 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Contrastive Feature learning for Tabular Data
Nov 19, 2022

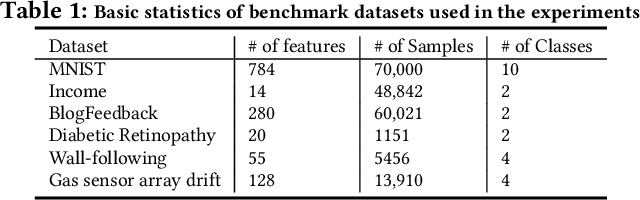
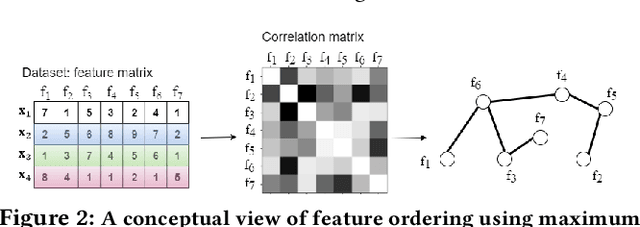
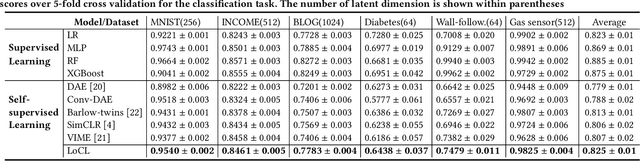
Contrastive self-supervised learning has been successfully used in many domains, such as images, texts, graphs, etc., to learn features without requiring label information. In this paper, we propose a new local contrastive feature learning (LoCL) framework, and our theme is to learn local patterns/features from tabular data. In order to create a niche for local learning, we use feature correlations to create a maximum-spanning tree, and break the tree into feature subsets, with strongly correlated features being assigned next to each other. Convolutional learning of the features is used to learn latent feature space, regulated by contrastive and reconstruction losses. Experiments on public tabular datasets show the effectiveness of the proposed method versus state-of-the-art baseline methods.
Method for Determining the Similarity of Text Documents for the Kazakh language, Taking Into Account Synonyms: Extension to TF-IDF
Nov 22, 2022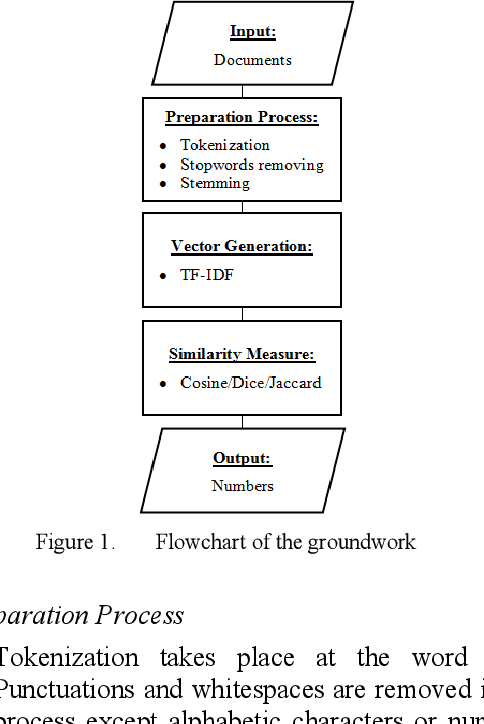
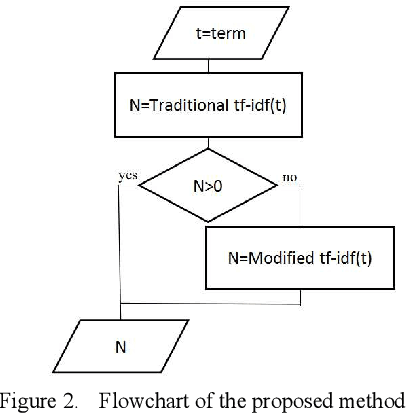
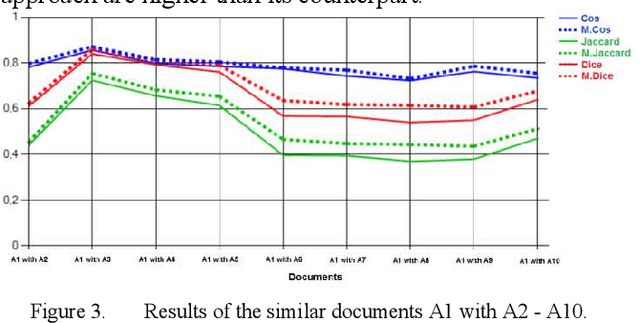
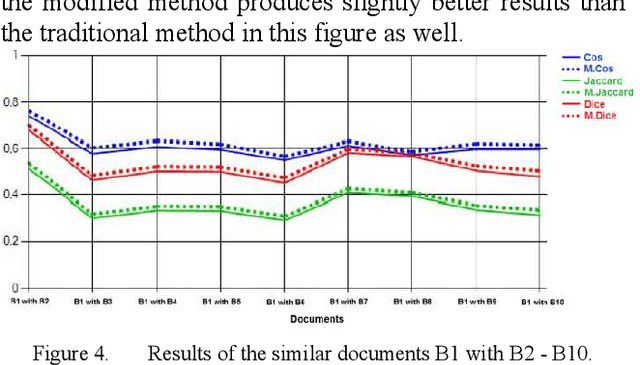
The task of determining the similarity of text documents has received considerable attention in many areas such as Information Retrieval, Text Mining, Natural Language Processing (NLP) and Computational Linguistics. Transferring data to numeric vectors is a complex task where algorithms such as tokenization, stopword filtering, stemming, and weighting of terms are used. The term frequency - inverse document frequency (TF-IDF) is the most widely used term weighting method to facilitate the search for relevant documents. To improve the weighting of terms, a large number of TF-IDF extensions are made. In this paper, another extension of the TF-IDF method is proposed where synonyms are taken into account. The effectiveness of the method is confirmed by experiments on functions such as Cosine, Dice and Jaccard to measure the similarity of text documents for the Kazakh language.
Explainable Artificial Intelligence: Precepts, Methods, and Opportunities for Research in Construction
Nov 12, 2022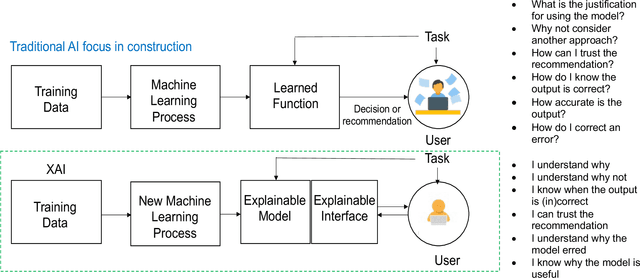
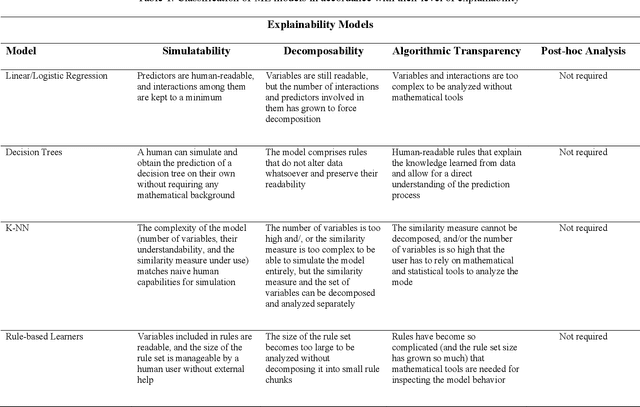
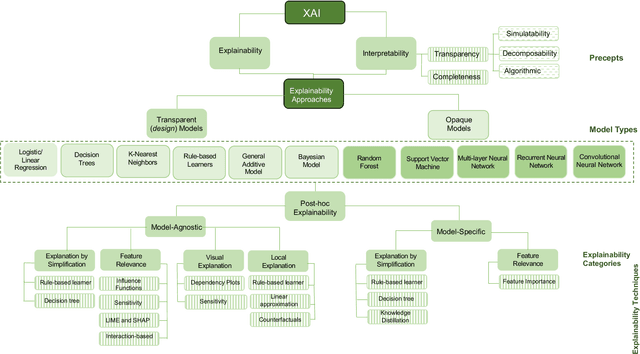

Explainable artificial intelligence has received limited attention in construction despite its growing importance in various other industrial sectors. In this paper, we provide a narrative review of XAI to raise awareness about its potential in construction. Our review develops a taxonomy of the XAI literature comprising its precepts and approaches. Opportunities for future XAI research focusing on stakeholder desiderata and data and information fusion are identified and discussed. We hope the opportunities we suggest stimulate new lines of inquiry to help alleviate the scepticism and hesitancy toward AI adoption and integration in construction.
End-to-end Transformer for Compressed Video Quality Enhancement
Oct 25, 2022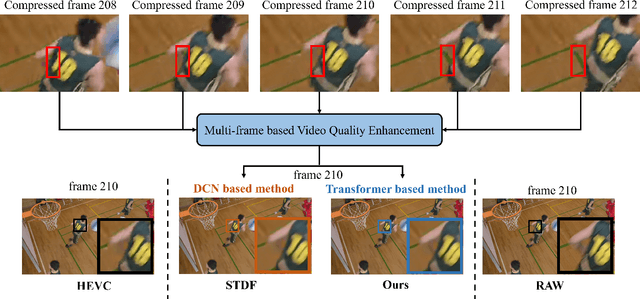
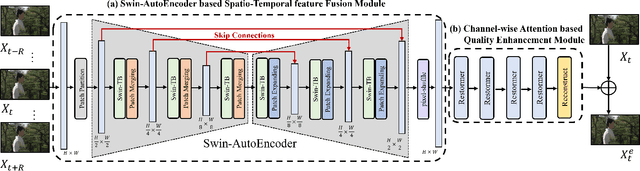
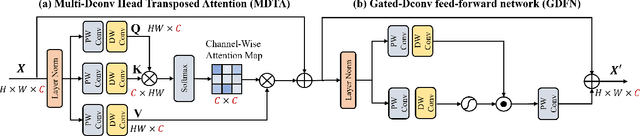
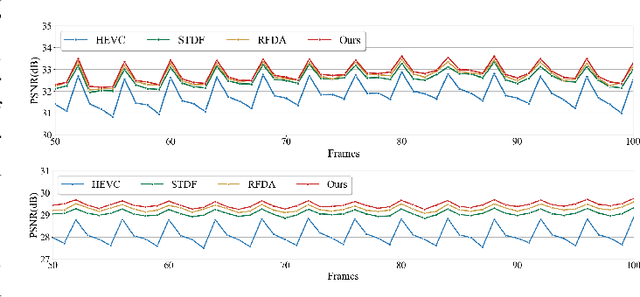
Convolutional neural networks have achieved excellent results in compressed video quality enhancement task in recent years. State-of-the-art methods explore the spatiotemporal information of adjacent frames mainly by deformable convolution. However, offset fields in deformable convolution are difficult to train, and its instability in training often leads to offset overflow, which reduce the efficiency of correlation modeling. In this work, we propose a transformer-based compressed video quality enhancement (TVQE) method, consisting of Swin-AutoEncoder based Spatio-Temporal feature Fusion (SSTF) module and Channel-wise Attention based Quality Enhancement (CAQE) module. The proposed SSTF module learns both local and global features with the help of Swin-AutoEncoder, which improves the ability of correlation modeling. Meanwhile, the window mechanism-based Swin Transformer and the encoderdecoder structure greatly improve the execution efficiency. On the other hand, the proposed CAQE module calculates the channel attention, which aggregates the temporal information between channels in the feature map, and finally achieves the efficient fusion of inter-frame information. Extensive experimental results on the JCT-VT test sequences show that the proposed method achieves better performance in average for both subjective and objective quality. Meanwhile, our proposed method outperforms existing ones in terms of both inference speed and GPU consumption.
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022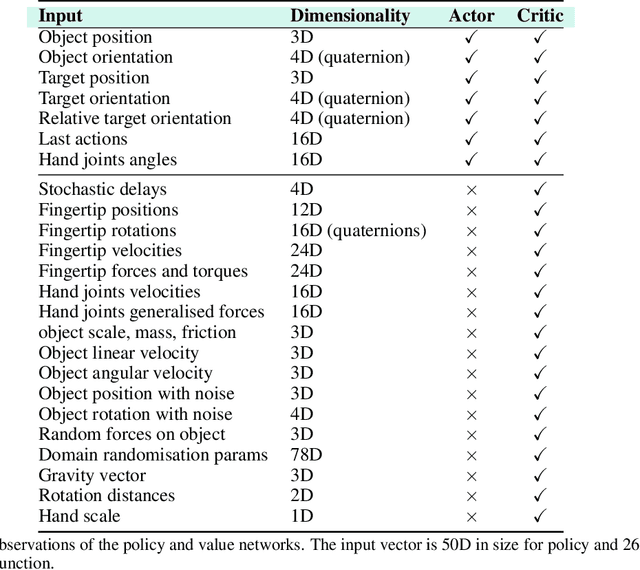


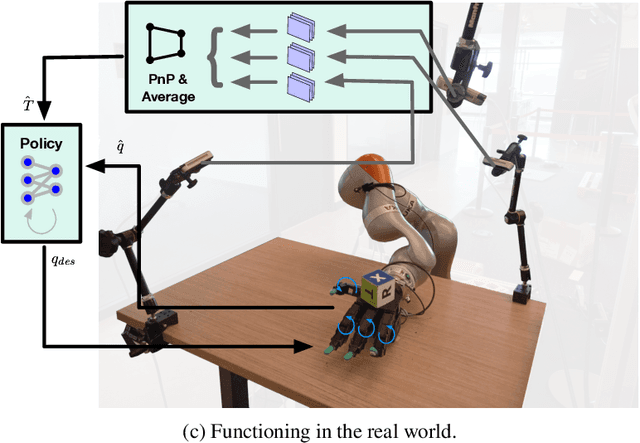
Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022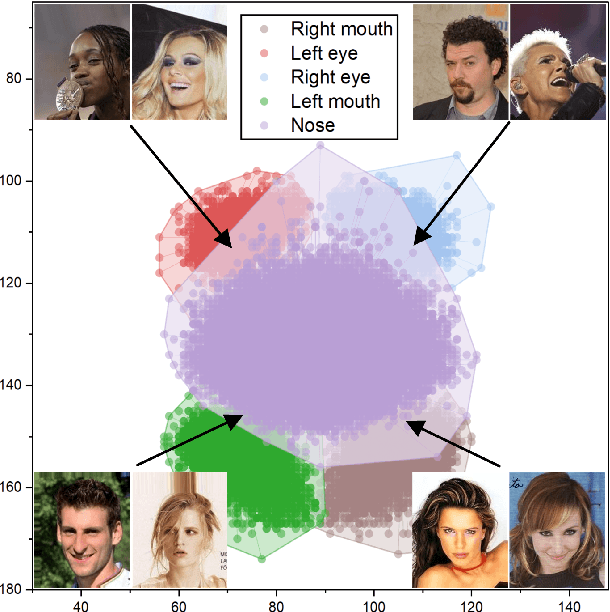
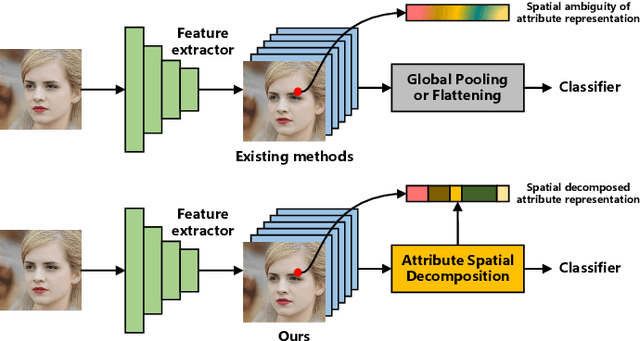
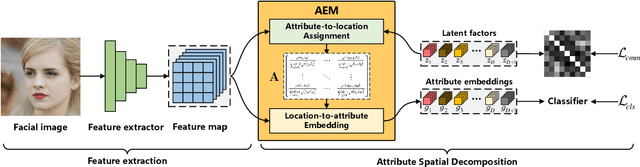
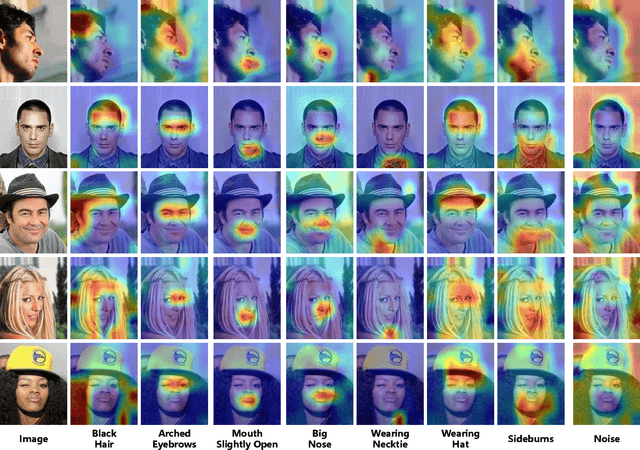
Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
PointSee: Image Enhances Point Cloud
Nov 03, 2022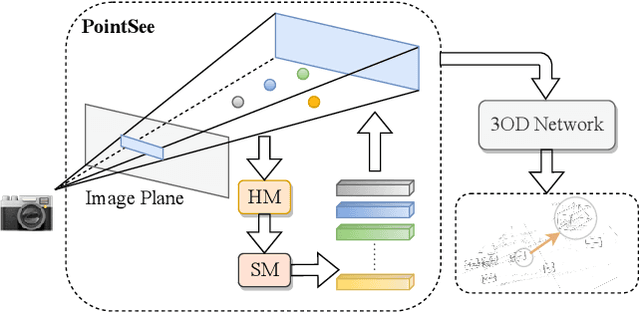
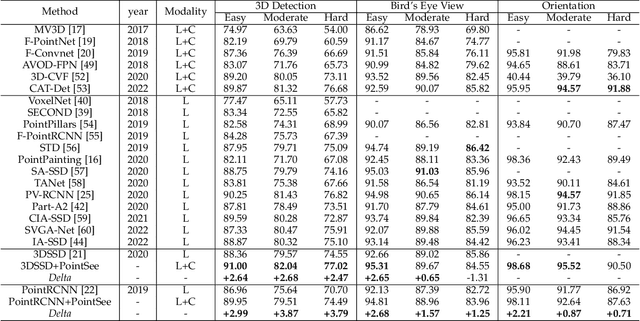
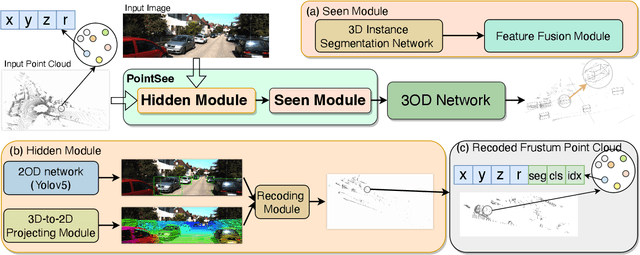

There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.
Data-based Polymer-Unit Fingerprint (PUFp): A Newly Accessible Expression of Polymer Organic Semiconductors for Machine Learning
Nov 03, 2022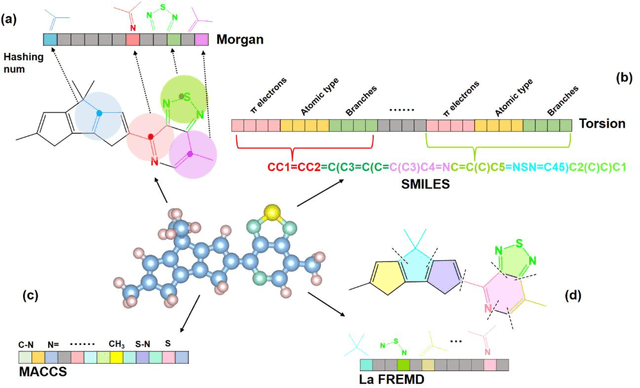
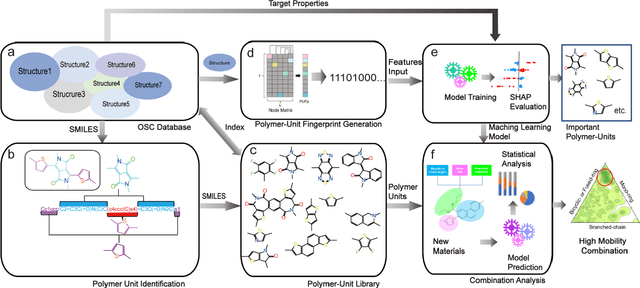
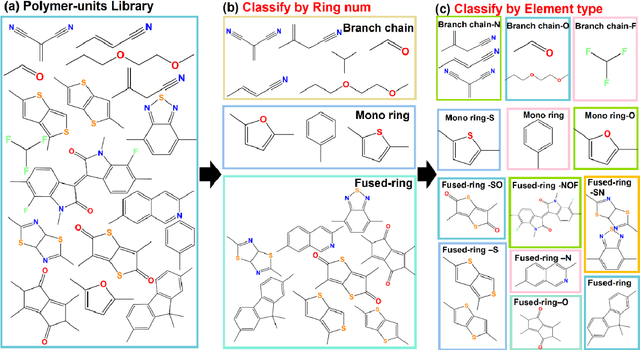

In the process of finding high-performance organic semiconductors (OSCs), it is of paramount importance in material development to identify important functional units that play key roles in material performance and subsequently establish substructure-property relationships. Herein, we describe a polymer-unit fingerprint (PUFp) generation framework. Machine learning (ML) models can be used to determine structure-mobility relationships by using PUFp information as structural input with 678 pieces of collected OSC data. A polymer-unit library consisting of 445 units is constructed, and the key polymer units for the mobility of OSCs are identified. By investigating the combinations of polymer units with mobility performance, a scheme for designing polymer OSC materials by combining ML approaches and PUFp information is proposed to not only passively predict OSC mobility but also actively provide structural guidance for new high-mobility OSC material design. The proposed scheme demonstrates the ability to screen new materials through pre-evaluation and classification ML steps and is an alternative methodology for applying ML in new high-mobility OSC discovery.
Analysing the effectiveness of a generative model for semi-supervised medical image segmentation
Nov 03, 2022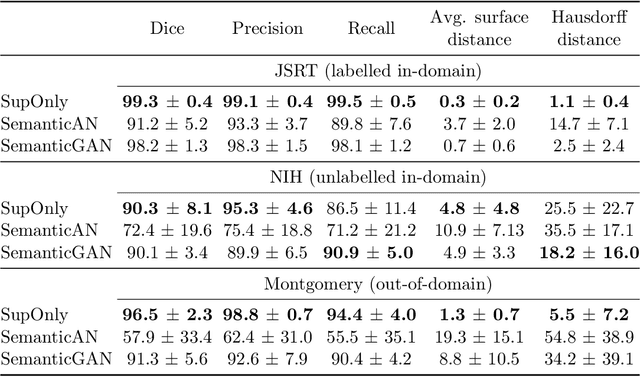
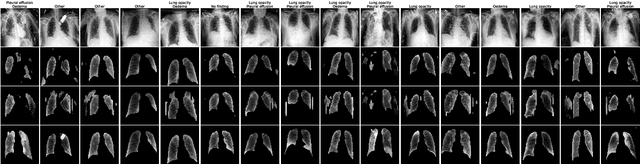
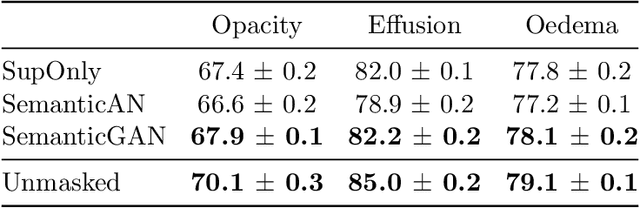

Image segmentation is important in medical imaging, providing valuable, quantitative information for clinical decision-making in diagnosis, therapy, and intervention. The state-of-the-art in automated segmentation remains supervised learning, employing discriminative models such as U-Net. However, training these models requires access to large amounts of manually labelled data which is often difficult to obtain in real medical applications. In such settings, semi-supervised learning (SSL) attempts to leverage the abundance of unlabelled data to obtain more robust and reliable models. Recently, generative models have been proposed for semantic segmentation, as they make an attractive choice for SSL. Their ability to capture the joint distribution over input images and output label maps provides a natural way to incorporate information from unlabelled images. This paper analyses whether deep generative models such as the SemanticGAN are truly viable alternatives to tackle challenging medical image segmentation problems. To that end, we thoroughly evaluate the segmentation performance, robustness, and potential subgroup disparities of discriminative and generative segmentation methods when applied to large-scale, publicly available chest X-ray datasets.
Time-aware Prompting for Text Generation
Nov 03, 2022
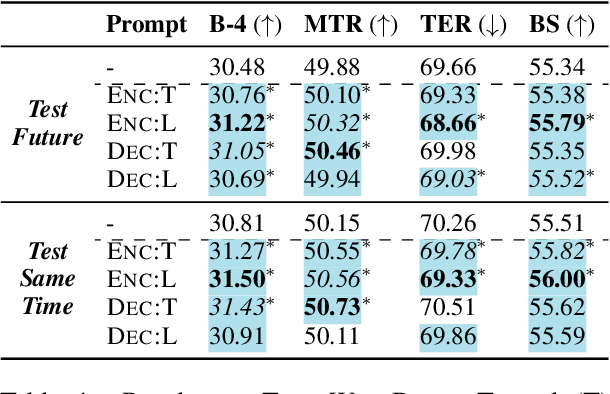
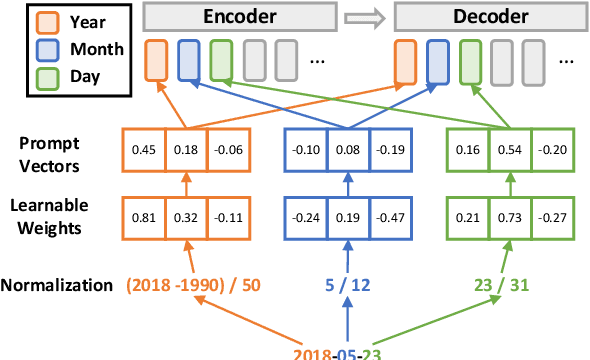
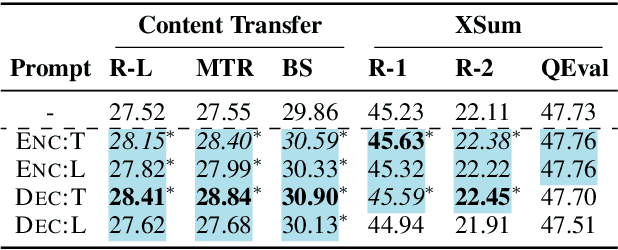
In this paper, we study the effects of incorporating timestamps, such as document creation dates, into generation systems. Two types of time-aware prompts are investigated: (1) textual prompts that encode document timestamps in natural language sentences; and (2) linear prompts that convert timestamps into continuous vectors. To explore extrapolation to future data points, we further introduce a new data-to-text generation dataset, TempWikiBio, containing more than 4 millions of chronologically ordered revisions of biographical articles from English Wikipedia, each paired with structured personal profiles. Through data-to-text generation on TempWikiBio, text-to-text generation on the content transfer dataset, and summarization on XSum, we show that linear prompts on encoder and textual prompts improve the generation quality on all datasets. Despite having less performance drop when testing on data drawn from a later time, linear prompts focus more on non-temporal information and are less sensitive to the given timestamps, according to human evaluations and sensitivity analyses. Meanwhile, textual prompts establish the association between the given timestamps and the output dates, yielding more factual temporal information in the output.