 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Service resource allocation problem in the IoT driven personalized healthcare information platform
Apr 05, 2022
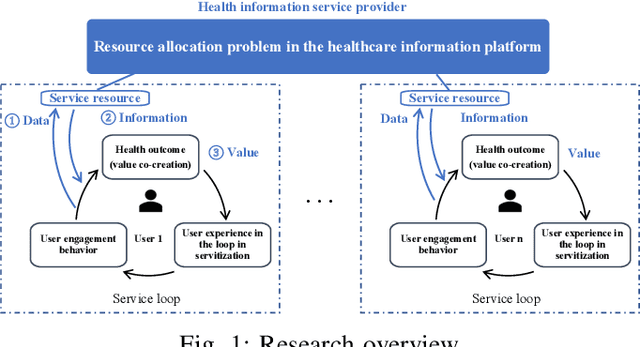
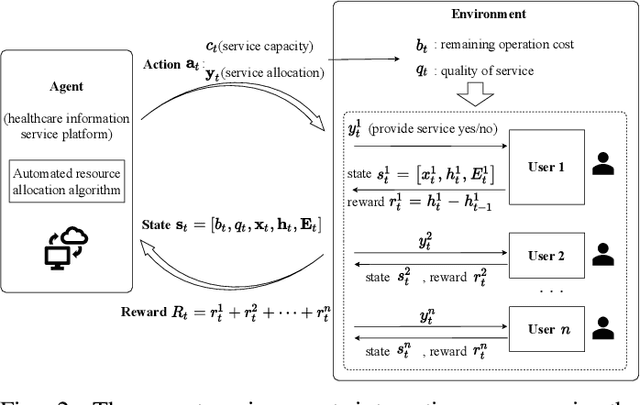
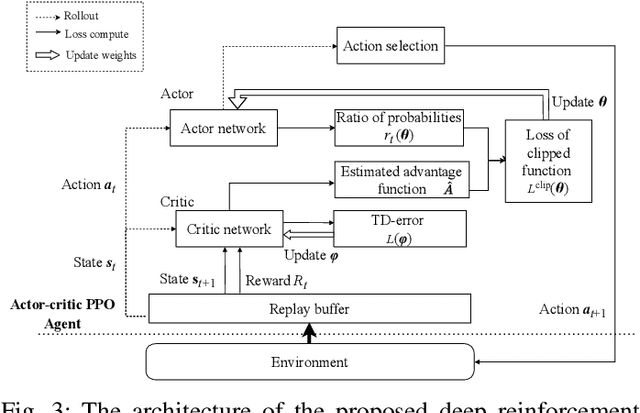
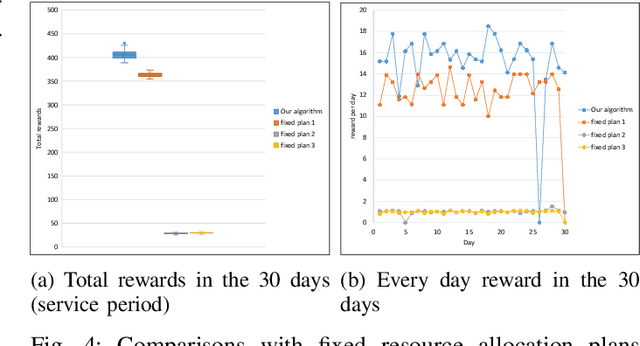
With real-time monitoring of the personalized healthcare condition, the IoT wearables collect the health data and transfer it to the healthcare information platform. The platform processes the data into healthcare recommendations and then delivers them to the users. The IoT structures in the personalized healthcare information service allows the users to engage in the loop in servitization more convenient in the COVID-19 pandemic. However, the uncertainty of the engagement behavior among the individual may result in inefficient of the service resource allocation. This paper seeks an efficient way to allocate the service resource by controlling the service capacity and pushing the service to the active users automatically. In this study, we propose a deep reinforcement learning method to solve the service resource allocation problem based on the proximal policy optimization (PPO) algorithm. Experimental results using the real world (open source) sport dataset reveal that our proposed proximal policy optimization adapts well to the users' changing behavior and with improved performance over fixed service resource policies.
Using Features at Multiple Temporal and Spatial Resolutions to Predict Human Behavior in Real Time
Nov 12, 2022

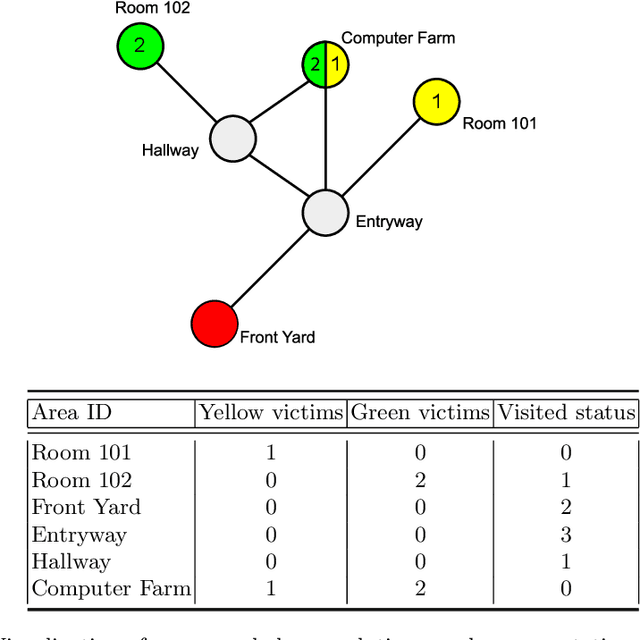

When performing complex tasks, humans naturally reason at multiple temporal and spatial resolutions simultaneously. We contend that for an artificially intelligent agent to effectively model human teammates, i.e., demonstrate computational theory of mind (ToM), it should do the same. In this paper, we present an approach for integrating high and low-resolution spatial and temporal information to predict human behavior in real time and evaluate it on data collected from human subjects performing simulated urban search and rescue (USAR) missions in a Minecraft-based environment. Our model composes neural networks for high and low-resolution feature extraction with a neural network for behavior prediction, with all three networks trained simultaneously. The high-resolution extractor encodes dynamically changing goals robustly by taking as input the Manhattan distance difference between the humans' Minecraft avatars and candidate goals in the environment for the latest few actions, computed from a high-resolution gridworld representation. In contrast, the low-resolution extractor encodes participants' historical behavior using a historical state matrix computed from a low-resolution graph representation. Through supervised learning, our model acquires a robust prior for human behavior prediction, and can effectively deal with long-term observations. Our experimental results demonstrate that our method significantly improves prediction accuracy compared to approaches that only use high-resolution information.
Semantic Graph Neural Network with Multi-measure Learning for Semi-supervised Classification
Dec 04, 2022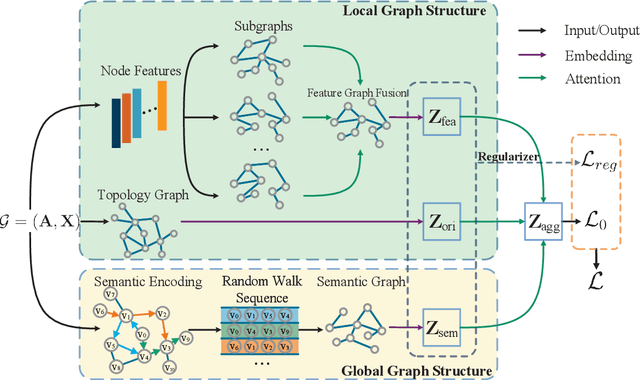
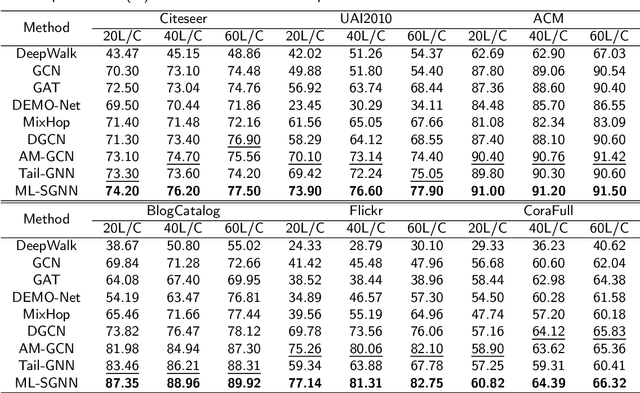
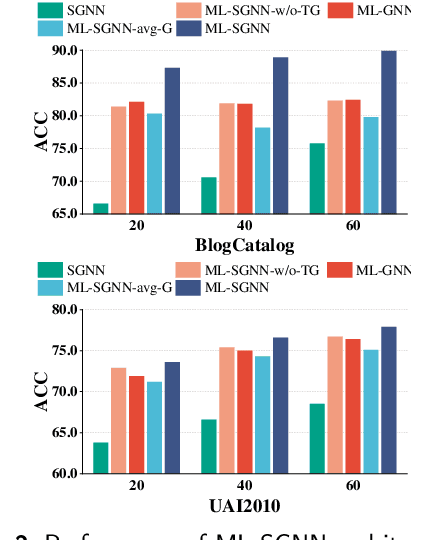
Graph Neural Networks (GNNs) have attracted increasing attention in recent years and have achieved excellent performance in semi-supervised node classification tasks. The success of most GNNs relies on one fundamental assumption, i.e., the original graph structure data is available. However, recent studies have shown that GNNs are vulnerable to the complex underlying structure of the graph, making it necessary to learn comprehensive and robust graph structures for downstream tasks, rather than relying only on the raw graph structure. In light of this, we seek to learn optimal graph structures for downstream tasks and propose a novel framework for semi-supervised classification. Specifically, based on the structural context information of graph and node representations, we encode the complex interactions in semantics and generate semantic graphs to preserve the global structure. Moreover, we develop a novel multi-measure attention layer to optimize the similarity rather than prescribing it a priori, so that the similarity can be adaptively evaluated by integrating measures. These graphs are fused and optimized together with GNN towards semi-supervised classification objective. Extensive experiments and ablation studies on six real-world datasets clearly demonstrate the effectiveness of our proposed model and the contribution of each component.
Deep learning based landslide density estimation on SAR data for rapid response
Nov 18, 2022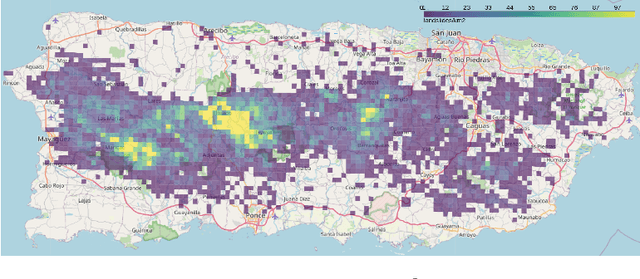
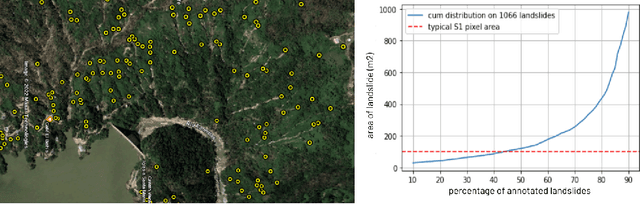
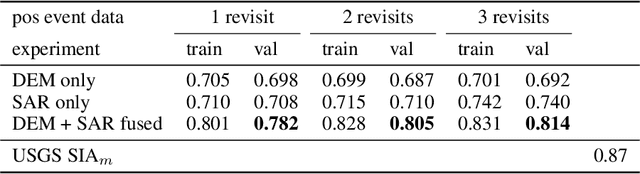
This work aims to produce landslide density estimates using Synthetic Aperture Radar (SAR) satellite imageries to prioritise emergency resources for rapid response. We use the United States Geological Survey (USGS) Landslide Inventory data annotated by experts after Hurricane Mar\'ia in Puerto Rico on Sept 20, 2017, and their subsequent susceptibility study which uses extensive additional information such as precipitation, soil moisture, geological terrain features, closeness to waterways and roads, etc. Since such data might not be available during other events or regions, we aimed to produce a landslide density map using only elevation and SAR data to be useful to decision-makers in rapid response scenarios. The USGS Landslide Inventory contains the coordinates of 71,431 landslide heads (not their full extent) and was obtained by manual inspection of aerial and satellite imagery. It is estimated that around 45\% of the landslides are smaller than a Sentinel-1 typical pixel which is 10m $\times$ 10m, although many are long and thin, probably leaving traces across several pixels. Our method obtains 0.814 AUC in predicting the correct density estimation class at the chip level (128$\times$128 pixels, at Sentinel-1 resolution) using only elevation data and up to three SAR acquisitions pre- and post-hurricane, thus enabling rapid assessment after a disaster. The USGS Susceptibility Study reports a 0.87 AUC, but it is measured at the landslide level and uses additional information sources (such as proximity to fluvial channels, roads, precipitation, etc.) which might not regularly be available in an rapid response emergency scenario.
Adversarial Detection without Model Information
Feb 09, 2022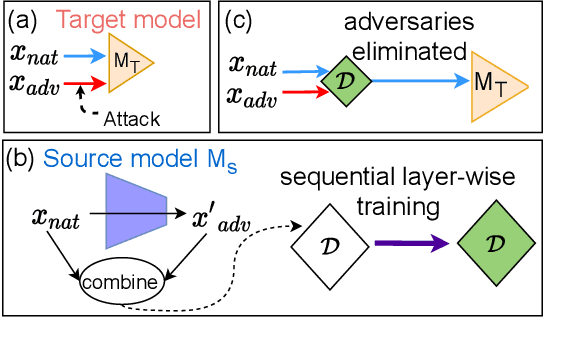

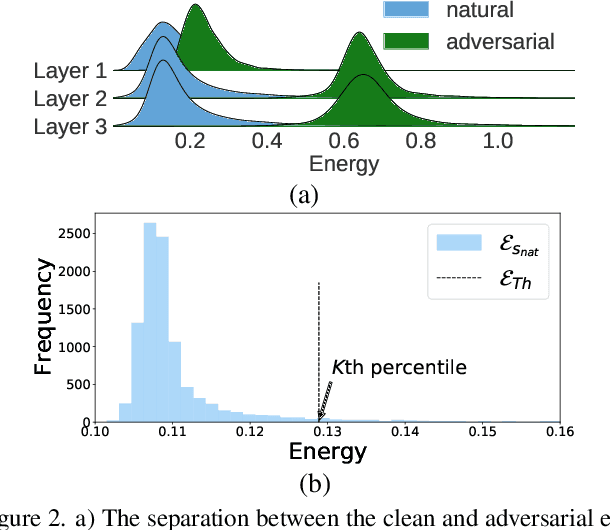

Most prior state-of-the-art adversarial detection works assume that the underlying vulnerable model is accessible, i,e., the model can be trained or its outputs are visible. However, this is not a practical assumption due to factors like model encryption, model information leakage and so on. In this work, we propose a model independent adversarial detection method using a simple energy function to distinguish between adversarial and natural inputs. We train a standalone detector independent of the underlying model, with sequential layer-wise training to increase the energy separation corresponding to natural and adversarial inputs. With this, we perform energy distribution-based adversarial detection. Our method achieves state-of-the-art detection performance (ROC-AUC > 0.9) across a wide range of gradient, score and decision-based adversarial attacks on CIFAR10, CIFAR100 and TinyImagenet datasets. Compared to prior approaches, our method requires ~10-100x less number of operations and parameters for adversarial detection. Further, we show that our detection method is transferable across different datasets and adversarial attacks. For reproducibility, we provide code in the supplementary material.
Fair Visual Recognition via Intervention with Proxy Features
Nov 02, 2022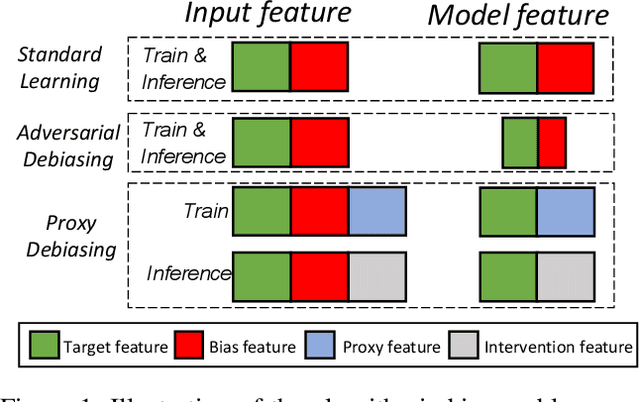
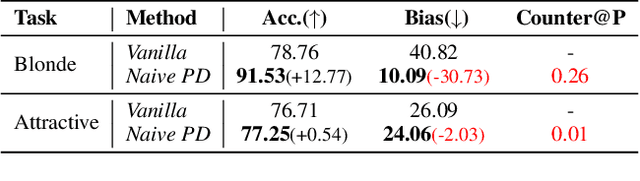
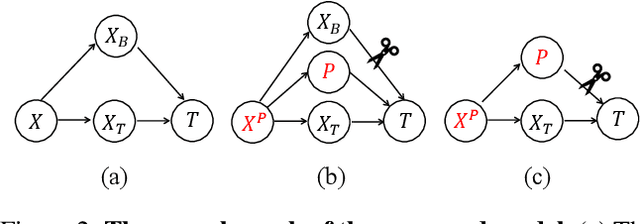
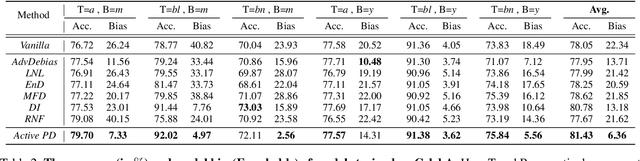
Deep learning models often learn to make predictions that rely on sensitive social attributes like gender and race, which poses significant fairness risks, especially in societal applications, e.g., hiring, banking, and criminal justice. Existing work tackles this issue by minimizing information about social attributes in models for debiasing. However, the high correlation between target task and social attributes makes bias mitigation incompatible with target task accuracy. Recalling that model bias arises because the learning of features in regard to bias attributes (i.e., bias features) helps target task optimization, we explore the following research question: \emph{Can we leverage proxy features to replace the role of bias feature in target task optimization for debiasing?} To this end, we propose \emph{Proxy Debiasing}, to first transfer the target task's learning of bias information from bias features to artificial proxy features, and then employ causal intervention to eliminate proxy features in inference. The key idea of \emph{Proxy Debiasing} is to design controllable proxy features to on one hand replace bias features in contributing to target task during the training stage, and on the other hand easily to be removed by intervention during the inference stage. This guarantees the elimination of bias features without affecting the target information, thus addressing the fairness-accuracy paradox in previous debiasing solutions. We apply \emph{Proxy Debiasing} to several benchmark datasets, and achieve significant improvements over the state-of-the-art debiasing methods in both of accuracy and fairness.
Ischemic Stroke Lesion Prediction using imbalanced Temporal Deep Gaussian Process (iTDGP)
Nov 16, 2022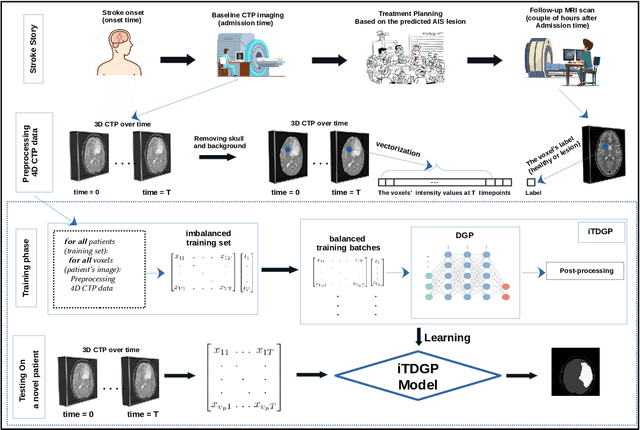
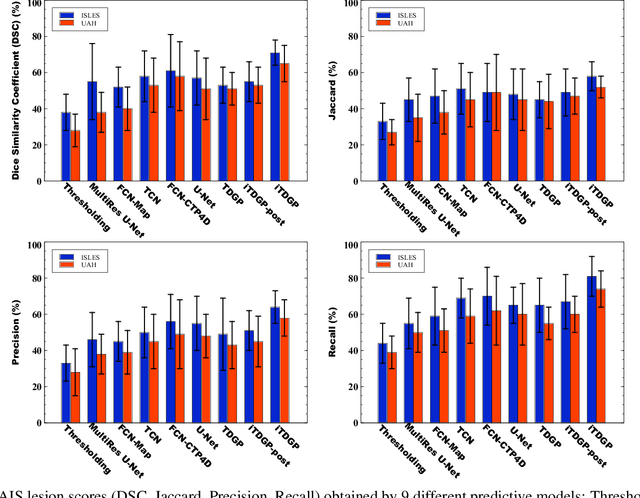
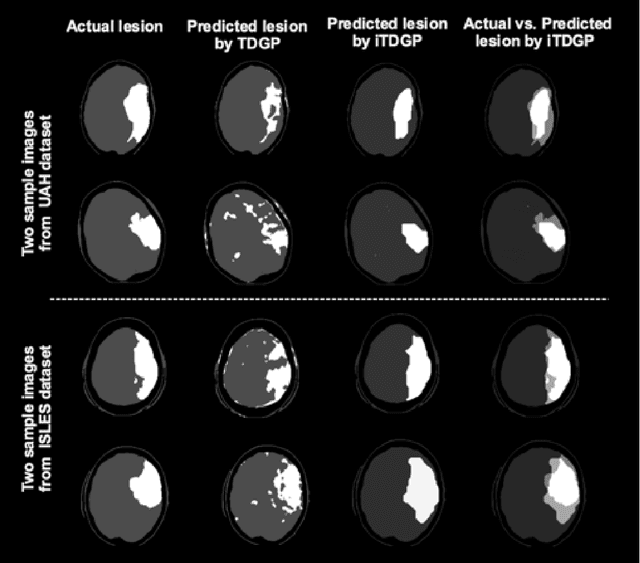
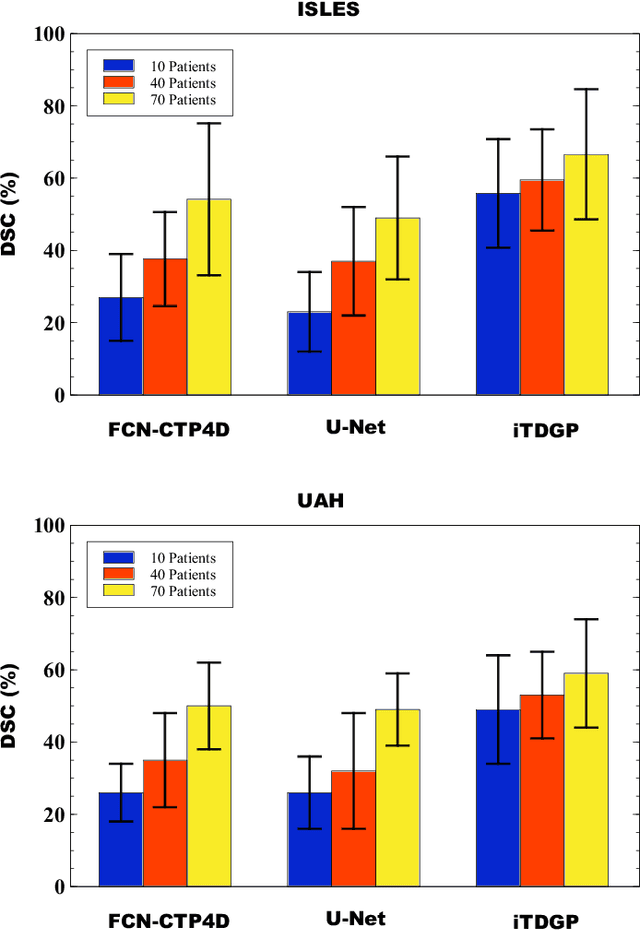
As one of the leading causes of mortality and disability worldwide, Acute Ischemic Stroke (AIS) occurs when the blood supply to the brain is suddenly interrupted because of a blocked artery. Within seconds of AIS onset, the brain cells surrounding the blocked artery die, which leads to the progression of the lesion. The automated and precise prediction of the existing lesion plays a vital role in the AIS treatment planning and prevention of further injuries. The current standard AIS assessment method, which thresholds the 3D measurement maps extracted from Computed Tomography Perfusion (CTP) images, is not accurate enough. Due to this fact, in this article, we propose the imbalanced Temporal Deep Gaussian Process (iTDGP), a probabilistic model that can improve AIS lesions prediction by using baseline CTP time series. Our proposed model can effectively extract temporal information from the CTP time series and map it to the class labels of the brain's voxels. In addition, by using batch training and voxel-level analysis iTDGP can learn from a few patients and it is robust against imbalanced classes. Moreover, our model incorporates a post-processor capable of improving prediction accuracy using spatial information. Our comprehensive experiments, on the ISLES 2018 and the University of Alberta Hospital (UAH) datasets, show that iTDGP performs better than state-of-the-art AIS lesion predictors, obtaining the (cross-validation) Dice score of 71.42% and 65.37% with a significant p<0.05, respectively.
Zero-Shot Learning for Joint Intent and Slot Labeling
Nov 29, 2022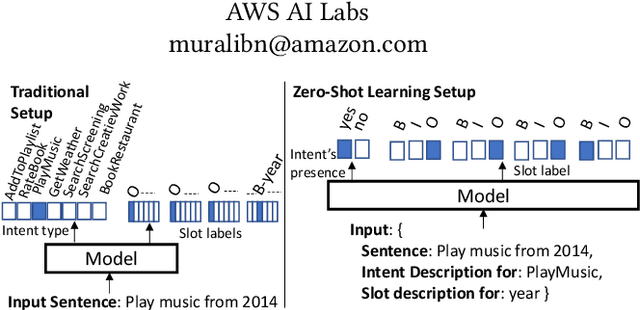
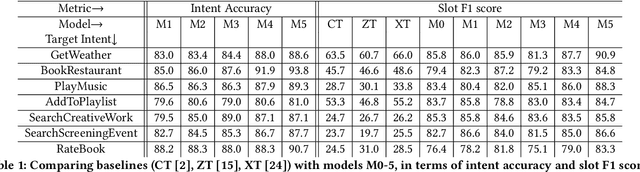

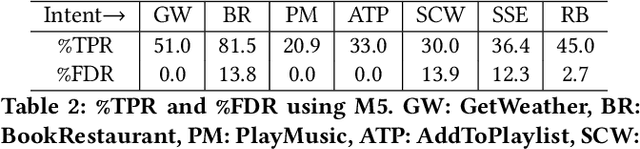
It is expensive and difficult to obtain the large number of sentence-level intent and token-level slot label annotations required to train neural network (NN)-based Natural Language Understanding (NLU) components of task-oriented dialog systems, especially for the many real world tasks that have a large and growing number of intents and slot types. While zero shot learning approaches that require no labeled examples -- only features and auxiliary information -- have been proposed only for slot labeling, we show that one can profitably perform joint zero-shot intent classification and slot labeling. We demonstrate the value of capturing dependencies between intents and slots, and between different slots in an utterance in the zero shot setting. We describe NN architectures that translate between word and sentence embedding spaces, and demonstrate that these modifications are required to enable zero shot learning for this task. We show a substantial improvement over strong baselines and explain the intuition behind each architectural modification through visualizations and ablation studies.
Best Subset Selection in Reduced Rank Regression
Nov 29, 2022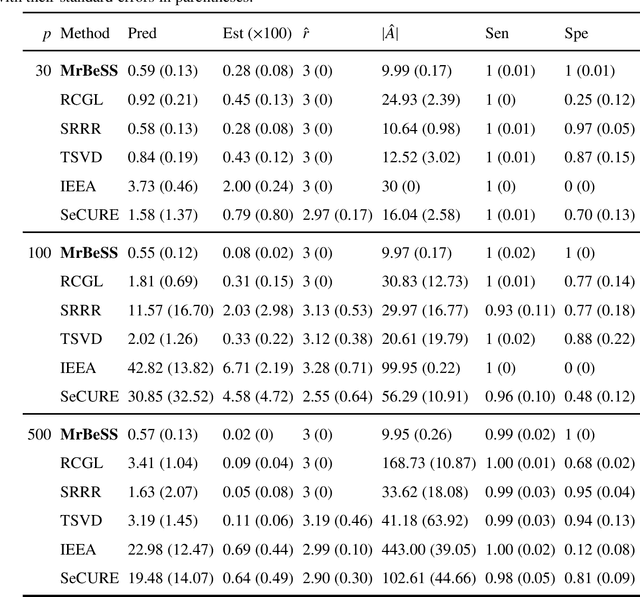
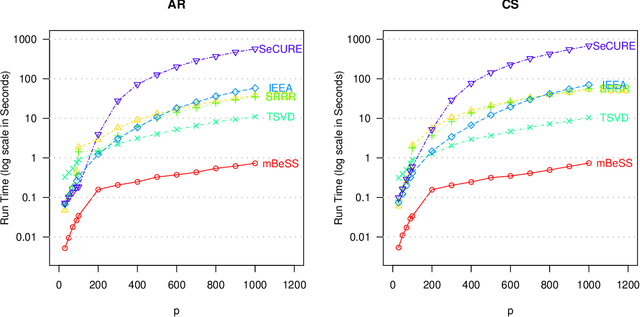
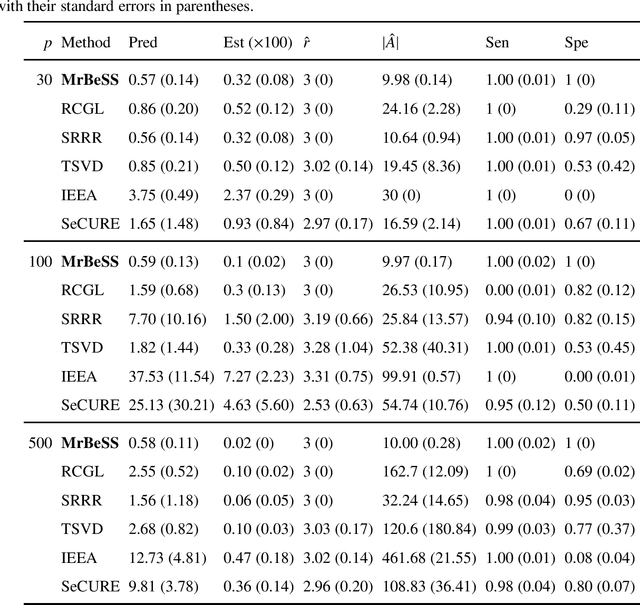
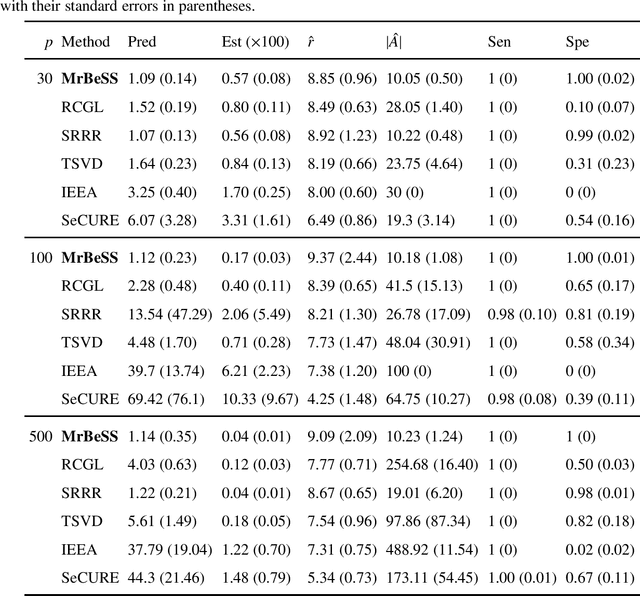
Sparse reduced rank regression is an essential statistical learning method. In the contemporary literature, estimation is typically formulated as a nonconvex optimization that often yields to a local optimum in numerical computation. Yet, their theoretical analysis is always centered on the global optimum, resulting in a discrepancy between the statistical guarantee and the numerical computation. In this research, we offer a new algorithm to address the problem and establish an almost optimal rate for the algorithmic solution. We also demonstrate that the algorithm achieves the estimation with a polynomial number of iterations. In addition, we present a generalized information criterion to simultaneously ensure the consistency of support set recovery and rank estimation. Under the proposed criterion, we show that our algorithm can achieve the oracle reduced rank estimation with a significant probability. The numerical studies and an application in the ovarian cancer genetic data demonstrate the effectiveness and scalability of our approach.
Adap DP-FL: Differentially Private Federated Learning with Adaptive Noise
Nov 29, 2022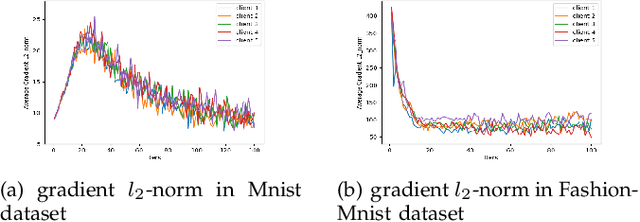
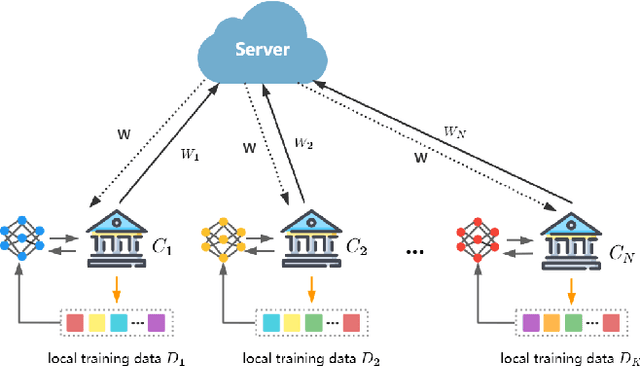
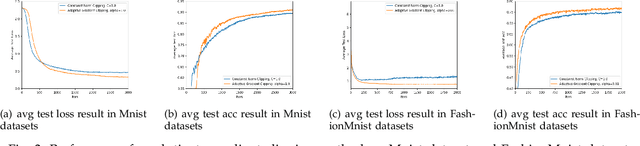
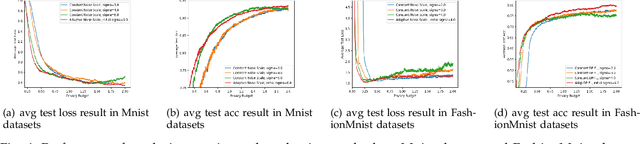
Federated learning seeks to address the issue of isolated data islands by making clients disclose only their local training models. However, it was demonstrated that private information could still be inferred by analyzing local model parameters, such as deep neural network model weights. Recently, differential privacy has been applied to federated learning to protect data privacy, but the noise added may degrade the learning performance much. Typically, in previous work, training parameters were clipped equally and noises were added uniformly. The heterogeneity and convergence of training parameters were simply not considered. In this paper, we propose a differentially private scheme for federated learning with adaptive noise (Adap DP-FL). Specifically, due to the gradient heterogeneity, we conduct adaptive gradient clipping for different clients and different rounds; due to the gradient convergence, we add decreasing noises accordingly. Extensive experiments on real-world datasets demonstrate that our Adap DP-FL outperforms previous methods significantly.