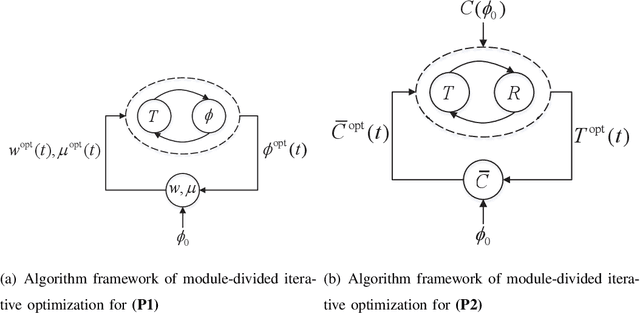
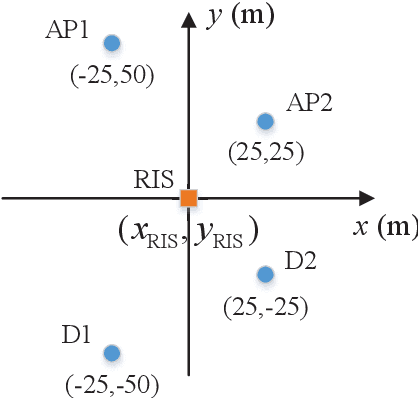
A novel reconfigurable intelligent surface (RIS)-aided hybrid reflection/transmitter design is proposed for achieving information exchange in cross-media communications. In pursuit of the balance between energy efficiency and low-cost implementations, the cloud-management transmission protocol is adopted in the integrated multi-media system. Specifically, the messages of devices using heterogeneous propagation media, are firstly transmitted to the medium-matched AP, with the aid of the RIS-based dual-hop transmission. After the operation of intermediate frequency conversion, the access point (AP) uploads the received signals to the cloud for further demodulating and decoding process. Based on time division multiple access (TDMA), the cloud is able to distinguish the downlink data transmitted to different devices and transforms them into the input of the RIS controller via the dedicated control channel. Thereby, the RIS can passively reflect the incident carrier back into the original receiver with the exchanged information during the preallocated slots, following the idea of an index modulation-based transmitter. Moreover, the iterative optimization algorithm is utilized for optimizing the RIS phase, transmit rate and time allocation jointly in the delay-constrained cross-media communication model. Our simulation results demonstrate that the proposed RIS-based scheme can improve the end-to-end throughput than that of the AP-based transmission, the equal time allocation, the random and the discrete phase adjustment benchmarks.
Multi-Source Survival Domain Adaptation
Dec 01, 2022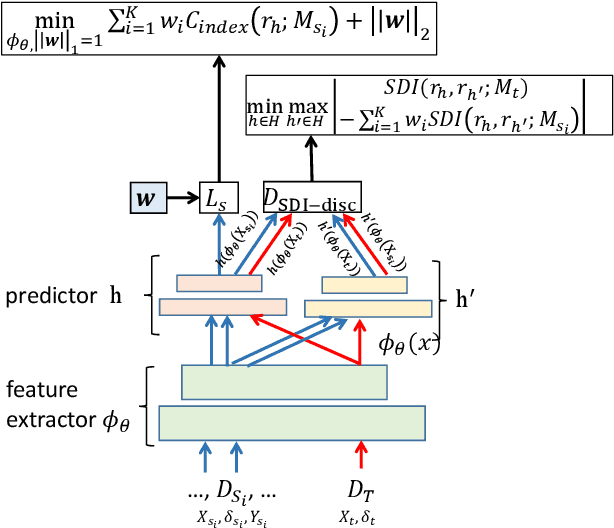
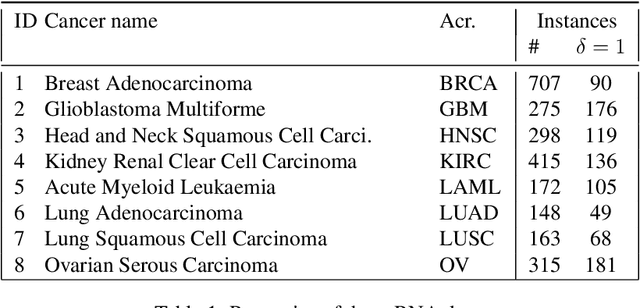
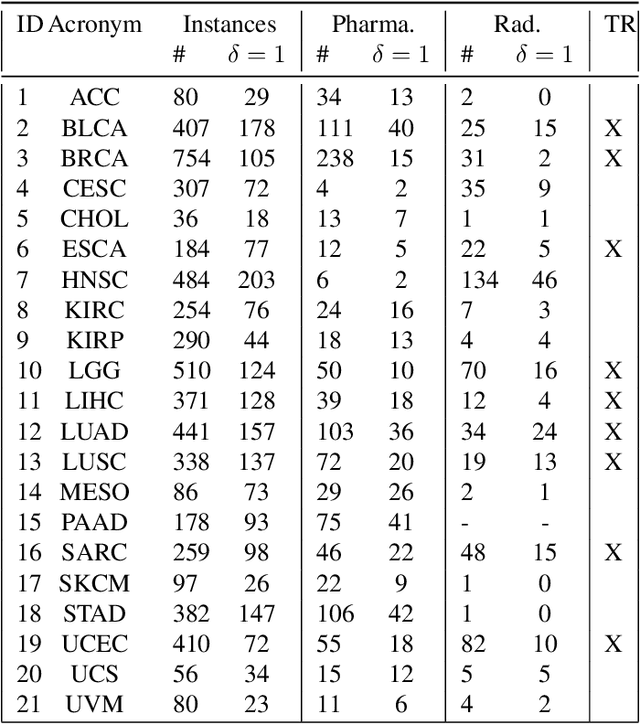
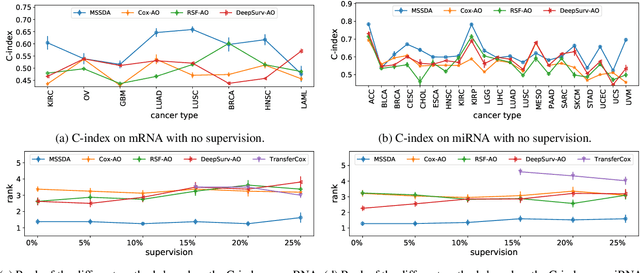
Survival analysis is the branch of statistics that studies the relation between the characteristics of living entities and their respective survival times, taking into account the partial information held by censored cases. A good analysis can, for example, determine whether one medical treatment for a group of patients is better than another. With the rise of machine learning, survival analysis can be modeled as learning a function that maps studied patients to their survival times. To succeed with that, there are three crucial issues to be tackled. First, some patient data is censored: we do not know the true survival times for all patients. Second, data is scarce, which led past research to treat different illness types as domains in a multi-task setup. Third, there is the need for adaptation to new or extremely rare illness types, where little or no labels are available. In contrast to previous multi-task setups, we want to investigate how to efficiently adapt to a new survival target domain from multiple survival source domains. For this, we introduce a new survival metric and the corresponding discrepancy measure between survival distributions. These allow us to define domain adaptation for survival analysis while incorporating censored data, which would otherwise have to be dropped. Our experiments on two cancer data sets reveal a superb performance on target domains, a better treatment recommendation, and a weight matrix with a plausible explanation.