 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proprioceptive Sensing of Soft Tentacles with Model Based Reconstruction for Controller Optimization
Nov 24, 2022
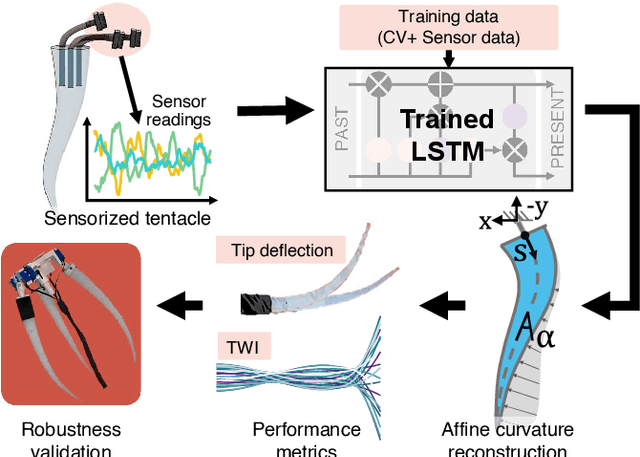
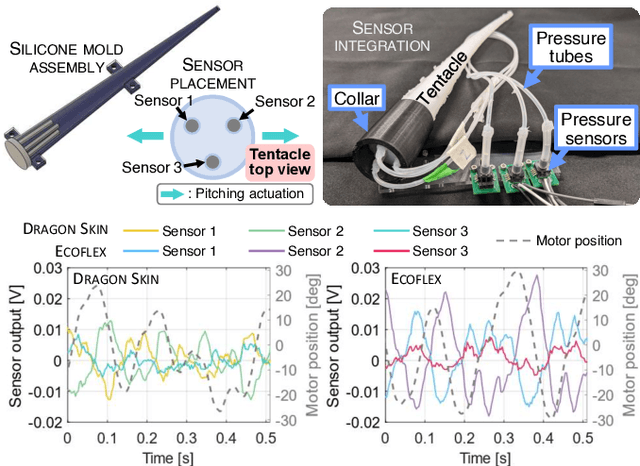
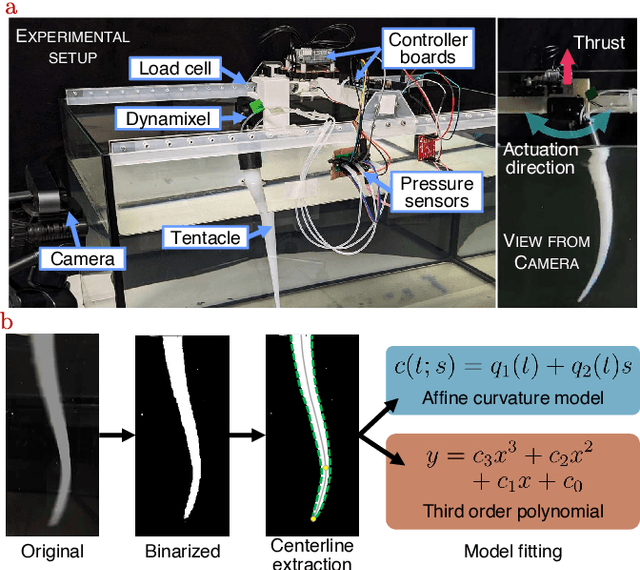
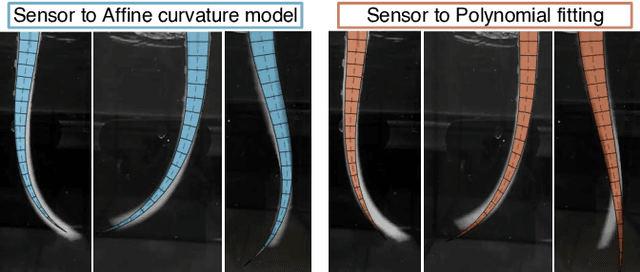
The success of soft robots in displaying emergent behaviors is tightly linked to the compliant interaction with the environment. However, to exploit such phenomena, proprioceptive sensing methods which do not hinder their softness are needed. In this work we propose a new sensing approach for soft underwater slender structures based on embedded pressure sensors and use a learning-based pipeline to link the sensor readings to the shape of the soft structure. Using two different modeling techniques, we compare the pose reconstruction accuracy and identify the optimal approach. Using the proprioceptive sensing capabilities we show how this information can be used to assess the swimming performance over a number of metrics, namely swimming thrust, tip deflection, and the traveling wave index. We conclude by demonstrating the robustness of the embedded sensor on a free swimming soft robotic squid swimming at a maximum velocity of 9.5 cm/s, with the absolute tip deflection being predicted within an error less than 9% without the aid of external sensors.
ditlab system for Dialogue Robot Competition 2022
Oct 13, 2022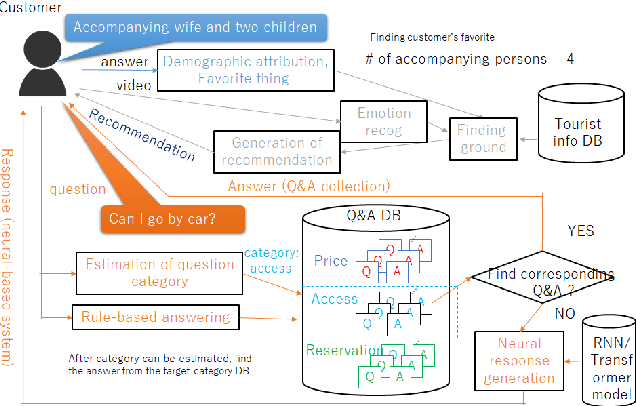
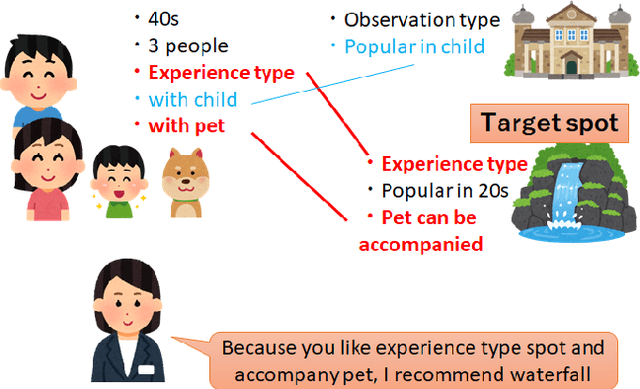
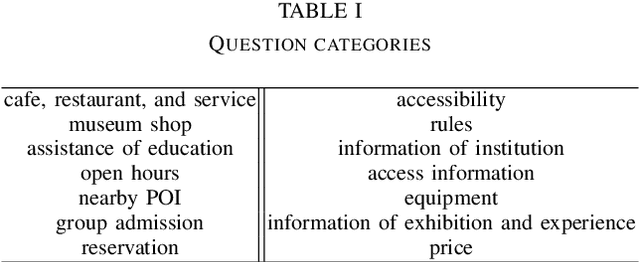
We developed a dialogue system for Dialogue Robot Competition 2022. Our system is composed of three parts. First part investigates participants' demographic information by rule-based interview. Second part recommends a point of interest (POI) based on the collected demographic information. Third part answers participants' question based on the combination of rule-based answering and deep-learning-based answering with nearby POI search.
Shadow Removal by High-Quality Shadow Synthesis
Dec 08, 2022
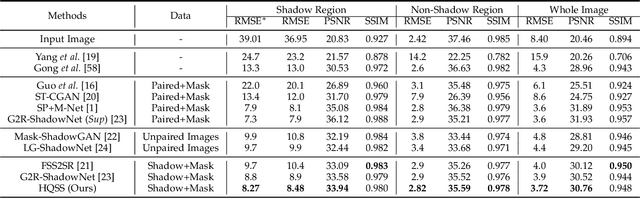
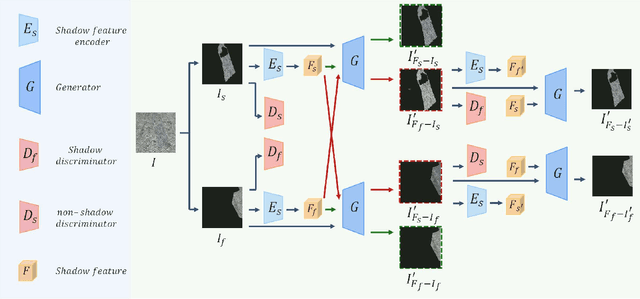
Most shadow removal methods rely on the invasion of training images associated with laborious and lavish shadow region annotations, leading to the increasing popularity of shadow image synthesis. However, the poor performance also stems from these synthesized images since they are often shadow-inauthentic and details-impaired. In this paper, we present a novel generation framework, referred to as HQSS, for high-quality pseudo shadow image synthesis. The given image is first decoupled into a shadow region identity and a non-shadow region identity. HQSS employs a shadow feature encoder and a generator to synthesize pseudo images. Specifically, the encoder extracts the shadow feature of a region identity which is then paired with another region identity to serve as the generator input to synthesize a pseudo image. The pseudo image is expected to have the shadow feature as its input shadow feature and as well as a real-like image detail as its input region identity. To fulfill this goal, we design three learning objectives. When the shadow feature and input region identity are from the same region identity, we propose a self-reconstruction loss that guides the generator to reconstruct an identical pseudo image as its input. When the shadow feature and input region identity are from different identities, we introduce an inter-reconstruction loss and a cycle-reconstruction loss to make sure that shadow characteristics and detail information can be well retained in the synthesized images. Our HQSS is observed to outperform the state-of-the-art methods on ISTD dataset, Video Shadow Removal dataset, and SRD dataset. The code is available at https://github.com/zysxmu/HQSS.
Deep Surface Reconstruction from Point Clouds with Visibility Information
Feb 03, 2022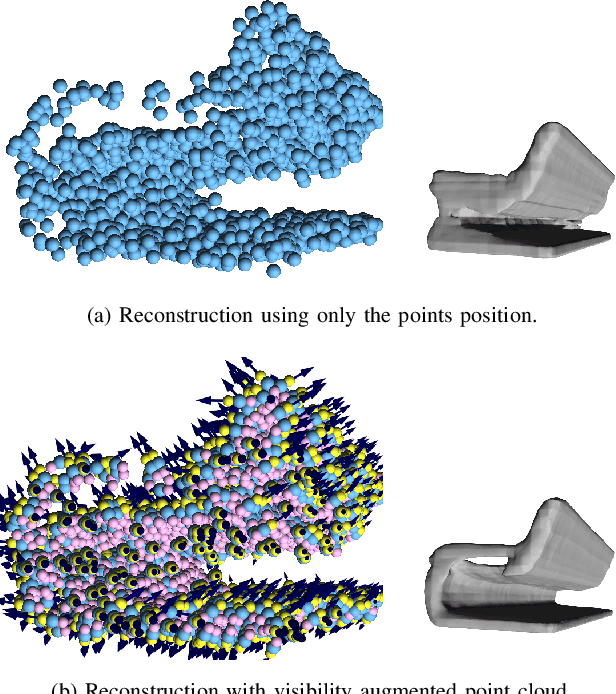


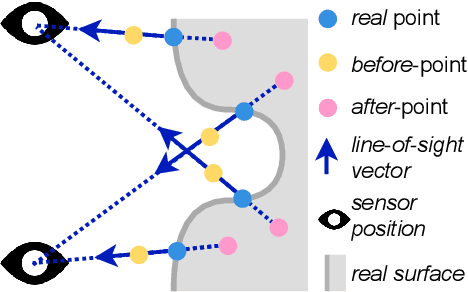
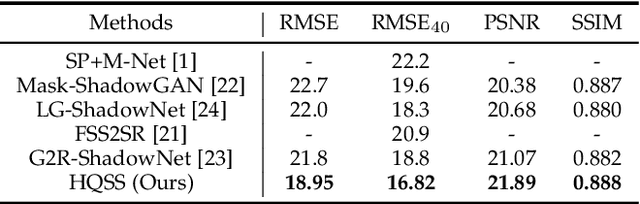
Most current neural networks for reconstructing surfaces from point clouds ignore sensor poses and only operate on raw point locations. Sensor visibility, however, holds meaningful information regarding space occupancy and surface orientation. In this paper, we present two simple ways to augment raw point clouds with visibility information, so it can directly be leveraged by surface reconstruction networks with minimal adaptation. Our proposed modifications consistently improve the accuracy of generated surfaces as well as the generalization ability of the networks to unseen shape domains. Our code and data is available at https://github.com/raphaelsulzer/dsrv-data.
M$^3$Care: Learning with Missing Modalities in Multimodal Healthcare Data
Oct 28, 2022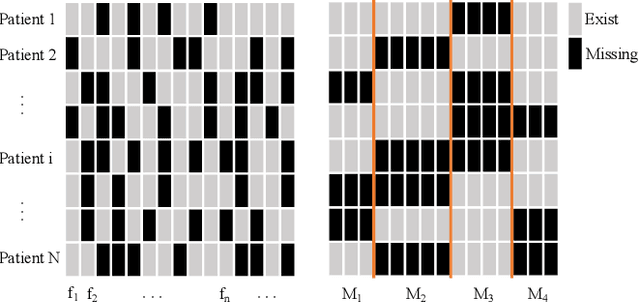
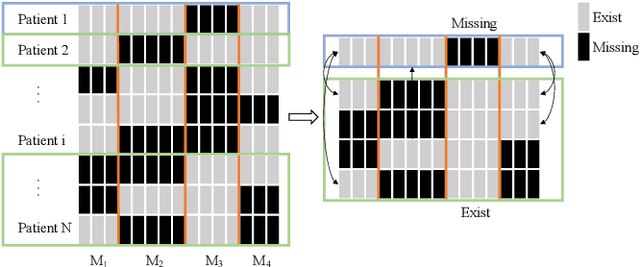
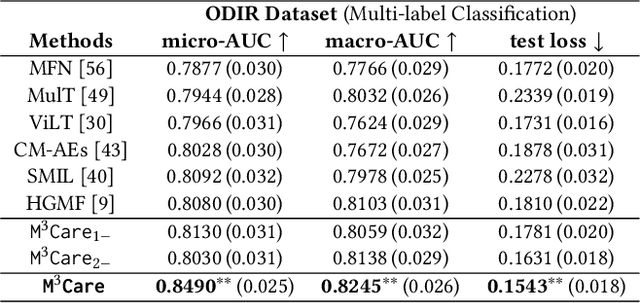
Multimodal electronic health record (EHR) data are widely used in clinical applications. Conventional methods usually assume that each sample (patient) is associated with the unified observed modalities, and all modalities are available for each sample. However, missing modality caused by various clinical and social reasons is a common issue in real-world clinical scenarios. Existing methods mostly rely on solving a generative model that learns a mapping from the latent space to the original input space, which is an unstable ill-posed inverse problem. To relieve the underdetermined system, we propose a model solving a direct problem, dubbed learning with Missing Modalities in Multimodal healthcare data (M3Care). M3Care is an end-to-end model compensating the missing information of the patients with missing modalities to perform clinical analysis. Instead of generating raw missing data, M3Care imputes the task-related information of the missing modalities in the latent space by the auxiliary information from each patient's similar neighbors, measured by a task-guided modality-adaptive similarity metric, and thence conducts the clinical tasks. The task-guided modality-adaptive similarity metric utilizes the uncensored modalities of the patient and the other patients who also have the same uncensored modalities to find similar patients. Experiments on real-world datasets show that M3Care outperforms the state-of-the-art baselines. Moreover, the findings discovered by M3Care are consistent with experts and medical knowledge, demonstrating the capability and the potential of providing useful insights and explanations.
* 9 pages
A Survey on Over-the-Air Computation
Oct 20, 2022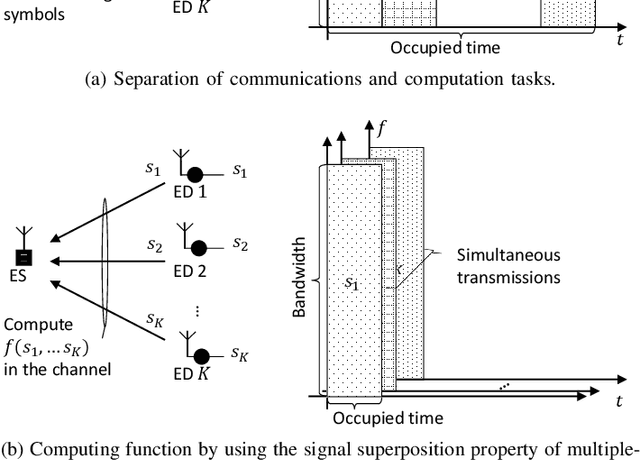
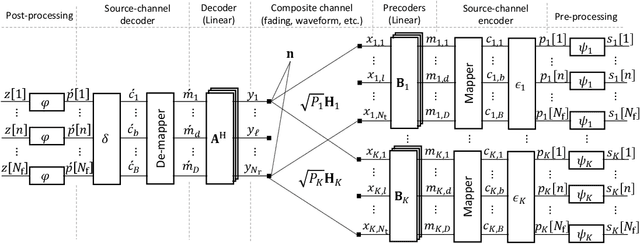
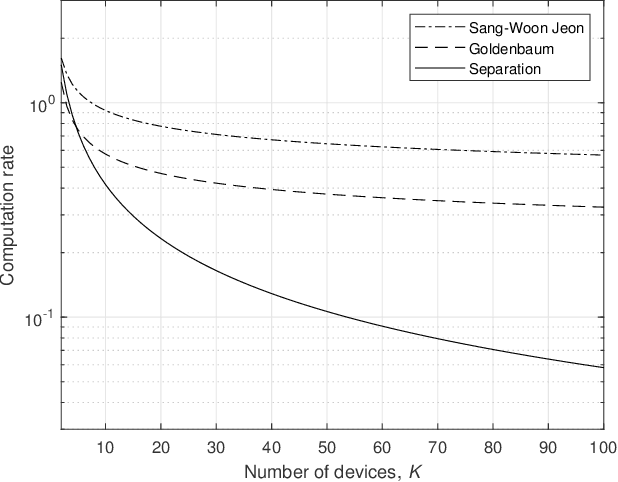
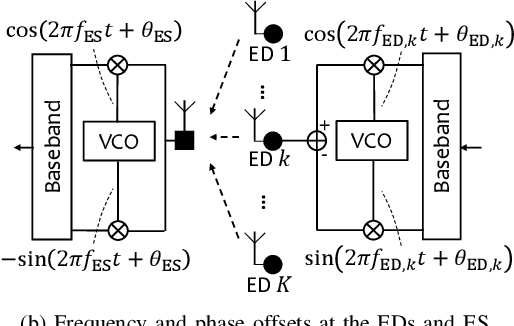
Communication and computation are often viewed as separate tasks. This approach is very effective from the perspective of engineering as isolated optimizations can be performed. On the other hand, there are many cases where the main interest is a function of the local information at the devices instead of the local information itself. For such scenarios, information theoretical results show that harnessing the interference in a multiple-access channel for computation, i.e., over-the-air computation (OAC), can provide a significantly higher achievable computation rate than the one with the separation of communication and computation tasks. Besides, the gap between OAC and separation in terms of computation rate increases with more participating nodes. Given this motivation, in this study, we provide a comprehensive survey on practical OAC methods. After outlining fundamentals related to OAC, we discuss the available OAC schemes with their pros and cons. We then provide an overview of the enabling mechanisms and relevant metrics to achieve reliable computation in the wireless channel. Finally, we summarize the potential applications of OAC and point out some future directions.
Methods for Recovering Conditional Independence Graphs: A Survey
Nov 13, 2022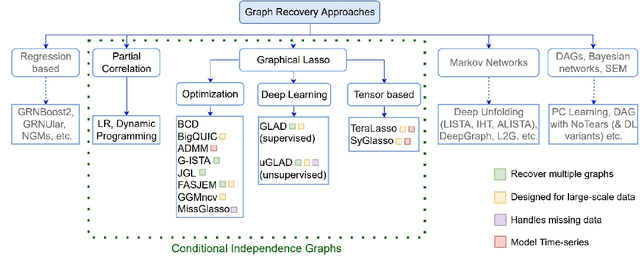
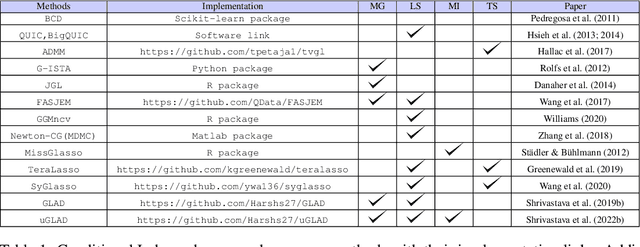
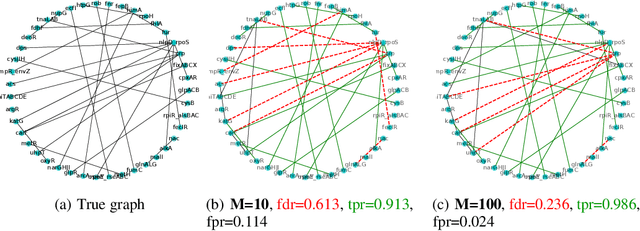
Conditional Independence (CI) graphs are a type of probabilistic graphical models that are primarily used to gain insights about feature relationships. Each edge represents the partial correlation between the connected features which gives information about their direct dependence. In this survey, we list out different methods and study the advances in techniques developed to recover CI graphs. We cover traditional optimization methods as well as recently developed deep learning architectures along with their recommended implementations. To facilitate wider adoption, we include preliminaries that consolidate associated operations, for example techniques to obtain covariance matrix for mixed datatypes.
Transformer Language Models without Positional Encodings Still Learn Positional Information
Mar 30, 2022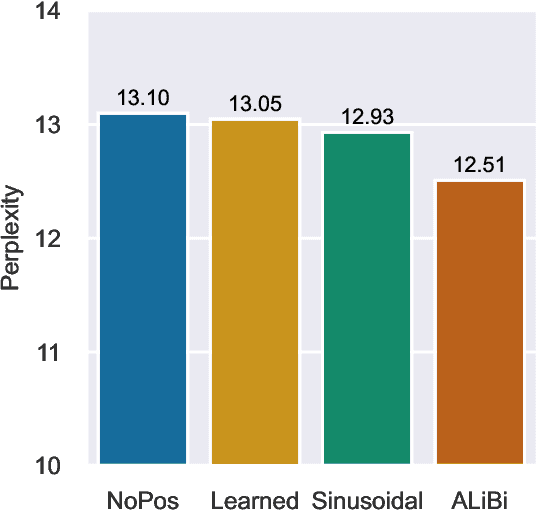
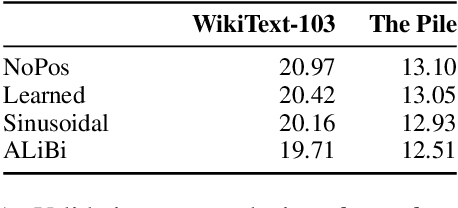
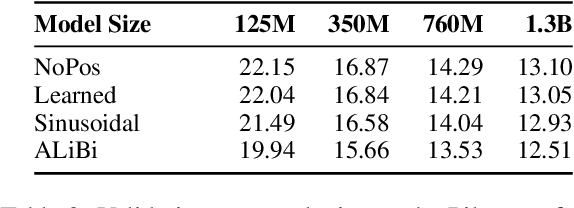
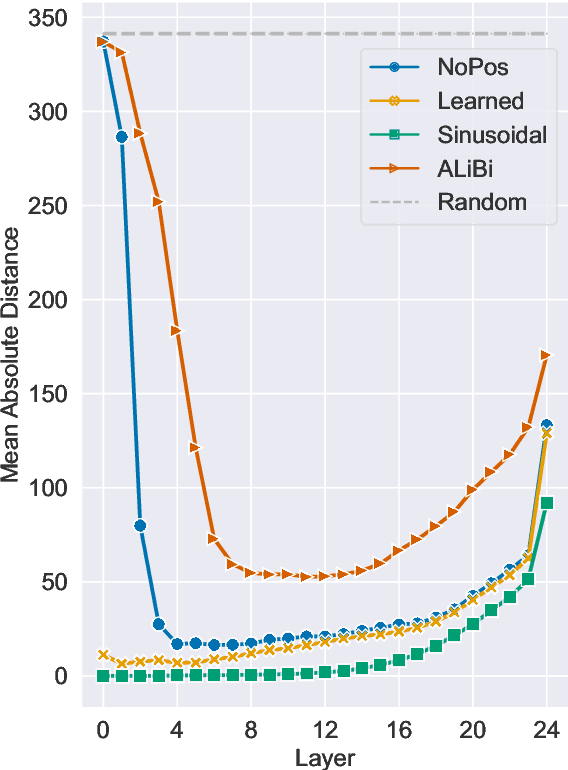
Transformers typically require some form of positional encoding, such as positional embeddings, to process natural language sequences. Surprisingly, we find that transformer language models without any explicit positional encoding are still competitive with standard models, and that this phenomenon is robust across different datasets, model sizes, and sequence lengths. Probing experiments reveal that such models acquire an implicit notion of absolute positions throughout the network, effectively compensating for the missing information. We conjecture that causal attention enables the model to infer the number of predecessors that each token can attend to, thereby approximating its absolute position.
HaptiX: Extending Cobot's Motion Intention Visualization by Haptic Feedback
Oct 28, 2022

Nowadays, robots are found in a growing number of areas where they collaborate closely with humans. Enabled by lightweight materials and safety sensors, these cobots are gaining increasing popularity in domestic care, supporting people with physical impairments in their everyday lives. However, when cobots perform actions autonomously, it remains challenging for human collaborators to understand and predict their behavior, which is crucial for achieving trust and user acceptance. One significant aspect of predicting cobot behavior is understanding their motion intention and comprehending how they "think" about their actions. Moreover, other information sources often occupy human visual and audio modalities, rendering them frequently unsuitable for transmitting such information. We work on a solution that communicates cobot intention via haptic feedback to tackle this challenge. In our concept, we map planned motions of the cobot to different haptic patterns to extend the visual intention feedback.
GliTr: Glimpse Transformers with Spatiotemporal Consistency for Online Action Prediction
Oct 24, 2022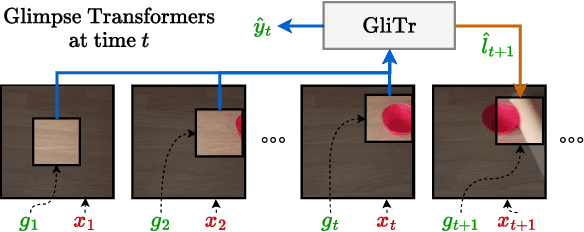
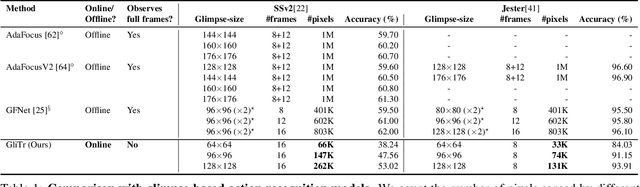
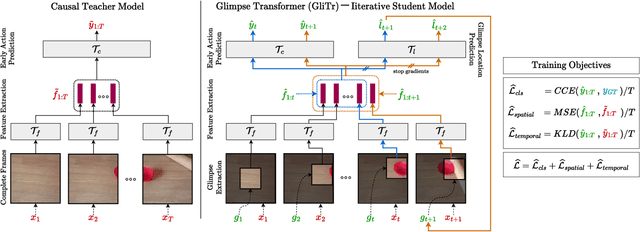

Many online action prediction models observe complete frames to locate and attend to informative subregions in the frames called glimpses and recognize an ongoing action based on global and local information. However, in applications with constrained resources, an agent may not be able to observe the complete frame, yet must still locate useful glimpses to predict an incomplete action based on local information only. In this paper, we develop Glimpse Transformers (GliTr), which observe only narrow glimpses at all times, thus predicting an ongoing action and the following most informative glimpse location based on the partial spatiotemporal information collected so far. In the absence of a ground truth for the optimal glimpse locations for action recognition, we train GliTr using a novel spatiotemporal consistency objective: We require GliTr to attend to the glimpses with features similar to the corresponding complete frames (i.e. spatial consistency) and the resultant class logits at time t equivalent to the ones predicted using whole frames up to t (i.e. temporal consistency). Inclusion of our proposed consistency objective yields ~10% higher accuracy on the Something-Something-v2 (SSv2) dataset than the baseline cross-entropy objective. Overall, despite observing only ~33% of the total area per frame, GliTr achieves 53.02%and 93.91% accuracy on the SSv2 and Jester datasets, respectively.