 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Datavoidant: An AI System for Addressing Political Data Voids on Social Media
Oct 24, 2022
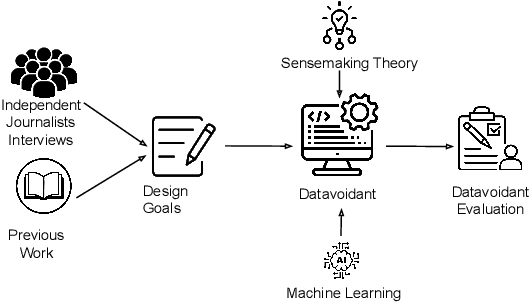

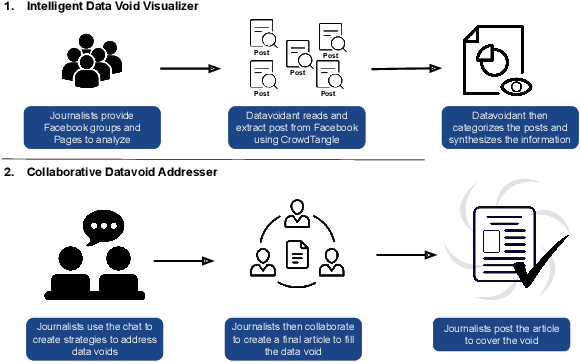

The limited information (data voids) on political topics relevant to underrepresented communities has facilitated the spread of disinformation. Independent journalists who combat disinformation in underrepresented communities have reported feeling overwhelmed because they lack the tools necessary to make sense of the information they monitor and address the data voids. In this paper, we present a system to identify and address political data voids within underrepresented communities. Armed with an interview study, indicating that the independent news media has the potential to address them, we designed an intelligent collaborative system, called Datavoidant. Datavoidant uses state-of-the-art machine learning models and introduces a novel design space to provide independent journalists with a collective understanding of data voids to facilitate generating content to cover the voids. We performed a user interface evaluation with independent news media journalists (N=22). These journalists reported that Datavoidant's features allowed them to more rapidly while easily having a sense of what was taking place in the information ecosystem to address the data voids. They also reported feeling more confident about the content they created and the unique perspectives they had proposed to cover the voids. We conclude by discussing how Datavoidant enables a new design space wherein individuals can collaborate to make sense of their information ecosystem and actively devise strategies to prevent disinformation.
Regularized Optimal Transport Layers for Generalized Global Pooling Operations
Dec 13, 2022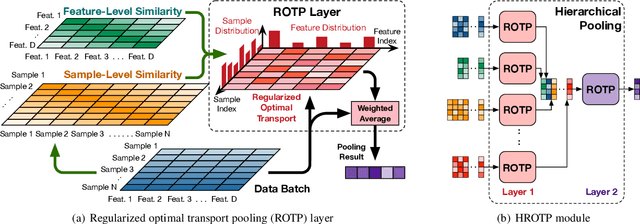
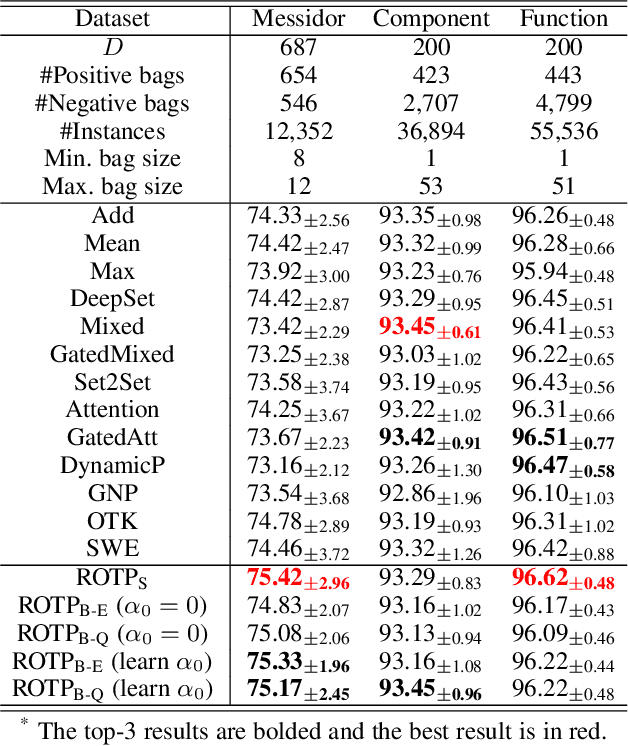
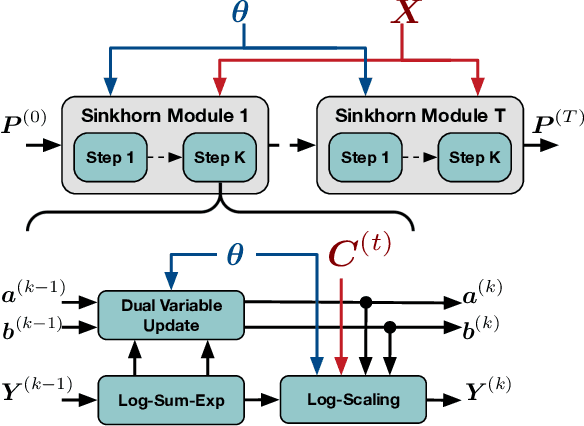
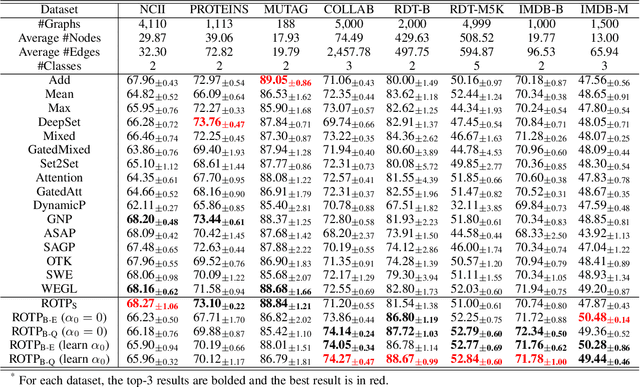
Global pooling is one of the most significant operations in many machine learning models and tasks, which works for information fusion and structured data (like sets and graphs) representation. However, without solid mathematical fundamentals, its practical implementations often depend on empirical mechanisms and thus lead to sub-optimal, even unsatisfactory performance. In this work, we develop a novel and generalized global pooling framework through the lens of optimal transport. The proposed framework is interpretable from the perspective of expectation-maximization. Essentially, it aims at learning an optimal transport across sample indices and feature dimensions, making the corresponding pooling operation maximize the conditional expectation of input data. We demonstrate that most existing pooling methods are equivalent to solving a regularized optimal transport (ROT) problem with different specializations, and more sophisticated pooling operations can be implemented by hierarchically solving multiple ROT problems. Making the parameters of the ROT problem learnable, we develop a family of regularized optimal transport pooling (ROTP) layers. We implement the ROTP layers as a new kind of deep implicit layer. Their model architectures correspond to different optimization algorithms. We test our ROTP layers in several representative set-level machine learning scenarios, including multi-instance learning (MIL), graph classification, graph set representation, and image classification. Experimental results show that applying our ROTP layers can reduce the difficulty of the design and selection of global pooling -- our ROTP layers may either imitate some existing global pooling methods or lead to some new pooling layers fitting data better. The code is available at \url{https://github.com/SDS-Lab/ROT-Pooling}.
Semantic Brain Decoding: from fMRI to conceptually similar image reconstruction of visual stimuli
Dec 13, 2022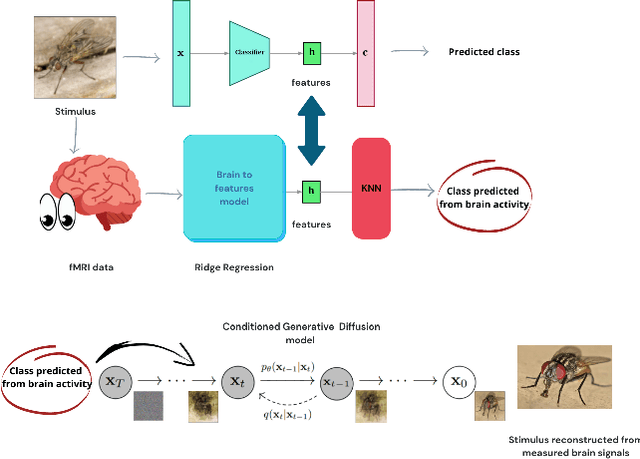
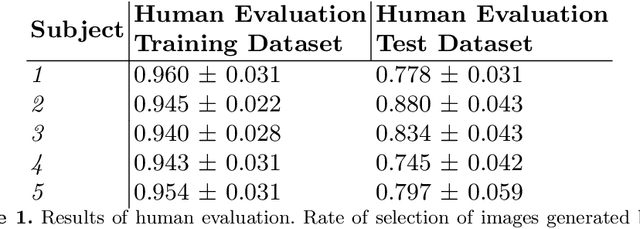

Brain decoding is a field of computational neuroscience that uses measurable brain activity to infer mental states or internal representations of perceptual inputs. Therefore, we propose a novel approach to brain decoding that also relies on semantic and contextual similarity. We employ an fMRI dataset of natural image vision and create a deep learning decoding pipeline inspired by the existence of both bottom-up and top-down processes in human vision. We train a linear brain-to-feature model to map fMRI activity features to visual stimuli features, assuming that the brain projects visual information onto a space that is homeomorphic to the latent space represented by the last convolutional layer of a pretrained convolutional neural network, which typically collects a variety of semantic features that summarize and highlight similarities and differences between concepts. These features are then categorized in the latent space using a nearest-neighbor strategy, and the results are used to condition a generative latent diffusion model to create novel images. From fMRI data only, we produce reconstructions of visual stimuli that match the original content very well on a semantic level, surpassing the state of the art in previous literature. We evaluate our work and obtain good results using a quantitative semantic metric (the Wu-Palmer similarity metric over the WordNet lexicon, which had an average value of 0.57) and perform a human evaluation experiment that resulted in correct evaluation, according to the multiplicity of human criteria in evaluating image similarity, in over 80% of the test set.
Scanpath Prediction on Information Visualisations
Dec 04, 2021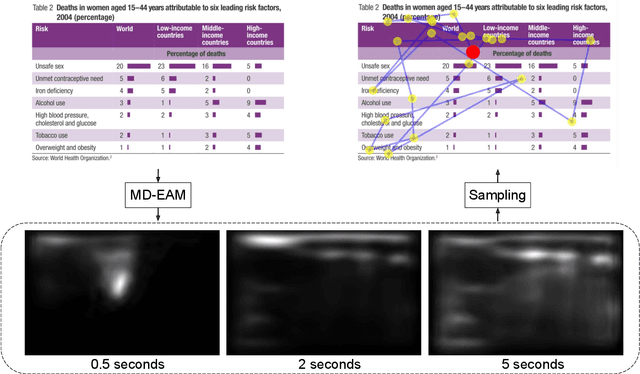
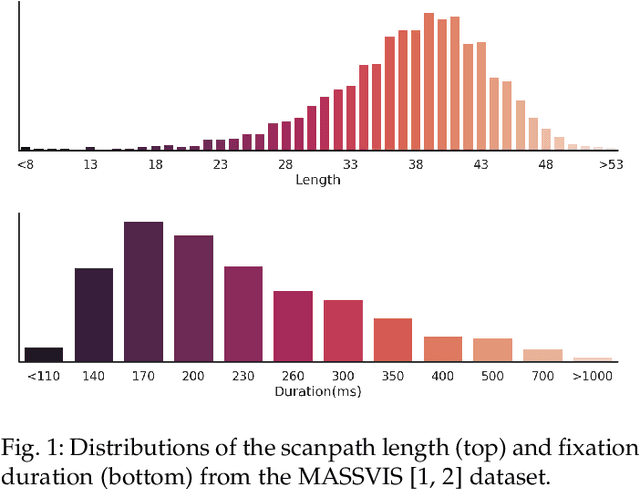
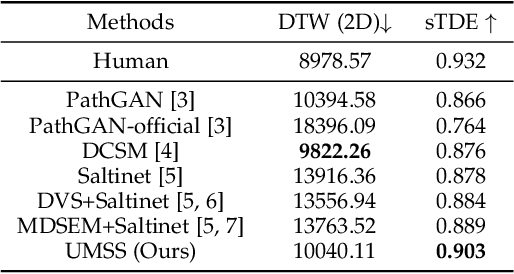
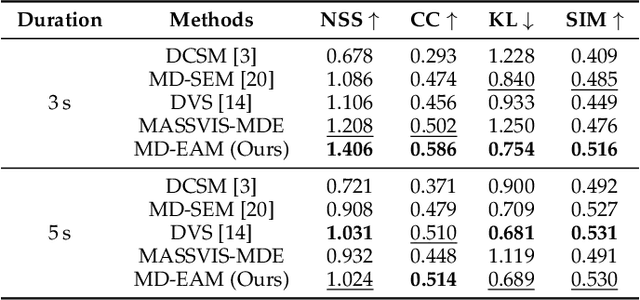
We propose Unified Model of Saliency and Scanpaths (UMSS) -- a model that learns to predict visual saliency and scanpaths (i.e. sequences of eye fixations) on information visualisations. Although scanpaths provide rich information about the importance of different visualisation elements during the visual exploration process, prior work has been limited to predicting aggregated attention statistics, such as visual saliency. We present in-depth analyses of gaze behaviour for different information visualisation elements (e.g. Title, Label, Data) on the popular MASSVIS dataset. We show that while, overall, gaze patterns are surprisingly consistent across visualisations and viewers, there are also structural differences in gaze dynamics for different elements. Informed by our analyses, UMSS first predicts multi-duration element-level saliency maps, then probabilistically samples scanpaths from them. Extensive experiments on MASSVIS show that our method consistently outperforms state-of-the-art methods with respect to several, widely used scanpath and saliency evaluation metrics. Our method achieves a relative improvement in sequence score of 11.5% for scanpath prediction, and a relative improvement in Pearson correlation coefficient of up to 23.6% for saliency prediction. These results are auspicious and point towards richer user models and simulations of visual attention on visualisations without the need for any eye tracking equipment.
An ensemble of VisNet, Transformer-M, and pretraining models for molecular property prediction in OGB Large-Scale Challenge @ NeurIPS 2022
Nov 23, 2022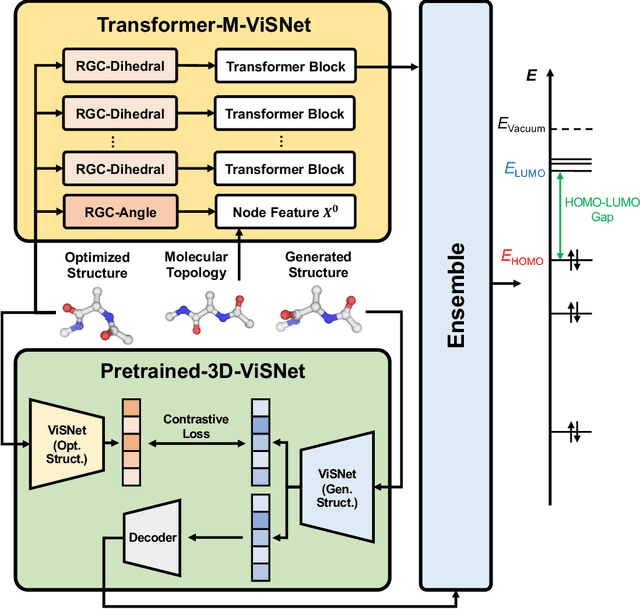
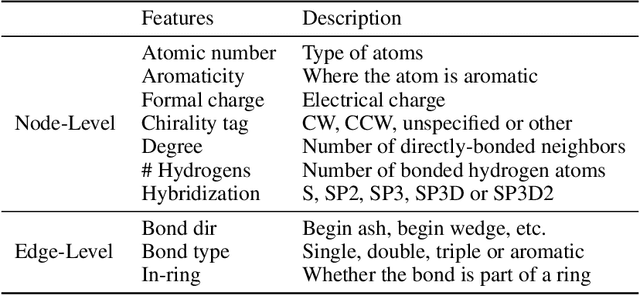

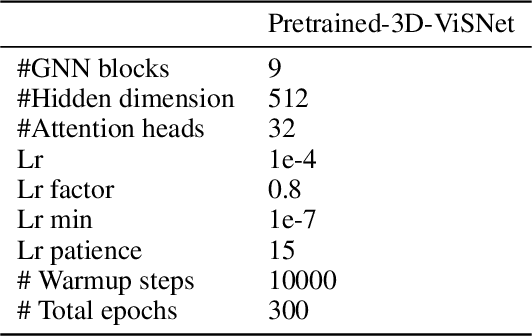
In the technical report, we provide our solution for OGB-LSC 2022 Graph Regression Task. The target of this task is to predict the quantum chemical property, HOMO-LUMO gap for a given molecule on PCQM4Mv2 dataset. In the competition, we designed two kinds of models: Transformer-M-ViSNet which is an geometry-enhanced graph neural network for fully connected molecular graphs and Pretrained-3D-ViSNet which is a pretrained ViSNet by distilling geomeotric information from optimized structures. With an ensemble of 22 models, ViSNet Team achieved the MAE of 0.0723 eV on the test-challenge set, dramatically reducing the error by 39.75% compared with the best method in the last year competition.
Research on Data Fusion Algorithm Based on Deep Learning in Target Tracking
Nov 23, 2022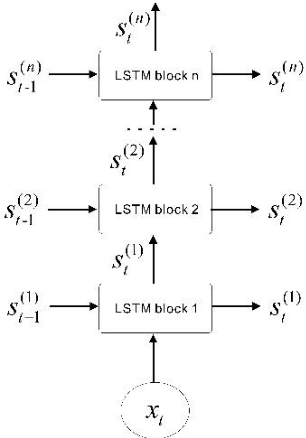
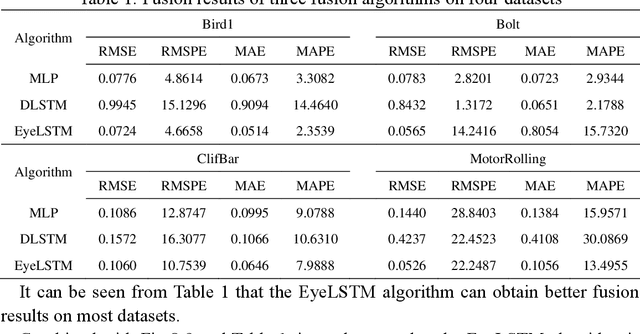
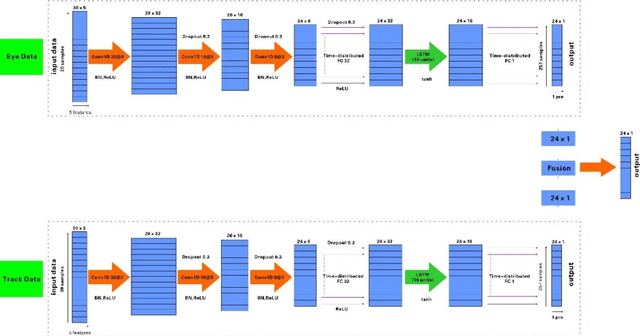

Aiming at the limitation that deep long and short-term memory network(DLSTM) algorithm cannot perform parallel computing and cannot obtain global information, in this paper, feature extraction and feature processing are firstly carried out according to the characteristics of eye movement data and tracking data, then by introducing a convolutional neural network (CNN) into a deep long and short-term memory network, developed a new network structure and designed a fusion strategy, an eye tracking data fusion algorithm based on long and short-term memory network is proposed. The experimental results show that compared with the two fusion algorithms based on deep learning, the algorithm proposed in this paper performs well in terms of fusion quality.
LDL: A Defense for Label-Based Membership Inference Attacks
Dec 16, 2022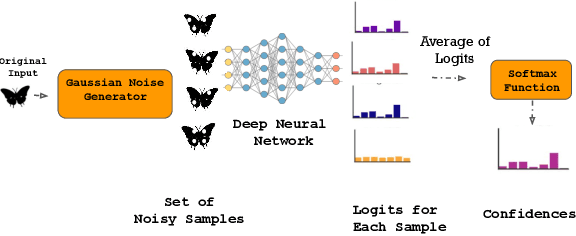
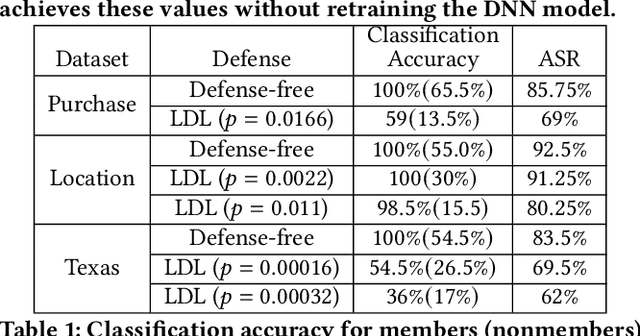
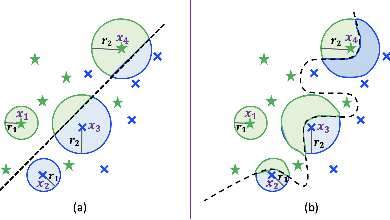
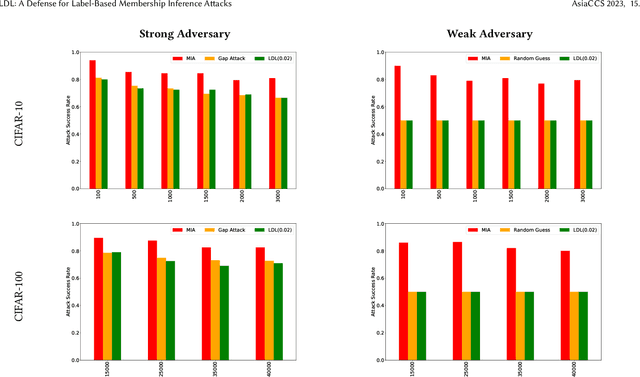
The data used to train deep neural network (DNN) models in applications such as healthcare and finance typically contain sensitive information. A DNN model may suffer from overfitting. Overfitted models have been shown to be susceptible to query-based attacks such as membership inference attacks (MIAs). MIAs aim to determine whether a sample belongs to the dataset used to train a classifier (members) or not (nonmembers). Recently, a new class of label based MIAs (LAB MIAs) was proposed, where an adversary was only required to have knowledge of predicted labels of samples. Developing a defense against an adversary carrying out a LAB MIA on DNN models that cannot be retrained remains an open problem. We present LDL, a light weight defense against LAB MIAs. LDL works by constructing a high-dimensional sphere around queried samples such that the model decision is unchanged for (noisy) variants of the sample within the sphere. This sphere of label-invariance creates ambiguity and prevents a querying adversary from correctly determining whether a sample is a member or a nonmember. We analytically characterize the success rate of an adversary carrying out a LAB MIA when LDL is deployed, and show that the formulation is consistent with experimental observations. We evaluate LDL on seven datasets -- CIFAR-10, CIFAR-100, GTSRB, Face, Purchase, Location, and Texas -- with varying sizes of training data. All of these datasets have been used by SOTA LAB MIAs. Our experiments demonstrate that LDL reduces the success rate of an adversary carrying out a LAB MIA in each case. We empirically compare LDL with defenses against LAB MIAs that require retraining of DNN models, and show that LDL performs favorably despite not needing to retrain the DNNs.
On Human Visual Contrast Sensitivity and Machine Vision Robustness: A Comparative Study
Dec 16, 2022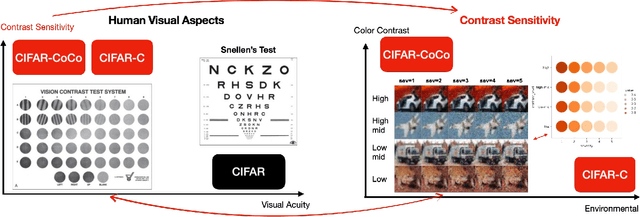
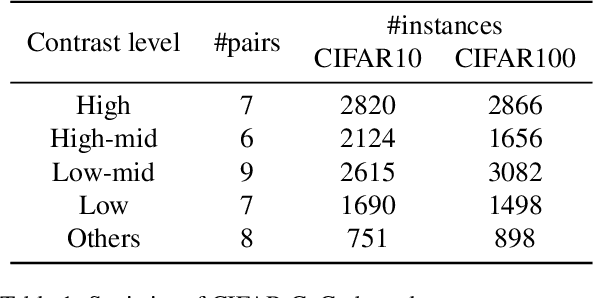

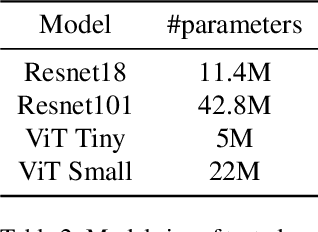
It is well established in neuroscience that color vision plays an essential part in the human visual perception system. Meanwhile, many novel designs for computer vision inspired by human vision have achieved success in a wide range of tasks and applications. Nonetheless, how color differences affect machine vision has not been well explored. Our work tries to bridge this gap between the human color vision aspect of visual recognition and that of the machine. To achieve this, we curate two datasets: CIFAR10-F and CIFAR100-F, which are based on the foreground colors of the popular CIFAR datasets. Together with CIFAR10-B and CIFAR100-B, the existing counterpart datasets with information on the background colors of CIFAR test sets, we assign each image based on its color contrast level per its foreground and background color labels and use this as a proxy to study how color contrast affects machine vision. We first conduct a proof-of-concept study, showing the effect of color difference and validate our datasets. Furthermore, on a broader level, an important characteristic of human vision is its robustness against ambient changes; therefore, drawing inspirations from ophthalmology and the robustness literature, we analogize contrast sensitivity from the human visual aspect to machine vision and complement the current robustness study using corrupted images with our CIFAR-CoCo datasets. In summary, motivated by neuroscience and equipped with the datasets we curate, we devise a new framework in two dimensions to perform extensive analyses on the effect of color contrast and corrupted images: (1) model architecture, (2) model size, to measure the perception ability of machine vision beyond total accuracy. We also explore how task complexity and data augmentation play a role in this setup. Our results call attention to new evaluation approaches for human-like machine perception.
Hippocampus-Inspired Cognitive Architecture (HICA) for Operant Conditioning
Dec 16, 2022
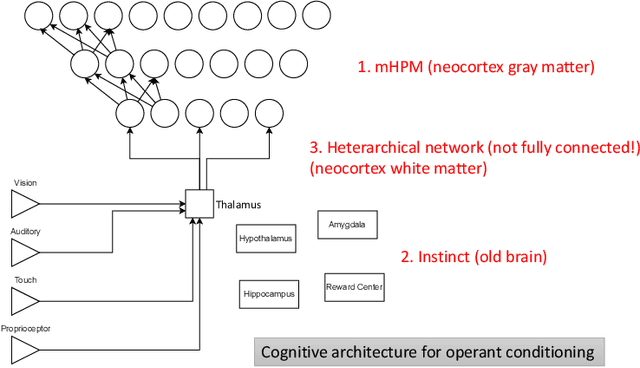
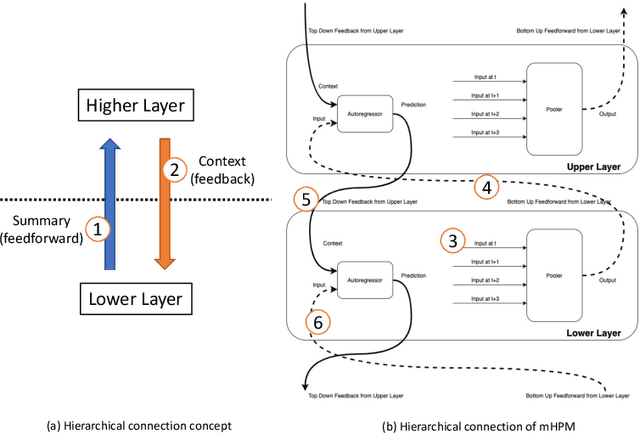
The neural implementation of operant conditioning with few trials is unclear. We propose a Hippocampus-Inspired Cognitive Architecture (HICA) as a neural mechanism for operant conditioning. HICA explains a learning mechanism in which agents can learn a new behavior policy in a few trials, as mammals do in operant conditioning experiments. HICA is composed of two different types of modules. One is a universal learning module type that represents a cortical column in the neocortex gray matter. The working principle is modeled as Modulated Heterarchical Prediction Memory (mHPM). In mHPM, each module learns to predict a succeeding input vector given the sequence of the input vectors from lower layers and the context vectors from higher layers. The prediction is fed into the lower layers as a context signal (top-down feedback signaling), and into the higher layers as an input signal (bottom-up feedforward signaling). Rewards modulate the learning rate in those modules to memorize meaningful sequences effectively. In mHPM, each module updates in a local and distributed way compared to conventional end-to-end learning with backpropagation of the single objective loss. This local structure enables the heterarchical network of modules. The second type is an innate, special-purpose module representing various organs of the brain's subcortical system. Modules modeling organs such as the amygdala, hippocampus, and reward center are pre-programmed to enable instinctive behaviors. The hippocampus plays the role of the simulator. It is an autoregressive prediction model of the top-most level signal with a loop structure of memory, while cortical columns are lower layers that provide detailed information to the simulation. The simulation becomes the basis for learning with few trials and the deliberate planning required for operant conditioning.
Multi-robot Social-aware Cooperative Planning in Pedestrian Environments Using Multi-agent Reinforcement Learning
Nov 29, 2022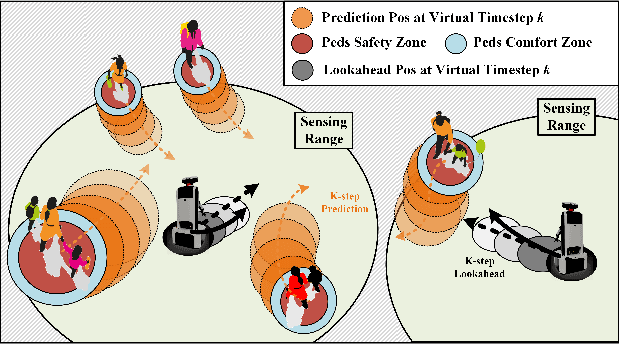
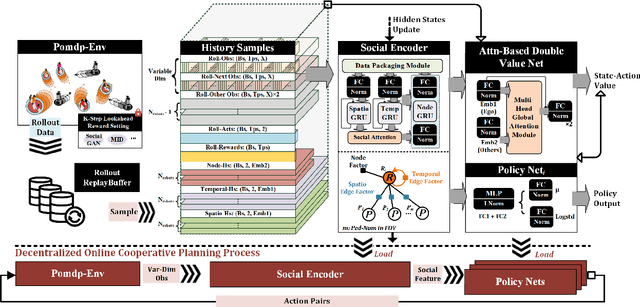
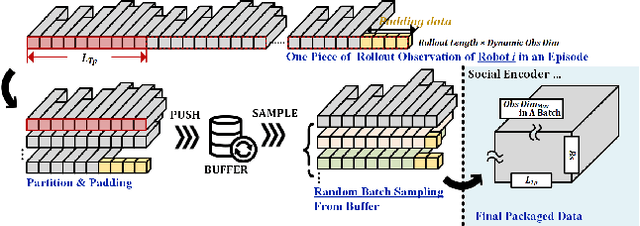
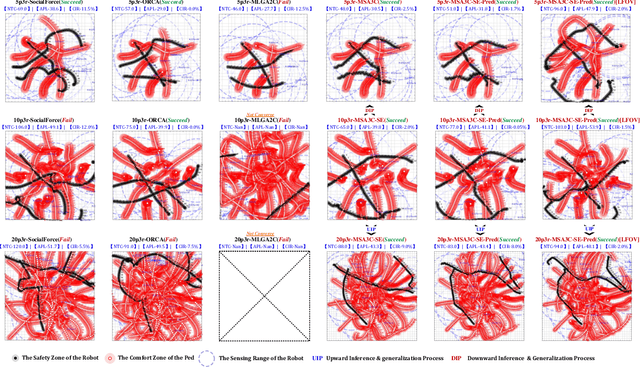
Safe and efficient co-planning of multiple robots in pedestrian participation environments is promising for applications. In this work, a novel multi-robot social-aware efficient cooperative planner that on the basis of off-policy multi-agent reinforcement learning (MARL) under partial dimension-varying observation and imperfect perception conditions is proposed. We adopt temporal-spatial graph (TSG)-based social encoder to better extract the importance of social relation between each robot and the pedestrians in its field of view (FOV). Also, we introduce K-step lookahead reward setting in multi-robot RL framework to avoid aggressive, intrusive, short-sighted, and unnatural motion decisions generated by robots. Moreover, we improve the traditional centralized critic network with multi-head global attention module to better aggregates local observation information among different robots to guide the process of individual policy update. Finally, multi-group experimental results verify the effectiveness of the proposed cooperative motion planner.