 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrated Sensing and Communication in Distributed Antenna Networks
Nov 02, 2022
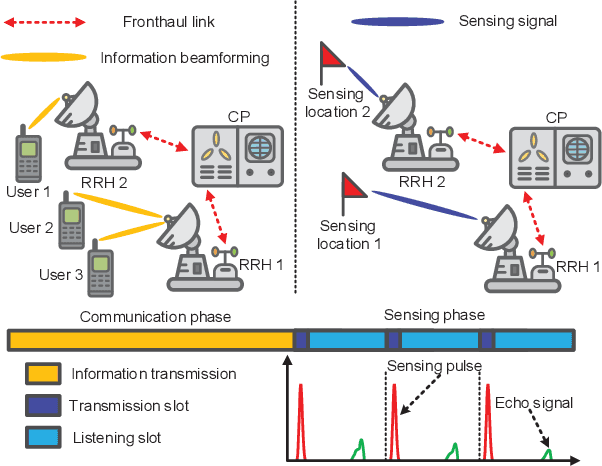
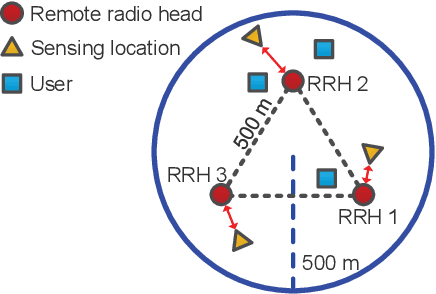
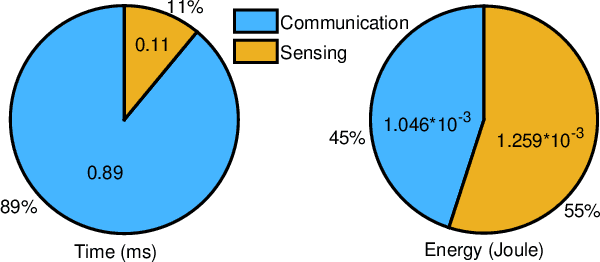
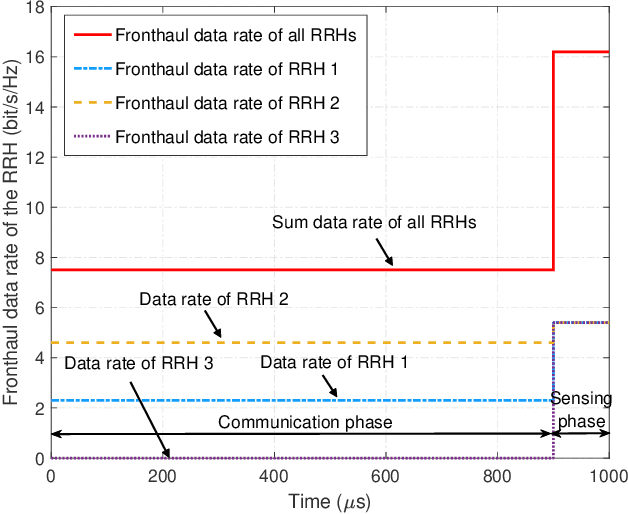
In this paper, we investigate the resource allocation design for integrated sensing and communication (ISAC) in distributed antenna networks (DANs). In particular, coordinated by a central processor (CP), a set of remote radio heads (RRHs) provide communication services to multiple users and sense several target locations within an ISAC frame. To avoid the severe interference between the information transmission and the radar echo, we propose to divide the ISAC frame into a communication phase and a sensing phase. During the communication phase, the data signal is generated at the CP and then conveyed to the RRHs via fronthaul links. As for the sensing phase, based on pre-determined RRH-target pairings, each RRH senses a dedicated target location with a synthesized highly-directional beam and then transfers the samples of the received echo to the CP via its fronthaul link for further processing of the sensing information. Taking into account the limited fronthaul capacity and the quality-of-service requirements of both communication and sensing, we jointly optimize the durations of the two phases, the information beamforming, and the covariance matrix of the sensing signal for minimization of the total energy consumption over a given finite time horizon. To solve the formulated non-convex design problem, we develop a low-complexity alternating optimization algorithm which converges to a suboptimal solution. Simulation results show that the proposed scheme achieves significant energy savings compared to two baseline schemes. Moreover, our results reveal that for efficient ISAC in wireless networks, energy-focused short-duration pulses are favorable for sensing while low-power long-duration signals are preferable for communication.
Scientific and Technological News Recommendation Based on Knowledge Graph with User Perception
Oct 07, 2022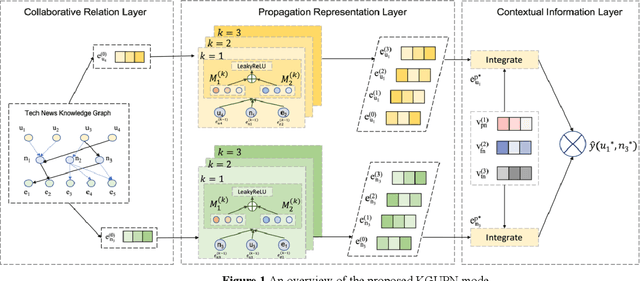
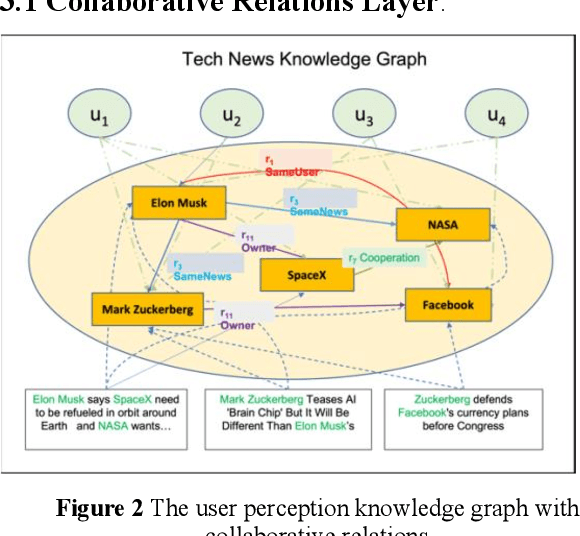
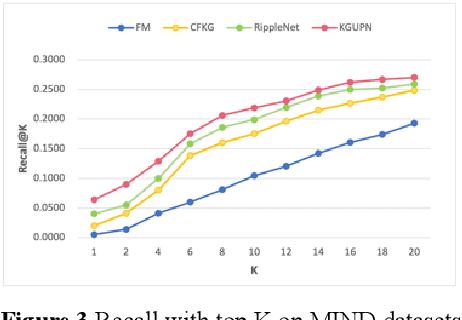
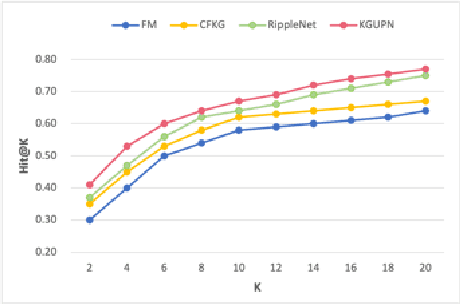
Existing research usually utilizes side information such as social network or item attributes to improve the performance of collaborative filtering-based recommender systems. In this paper, the knowledge graph with user perception is used to acquire the source of side information. We proposed KGUPN to address the limitations of existing embedding-based and path-based knowledge graph-aware recommendation methods, an end-to-end framework that integrates knowledge graph and user awareness into scientific and technological news recommendation systems. KGUPN contains three main layers, which are the propagation representation layer, the contextual information layer and collaborative relation layer. The propagation representation layer improves the representation of an entity by recursively propagating embeddings from its neighbors (which can be users, news, or relationships) in the knowledge graph. The contextual information layer improves the representation of entities by encoding the behavioral information of entities appearing in the news. The collaborative relation layer complements the relationship between entities in the news knowledge graph. Experimental results on real-world datasets show that KGUPN significantly outperforms state-of-the-art baselines in scientific and technological news recommendation.
Two-Hop Age of Information Scheduling for Multi-UAV Assisted Mobile Edge Computing: FRL vs MADDPG
Jun 19, 2022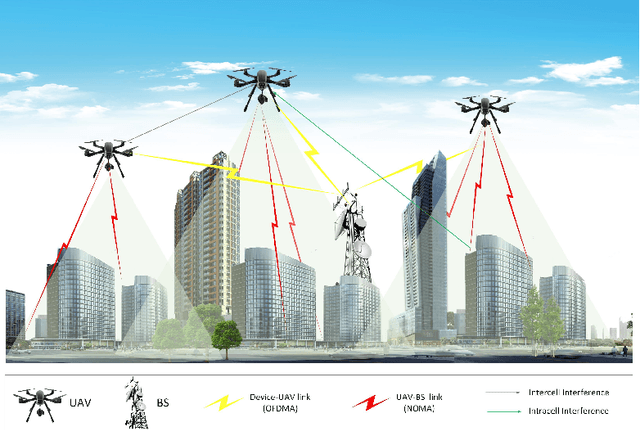
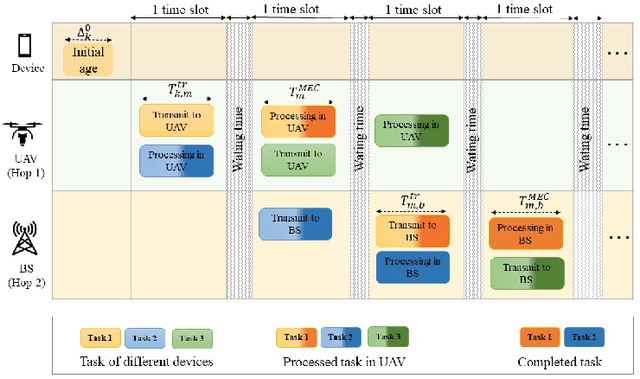
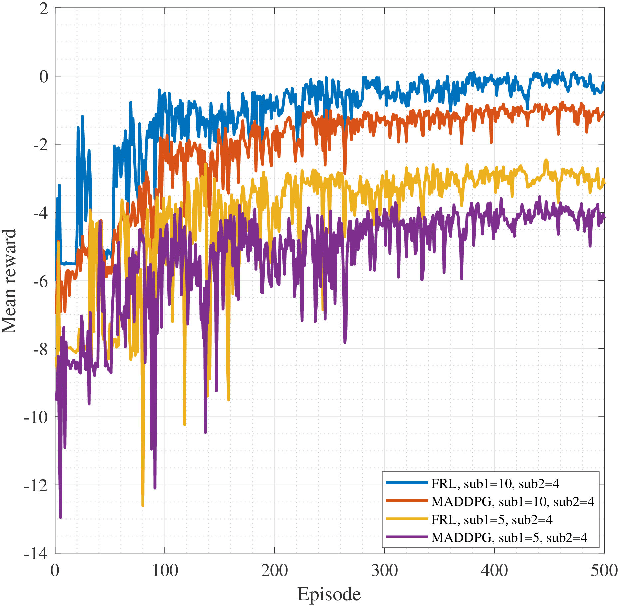
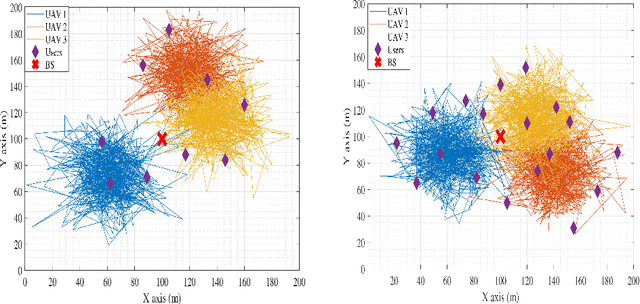
In this work, we adopt the emerging technology of mobile edge computing (MEC) in the Unmanned aerial vehicles (UAVs) for communication-computing systems, to optimize the age of information (AoI) in the network. We assume that tasks are processed jointly on UAVs and BS to enhance edge performance with limited connectivity and computing. Using UAVs and BS jointly with MEC can reduce AoI on the network. To maintain the freshness of the tasks, we formulate the AoI minimization in two-hop communication framework, the first hop at the UAVs and the second hop at the BS. To approach the challenge, we optimize the problem using a deep reinforcement learning (DRL) framework, called federated reinforcement learning (FRL). In our network we have two types of agents with different states and actions but with the same policy. Our FRL enables us to handle the two-step AoI minimization and UAV trajectory problems. In addition, we compare our proposed algorithm, which has a centralized processing unit to update the weights, with fully decentralized multi-agent deep deterministic policy gradient (MADDPG), which enhances the agent's performance. As a result, the suggested algorithm outperforms the MADDPG by about 38\%
Public Information Representation for Adversarial Team Games
Jan 25, 2022
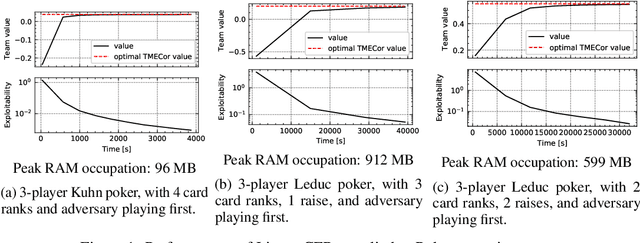
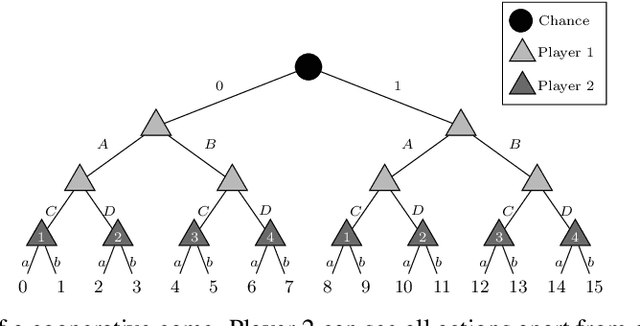
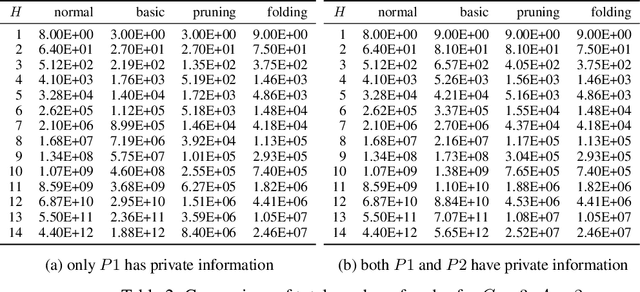
The peculiarity of adversarial team games resides in the asymmetric information available to the team members during the play, which makes the equilibrium computation problem hard even with zero-sum payoffs. The algorithms available in the literature work with implicit representations of the strategy space and mainly resort to Linear Programming and column generation techniques to enlarge incrementally the strategy space. Such representations prevent the adoption of standard tools such as abstraction generation, game solving, and subgame solving, which demonstrated to be crucial when solving huge, real-world two-player zero-sum games. Differently from these works, we answer the question of whether there is any suitable game representation enabling the adoption of those tools. In particular, our algorithms convert a sequential team game with adversaries to a classical two-player zero-sum game. In this converted game, the team is transformed into a single coordinator player who only knows information common to the whole team and prescribes to the players an action for any possible private state. Interestingly, we show that our game is more expressive than the original extensive-form game as any state/action abstraction of the extensive-form game can be captured by our representation, while the reverse does not hold. Due to the NP-hard nature of the problem, the resulting Public Team game may be exponentially larger than the original one. To limit this explosion, we provide three algorithms, each returning an information-lossless abstraction that dramatically reduces the size of the tree. These abstractions can be produced without generating the original game tree. Finally, we show the effectiveness of the proposed approach by presenting experimental results on Kuhn and Leduc Poker games, obtained by applying state-of-art algorithms for two-player zero-sum games on the converted games
Progressive Learning without Forgetting
Nov 28, 2022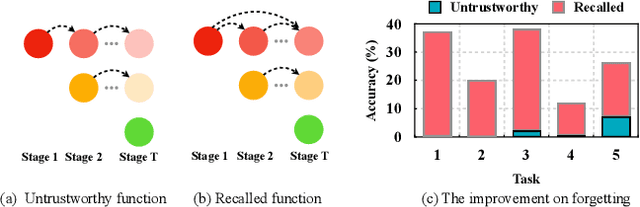
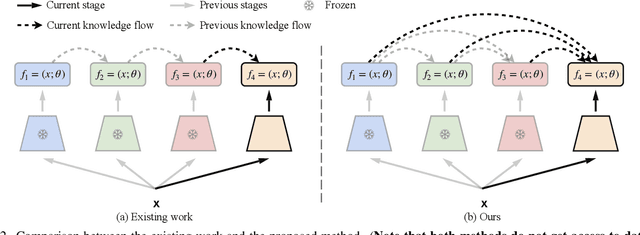
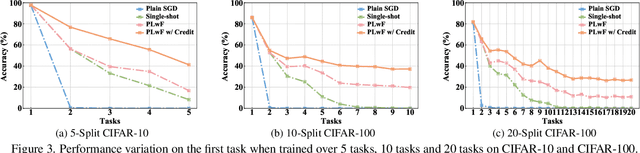
Learning from changing tasks and sequential experience without forgetting the obtained knowledge is a challenging problem for artificial neural networks. In this work, we focus on two challenging problems in the paradigm of Continual Learning (CL) without involving any old data: (i) the accumulation of catastrophic forgetting caused by the gradually fading knowledge space from which the model learns the previous knowledge; (ii) the uncontrolled tug-of-war dynamics to balance the stability and plasticity during the learning of new tasks. In order to tackle these problems, we present Progressive Learning without Forgetting (PLwF) and a credit assignment regime in the optimizer. PLwF densely introduces model functions from previous tasks to construct a knowledge space such that it contains the most reliable knowledge on each task and the distribution information of different tasks, while credit assignment controls the tug-of-war dynamics by removing gradient conflict through projection. Extensive ablative experiments demonstrate the effectiveness of PLwF and credit assignment. In comparison with other CL methods, we report notably better results even without relying on any raw data.
FLAIR #1: semantic segmentation and domain adaptation dataset
Nov 28, 2022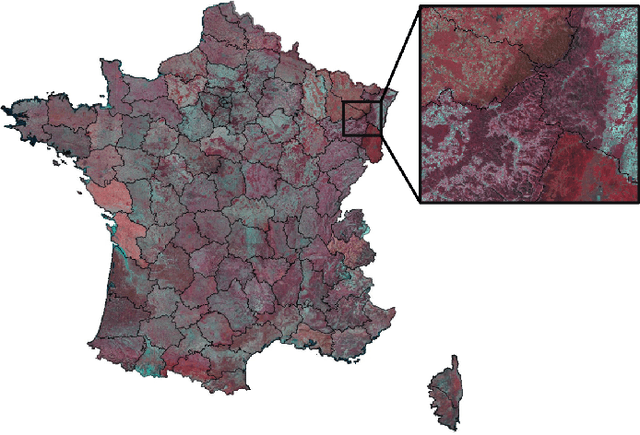
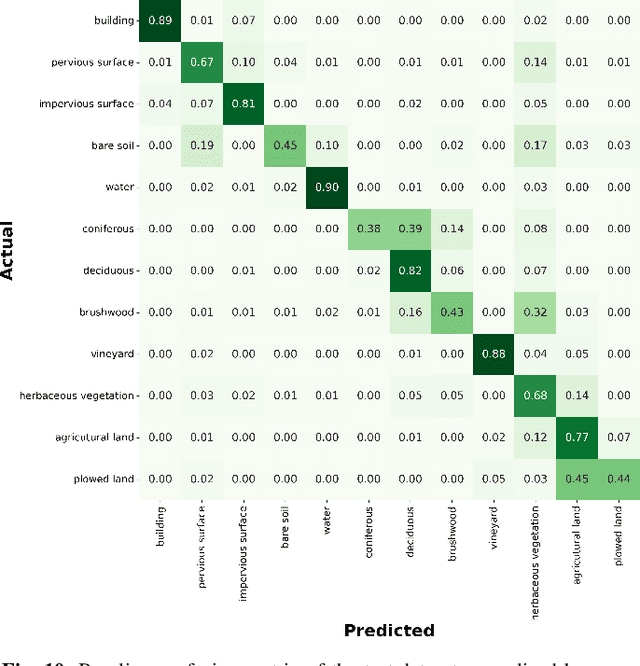
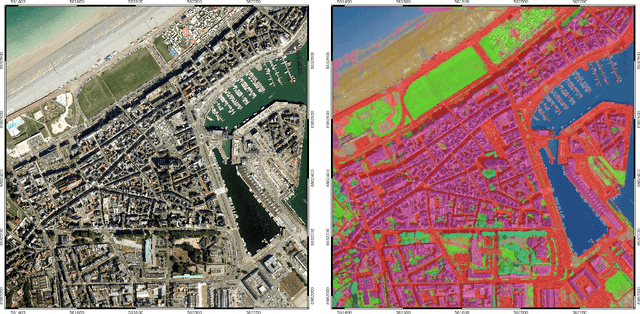
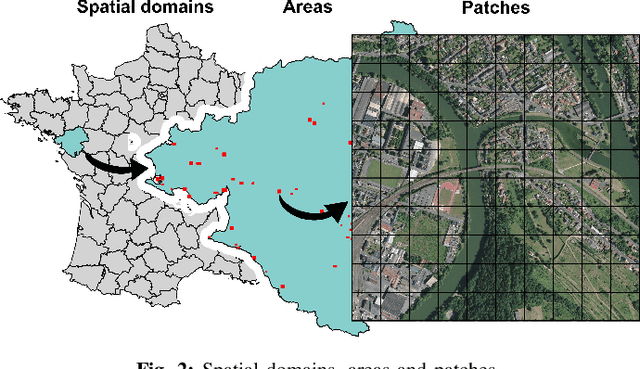
The French National Institute of Geographical and Forest Information (IGN) has the mission to document and measure land-cover on French territory and provides referential geographical datasets, including high-resolution aerial images and topographic maps. The monitoring of land-cover plays a crucial role in land management and planning initiatives, which can have significant socio-economic and environmental impact. Together with remote sensing technologies, artificial intelligence (IA) promises to become a powerful tool in determining land-cover and its evolution. IGN is currently exploring the potential of IA in the production of high-resolution land cover maps. Notably, deep learning methods are employed to obtain a semantic segmentation of aerial images. However, territories as large as France imply heterogeneous contexts: variations in landscapes and image acquisition make it challenging to provide uniform, reliable and accurate results across all of France. The FLAIR-one dataset presented is part of the dataset currently used at IGN to establish the French national reference land cover map "Occupation du sol \`a grande \'echelle" (OCS- GE).
Interactive Visual Feature Search
Nov 28, 2022
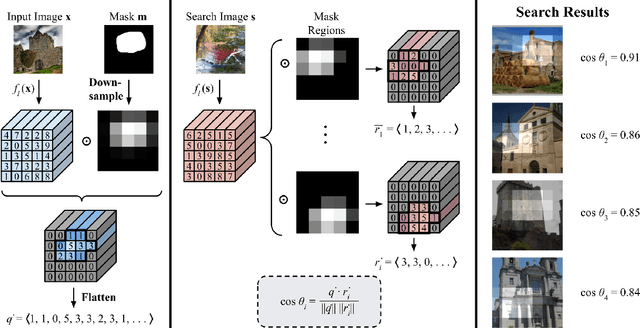


Many visualization techniques have been created to help explain the behavior of convolutional neural networks (CNNs), but they largely consist of static diagrams that convey limited information. Interactive visualizations can provide more rich insights and allow users to more easily explore a model's behavior; however, they are typically not easily reusable and are specific to a particular model. We introduce Visual Feature Search, a novel interactive visualization that is generalizable to any CNN and can easily be incorporated into a researcher's workflow. Our tool allows a user to highlight an image region and search for images from a given dataset with the most similar CNN features. It supports searching through large image datasets with an efficient cache-based search implementation. We demonstrate how our tool elucidates different aspects of model behavior by performing experiments on supervised, self-supervised, and human-edited CNNs. We also release a portable Python library and several IPython notebooks to enable researchers to easily use our tool in their own experiments. Our code can be found at https://github.com/lookingglasslab/VisualFeatureSearch.
Deep Surface Reconstruction from Point Clouds with Visibility Information
Feb 03, 2022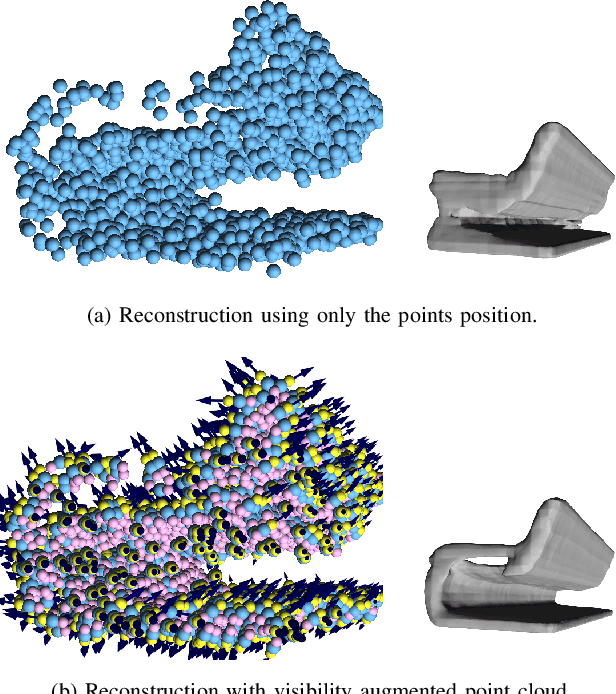


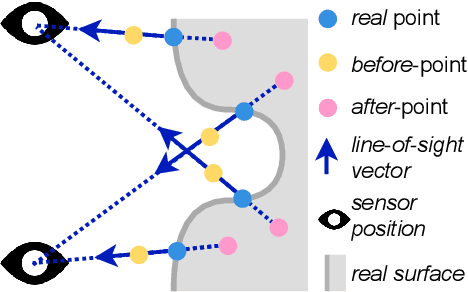
Most current neural networks for reconstructing surfaces from point clouds ignore sensor poses and only operate on raw point locations. Sensor visibility, however, holds meaningful information regarding space occupancy and surface orientation. In this paper, we present two simple ways to augment raw point clouds with visibility information, so it can directly be leveraged by surface reconstruction networks with minimal adaptation. Our proposed modifications consistently improve the accuracy of generated surfaces as well as the generalization ability of the networks to unseen shape domains. Our code and data is available at https://github.com/raphaelsulzer/dsrv-data.
A Unified Multimodal De- and Re-coupling Framework for RGB-D Motion Recognition
Nov 16, 2022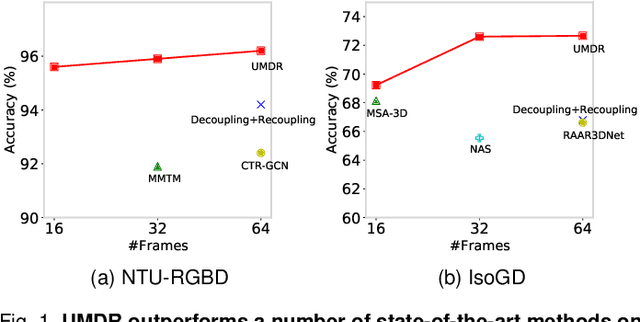
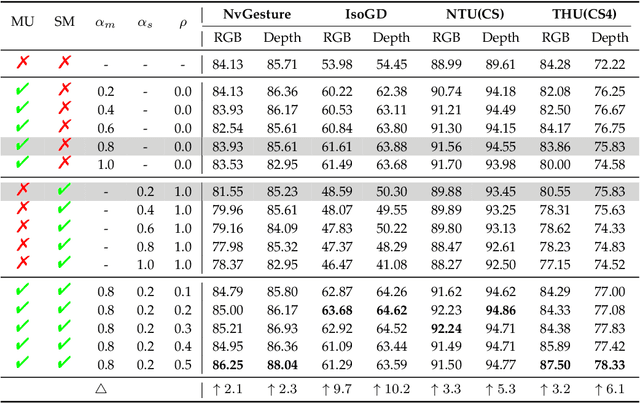

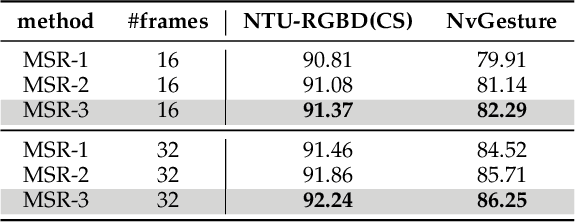
Motion recognition is a promising direction in computer vision, but the training of video classification models is much harder than images due to insufficient data and considerable parameters. To get around this, some works strive to explore multimodal cues from RGB-D data. Although improving motion recognition to some extent, these methods still face sub-optimal situations in the following aspects: (i) Data augmentation, i.e., the scale of the RGB-D datasets is still limited, and few efforts have been made to explore novel data augmentation strategies for videos; (ii) Optimization mechanism, i.e., the tightly space-time-entangled network structure brings more challenges to spatiotemporal information modeling; And (iii) cross-modal knowledge fusion, i.e., the high similarity between multimodal representations caused to insufficient late fusion. To alleviate these drawbacks, we propose to improve RGB-D-based motion recognition both from data and algorithm perspectives in this paper. In more detail, firstly, we introduce a novel video data augmentation method dubbed ShuffleMix, which acts as a supplement to MixUp, to provide additional temporal regularization for motion recognition. Secondly, a Unified Multimodal De-coupling and multi-stage Re-coupling framework, termed UMDR, is proposed for video representation learning. Finally, a novel cross-modal Complement Feature Catcher (CFCer) is explored to mine potential commonalities features in multimodal information as the auxiliary fusion stream, to improve the late fusion results. The seamless combination of these novel designs forms a robust spatiotemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Specifically, UMDR achieves unprecedented improvements of +4.5% on the Chalearn IsoGD dataset.Our code is available at https://github.com/zhoubenjia/MotionRGBD-PAMI.
Tapping the Potential of Coherence and Syntactic Features in Neural Models for Automatic Essay Scoring
Nov 24, 2022
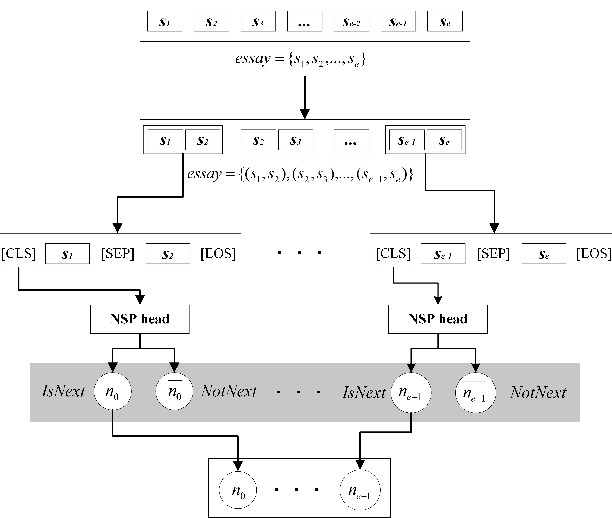
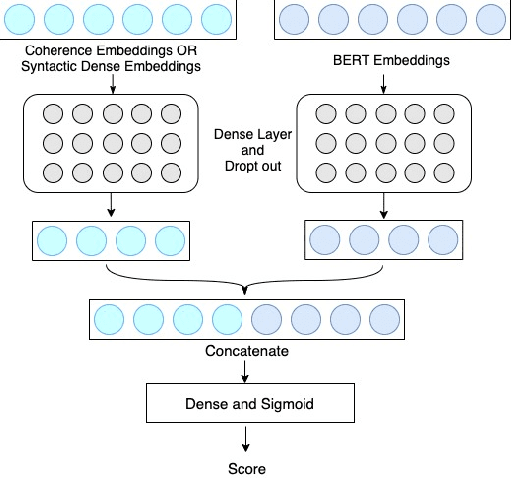
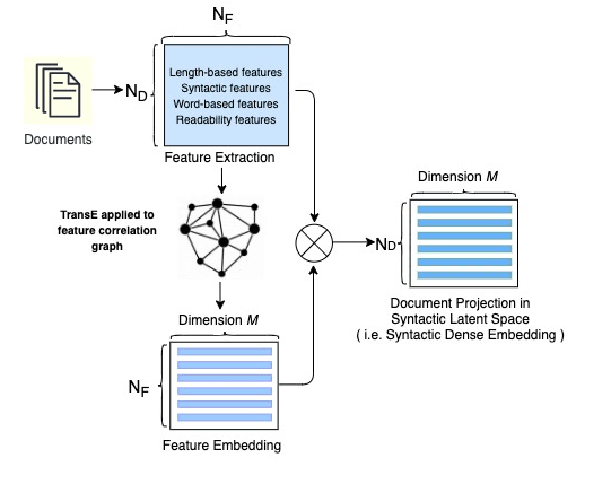
In the prompt-specific holistic score prediction task for Automatic Essay Scoring, the general approaches include pre-trained neural model, coherence model, and hybrid model that incorporate syntactic features with neural model. In this paper, we propose a novel approach to extract and represent essay coherence features with prompt-learning NSP that shows to match the state-of-the-art AES coherence model, and achieves the best performance for long essays. We apply syntactic feature dense embedding to augment BERT-based model and achieve the best performance for hybrid methodology for AES. In addition, we explore various ideas to combine coherence, syntactic information and semantic embeddings, which no previous study has done before. Our combined model also performs better than the SOTA available for combined model, even though it does not outperform our syntactic enhanced neural model. We further offer analyses that can be useful for future study.