 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Scale Implicit Transformer with Re-parameterize for Arbitrary-Scale Super-Resolution
Mar 11, 2024

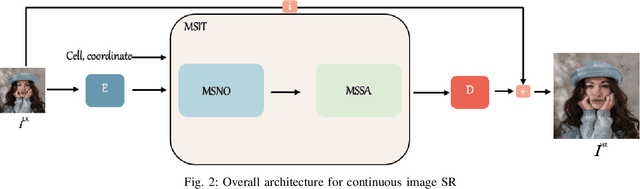
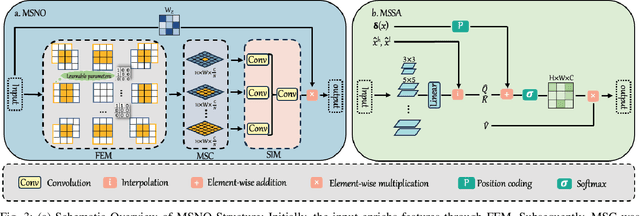
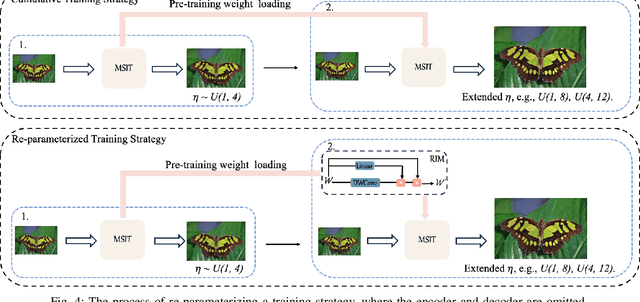
Recently, the methods based on implicit neural representations have shown excellent capabilities for arbitrary-scale super-resolution (ASSR). Although these methods represent the features of an image by generating latent codes, these latent codes are difficult to adapt for different magnification factors of super-resolution, which seriously affects their performance. Addressing this, we design Multi-Scale Implicit Transformer (MSIT), consisting of an Multi-scale Neural Operator (MSNO) and Multi-Scale Self-Attention (MSSA). Among them, MSNO obtains multi-scale latent codes through feature enhancement, multi-scale characteristics extraction, and multi-scale characteristics merging. MSSA further enhances the multi-scale characteristics of latent codes, resulting in better performance. Furthermore, to improve the performance of network, we propose the Re-Interaction Module (RIM) combined with the cumulative training strategy to improve the diversity of learned information for the network. We have systematically introduced multi-scale characteristics for the first time in ASSR, extensive experiments are performed to validate the effectiveness of MSIT, and our method achieves state-of-the-art performance in arbitrary super-resolution tasks.
OMH: Structured Sparsity via Optimally Matched Hierarchy for Unsupervised Semantic Segmentation
Mar 11, 2024
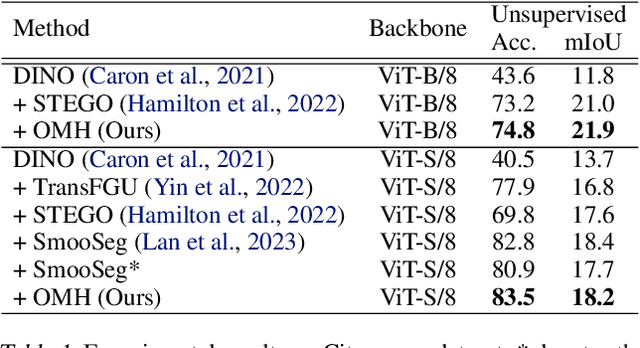
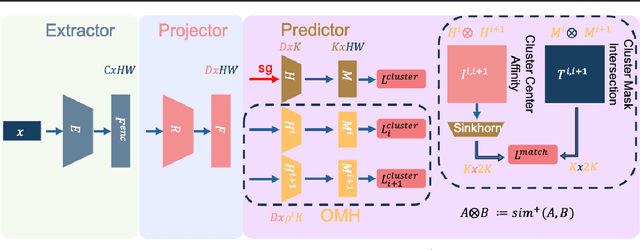

Unsupervised Semantic Segmentation (USS) involves segmenting images without relying on predefined labels, aiming to alleviate the burden of extensive human labeling. Existing methods utilize features generated by self-supervised models and specific priors for clustering. However, their clustering objectives are not involved in the optimization of the features during training. Additionally, due to the lack of clear class definitions in USS, the resulting segments may not align well with the clustering objective. In this paper, we introduce a novel approach called Optimally Matched Hierarchy (OMH) to simultaneously address the above issues. The core of our method lies in imposing structured sparsity on the feature space, which allows the features to encode information with different levels of granularity. The structure of this sparsity stems from our hierarchy (OMH). To achieve this, we learn a soft but sparse hierarchy among parallel clusters through Optimal Transport. Our OMH yields better unsupervised segmentation performance compared to existing USS methods. Our extensive experiments demonstrate the benefits of OMH when utilizing our differentiable paradigm. We will make our code publicly available.
Process-Aware Analysis of Treatment Paths in Heart Failure Patients: A Case Study
Mar 11, 2024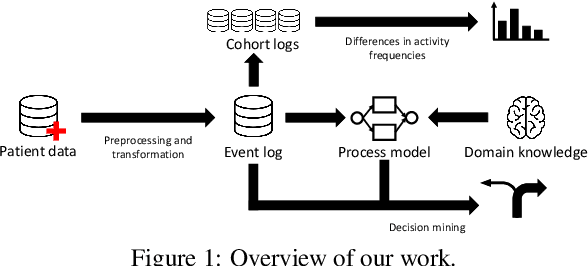
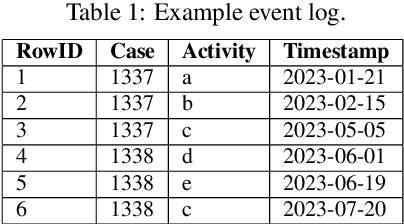
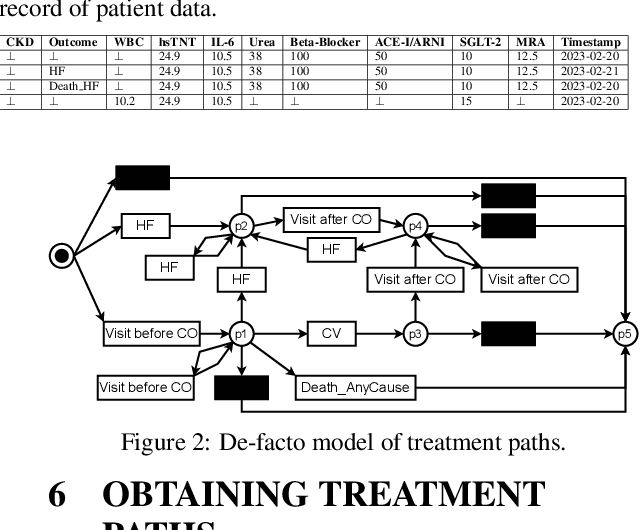
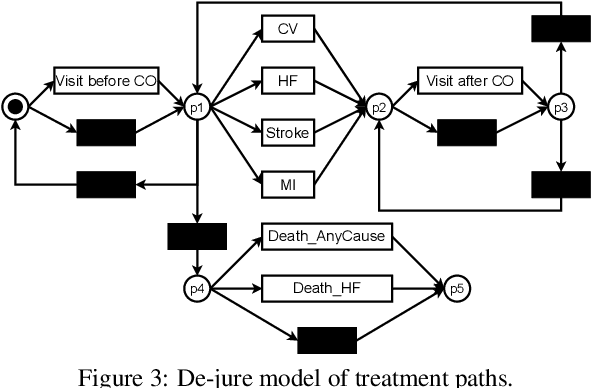
Process mining in healthcare presents a range of challenges when working with different types of data within the healthcare domain. There is high diversity considering the variety of data collected from healthcare processes: operational processes given by claims data, a collection of events during surgery, data related to pre-operative and post-operative care, and high-level data collections based on regular ambulant visits with no apparent events. In this case study, a data set from the last category is analyzed. We apply process-mining techniques on sparse patient heart failure data and investigate whether an information gain towards several research questions is achievable. Here, available data are transformed into an event log format, and process discovery and conformance checking are applied. Additionally, patients are split into different cohorts based on comorbidities, such as diabetes and chronic kidney disease, and multiple statistics are compared between the cohorts. Conclusively, we apply decision mining to determine whether a patient will have a cardiovascular outcome and whether a patient will die.
Attention-guided Feature Distillation for Semantic Segmentation
Mar 08, 2024
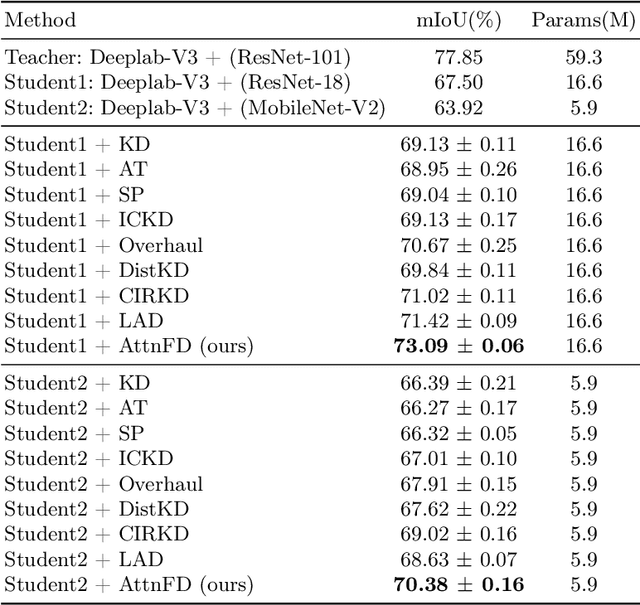
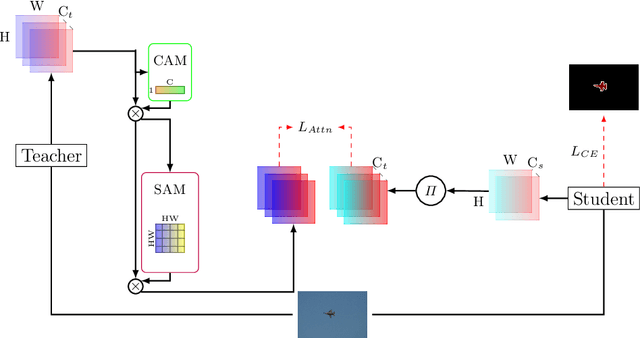
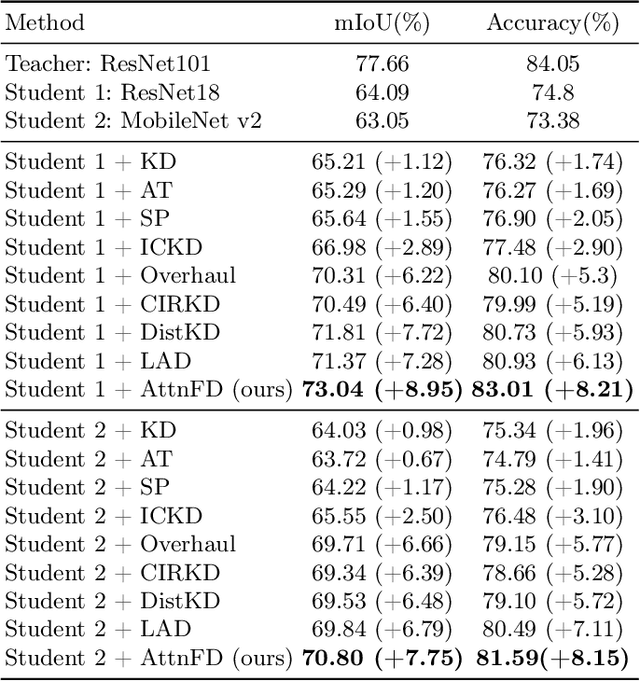
In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, the pro-posed method showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, em-ploys the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. By only using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student,AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of mean Intersection over Union (mIoU) on the PascalVoc 2012 and Cityscapes datasets. The Code is available at https://github.com/AmirMansurian/AttnFD.
MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small Target Detection
Mar 08, 2024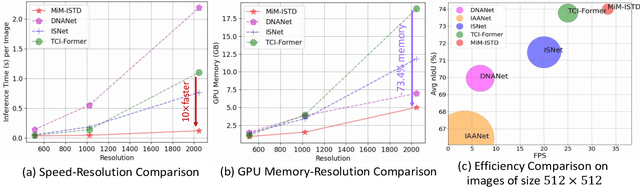
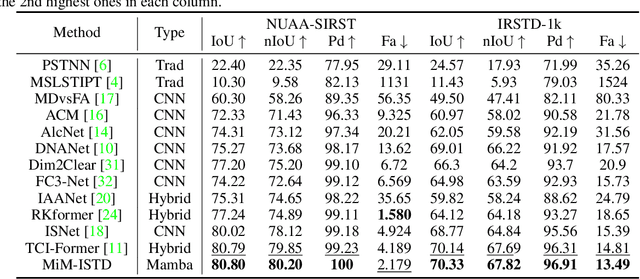
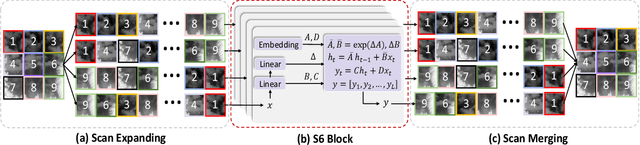
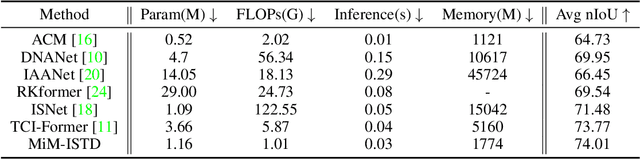
Recently, infrared small target detection (ISTD) has made significant progress, thanks to the development of basic models. Specifically, the structures combining convolutional networks with transformers can successfully extract both local and global features. However, the disadvantage of the transformer is also inherited, i.e., the quadratic computational complexity to the length of the sequence. Inspired by the recent basic model with linear complexity for long-distance modeling, called Mamba, we explore the potential of this state space model for ISTD task in terms of effectiveness and efficiency in the paper. However, directly applying Mamba achieves poor performance since local features, which are critical to detecting small targets, cannot be fully exploited. Instead, we tailor a Mamba-in-Mamba (MiM-ISTD) structure for efficient ISTD. Specifically, we treat the local patches as "visual sentences" and use the Outer Mamba to explore the global information. We then decompose each visual sentence into sub-patches as "visual words" and use the Inner Mamba to further explore the local information among words in the visual sentence with negligible computational costs. By aggregating the word and sentence features, the MiM-ISTD can effectively explore both global and local information. Experiments on NUAA-SIRST and IRSTD-1k show the superior accuracy and efficiency of our method. Specifically, MiM-ISTD is $10 \times$ faster than the SOTA method and reduces GPU memory usage by 73.4$\%$ when testing on $2048 \times 2048$ image, overcoming the computation and memory constraints on high-resolution infrared images. Source code is available at https://github.com/txchen-USTC/MiM-ISTD.
Characterising harmful data sources when constructing multi-fidelity surrogate models
Mar 12, 2024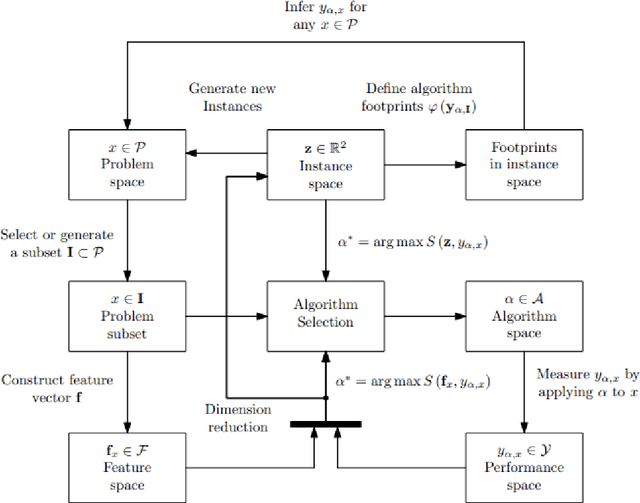
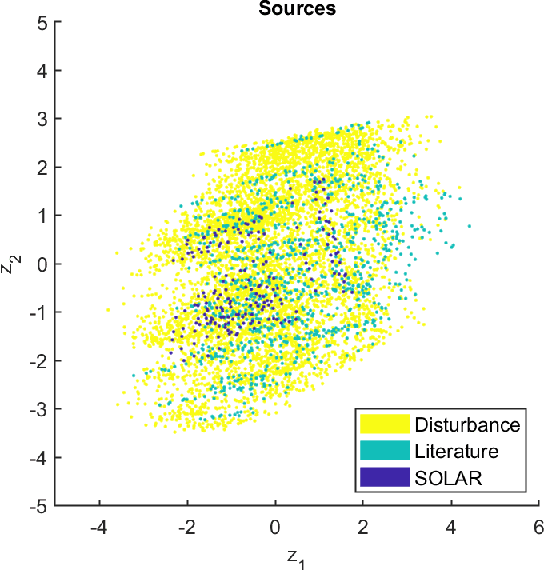

Surrogate modelling techniques have seen growing attention in recent years when applied to both modelling and optimisation of industrial design problems. These techniques are highly relevant when assessing the performance of a particular design carries a high cost, as the overall cost can be mitigated via the construction of a model to be queried in lieu of the available high-cost source. The construction of these models can sometimes employ other sources of information which are both cheaper and less accurate. The existence of these sources however poses the question of which sources should be used when constructing a model. Recent studies have attempted to characterise harmful data sources to guide practitioners in choosing when to ignore a certain source. These studies have done so in a synthetic setting, characterising sources using a large amount of data that is not available in practice. Some of these studies have also been shown to potentially suffer from bias in the benchmarks used in the analysis. In this study, we present a characterisation of harmful low-fidelity sources using only the limited data available to train a surrogate model. We employ recently developed benchmark filtering techniques to conduct a bias-free assessment, providing objectively varied benchmark suites of different sizes for future research. Analysing one of these benchmark suites with the technique known as Instance Space Analysis, we provide an intuitive visualisation of when a low-fidelity source should be used and use this analysis to provide guidelines that can be used in an applied industrial setting.
Quantifying and Mitigating Privacy Risks for Tabular Generative Models
Mar 12, 2024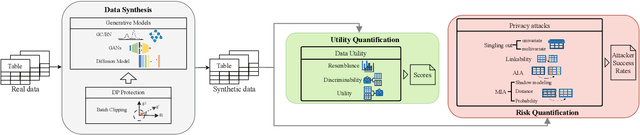

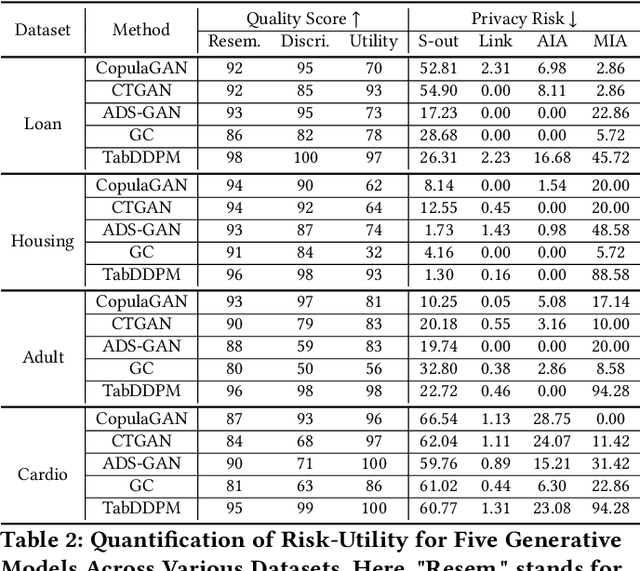
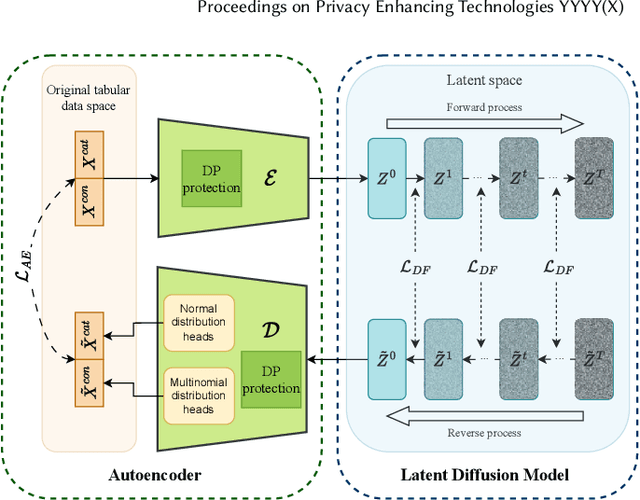
Synthetic data from generative models emerges as the privacy-preserving data-sharing solution. Such a synthetic data set shall resemble the original data without revealing identifiable private information. The backbone technology of tabular synthesizers is rooted in image generative models, ranging from Generative Adversarial Networks (GANs) to recent diffusion models. Recent prior work sheds light on the utility-privacy tradeoff on tabular data, revealing and quantifying privacy risks on synthetic data. We first conduct an exhaustive empirical analysis, highlighting the utility-privacy tradeoff of five state-of-the-art tabular synthesizers, against eight privacy attacks, with a special focus on membership inference attacks. Motivated by the observation of high data quality but also high privacy risk in tabular diffusion, we propose DP-TLDM, Differentially Private Tabular Latent Diffusion Model, which is composed of an autoencoder network to encode the tabular data and a latent diffusion model to synthesize the latent tables. Following the emerging f-DP framework, we apply DP-SGD to train the auto-encoder in combination with batch clipping and use the separation value as the privacy metric to better capture the privacy gain from DP algorithms. Our empirical evaluation demonstrates that DP-TLDM is capable of achieving a meaningful theoretical privacy guarantee while also significantly enhancing the utility of synthetic data. Specifically, compared to other DP-protected tabular generative models, DP-TLDM improves the synthetic quality by an average of 35% in data resemblance, 15% in the utility for downstream tasks, and 50% in data discriminability, all while preserving a comparable level of privacy risk.
MoralBERT: Detecting Moral Values in Social Discourse
Mar 12, 2024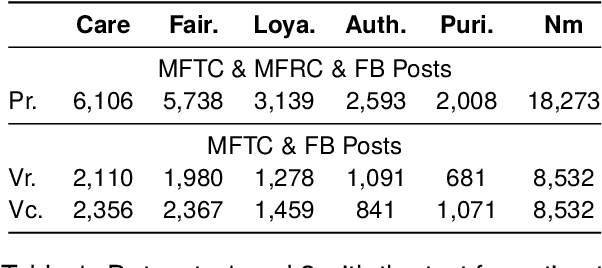
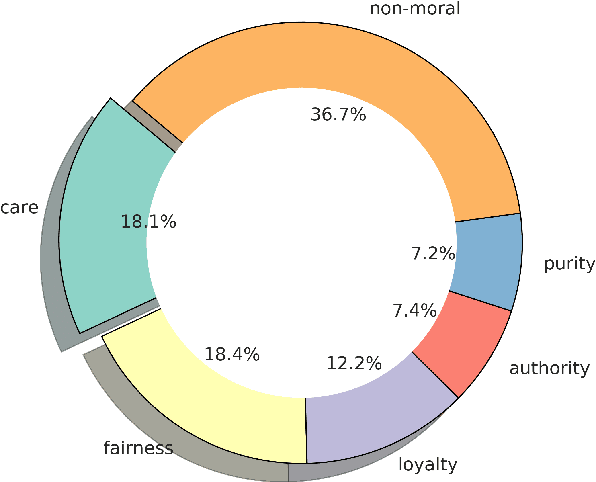
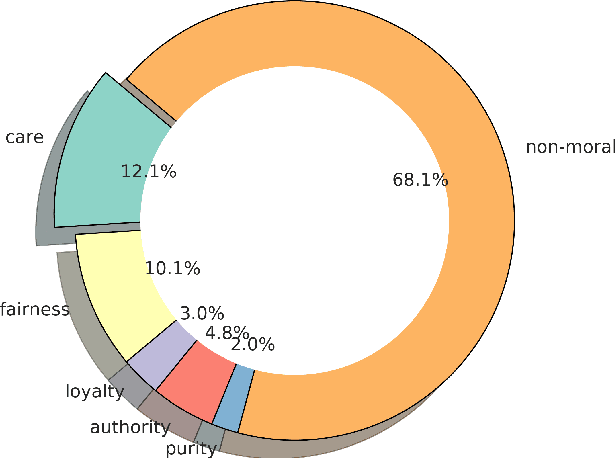
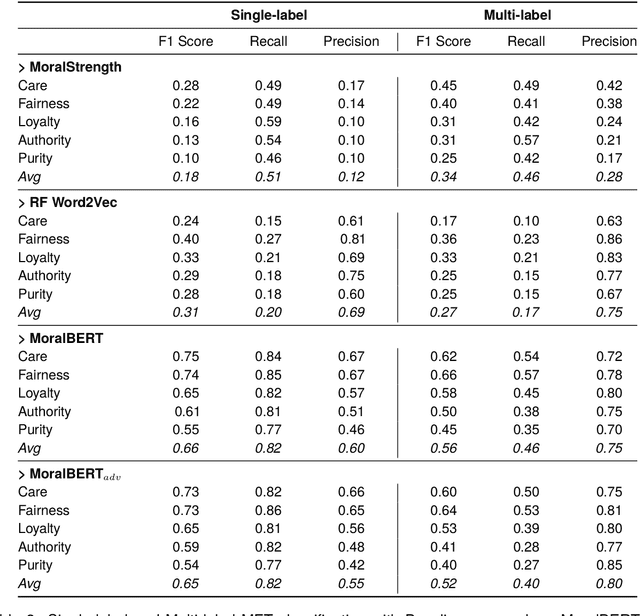
Morality plays a fundamental role in how we perceive information while greatly influencing our decisions and judgements. Controversial topics, including vaccination, abortion, racism, and sexuality, often elicit opinions and attitudes that are not solely based on evidence but rather reflect moral worldviews. Recent advances in natural language processing have demonstrated that moral values can be gauged in human-generated textual content. Here, we design a range of language representation models fine-tuned to capture exactly the moral nuances in text, called MoralBERT. We leverage annotated moral data from three distinct sources: Twitter, Reddit, and Facebook user-generated content covering various socially relevant topics. This approach broadens linguistic diversity and potentially enhances the models' ability to comprehend morality in various contexts. We also explore a domain adaptation technique and compare it to the standard fine-tuned BERT model, using two different frameworks for moral prediction: single-label and multi-label. We compare in-domain approaches with conventional models relying on lexicon-based techniques, as well as a Machine Learning classifier with Word2Vec representation. Our results showed that in-domain prediction models significantly outperformed traditional models. While the single-label setting reaches a higher accuracy than previously achieved for the task when using BERT pretrained models. Experiments in an out-of-domain setting, instead, suggest that further work is needed for existing domain adaptation techniques to generalise between different social media platforms, especially for the multi-label task. The investigations and outcomes from this study pave the way for further exploration, enabling a more profound comprehension of moral narratives about controversial social issues.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024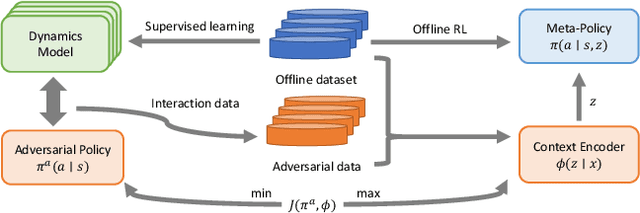
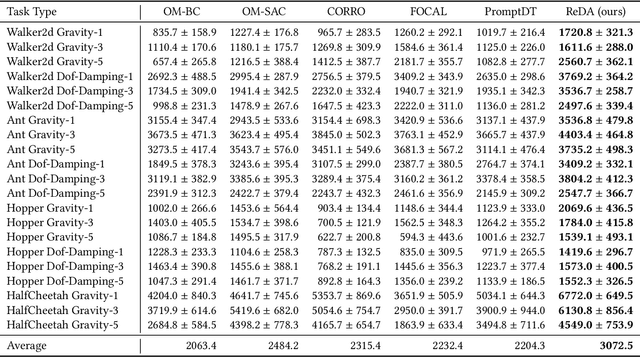
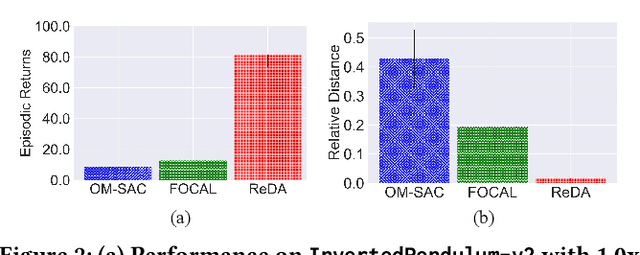
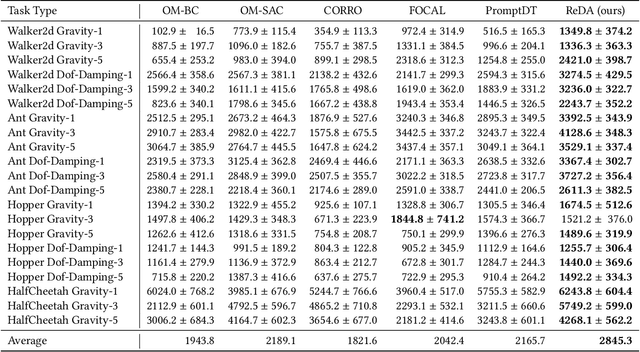
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Low coordinate degree algorithms I: Universality of computational thresholds for hypothesis testing
Mar 12, 2024We study when low coordinate degree functions (LCDF) -- linear combinations of functions depending on small subsets of entries of a vector -- can hypothesis test between high-dimensional probability measures. These functions are a generalization, proposed in Hopkins' 2018 thesis but seldom studied since, of low degree polynomials (LDP), a class widely used in recent literature as a proxy for all efficient algorithms for tasks in statistics and optimization. Instead of the orthogonal polynomial decompositions used in LDP calculations, our analysis of LCDF is based on the Efron-Stein or ANOVA decomposition, making it much more broadly applicable. By way of illustration, we prove channel universality for the success of LCDF in testing for the presence of sufficiently "dilute" random signals through noisy channels: the efficacy of LCDF depends on the channel only through the scalar Fisher information for a class of channels including nearly arbitrary additive i.i.d. noise and nearly arbitrary exponential families. As applications, we extend lower bounds against LDP for spiked matrix and tensor models under additive Gaussian noise to lower bounds against LCDF under general noisy channels. We also give a simple and unified treatment of the effect of censoring models by erasing observations at random and of quantizing models by taking the sign of the observations. These results are the first computational lower bounds against any large class of algorithms for all of these models when the channel is not one of a few special cases, and thereby give the first substantial evidence for the universality of several statistical-to-computational gaps.