 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GoSum: Extractive Summarization of Long Documents by Reinforcement Learning and Graph Organized discourse state
Nov 18, 2022
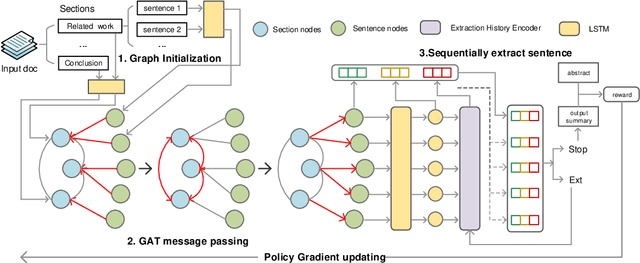

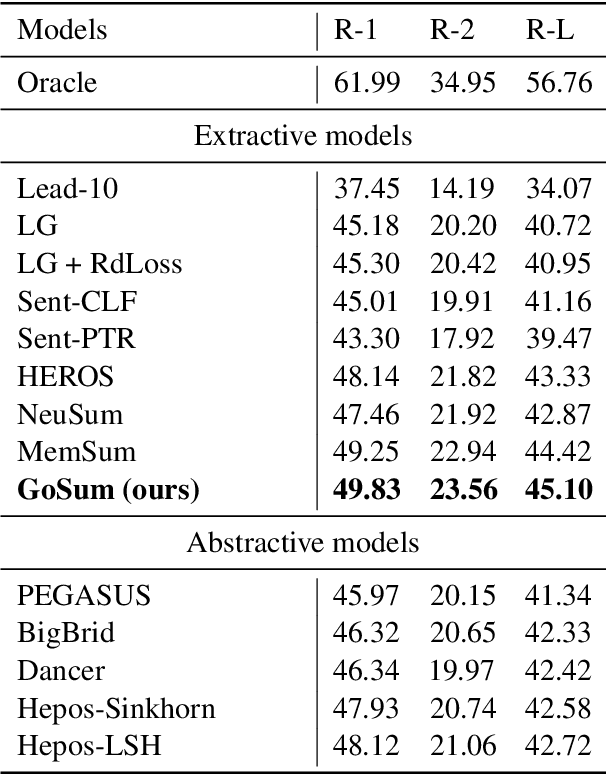
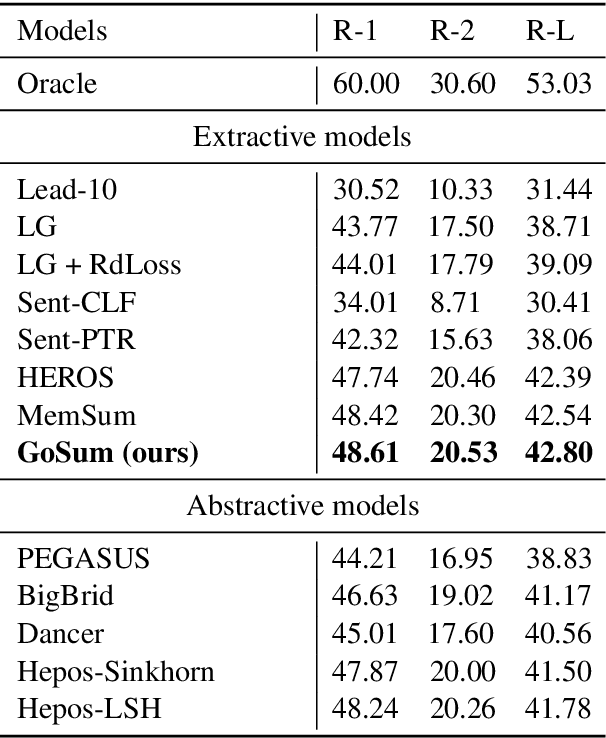
Handling long texts with structural information and excluding redundancy between summary sentences are essential in extractive document summarization. In this work, we propose GoSum, a novel reinforcement-learning-based extractive model for long-paper summarization. GoSum encodes states by building a heterogeneous graph from different discourse levels for each input document. We evaluate the model on two datasets of scientific articles summarization: PubMed and arXiv where it outperforms all extractive summarization models and most of the strong abstractive baselines.
The Transitive Information Theory and its Application to Deep Generative Models
Mar 28, 2022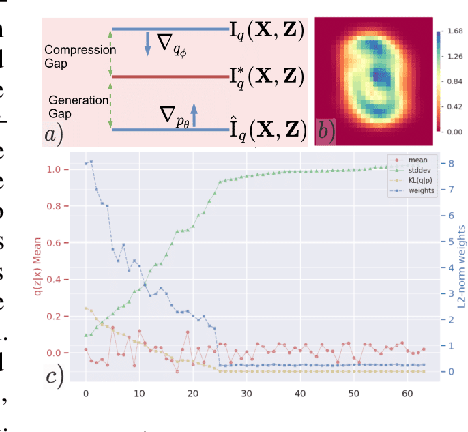

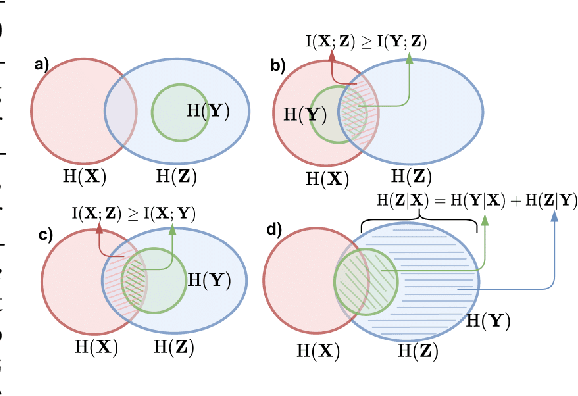
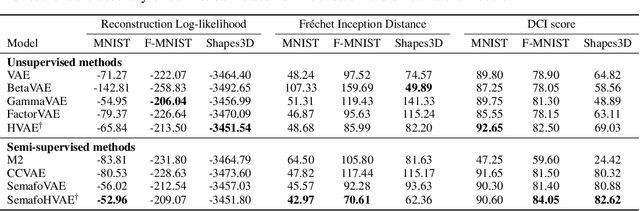
Paradoxically, a Variational Autoencoder (VAE) could be pushed in two opposite directions, utilizing powerful decoder model for generating realistic images but collapsing the learned representation, or increasing regularization coefficient for disentangling representation but ultimately generating blurry examples. Existing methods narrow the issues to the rate-distortion trade-off between compression and reconstruction. We argue that a good reconstruction model does learn high capacity latents that encode more details, however, its use is hindered by two major issues: the prior is random noise which is completely detached from the posterior and allow no controllability in the generation; mean-field variational inference doesn't enforce hierarchy structure which makes the task of recombining those units into plausible novel output infeasible. As a result, we develop a system that learns a hierarchy of disentangled representation together with a mechanism for recombining the learned representation for generalization. This is achieved by introducing a minimal amount of inductive bias to learn controllable prior for the VAE. The idea is supported by here developed transitive information theory, that is, the mutual information between two target variables could alternately be maximized through the mutual information to the third variable, thus bypassing the rate-distortion bottleneck in VAE design. In particular, we show that our model, named SemafoVAE (inspired by the similar concept in computer science), could generate high-quality examples in a controllable manner, perform smooth traversals of the disentangled factors and intervention at a different level of representation hierarchy.
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022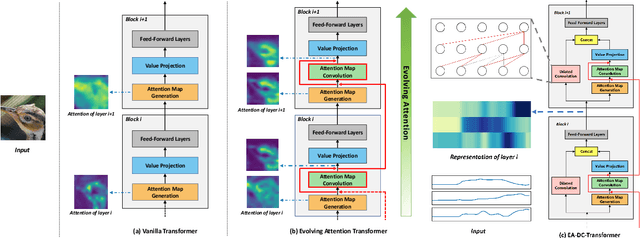

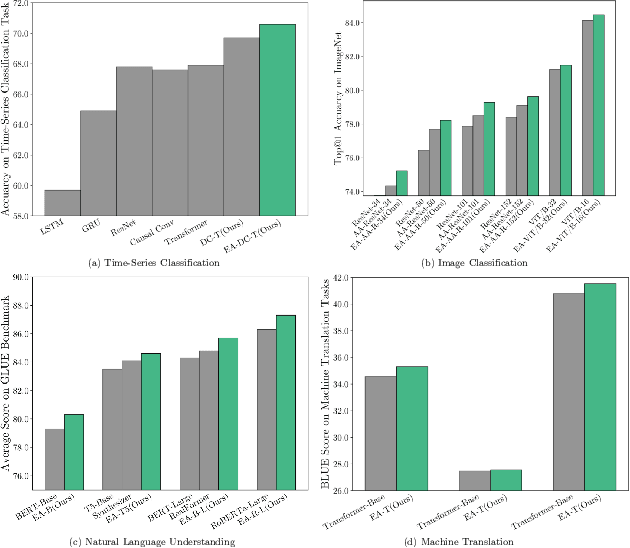
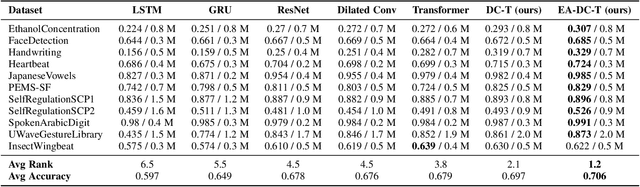
Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
Fluid Antenna with Linear MMSE Channel Estimation for Large-Scale Cellular Networks
Dec 16, 2022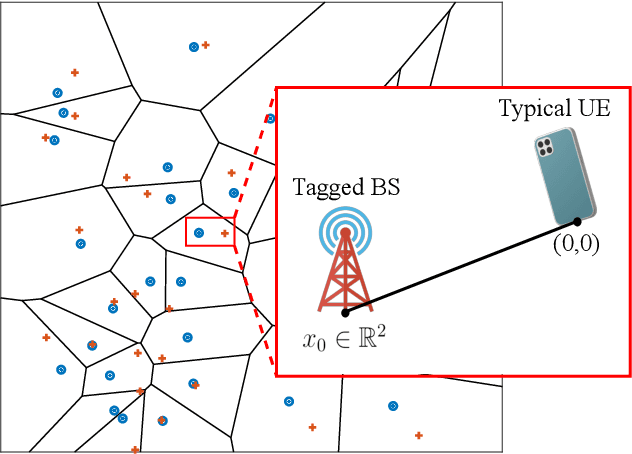
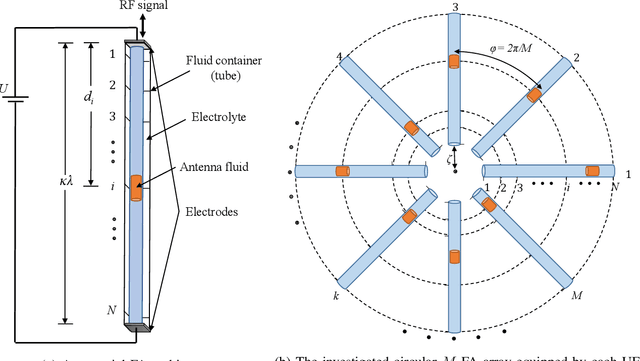
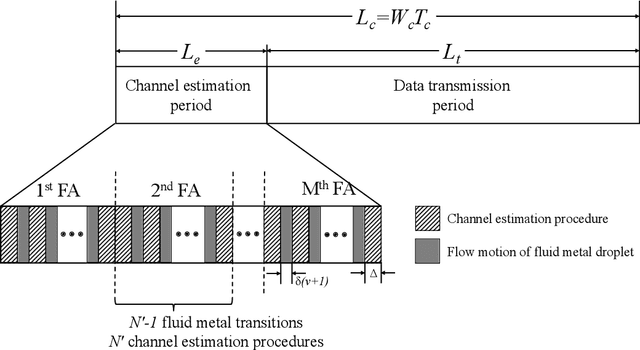
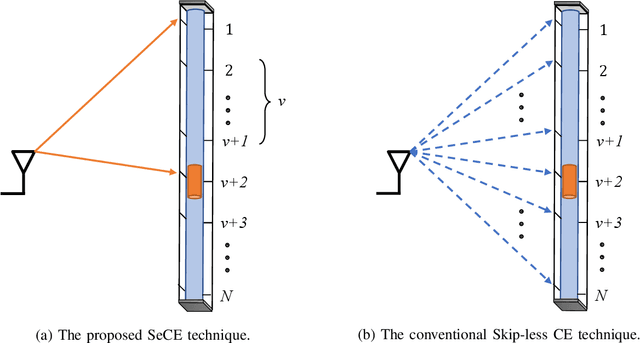
The concept of reconfigurable fluid antennas (FA) is a potential and promising solution to enhance the spectral efficiency of wireless communication networks. Despite their many advantages, FA-enabled communications have limitations as they require an enormous amount of spectral resources in order to select the most desirable position of the radiating element from a large number of prescribed locations. In this paper, we present an analytical framework for the outage performance of large-scale FA-enabled communications, where all user equipments (UEs) employ circular multi-FA array. In contrast to existing studies, which assume perfect channel state information, the developed framework accurately captures the channel estimation errors on the performance of the considered network deployments. In particular, we focus on the limited coherence interval scenario, where a novel sequential linear minimum mean-squared error (LMMSE)-based channel estimation method is performed for only a very small number of FA ports. Next, for the communication of each BS with its associated UE, a low-complexity port-selection technique is employed, where the port that provides the highest signal-to-interference-plus-noise-ratio is selected among the ports that are estimated to provide the strongest channel from each FA. By using stochastic geometry tools, we derive both analytical and closed-form expressions for the outage probability, highlighting the impact of channel estimation on the performance of FA-based UEs. Our results reveal the trade-off imposed between improving the network's performance and reducing the channel estimation quality, indicating new insights for the design of FA-enabled communications.
It is not "accuracy vs. explainability" -- we need both for trustworthy AI systems
Dec 16, 2022We are witnessing the emergence of an AI economy and society where AI technologies are increasingly impacting health care, business, transportation and many aspects of everyday life. Many successes have been reported where AI systems even surpassed the accuracy of human experts. However, AI systems may produce errors, can exhibit bias, may be sensitive to noise in the data, and often lack technical and judicial transparency resulting in reduction in trust and challenges in their adoption. These recent shortcomings and concerns have been documented in scientific but also in general press such as accidents with self driving cars, biases in healthcare, hiring and face recognition systems for people of color, seemingly correct medical decisions later found to be made due to wrong reasons etc. This resulted in emergence of many government and regulatory initiatives requiring trustworthy and ethical AI to provide accuracy and robustness, some form of explainability, human control and oversight, elimination of bias, judicial transparency and safety. The challenges in delivery of trustworthy AI systems motivated intense research on explainable AI systems (XAI). Aim of XAI is to provide human understandable information of how AI systems make their decisions. In this paper we first briefly summarize current XAI work and then challenge the recent arguments of accuracy vs. explainability for being mutually exclusive and being focused only on deep learning. We then present our recommendations for the use of XAI in full lifecycle of high stakes trustworthy AI systems delivery, e.g. development, validation and certification, and trustworthy production and maintenance.
ADIR: Adaptive Diffusion for Image Reconstruction
Dec 06, 2022
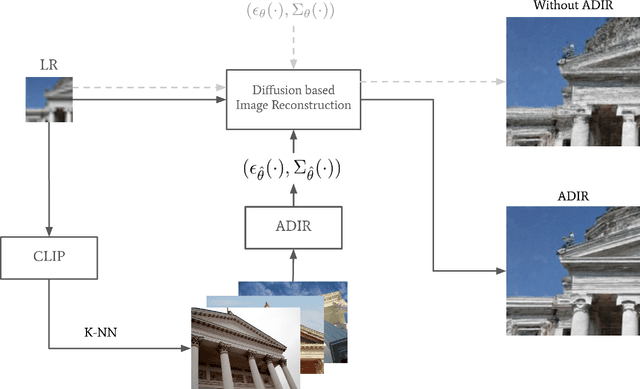


In recent years, denoising diffusion models have demonstrated outstanding image generation performance. The information on natural images captured by these models is useful for many image reconstruction applications, where the task is to restore a clean image from its degraded observations. In this work, we propose a conditional sampling scheme that exploits the prior learned by diffusion models while retaining agreement with the observations. We then combine it with a novel approach for adapting pretrained diffusion denoising networks to their input. We examine two adaption strategies: the first uses only the degraded image, while the second, which we advocate, is performed using images that are ``nearest neighbors'' of the degraded image, retrieved from a diverse dataset using an off-the-shelf visual-language model. To evaluate our method, we test it on two state-of-the-art publicly available diffusion models, Stable Diffusion and Guided Diffusion. We show that our proposed `adaptive diffusion for image reconstruction' (ADIR) approach achieves a significant improvement in the super-resolution, deblurring, and text-based editing tasks.
IncepFormer: Efficient Inception Transformer with Pyramid Pooling for Semantic Segmentation
Dec 06, 2022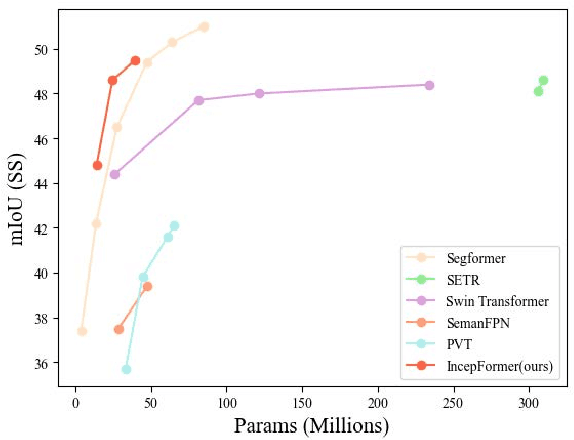
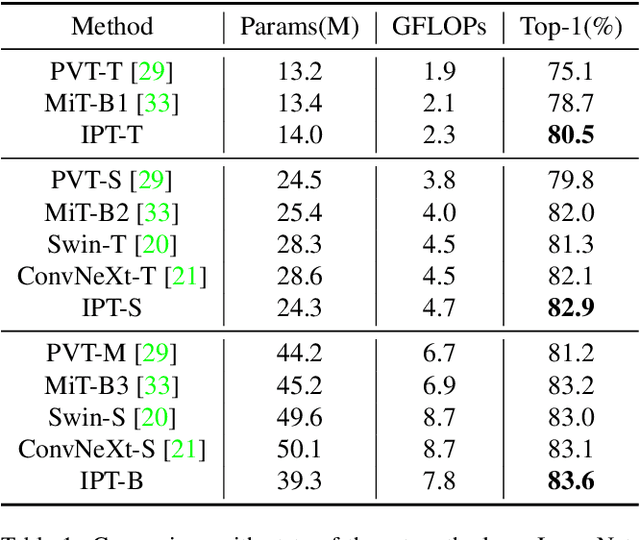
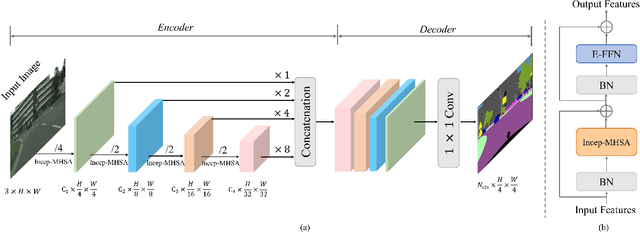
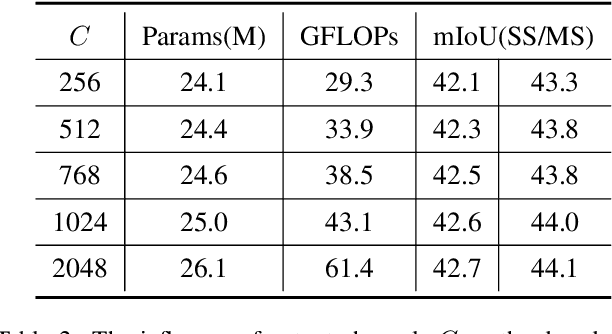
Semantic segmentation usually benefits from global contexts, fine localisation information, multi-scale features, etc. To advance Transformer-based segmenters with these aspects, we present a simple yet powerful semantic segmentation architecture, termed as IncepFormer. IncepFormer has two critical contributions as following. First, it introduces a novel pyramid structured Transformer encoder which harvests global context and fine localisation features simultaneously. These features are concatenated and fed into a convolution layer for final per-pixel prediction. Second, IncepFormer integrates an Inception-like architecture with depth-wise convolutions, and a light-weight feed-forward module in each self-attention layer, efficiently obtaining rich local multi-scale object features. Extensive experiments on five benchmarks show that our IncepFormer is superior to state-of-the-art methods in both accuracy and speed, e.g., 1) our IncepFormer-S achieves 47.7% mIoU on ADE20K which outperforms the existing best method by 1% while only costs half parameters and fewer FLOPs. 2) Our IncepFormer-B finally achieves 82.0% mIoU on Cityscapes dataset with 39.6M parameters. Code is available:github.com/shendu0321/IncepFormer.
Orders Are Unwanted: Dynamic Deep Graph Convolutional Network for Personality Detection
Dec 06, 2022
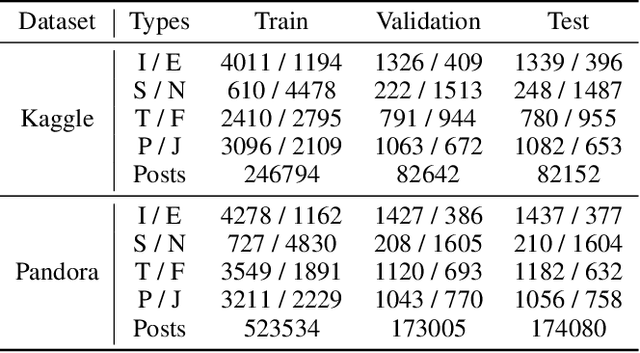
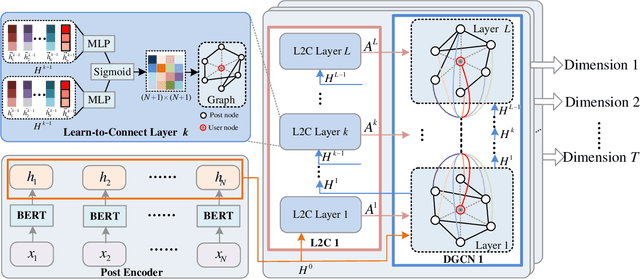
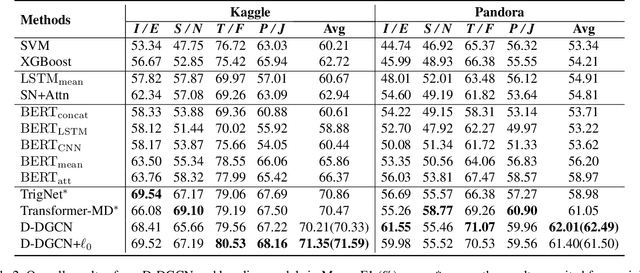
Predicting personality traits based on online posts has emerged as an important task in many fields such as social network analysis. One of the challenges of this task is assembling information from various posts into an overall profile for each user. While many previous solutions simply concatenate the posts into a long document and then encode the document by sequential or hierarchical models, they introduce unwarranted orders for the posts, which may mislead the models. In this paper, we propose a dynamic deep graph convolutional network (D-DGCN) to overcome the above limitation. Specifically, we design a learn-to-connect approach that adopts a dynamic multi-hop structure instead of a deterministic structure, and combine it with a DGCN module to automatically learn the connections between posts. The modules of post encoder, learn-to-connect, and DGCN are jointly trained in an end-to-end manner. Experimental results on the Kaggle and Pandora datasets show the superior performance of D-DGCN to state-of-the-art baselines. Our code is available at https://github.com/djz233/D-DGCN.
Understanding Self-Predictive Learning for Reinforcement Learning
Dec 06, 2022
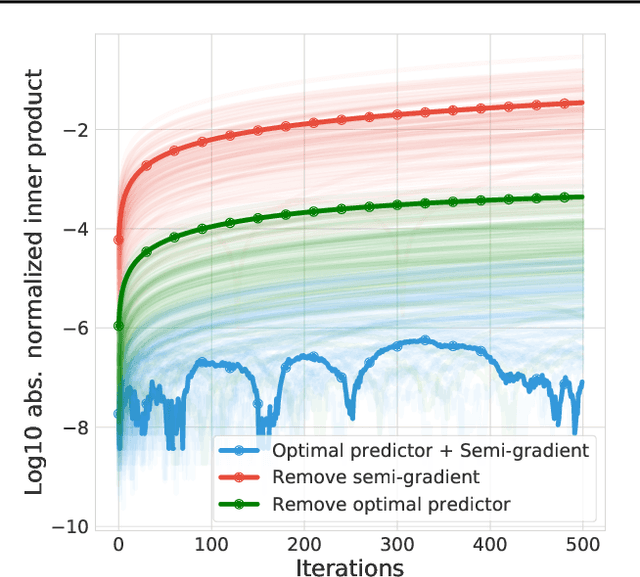
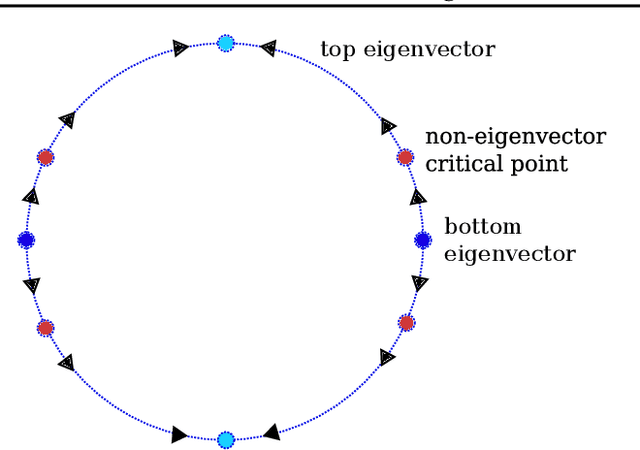
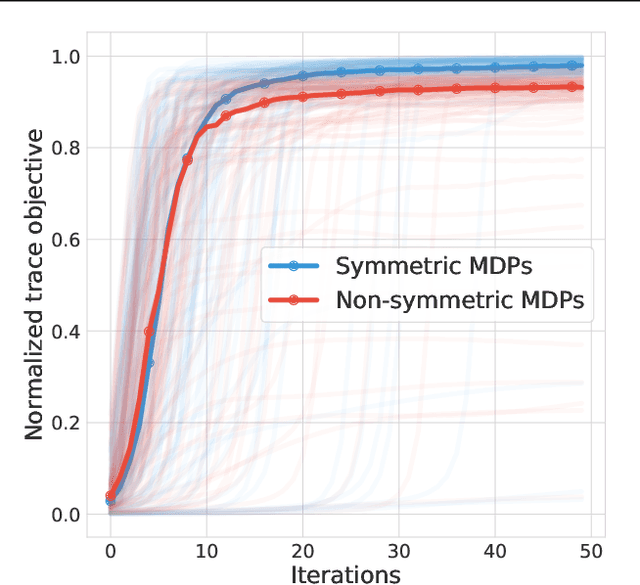
We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
Data Imputation with Iterative Graph Reconstruction
Dec 06, 2022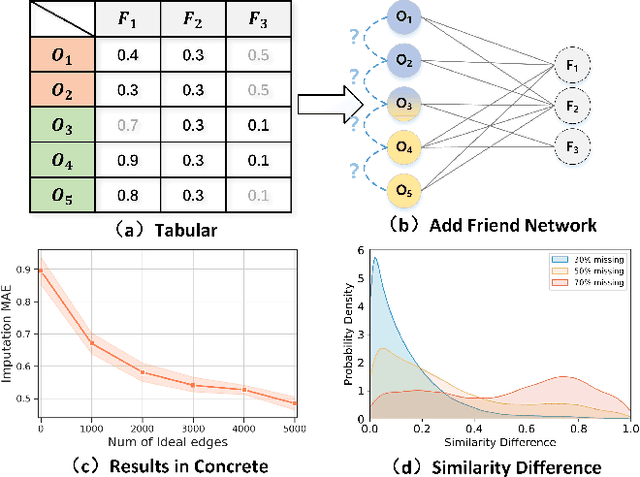
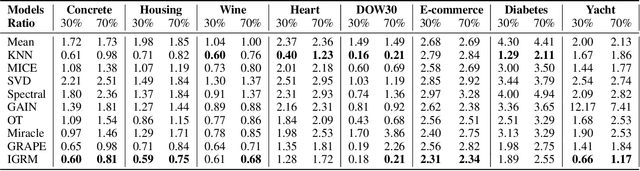
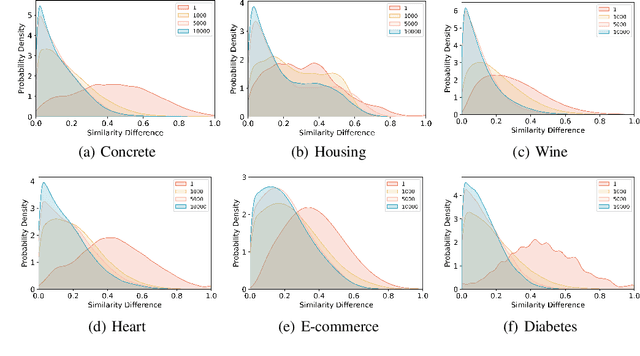
Effective data imputation demands rich latent ``structure" discovery capabilities from ``plain" tabular data. Recent advances in graph neural networks-based data imputation solutions show their strong structure learning potential by directly translating tabular data as bipartite graphs. However, due to a lack of relations between samples, those solutions treat all samples equally which is against one important observation: ``similar sample should give more information about missing values." This paper presents a novel Iterative graph Generation and Reconstruction framework for Missing data imputation(IGRM). Instead of treating all samples equally, we introduce the concept: ``friend networks" to represent different relations among samples. To generate an accurate friend network with missing data, an end-to-end friend network reconstruction solution is designed to allow for continuous friend network optimization during imputation learning. The representation of the optimized friend network, in turn, is used to further optimize the data imputation process with differentiated message passing. Experiment results on eight benchmark datasets show that IGRM yields 39.13% lower mean absolute error compared with nine baselines and 9.04% lower than the second-best.