 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scanpath Prediction on Information Visualisations
Dec 04, 2021
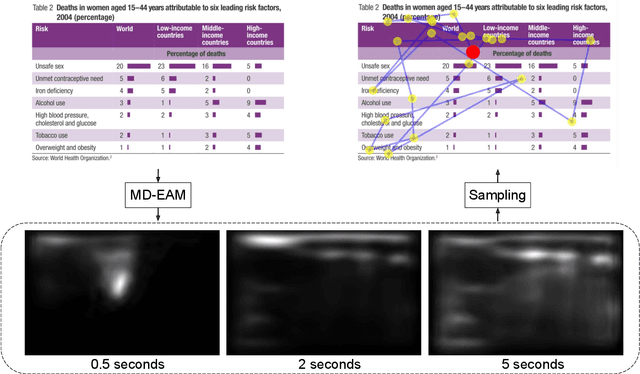
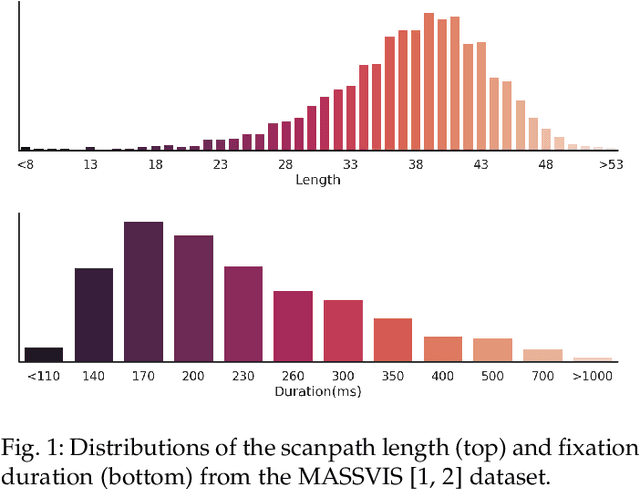
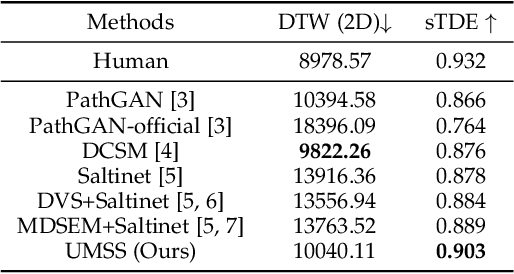
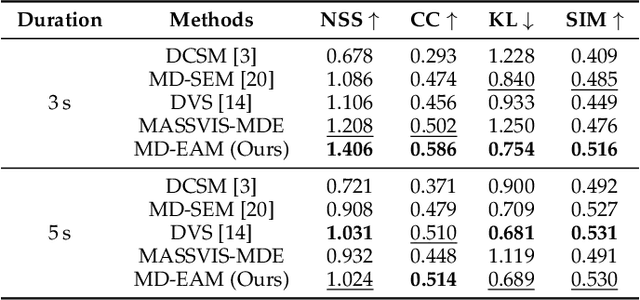
We propose Unified Model of Saliency and Scanpaths (UMSS) -- a model that learns to predict visual saliency and scanpaths (i.e. sequences of eye fixations) on information visualisations. Although scanpaths provide rich information about the importance of different visualisation elements during the visual exploration process, prior work has been limited to predicting aggregated attention statistics, such as visual saliency. We present in-depth analyses of gaze behaviour for different information visualisation elements (e.g. Title, Label, Data) on the popular MASSVIS dataset. We show that while, overall, gaze patterns are surprisingly consistent across visualisations and viewers, there are also structural differences in gaze dynamics for different elements. Informed by our analyses, UMSS first predicts multi-duration element-level saliency maps, then probabilistically samples scanpaths from them. Extensive experiments on MASSVIS show that our method consistently outperforms state-of-the-art methods with respect to several, widely used scanpath and saliency evaluation metrics. Our method achieves a relative improvement in sequence score of 11.5% for scanpath prediction, and a relative improvement in Pearson correlation coefficient of up to 23.6% for saliency prediction. These results are auspicious and point towards richer user models and simulations of visual attention on visualisations without the need for any eye tracking equipment.
Tucker-O-Minus Decomposition for Multi-view Tensor Subspace Clustering
Oct 23, 2022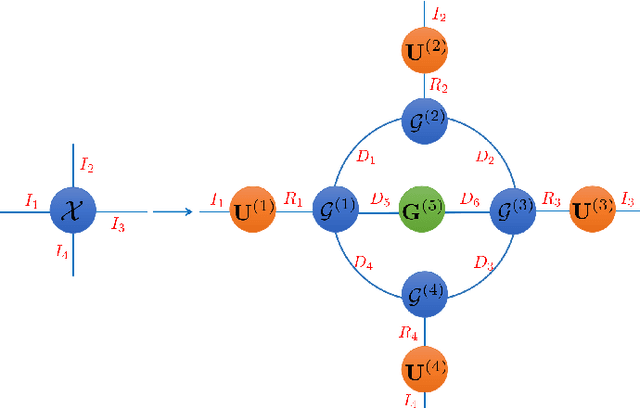

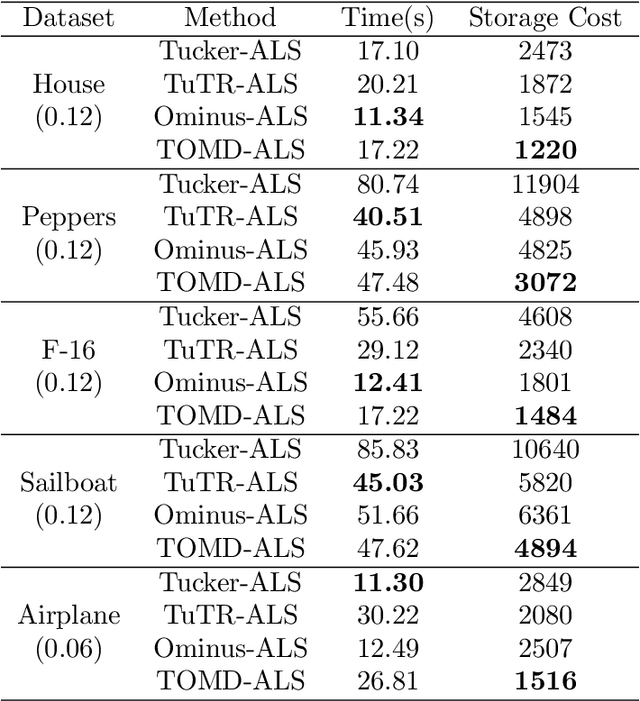
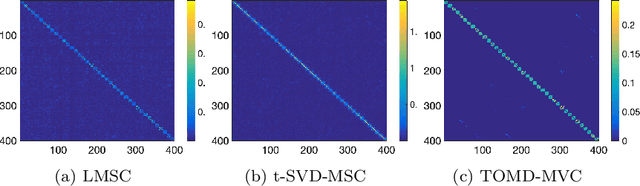
With powerful ability to exploit latent structure of self-representation information, different tensor decompositions have been employed into low rank multi-view clustering (LRMVC) models for achieving significant performance. However, current approaches suffer from a series of problems related to those tensor decomposition, such as the unbalanced matricization scheme, rotation sensitivity, deficient correlations capture and so forth. All these will lead to LRMVC having insufficient access to global information, which is contrary to the target of multi-view clustering. To alleviate these problems, we propose a new tensor decomposition called Tucker-O-Minus Decomposition (TOMD) for multi-view clustering. Specifically, based on the Tucker format, we additionally employ the O-minus structure, which consists of a circle with an efficient bridge linking two weekly correlated factors. In this way, the core tensor in Tucker format is replaced by the O-minus architecture with a more balanced structure, and the enhanced capacity of capturing the global low rank information will be achieved. The proposed TOMD also provides more compact and powerful representation abilities for the self-representation tensor, simultaneously. The alternating direction method of multipliers is used to solve the proposed model TOMD-MVC. Numerical experiments on six benchmark data sets demonstrate the superiority of our proposed method in terms of F-score, precision, recall, normalized mutual information, adjusted rand index, and accuracy.
Observable Perfect Equilibrium
Nov 01, 2022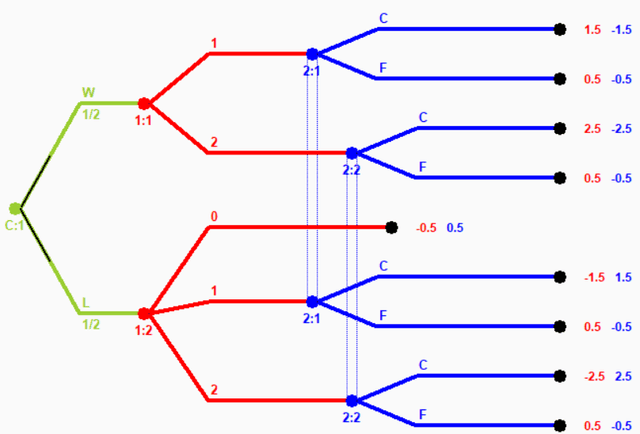
While Nash equilibrium has emerged as the central game-theoretic solution concept, many important games contain several Nash equilibria and we must determine how to select between them in order to create real strategic agents. Several Nash equilibrium refinement concepts have been proposed and studied for sequential imperfect-information games, the most prominent being trembling-hand perfect equilibrium, quasi-perfect equilibrium, and recently one-sided quasi-perfect equilibrium. These concepts are robust to certain arbitrarily small mistakes, and are guaranteed to always exist; however, we argue that neither of these is the correct concept for developing strong agents in sequential games of imperfect information. We define a new equilibrium refinement concept for extensive-form games called observable perfect equilibrium in which the solution is robust over trembles in publicly-observable action probabilities (not necessarily over all action probabilities that may not be observable by opposing players). Observable perfect equilibrium correctly captures the assumption that the opponent is playing as rationally as possible given mistakes that have been observed (while previous solution concepts do not). We prove that observable perfect equilibrium is always guaranteed to exist, and demonstrate that it leads to a different solution than the prior extensive-form refinements in no-limit poker. We expect observable perfect equilibrium to be a useful equilibrium refinement concept for modeling many important imperfect-information games of interest in artificial intelligence.
Digital twins of physical printing-imaging channel
Oct 28, 2022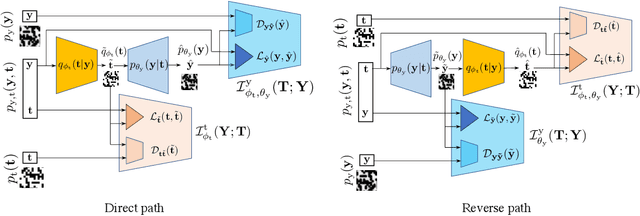
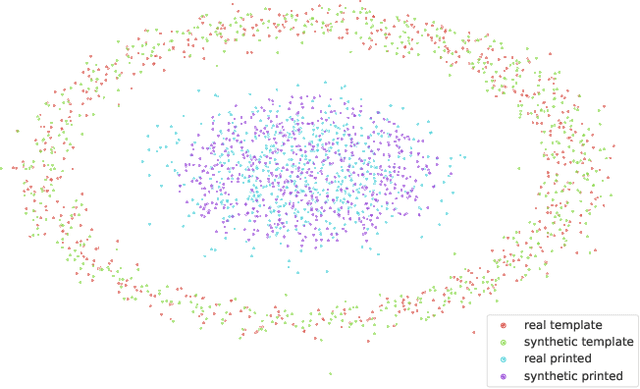
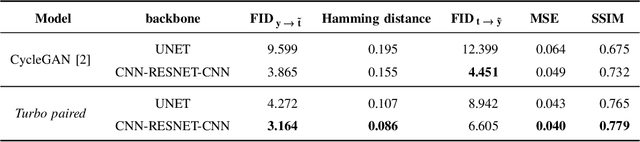
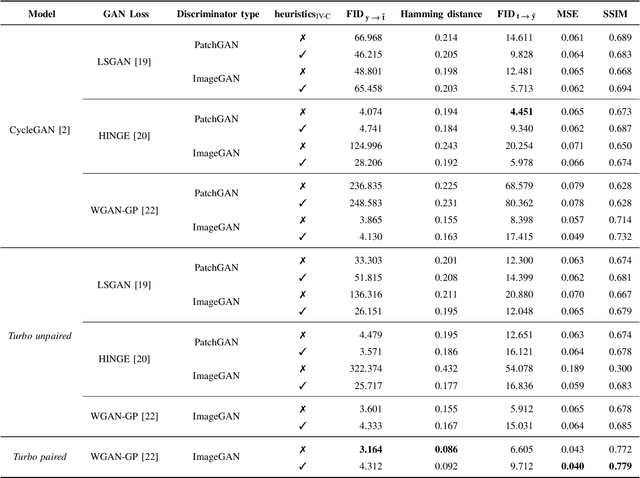
In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.
Self-supervised vision-language pretraining for Medical visual question answering
Nov 24, 2022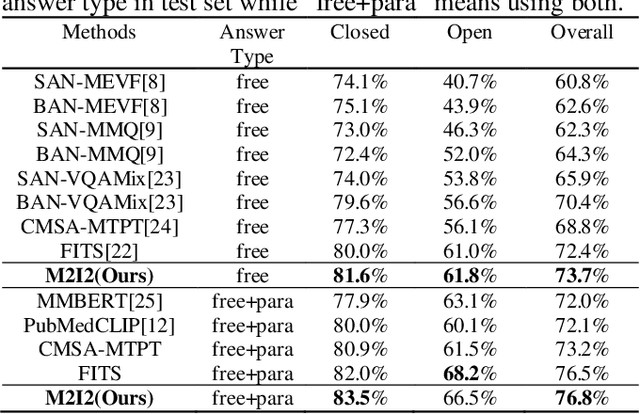
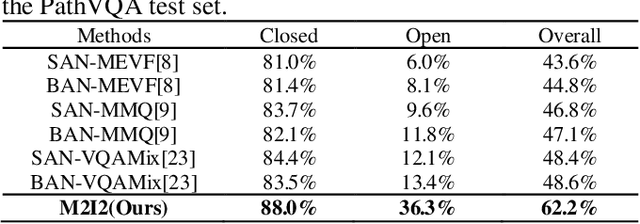
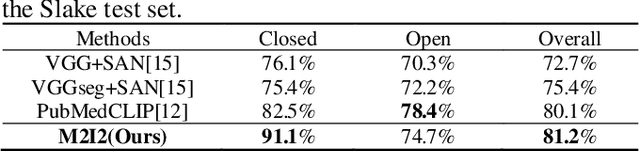
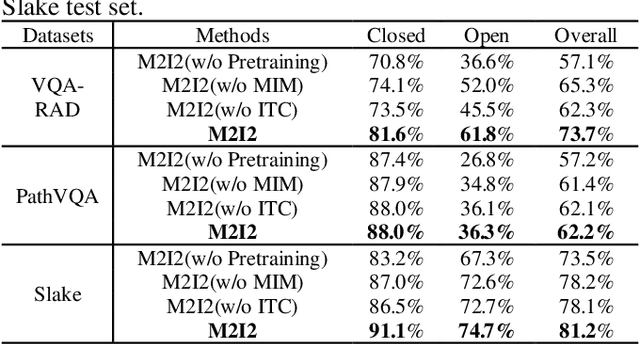
Medical image visual question answering (VQA) is a task to answer clinical questions, given a radiographic image, which is a challenging problem that requires a model to integrate both vision and language information. To solve medical VQA problems with a limited number of training data, pretrain-finetune paradigm is widely used to improve the model generalization. In this paper, we propose a self-supervised method that applies Masked image modeling, Masked language modeling, Image text matching and Image text alignment via contrastive learning (M2I2) for pretraining on medical image caption dataset, and finetunes to downstream medical VQA tasks. The proposed method achieves state-of-the-art performance on all the three public medical VQA datasets. Our codes and models are available at https://github.com/pengfeiliHEU/M2I2.
Query-Specific Knowledge Graphs for Complex Finance Topics
Nov 08, 2022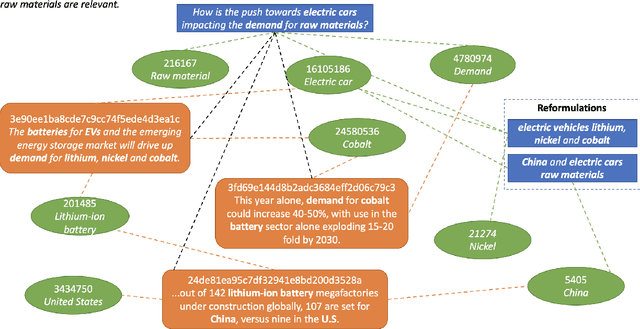
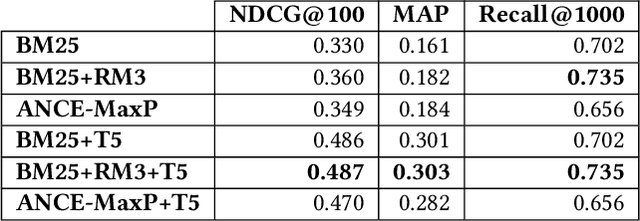

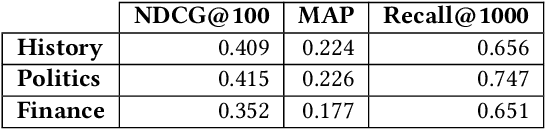
Across the financial domain, researchers answer complex questions by extensively "searching" for relevant information to generate long-form reports. This workshop paper discusses automating the construction of query-specific document and entity knowledge graphs (KGs) for complex research topics. We focus on the CODEC dataset, where domain experts (1) create challenging questions, (2) construct long natural language narratives, and (3) iteratively search and assess the relevance of documents and entities. For the construction of query-specific KGs, we show that state-of-the-art ranking systems have headroom for improvement, with specific failings due to a lack of context or explicit knowledge representation. We demonstrate that entity and document relevance are positively correlated, and that entity-based query feedback improves document ranking effectiveness. Furthermore, we construct query-specific KGs using retrieval and evaluate using CODEC's "ground-truth graphs", showing the precision and recall trade-offs. Lastly, we point to future work, including adaptive KG retrieval algorithms and GNN-based weighting methods, while highlighting key challenges such as high-quality data, information extraction recall, and the size and sparsity of complex topic graphs.
Two-stream Multi-dimensional Convolutional Network for Real-time Violence Detection
Nov 08, 2022
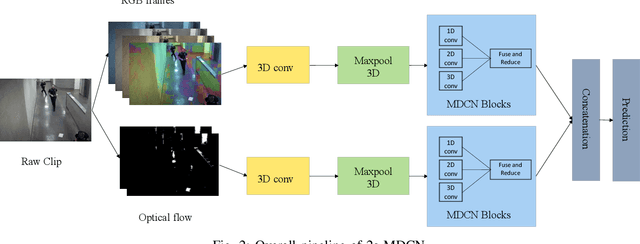
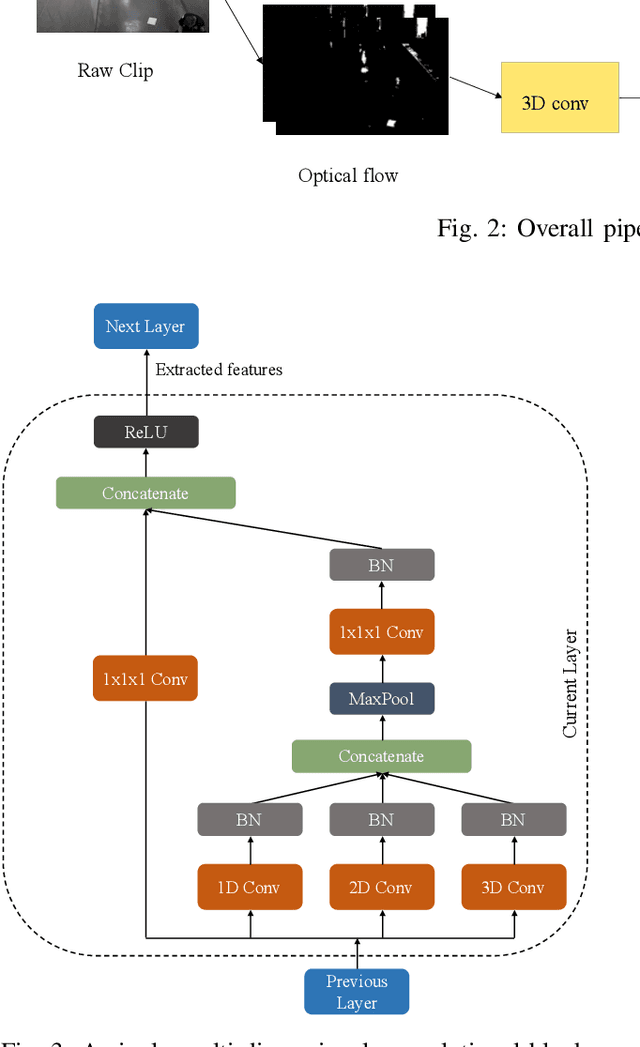
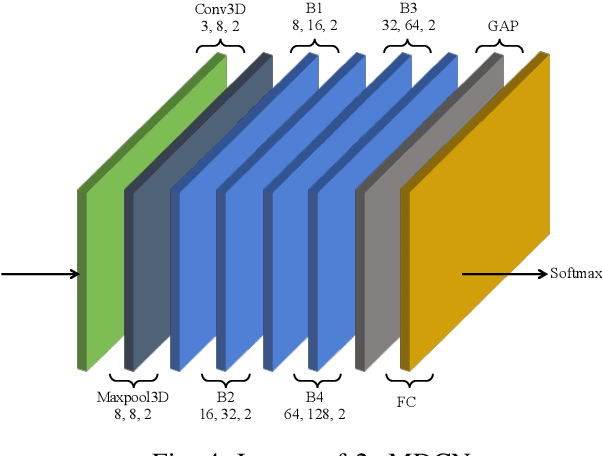
The increasing number of surveillance cameras and security concerns have made automatic violent activity detection from surveillance footage an active area for research. Modern deep learning methods have achieved good accuracy in violence detection and proved to be successful because of their applicability in intelligent surveillance systems. However, the models are computationally expensive and large in size because of their inefficient methods for feature extraction. This work presents a novel architecture for violence detection called Two-stream Multi-dimensional Convolutional Network (2s-MDCN), which uses RGB frames and optical flow to detect violence. Our proposed method extracts temporal and spatial information independently by 1D, 2D, and 3D convolutions. Despite combining multi-dimensional convolutional networks, our models are lightweight and efficient due to reduced channel capacity, yet they learn to extract meaningful spatial and temporal information. Additionally, combining RGB frames and optical flow yields 2.2% more accuracy than a single RGB stream. Regardless of having less complexity, our models obtained state-of-the-art accuracy of 89.7% on the largest violence detection benchmark dataset.
Improving Biomedical Information Retrieval with Neural Retrievers
Jan 19, 2022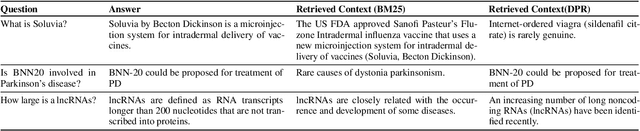
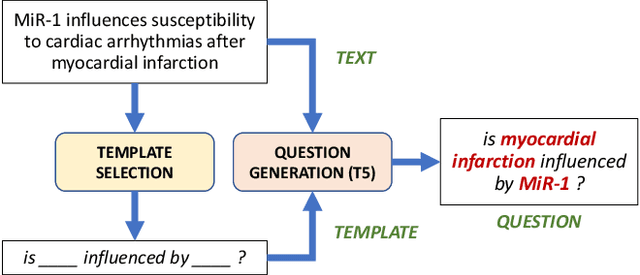

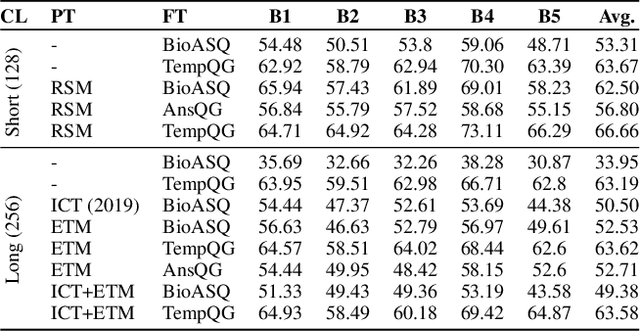
Information retrieval (IR) is essential in search engines and dialogue systems as well as natural language processing tasks such as open-domain question answering. IR serve an important function in the biomedical domain, where content and sources of scientific knowledge may evolve rapidly. Although neural retrievers have surpassed traditional IR approaches such as TF-IDF and BM25 in standard open-domain question answering tasks, they are still found lacking in the biomedical domain. In this paper, we seek to improve information retrieval (IR) using neural retrievers (NR) in the biomedical domain, and achieve this goal using a three-pronged approach. First, to tackle the relative lack of data in the biomedical domain, we propose a template-based question generation method that can be leveraged to train neural retriever models. Second, we develop two novel pre-training tasks that are closely aligned to the downstream task of information retrieval. Third, we introduce the ``Poly-DPR'' model which encodes each context into multiple context vectors. Extensive experiments and analysis on the BioASQ challenge suggest that our proposed method leads to large gains over existing neural approaches and beats BM25 in the small-corpus setting. We show that BM25 and our method can complement each other, and a simple hybrid model leads to further gains in the large corpus setting.
A Library Perspective on Nearly-Unsupervised Information Extraction Workflows in Digital Libraries
May 02, 2022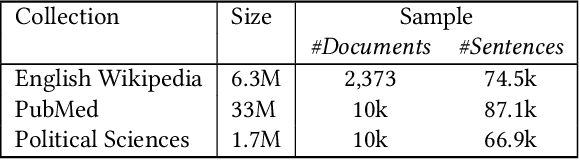



Information extraction can support novel and effective access paths for digital libraries. Nevertheless, designing reliable extraction workflows can be cost-intensive in practice. On the one hand, suitable extraction methods rely on domain-specific training data. On the other hand, unsupervised and open extraction methods usually produce not-canonicalized extraction results. This paper tackles the question how digital libraries can handle such extractions and if their quality is sufficient in practice. We focus on unsupervised extraction workflows by analyzing them in case studies in the domains of encyclopedias (Wikipedia), pharmacy and political sciences. We report on opportunities and limitations. Finally we discuss best practices for unsupervised extraction workflows.
Neural Radiance Fields for Manhattan Scenes with Unknown Manhattan Frame
Dec 02, 2022
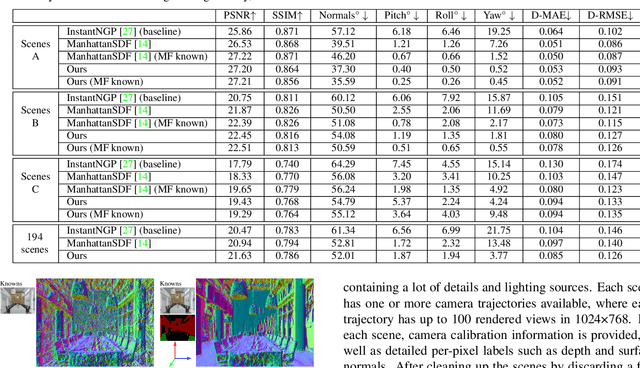
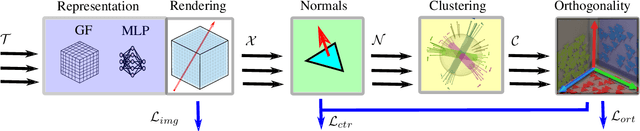
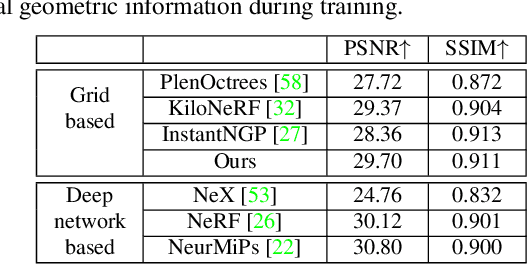
Novel view synthesis and 3D modeling using implicit neural field representation are shown to be very effective for calibrated multi-view cameras. Such representations are known to benefit from additional geometric and semantic supervision. Most existing methods that exploit additional supervision require dense pixel-wise labels or localized scene priors. These methods cannot benefit from high-level vague scene priors provided in terms of scenes' descriptions. In this work, we aim to leverage the geometric prior of Manhattan scenes to improve the implicit neural radiance field representations. More precisely, we assume that only the knowledge of the scene (under investigation) being Manhattan is known - with no additional information whatsoever - with an unknown Manhattan coordinate frame. Such high-level prior is then used to self-supervise the surface normals derived explicitly in the implicit neural fields. Our modeling allows us to group the derived normals, followed by exploiting their orthogonality constraints for self-supervision. Our exhaustive experiments on datasets of diverse indoor scenes demonstrate the significant benefit of the proposed method over the established baselines.