 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLAS: Coordinating Multi-Robot Manipulation with Central Latent Action Spaces
Nov 28, 2022
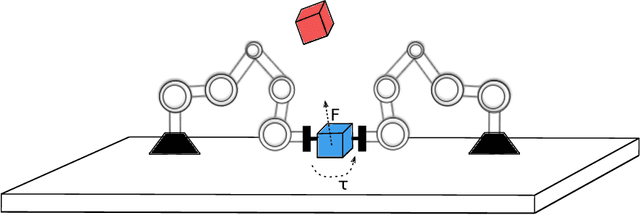
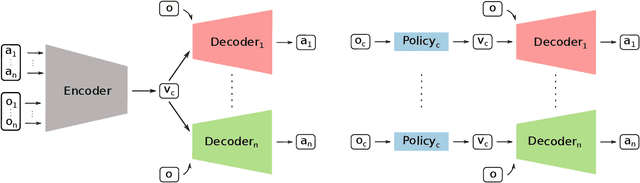
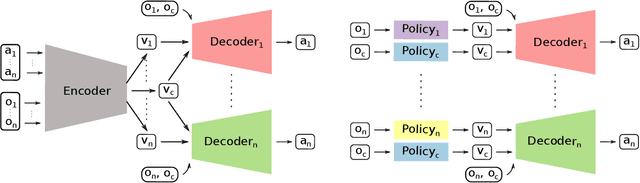

Multi-robot manipulation tasks involve various control entities that can be separated into dynamically independent parts. A typical example of such real-world tasks is dual-arm manipulation. Learning to naively solve such tasks with reinforcement learning is often unfeasible due to the sample complexity and exploration requirements growing with the dimensionality of the action and state spaces. Instead, we would like to handle such environments as multi-agent systems and have several agents control parts of the whole. However, decentralizing the generation of actions requires coordination across agents through a channel limited to information central to the task. This paper proposes an approach to coordinating multi-robot manipulation through learned latent action spaces that are shared across different agents. We validate our method in simulated multi-robot manipulation tasks and demonstrate improvement over previous baselines in terms of sample efficiency and learning performance.
Personalized Reward Learning with Interaction-Grounded Learning (IGL)
Nov 28, 2022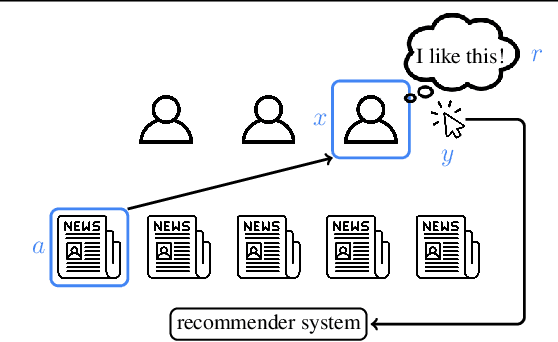



In an era of countless content offerings, recommender systems alleviate information overload by providing users with personalized content suggestions. Due to the scarcity of explicit user feedback, modern recommender systems typically optimize for the same fixed combination of implicit feedback signals across all users. However, this approach disregards a growing body of work highlighting that (i) implicit signals can be used by users in diverse ways, signaling anything from satisfaction to active dislike, and (ii) different users communicate preferences in different ways. We propose applying the recent Interaction Grounded Learning (IGL) paradigm to address the challenge of learning representations of diverse user communication modalities. Rather than taking a fixed, human-designed reward function, IGL is able to learn personalized reward functions for different users and then optimize directly for the latent user satisfaction. We demonstrate the success of IGL with experiments using simulations as well as with real-world production traces.
Two-stream Multi-dimensional Convolutional Network for Real-time Violence Detection
Nov 08, 2022
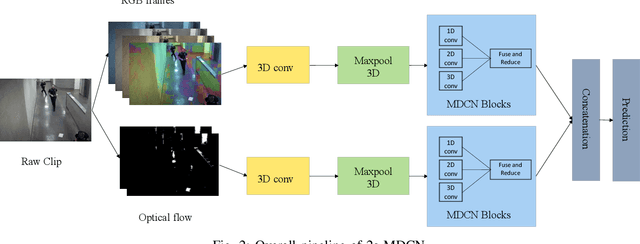
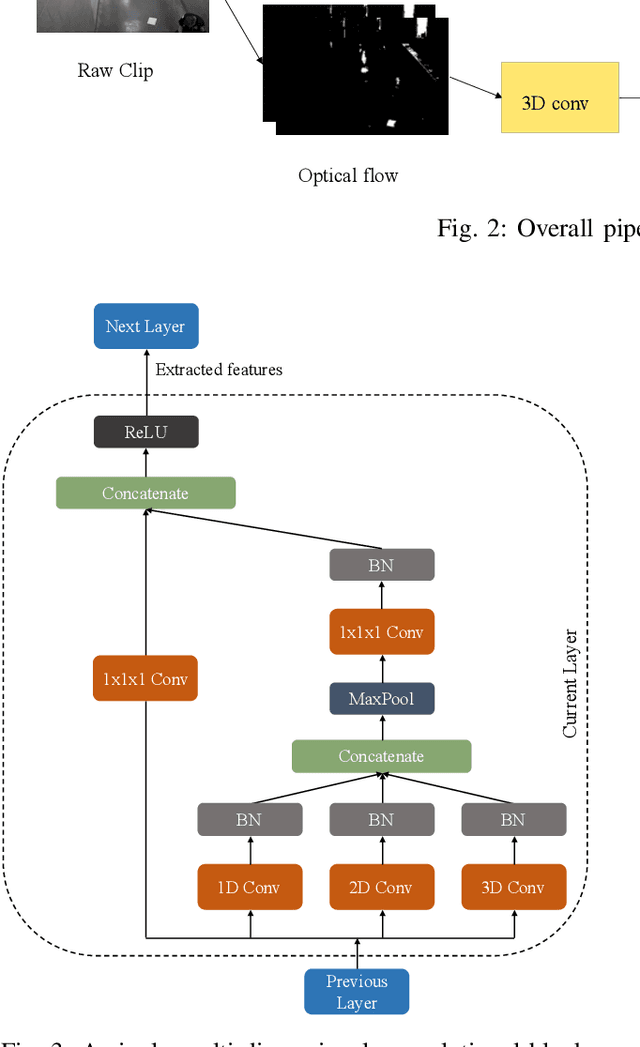
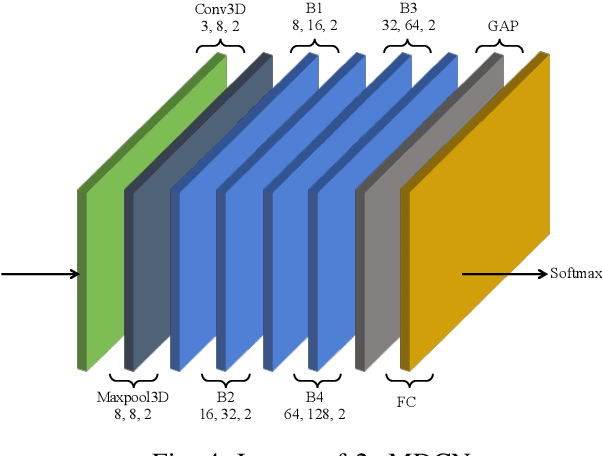
The increasing number of surveillance cameras and security concerns have made automatic violent activity detection from surveillance footage an active area for research. Modern deep learning methods have achieved good accuracy in violence detection and proved to be successful because of their applicability in intelligent surveillance systems. However, the models are computationally expensive and large in size because of their inefficient methods for feature extraction. This work presents a novel architecture for violence detection called Two-stream Multi-dimensional Convolutional Network (2s-MDCN), which uses RGB frames and optical flow to detect violence. Our proposed method extracts temporal and spatial information independently by 1D, 2D, and 3D convolutions. Despite combining multi-dimensional convolutional networks, our models are lightweight and efficient due to reduced channel capacity, yet they learn to extract meaningful spatial and temporal information. Additionally, combining RGB frames and optical flow yields 2.2% more accuracy than a single RGB stream. Regardless of having less complexity, our models obtained state-of-the-art accuracy of 89.7% on the largest violence detection benchmark dataset.
Query-Specific Knowledge Graphs for Complex Finance Topics
Nov 08, 2022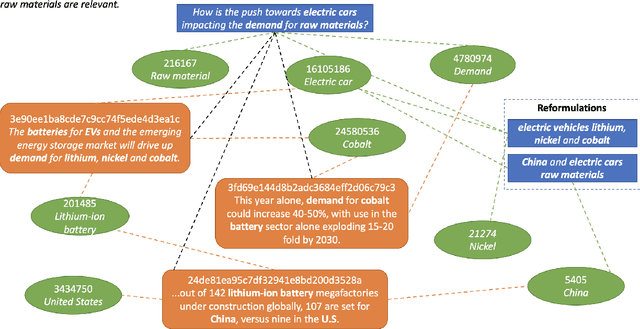
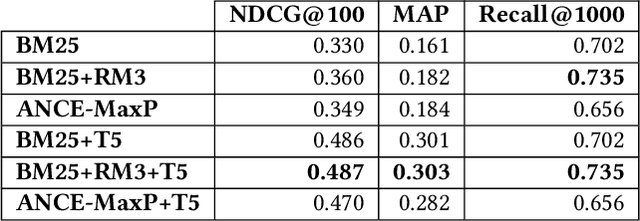

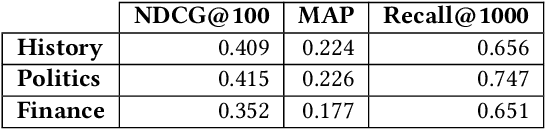
Across the financial domain, researchers answer complex questions by extensively "searching" for relevant information to generate long-form reports. This workshop paper discusses automating the construction of query-specific document and entity knowledge graphs (KGs) for complex research topics. We focus on the CODEC dataset, where domain experts (1) create challenging questions, (2) construct long natural language narratives, and (3) iteratively search and assess the relevance of documents and entities. For the construction of query-specific KGs, we show that state-of-the-art ranking systems have headroom for improvement, with specific failings due to a lack of context or explicit knowledge representation. We demonstrate that entity and document relevance are positively correlated, and that entity-based query feedback improves document ranking effectiveness. Furthermore, we construct query-specific KGs using retrieval and evaluate using CODEC's "ground-truth graphs", showing the precision and recall trade-offs. Lastly, we point to future work, including adaptive KG retrieval algorithms and GNN-based weighting methods, while highlighting key challenges such as high-quality data, information extraction recall, and the size and sparsity of complex topic graphs.
Digital twins of physical printing-imaging channel
Oct 28, 2022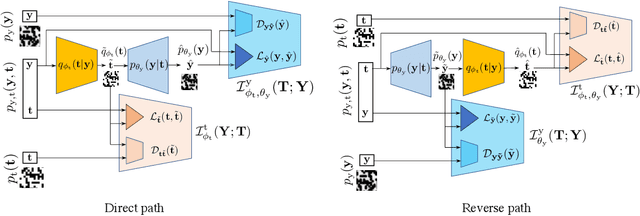
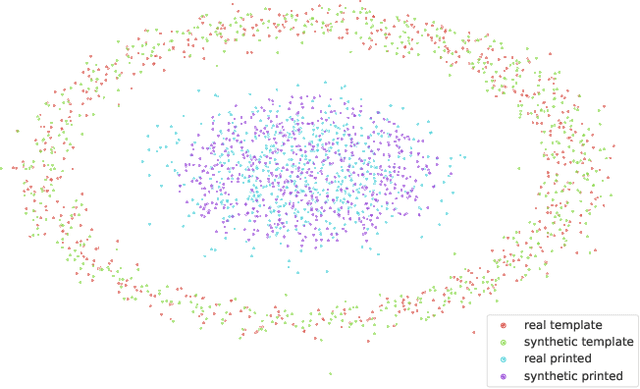
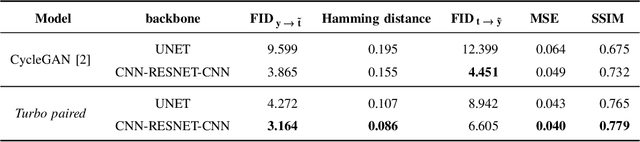
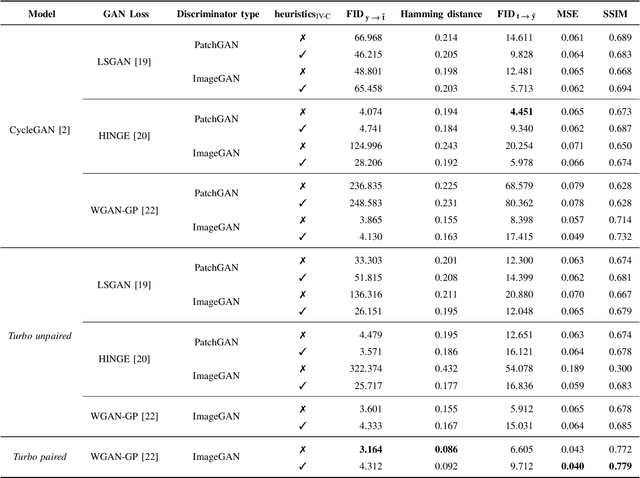
In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.
A Short Survey of Systematic Generalization
Nov 22, 2022This survey includes systematic generalization and a history of how machine learning addresses it. We aim to summarize and organize the related information of both conventional and recent improvements. We first look at the definition of systematic generalization, then introduce Classicist and Connectionist. We then discuss different types of Connectionists and how they approach the generalization. Two crucial problems of variable binding and causality are discussed. We look into systematic generalization in language, vision, and VQA fields. Recent improvements from different aspects are discussed. Systematic generalization has a long history in artificial intelligence. We could cover only a small portion of many contributions. We hope this paper provides a background and is beneficial for discoveries in future work.
Contextually Aware Intelligent Control Agents for Heterogeneous Swarms
Nov 22, 2022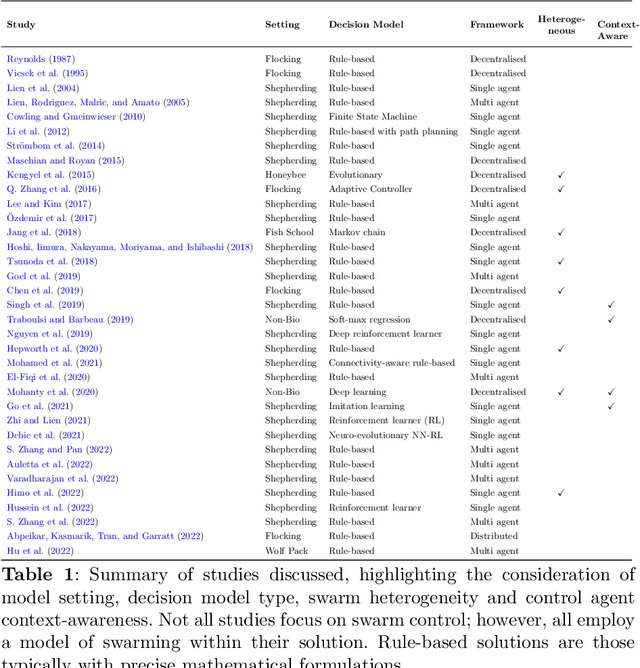
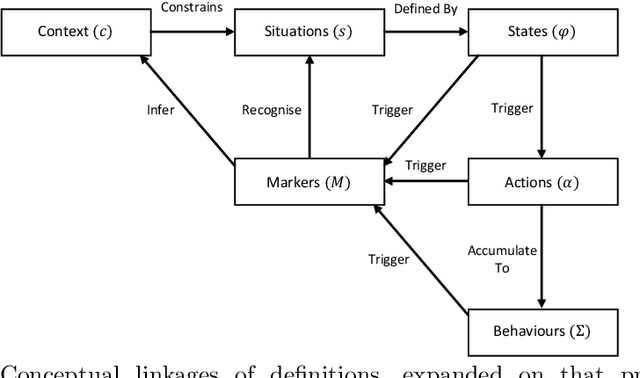
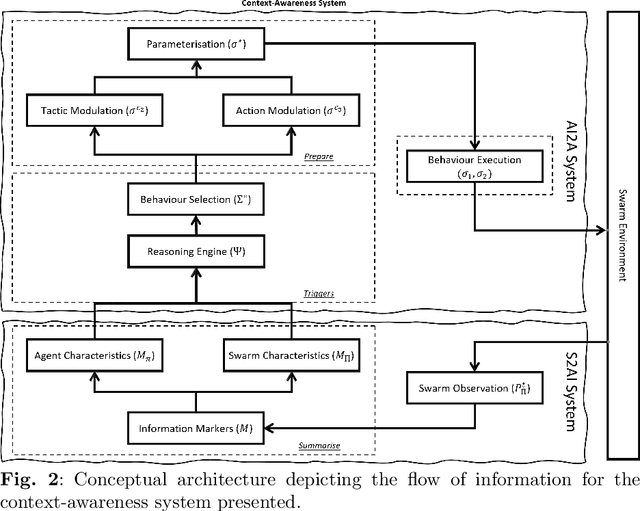
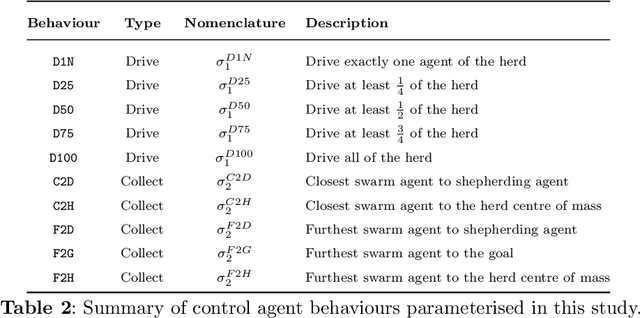
An emerging challenge in swarm shepherding research is to design effective and efficient artificial intelligence algorithms that maintain a low-computational ceiling while increasing the swarm's abilities to operate in diverse contexts. We propose a methodology to design a context-aware swarm-control intelligent agent. The intelligent control agent (shepherd) first uses swarm metrics to recognise the type of swarm it interacts with to then select a suitable parameterisation from its behavioural library for that particular swarm type. The design principle of our methodology is to increase the situation awareness (i.e. information contents) of the control agent without sacrificing the low-computational cost necessary for efficient swarm control. We demonstrate successful shepherding in both homogeneous and heterogeneous swarms.
Semantic Graph Neural Network with Multi-measure Learning for Semi-supervised Classification
Dec 04, 2022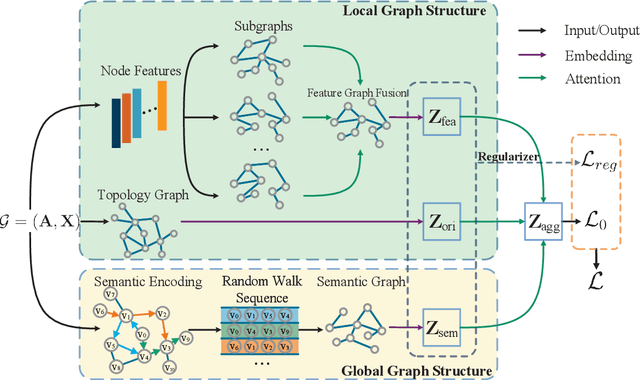
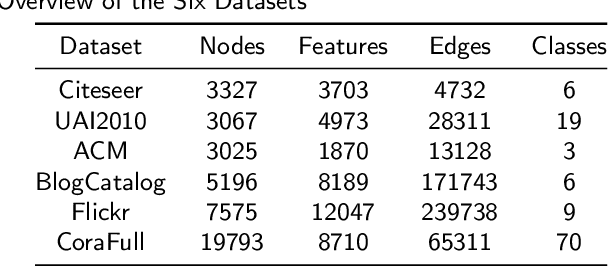
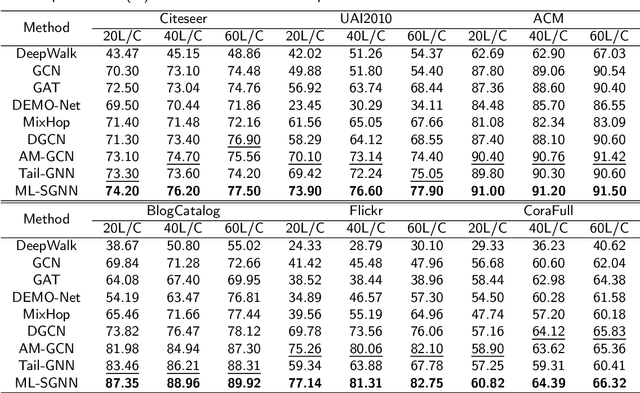
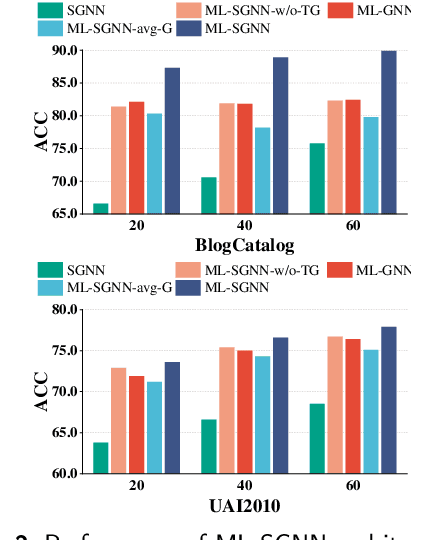
Graph Neural Networks (GNNs) have attracted increasing attention in recent years and have achieved excellent performance in semi-supervised node classification tasks. The success of most GNNs relies on one fundamental assumption, i.e., the original graph structure data is available. However, recent studies have shown that GNNs are vulnerable to the complex underlying structure of the graph, making it necessary to learn comprehensive and robust graph structures for downstream tasks, rather than relying only on the raw graph structure. In light of this, we seek to learn optimal graph structures for downstream tasks and propose a novel framework for semi-supervised classification. Specifically, based on the structural context information of graph and node representations, we encode the complex interactions in semantics and generate semantic graphs to preserve the global structure. Moreover, we develop a novel multi-measure attention layer to optimize the similarity rather than prescribing it a priori, so that the similarity can be adaptively evaluated by integrating measures. These graphs are fused and optimized together with GNN towards semi-supervised classification objective. Extensive experiments and ablation studies on six real-world datasets clearly demonstrate the effectiveness of our proposed model and the contribution of each component.
Tucker-O-Minus Decomposition for Multi-view Tensor Subspace Clustering
Oct 23, 2022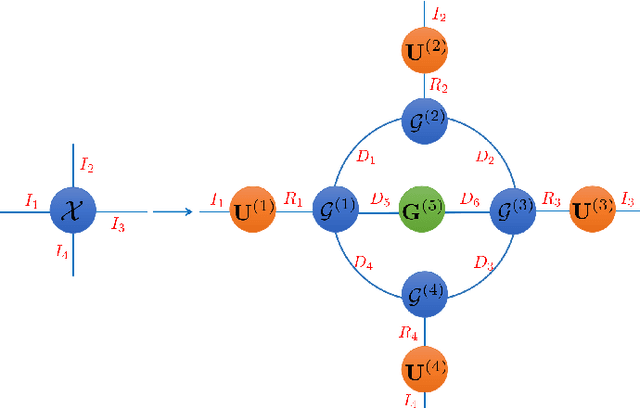

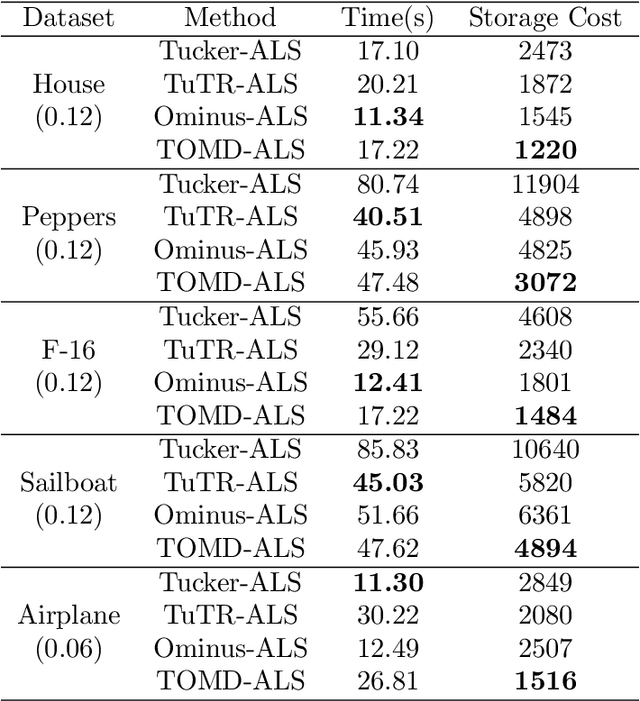
With powerful ability to exploit latent structure of self-representation information, different tensor decompositions have been employed into low rank multi-view clustering (LRMVC) models for achieving significant performance. However, current approaches suffer from a series of problems related to those tensor decomposition, such as the unbalanced matricization scheme, rotation sensitivity, deficient correlations capture and so forth. All these will lead to LRMVC having insufficient access to global information, which is contrary to the target of multi-view clustering. To alleviate these problems, we propose a new tensor decomposition called Tucker-O-Minus Decomposition (TOMD) for multi-view clustering. Specifically, based on the Tucker format, we additionally employ the O-minus structure, which consists of a circle with an efficient bridge linking two weekly correlated factors. In this way, the core tensor in Tucker format is replaced by the O-minus architecture with a more balanced structure, and the enhanced capacity of capturing the global low rank information will be achieved. The proposed TOMD also provides more compact and powerful representation abilities for the self-representation tensor, simultaneously. The alternating direction method of multipliers is used to solve the proposed model TOMD-MVC. Numerical experiments on six benchmark data sets demonstrate the superiority of our proposed method in terms of F-score, precision, recall, normalized mutual information, adjusted rand index, and accuracy.
CiaoSR: Continuous Implicit Attention-in-Attention Network for Arbitrary-Scale Image Super-Resolution
Dec 08, 2022
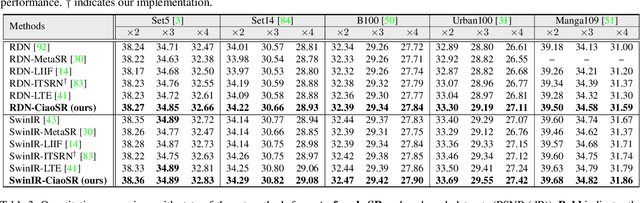
Learning continuous image representations is recently gaining popularity for image super-resolution (SR) because of its ability to reconstruct high-resolution images with arbitrary scales from low-resolution inputs. Existing methods mostly ensemble nearby features to predict the new pixel at any queried coordinate in the SR image. Such a local ensemble suffers from some limitations: i) it has no learnable parameters and it neglects the similarity of the visual features; ii) it has a limited receptive field and cannot ensemble relevant features in a large field which are important in an image; iii) it inherently has a gap with real camera imaging since it only depends on the coordinate. To address these issues, this paper proposes a continuous implicit attention-in-attention network, called CiaoSR. We explicitly design an implicit attention network to learn the ensemble weights for the nearby local features. Furthermore, we embed a scale-aware attention in this implicit attention network to exploit additional non-local information. Extensive experiments on benchmark datasets demonstrate CiaoSR significantly outperforms the existing single image super resolution (SISR) methods with the same backbone. In addition, the proposed method also achieves the state-of-the-art performance on the arbitrary-scale SR task. The effectiveness of the method is also demonstrated on the real-world SR setting. More importantly, CiaoSR can be flexibly integrated into any backbone to improve the SR performance.