 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated deep clustering with GAN-based data synthesis
Nov 30, 2022
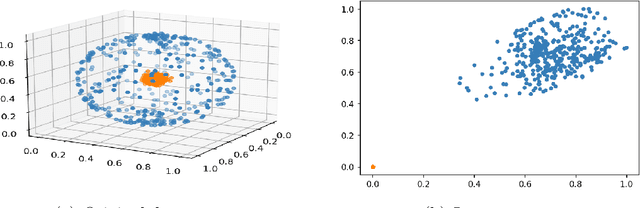
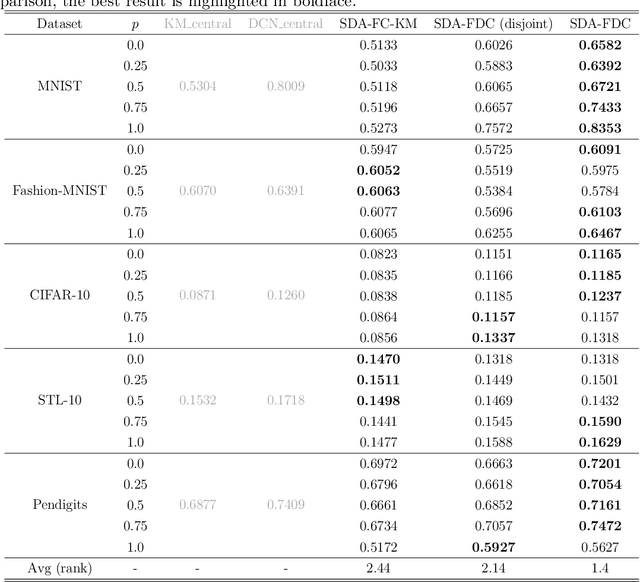
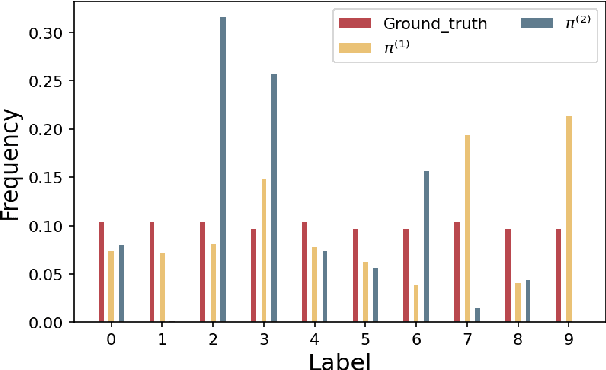
Clustering has been extensively studied in centralized settings, but relatively unexplored in federated ones that data are distributed among multiple clients and can only be kept local at the clients. The necessity to invest more resources in improving federated clustering methods is twofold: 1) The performance of supervised federated learning models can benefit from clustering. 2) It is non-trivial to extend centralized ones to perform federated clustering tasks. In centralized settings, various deep clustering methods that perform dimensionality reduction and clustering jointly have achieved great success. To obtain high-quality cluster information, it is natural but non-trivial to extend these methods to federated settings. For this purpose, we propose a simple but effective federated deep clustering method. It requires only one communication round between the central server and clients, can run asynchronously, and can handle device failures. Moreover, although most studies have highlighted adverse effects of the non-independent and identically distributed (non-IID) data across clients, experimental results indicate that the proposed method can significantly benefit from this scenario.
Investigating the Role of Centering Theory in the Context of Neural Coreference Resolution Systems
Oct 26, 2022
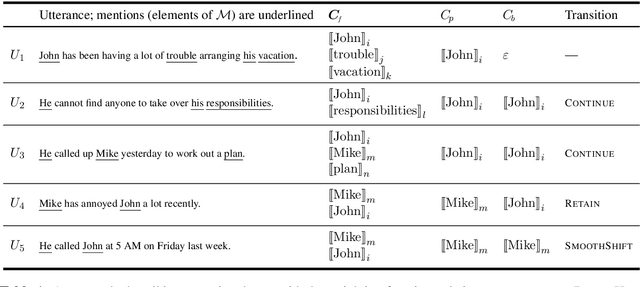

Centering theory (CT; Grosz et al., 1995) provides a linguistic analysis of the structure of discourse. According to the theory, local coherence of discourse arises from the manner and extent to which successive utterances make reference to the same entities. In this paper, we investigate the connection between centering theory and modern coreference resolution systems. We provide an operationalization of centering and systematically investigate if neural coreference resolvers adhere to the rules of centering theory by defining various discourse metrics and developing a search-based methodology. Our information-theoretic analysis reveals a positive dependence between coreference and centering; but also shows that high-quality neural coreference resolvers may not benefit much from explicitly modeling centering ideas. Our analysis further shows that contextualized embeddings contain much of the coherence information, which helps explain why CT can only provide little gains to modern neural coreference resolvers which make use of pretrained representations. Finally, we discuss factors that contribute to coreference which are not modeled by CT such as world knowledge and recency bias. We formulate a version of CT that also models recency and show that it captures coreference information better compared to vanilla CT.
DiscreteCommunication and ControlUpdating in Event-Triggered Consensus
Oct 26, 2022
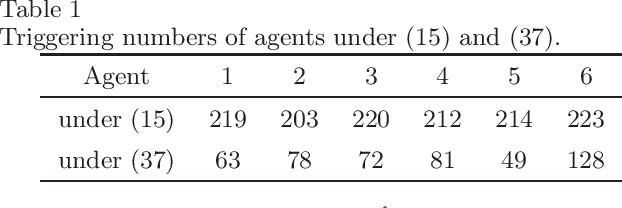
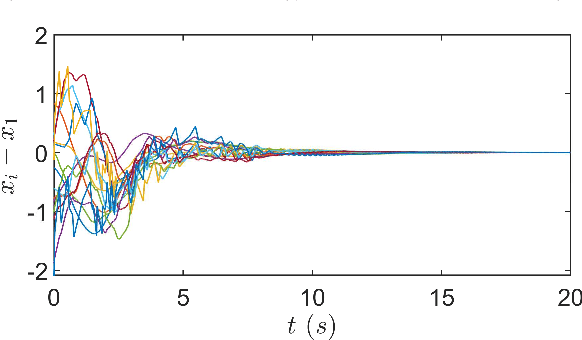
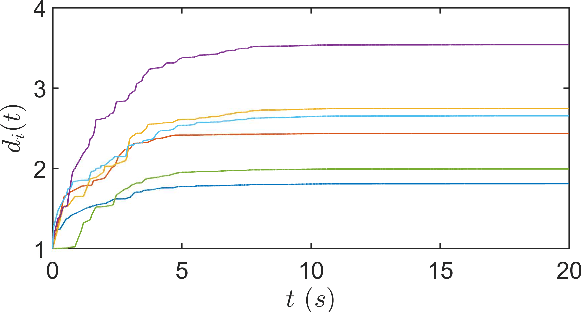
This paper studies the consensus control problem faced with three essential demands, namely, discrete control updating for each agent, discrete-time communications among neighboring agents, and the fully distributed fashion of the controller implementation without requiring any global information of the whole network topology. Noting that the existing related results only meeting one or two demands at most are essentially not applicable, in this paper we establish a novel framework to solve the problem of fully distributed consensus with discrete communication and control. The first key point in this framework is the design of controllers that are only updated at discrete event instants and do not depend on global information by introducing time-varying gains inspired by the adaptive control technique. Another key point is the invention of novel dynamic triggering functions that are independent of relative information among neighboring agents. Under the established framework, we propose fully distributed state-feedback event-triggered protocols for undirected graphs and also further study the more complexed cases of output-feedback control and directed graphs. Finally, numerical examples are provided to verify the effectiveness of the proposed event-triggered protocols.
SINE: SINgle Image Editing with Text-to-Image Diffusion Models
Dec 08, 2022

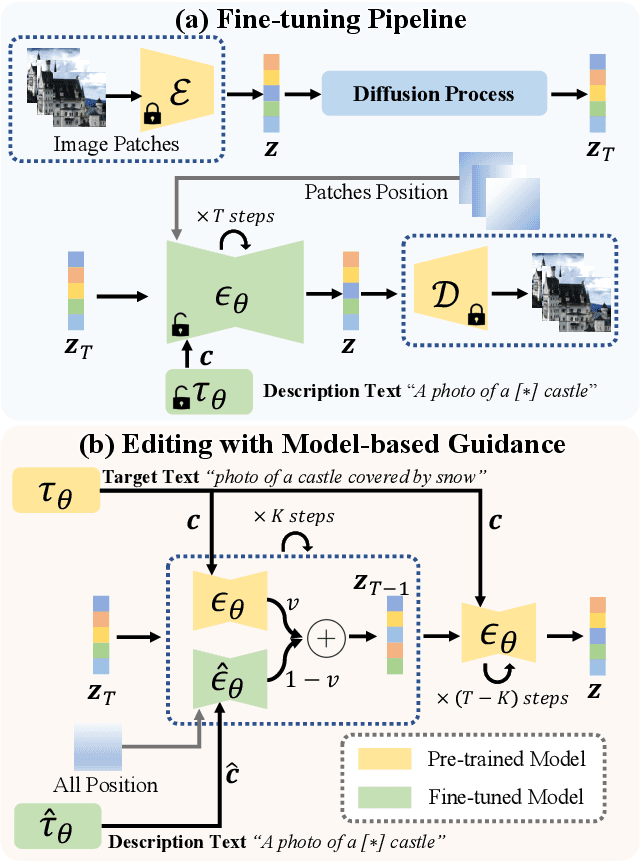
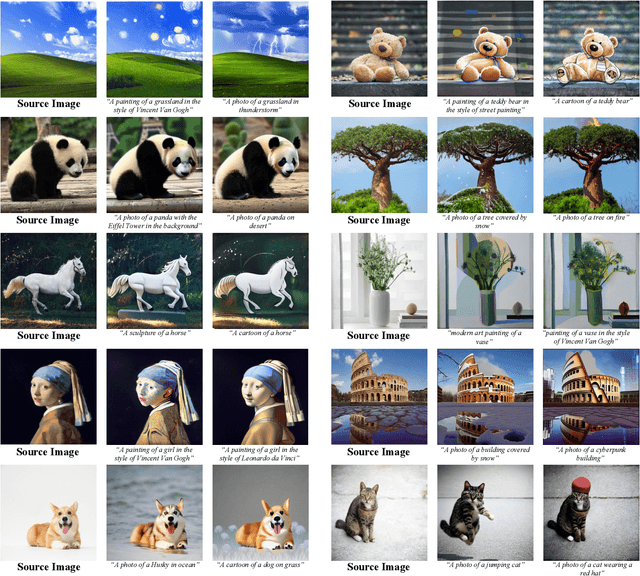
Recent works on diffusion models have demonstrated a strong capability for conditioning image generation, e.g., text-guided image synthesis. Such success inspires many efforts trying to use large-scale pre-trained diffusion models for tackling a challenging problem--real image editing. Works conducted in this area learn a unique textual token corresponding to several images containing the same object. However, under many circumstances, only one image is available, such as the painting of the Girl with a Pearl Earring. Using existing works on fine-tuning the pre-trained diffusion models with a single image causes severe overfitting issues. The information leakage from the pre-trained diffusion models makes editing can not keep the same content as the given image while creating new features depicted by the language guidance. This work aims to address the problem of single-image editing. We propose a novel model-based guidance built upon the classifier-free guidance so that the knowledge from the model trained on a single image can be distilled into the pre-trained diffusion model, enabling content creation even with one given image. Additionally, we propose a patch-based fine-tuning that can effectively help the model generate images of arbitrary resolution. We provide extensive experiments to validate the design choices of our approach and show promising editing capabilities, including changing style, content addition, and object manipulation. The code is available for research purposes at https://github.com/zhang-zx/SINE.git .
Multi-fidelity Gaussian Process for Biomanufacturing Process Modeling with Small Data
Nov 26, 2022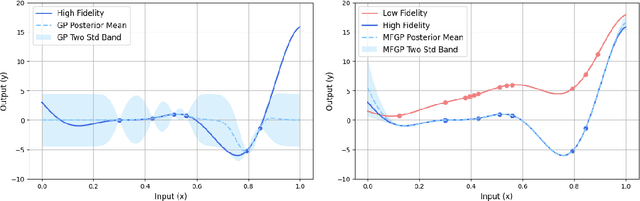
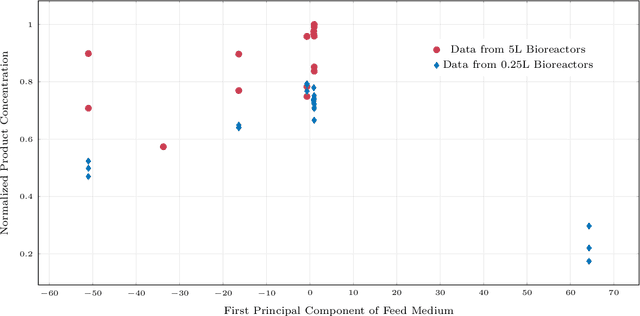
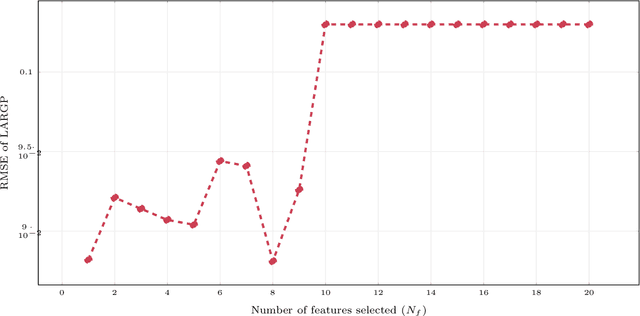
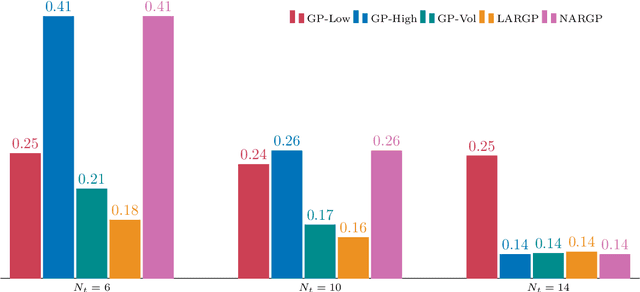
In biomanufacturing, developing an accurate model to simulate the complex dynamics of bioprocesses is an important yet challenging task. This is partially due to the uncertainty associated with bioprocesses, high data acquisition cost, and lack of data availability to learn complex relations in bioprocesses. To deal with these challenges, we propose to use a statistical machine learning approach, multi-fidelity Gaussian process, for process modelling in biomanufacturing. Gaussian process regression is a well-established technique based on probability theory which can naturally consider uncertainty in a dataset via Gaussian noise, and multi-fidelity techniques can make use of multiple sources of information with different levels of fidelity, thus suitable for bioprocess modeling with small data. We apply the multi-fidelity Gaussian process to solve two significant problems in biomanufacturing, bioreactor scale-up and knowledge transfer across cell lines, and demonstrate its efficacy on real-world datasets.
A Survey of Text Representation Methods and Their Genealogy
Nov 26, 2022

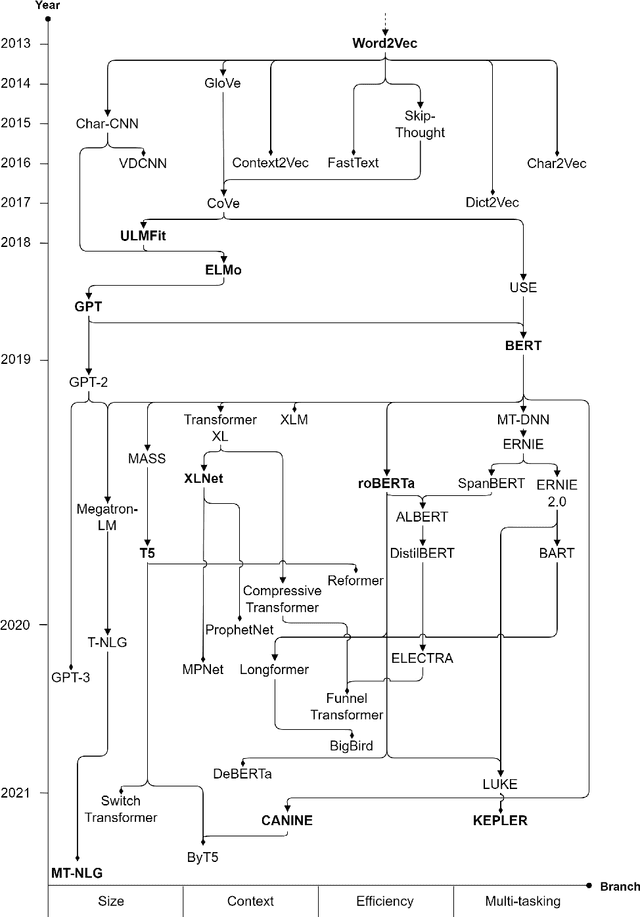
In recent years, with the advent of highly scalable artificial-neural-network-based text representation methods the field of natural language processing has seen unprecedented growth and sophistication. It has become possible to distill complex linguistic information of text into multidimensional dense numeric vectors with the use of the distributional hypothesis. As a consequence, text representation methods have been evolving at such a quick pace that the research community is struggling to retain knowledge of the methods and their interrelations. We contribute threefold to this lack of compilation, composition, and systematization by providing a survey of current approaches, by arranging them in a genealogy, and by conceptualizing a taxonomy of text representation methods to examine and explain the state-of-the-art. Our research is a valuable guide and reference for artificial intelligence researchers and practitioners interested in natural language processing applications such as recommender systems, chatbots, and sentiment analysis.
* Published online in IEEE Access
StructVPR: Distill Structural Knowledge with Weighting Samples for Visual Place Recognition
Dec 02, 2022Visual place recognition (VPR) is usually considered as a specific image retrieval problem. Limited by existing training frameworks, most deep learning-based works cannot extract sufficiently stable global features from RGB images and rely on a time-consuming re-ranking step to exploit spatial structural information for better performance. In this paper, we propose StructVPR, a novel training architecture for VPR, to enhance structural knowledge in RGB global features and thus improve feature stability in a constantly changing environment. Specifically, StructVPR uses segmentation images as a more definitive source of structural knowledge input into a CNN network and applies knowledge distillation to avoid online segmentation and inference of seg-branch in testing. Considering that not all samples contain high-quality and helpful knowledge, and some even hurt the performance of distillation, we partition samples and weigh each sample's distillation loss to enhance the expected knowledge precisely. Finally, StructVPR achieves impressive performance on several benchmarks using only global retrieval and even outperforms many two-stage approaches by a large margin. After adding additional re-ranking, ours achieves state-of-the-art performance while maintaining a low computational cost.
On Solution Functions of Optimization: Universal Approximation and Covering Number Bounds
Dec 02, 2022
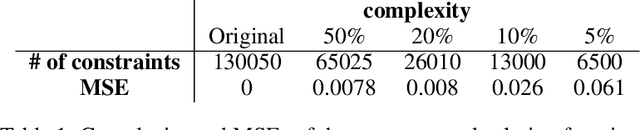
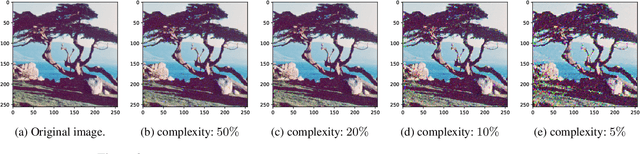
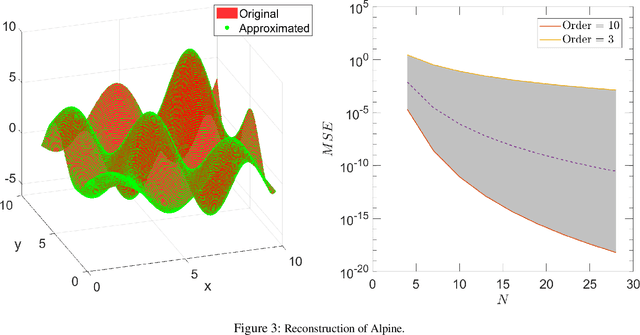
We study the expressibility and learnability of convex optimization solution functions and their multi-layer architectural extension. The main results are: \emph{(1)} the class of solution functions of linear programming (LP) and quadratic programming (QP) is a universal approximant for the $C^k$ smooth model class or some restricted Sobolev space, and we characterize the rate-distortion, \emph{(2)} the approximation power is investigated through a viewpoint of regression error, where information about the target function is provided in terms of data observations, \emph{(3)} compositionality in the form of a deep architecture with optimization as a layer is shown to reconstruct some basic functions used in numerical analysis without error, which implies that \emph{(4)} a substantial reduction in rate-distortion can be achieved with a universal network architecture, and \emph{(5)} we discuss the statistical bounds of empirical covering numbers for LP/QP, as well as a generic optimization problem (possibly nonconvex) by exploiting tame geometry. Our results provide the \emph{first rigorous analysis of the approximation and learning-theoretic properties of solution functions} with implications for algorithmic design and performance guarantees.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022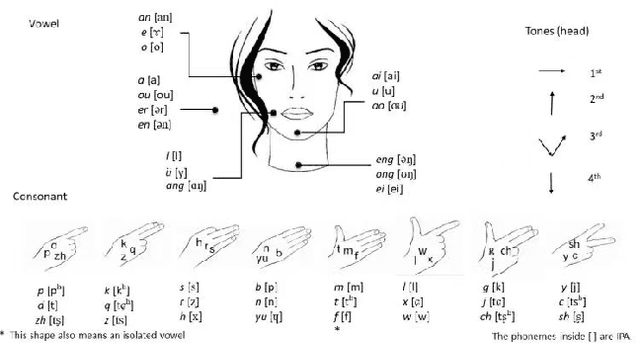
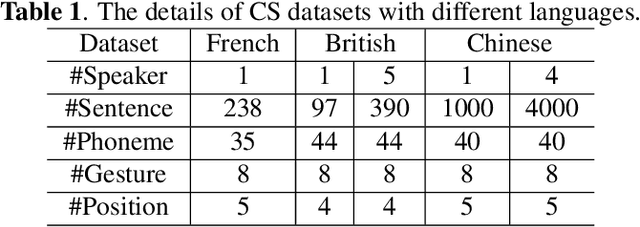
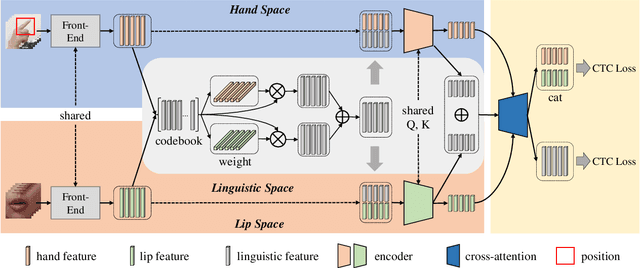
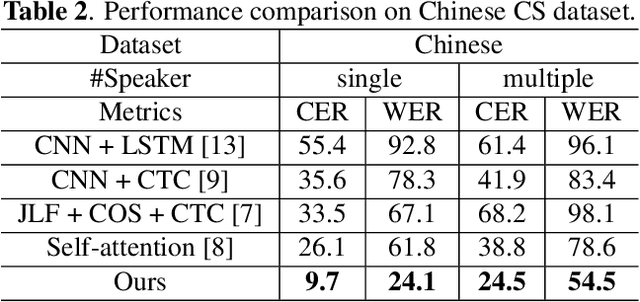
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Evaluating Feature Attribution: An Information-Theoretic Perspective
Feb 01, 2022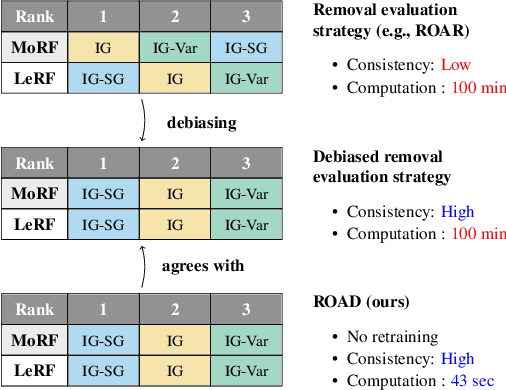

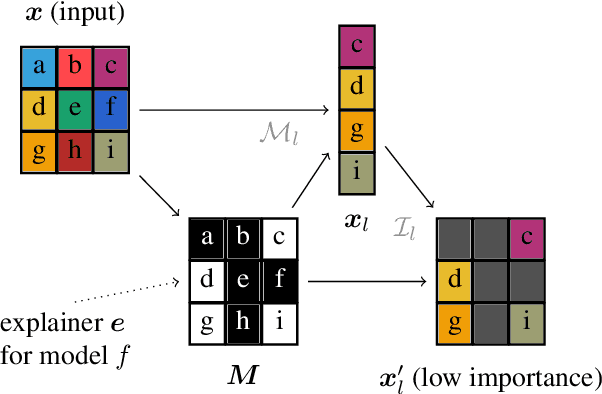
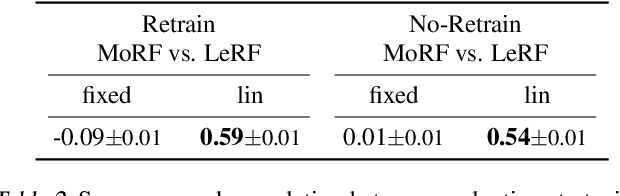
With a variety of local feature attribution methods being proposed in recent years, follow-up work suggested several evaluation strategies. To assess the attribution quality across different attribution techniques, the most popular among these evaluation strategies in the image domain use pixel perturbations. However, recent advances discovered that different evaluation strategies produce conflicting rankings of attribution methods and can be prohibitively expensive to compute. In this work, we present an information-theoretic analysis of evaluation strategies based on pixel perturbations. Our findings reveal that the results output by different evaluation strategies are strongly affected by information leakage through the shape of the removed pixels as opposed to their actual values. Using our theoretical insights, we propose a novel evaluation framework termed Remove and Debias (ROAD) which offers two contributions: First, it mitigates the impact of the confounders, which entails higher consistency among evaluation strategies. Second, ROAD does not require the computationally expensive retraining step and saves up to 99% in computational costs compared to the state-of-the-art. Our source code is available at https://github.com/tleemann/road_evaluation.