 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild
Nov 23, 2022
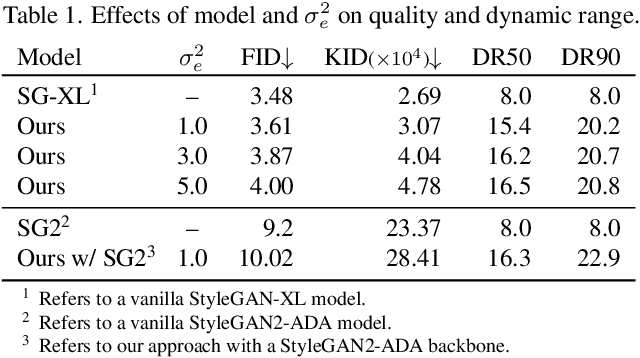

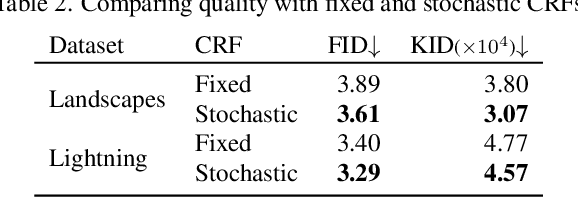
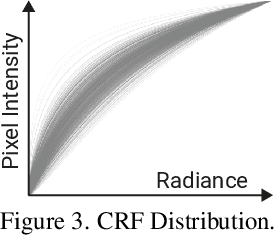
Most in-the-wild images are stored in Low Dynamic Range (LDR) form, serving as a partial observation of the High Dynamic Range (HDR) visual world. Despite limited dynamic range, these LDR images are often captured with different exposures, implicitly containing information about the underlying HDR image distribution. Inspired by this intuition, in this work we present, to the best of our knowledge, the first method for learning a generative model of HDR images from in-the-wild LDR image collections in a fully unsupervised manner. The key idea is to train a generative adversarial network (GAN) to generate HDR images which, when projected to LDR under various exposures, are indistinguishable from real LDR images. The projection from HDR to LDR is achieved via a camera model that captures the stochasticity in exposure and camera response function. Experiments show that our method GlowGAN can synthesize photorealistic HDR images in many challenging cases such as landscapes, lightning, or windows, where previous supervised generative models produce overexposed images. We further demonstrate the new application of unsupervised inverse tone mapping (ITM) enabled by GlowGAN. Our ITM method does not need HDR images or paired multi-exposure images for training, yet it reconstructs more plausible information for overexposed regions than state-of-the-art supervised learning models trained on such data.
Contrastive Masked Autoencoders for Self-Supervised Video Hashing
Nov 23, 2022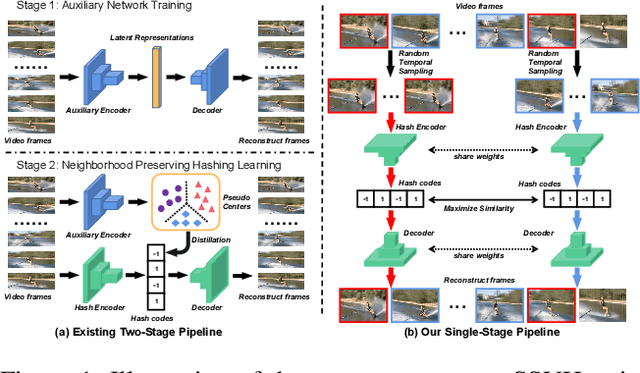

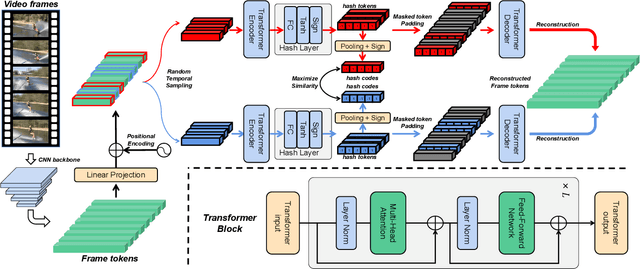
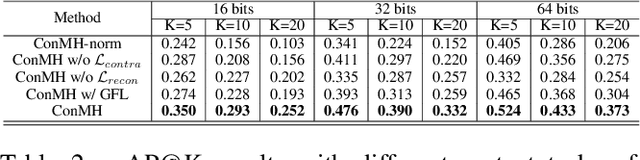
Self-Supervised Video Hashing (SSVH) models learn to generate short binary representations for videos without ground-truth supervision, facilitating large-scale video retrieval efficiency and attracting increasing research attention. The success of SSVH lies in the understanding of video content and the ability to capture the semantic relation among unlabeled videos. Typically, state-of-the-art SSVH methods consider these two points in a two-stage training pipeline, where they firstly train an auxiliary network by instance-wise mask-and-predict tasks and secondly train a hashing model to preserve the pseudo-neighborhood structure transferred from the auxiliary network. This consecutive training strategy is inflexible and also unnecessary. In this paper, we propose a simple yet effective one-stage SSVH method called ConMH, which incorporates video semantic information and video similarity relationship understanding in a single stage. To capture video semantic information for better hashing learning, we adopt an encoder-decoder structure to reconstruct the video from its temporal-masked frames. Particularly, we find that a higher masking ratio helps video understanding. Besides, we fully exploit the similarity relationship between videos by maximizing agreement between two augmented views of a video, which contributes to more discriminative and robust hash codes. Extensive experiments on three large-scale video datasets (i.e., FCVID, ActivityNet and YFCC) indicate that ConMH achieves state-of-the-art results. Code is available at https://github.com/huangmozhi9527/ConMH.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Nov 23, 2022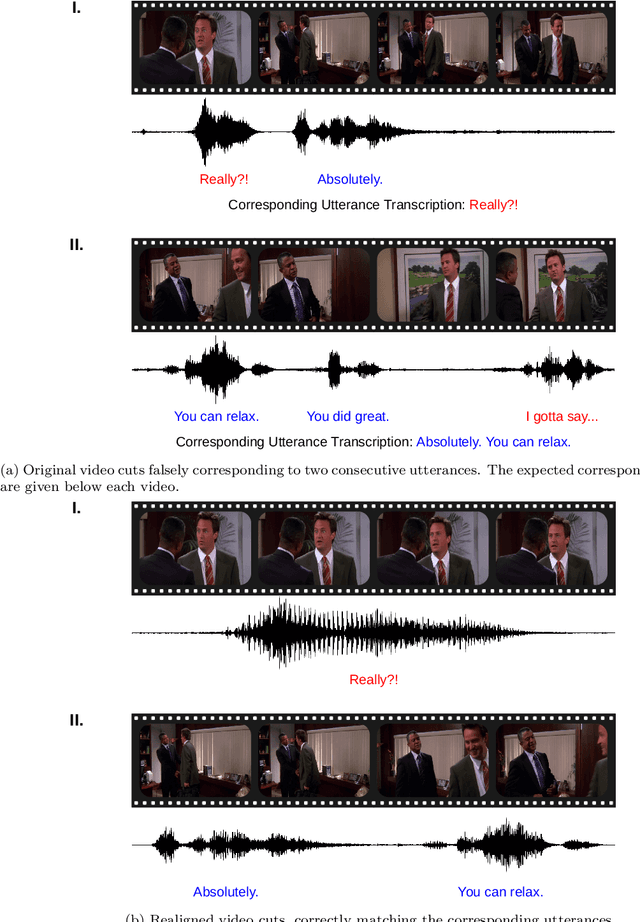

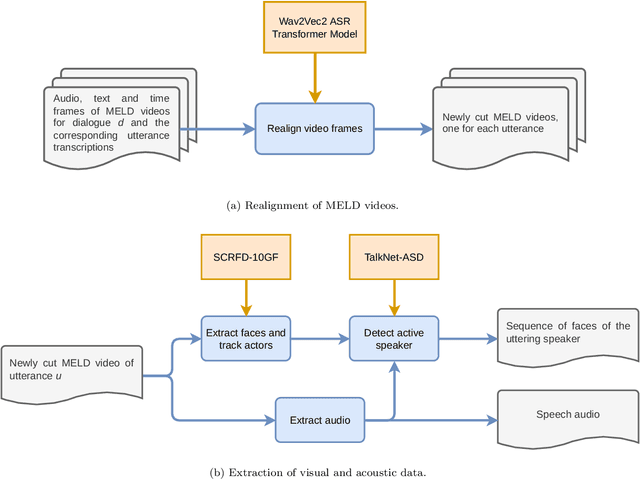
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
Resolution enhancement of NMR by decoupling with low-rank Hankel model
Dec 02, 2022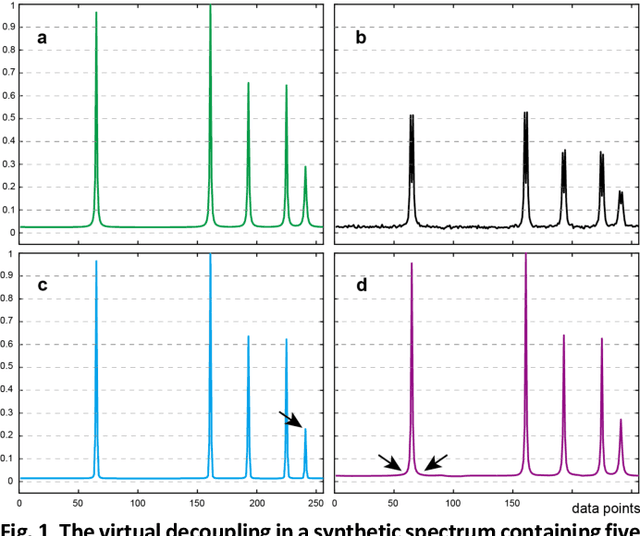
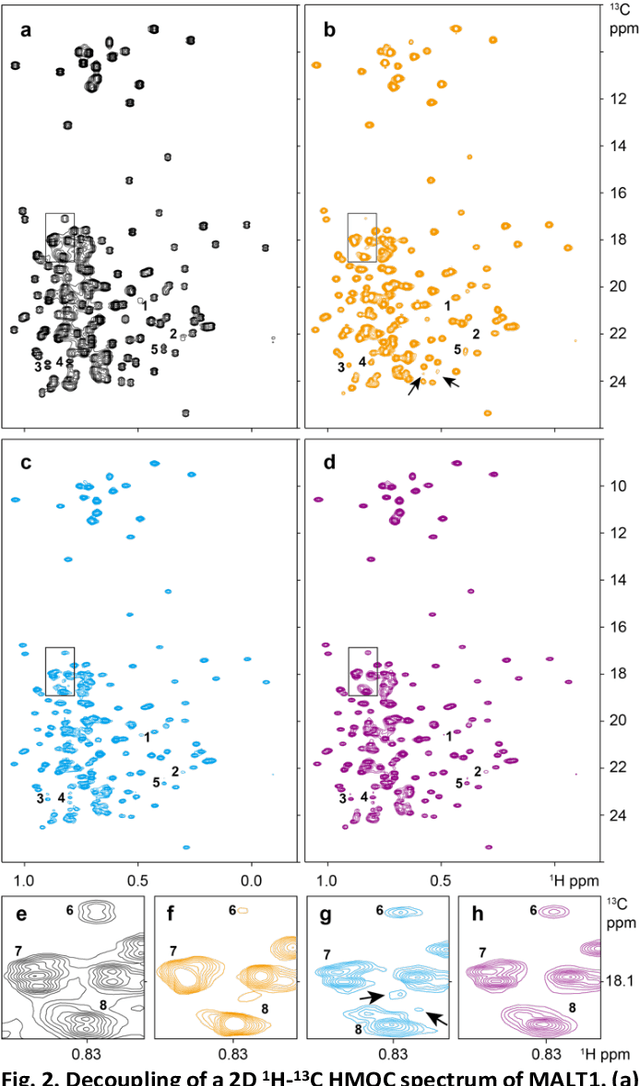
Nuclear magnetic resonance (NMR) spectroscopy has become a formidable tool for biochemistry and medicine. Although J-coupling carries essential structural information it may also limit the spectral resolution. Homonuclear decoupling remains a challenging problem. In this work, we introduce a new approach that uses a specific coupling value as prior knowledge, and Hankel property of exponential NMR signal to achieve the broadband heteronuclear decoupling using the low-rank method. Our results on synthetic and realistic HMQC spectra demonstrate that the proposed method not only effectively enhances resolution by decoupling, but also maintains sensitivity and suppresses spectral artefacts. The approach can be combined with the non-uniform sampling, which means that the resolution can be further improved without any extra acquisition time
Models for information propagation on graphs
Jan 19, 2022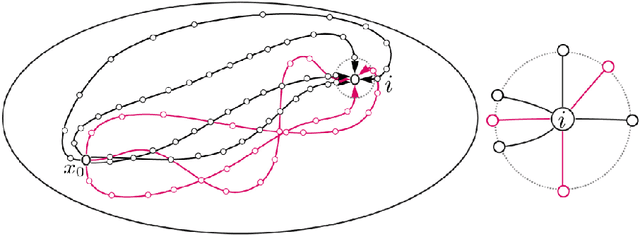

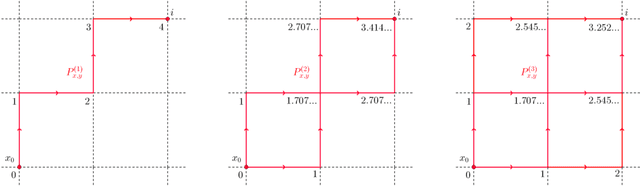
In this work we propose and unify classes of different models for information propagation over graphs. In a first class, propagation is modeled as a wave which emanates from a set of known nodes at an initial time, to all other unknown nodes at later times with an ordering determined by the time at which the information wave front reaches nodes. A second class of models is based on the notion of a travel time along paths between nodes. The time of information propagation from an initial known set of nodes to a node is defined as the minimum of a generalized travel time over subsets of all admissible paths. A final class is given by imposing a local equation of an eikonal form at each unknown node, with boundary conditions at the known nodes. The solution value of the local equation at a node is coupled the neighbouring nodes with smaller solution values. We provide precise formulations of the model classes in this graph setting, and prove equivalences between them. Motivated by the connection between first arrival time model and the eikonal equation in the continuum setting, we demonstrate that for graphs in the particular form of grids in Euclidean space mean field limits under grid refinement of certain graph models lead to Hamilton-Jacobi PDEs. For a specific parameter setting, we demonstrate that the solution on the grid approximates the Euclidean distance.
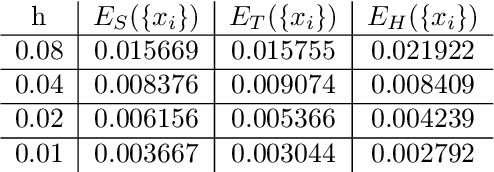
Improving Chest X-Ray Classification by RNN-based Patient Monitoring
Oct 28, 2022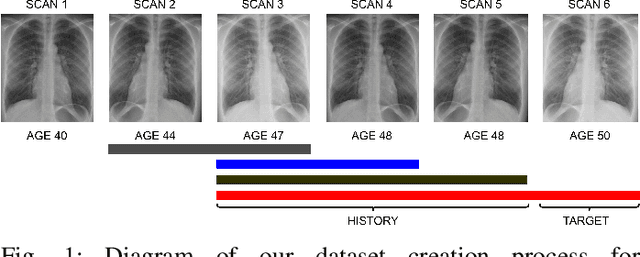
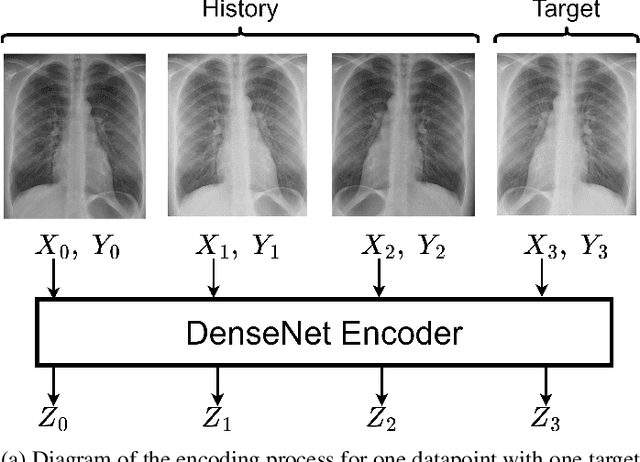

Chest X-Ray imaging is one of the most common radiological tools for detection of various pathologies related to the chest area and lung function. In a clinical setting, automated assessment of chest radiographs has the potential of assisting physicians in their decision making process and optimize clinical workflows, for example by prioritizing emergency patients. Most work analyzing the potential of machine learning models to classify chest X-ray images focuses on vision methods processing and predicting pathologies for one image at a time. However, many patients undergo such a procedure multiple times during course of a treatment or during a single hospital stay. The patient history, that is previous images and especially the corresponding diagnosis contain useful information that can aid a classification system in its prediction. In this study, we analyze how information about diagnosis can improve CNN-based image classification models by constructing a novel dataset from the well studied CheXpert dataset of chest X-rays. We show that a model trained on additional patient history information outperforms a model trained without the information by a significant margin. We provide code to replicate the dataset creation and model training.
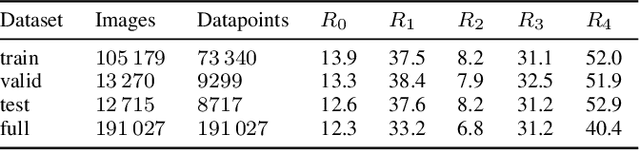
Neuromorphic Computing and Sensing in Space
Dec 10, 2022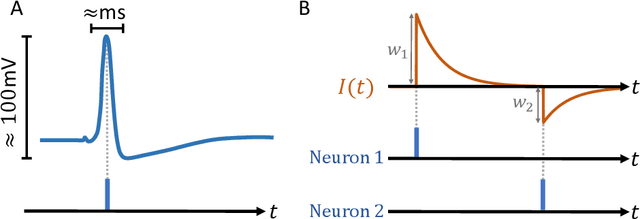
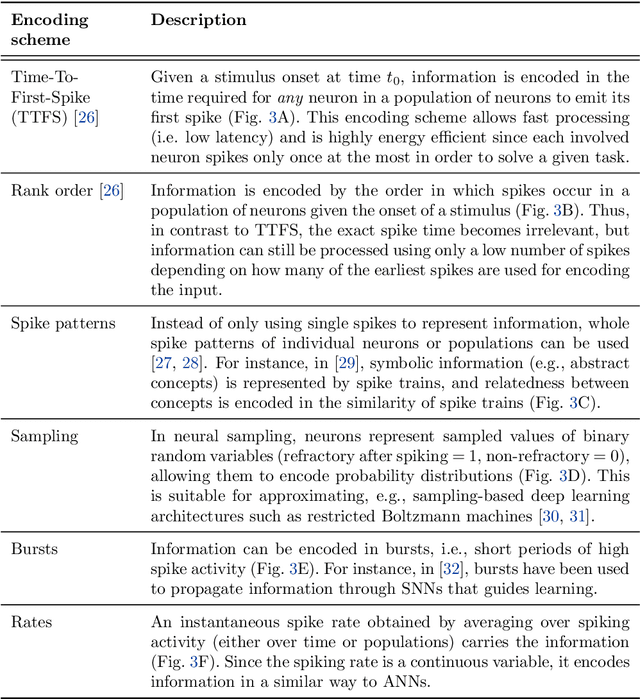
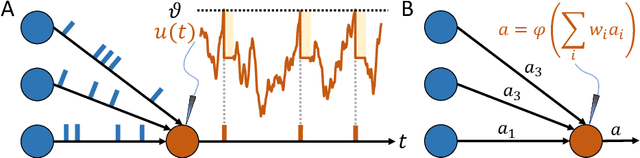
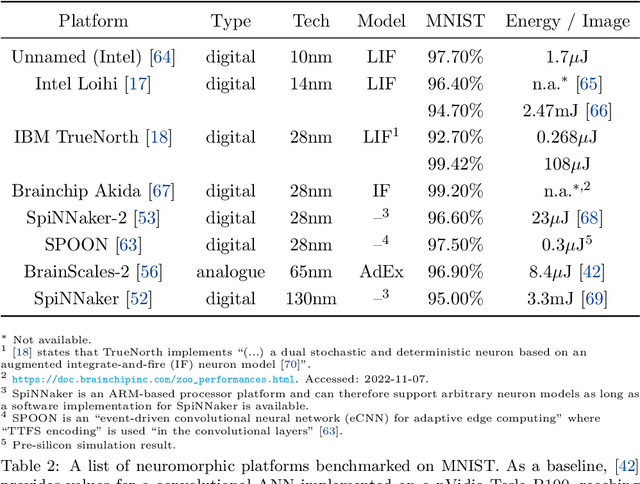
The term ``neuromorphic'' refers to systems that are closely resembling the architecture and/or the dynamics of biological neural networks. Typical examples are novel computer chips designed to mimic the architecture of a biological brain, or sensors that get inspiration from, e.g., the visual or olfactory systems in insects and mammals to acquire information about the environment. This approach is not without ambition as it promises to enable engineered devices able to reproduce the level of performance observed in biological organisms -- the main immediate advantage being the efficient use of scarce resources, which translates into low power requirements. The emphasis on low power and energy efficiency of neuromorphic devices is a perfect match for space applications. Spacecraft -- especially miniaturized ones -- have strict energy constraints as they need to operate in an environment which is scarce with resources and extremely hostile. In this work we present an overview of early attempts made to study a neuromorphic approach in a space context at the European Space Agency's (ESA) Advanced Concepts Team (ACT).
Image augmentation with conformal mappings for a convolutional neural network
Dec 10, 2022

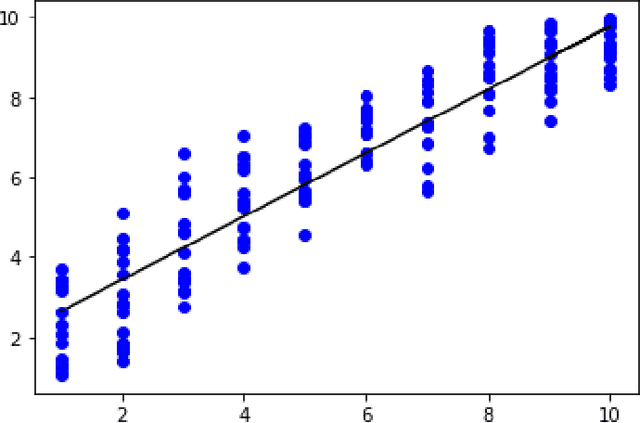
For augmentation of the square-shaped image data of a convolutional neural network (CNN), we introduce a new method, in which the original images are mapped onto a disk with a conformal mapping, rotated around the center of this disk and mapped under such a M\"obius transformation that preserves the disk, and then mapped back onto their original square shape. This process does not result the loss of information caused by removing areas from near the edges of the original images unlike the typical transformations used in the data augmentation for a CNN. We offer here the formulas of all the mappings needed together with detailed instructions how to write a code for transforming the images. The new method is also tested with simulated data and, according the results, using this method to augment the training data of 10 images into 40 images decreases the amount of the error in the predictions by a CNN for a test set of 160 images in a statistically significant way (p-value=0.0360).
FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness
Nov 01, 2022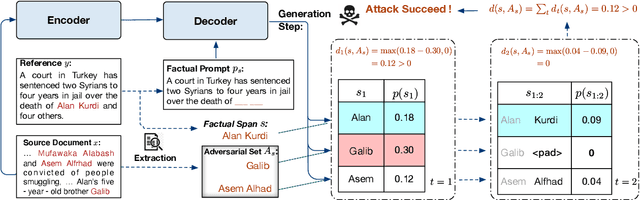
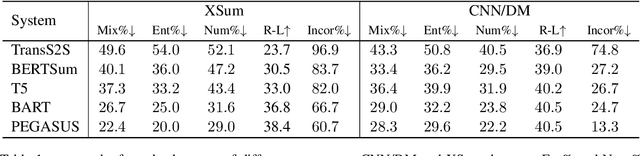
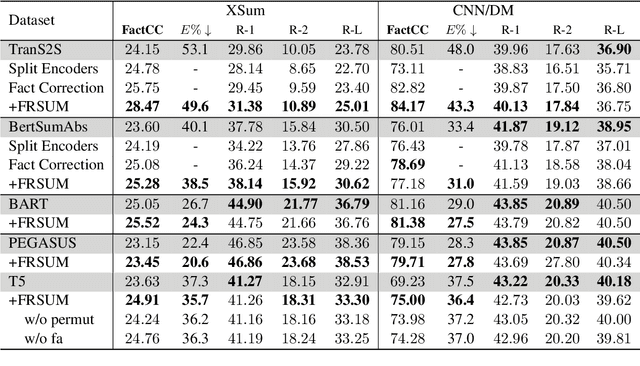
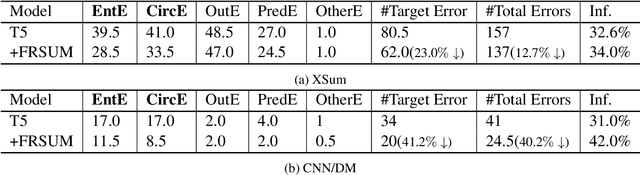
Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART.
Unimodal and Multimodal Representation Training for Relation Extraction
Nov 11, 2022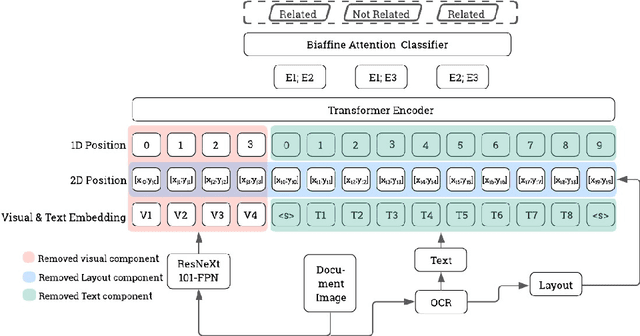
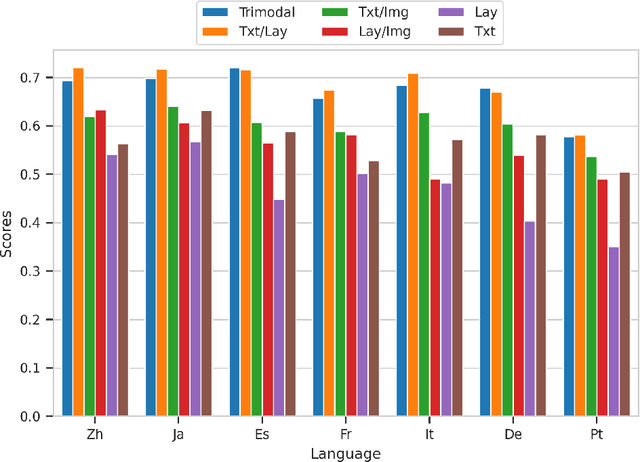
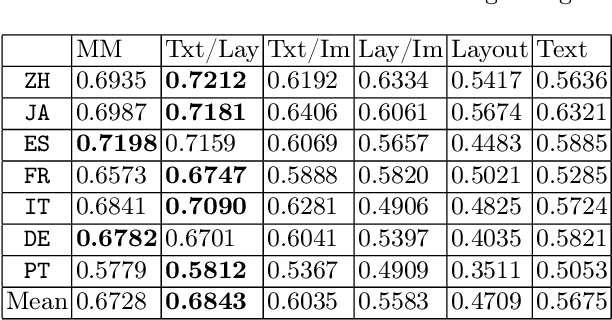
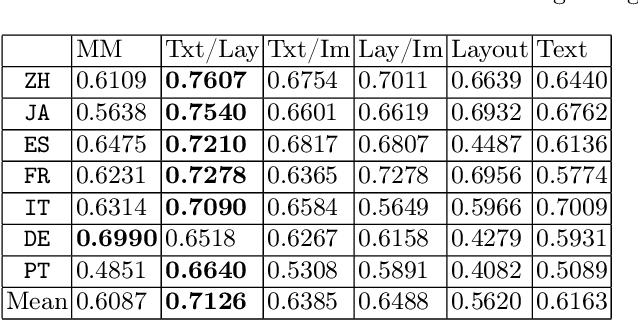
Multimodal integration of text, layout and visual information has achieved SOTA results in visually rich document understanding (VrDU) tasks, including relation extraction (RE). However, despite its importance, evaluation of the relative predictive capacity of these modalities is less prevalent. Here, we demonstrate the value of shared representations for RE tasks by conducting experiments in which each data type is iteratively excluded during training. In addition, text and layout data are evaluated in isolation. While a bimodal text and layout approach performs best (F1=0.684), we show that text is the most important single predictor of entity relations. Additionally, layout geometry is highly predictive and may even be a feasible unimodal approach. Despite being less effective, we highlight circumstances where visual information can bolster performance. In total, our results demonstrate the efficacy of training joint representations for RE.