 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models
Nov 30, 2022


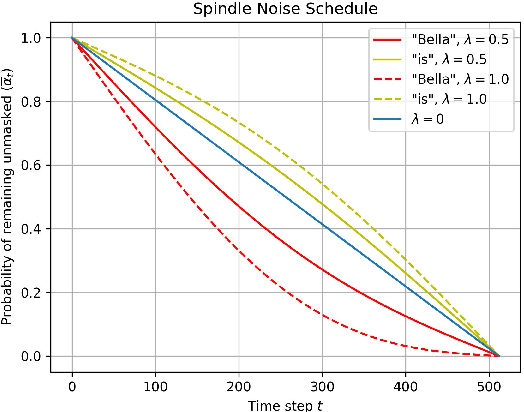
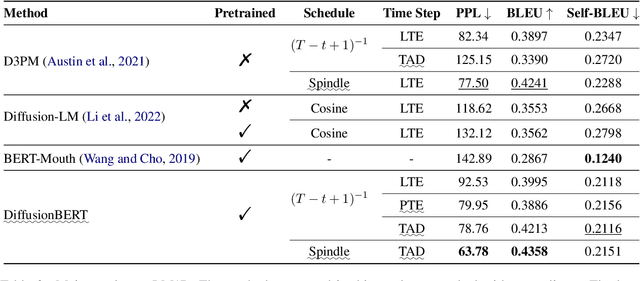
We present DiffusionBERT, a new generative masked language model based on discrete diffusion models. Diffusion models and many pre-trained language models have a shared training objective, i.e., denoising, making it possible to combine the two powerful models and enjoy the best of both worlds. On the one hand, diffusion models offer a promising training strategy that helps improve the generation quality. On the other hand, pre-trained denoising language models (e.g., BERT) can be used as a good initialization that accelerates convergence. We explore training BERT to learn the reverse process of a discrete diffusion process with an absorbing state and elucidate several designs to improve it. First, we propose a new noise schedule for the forward diffusion process that controls the degree of noise added at each step based on the information of each token. Second, we investigate several designs of incorporating the time step into BERT. Experiments on unconditional text generation demonstrate that DiffusionBERT achieves significant improvement over existing diffusion models for text (e.g., D3PM and Diffusion-LM) and previous generative masked language models in terms of perplexity and BLEU score.
Incremental Fourier Neural Operator
Nov 30, 2022
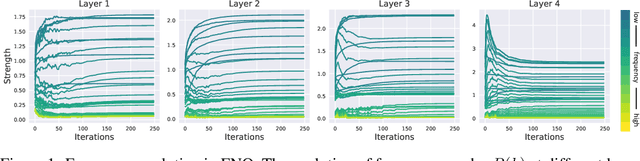

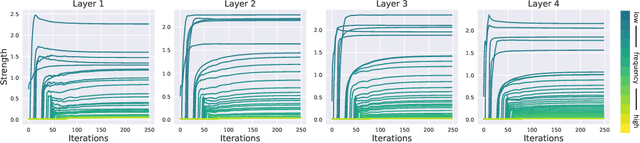
Recently, neural networks have proven their impressive ability to solve partial differential equations (PDEs). Among them, Fourier neural operator (FNO) has shown success in learning solution operators for highly non-linear problems such as turbulence flow. FNO is discretization-invariant, where it can be trained on low-resolution data and generalizes to problems with high-resolution. This property is related to the low-pass filters in FNO, where only a limited number of frequency modes are selected to propagate information. However, it is still a challenge to select an appropriate number of frequency modes and training resolution for different PDEs. Too few frequency modes and low-resolution data hurt generalization, while too many frequency modes and high-resolution data are computationally expensive and lead to over-fitting. To this end, we propose Incremental Fourier Neural Operator (IFNO), which augments both the frequency modes and data resolution incrementally during training. We show that IFNO achieves better generalization (around 15% reduction on testing L2 loss) while reducing the computational cost by 35%, compared to the standard FNO. In addition, we observe that IFNO follows the behavior of implicit regularization in FNO, which explains its excellent generalization ability.
A data set providing synthetic and real-world fisheye video sequences
Nov 30, 2022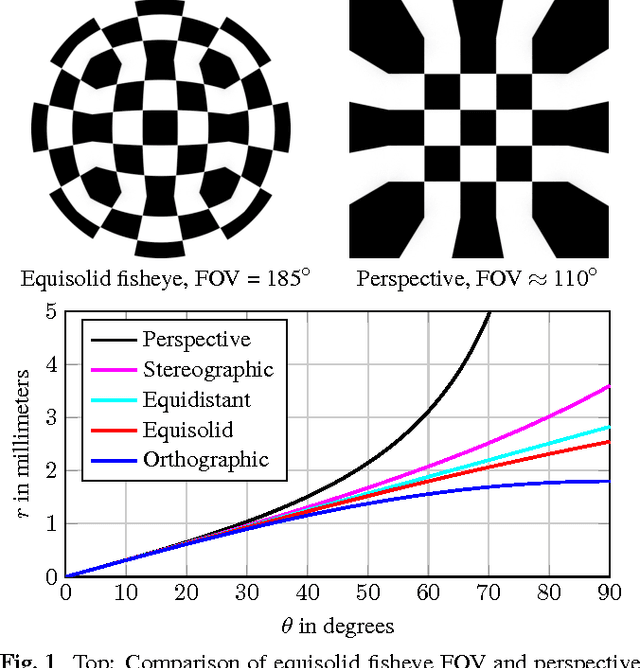
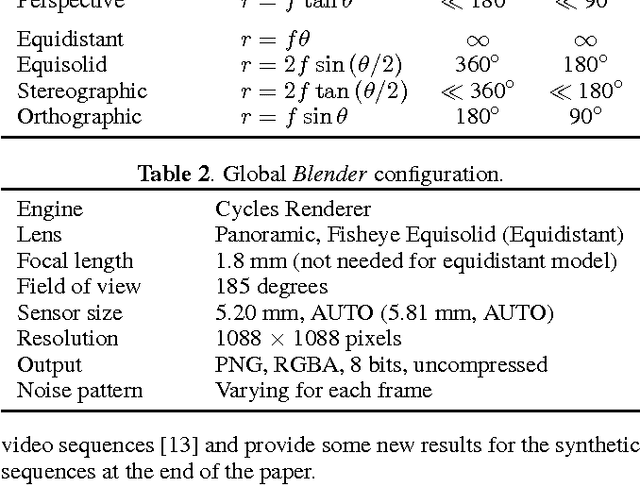

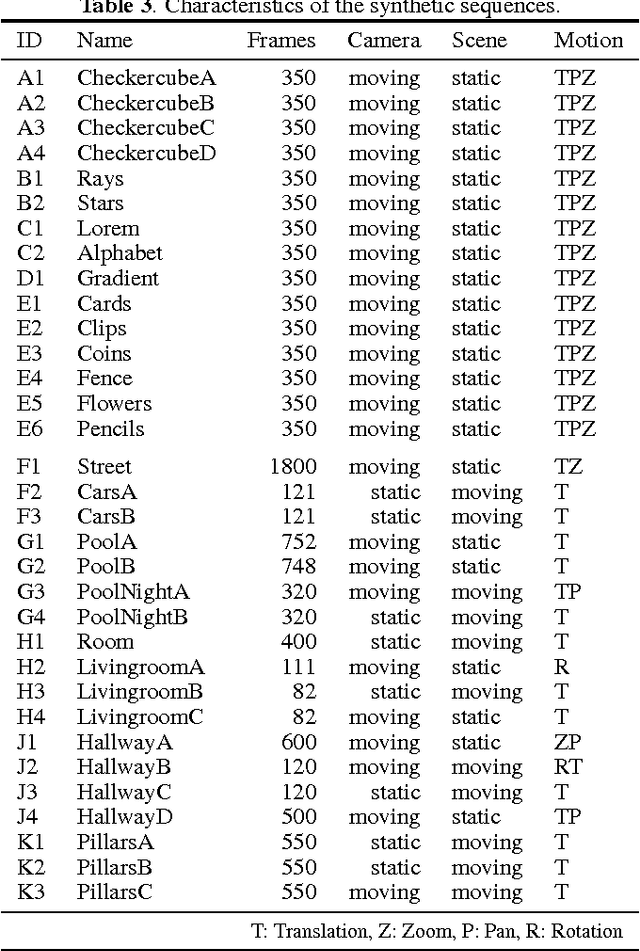
In video surveillance as well as automotive applications, so-called fisheye cameras are often employed to capture a very wide angle of view. As such cameras depend on projections quite different from the classical perspective projection, the resulting fisheye image and video data correspondingly exhibits non-rectilinear image characteristics. Typical image and video processing algorithms, however, are not designed for these fisheye characteristics. To be able to develop and evaluate algorithms specifically adapted to fisheye images and videos, a corresponding test data set is therefore introduced in this paper. The first of those sequences were generated during the authors' own work on motion estimation for fish-eye videos and further sequences have gradually been added to create a more extensive collection. The data set now comprises synthetically generated fisheye sequences, ranging from simple patterns to more complex scenes, as well as fisheye video sequences captured with an actual fisheye camera. For the synthetic sequences, exact information on the lens employed is available, thus facilitating both verification and evaluation of any adapted algorithms. For the real-world sequences, we provide calibration data as well as the settings used during acquisition. The sequences are freely available via www.lms.lnt.de/fisheyedataset/.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022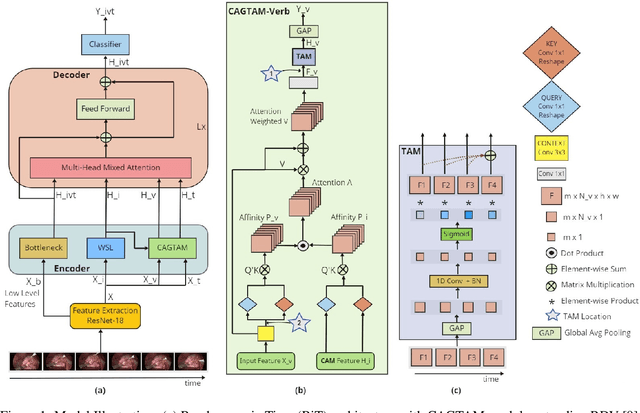

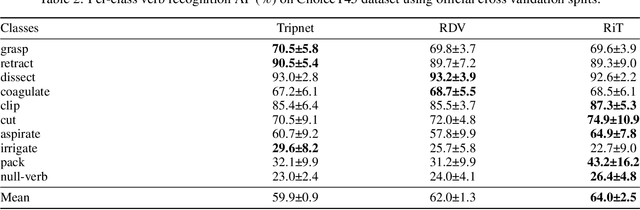
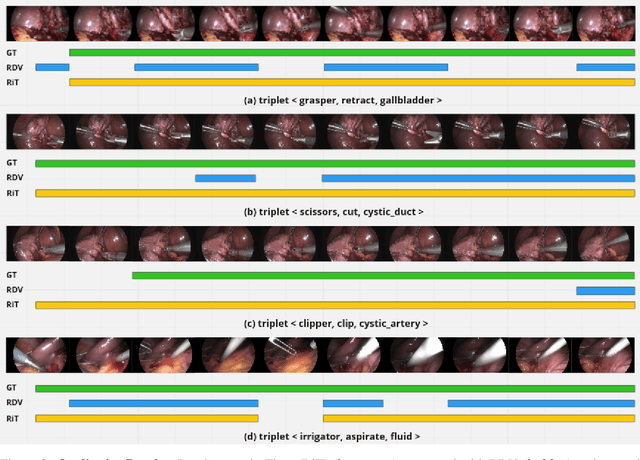
One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
Self-Supervised Feature Learning for Long-Term Metric Visual Localization
Nov 30, 2022
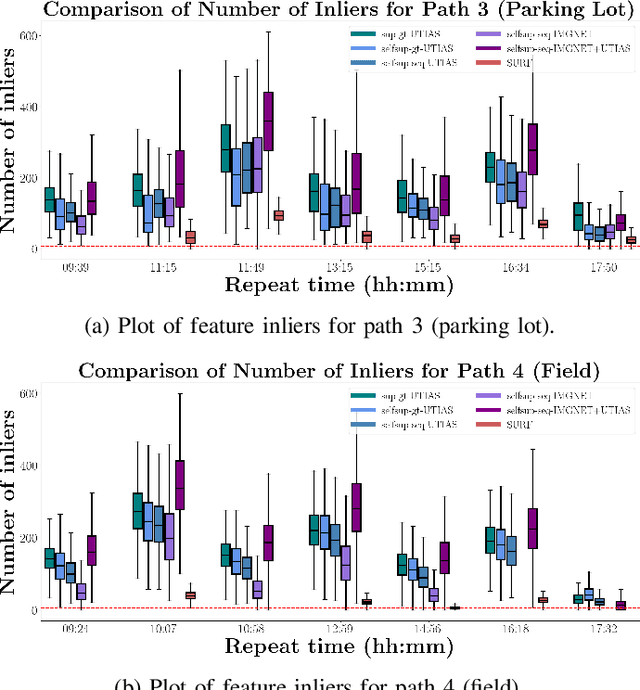
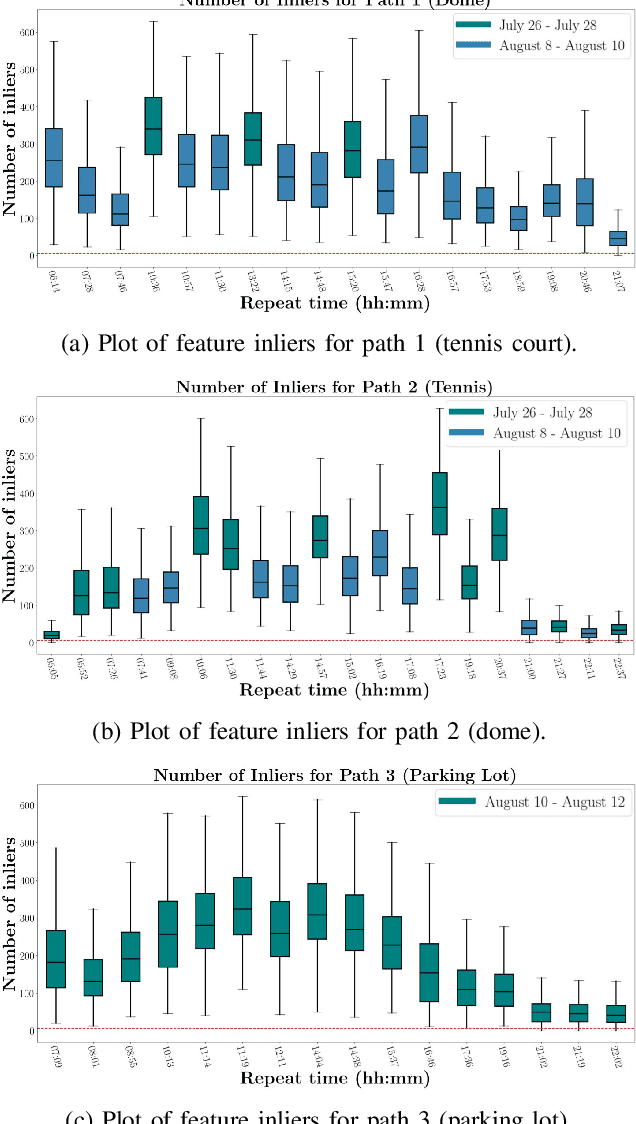
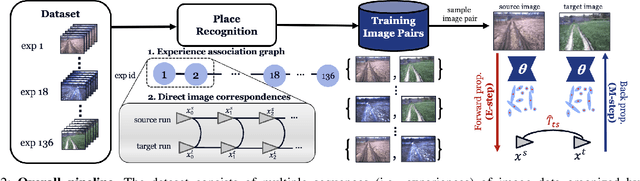
Visual localization is the task of estimating camera pose in a known scene, which is an essential problem in robotics and computer vision. However, long-term visual localization is still a challenge due to the environmental appearance changes caused by lighting and seasons. While techniques exist to address appearance changes using neural networks, these methods typically require ground-truth pose information to generate accurate image correspondences or act as a supervisory signal during training. In this paper, we present a novel self-supervised feature learning framework for metric visual localization. We use a sequence-based image matching algorithm across different sequences of images (i.e., experiences) to generate image correspondences without ground-truth labels. We can then sample image pairs to train a deep neural network that learns sparse features with associated descriptors and scores without ground-truth pose supervision. The learned features can be used together with a classical pose estimator for visual stereo localization. We validate the learned features by integrating with an existing Visual Teach & Repeat pipeline to perform closed-loop localization experiments under different lighting conditions for a total of 22.4 km.
Hierarchically Structured Task-Agnostic Continual Learning
Nov 14, 2022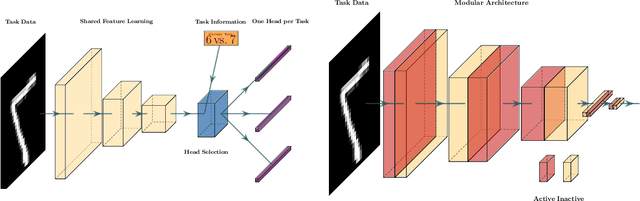
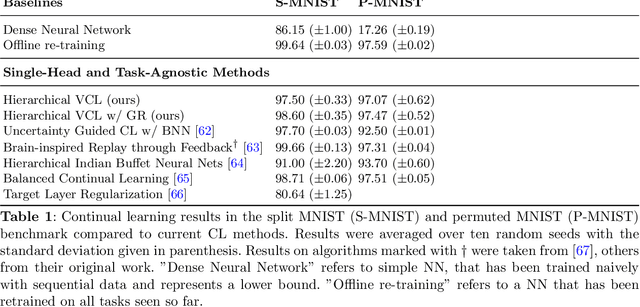
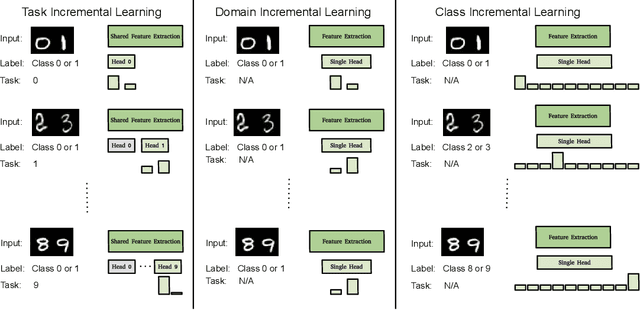
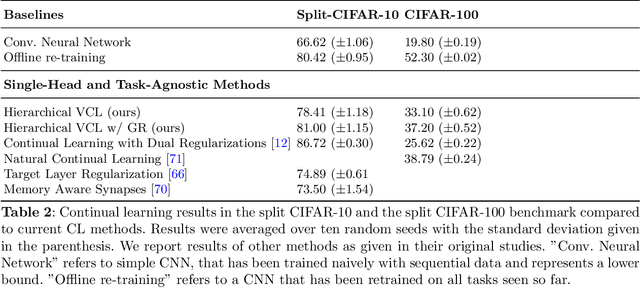
One notable weakness of current machine learning algorithms is the poor ability of models to solve new problems without forgetting previously acquired knowledge. The Continual Learning paradigm has emerged as a protocol to systematically investigate settings where the model sequentially observes samples generated by a series of tasks. In this work, we take a task-agnostic view of continual learning and develop a hierarchical information-theoretic optimality principle that facilitates a trade-off between learning and forgetting. We derive this principle from a Bayesian perspective and show its connections to previous approaches to continual learning. Based on this principle, we propose a neural network layer, called the Mixture-of-Variational-Experts layer, that alleviates forgetting by creating a set of information processing paths through the network which is governed by a gating policy. Equipped with a diverse and specialized set of parameters, each path can be regarded as a distinct sub-network that learns to solve tasks. To improve expert allocation, we introduce diversity objectives, which we evaluate in additional ablation studies. Importantly, our approach can operate in a task-agnostic way, i.e., it does not require task-specific knowledge, as is the case with many existing continual learning algorithms. Due to the general formulation based on generic utility functions, we can apply this optimality principle to a large variety of learning problems, including supervised learning, reinforcement learning, and generative modeling. We demonstrate the competitive performance of our method on continual reinforcement learning and variants of the MNIST, CIFAR-10, and CIFAR-100 datasets.
Variational Bayes for Joint Channel Estimation and Data Detection in Few-Bit Massive MIMO Systems
Dec 04, 2022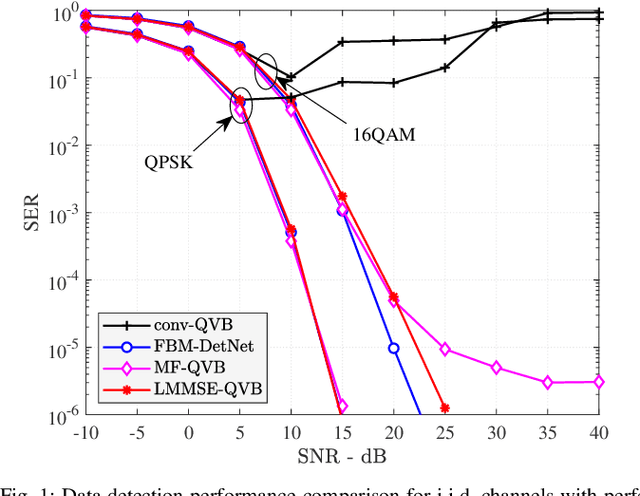
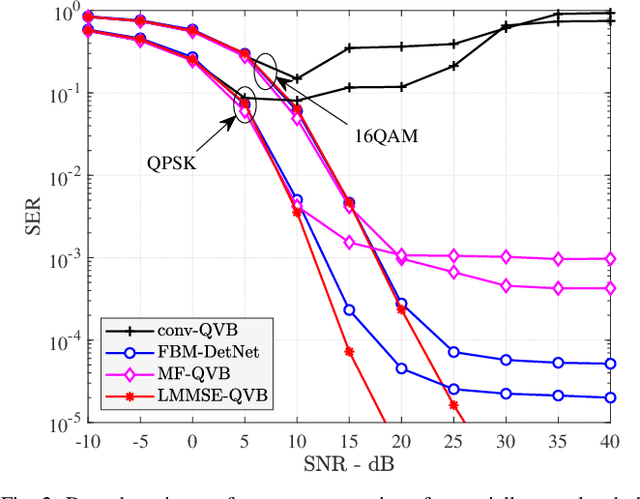
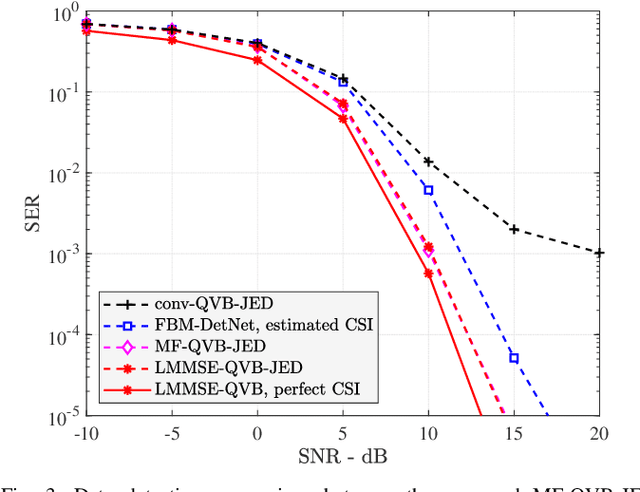
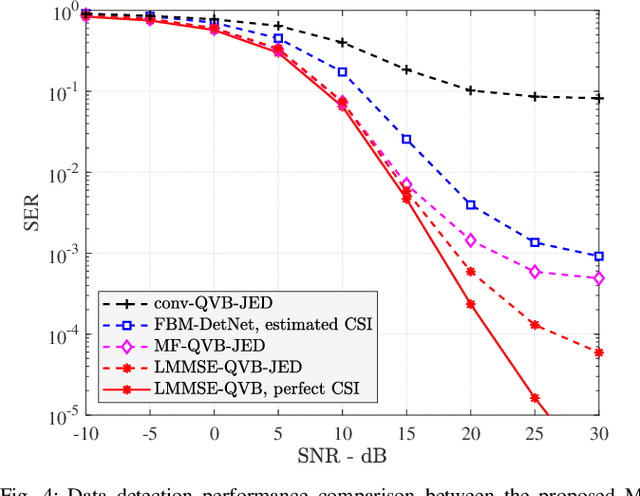
Massive multiple-input multiple-output (MIMO) communications using low-resolution analog-to-digital converters (ADCs) is a promising technology for providing high spectral and energy efficiency with affordable hardware cost and power consumption. However, the use of low-resolution ADCs requires special signal processing methods for channel estimation and data detection since the resulting system is severely non-linear. This paper proposes joint channel estimation and data detection methods for massive MIMO systems with low-resolution ADCs based on the variational Bayes (VB) inference framework. We first derive matched-filter quantized VB (MF-QVB) and linear minimum mean-squared error quantized VB (LMMSE-QVB) detection methods assuming the channel state information (CSI) is available. Then we extend these methods to the joint channel estimation and data detection (JED) problem and propose two methods we refer to as MF-QVB-JED and LMMSE-QVB-JED. Unlike conventional VB-based detection methods that assume knowledge of the second-order statistics of the additive noise, we propose to float the noise variance/covariance matrix as an unknown random variable that is used to account for both the noise and the residual inter-user interference. We also present practical aspects of the QVB framework to improve its implementation stability. Finally, we show via numerical results that the proposed VB-based methods provide robust performance and also significantly outperform existing methods.
Two-Hop Age of Information Scheduling for Multi-UAV Assisted Mobile Edge Computing: FRL vs MADDPG
Jun 19, 2022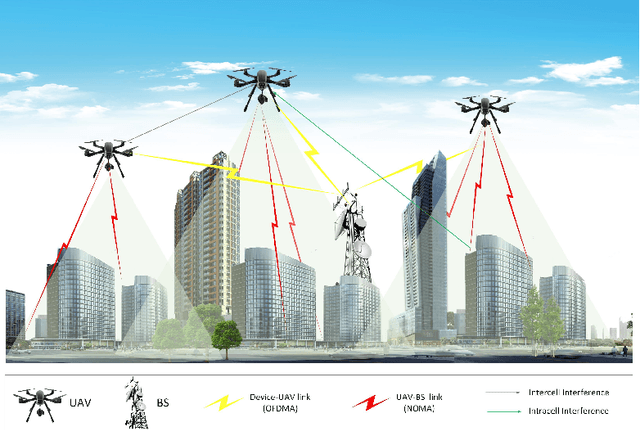
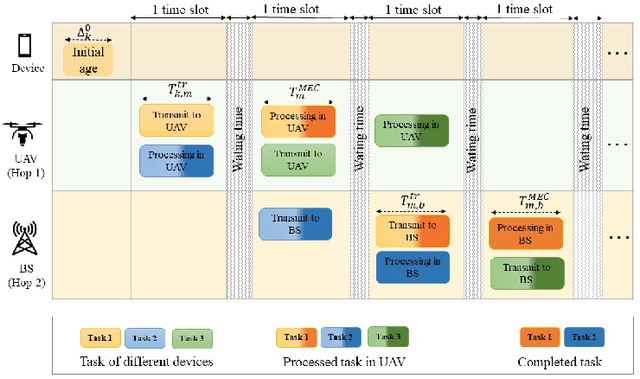
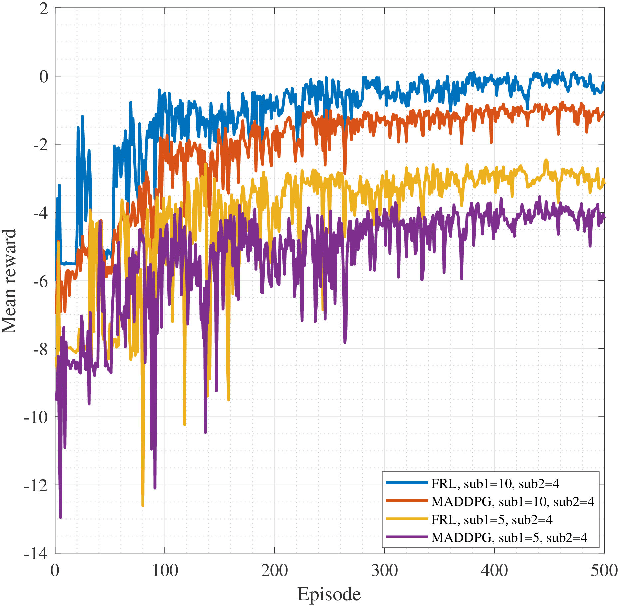
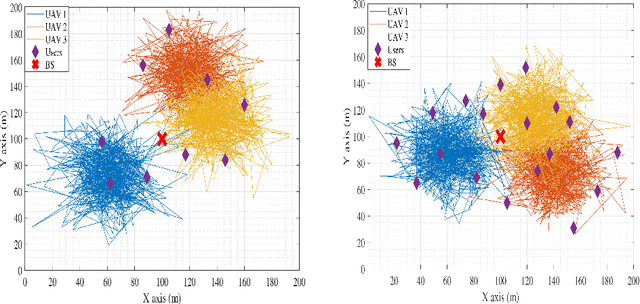
In this work, we adopt the emerging technology of mobile edge computing (MEC) in the Unmanned aerial vehicles (UAVs) for communication-computing systems, to optimize the age of information (AoI) in the network. We assume that tasks are processed jointly on UAVs and BS to enhance edge performance with limited connectivity and computing. Using UAVs and BS jointly with MEC can reduce AoI on the network. To maintain the freshness of the tasks, we formulate the AoI minimization in two-hop communication framework, the first hop at the UAVs and the second hop at the BS. To approach the challenge, we optimize the problem using a deep reinforcement learning (DRL) framework, called federated reinforcement learning (FRL). In our network we have two types of agents with different states and actions but with the same policy. Our FRL enables us to handle the two-step AoI minimization and UAV trajectory problems. In addition, we compare our proposed algorithm, which has a centralized processing unit to update the weights, with fully decentralized multi-agent deep deterministic policy gradient (MADDPG), which enhances the agent's performance. As a result, the suggested algorithm outperforms the MADDPG by about 38\%
Topic Modeling on Clinical Social Work Notes for Exploring Social Determinants of Health Factors
Dec 02, 2022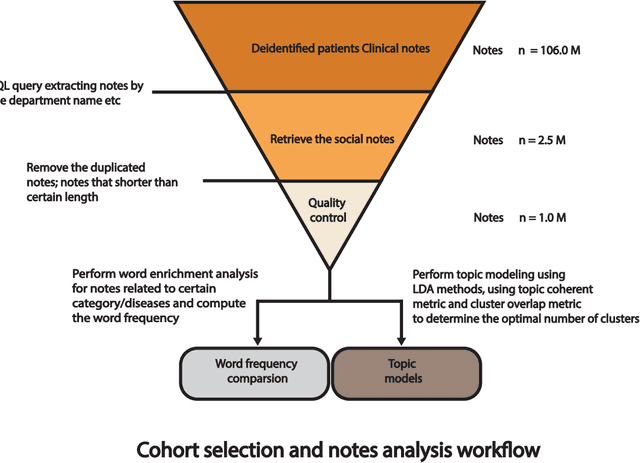
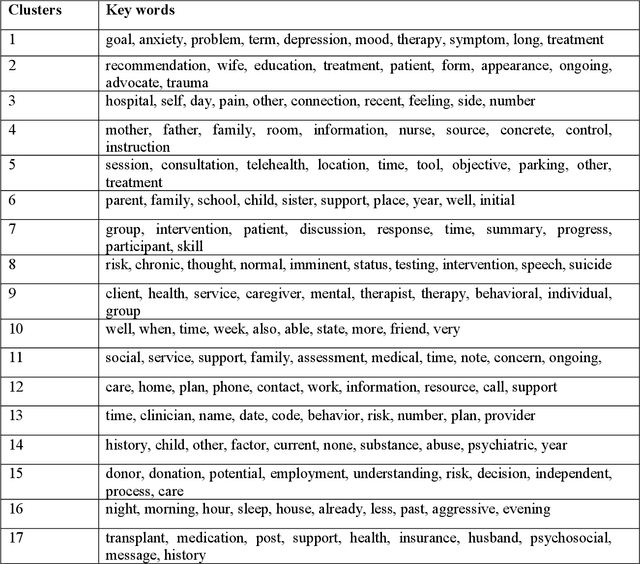
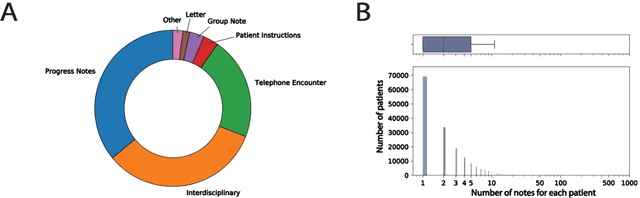
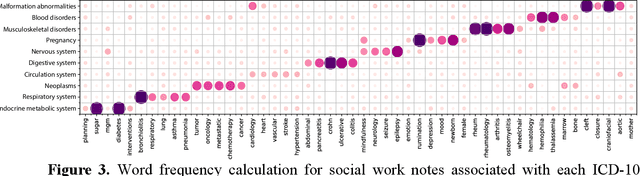
Most research studying social determinants of health (SDoH) has focused on physician notes or structured elements of the electronic medical record (EMR). We hypothesize that clinical notes from social workers, whose role is to ameliorate social and economic factors, might provide a richer source of data on SDoH. We sought to perform topic modeling to identify robust topics of discussion within a large cohort of social work notes. We retrieved a diverse, deidentified corpus of 0.95 million clinical social work notes from 181,644 patients at the University of California, San Francisco. We used word frequency analysis and Latent Dirichlet Allocation (LDA) topic modeling analysis to characterize this corpus and identify potential topics of discussion. Word frequency analysis identified both medical and non-medical terms associated with specific ICD10 chapters. The LDA topic modeling analysis extracted 11 topics related to social determinants of health risk factors including financial status, abuse history, social support, risk of death, and mental health. In addition, the topic modeling approach captured the variation between different types of social work notes and across patients with different types of diseases or conditions. We demonstrated that social work notes contain rich, unique, and otherwise unobtainable information on an individual's SDoH.
Joint Open Knowledge Base Canonicalization and Linking
Dec 02, 2022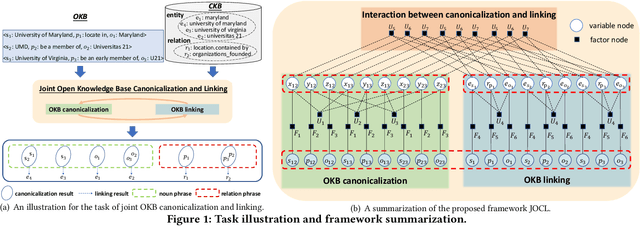
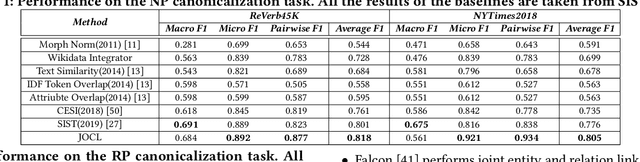
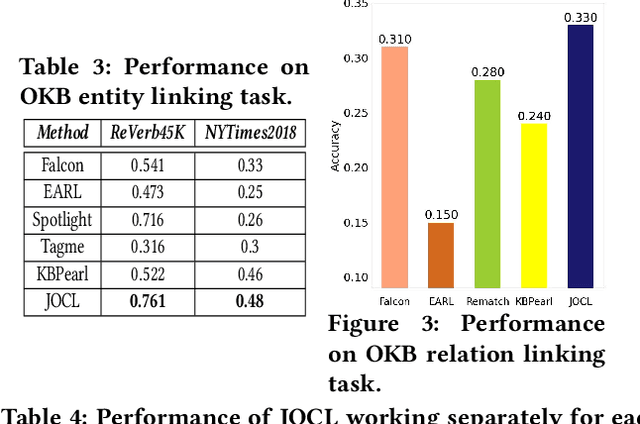
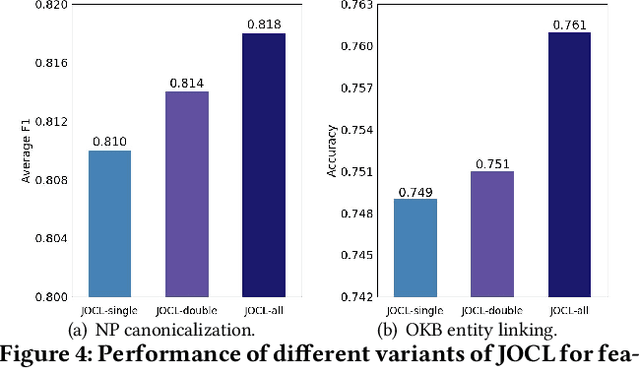
Open Information Extraction (OIE) methods extract a large number of OIE triples (noun phrase, relation phrase, noun phrase) from text, which compose large Open Knowledge Bases (OKBs). However, noun phrases (NPs) and relation phrases (RPs) in OKBs are not canonicalized and often appear in different paraphrased textual variants, which leads to redundant and ambiguous facts. To address this problem, there are two related tasks: OKB canonicalization (i.e., convert NPs and RPs to canonicalized form) and OKB linking (i.e., link NPs and RPs with their corresponding entities and relations in a curated Knowledge Base (e.g., DBPedia). These two tasks are tightly coupled, and one task can benefit significantly from the other. However, they have been studied in isolation so far. In this paper, we explore the task of joint OKB canonicalization and linking for the first time, and propose a novel framework JOCL based on factor graph model to make them reinforce each other. JOCL is flexible enough to combine different signals from both tasks, and able to extend to fit any new signals. A thorough experimental study over two large scale OIE triple data sets shows that our framework outperforms all the baseline methods for the task of OKB canonicalization (OKB linking) in terms of average F1 (accuracy).