 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Smart Agriculture : A Novel Multilevel Approach for Agricultural Risk Assessment over Unstructured Data
Nov 22, 2022
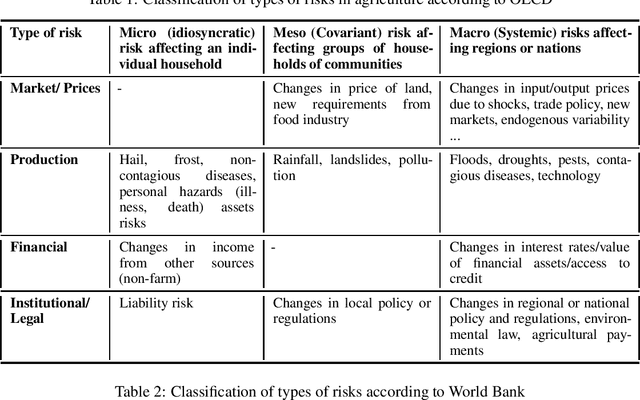
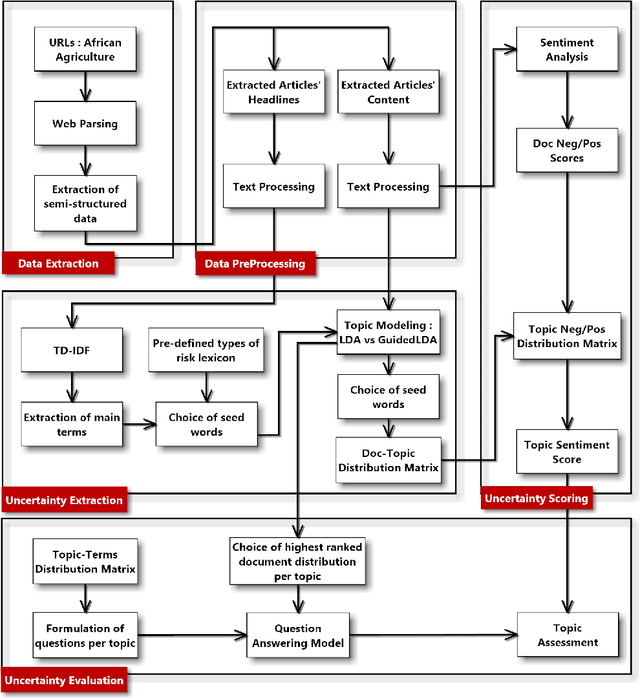
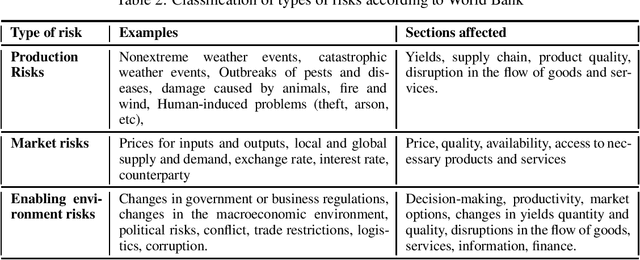
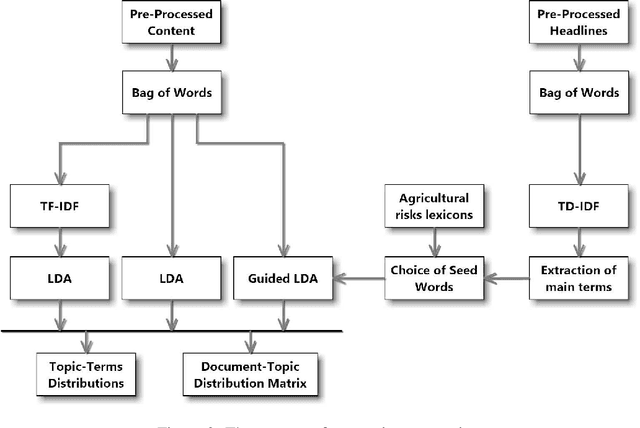
Detecting opportunities and threats from massive text data is a challenging task for most. Traditionally, companies would rely mainly on structured data to detect and predict risks, losing a huge amount of information that could be extracted from unstructured text data. Fortunately, artificial intelligence came to remedy this issue by innovating in data extraction and processing techniques, allowing us to understand and make use of Natural Language data and turning it into structures that a machine can process and extract insight from. Uncertainty refers to a state of not knowing what will happen in the future. This paper aims to leverage natural language processing and machine learning techniques to model uncertainties and evaluate the risk level in each uncertainty cluster using massive text data.
Neural Poisson: Indicator Functions for Neural Fields
Nov 25, 2022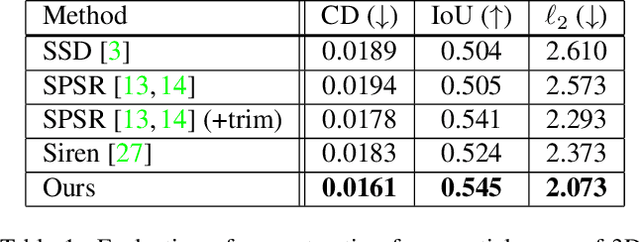
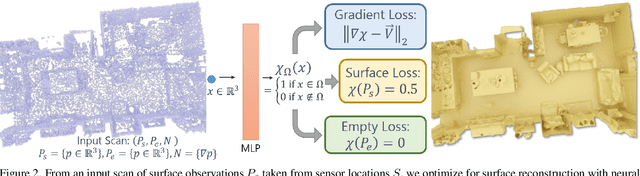
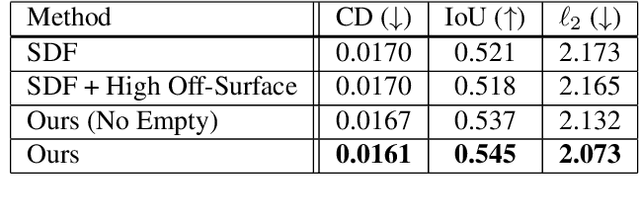
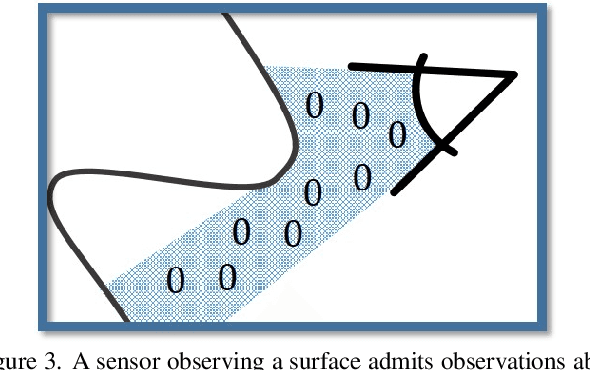
Implicit neural field generating signed distance field representations (SDFs) of 3D shapes have shown remarkable progress in 3D shape reconstruction and generation. We introduce a new paradigm for neural field representations of 3D scenes; rather than characterizing surfaces as SDFs, we propose a Poisson-inspired characterization for surfaces as indicator functions optimized by neural fields. Crucially, for reconstruction of real scan data, the indicator function representation enables simple and effective constraints based on common range sensing inputs, which indicate empty space based on line of sight. Such empty space information is intrinsic to the scanning process, and incorporating this knowledge enables more accurate surface reconstruction. We show that our approach demonstrates state-of-the-art reconstruction performance on both synthetic and real scanned 3D scene data, with 9.5% improvement in Chamfer distance over state of the art.
Aggregated Text Transformer for Scene Text Detection
Nov 25, 2022


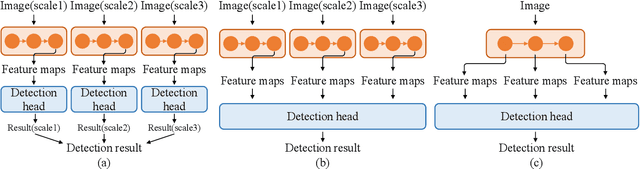
This paper explores the multi-scale aggregation strategy for scene text detection in natural images. We present the Aggregated Text TRansformer(ATTR), which is designed to represent texts in scene images with a multi-scale self-attention mechanism. Starting from the image pyramid with multiple resolutions, the features are first extracted at different scales with shared weight and then fed into an encoder-decoder architecture of Transformer. The multi-scale image representations are robust and contain rich information on text contents of various sizes. The text Transformer aggregates these features to learn the interaction across different scales and improve text representation. The proposed method detects scene texts by representing each text instance as an individual binary mask, which is tolerant of curve texts and regions with dense instances. Extensive experiments on public scene text detection datasets demonstrate the effectiveness of the proposed framework.
A Deep Learning Anomaly Detection Method in Textual Data
Nov 25, 2022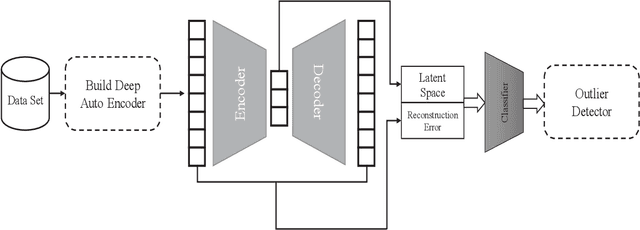

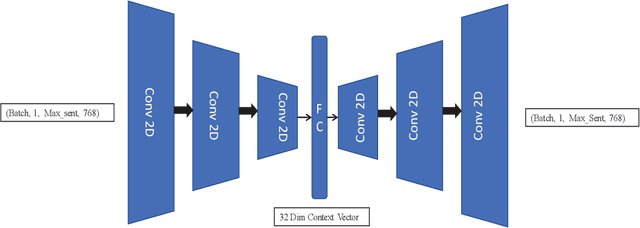
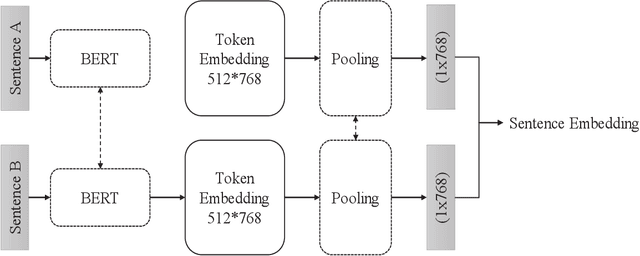
In this article, we propose using deep learning and transformer architectures combined with classical machine learning algorithms to detect and identify text anomalies in texts. Deep learning model provides a very crucial context information about the textual data which all textual context are converted to a numerical representation. We used multiple machine learning methods such as Sentence Transformers, Auto Encoders, Logistic Regression and Distance calculation methods to predict anomalies. The method are tested on the texts data and we used syntactic data from different source injected into the original text as anomalies or use them as target. Different methods and algorithm are explained in the field of outlier detection and the results of the best technique is presented. These results suggest that our algorithm could potentially reduce false positive rates compared with other anomaly detection methods that we are testing.
Copula Density Neural Estimation
Nov 25, 2022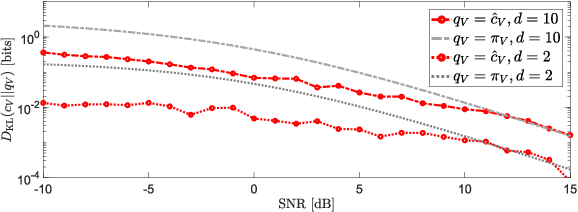
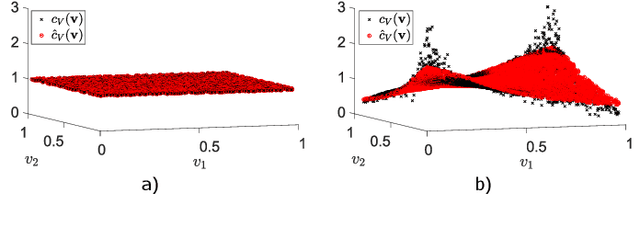
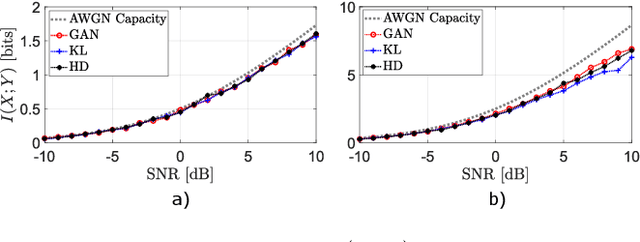
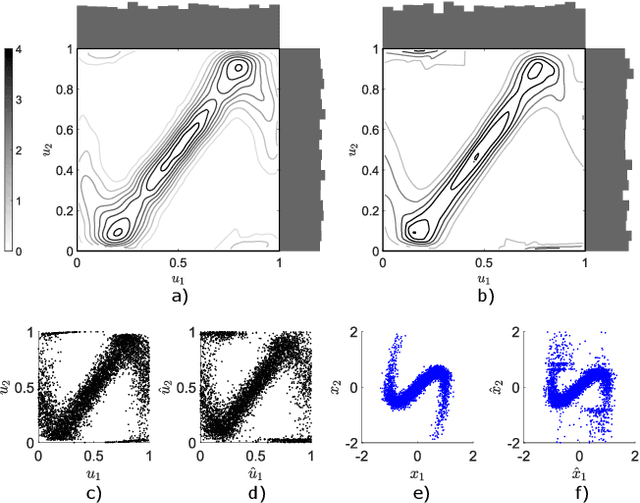
Probability density estimation from observed data constitutes a central task in statistics. Recent advancements in machine learning offer new tools but also pose new challenges. The big data era demands analysis of long-range spatial and long-term temporal dependencies in large collections of raw data, rendering neural networks an attractive solution for density estimation. In this paper, we exploit the concept of copula to explicitly build an estimate of the probability density function associated to any observed data. In particular, we separate univariate marginal distributions from the joint dependence structure in the data, the copula itself, and we model the latter with a neural network-based method referred to as copula density neural estimation (CODINE). Results show that the novel learning approach is capable of modeling complex distributions and it can be applied for mutual information estimation and data generation.
BEV-MAE: Bird's Eye View Masked Autoencoders for Outdoor Point Cloud Pre-training
Dec 12, 2022
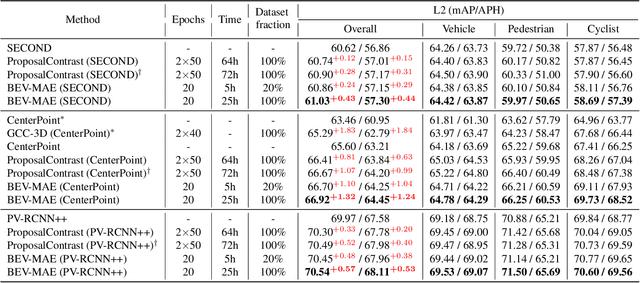
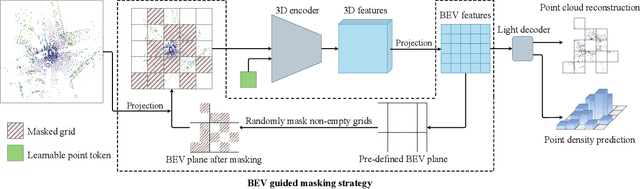

Current outdoor LiDAR-based 3D object detection methods mainly adopt the training-from-scratch paradigm. Unfortunately, this paradigm heavily relies on large-scale labeled data, whose collection can be expensive and time-consuming. Self-supervised pre-training is an effective and desirable way to alleviate this dependence on extensive annotated data. Recently, masked modeling has become a successful self-supervised learning approach for point clouds. However, current works mainly focus on synthetic or indoor datasets. When applied to large-scale and sparse outdoor point clouds, they fail to yield satisfactory results. In this work, we present BEV-MAE, a simple masked autoencoder pre-training framework for 3D object detection on outdoor point clouds. Specifically, we first propose a bird's eye view (BEV) guided masking strategy to guide the 3D encoder learning feature representation in a BEV perspective and avoid complex decoder design during pre-training. Besides, we introduce a learnable point token to maintain a consistent receptive field size of the 3D encoder with fine-tuning for masked point cloud inputs. Finally, based on the property of outdoor point clouds, i.e., the point clouds of distant objects are more sparse, we propose point density prediction to enable the 3D encoder to learn location information, which is essential for object detection. Experimental results show that BEV-MAE achieves new state-of-the-art self-supervised results on both Waymo and nuScenes with diverse 3D object detectors. Furthermore, with only 20% data and 7% training cost during pre-training, BEV-MAE achieves comparable performance with the state-of-the-art method ProposalContrast. The source code and pre-trained models will be made publicly available.
Learning Location from Shared Elevation Profiles in Fitness Apps: A Privacy Perspective
Oct 27, 2022
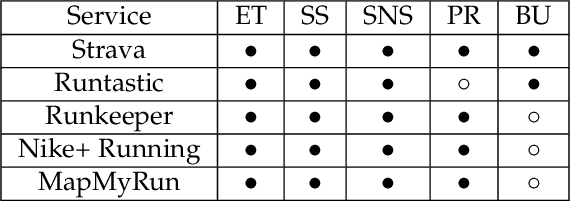
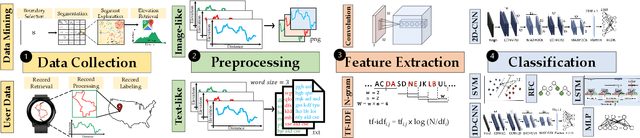
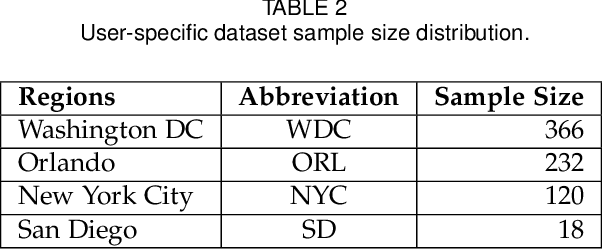
The extensive use of smartphones and wearable devices has facilitated many useful applications. For example, with Global Positioning System (GPS)-equipped smart and wearable devices, many applications can gather, process, and share rich metadata, such as geolocation, trajectories, elevation, and time. For example, fitness applications, such as Runkeeper and Strava, utilize the information for activity tracking and have recently witnessed a boom in popularity. Those fitness tracker applications have their own web platforms and allow users to share activities on such platforms or even with other social network platforms. To preserve the privacy of users while allowing sharing, several of those platforms may allow users to disclose partial information, such as the elevation profile for an activity, which supposedly would not leak the location of the users. In this work, and as a cautionary tale, we create a proof of concept where we examine the extent to which elevation profiles can be used to predict the location of users. To tackle this problem, we devise three plausible threat settings under which the city or borough of the targets can be predicted. Those threat settings define the amount of information available to the adversary to launch the prediction attacks. Establishing that simple features of elevation profiles, e.g., spectral features, are insufficient, we devise both natural language processing (NLP)-inspired text-like representation and computer vision-inspired image-like representation of elevation profiles, and we convert the problem at hand into text and image classification problem. We use both traditional machine learning- and deep learning-based techniques and achieve a prediction success rate ranging from 59.59\% to 99.80\%. The findings are alarming, highlighting that sharing elevation information may have significant location privacy risks.
Dynamic physical activity recommendation on personalised mobile health information service: A deep reinforcement learning approach
Apr 03, 2022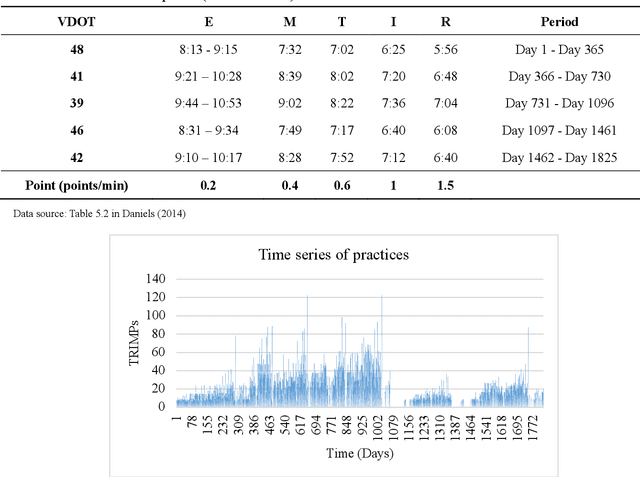
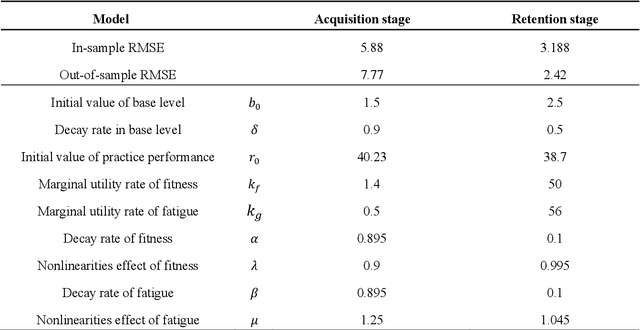


Mobile health (mHealth) information service makes healthcare management easier for users, who want to increase physical activity and improve health. However, the differences in activity preference among the individual, adherence problems, and uncertainty of future health outcomes may reduce the effect of the mHealth information service. The current health service system usually provides recommendations based on fixed exercise plans that do not satisfy the user specific needs. This paper seeks an efficient way to make physical activity recommendation decisions on physical activity promotion in personalised mHealth information service by establishing data-driven model. In this study, we propose a real-time interaction model to select the optimal exercise plan for the individual considering the time-varying characteristics in maximising the long-term health utility of the user. We construct a framework for mHealth information service system comprising a personalised AI module, which is based on the scientific knowledge about physical activity to evaluate the individual exercise performance, which may increase the awareness of the mHealth artificial intelligence system. The proposed deep reinforcement learning (DRL) methodology combining two classes of approaches to improve the learning capability for the mHealth information service system. A deep learning method is introduced to construct the hybrid neural network combing long-short term memory (LSTM) network and deep neural network (DNN) techniques to infer the individual exercise behavior from the time series data. A reinforcement learning method is applied based on the asynchronous advantage actor-critic algorithm to find the optimal policy through exploration and exploitation.
Machine Learning-Based Distributed Authentication of UWAN Nodes with Limited Shared Information
Aug 19, 2022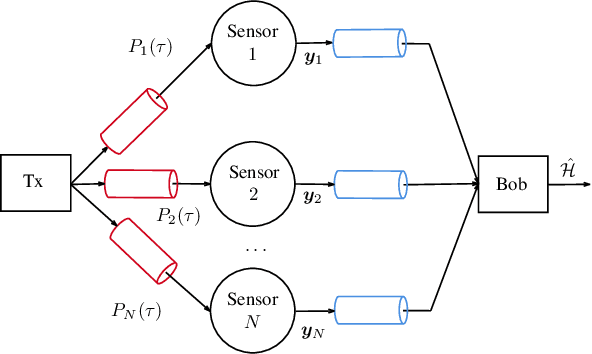
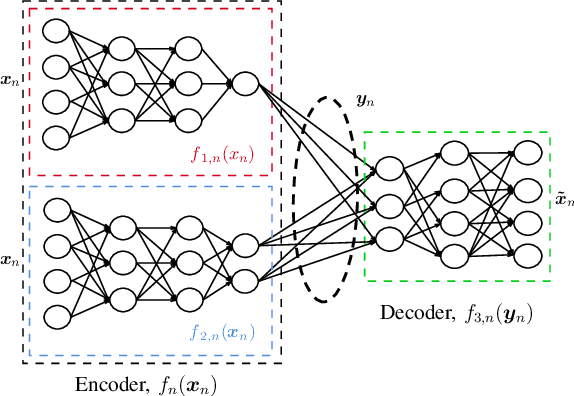
We propose a technique to authenticate received packets in underwater acoustic networks based on the physical layer features of the underwater acoustic channel (UWAC). Several sensors a) locally estimate features (e.g., the number of taps or the delay spread) of the UWAC over which the packet is received, b) obtain a compressed feature representation through a neural network (NN), and c) transmit their representations to a central sink node that, using a NN, decides whether the packet has been transmitted by the legitimate node or by an impersonating attacker. Although the purpose of the system is to make a binary decision as to whether a packet is authentic or not, we show the importance of having a rich set of compressed features, while still taking into account transmission rate limits among the nodes. We consider both global training, where all NNs are trained together, and local training, where each NN is trained individually. For the latter scenario, several alternatives for the NN structure and loss function were used for training.
HAQJSK: Hierarchical-Aligned Quantum Jensen-Shannon Kernels for Graph Classification
Nov 08, 2022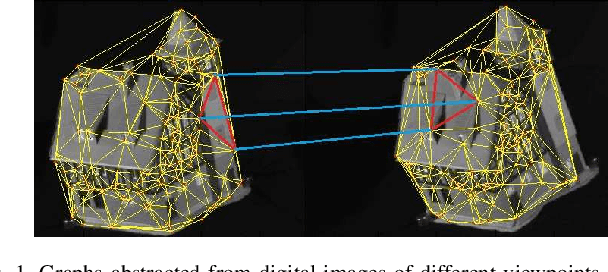
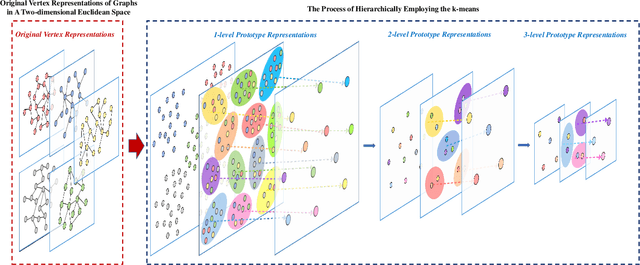
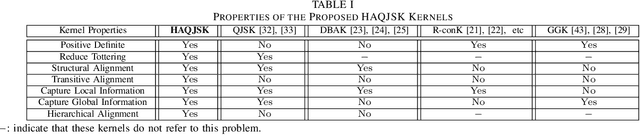
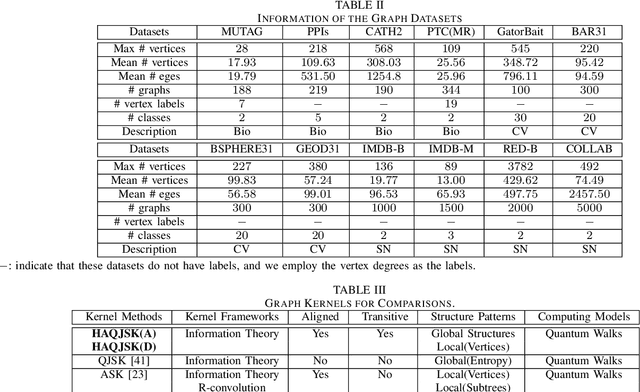
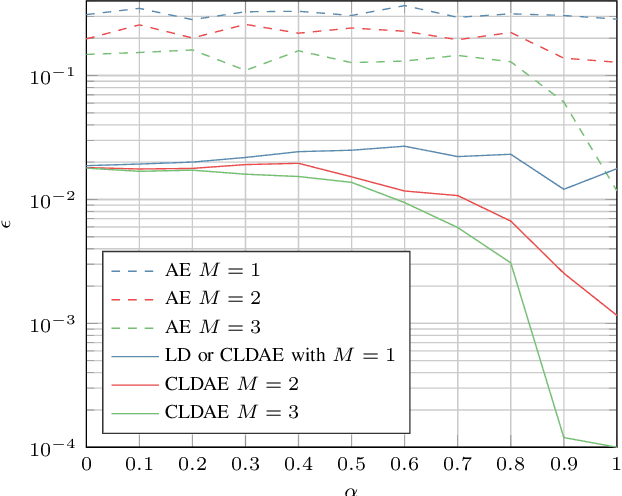
In this work, we propose a family of novel quantum kernels, namely the Hierarchical Aligned Quantum Jensen-Shannon Kernels (HAQJSK), for un-attributed graphs. Different from most existing classical graph kernels, the proposed HAQJSK kernels can incorporate hierarchical aligned structure information between graphs and transform graphs of random sizes into fixed-sized aligned graph structures, i.e., the Hierarchical Transitive Aligned Adjacency Matrix of vertices and the Hierarchical Transitive Aligned Density Matrix of the Continuous-Time Quantum Walk (CTQW). For a pair of graphs to hand, the resulting HAQJSK kernels are defined by measuring the Quantum Jensen-Shannon Divergence (QJSD) between their transitive aligned graph structures. We show that the proposed HAQJSK kernels not only reflect richer intrinsic global graph characteristics in terms of the CTQW, but also address the drawback of neglecting structural correspondence information arising in most existing R-convolution kernels. Furthermore, unlike the previous Quantum Jensen-Shannon Kernels associated with the QJSD and the CTQW, the proposed HAQJSK kernels can simultaneously guarantee the properties of permutation invariant and positive definiteness, explaining the theoretical advantages of the HAQJSK kernels. Experiments indicate the effectiveness of the proposed kernels.