 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lightweight and Adaptive FDD Massive MIMO CSI Feedback with Deep Equilibrium Learning
Nov 28, 2022
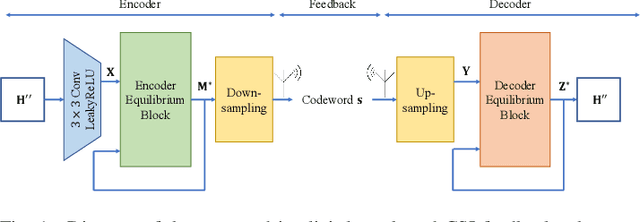
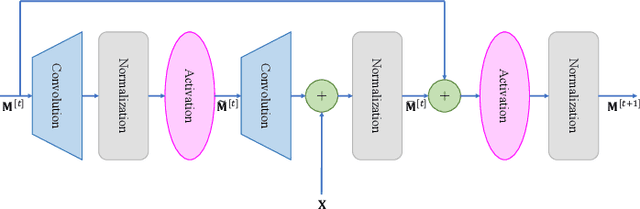
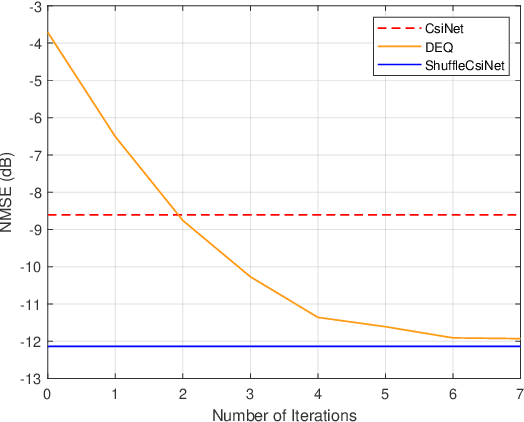
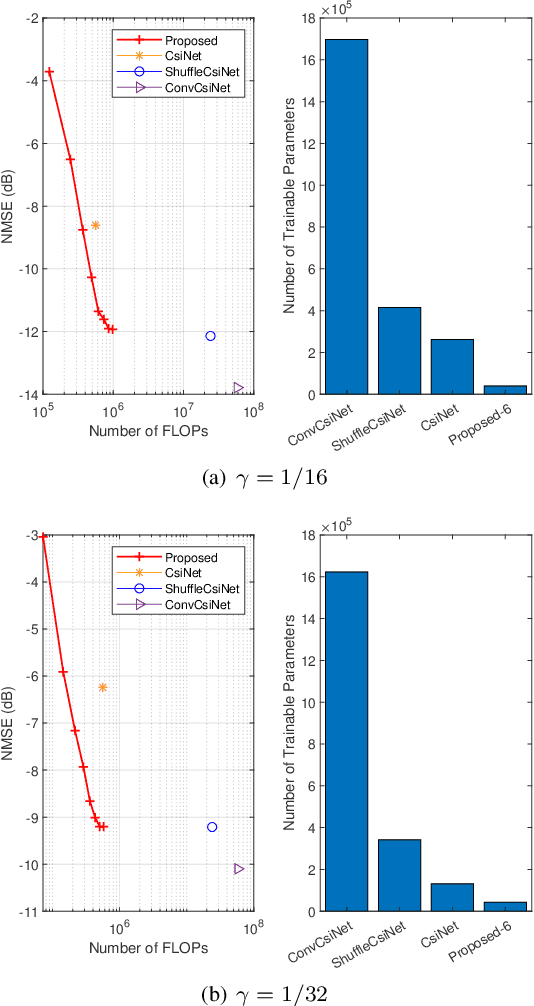
In frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems, downlink channel state information (CSI) needs to be sent from users back to the base station (BS), which causes prohibitive feedback overhead. In this paper, we propose a lightweight and adaptive deep learning-based CSI feedback scheme by capitalizing on deep equilibrium models. Different from existing deep learning-based approaches that stack multiple explicit layers, we propose an implicit equilibrium block to mimic the process of an infinite-depth neural network. In particular, the implicit equilibrium block is defined by a fixed-point iteration and the trainable parameters in each iteration are shared, which results in a lightweight model. Furthermore, the number of forward iterations can be adjusted according to the users' computational capability, achieving an online accuracy-efficiency trade-off. Simulation results will show that the proposed method obtains a comparable performance as the existing benchmarks but with much-reduced complexity and permits an accuracy-efficiency trade-off at runtime.
Semisoft Task Clustering for Multi-Task Learning
Nov 28, 2022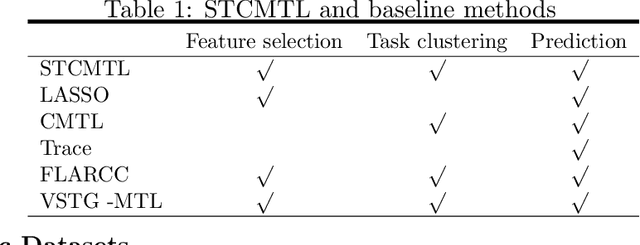
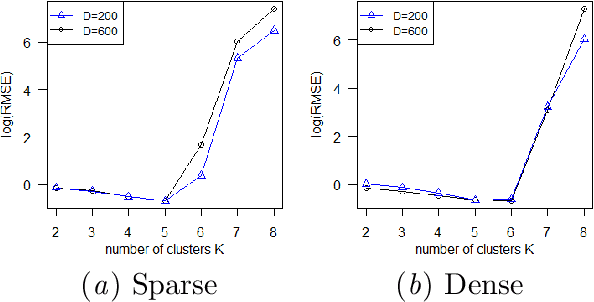
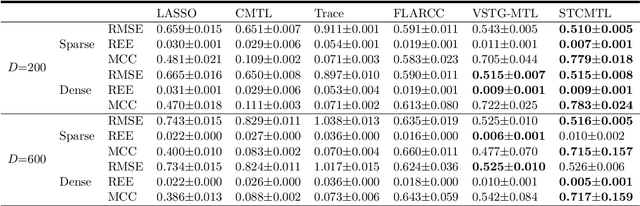
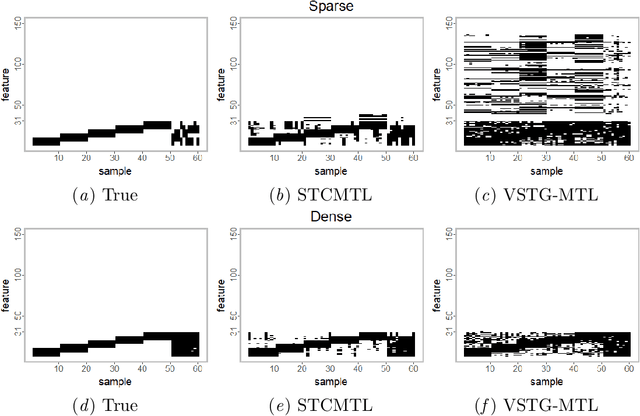
Multi-task learning (MTL) aims to improve the performance of multiple related prediction tasks by leveraging useful information from them. Due to their flexibility and ability to reduce unknown coefficients substantially, the task-clustering-based MTL approaches have attracted considerable attention. Motivated by the idea of semisoft clustering of data, we propose a semisoft task clustering approach, which can simultaneously reveal the task cluster structure for both pure and mixed tasks as well as select the relevant features. The main assumption behind our approach is that each cluster has some pure tasks, and each mixed task can be represented by a linear combination of pure tasks in different clusters. To solve the resulting non-convex constrained optimization problem, we design an efficient three-step algorithm. The experimental results based on synthetic and real-world datasets validate the effectiveness and efficiency of the proposed approach. Finally, we extend the proposed approach to a robust task clustering problem.
Heterogeneous Graph Learning for Multi-modal Medical Data Analysis
Nov 28, 2022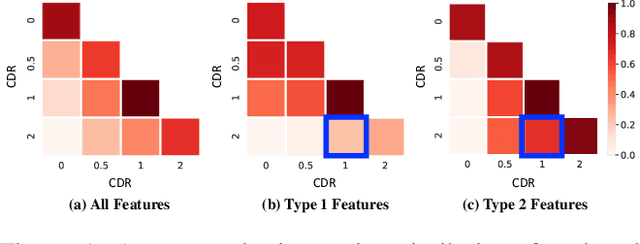

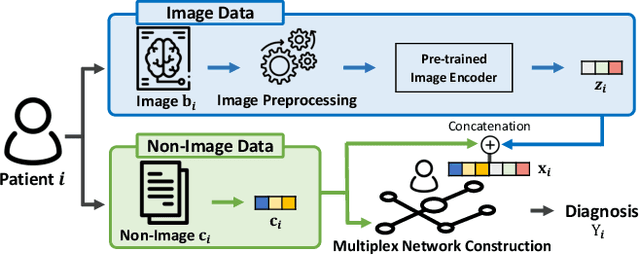

Routine clinical visits of a patient produce not only image data, but also non-image data containing clinical information regarding the patient, i.e., medical data is multi-modal in nature. Such heterogeneous modalities offer different and complementary perspectives on the same patient, resulting in more accurate clinical decisions when they are properly combined. However, despite its significance, how to effectively fuse the multi-modal medical data into a unified framework has received relatively little attention. In this paper, we propose an effective graph-based framework called HetMed (Heterogeneous Graph Learning for Multi-modal Medical Data Analysis) for fusing the multi-modal medical data. Specifically, we construct a multiplex network that incorporates multiple types of non-image features of patients to capture the complex relationship between patients in a systematic way, which leads to more accurate clinical decisions. Extensive experiments on various real-world datasets demonstrate the superiority and practicality of HetMed. The source code for HetMed is available at https://github.com/Sein-Kim/Multimodal-Medical.
Long-Range Zero-Shot Generative Deep Network Quantization
Nov 17, 2022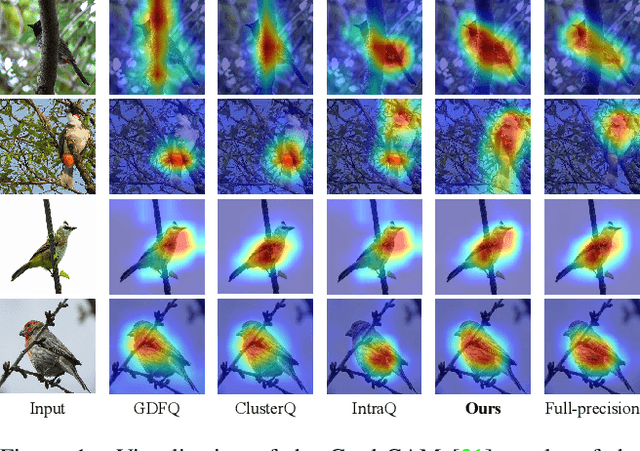

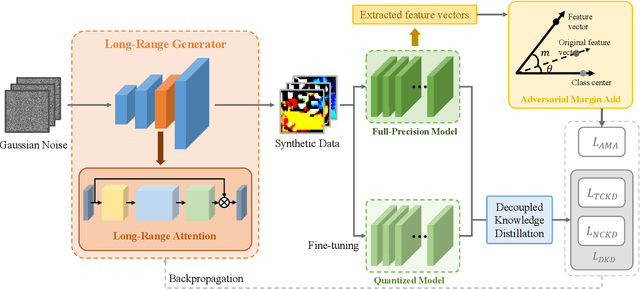
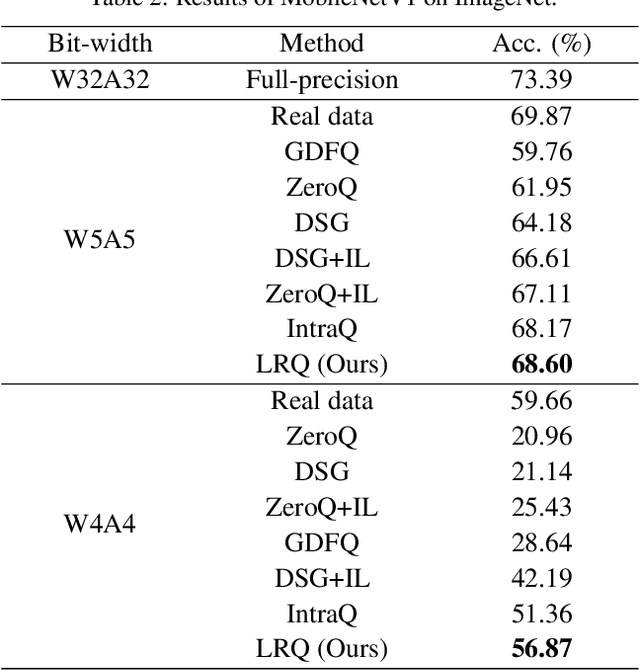
Quantization approximates a deep network model with floating-point numbers by the one with low bit width numbers, in order to accelerate inference and reduce computation. Quantizing a model without access to the original data, zero-shot quantization can be accomplished by fitting the real data distribution by data synthesis. However, zero-shot quantization achieves inferior performance compared to the post-training quantization with real data. We find it is because: 1) a normal generator is hard to obtain high diversity of synthetic data, since it lacks long-range information to allocate attention to global features; 2) the synthetic images aim to simulate the statistics of real data, which leads to weak intra-class heterogeneity and limited feature richness. To overcome these problems, we propose a novel deep network quantizer, dubbed Long-Range Zero-Shot Generative Deep Network Quantization (LRQ). Technically, we propose a long-range generator to learn long-range information instead of simple local features. In order for the synthetic data to contain more global features, long-range attention using large kernel convolution is incorporated into the generator. In addition, we also present an Adversarial Margin Add (AMA) module to force intra-class angular enlargement between feature vector and class center. As AMA increases the convergence difficulty of the loss function, which is opposite to the training objective of the original loss function, it forms an adversarial process. Furthermore, in order to transfer knowledge from the full-precision network, we also utilize a decoupled knowledge distillation. Extensive experiments demonstrate that LRQ obtains better performance than other competitors.
Joint Deep Learning for Improved Myocardial Scar Detection from Cardiac MRI
Nov 11, 2022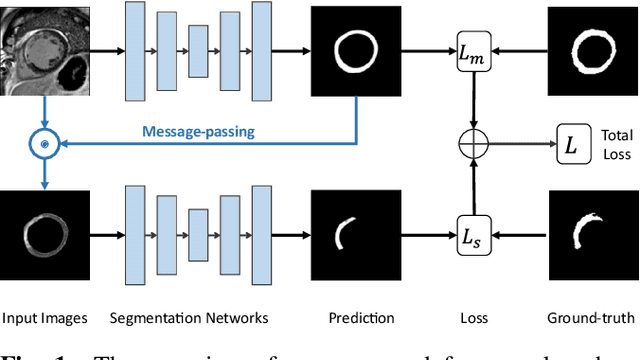


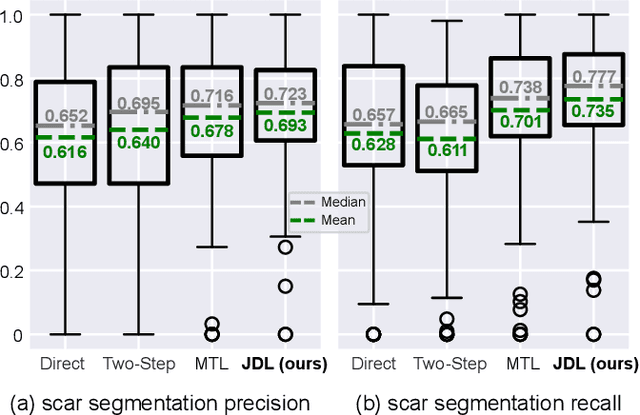
Automated identification of myocardial scar from late gadolinium enhancement cardiac magnetic resonance images (LGE-CMR) is limited by image noise and artifacts such as those related to motion and partial volume effect. This paper presents a novel joint deep learning (JDL) framework that improves such tasks by utilizing simultaneously learned myocardium segmentations to eliminate negative effects from non-region-of-interest areas. In contrast to previous approaches treating scar detection and myocardium segmentation as separate or parallel tasks, our proposed method introduces a message passing module where the information of myocardium segmentation is directly passed to guide scar detectors. This newly designed network will efficiently exploit joint information from the two related tasks and use all available sources of myocardium segmentation to benefit scar identification. We demonstrate the effectiveness of JDL on LGE-CMR images for automated left ventricular (LV) scar detection, with great potential to improve risk prediction in patients with both ischemic and non-ischemic heart disease and to improve response rates to cardiac resynchronization therapy (CRT) for heart failure patients. Experimental results show that our proposed approach outperforms multiple state-of-the-art methods, including commonly used two-step segmentation-classification networks, and multitask learning schemes where subtasks are indirectly interacted.
RCDPT: Radar-Camera fusion Dense Prediction Transformer
Nov 04, 2022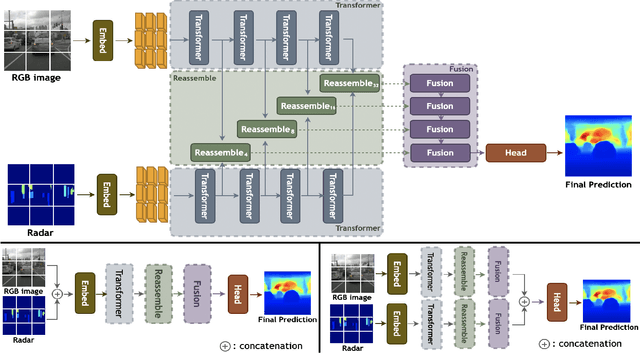
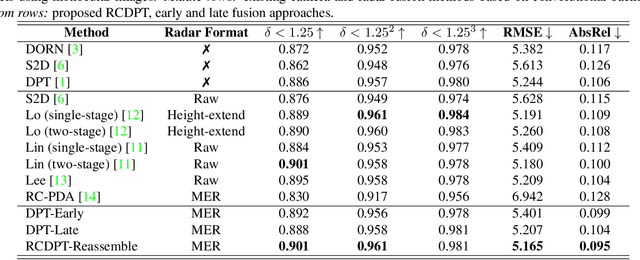

Recently, transformer networks have outperformed traditional deep neural networks in natural language processing and show a large potential in many computer vision tasks compared to convolutional backbones. In the original transformer, readout tokens are used as designated vectors for aggregating information from other tokens. However, the performance of using readout tokens in a vision transformer is limited. Therefore, we propose a novel fusion strategy to integrate radar data into a dense prediction transformer network by reassembling camera representations with radar representations. Instead of using readout tokens, radar representations contribute additional depth information to a monocular depth estimation model and improve performance. We further investigate different fusion approaches that are commonly used for integrating additional modality in a dense prediction transformer network. The experiments are conducted on the nuScenes dataset, which includes camera images, lidar, and radar data. The results show that our proposed method yields better performance than the commonly used fusion strategies and outperforms existing convolutional depth estimation models that fuse camera images and radar.
Probabilistic Deep Metric Learning for Hyperspectral Image Classification
Nov 15, 2022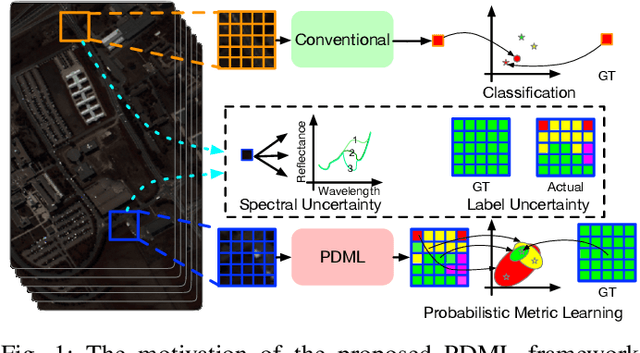
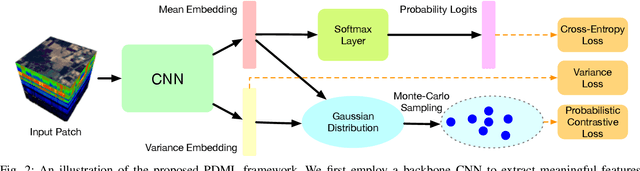
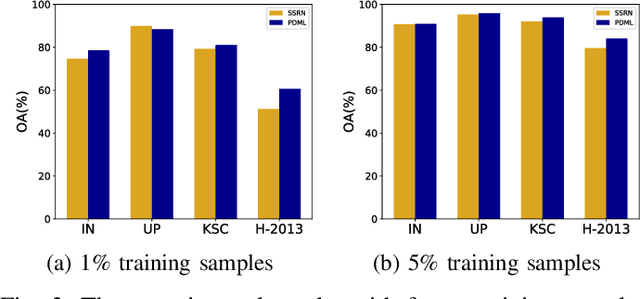
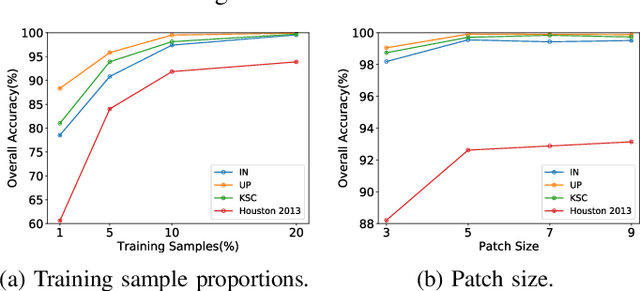
This paper proposes a probabilistic deep metric learning (PDML) framework for hyperspectral image classification, which aims to predict the category of each pixel for an image captured by hyperspectral sensors. The core problem for hyperspectral image classification is the spectral variability between intraclass materials and the spectral similarity between interclass materials, motivating the further incorporation of spatial information to differentiate a pixel based on its surrounding patch. However, different pixels and even the same pixel in one patch might not encode the same material due to the low spatial resolution of most hyperspectral sensors, leading to an inconsistent judgment of a specific pixel. To address this issue, we propose a probabilistic deep metric learning framework to model the categorical uncertainty of the spectral distribution of an observed pixel. We propose to learn a global probabilistic distribution for each pixel in the patch and a probabilistic metric to model the distance between distributions. We treat each pixel in a patch as a training sample, enabling us to exploit more information from the patch compared with conventional methods. Our framework can be readily applied to existing hyperspectral image classification methods with various network architectures and loss functions. Extensive experiments on four widely used datasets including IN, UP, KSC, and Houston 2013 datasets demonstrate that our framework improves the performance of existing methods and further achieves the state of the art. Code is available at: https://github.com/wzzheng/PDML.
Neighborhood Convolutional Network: A New Paradigm of Graph Neural Networks for Node Classification
Nov 15, 2022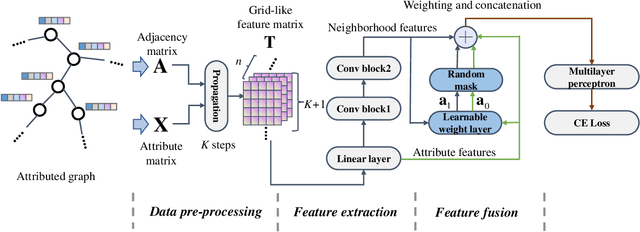
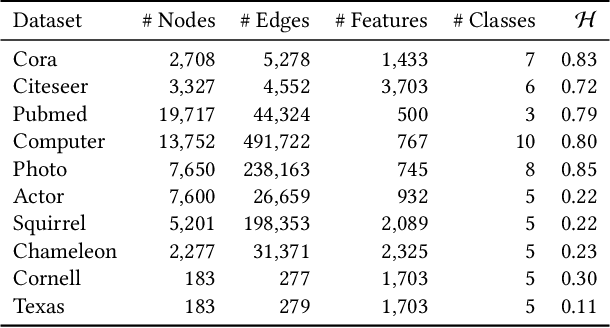
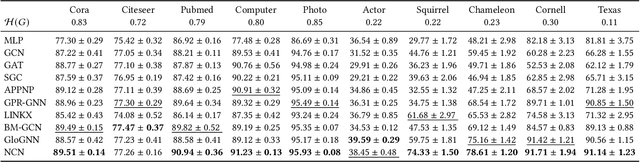
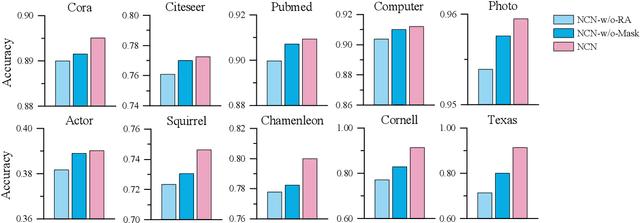
The decoupled Graph Convolutional Network (GCN), a recent development of GCN that decouples the neighborhood aggregation and feature transformation in each convolutional layer, has shown promising performance for graph representation learning. Existing decoupled GCNs first utilize a simple neural network (e.g., MLP) to learn the hidden features of the nodes, then propagate the learned features on the graph with fixed steps to aggregate the information of multi-hop neighborhoods. Despite effectiveness, the aggregation operation, which requires the whole adjacency matrix as the input, is involved in the model training, causing high training cost that hinders its potential on larger graphs. On the other hand, due to the independence of node attributes as the input, the neural networks used in decoupled GCNs are very simple, and advanced techniques cannot be applied to the modeling. To this end, we further liberate the aggregation operation from the decoupled GCN and propose a new paradigm of GCN, termed Neighborhood Convolutional Network (NCN), that utilizes the neighborhood aggregation result as the input, followed by a special convolutional neural network tailored for extracting expressive node representations from the aggregation input. In this way, the model could inherit the merit of decoupled GCN for aggregating neighborhood information, at the same time, develop much more powerful feature learning modules. A training strategy called mask training is incorporated to further boost the model performance. Extensive results demonstrate the effectiveness of our model for the node classification task on diverse homophilic graphs and heterophilic graphs.
FolkScope: Intention Knowledge Graph Construction for Discovering E-commerce Commonsense
Nov 15, 2022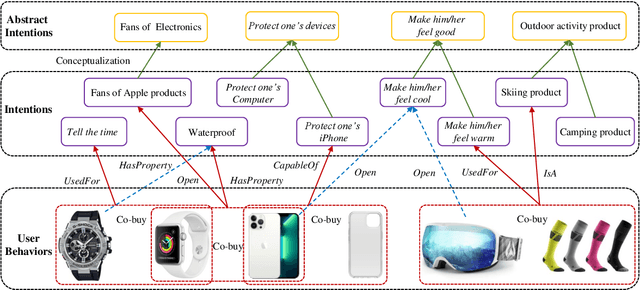
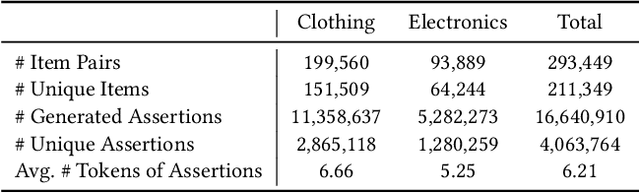
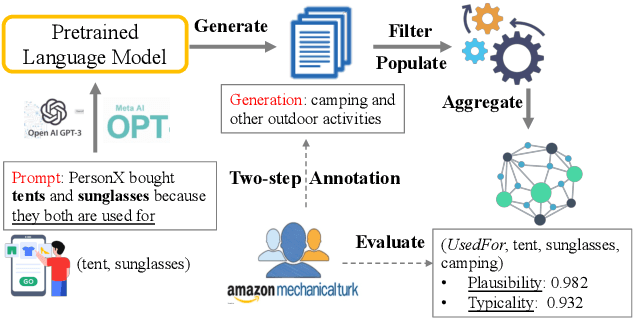
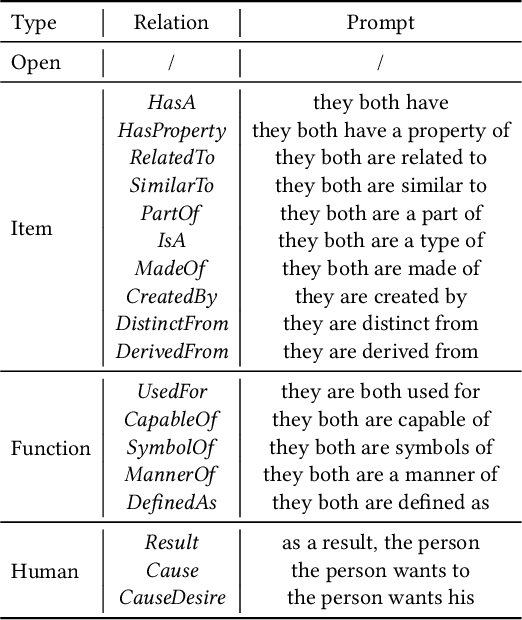
As stated by Oren Etzioni, ``commonsense is the dark matter of artificial intelligence''. In e-commerce, understanding users' needs or intentions requires substantial commonsense knowledge, e.g., ``A user bought an iPhone and a compatible case because the user wanted the phone to be protected''. In this paper, we present FolkScope, an intention knowledge graph construction framework, to reveal the structure of humans' minds about purchasing items on e-commerce platforms such as Amazon. As commonsense knowledge is usually ineffable and not expressed explicitly, it is challenging to perform any kind of information extraction. Thus, we propose a new approach that leverages the generation power of large-scale language models and human-in-the-loop annotations to semi-automatically construct the knowledge graph. We annotate a large amount of assertions for both plausibility and typicality of an intention that can explain a purchasing or co-purchasing behavior, where the intention can be an open reason or a predicate falling into one of 18 categories aligning with ConceptNet, e.g., IsA, MadeOf, UsedFor, etc. Then we populate the annotated information to all automatically generated ones, and further structurize the assertions using pattern mining and conceptualization to form more condensed and abstractive knowledge. We evaluate our knowledge graph using both intrinsic quality measures and a downstream application, i.e., recommendation. The comprehensive study shows that our knowledge graph can well model e-commerce commonsense knowledge and can have many potential applications.
Evaluating Feature Attribution: An Information-Theoretic Perspective
Feb 01, 2022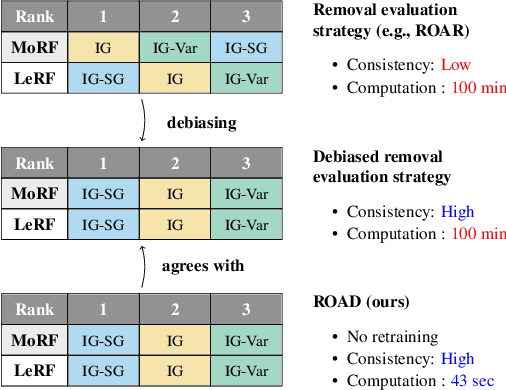

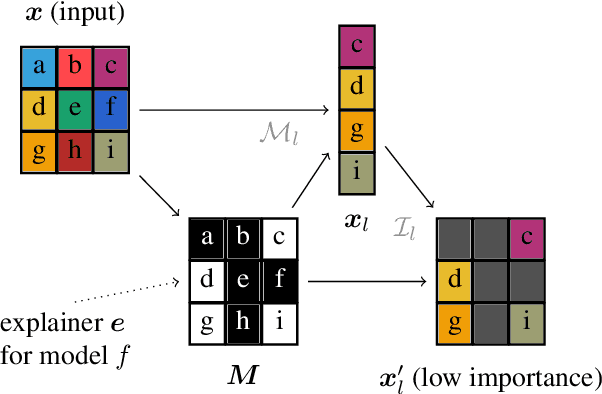
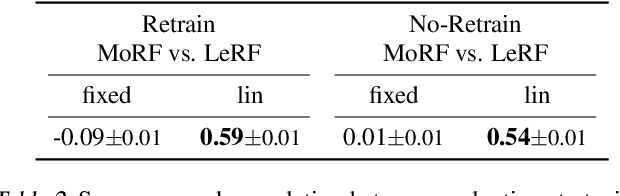
With a variety of local feature attribution methods being proposed in recent years, follow-up work suggested several evaluation strategies. To assess the attribution quality across different attribution techniques, the most popular among these evaluation strategies in the image domain use pixel perturbations. However, recent advances discovered that different evaluation strategies produce conflicting rankings of attribution methods and can be prohibitively expensive to compute. In this work, we present an information-theoretic analysis of evaluation strategies based on pixel perturbations. Our findings reveal that the results output by different evaluation strategies are strongly affected by information leakage through the shape of the removed pixels as opposed to their actual values. Using our theoretical insights, we propose a novel evaluation framework termed Remove and Debias (ROAD) which offers two contributions: First, it mitigates the impact of the confounders, which entails higher consistency among evaluation strategies. Second, ROAD does not require the computationally expensive retraining step and saves up to 99% in computational costs compared to the state-of-the-art. Our source code is available at https://github.com/tleemann/road_evaluation.