 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic Extraction of Materials and Properties from Superconductors Scientific Literature
Oct 26, 2022
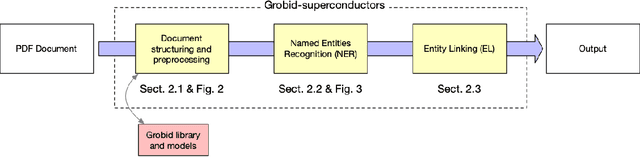
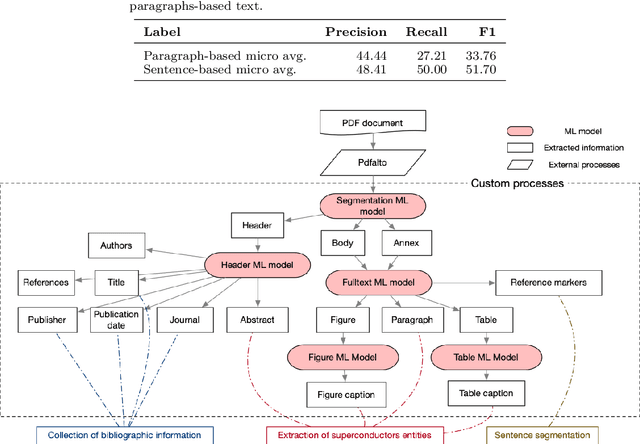


The automatic extraction of materials and related properties from the scientific literature is gaining attention in data-driven materials science (Materials Informatics). In this paper, we discuss Grobid-superconductors, our solution for automatically extracting superconductor material names and respective properties from text. Built as a Grobid module, it combines machine learning and heuristic approaches in a multi-step architecture that supports input data as raw text or PDF documents. Using Grobid-superconductors, we built SuperCon2, a database of 40324 materials and properties records from 37700 papers. The material (or sample) information is represented by name, chemical formula, and material class, and is characterized by shape, doping, substitution variables for components, and substrate as adjoined information. The properties include the Tc superconducting critical temperature and, when available, applied pressure with the Tc measurement method.
Time-rEversed diffusioN tEnsor Transformer: A new TENET of Few-Shot Object Detection
Oct 30, 2022In this paper, we tackle the challenging problem of Few-shot Object Detection. Existing FSOD pipelines (i) use average-pooled representations that result in information loss; and/or (ii) discard position information that can help detect object instances. Consequently, such pipelines are sensitive to large intra-class appearance and geometric variations between support and query images. To address these drawbacks, we propose a Time-rEversed diffusioN tEnsor Transformer (TENET), which i) forms high-order tensor representations that capture multi-way feature occurrences that are highly discriminative, and ii) uses a transformer that dynamically extracts correlations between the query image and the entire support set, instead of a single average-pooled support embedding. We also propose a Transformer Relation Head (TRH), equipped with higher-order representations, which encodes correlations between query regions and the entire support set, while being sensitive to the positional variability of object instances. Our model achieves state-of-the-art results on PASCAL VOC, FSOD, and COCO.
Local Information Assisted Attention-free Decoder for Audio Captioning
Jan 10, 2022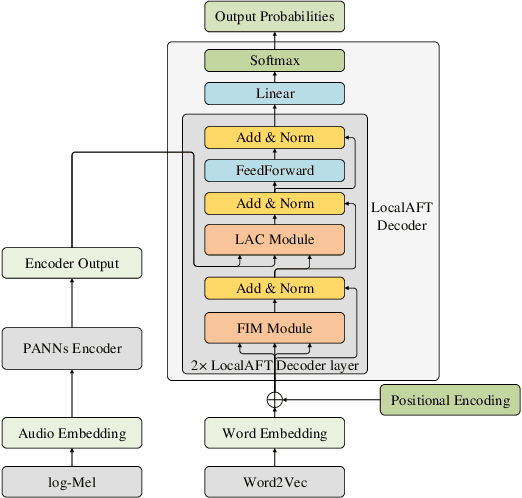
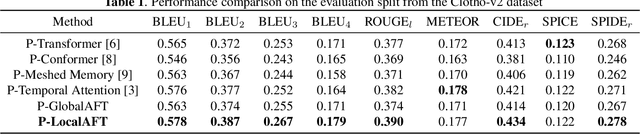
Automated audio captioning (AAC) aims to describe audio data with captions using natural language. Most existing AAC methods adopt an encoder-decoder structure, where the attention based mechanism is a popular choice in the decoder (e.g., Transformer decoder) for predicting captions from audio features. Such attention based decoders can capture the global information from the audio features, however, their ability in extracting local information can be limited, which may lead to degraded quality in the generated captions. In this paper, we present an AAC method with an attention-free decoder, where an encoder based on PANNs is employed for audio feature extraction, and the attention-free decoder is designed to introduce local information. The proposed method enables the effective use of both global and local information from audio signals. Experiments show that our method outperforms the state-of-the-art methods with the standard attention based decoder in Task 6 of the DCASE 2021 Challenge.
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Nov 16, 2022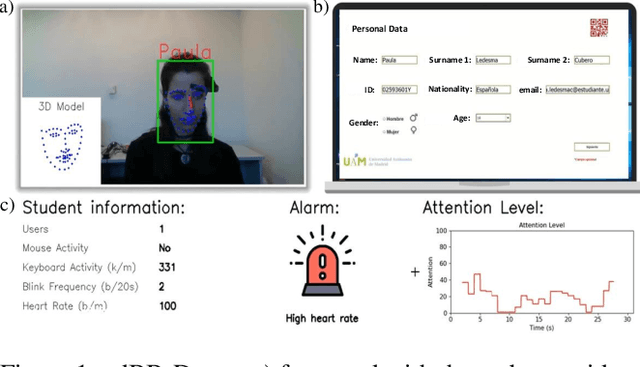
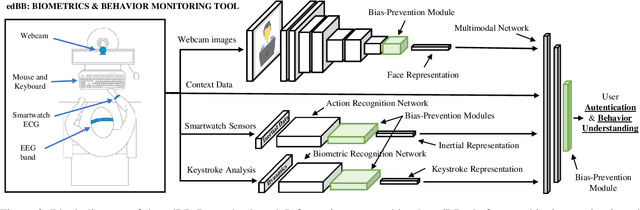
We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
A Physics-informed Diffusion Model for High-fidelity Flow Field Reconstruction
Nov 26, 2022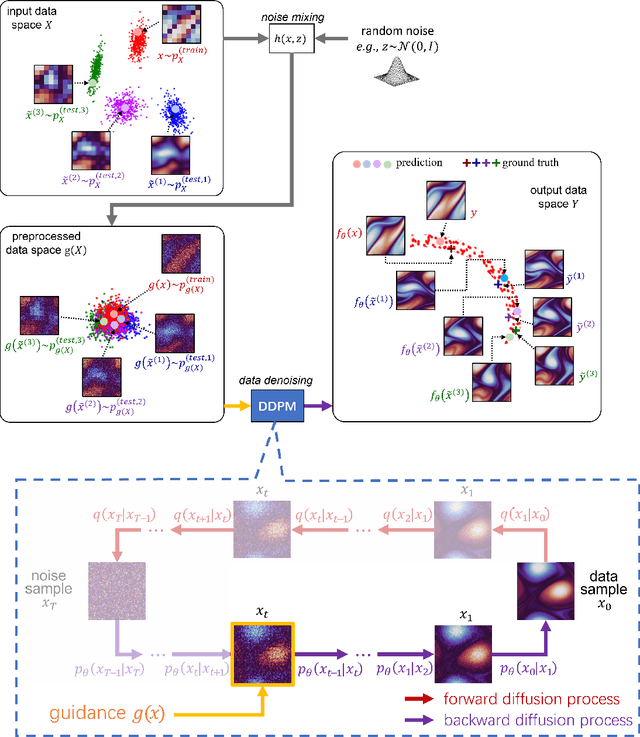

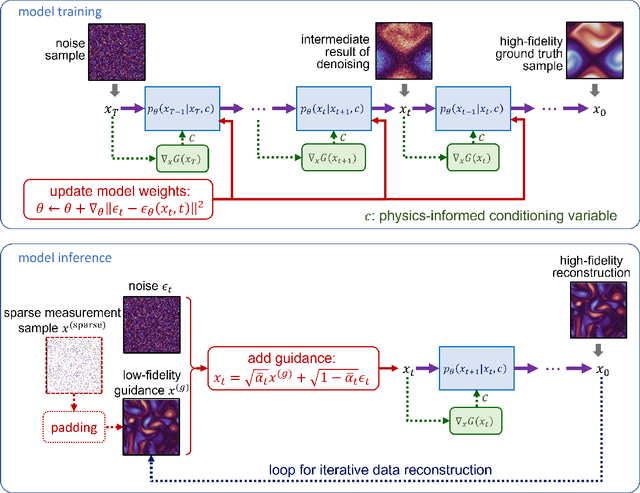
Machine learning models are gaining increasing popularity in the domain of fluid dynamics for their potential to accelerate the production of high-fidelity computational fluid dynamics data. However, many recently proposed machine learning models for high-fidelity data reconstruction require low-fidelity data for model training. Such requirement restrains the application performance of these models, since their data reconstruction accuracy would drop significantly if the low-fidelity input data used in model test has a large deviation from the training data. To overcome this restraint, we propose a diffusion model which only uses high-fidelity data at training. With different configurations, our model is able to reconstruct high-fidelity data from either a regular low-fidelity sample or a sparsely measured sample, and is also able to gain an accuracy increase by using physics-informed conditioning information from a known partial differential equation when that is available. Experimental results demonstrate that our model can produce accurate reconstruction results for 2d turbulent flows based on different input sources without retraining.
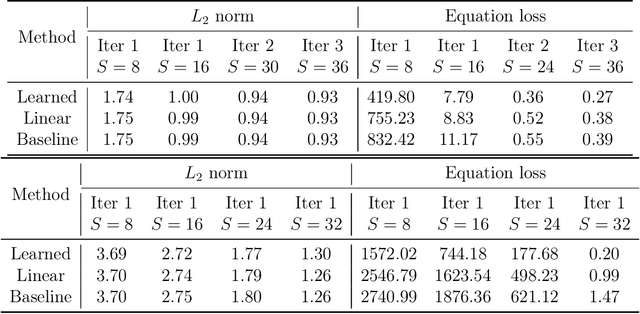
Self-Supervised Image Restoration with Blurry and Noisy Pairs
Nov 14, 2022
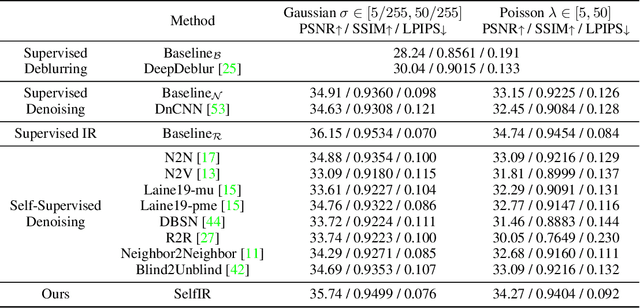
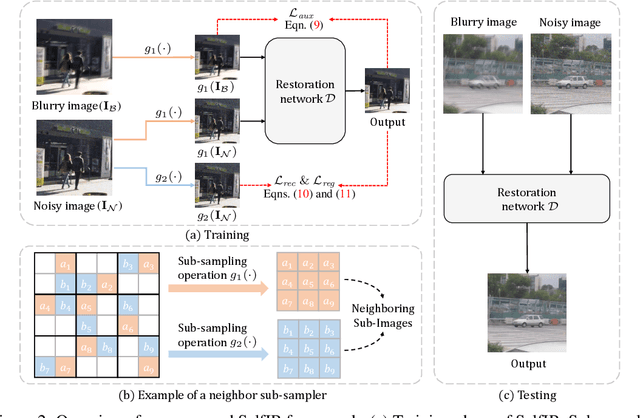
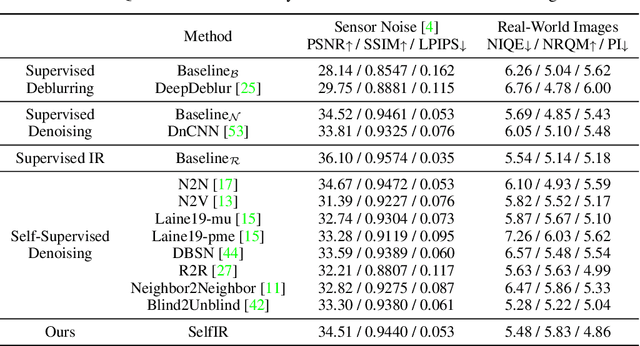
When taking photos under an environment with insufficient light, the exposure time and the sensor gain usually require to be carefully chosen to obtain images with satisfying visual quality. For example, the images with high ISO usually have inescapable noise, while the long-exposure ones may be blurry due to camera shake or object motion. Existing solutions generally suggest to seek a balance between noise and blur, and learn denoising or deblurring models under either full- or self-supervision. However, the real-world training pairs are difficult to collect, and the self-supervised methods merely rely on blurry or noisy images are limited in performance. In this work, we tackle this problem by jointly leveraging the short-exposure noisy image and the long-exposure blurry image for better image restoration. Such setting is practically feasible due to that short-exposure and long-exposure images can be either acquired by two individual cameras or synthesized by a long burst of images. Moreover, the short-exposure images are hardly blurry, and the long-exposure ones have negligible noise. Their complementarity makes it feasible to learn restoration model in a self-supervised manner. Specifically, the noisy images can be used as the supervision information for deblurring, while the sharp areas in the blurry images can be utilized as the auxiliary supervision information for self-supervised denoising. By learning in a collaborative manner, the deblurring and denoising tasks in our method can benefit each other. Experiments on synthetic and real-world images show the effectiveness and practicality of the proposed method. Codes are available at https://github.com/cszhilu1998/SelfIR.
OLIA: an open-source digital lock-in amplifier
Nov 22, 2022
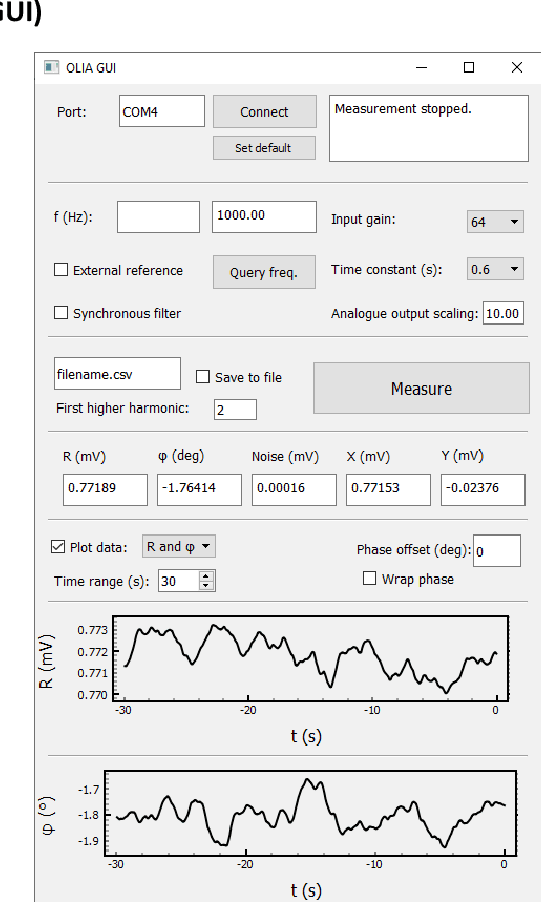
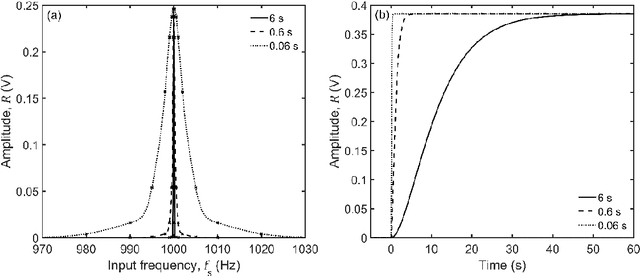
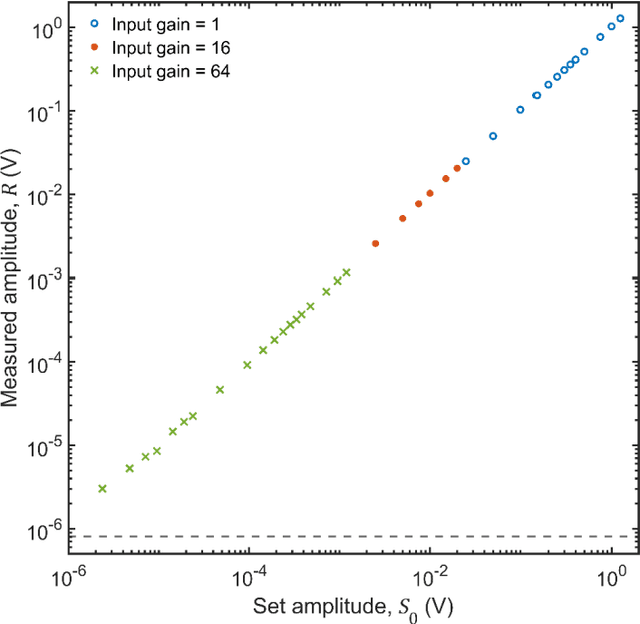
The Open Lock-In Amplifier (OLIA) is a microcontroller-based digital lock-in amplifier built from a small number of inexpensive and easily sourced electronic components. Despite its small credit card-sized form-factor and low build-cost of around US$35, OLIA is a capable instrument that offers many features associated with far costlier commercial devices. Key features include dual-phase lock-in detection at multiple harmonic frequencies up to 50 kHz, internal and external reference modes, adjustable levels of input gain, a choice between low-pass filtering and synchronous filtering, noise estimation, and a comprehensive programming interface for remote software control. OLIA comes with an optional optical breakout board that allows noise-tolerant optical detection down to the 40 pW level. OLIA and its breakout board are released here as open hardware, with technical diagrams, full parts-lists, and source-code for the firmware provided as Supporting Information.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022
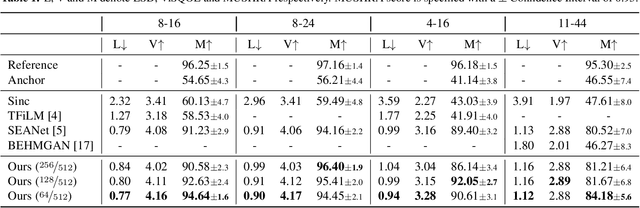
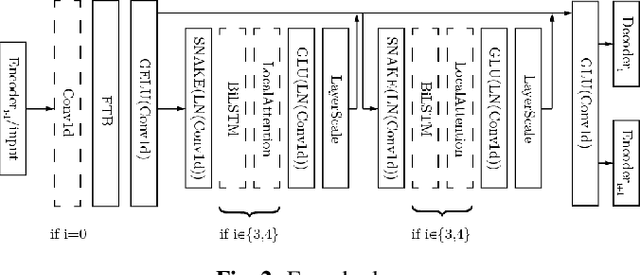
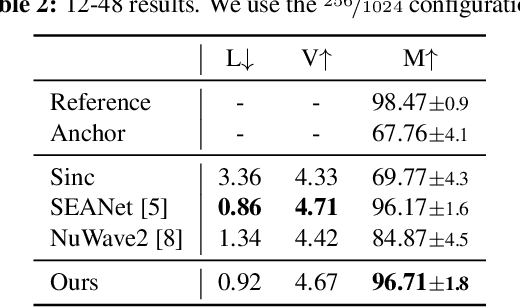
We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
Domain Alignment and Temporal Aggregation for Unsupervised Video Object Segmentation
Nov 22, 2022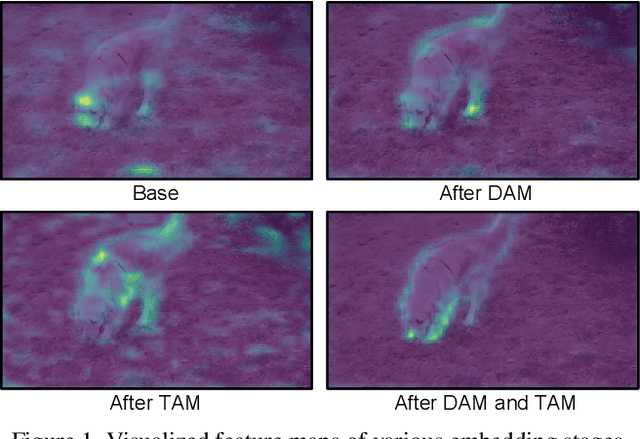
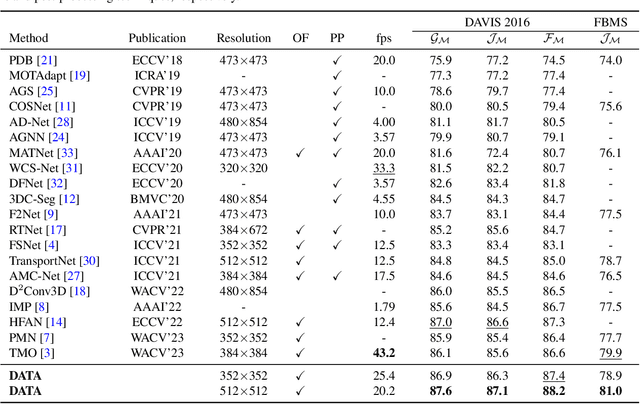
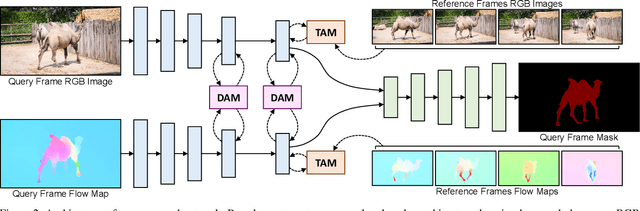
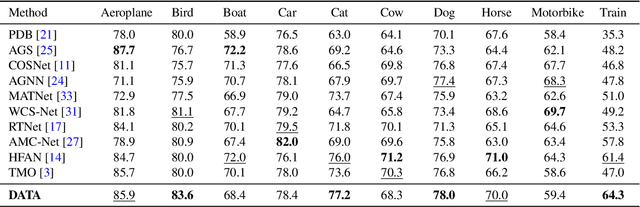
Unsupervised video object segmentation aims at detecting and segmenting the most salient object in videos. In recent times, two-stream approaches that collaboratively leverage appearance cues and motion cues have attracted extensive attention thanks to their powerful performance. However, there are two limitations faced by those methods: 1) the domain gap between appearance and motion information is not well considered; and 2) long-term temporal coherence within a video sequence is not exploited. To overcome these limitations, we propose a domain alignment module (DAM) and a temporal aggregation module (TAM). DAM resolves the domain gap between two modalities by forcing the values to be in the same range using a cross-correlation mechanism. TAM captures long-term coherence by extracting and leveraging global cues of a video. On public benchmark datasets, our proposed approach demonstrates its effectiveness, outperforming all existing methods by a substantial margin.
CySecBERT: A Domain-Adapted Language Model for the Cybersecurity Domain
Dec 06, 2022
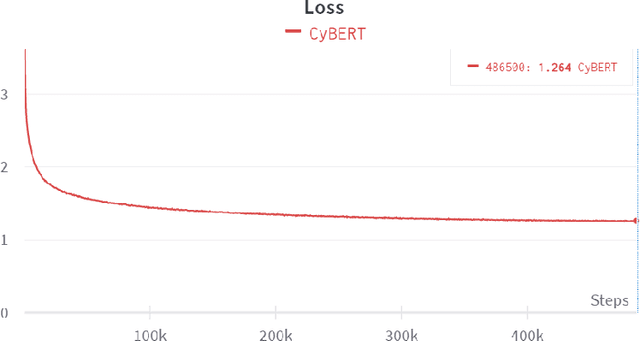
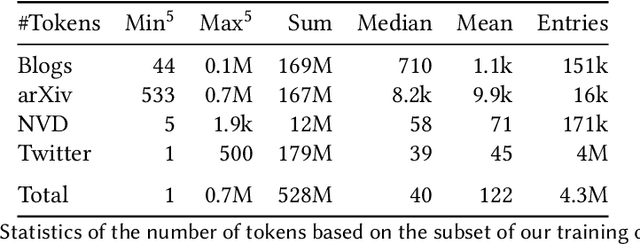
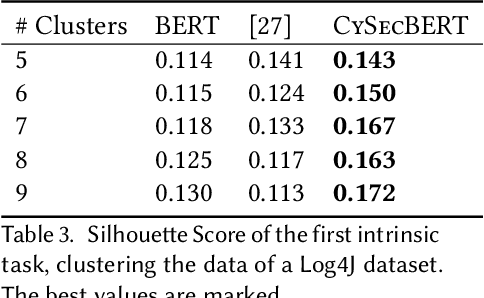
The field of cybersecurity is evolving fast. Experts need to be informed about past, current and - in the best case - upcoming threats, because attacks are becoming more advanced, targets bigger and systems more complex. As this cannot be addressed manually, cybersecurity experts need to rely on machine learning techniques. In the texutual domain, pre-trained language models like BERT have shown to be helpful, by providing a good baseline for further fine-tuning. However, due to the domain-knowledge and many technical terms in cybersecurity general language models might miss the gist of textual information, hence doing more harm than good. For this reason, we create a high-quality dataset and present a language model specifically tailored to the cybersecurity domain, which can serve as a basic building block for cybersecurity systems that deal with natural language. The model is compared with other models based on 15 different domain-dependent extrinsic and intrinsic tasks as well as general tasks from the SuperGLUE benchmark. On the one hand, the results of the intrinsic tasks show that our model improves the internal representation space of words compared to the other models. On the other hand, the extrinsic, domain-dependent tasks, consisting of sequence tagging and classification, show that the model is best in specific application scenarios, in contrast to the others. Furthermore, we show that our approach against catastrophic forgetting works, as the model is able to retrieve the previously trained domain-independent knowledge. The used dataset and trained model are made publicly available