 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Multimodal Entity-Relation Extraction Based on Edge-enhanced Graph Alignment Network and Word-pair Relation Tagging
Nov 28, 2022
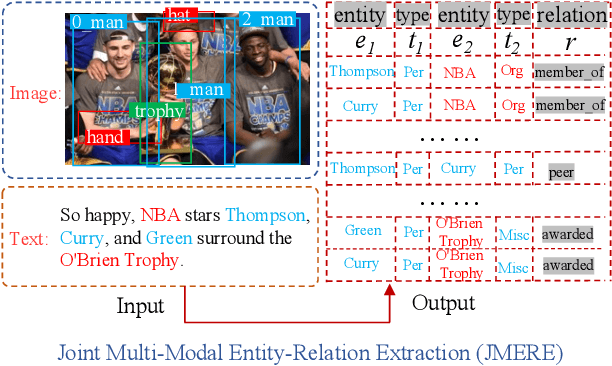
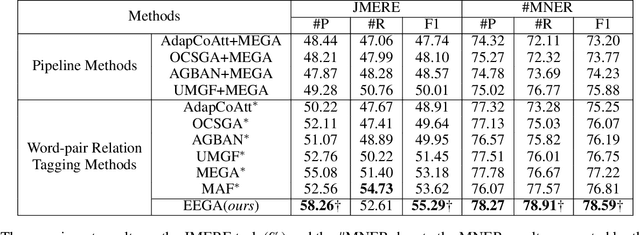
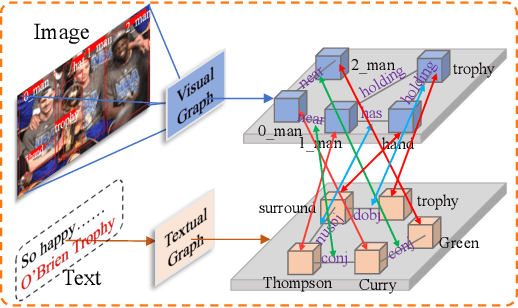
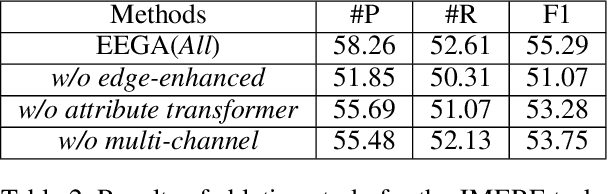
Multimodal named entity recognition (MNER) and multimodal relation extraction (MRE) are two fundamental subtasks in the multimodal knowledge graph construction task. However, the existing methods usually handle two tasks independently, which ignores the bidirectional interaction between them. This paper is the first to propose jointly performing MNER and MRE as a joint multimodal entity-relation extraction task (JMERE). Besides, the current MNER and MRE models only consider aligning the visual objects with textual entities in visual and textual graphs but ignore the entity-entity relationships and object-object relationships. To address the above challenges, we propose an edge-enhanced graph alignment network and a word-pair relation tagging (EEGA) for JMERE task. Specifically, we first design a word-pair relation tagging to exploit the bidirectional interaction between MNER and MRE and avoid the error propagation. Then, we propose an edge-enhanced graph alignment network to enhance the JMERE task by aligning nodes and edges in the cross-graph. Compared with previous methods, the proposed method can leverage the edge information to auxiliary alignment between objects and entities and find the correlations between entity-entity relationships and object-object relationships. Experiments are conducted to show the effectiveness of our model.
SgVA-CLIP: Semantic-guided Visual Adapting of Vision-Language Models for Few-shot Image Classification
Nov 28, 2022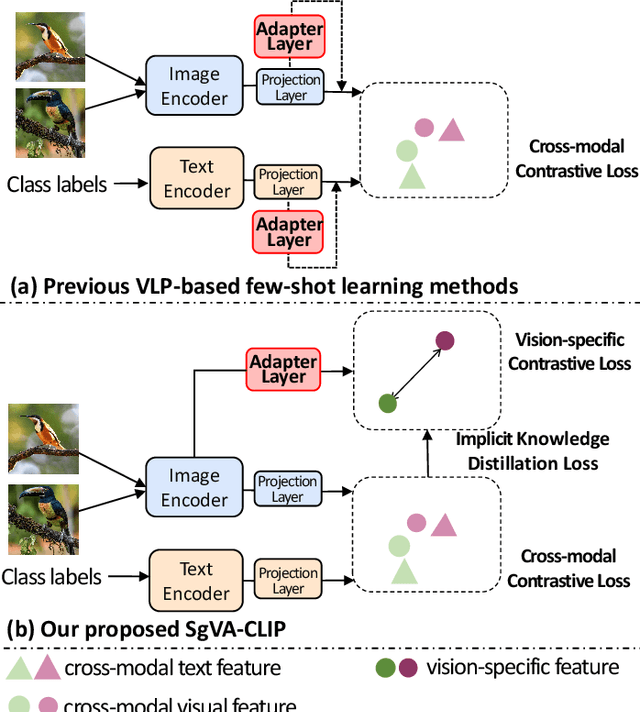
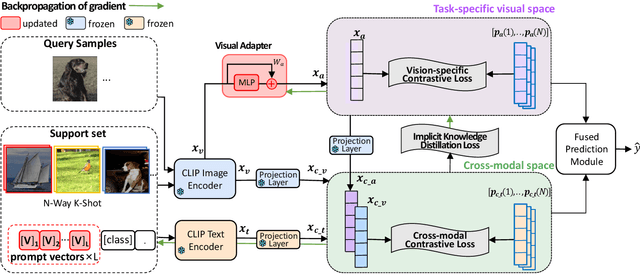
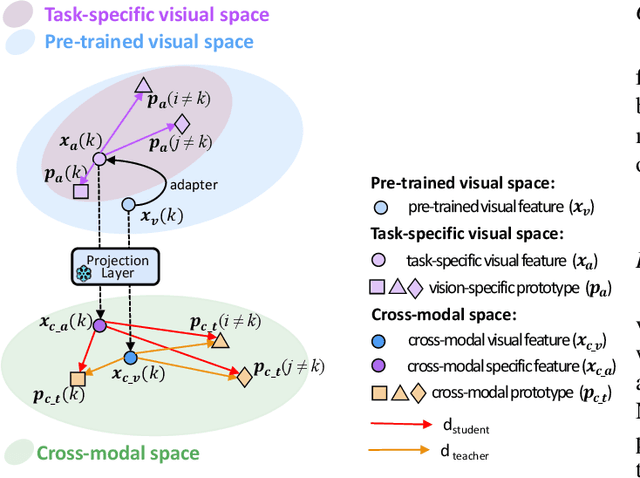
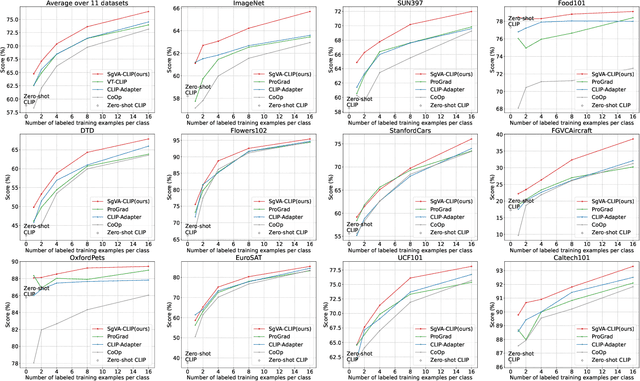
Although significant progress has been made in few-shot learning, most of existing few-shot learning methods require supervised pre-training on a large amount of samples of base classes, which limits their generalization ability in real world application. Recently, large-scale self-supervised vision-language models (e.g., CLIP) have provided a new paradigm for transferable visual representation learning. However, the pre-trained VLPs may neglect detailed visual information that is difficult to describe by language sentences, but important for learning an effective classifier in few-shot classification. To address the above problem, we propose a new framework, named Semantic-guided Visual Adapting (SgVA), which can effectively extend vision-language pre-trained models to produce discriminative task-specific visual features by comprehensively using a vision-specific contrastive loss, a cross-modal contrastive loss, and an implicit knowledge distillation. The implicit knowledge distillation is designed to transfer the fine-grained cross-modal knowledge to guide the updating of the vision adapter. State-of-the-art results on 13 datasets demonstrate that the adapted visual features can well complement the cross-modal features to improve few-shot image classification.
A Bayesian Approach to Reconstructing Interdependent Infrastructure Networks from Cascading Failures
Nov 28, 2022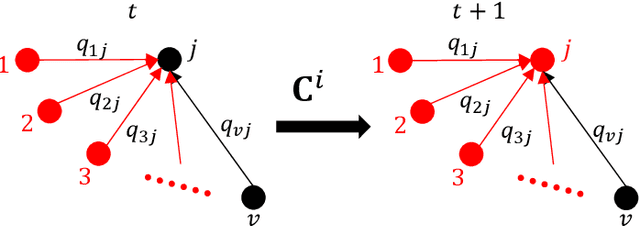
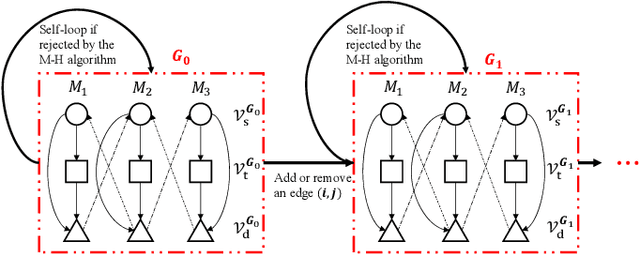
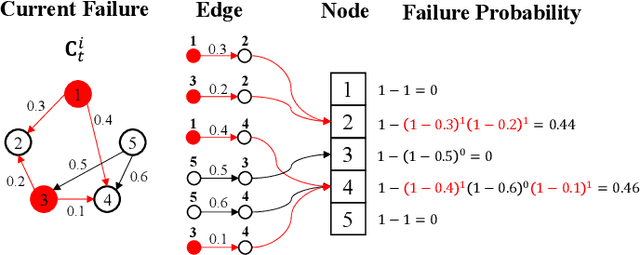
Analyzing the behavior of complex interdependent networks requires complete information about the network topology and the interdependent links across networks. For many applications such as critical infrastructure systems, understanding network interdependencies is crucial to anticipate cascading failures and plan for disruptions. However, data on the topology of individual networks are often publicly unavailable due to privacy and security concerns. Additionally, interdependent links are often only revealed in the aftermath of a disruption as a result of cascading failures. We propose a scalable nonparametric Bayesian approach to reconstruct the topology of interdependent infrastructure networks from observations of cascading failures. Metropolis-Hastings algorithm coupled with the infrastructure-dependent proposal are employed to increase the efficiency of sampling possible graphs. Results of reconstructing a synthetic system of interdependent infrastructure networks demonstrate that the proposed approach outperforms existing methods in both accuracy and computational time. We further apply this approach to reconstruct the topology of one synthetic and two real-world systems of interdependent infrastructure networks, including gas-power-water networks in Shelby County, TN, USA, and an interdependent system of power-water networks in Italy, to demonstrate the general applicability of the approach.
Efficient Mirror Detection via Multi-level Heterogeneous Learning
Nov 28, 2022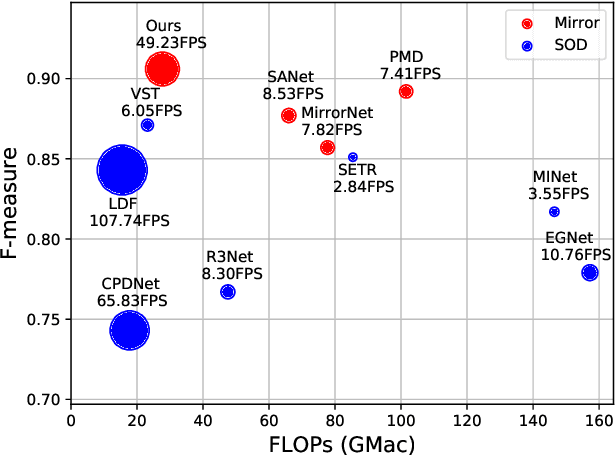
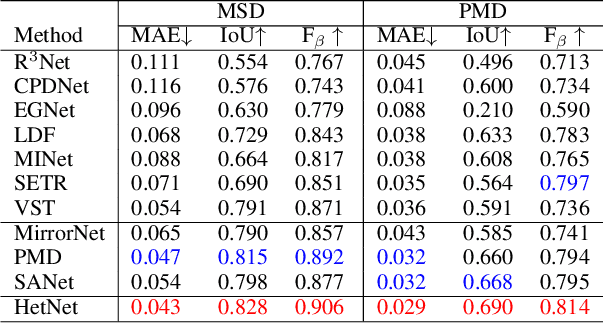
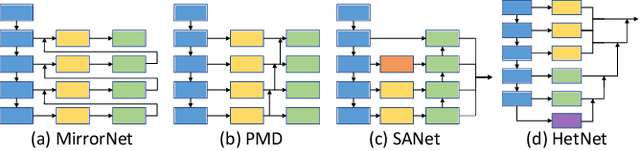
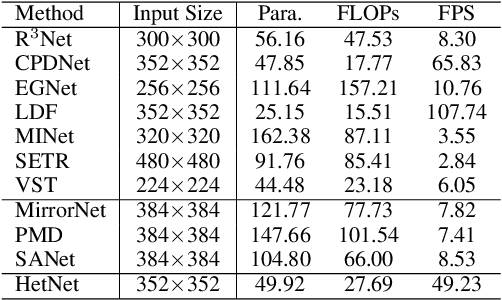
We present HetNet (Multi-level \textbf{Het}erogeneous \textbf{Net}work), a highly efficient mirror detection network. Current mirror detection methods focus more on performance than efficiency, limiting the real-time applications (such as drones). Their lack of efficiency is aroused by the common design of adopting homogeneous modules at different levels, which ignores the difference between different levels of features. In contrast, HetNet detects potential mirror regions initially through low-level understandings (\textit{e.g.}, intensity contrasts) and then combines with high-level understandings (contextual discontinuity for instance) to finalize the predictions. To perform accurate yet efficient mirror detection, HetNet follows an effective architecture that obtains specific information at different stages to detect mirrors. We further propose a multi-orientation intensity-based contrasted module (MIC) and a reflection semantic logical module (RSL), equipped on HetNet, to predict potential mirror regions by low-level understandings and analyze semantic logic in scenarios by high-level understandings, respectively. Compared to the state-of-the-art method, HetNet runs 664$\%$ faster and draws an average performance gain of 8.9$\%$ on MAE, 3.1$\%$ on IoU, and 2.0$\%$ on F-measure on two mirror detection benchmarks.
Generating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022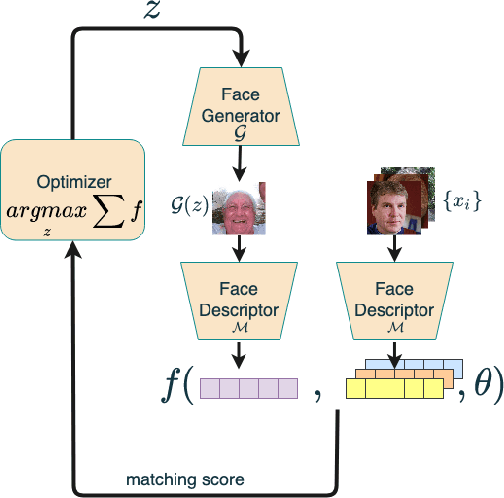
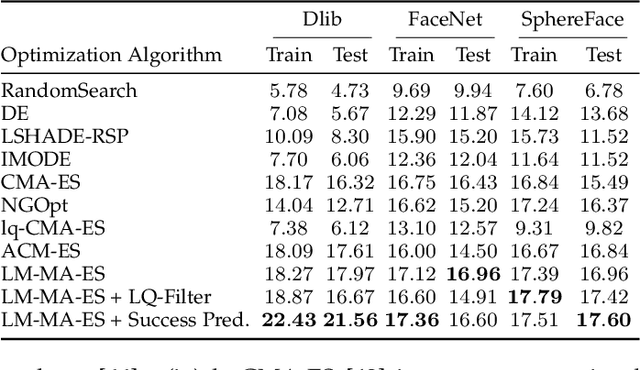
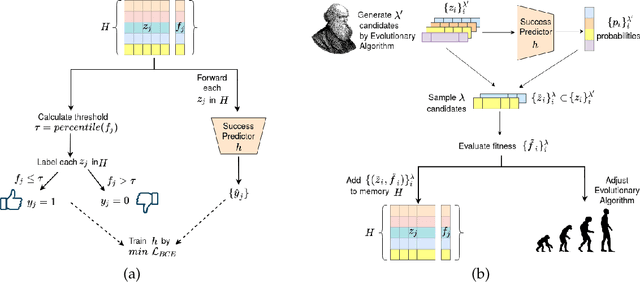
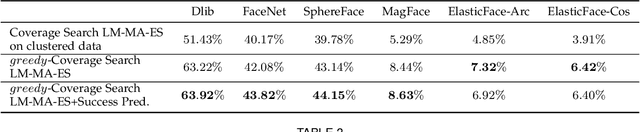
A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
Long-tail Cross Modal Hashing
Nov 28, 2022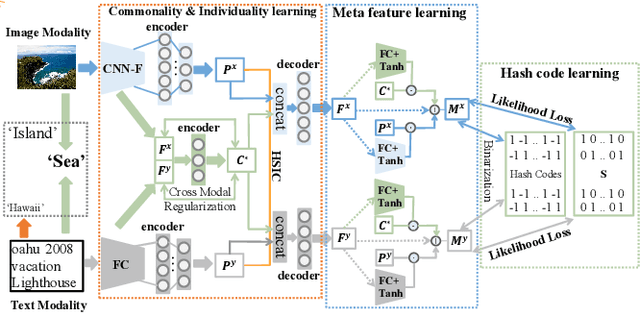

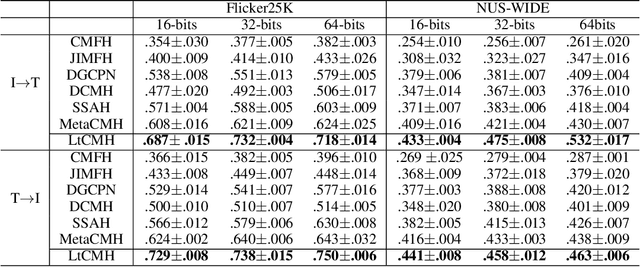
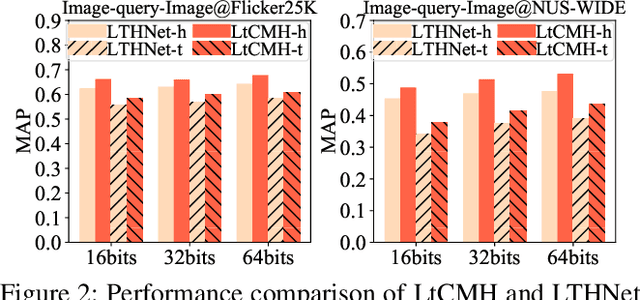
Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
SLAN: Self-Locator Aided Network for Cross-Modal Understanding
Nov 28, 2022
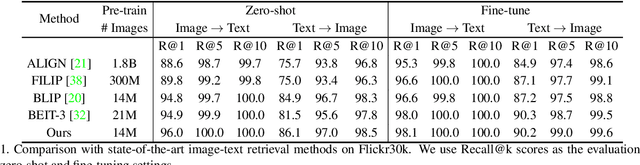
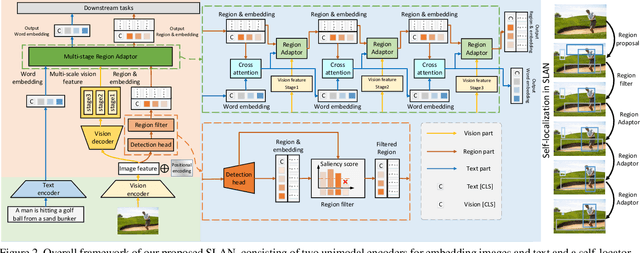
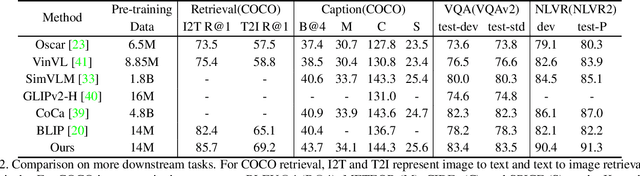
Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.
PHO-LID: A Unified Model Incorporating Acoustic-Phonetic and Phonotactic Information for Language Identification
Mar 31, 2022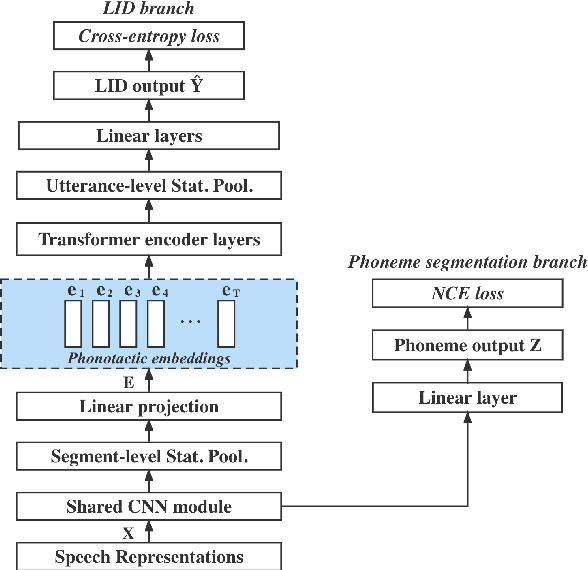
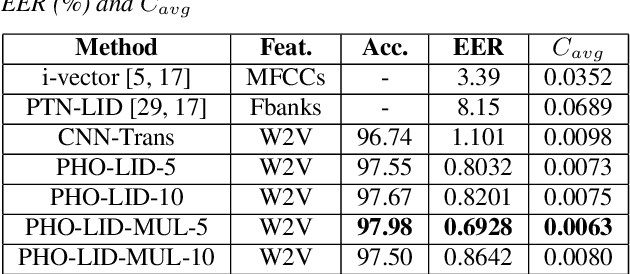
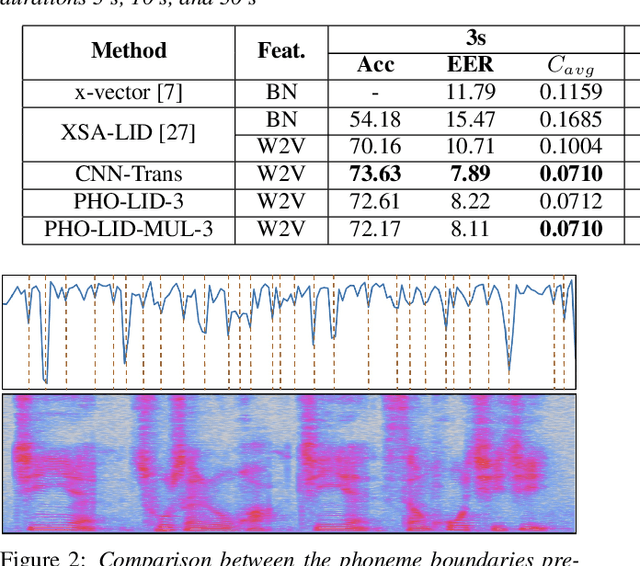
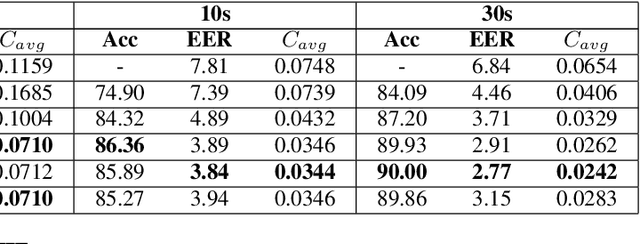
We propose a novel model to hierarchically incorporate phoneme and phonotactic information for language identification (LID) without requiring phoneme annotations for training. In this model, named PHO-LID, a self-supervised phoneme segmentation task and a LID task share a convolutional neural network (CNN) module, which encodes both language identity and sequential phonemic information in the input speech to generate an intermediate sequence of phonotactic embeddings. These embeddings are then fed into transformer encoder layers for utterance-level LID. We call this architecture CNN-Trans. We evaluate it on AP17-OLR data and the MLS14 set of NIST LRE 2017, and show that the PHO-LID model with multi-task optimization exhibits the highest LID performance among all models, achieving over 40% relative improvement in terms of average cost on AP17-OLR data compared to a CNN-Trans model optimized only for LID. The visualized confusion matrices imply that our proposed method achieves higher performance on languages of the same cluster in NIST LRE 2017 data than the CNN-Trans model. A comparison between predicted phoneme boundaries and corresponding audio spectrograms illustrates the leveraging of phoneme information for LID.
Open-vocabulary Attribute Detection
Nov 23, 2022
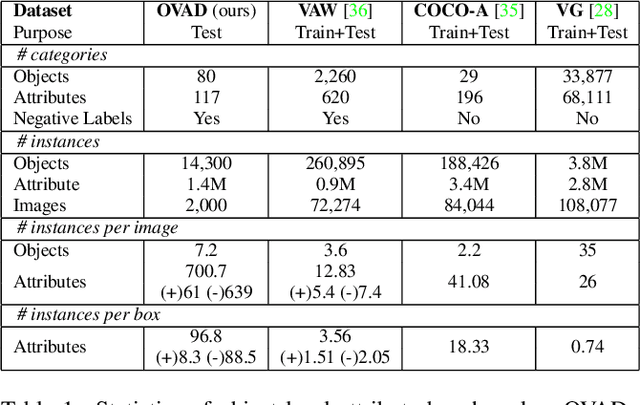

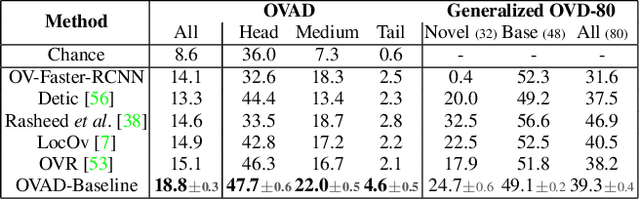
Vision-language modeling has enabled open-vocabulary tasks where predictions can be queried using any text prompt in a zero-shot manner. Existing open-vocabulary tasks focus on object classes, whereas research on object attributes is limited due to the lack of a reliable attribute-focused evaluation benchmark. This paper introduces the Open-Vocabulary Attribute Detection (OVAD) task and the corresponding OVAD benchmark. The objective of the novel task and benchmark is to probe object-level attribute information learned by vision-language models. To this end, we created a clean and densely annotated test set covering 117 attribute classes on the 80 object classes of MS COCO. It includes positive and negative annotations, which enables open-vocabulary evaluation. Overall, the benchmark consists of 1.4 million annotations. For reference, we provide a first baseline method for open-vocabulary attribute detection. Moreover, we demonstrate the benchmark's value by studying the attribute detection performance of several foundation models. Project page https://ovad-benchmark.github.io/
Completing point cloud from few points by Wasserstein GAN and Transformers
Nov 23, 2022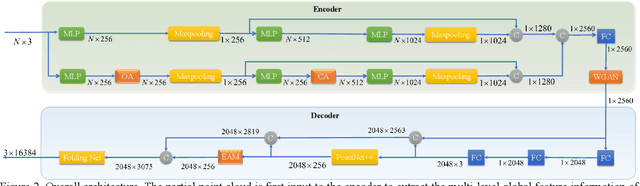
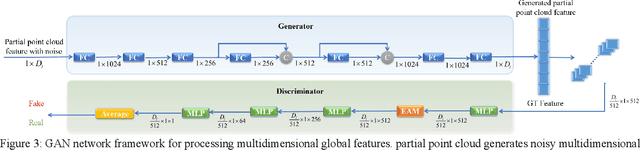
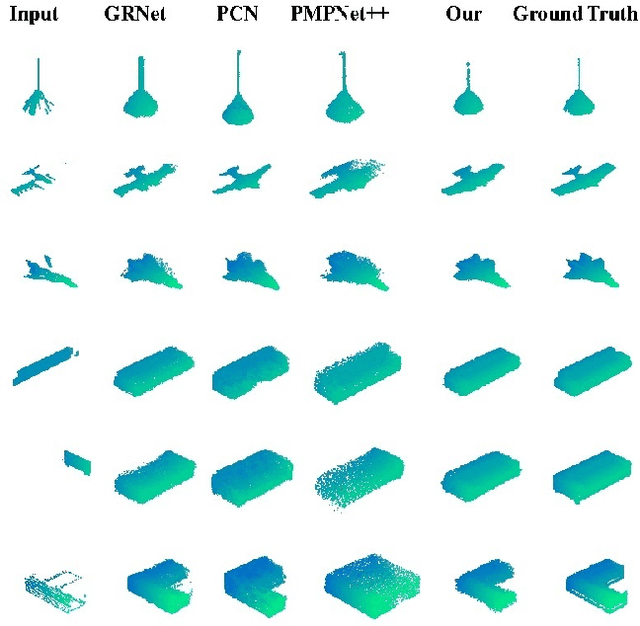
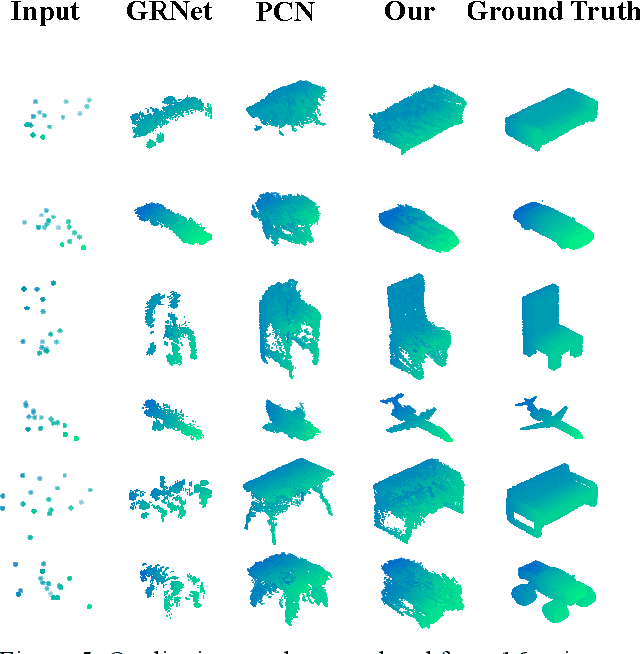
In many vision and robotics applications, it is common that the captured objects are represented by very few points. Most of the existing completion methods are designed for partial point clouds with many points, and they perform poorly or even fail completely in the case of few points. However, due to the lack of detail information, completing objects from few points faces a huge challenge. Inspired by the successful applications of GAN and Transformers in the image-based vision task, we introduce GAN and Transformer techniques to address the above problem. Firstly, the end-to-end encoder-decoder network with Transformers and the Wasserstein GAN with Transformer are pre-trained, and then the overall network is fine-tuned. Experimental results on the ShapeNet dataset show that our method can not only improve the completion performance for many input points, but also keep stable for few input points. Our source code is available at https://github.com/WxfQjh/Stability-point-recovery.git.