 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging pre-trained language models for conversational information seeking from text
Mar 31, 2022
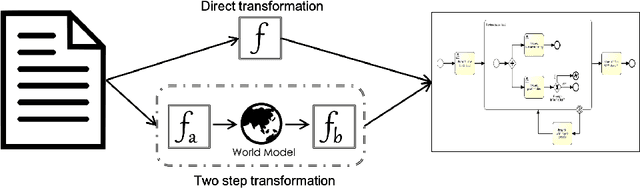
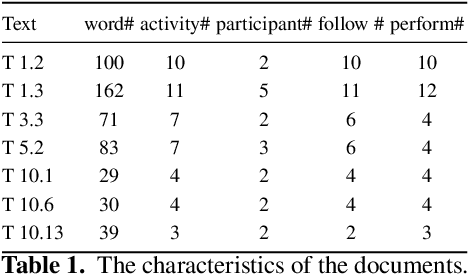
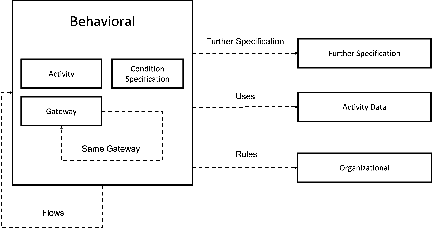
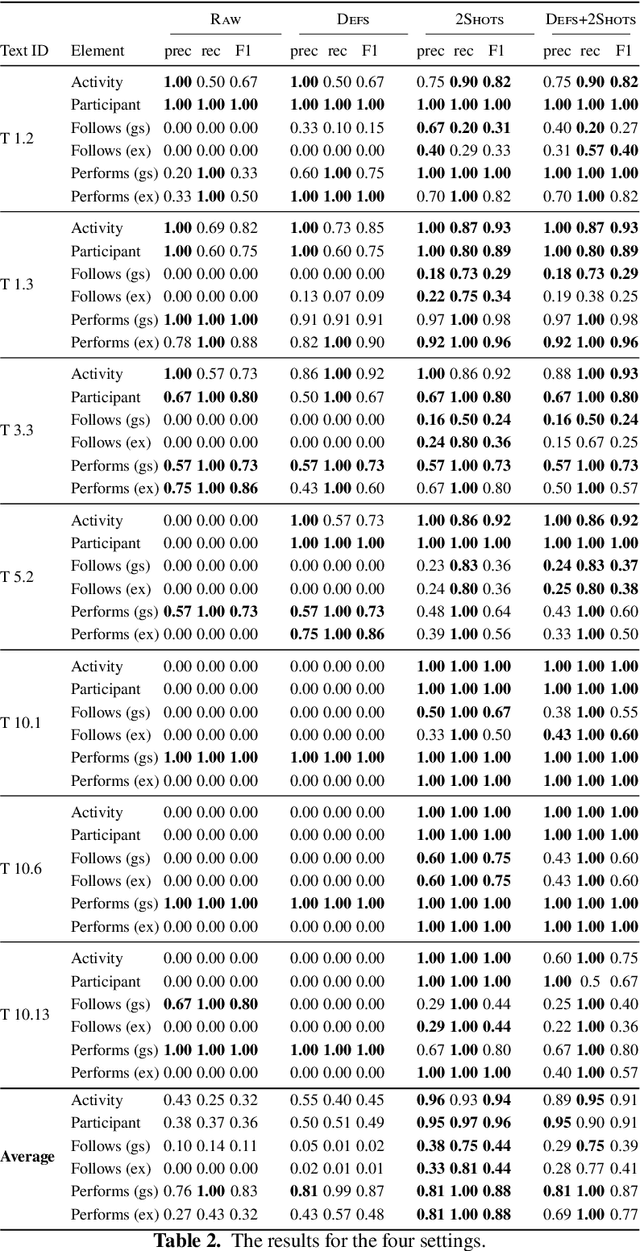
Recent advances in Natural Language Processing, and in particular on the construction of very large pre-trained language representation models, is opening up new perspectives on the construction of conversational information seeking (CIS) systems. In this paper we investigate the usage of in-context learning and pre-trained language representation models to address the problem of information extraction from process description documents, in an incremental question and answering oriented fashion. In particular we investigate the usage of the native GPT-3 (Generative Pre-trained Transformer 3) model, together with two in-context learning customizations that inject conceptual definitions and a limited number of samples in a few shot-learning fashion. The results highlight the potential of the approach and the usefulness of the in-context learning customizations, which can substantially contribute to address the "training data challenge" of deep learning based NLP techniques the BPM field. It also highlight the challenge posed by control flow relations for which further training needs to be devised.
Discourse Context Predictability Effects in Hindi Word Order
Oct 25, 2022
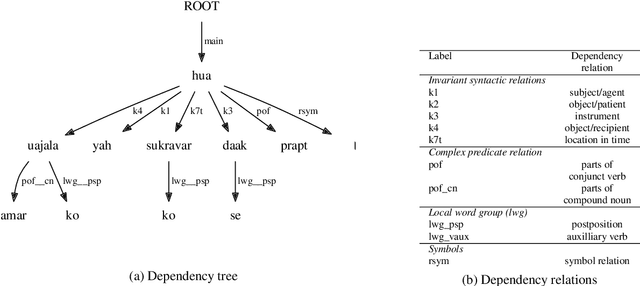
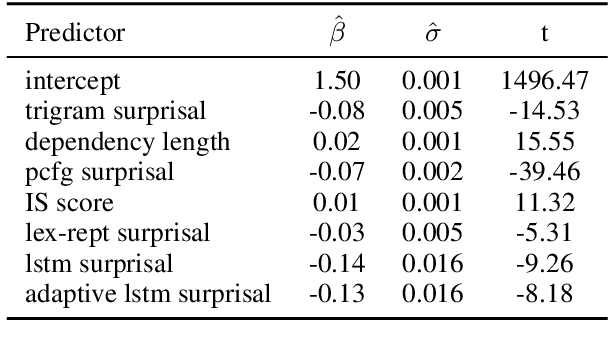
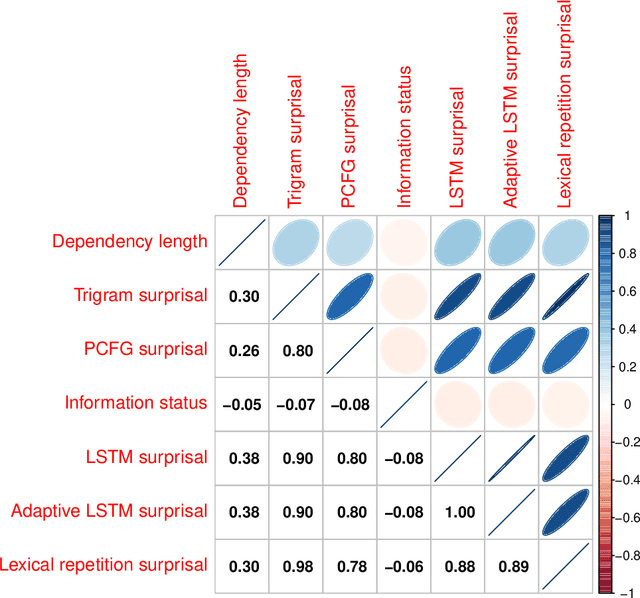
We test the hypothesis that discourse predictability influences Hindi syntactic choice. While prior work has shown that a number of factors (e.g., information status, dependency length, and syntactic surprisal) influence Hindi word order preferences, the role of discourse predictability is underexplored in the literature. Inspired by prior work on syntactic priming, we investigate how the words and syntactic structures in a sentence influence the word order of the following sentences. Specifically, we extract sentences from the Hindi-Urdu Treebank corpus (HUTB), permute the preverbal constituents of those sentences, and build a classifier to predict which sentences actually occurred in the corpus against artificially generated distractors. The classifier uses a number of discourse-based features and cognitive features to make its predictions, including dependency length, surprisal, and information status. We find that information status and LSTM-based discourse predictability influence word order choices, especially for non-canonical object-fronted orders. We conclude by situating our results within the broader syntactic priming literature.
Bayesian Information Criterion for Event-based Multi-trial Ensemble data
Apr 29, 2022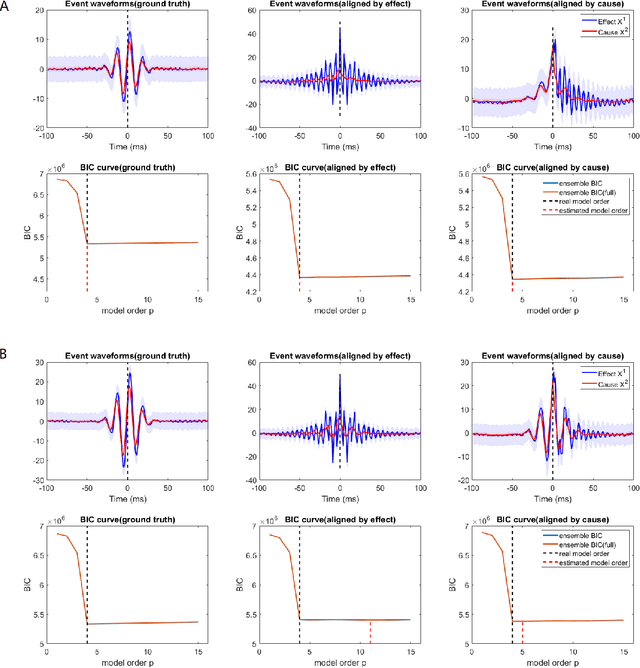
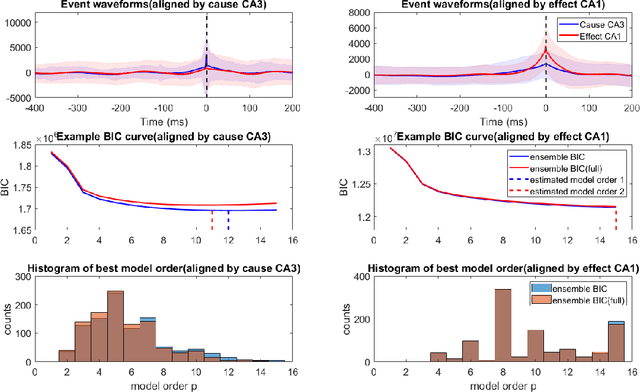
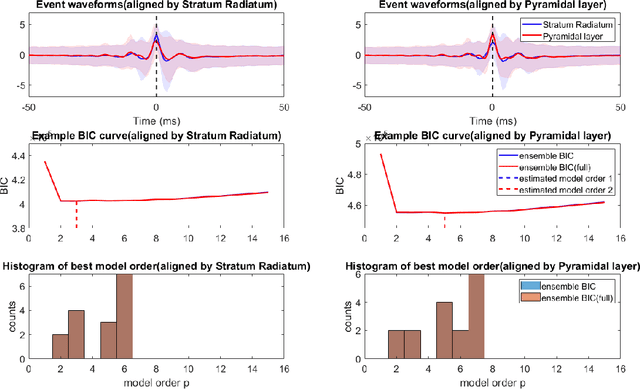
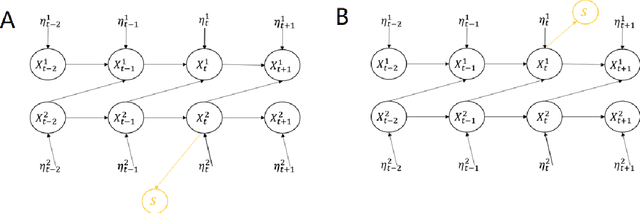
Transient recurring phenomena are ubiquitous in many scientific fields like neuroscience and meteorology. Time inhomogenous Vector Autoregressive Models (VAR) may be used to characterize peri-event system dynamics associated with such phenomena, and can be learned by exploiting multi-dimensional data gathering samples of the evolution of the system in multiple time windows comprising, each associated with one occurrence of the transient phenomenon, that we will call "trial". However, optimal VAR model order selection methods, commonly relying on the Akaike or Bayesian Information Criteria (AIC/BIC), are typically not designed for multi-trial data. Here we derive the BIC methods for multi-trial ensemble data which are gathered after the detection of the events. We show using simulated bivariate AR models that the multi-trial BIC is able to recover the real model order. We also demonstrate with simulated transient events and real data that the multi-trial BIC is able to estimate a sufficiently small model order for dynamic system modeling.
DINER: Depth-aware Image-based NEural Radiance fields
Nov 29, 2022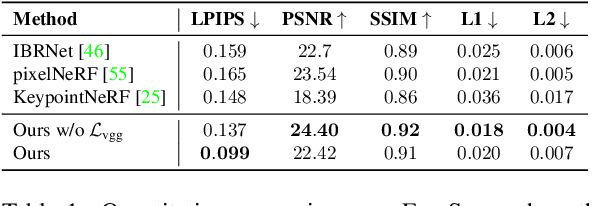
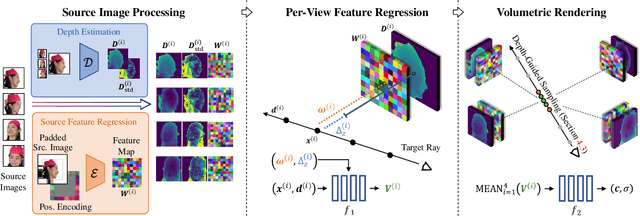
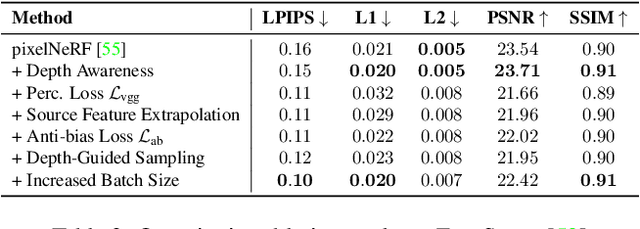
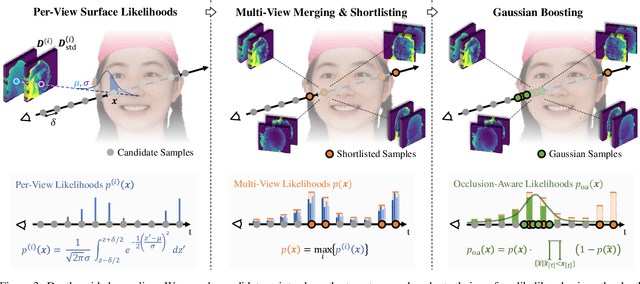
We present Depth-aware Image-based NEural Radiance fields (DINER). Given a sparse set of RGB input views, we predict depth and feature maps to guide the reconstruction of a volumetric scene representation that allows us to render 3D objects under novel views. Specifically, we propose novel techniques to incorporate depth information into feature fusion and efficient scene sampling. In comparison to the previous state of the art, DINER achieves higher synthesis quality and can process input views with greater disparity. This allows us to capture scenes more completely without changing capturing hardware requirements and ultimately enables larger viewpoint changes during novel view synthesis. We evaluate our method by synthesizing novel views, both for human heads and for general objects, and observe significantly improved qualitative results and increased perceptual metrics compared to the previous state of the art. The code will be made publicly available for research purposes.
Multi-robot Social-aware Cooperative Planning in Pedestrian Environments Using Multi-agent Reinforcement Learning
Nov 29, 2022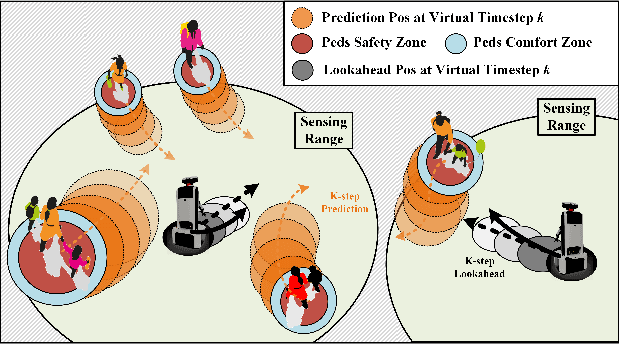
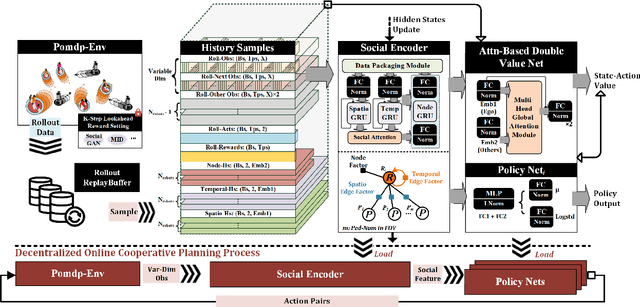
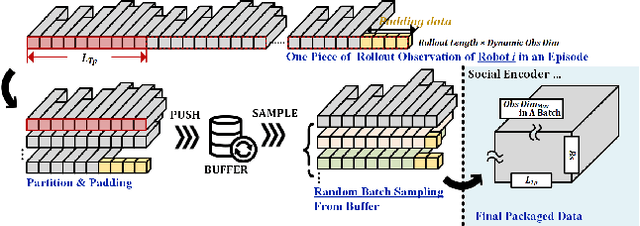
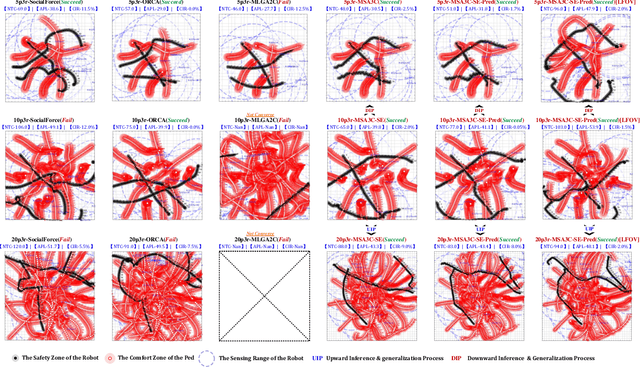
Safe and efficient co-planning of multiple robots in pedestrian participation environments is promising for applications. In this work, a novel multi-robot social-aware efficient cooperative planner that on the basis of off-policy multi-agent reinforcement learning (MARL) under partial dimension-varying observation and imperfect perception conditions is proposed. We adopt temporal-spatial graph (TSG)-based social encoder to better extract the importance of social relation between each robot and the pedestrians in its field of view (FOV). Also, we introduce K-step lookahead reward setting in multi-robot RL framework to avoid aggressive, intrusive, short-sighted, and unnatural motion decisions generated by robots. Moreover, we improve the traditional centralized critic network with multi-head global attention module to better aggregates local observation information among different robots to guide the process of individual policy update. Finally, multi-group experimental results verify the effectiveness of the proposed cooperative motion planner.
Positional Information is All You Need: A Novel Pipeline for Self-Supervised SVDE from Videos
May 18, 2022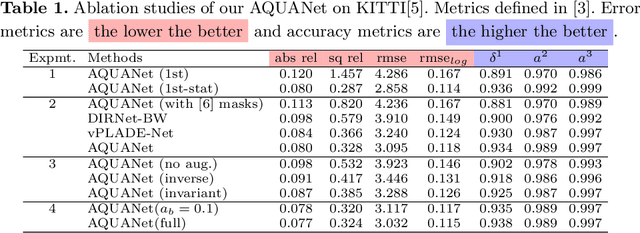
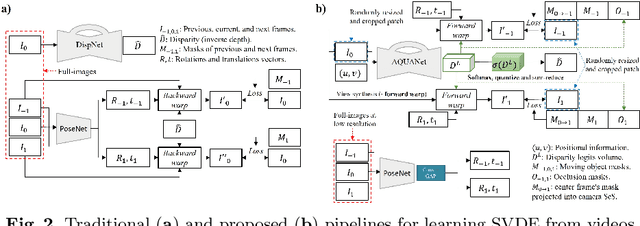
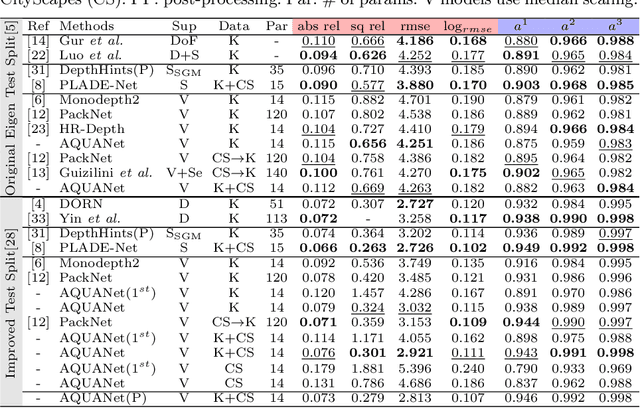
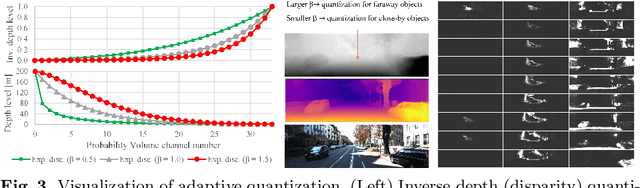
Recently, much attention has been drawn to learning the underlying 3D structures of a scene from monocular videos in a fully self-supervised fashion. One of the most challenging aspects of this task is handling the independently moving objects as they break the rigid-scene assumption. For the first time, we show that pixel positional information can be exploited to learn SVDE (Single View Depth Estimation) from videos. Our proposed moving object (MO) masks, which are induced by shifted positional information (SPI) and referred to as `SPIMO' masks, are very robust and consistently remove the independently moving objects in the scenes, allowing for better learning of SVDE from videos. Additionally, we introduce a new adaptive quantization scheme that assigns the best per-pixel quantization curve for our depth discretization. Finally, we employ existing boosting techniques in a new way to further self-supervise the depth of the moving objects. With these features, our pipeline is robust against moving objects and generalizes well to high-resolution images, even when trained with small patches, yielding state-of-the-art (SOTA) results with almost 8.5x fewer parameters than the previous works that learn from videos. We present extensive experiments on KITTI and CityScapes that show the effectiveness of our method.
Deep Joint Source-Channel Coding for Semantic Communications
Dec 05, 2022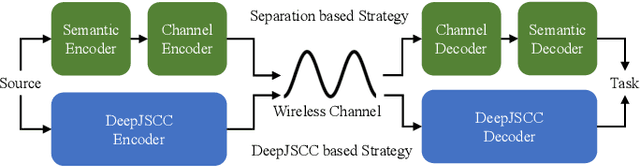
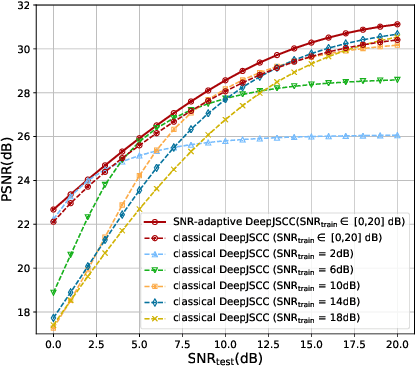
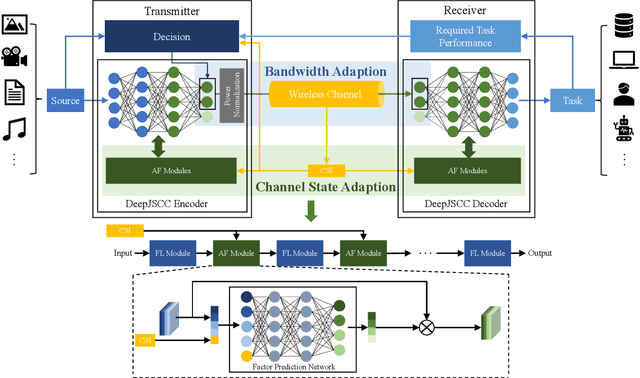
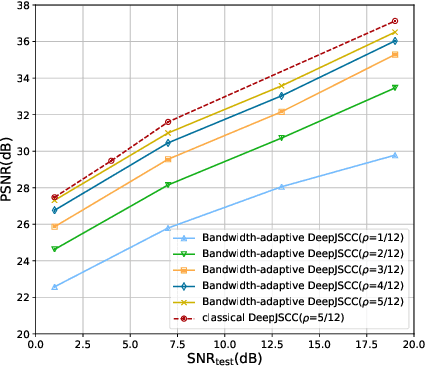
Semantic communications is considered as a promising technology for reducing the bandwidth requirements of next-generation communication systems, particularly targeting human-machine interactions. In contrast to the source-agnostic approach of conventional wireless communication systems, semantic communication seeks to ensure that only the relevant information for the underlying task is communicated to the receiver. A prominent approach to semantic communications is to model it as a joint source-channel coding (JSCC) problem. Although JSCC has been a long-standing open problem in communication and coding theory, remarkable performance gains have been shown recently over existing separate source and channel coding systems, particularly in low-latency and low-power scenarios, typically encountered in edge intelligence applications. Recent progress is thanks to the adoption of deep learning techniques for JSCC code design, which are shown to outperform the concatenation of state-of-the-art compression and channel coding schemes, each of which is a result of decades-long research efforts. In this article, we present an adaptive deep learning based JSCC (DeepJSCC) architecture for semantic communications, introduce its design principles, highlight its benefits, and outline future research challenges that lie ahead.
Generalizable Person Re-Identification via Viewpoint Alignment and Fusion
Dec 05, 2022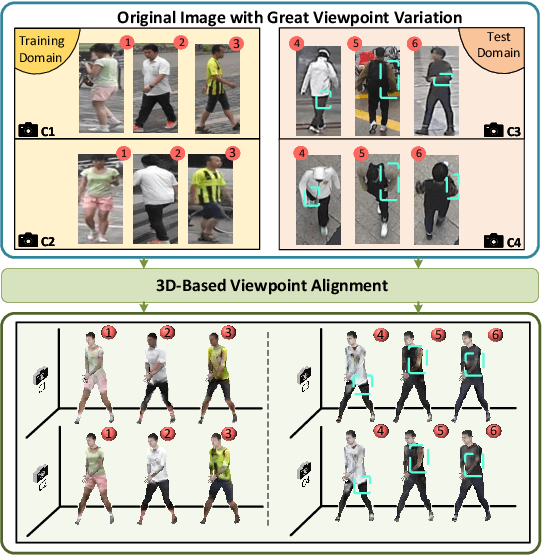
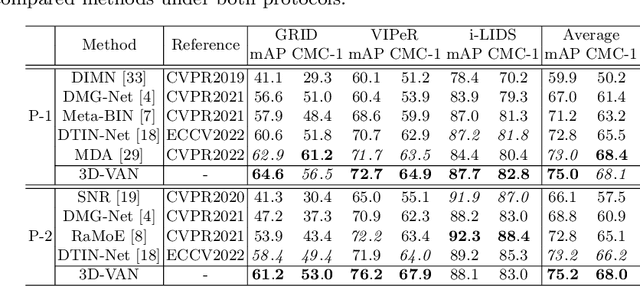
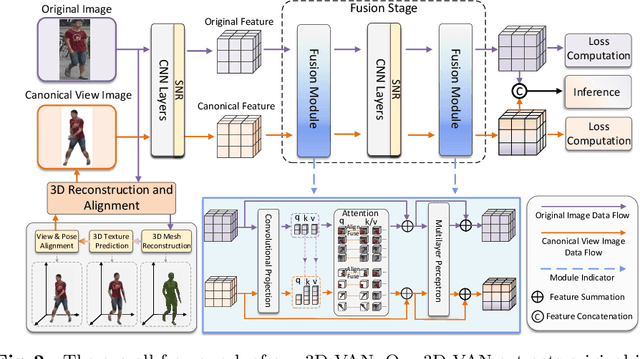
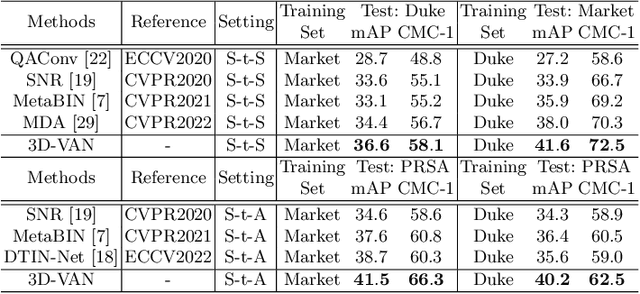
In the current person Re-identification (ReID) methods, most domain generalization works focus on dealing with style differences between domains while largely ignoring unpredictable camera view change, which we identify as another major factor leading to a poor generalization of ReID methods. To tackle the viewpoint change, this work proposes to use a 3D dense pose estimation model and a texture mapping module to map the pedestrian images to canonical view images. Due to the imperfection of the texture mapping module, the canonical view images may lose the discriminative detail clues from the original images, and thus directly using them for ReID will inevitably result in poor performance. To handle this issue, we propose to fuse the original image and canonical view image via a transformer-based module. The key insight of this design is that the cross-attention mechanism in the transformer could be an ideal solution to align the discriminative texture clues from the original image with the canonical view image, which could compensate for the low-quality texture information of the canonical view image. Through extensive experiments, we show that our method can lead to superior performance over the existing approaches in various evaluation settings.
Inspired by Norbert Wiener: FeedBack Loop Network Learning Incremental Knowledge for Driver Attention Prediction and Beyond
Dec 05, 2022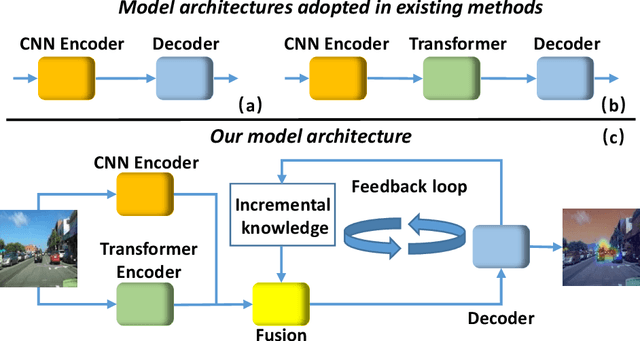
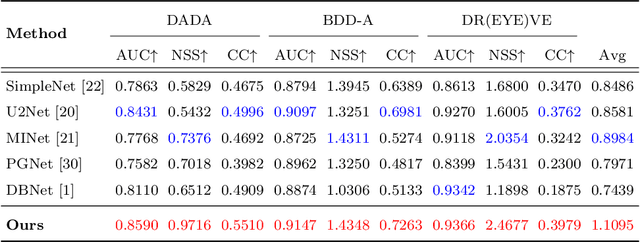
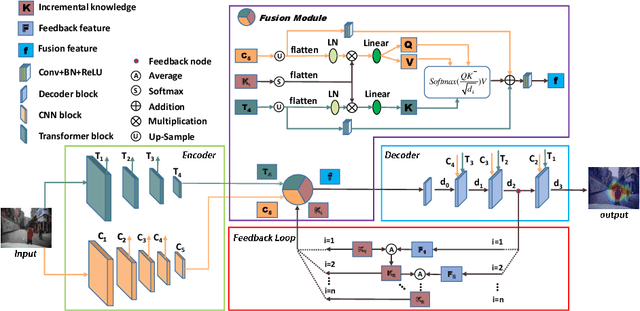
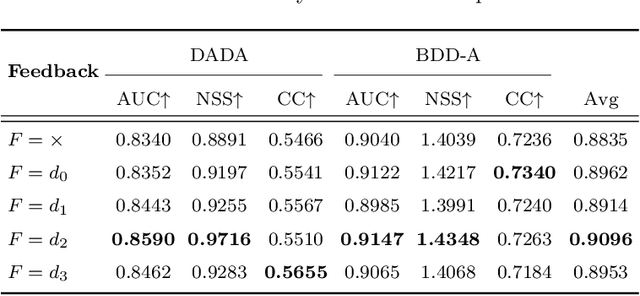
The problem of predicting driver attention from the driving perspective is gaining the increasing research focuses due to its remarkable significance for autonomous driving and assisted driving systems. Driving experience is extremely important for driver attention prediction, a skilled driver is able to effortlessly predict oncoming danger (before it becomes salient) based on driving experience and quickly pay attention on the corresponding zones. However, the nonobjective driving experience is difficult to model, so a mechanism simulating driver experience accumulation procedure is absent in existing methods, and the existing methods usually follow the technique line of saliency prediction methods to predict driver attention. In this paper, we propose a FeedBack Loop Network (FBLNet), which attempts to model the driving experience accumulation procedure. By over-and-over iterations, FBLNet generates the incremental knowledge that carries rich historically-accumulative long-term temporal information. The incremental knowledge to our model is like the driving experience to humans. Under the guidance of the incremental knowledge, our model fuses the CNN feature and Transformer feature that are extracted from the input image to predict driver attention. Our model exhibits solid advantage over existing methods, achieving an average 10.3% performance improvement on three public datasets.
Research on Data Fusion Algorithm Based on Deep Learning in Target Tracking
Nov 23, 2022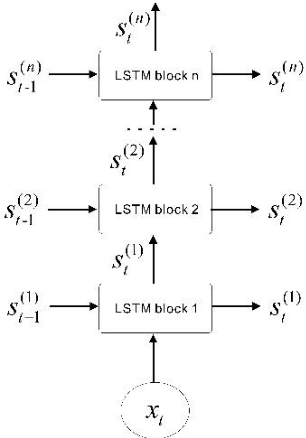
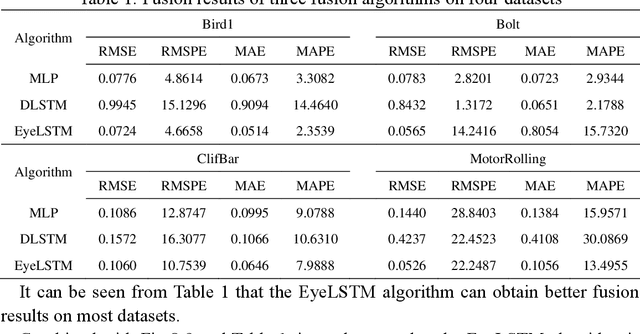
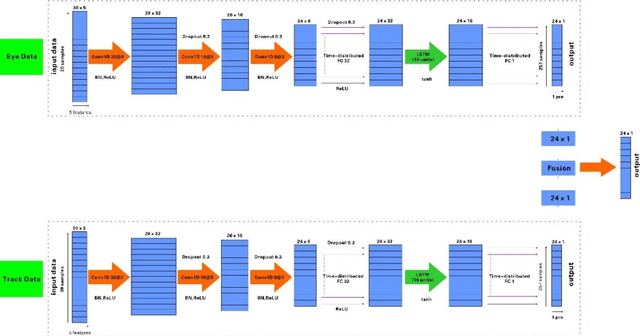

Aiming at the limitation that deep long and short-term memory network(DLSTM) algorithm cannot perform parallel computing and cannot obtain global information, in this paper, feature extraction and feature processing are firstly carried out according to the characteristics of eye movement data and tracking data, then by introducing a convolutional neural network (CNN) into a deep long and short-term memory network, developed a new network structure and designed a fusion strategy, an eye tracking data fusion algorithm based on long and short-term memory network is proposed. The experimental results show that compared with the two fusion algorithms based on deep learning, the algorithm proposed in this paper performs well in terms of fusion quality.