 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Purifier: Defending Data Inference Attacks via Transforming Confidence Scores
Dec 01, 2022
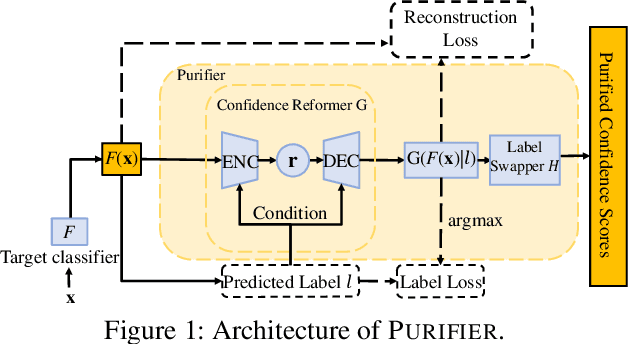
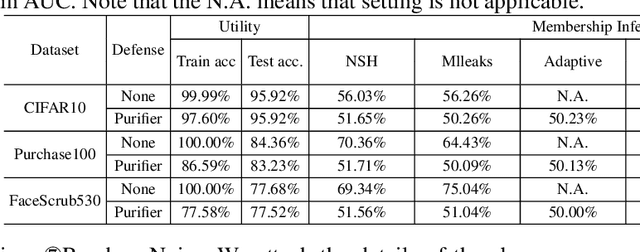
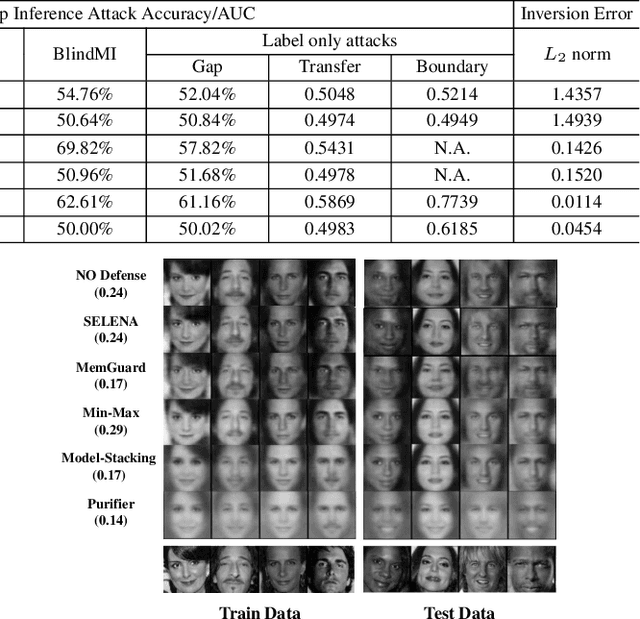
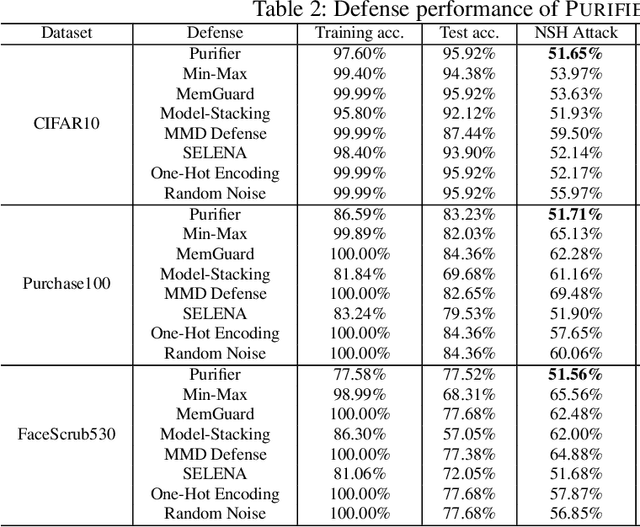
Neural networks are susceptible to data inference attacks such as the membership inference attack, the adversarial model inversion attack and the attribute inference attack, where the attacker could infer useful information such as the membership, the reconstruction or the sensitive attributes of a data sample from the confidence scores predicted by the target classifier. In this paper, we propose a method, namely PURIFIER, to defend against membership inference attacks. It transforms the confidence score vectors predicted by the target classifier and makes purified confidence scores indistinguishable in individual shape, statistical distribution and prediction label between members and non-members. The experimental results show that PURIFIER helps defend membership inference attacks with high effectiveness and efficiency, outperforming previous defense methods, and also incurs negligible utility loss. Besides, our further experiments show that PURIFIER is also effective in defending adversarial model inversion attacks and attribute inference attacks. For example, the inversion error is raised about 4+ times on the Facescrub530 classifier, and the attribute inference accuracy drops significantly when PURIFIER is deployed in our experiment.
Learning Progressive Modality-shared Transformers for Effective Visible-Infrared Person Re-identification
Dec 01, 2022
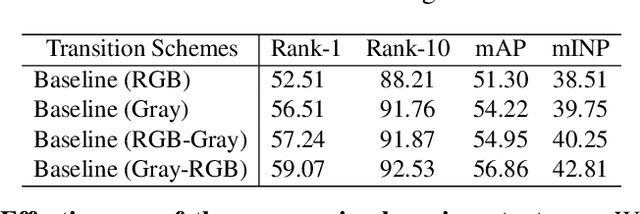
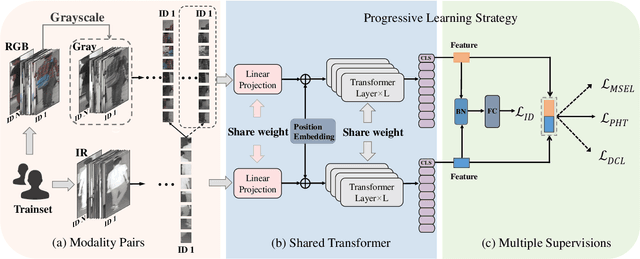
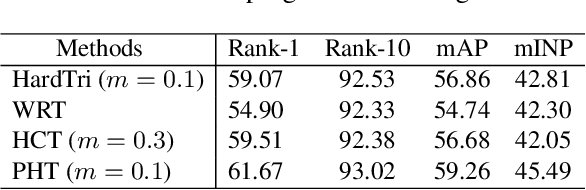
Visible-Infrared Person Re-Identification (VI-ReID) is a challenging retrieval task under complex modality changes. Existing methods usually focus on extracting discriminative visual features while ignoring the reliability and commonality of visual features between different modalities. In this paper, we propose a novel deep learning framework named Progressive Modality-shared Transformer (PMT) for effective VI-ReID. To reduce the negative effect of modality gaps, we first take the gray-scale images as an auxiliary modality and propose a progressive learning strategy. Then, we propose a Modality-Shared Enhancement Loss (MSEL) to guide the model to explore more reliable identity information from modality-shared features. Finally, to cope with the problem of large intra-class differences and small inter-class differences, we propose a Discriminative Center Loss (DCL) combined with the MSEL to further improve the discrimination of reliable features. Extensive experiments on SYSU-MM01 and RegDB datasets show that our proposed framework performs better than most state-of-the-art methods. For model reproduction, we release the source code at https://github.com/hulu88/PMT.
A novel TomoSAR imaging method with few observations based on nested array
Dec 01, 2022
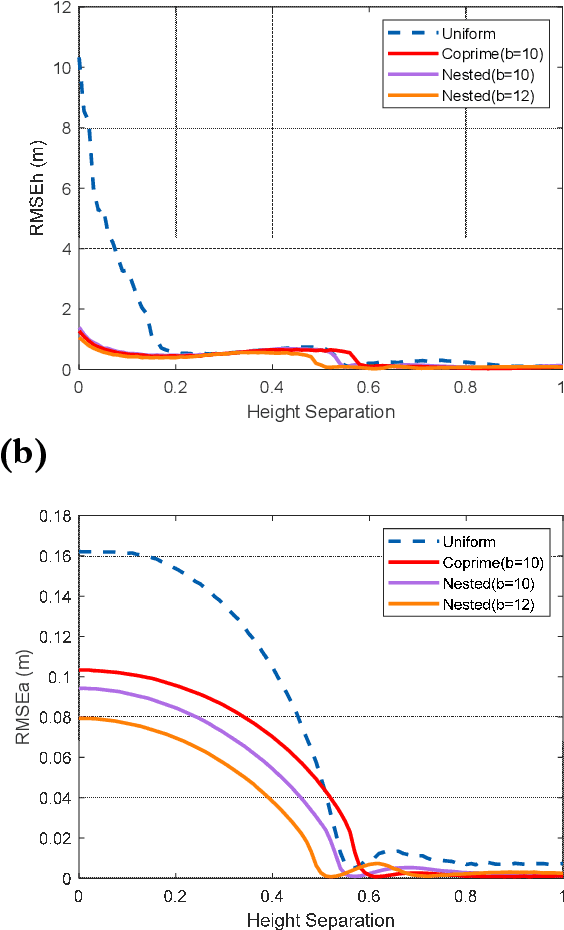
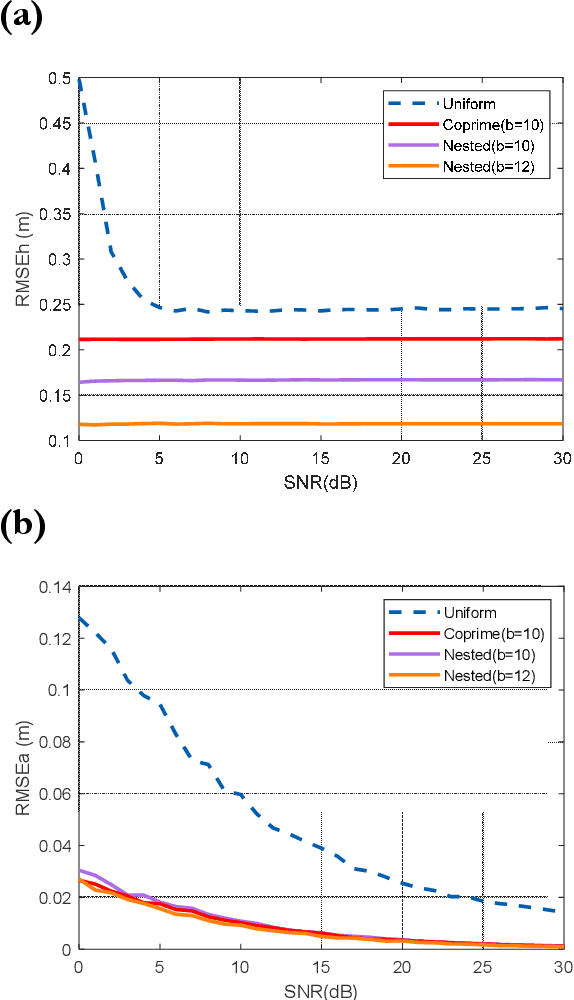
Synthetic aperture radar tomography (TomoSAR) baseline optimization technique is capable of reducing system complexity and improving the temporal coherence of data, which has become an important research in the field of TomoSAR. In this paper, we propose a nested TomoSAR technique, which introduces the nested array into TomoSAR as the baseline configuration. This technique obtains uniform and continuous difference co-array through nested array to increase the degrees of freedom (DoF) of the system and expands the virtual aperture along the elevation direction. In order to make full use of the difference co-array, covariance matrix of the echo needs to be obtained. Therefore, we propose a TomoSAR sparse reconstruction algorithm based on nested array, which uses adaptive covariance matrix estimation to improve the estimation performance in complex scenes. We demonstrate the effectiveness of the proposed method through simulated and real data experiments. Compared with traditional TomoSAR and coprime TomoSAR, the imaging results of our proposed method have a better anti-noise performance and retain more image information.
Ghost-free High Dynamic Range Imaging via Hybrid CNN-Transformer and Structure Tensor
Dec 01, 2022

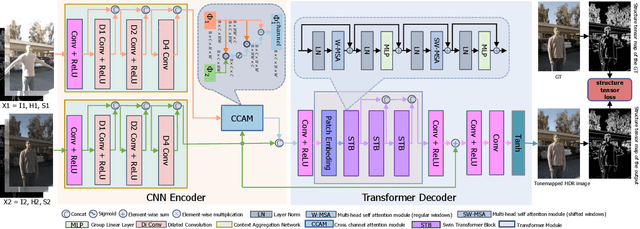
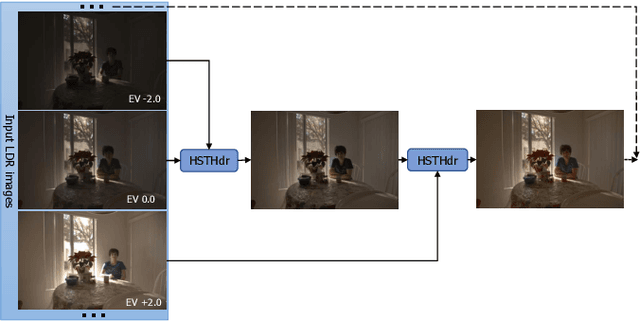
Eliminating ghosting artifacts due to moving objects is a challenging problem in high dynamic range (HDR) imaging. In this letter, we present a hybrid model consisting of a convolutional encoder and a Transformer decoder to generate ghost-free HDR images. In the encoder, a context aggregation network and non-local attention block are adopted to optimize multi-scale features and capture both global and local dependencies of multiple low dynamic range (LDR) images. The decoder based on Swin Transformer is utilized to improve the reconstruction capability of the proposed model. Motivated by the phenomenal difference between the presence and absence of artifacts under the field of structure tensor (ST), we integrate the ST information of LDR images as auxiliary inputs of the network and use ST loss to further constrain artifacts. Different from previous approaches, our network is capable of processing an arbitrary number of input LDR images. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method by comparing it with existing state-of-the-art HDR deghosting models. Codes are available at https://github.com/pandayuanyu/HSTHdr.
From CNNs to Shift-Invariant Twin Wavelet Models
Dec 01, 2022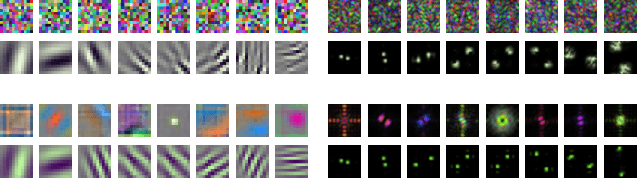

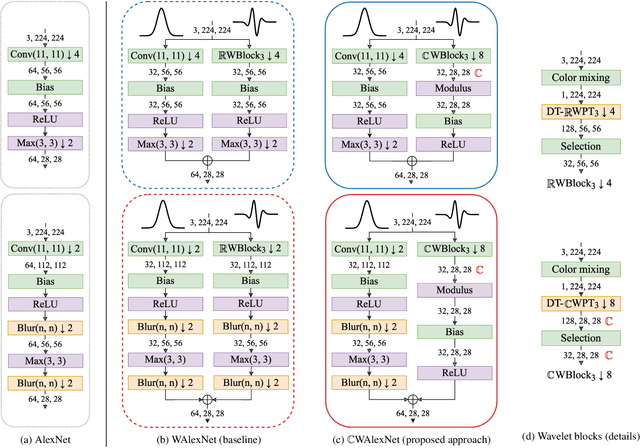
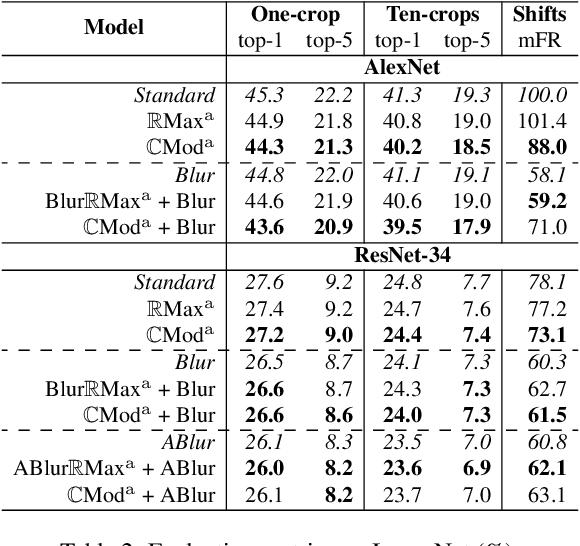
We propose a novel antialiasing method to increase shift invariance in convolutional neural networks (CNNs). More precisely, we replace the conventional combination "real-valued convolutions + max pooling" ($\mathbb R$Max) by "complex-valued convolutions + modulus" ($\mathbb C$Mod), which produce stable feature representations for band-pass filters with well-defined orientations. In a recent work, we proved that, for such filters, the two operators yield similar outputs. Therefore, $\mathbb C$Mod can be viewed as a stable alternative to $\mathbb R$Max. To separate band-pass filters from other freely-trained kernels, in this paper, we designed a "twin" architecture based on the dual-tree complex wavelet packet transform, which generates similar outputs as standard CNNs with fewer trainable parameters. In addition to improving stability to small shifts, our experiments on AlexNet and ResNet showed increased prediction accuracy on natural image datasets such as ImageNet and CIFAR10. Furthermore, our approach outperformed recent antialiasing methods based on low-pass filtering by preserving high-frequency information, while reducing memory usage.
CliMedBERT: A Pre-trained Language Model for Climate and Health-related Text
Dec 01, 2022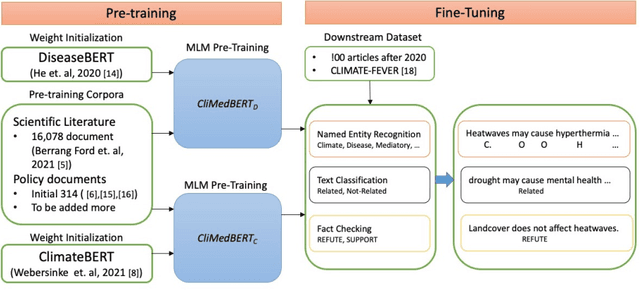
Climate change is threatening human health in unprecedented orders and many ways. These threats are expected to grow unless effective and evidence-based policies are developed and acted upon to minimize or eliminate them. Attaining such a task requires the highest degree of the flow of knowledge from science into policy. The multidisciplinary, location-specific, and vastness of published science makes it challenging to keep track of novel work in this area, as well as making the traditional knowledge synthesis methods inefficient in infusing science into policy. To this end, we consider developing multiple domain-specific language models (LMs) with different variations from Climate- and Health-related information, which can serve as a foundational step toward capturing available knowledge to enable solving different tasks, such as detecting similarities between climate- and health-related concepts, fact-checking, relation extraction, evidence of health effects to policy text generation, and more. To our knowledge, this is the first work that proposes developing multiple domain-specific language models for the considered domains. We will make the developed models, resources, and codebase available for the researchers.
Principled Multi-Aspect Evaluation Measures of Rankings
Dec 01, 2022


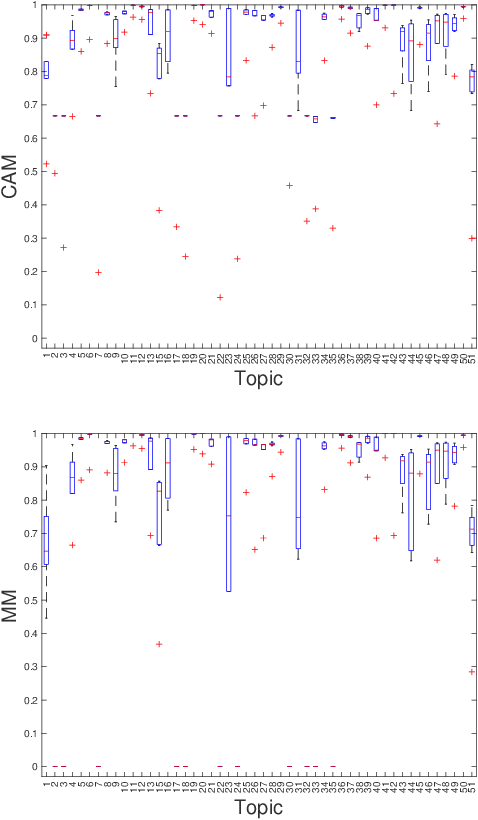
Information Retrieval evaluation has traditionally focused on defining principled ways of assessing the relevance of a ranked list of documents with respect to a query. Several methods extend this type of evaluation beyond relevance, making it possible to evaluate different aspects of a document ranking (e.g., relevance, usefulness, or credibility) using a single measure (multi-aspect evaluation). However, these methods either are (i) tailor-made for specific aspects and do not extend to other types or numbers of aspects, or (ii) have theoretical anomalies, e.g. assign maximum score to a ranking where all documents are labelled with the lowest grade with respect to all aspects (e.g., not relevant, not credible, etc.). We present a theoretically principled multi-aspect evaluation method that can be used for any number, and any type, of aspects. A thorough empirical evaluation using up to 5 aspects and a total of 425 runs officially submitted to 10 TREC tracks shows that our method is more discriminative than the state-of-the-art and overcomes theoretical limitations of the state-of-the-art.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022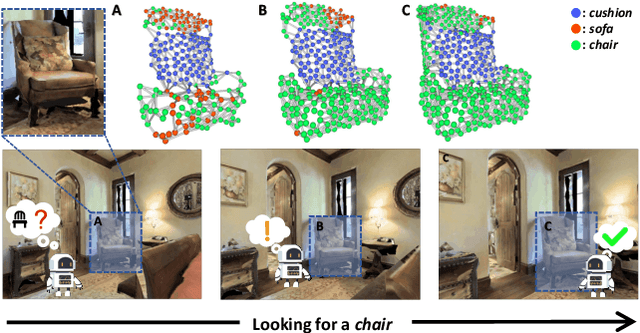
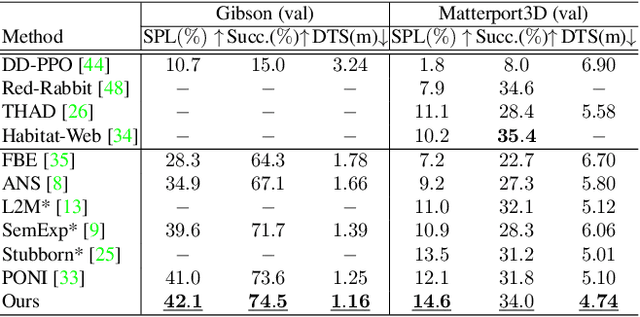
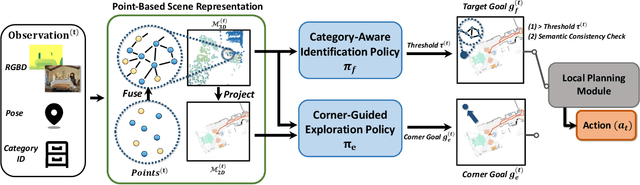
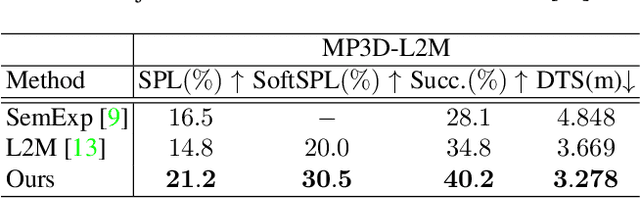
Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.
3D Scene Inference from Transient Histograms
Nov 09, 2022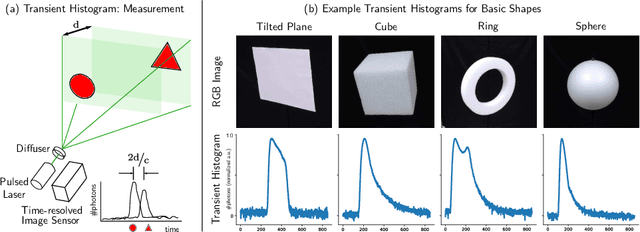
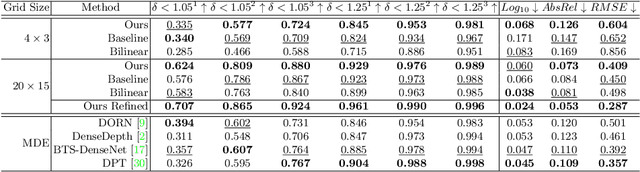
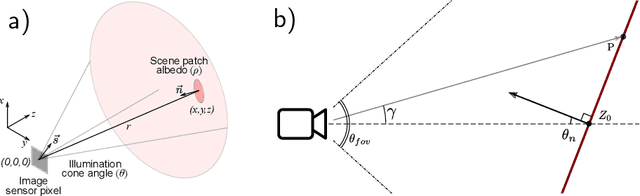
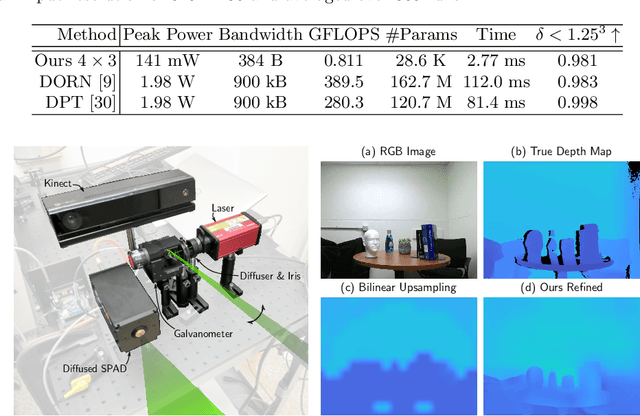
Time-resolved image sensors that capture light at pico-to-nanosecond timescales were once limited to niche applications but are now rapidly becoming mainstream in consumer devices. We propose low-cost and low-power imaging modalities that capture scene information from minimal time-resolved image sensors with as few as one pixel. The key idea is to flood illuminate large scene patches (or the entire scene) with a pulsed light source and measure the time-resolved reflected light by integrating over the entire illuminated area. The one-dimensional measured temporal waveform, called \emph{transient}, encodes both distances and albedoes at all visible scene points and as such is an aggregate proxy for the scene's 3D geometry. We explore the viability and limitations of the transient waveforms by themselves for recovering scene information, and also when combined with traditional RGB cameras. We show that plane estimation can be performed from a single transient and that using only a few more it is possible to recover a depth map of the whole scene. We also show two proof-of-concept hardware prototypes that demonstrate the feasibility of our approach for compact, mobile, and budget-limited applications.
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
Mar 21, 2022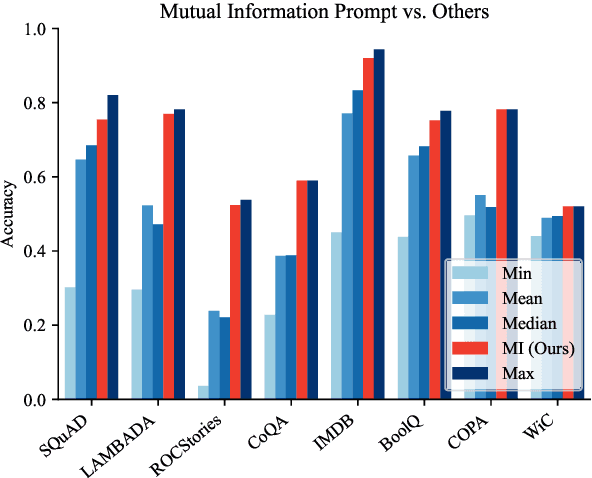
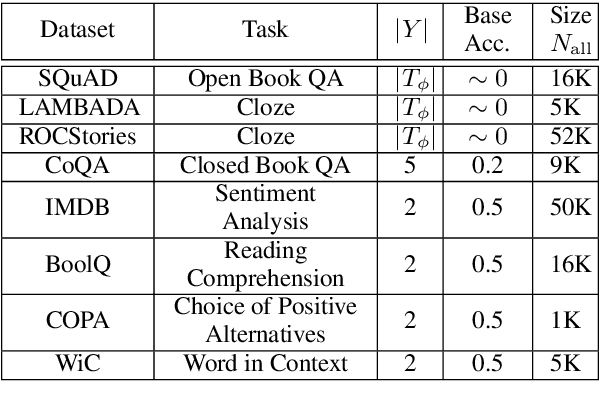
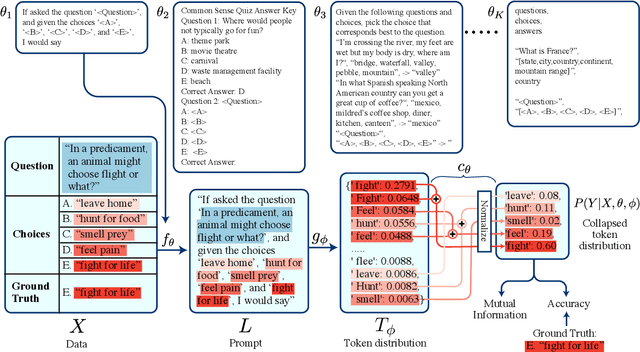
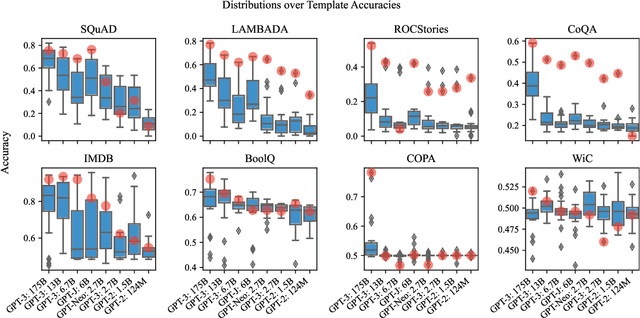
Pre-trained language models derive substantial linguistic and factual knowledge from the massive corpora on which they are trained, and prompt engineering seeks to align these models to specific tasks. Unfortunately, existing prompt engineering methods require significant amounts of labeled data, access to model parameters, or both. We introduce a new method for selecting prompt templates \textit{without labeled examples} and \textit{without direct access to the model}. Specifically, over a set of candidate templates, we choose the template that maximizes the mutual information between the input and the corresponding model output. Across 8 datasets representing 7 distinct NLP tasks, we show that when a template has high mutual information, it also has high accuracy on the task. On the largest model, selecting prompts with our method gets 90\% of the way from the average prompt accuracy to the best prompt accuracy and requires no ground truth labels.