 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Explainable Motion Prediction using Heterogeneous Graph Representations
Dec 07, 2022
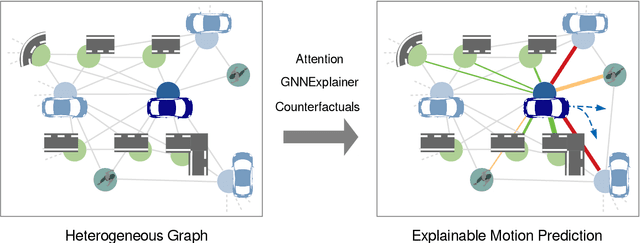
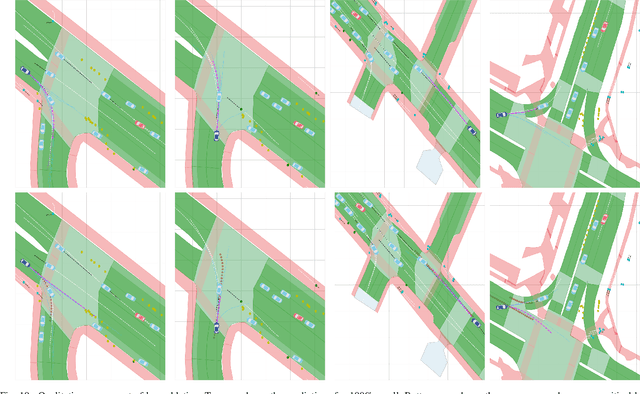
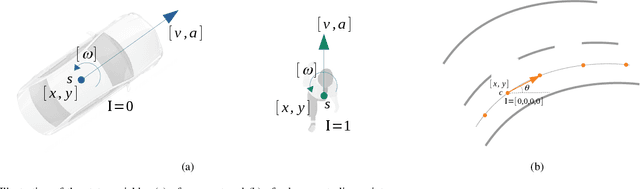
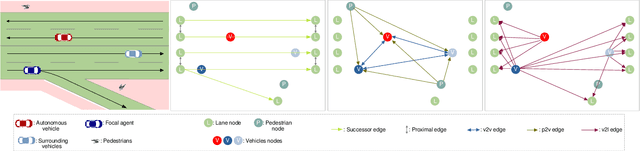
Motion prediction systems aim to capture the future behavior of traffic scenarios enabling autonomous vehicles to perform safe and efficient planning. The evolution of these scenarios is highly uncertain and depends on the interactions of agents with static and dynamic objects in the scene. GNN-based approaches have recently gained attention as they are well suited to naturally model these interactions. However, one of the main challenges that remains unexplored is how to address the complexity and opacity of these models in order to deal with the transparency requirements for autonomous driving systems, which includes aspects such as interpretability and explainability. In this work, we aim to improve the explainability of motion prediction systems by using different approaches. First, we propose a new Explainable Heterogeneous Graph-based Policy (XHGP) model based on an heterograph representation of the traffic scene and lane-graph traversals, which learns interaction behaviors using object-level and type-level attention. This learned attention provides information about the most important agents and interactions in the scene. Second, we explore this same idea with the explanations provided by GNNExplainer. Third, we apply counterfactual reasoning to provide explanations of selected individual scenarios by exploring the sensitivity of the trained model to changes made to the input data, i.e., masking some elements of the scene, modifying trajectories, and adding or removing dynamic agents. The explainability analysis provided in this paper is a first step towards more transparent and reliable motion prediction systems, important from the perspective of the user, developers and regulatory agencies. The code to reproduce this work is publicly available at https://github.com/sancarlim/Explainable-MP/tree/v1.1.
Pre-training Methods in Information Retrieval
Nov 27, 2021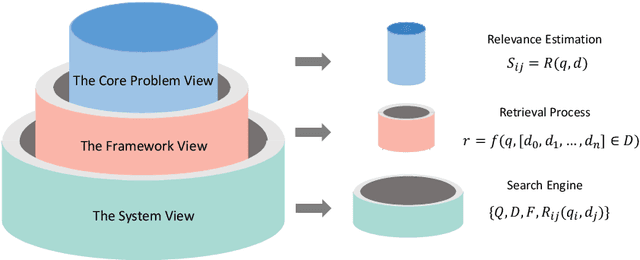
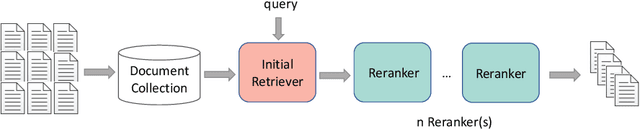
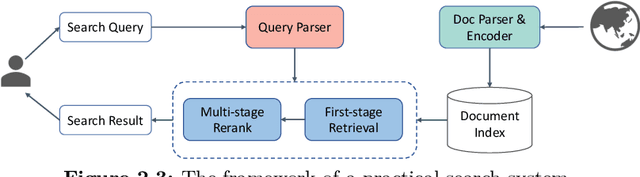

The core of information retrieval (IR) is to identify relevant information from large-scale resources and return it as a ranked list to respond to user's information need. Recently, the resurgence of deep learning has greatly advanced this field and leads to a hot topic named NeuIR (i.e., neural information retrieval), especially the paradigm of pre-training methods (PTMs). Owing to sophisticated pre-training objectives and huge model size, pre-trained models can learn universal language representations from massive textual data, which are beneficial to the ranking task of IR. Since there have been a large number of works dedicating to the application of PTMs in IR, we believe it is the right time to summarize the current status, learn from existing methods, and gain some insights for future development. In this survey, we present an overview of PTMs applied in different components of IR system, including the retrieval component, the re-ranking component, and other components. In addition, we also introduce PTMs specifically designed for IR, and summarize available datasets as well as benchmark leaderboards. Moreover, we discuss some open challenges and envision some promising directions, with the hope of inspiring more works on these topics for future research.
High-Resolution Channel Sounding and Parameter Estimation in Multi-Site Cellular Networks
Nov 17, 2022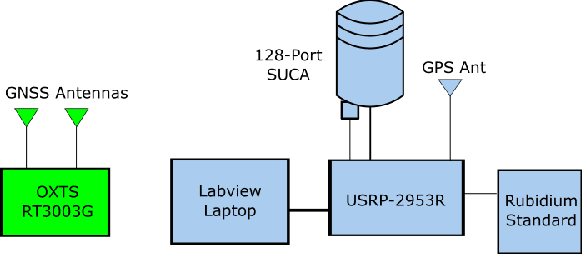

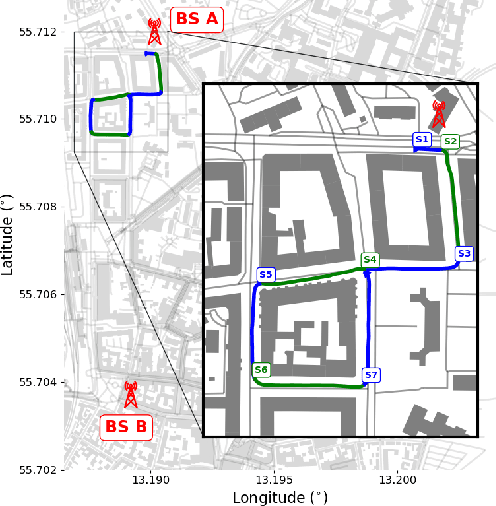
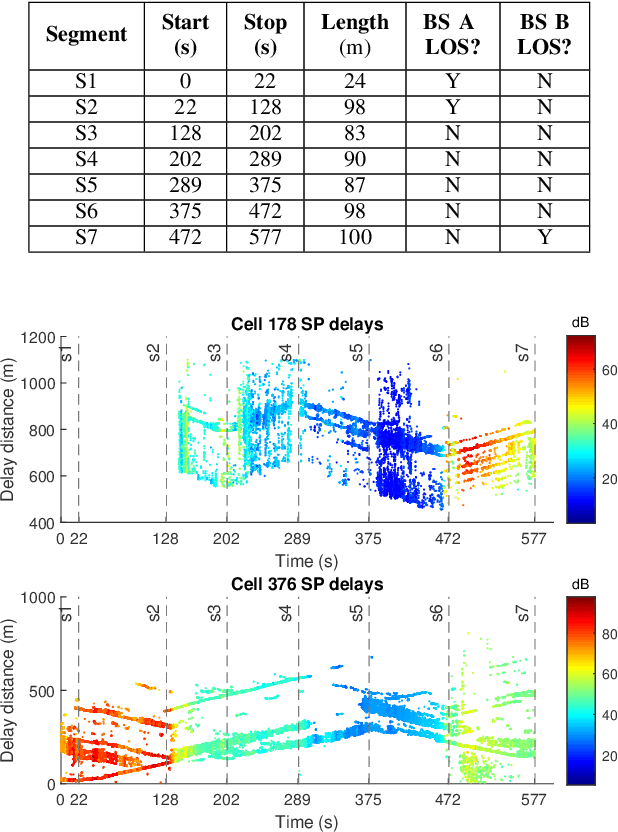
Accurate understanding of electromagnetic propagation properties in real environments is necessary for efficient design and deployment of cellular systems. In this paper, we show a method to estimate high-resolution channel parameters with a massive antenna array in real network deployments. An antenna array mounted on a vehicle is used to receive downlink long-term evolution (LTE) reference signals from neighboring base stations (BS) with mutual interference. Delay and angular information of multipath components is estimated with a novel inter-cell interference cancellation algorithm and an extension of the RIMAX algorithm. The estimated high-resolution channel parameters are consistent with the movement pattern of the vehicle and the geometry of the environment and allow for refined channel modeling and precise cellular positioning.
Heterogenous Ensemble of Models for Molecular Property Prediction
Nov 20, 2022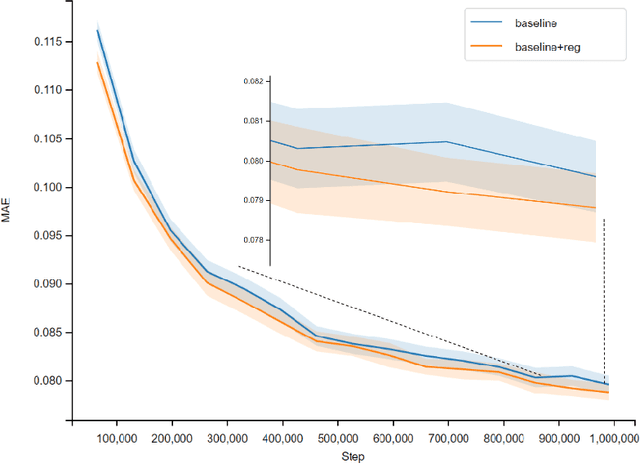
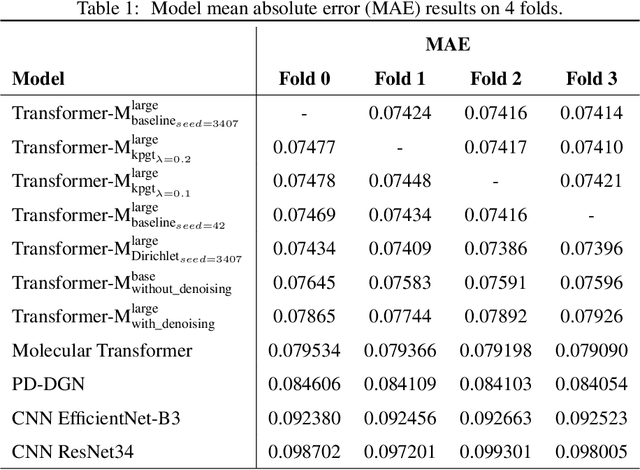
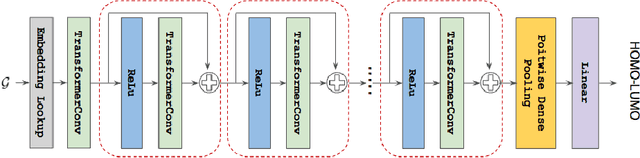
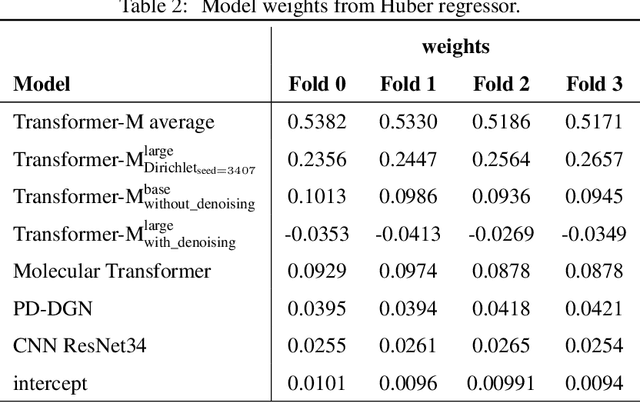
Previous works have demonstrated the importance of considering different modalities on molecules, each of which provide a varied granularity of information for downstream property prediction tasks. Our method combines variants of the recent TransformerM architecture with Transformer, GNN, and ResNet backbone architectures. Models are trained on the 2D data, 3D data, and image modalities of molecular graphs. We ensemble these models with a HuberRegressor. The models are trained on 4 different train/validation splits of the original train + valid datasets. This yields a winning solution to the 2\textsuperscript{nd} edition of the OGB Large-Scale Challenge (2022) on the PCQM4Mv2 molecular property prediction dataset. Our proposed method achieves a test-challenge MAE of $0.0723$ and a validation MAE of $0.07145$. Total inference time for our solution is less than 2 hours. We open-source our code at https://github.com/jfpuget/NVIDIA-PCQM4Mv2.
Understanding Acoustic Patterns of Human Teachers Demonstrating Manipulation Tasks to Robots
Nov 01, 2022

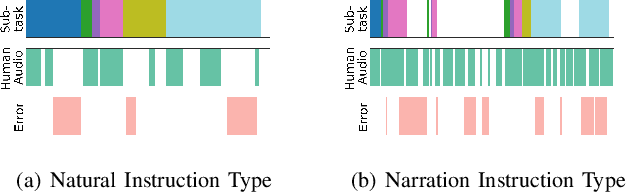
Humans use audio signals in the form of spoken language or verbal reactions effectively when teaching new skills or tasks to other humans. While demonstrations allow humans to teach robots in a natural way, learning from trajectories alone does not leverage other available modalities including audio from human teachers. To effectively utilize audio cues accompanying human demonstrations, first it is important to understand what kind of information is present and conveyed by such cues. This work characterizes audio from human teachers demonstrating multi-step manipulation tasks to a situated Sawyer robot using three feature types: (1) duration of speech used, (2) expressiveness in speech or prosody, and (3) semantic content of speech. We analyze these features along four dimensions and find that teachers convey similar semantic concepts via spoken words for different conditions of (1) demonstration types, (2) audio usage instructions, (3) subtasks, and (4) errors during demonstrations. However, differentiating properties of speech in terms of duration and expressiveness are present along the four dimensions, highlighting that human audio carries rich information, potentially beneficial for technological advancement of robot learning from demonstration methods.
MHITNet: a minimize network with a hierarchical context-attentional filter for segmenting medical ct images
Nov 01, 2022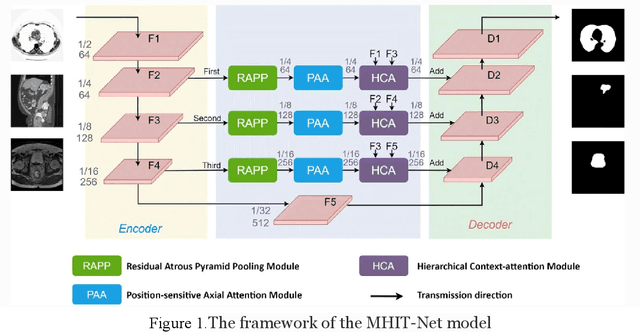
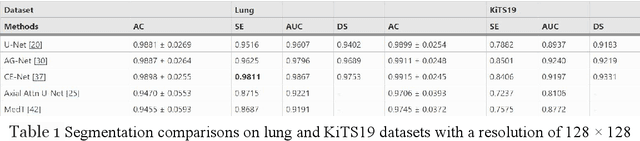
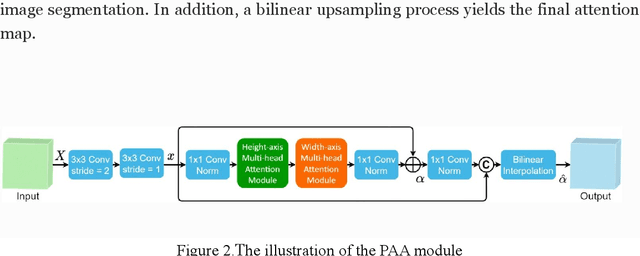
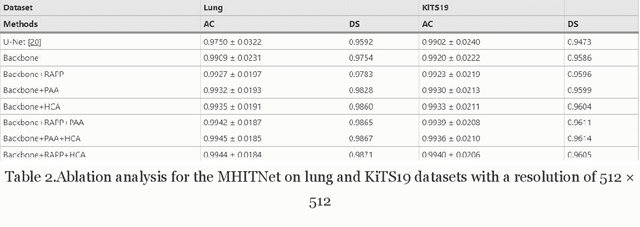
In the field of medical CT image processing, convolutional neural networks (CNNs) have been the dominant technique.Encoder-decoder CNNs utilise locality for efficiency, but they cannot simulate distant pixel interactions properly.Recent research indicates that self-attention or transformer layers can be stacked to efficiently learn long-range dependencies.By constructing and processing picture patches as embeddings, transformers have been applied to computer vision applications. However, transformer-based architectures lack global semantic information interaction and require a large-scale training dataset, making it challenging to train with small data samples. In order to solve these challenges, we present a hierarchical contextattention transformer network (MHITNet) that combines the multi-scale, transformer, and hierarchical context extraction modules in skip-connections. The multi-scale module captures deeper CT semantic information, enabling transformers to encode feature maps of tokenized picture patches from various CNN stages as input attention sequences more effectively. The hierarchical context attention module augments global data and reweights pixels to capture semantic context.Extensive trials on three datasets show that the proposed MHITNet beats current best practises
Are word boundaries useful for unsupervised language learning?
Oct 06, 2022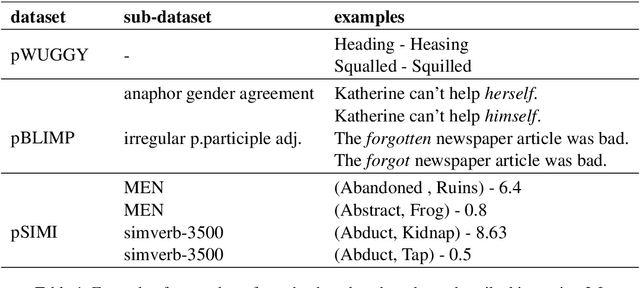
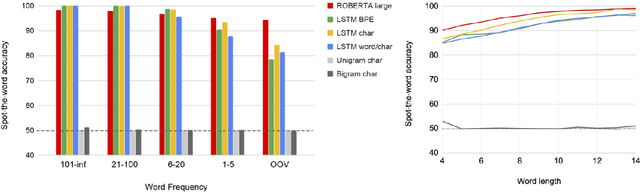
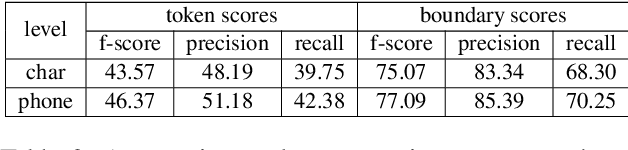
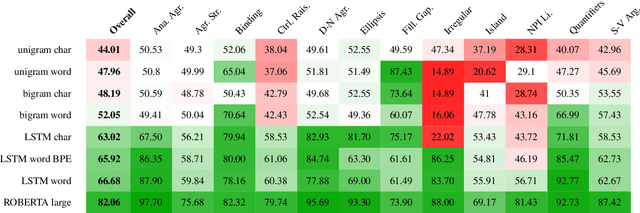
Word or word-fragment based Language Models (LM) are typically preferred over character-based ones in many downstream applications. This may not be surprising as words seem more linguistically relevant units than characters. Words provide at least two kinds of relevant information: boundary information and meaningful units. However, word boundary information may be absent or unreliable in the case of speech input (word boundaries are not marked explicitly in the speech stream). Here, we systematically compare LSTMs as a function of the input unit (character, phoneme, word, word part), with or without gold boundary information. We probe linguistic knowledge in the networks at the lexical, syntactic and semantic levels using three speech-adapted black box NLP psycholinguistically-inpired benchmarks (pWUGGY, pBLIMP, pSIMI). We find that the absence of boundaries costs between 2\% and 28\% in relative performance depending on the task. We show that gold boundaries can be replaced by automatically found ones obtained with an unsupervised segmentation algorithm, and that even modest segmentation performance gives a gain in performance on two of the three tasks compared to basic character/phone based models without boundary information.
A Strong Baseline for Generalized Few-Shot Semantic Segmentation
Nov 25, 2022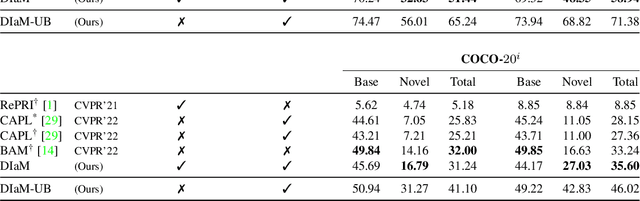
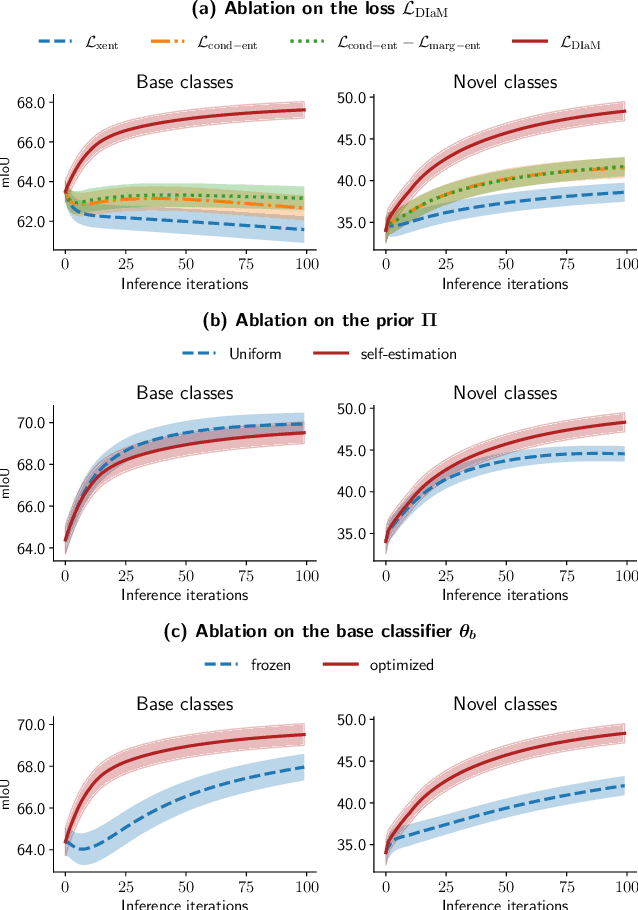
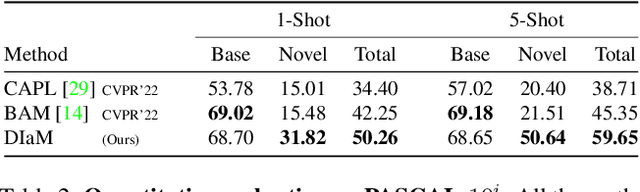
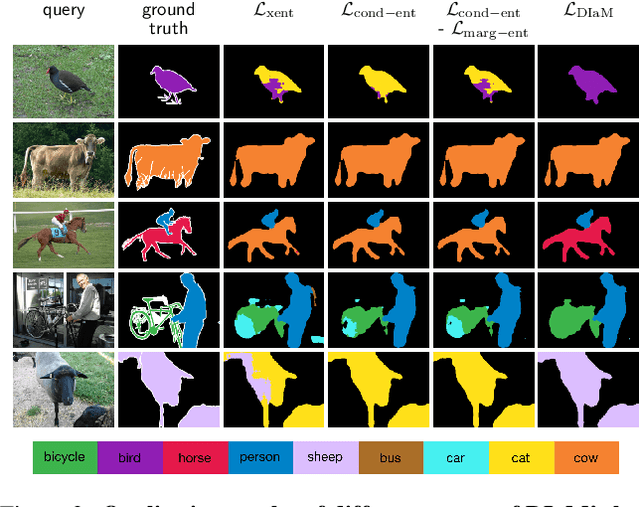
This paper introduces a generalized few-shot segmentation framework with a straightforward training process and an easy-to-optimize inference phase. In particular, we propose a simple yet effective model based on the well-known InfoMax principle, where the Mutual Information (MI) between the learned feature representations and their corresponding predictions is maximized. In addition, the terms derived from our MI-based formulation are coupled with a knowledge distillation term to retain the knowledge on base classes. With a simple training process, our inference model can be applied on top of any segmentation network trained on base classes. The proposed inference yields substantial improvements on the popular few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$. Particularly, for novel classes, the improvement gains range from 5% to 20% (PASCAL-$5^i$) and from 2.5% to 10.5% (COCO-$20^i$) in the 1-shot and 5-shot scenarios, respectively. Furthermore, we propose a more challenging setting, where performance gaps are further exacerbated. Our code is publicly available at https://github.com/sinahmr/DIaM.
Evaluation of the impact of the indiscernibility relation on the fuzzy-rough nearest neighbours algorithm
Nov 25, 2022

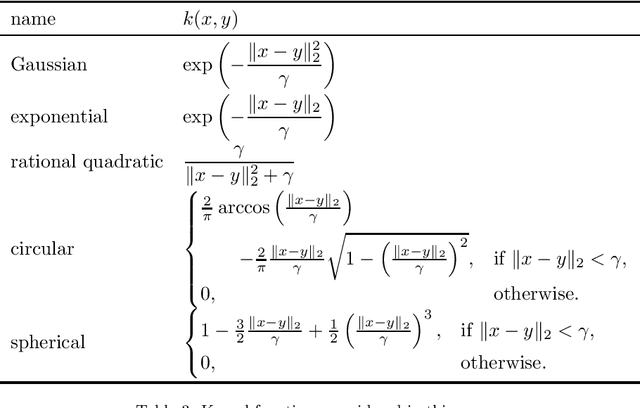

Fuzzy rough sets are well-suited for working with vague, imprecise or uncertain information and have been succesfully applied in real-world classification problems. One of the prominent representatives of this theory is fuzzy-rough nearest neighbours (FRNN), a classification algorithm based on the classical k-nearest neighbours algorithm. The crux of FRNN is the indiscernibility relation, which measures how similar two elements in the data set of interest are. In this paper, we investigate the impact of this indiscernibility relation on the performance of FRNN classification. In addition to relations based on distance functions and kernels, we also explore the effect of distance metric learning on FRNN for the first time. Furthermore, we also introduce an asymmetric, class-specific relation based on the Mahalanobis distance which uses the correlation within each class, and which shows a significant improvement over the regular Mahalanobis distance, but is still beaten by the Manhattan distance. Overall, the Neighbourhood Components Analysis algorithm is found to be the best performer, trading speed for accuracy.
Competency-Aware Neural Machine Translation: Can Machine Translation Know its Own Translation Quality?
Nov 25, 2022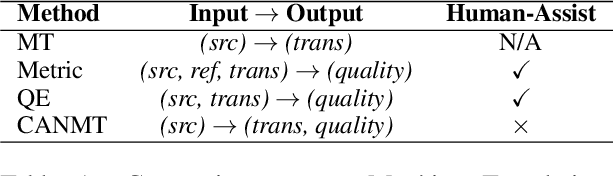
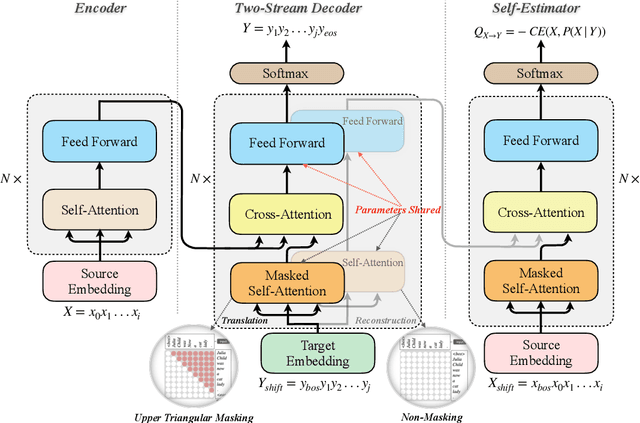
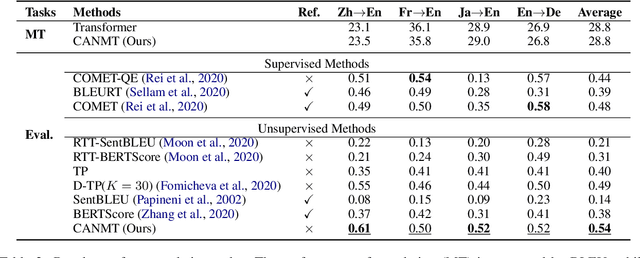
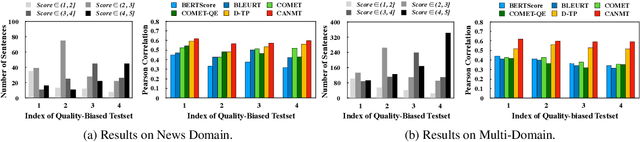
Neural machine translation (NMT) is often criticized for failures that happen without awareness. The lack of competency awareness makes NMT untrustworthy. This is in sharp contrast to human translators who give feedback or conduct further investigations whenever they are in doubt about predictions. To fill this gap, we propose a novel competency-aware NMT by extending conventional NMT with a self-estimator, offering abilities to translate a source sentence and estimate its competency. The self-estimator encodes the information of the decoding procedure and then examines whether it can reconstruct the original semantics of the source sentence. Experimental results on four translation tasks demonstrate that the proposed method not only carries out translation tasks intact but also delivers outstanding performance on quality estimation. Without depending on any reference or annotated data typically required by state-of-the-art metric and quality estimation methods, our model yields an even higher correlation with human quality judgments than a variety of aforementioned methods, such as BLEURT, COMET, and BERTScore. Quantitative and qualitative analyses show better robustness of competency awareness in our model.