 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Mar 11, 2024


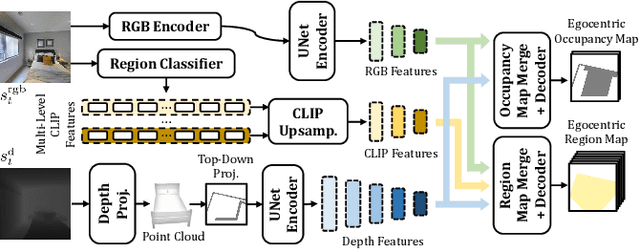
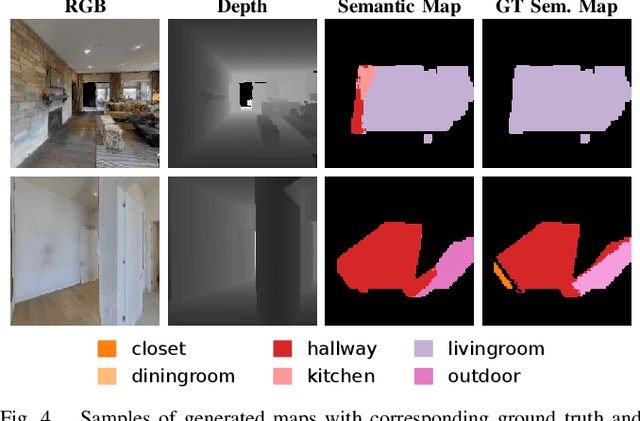
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
One-Bit Target Detection in Collocated MIMO Radar with Colored Background Noise
Mar 11, 2024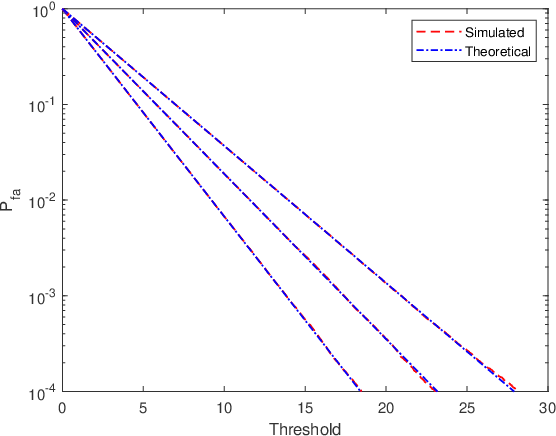

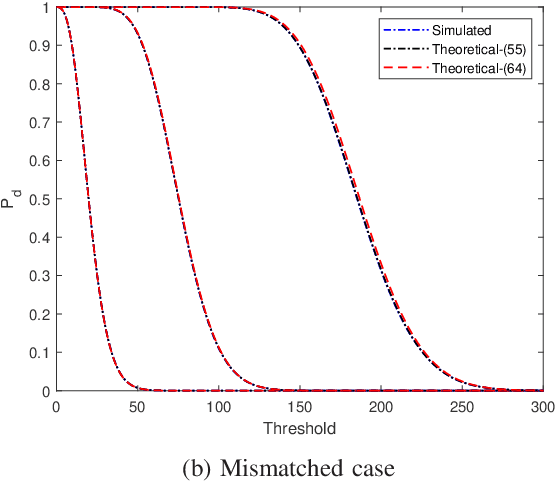
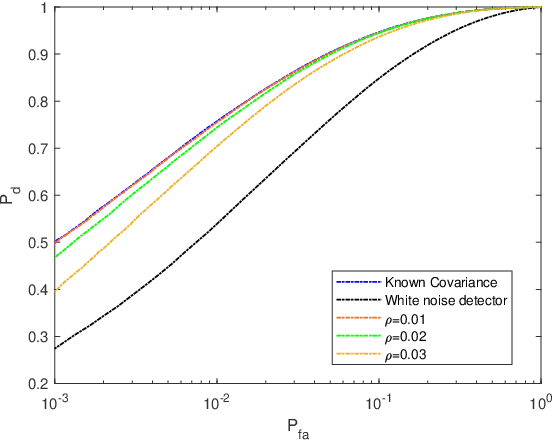
One-bit sampling has emerged as a promising technique in multiple-input multiple-output (MIMO) radar systems due to its ability to significantly reduce data volume and processing requirements. Nevertheless, current detection methods have not adequately addressed the impact of colored noise, which is frequently encountered in real scenarios. In this paper, we present a novel detection method that accounts for colored noise in MIMO radar systems. Specifically, we derive Rao's test by computing the derivative of the likelihood function with respect to the target reflectivity parameter and the Fisher information matrix, resulting in a detector that takes the form of a weighted matched filter. To ensure the constant false alarm rate (CFAR) property, we also consider noise covariance uncertainty and examine its effect on the probability of false alarm. The detection probability is also studied analytically. Simulation results demonstrate that the proposed detector provides considerable performance gains in the presence of colored noise.
What makes an image realistic?
Mar 11, 2024The last decade has seen tremendous progress in our ability to generate realistic-looking data, be it images, text, audio, or video. Here, we discuss the closely related problem of quantifying realism, that is, designing functions that can reliably tell realistic data from unrealistic data. This problem turns out to be significantly harder to solve and remains poorly understood, despite its prevalence in machine learning and recent breakthroughs in generative AI. Drawing on insights from algorithmic information theory, we discuss why this problem is challenging, why a good generative model alone is insufficient to solve it, and what a good solution would look like. In particular, we introduce the notion of a universal critic, which unlike adversarial critics does not require adversarial training. While universal critics are not immediately practical, they can serve both as a North Star for guiding practical implementations and as a tool for analyzing existing attempts to capture realism.
HDRTransDC: High Dynamic Range Image Reconstruction with Transformer Deformation Convolution
Mar 11, 2024
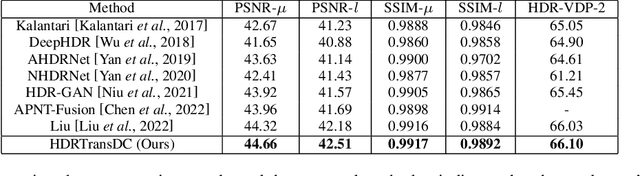
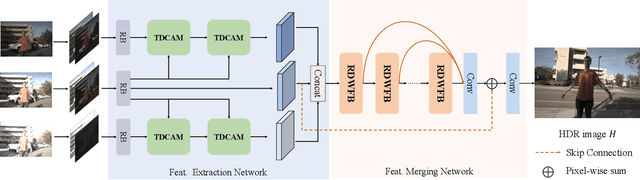
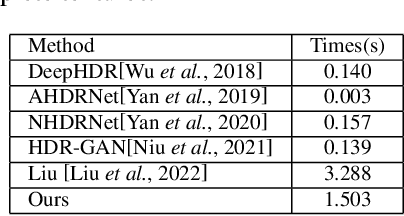
High Dynamic Range (HDR) imaging aims to generate an artifact-free HDR image with realistic details by fusing multi-exposure Low Dynamic Range (LDR) images. Caused by large motion and severe under-/over-exposure among input LDR images, HDR imaging suffers from ghosting artifacts and fusion distortions. To address these critical issues, we propose an HDR Transformer Deformation Convolution (HDRTransDC) network to generate high-quality HDR images, which consists of the Transformer Deformable Convolution Alignment Module (TDCAM) and the Dynamic Weight Fusion Block (DWFB). To solve the ghosting artifacts, the proposed TDCAM extracts long-distance content similar to the reference feature in the entire non-reference features, which can accurately remove misalignment and fill the content occluded by moving objects. For the purpose of eliminating fusion distortions, we propose DWFB to spatially adaptively select useful information across frames to effectively fuse multi-exposed features. Extensive experiments show that our method quantitatively and qualitatively achieves state-of-the-art performance.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Mar 08, 2024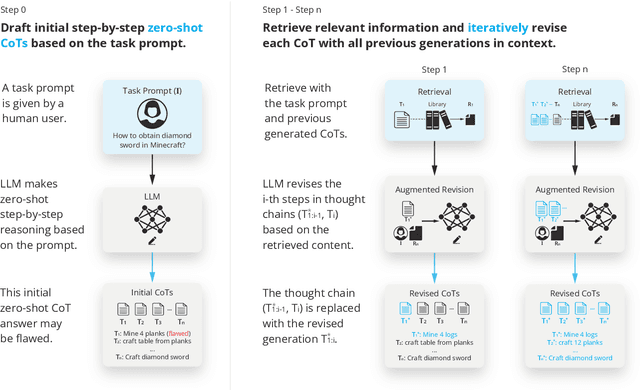
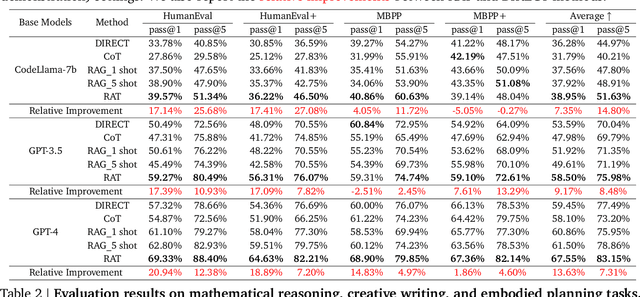
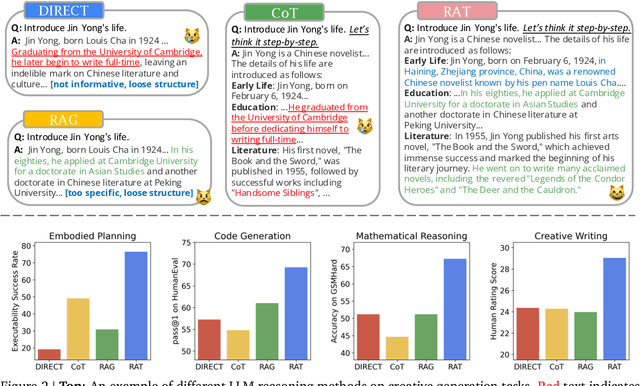
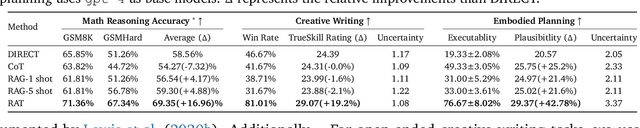
We explore how iterative revising a chain of thoughts with the help of information retrieval significantly improves large language models' reasoning and generation ability in long-horizon generation tasks, while hugely mitigating hallucination. In particular, the proposed method -- *retrieval-augmented thoughts* (RAT) -- revises each thought step one by one with retrieved information relevant to the task query, the current and the past thought steps, after the initial zero-shot CoT is generated. Applying RAT to GPT-3.5, GPT-4, and CodeLLaMA-7b substantially improves their performances on various long-horizon generation tasks; on average of relatively increasing rating scores by 13.63% on code generation, 16.96% on mathematical reasoning, 19.2% on creative writing, and 42.78% on embodied task planning. The demo page can be found at https://craftjarvis.github.io/RAT
Multi-Tower Multi-Interest Recommendation with User Representation Repel
Mar 08, 2024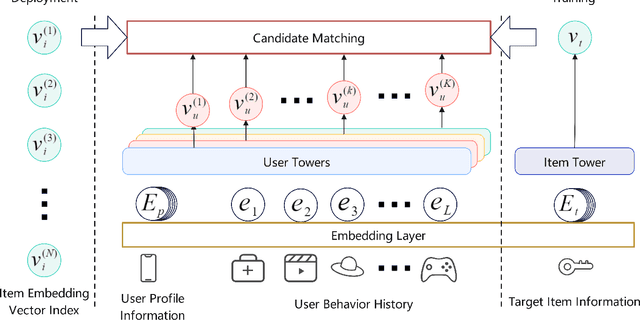
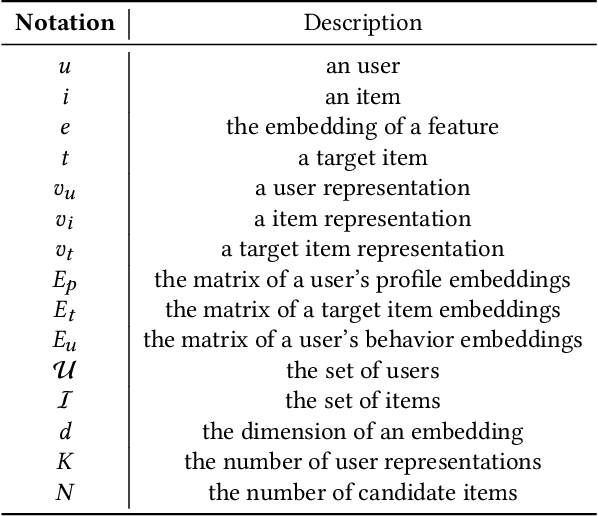

In the era of information overload, the value of recommender systems has been profoundly recognized in academia and industry alike. Multi-interest sequential recommendation, in particular, is a subfield that has been receiving increasing attention in recent years. By generating multiple-user representations, multi-interest learning models demonstrate superior expressiveness than single-user representation models, both theoretically and empirically. Despite major advancements in the field, three major issues continue to plague the performance and adoptability of multi-interest learning methods, the difference between training and deployment objectives, the inability to access item information, and the difficulty of industrial adoption due to its single-tower architecture. We address these challenges by proposing a novel multi-tower multi-interest framework with user representation repel. Experimental results across multiple large-scale industrial datasets proved the effectiveness and generalizability of our proposed framework.
LVIC: Multi-modality segmentation by Lifting Visual Info as Cue
Mar 08, 2024
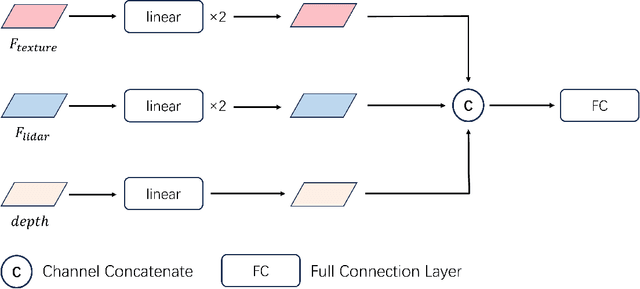

Multi-modality fusion is proven an effective method for 3d perception for autonomous driving. However, most current multi-modality fusion pipelines for LiDAR semantic segmentation have complicated fusion mechanisms. Point painting is a quite straight forward method which directly bind LiDAR points with visual information. Unfortunately, previous point painting like methods suffer from projection error between camera and LiDAR. In our experiments, we find that this projection error is the devil in point painting. As a result of that, we propose a depth aware point painting mechanism, which significantly boosts the multi-modality fusion. Apart from that, we take a deeper look at the desired visual feature for LiDAR to operate semantic segmentation. By Lifting Visual Information as Cue, LVIC ranks 1st on nuScenes LiDAR semantic segmentation benchmark. Our experiments show the robustness and effectiveness. Codes would be make publicly available soon.
Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs
Mar 08, 2024
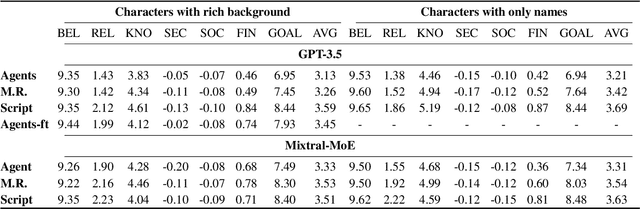
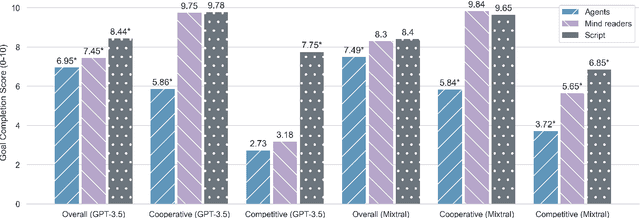

Recent advances in large language models (LLM) have enabled richer social simulations, allowing for the study of various social phenomena with LLM-based agents. However, most work has used an omniscient perspective on these simulations (e.g., single LLM to generate all interlocutors), which is fundamentally at odds with the non-omniscient, information asymmetric interactions that humans have. To examine these differences, we develop an evaluation framework to simulate social interactions with LLMs in various settings (omniscient, non-omniscient). Our experiments show that interlocutors simulated omnisciently are much more successful at accomplishing social goals compared to non-omniscient agents, despite the latter being the more realistic setting. Furthermore, we demonstrate that learning from omniscient simulations improves the apparent naturalness of interactions but scarcely enhances goal achievement in cooperative scenarios. Our findings indicate that addressing information asymmetry remains a fundamental challenge for LLM-based agents.
Achievable Rate Analysis and Optimization of Double-RIS Assisted Spatially Correlated MIMO with Statistical CSI
Mar 12, 2024
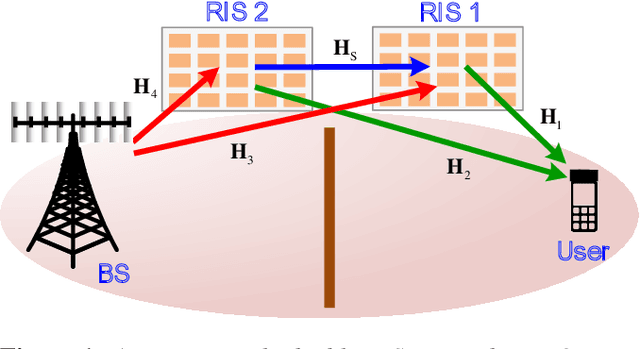
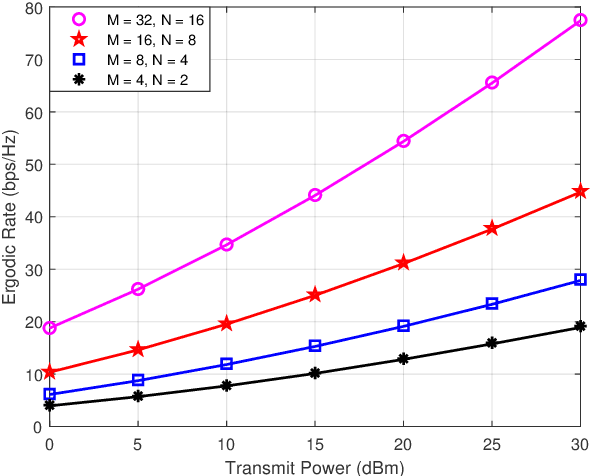
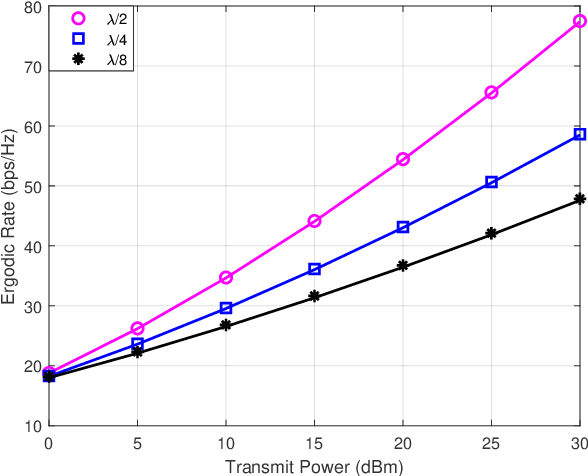
Reconfigurable intelligent surface (RIS) is a novel meta-material which can form a smart radio environment by dynamically altering reflection directions of the impinging electromagnetic waves. In the prior literature, the inter-RIS links which also contribute to the performance of the whole system are usually neglected when multiple RISs are deployed. In this paper we investigate a general double-RIS assisted multiple-input multiple-output (MIMO) wireless communication system under spatially correlated non line-of-sight propagation channels, where the cooperation of the double RISs is also considered. The design objective is to maximize the achievable ergodic rate based on full statistical channel state information (CSI). Specifically, we firstly present a closed-form asymptotic expression for the achievable ergodic rate by utilizing replica method from statistical physics. Then a full statistical CSI-enabled optimal design is proposed which avoids high pilot training overhead compared to instantaneous CSI-enabled design. To further reduce the signal processing overhead and lower the complexity for practical realization, a common-phase scheme is proposed to design the double RISs. Simulation results show that the derived asymptotic ergodic rate is quite accurate even for small-sized antenna arrays. And the proposed optimization algorithm can achieve substantial gain at the expense of a low overhead and complexity. Furthermore, the cooperative double-RIS assisted MIMO framework is proven to achieve superior ergodic rate performance and high communication reliability under harsh propagation environment.
Genuine Knowledge from Practice: Diffusion Test-Time Adaptation for Video Adverse Weather Removal
Mar 12, 2024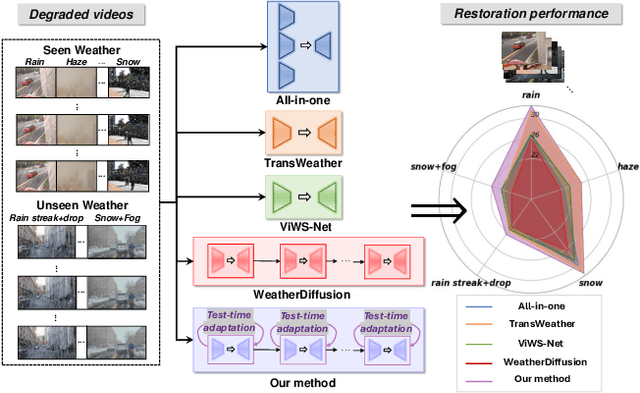
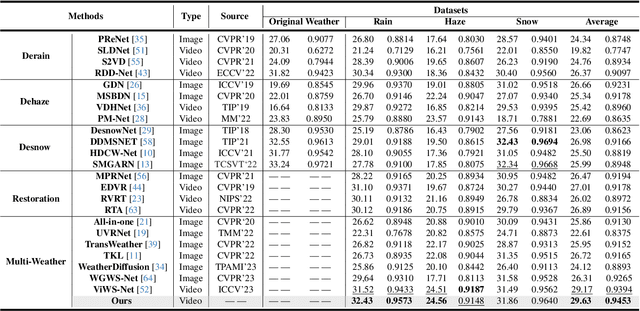
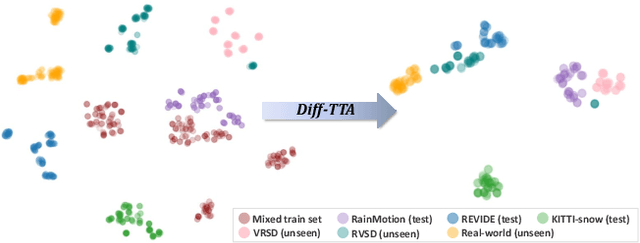
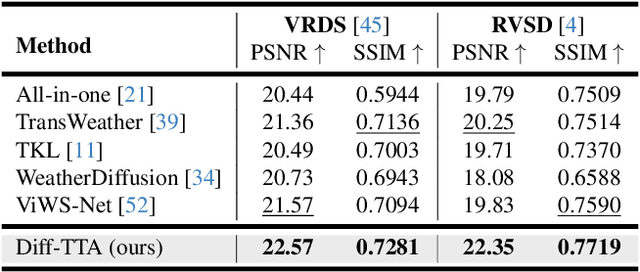
Real-world vision tasks frequently suffer from the appearance of unexpected adverse weather conditions, including rain, haze, snow, and raindrops. In the last decade, convolutional neural networks and vision transformers have yielded outstanding results in single-weather video removal. However, due to the absence of appropriate adaptation, most of them fail to generalize to other weather conditions. Although ViWS-Net is proposed to remove adverse weather conditions in videos with a single set of pre-trained weights, it is seriously blinded by seen weather at train-time and degenerates when coming to unseen weather during test-time. In this work, we introduce test-time adaptation into adverse weather removal in videos, and propose the first framework that integrates test-time adaptation into the iterative diffusion reverse process. Specifically, we devise a diffusion-based network with a novel temporal noise model to efficiently explore frame-correlated information in degraded video clips at training stage. During inference stage, we introduce a proxy task named Diffusion Tubelet Self-Calibration to learn the primer distribution of test video stream and optimize the model by approximating the temporal noise model for online adaptation. Experimental results, on benchmark datasets, demonstrate that our Test-Time Adaptation method with Diffusion-based network(Diff-TTA) outperforms state-of-the-art methods in terms of restoring videos degraded by seen weather conditions. Its generalizable capability is also validated with unseen weather conditions in both synthesized and real-world videos.