 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-aware Metapath Feature Augmentation for Ponzi Detection in Ethereum
Oct 30, 2022
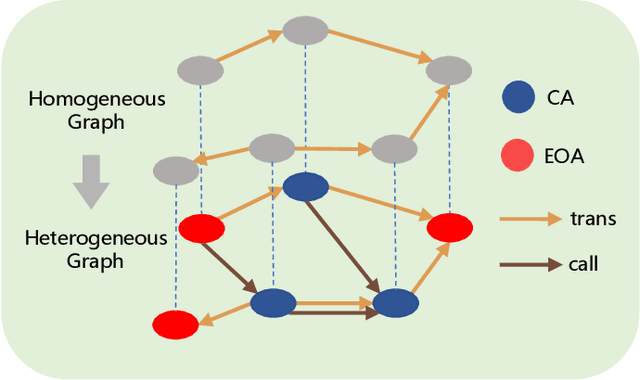
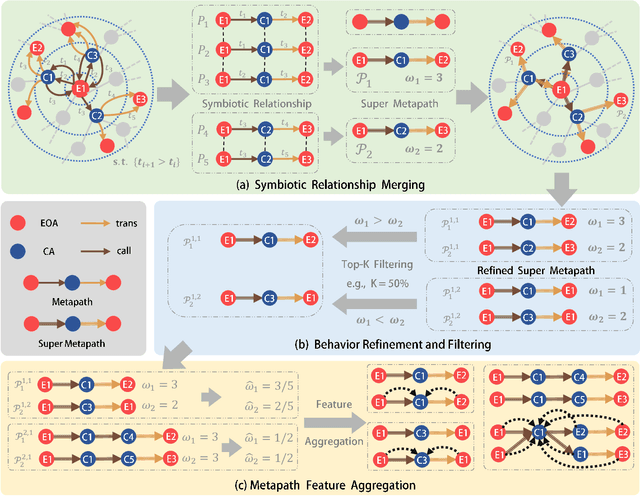

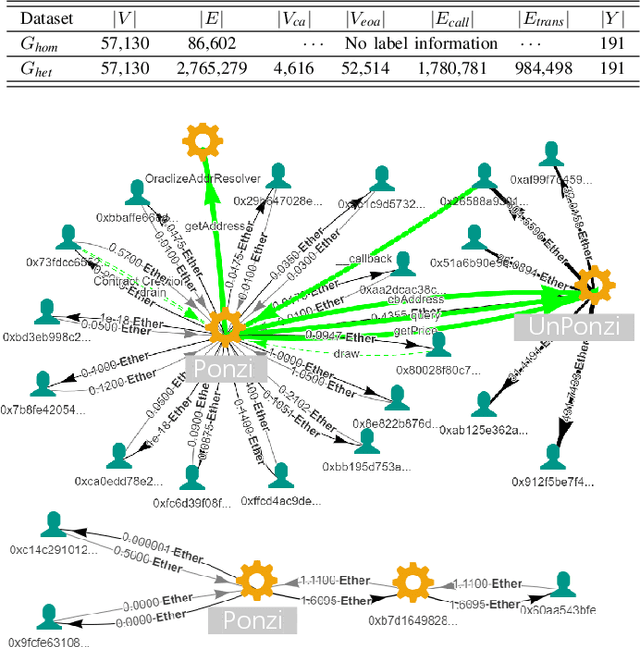
With the development of Web 3.0 which emphasizes decentralization, blockchain technology ushers in its revolution and also brings numerous challenges, particularly in the field of cryptocurrency. Recently, a large number of criminal behaviors continuously emerge on blockchain, such as Ponzi schemes and phishing scams, which severely endanger decentralized finance. Existing graph-based abnormal behavior detection methods on blockchain usually focus on constructing homogeneous transaction graphs without distinguishing the heterogeneity of nodes and edges, resulting in partial loss of transaction pattern information. Although existing heterogeneous modeling methods can depict richer information through metapaths, the extracted metapaths generally neglect temporal dependencies between entities and do not reflect real behavior. In this paper, we introduce Time-aware Metapath Feature Augmentation (TMFAug) as a plug-and-play module to capture the real metapath-based transaction patterns during Ponzi scheme detection on Ethereum. The proposed module can be adaptively combined with existing graph-based Ponzi detection methods. Extensive experimental results show that our TMFAug can help existing Ponzi detection methods achieve significant performance improvements on the Ethereum dataset, indicating the effectiveness of heterogeneous temporal information for Ponzi scheme detection.
Weakly Supervised Annotations for Multi-modal Greeting Cards Dataset
Dec 01, 2022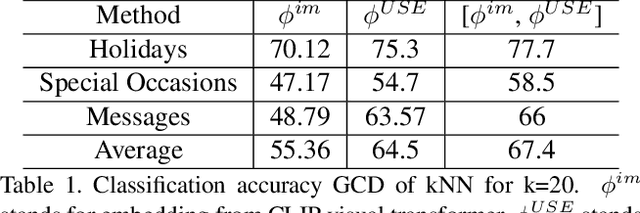
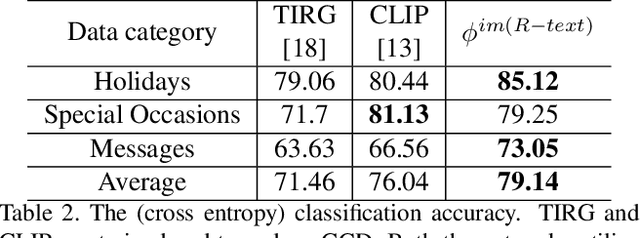
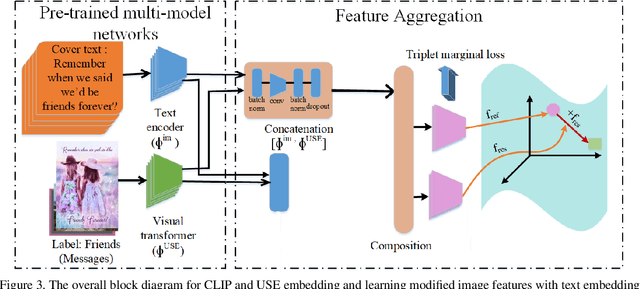

In recent years, there is a growing number of pre-trained models trained on a large corpus of data and yielding good performance on various tasks such as classifying multimodal datasets. These models have shown good performance on natural images but are not fully explored for scarce abstract concepts in images. In this work, we introduce an image/text-based dataset called Greeting Cards. Dataset (GCD) that has abstract visual concepts. In our work, we propose to aggregate features from pretrained images and text embeddings to learn abstract visual concepts from GCD. This allows us to learn the text-modified image features, which combine complementary and redundant information from the multi-modal data streams into a single, meaningful feature. Secondly, the captions for the GCD dataset are computed with the pretrained CLIP-based image captioning model. Finally, we also demonstrate that the proposed the dataset is also useful for generating greeting card images using pre-trained text-to-image generation model.
Synaptic Dynamics Realize First-order Adaptive Learning and Weight Symmetry
Dec 01, 2022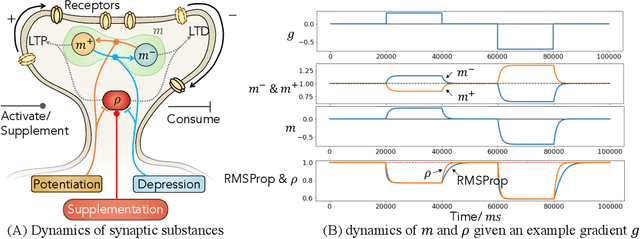
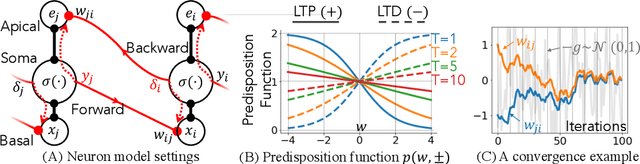
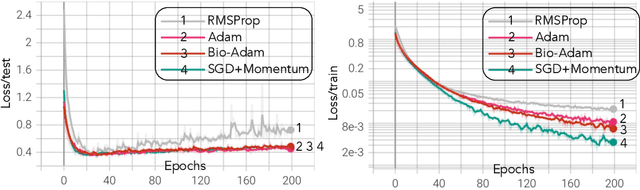
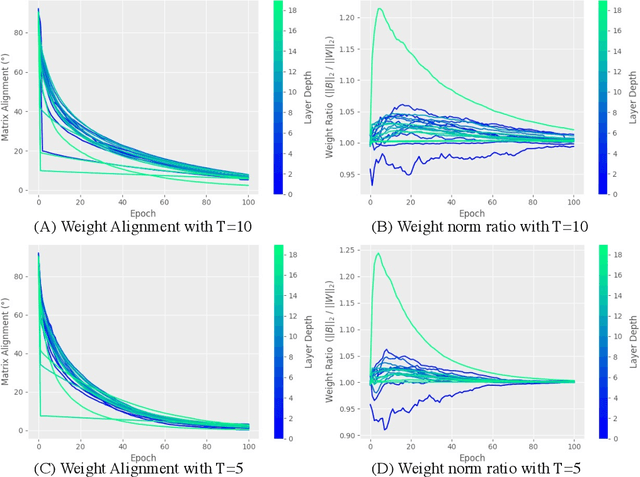
Gradient-based first-order adaptive optimization methods such as the Adam optimizer are prevalent in training artificial networks, achieving the state-of-the-art results. This work attempts to answer the question whether it is viable for biological neural systems to adopt such optimization methods. To this end, we demonstrate a realization of the Adam optimizer using biologically-plausible mechanisms in synapses. The proposed learning rule has clear biological correspondence, runs continuously in time, and achieves performance to comparable Adam's. In addition, we present a new approach, inspired by the predisposition property of synapses observed in neuroscience, to circumvent the biological implausibility of the weight transport problem in backpropagation (BP). With only local information and no separate training phases, this method establishes and maintains weight symmetry in the forward and backward signaling paths, and is applicable to the proposed biologically plausible Adam learning rule. These mechanisms may shed light on the way in which biological synaptic dynamics facilitate learning.
A General Purpose Supervisory Signal for Embodied Agents
Dec 01, 2022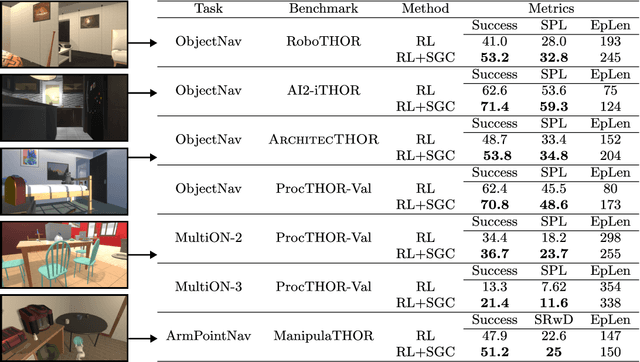
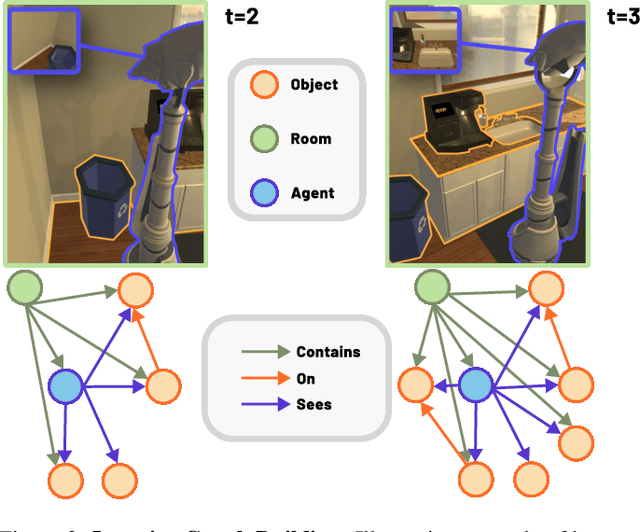
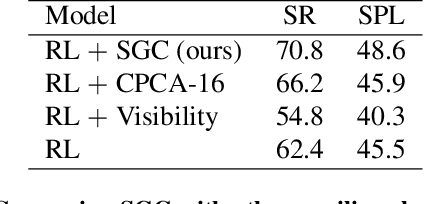
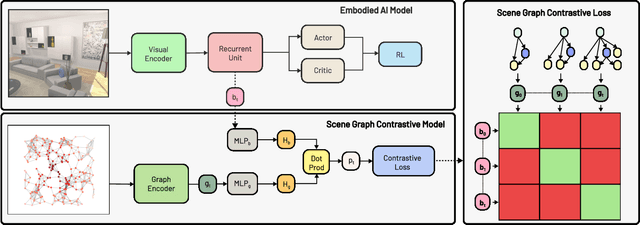
Training effective embodied AI agents often involves manual reward engineering, expert imitation, specialized components such as maps, or leveraging additional sensors for depth and localization. Another approach is to use neural architectures alongside self-supervised objectives which encourage better representation learning. In practice, there are few guarantees that these self-supervised objectives encode task-relevant information. We propose the Scene Graph Contrastive (SGC) loss, which uses scene graphs as general-purpose, training-only, supervisory signals. The SGC loss does away with explicit graph decoding and instead uses contrastive learning to align an agent's representation with a rich graphical encoding of its environment. The SGC loss is generally applicable, simple to implement, and encourages representations that encode objects' semantics, relationships, and history. Using the SGC loss, we attain significant gains on three embodied tasks: Object Navigation, Multi-Object Navigation, and Arm Point Navigation. Finally, we present studies and analyses which demonstrate the ability of our trained representation to encode semantic cues about the environment.
Adapted Multimodal BERT with Layer-wise Fusion for Sentiment Analysis
Dec 01, 2022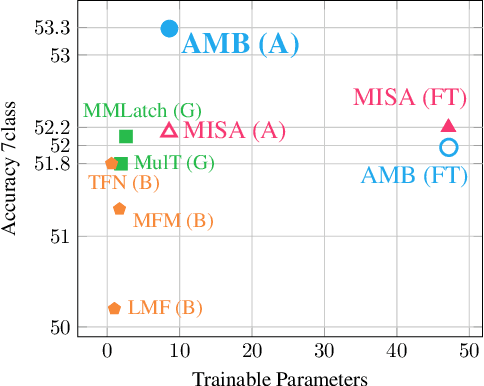
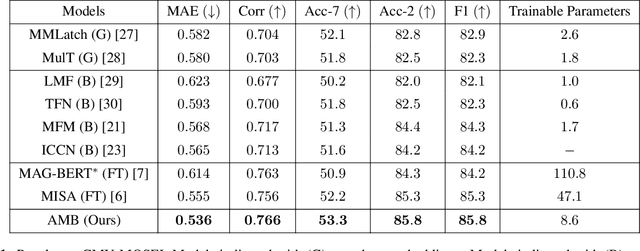
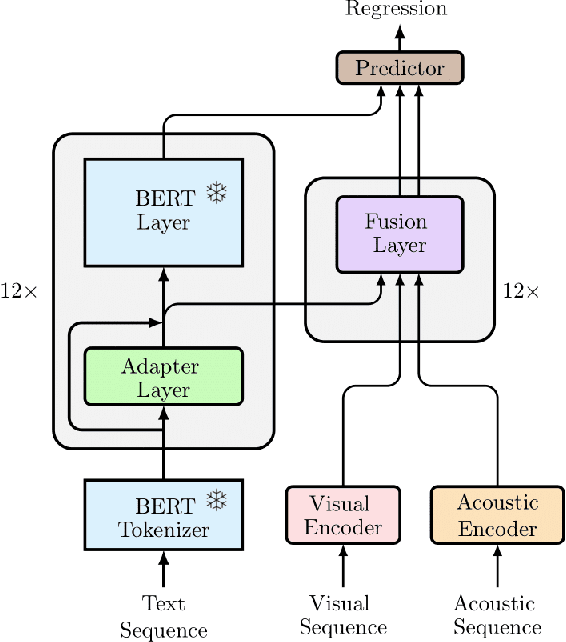
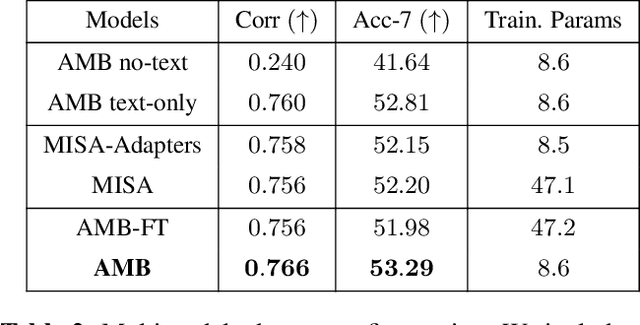
Multimodal learning pipelines have benefited from the success of pretrained language models. However, this comes at the cost of increased model parameters. In this work, we propose Adapted Multimodal BERT (AMB), a BERT-based architecture for multimodal tasks that uses a combination of adapter modules and intermediate fusion layers. The adapter adjusts the pretrained language model for the task at hand, while the fusion layers perform task-specific, layer-wise fusion of audio-visual information with textual BERT representations. During the adaptation process the pre-trained language model parameters remain frozen, allowing for fast, parameter-efficient training. In our ablations we see that this approach leads to efficient models, that can outperform their fine-tuned counterparts and are robust to input noise. Our experiments on sentiment analysis with CMU-MOSEI show that AMB outperforms the current state-of-the-art across metrics, with 3.4% relative reduction in the resulting error and 2.1% relative improvement in 7-class classification accuracy.
Unbiased Heterogeneous Scene Graph Generation with Relation-aware Message Passing Neural Network
Dec 01, 2022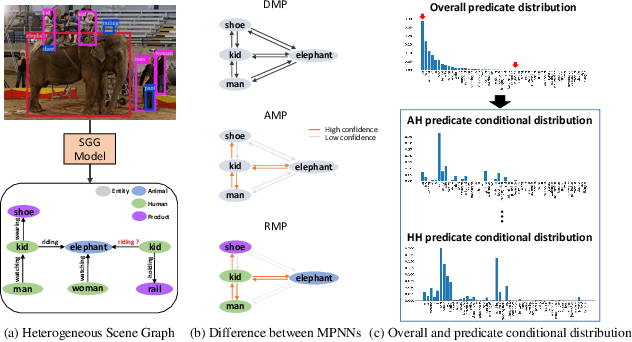
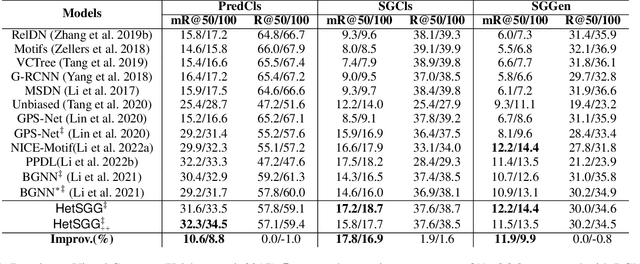
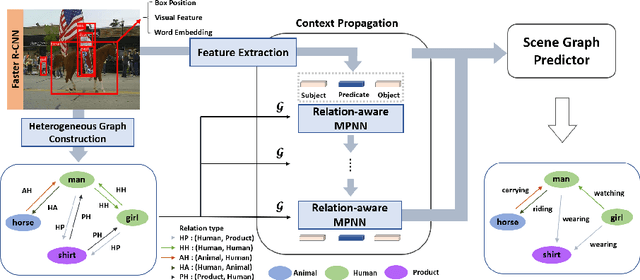
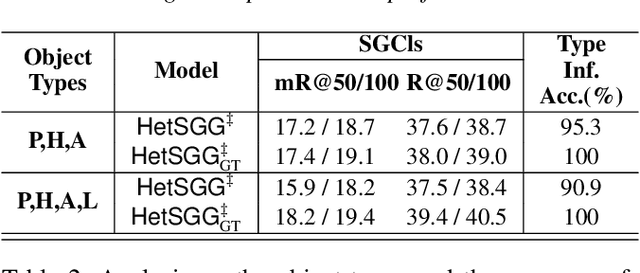
Recent scene graph generation (SGG) frameworks have focused on learning complex relationships among multiple objects in an image. Thanks to the nature of the message passing neural network (MPNN) that models high-order interactions between objects and their neighboring objects, they are dominant representation learning modules for SGG. However, existing MPNN-based frameworks assume the scene graph as a homogeneous graph, which restricts the context-awareness of visual relations between objects. That is, they overlook the fact that the relations tend to be highly dependent on the objects with which the relations are associated. In this paper, we propose an unbiased heterogeneous scene graph generation (HetSGG) framework that captures relation-aware context using message passing neural networks. We devise a novel message passing layer, called relation-aware message passing neural network (RMP), that aggregates the contextual information of an image considering the predicate type between objects. Our extensive evaluations demonstrate that HetSGG outperforms state-of-the-art methods, especially outperforming on tail predicate classes.
Differentially Private Adaptive Optimization with Delayed Preconditioners
Dec 01, 2022

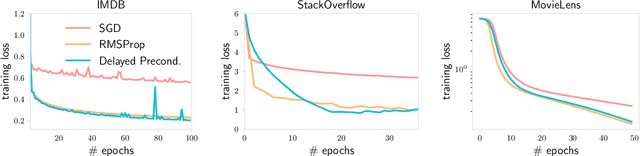

Privacy noise may negate the benefits of using adaptive optimizers in differentially private model training. Prior works typically address this issue by using auxiliary information (e.g., public data) to boost the effectiveness of adaptive optimization. In this work, we explore techniques to estimate and efficiently adapt to gradient geometry in private adaptive optimization without auxiliary data. Motivated by the observation that adaptive methods can tolerate stale preconditioners, we propose differentially private adaptive training with delayed preconditioners (DP^2), a simple method that constructs delayed but less noisy preconditioners to better realize the benefits of adaptivity. Theoretically, we provide convergence guarantees for our method for both convex and non-convex problems, and analyze trade-offs between delay and privacy noise reduction. Empirically, we explore DP^2 across several real-world datasets, demonstrating that it can improve convergence speed by as much as 4x relative to non-adaptive baselines and match the performance of state-of-the-art optimization methods that require auxiliary data.
Conditional Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
Mar 06, 2022
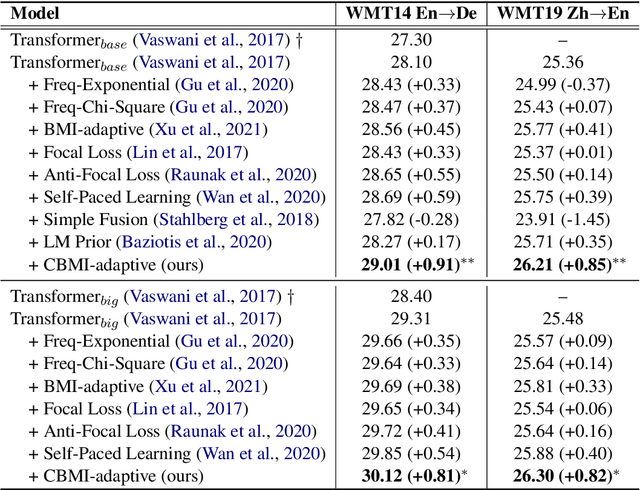
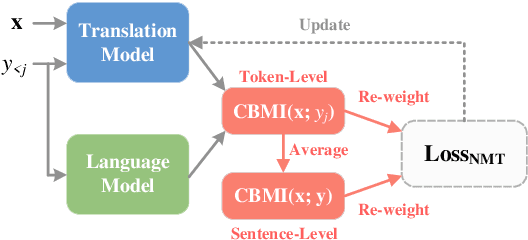

Token-level adaptive training approaches can alleviate the token imbalance problem and thus improve neural machine translation, through re-weighting the losses of different target tokens based on specific statistical metrics (e.g., token frequency or mutual information). Given that standard translation models make predictions on the condition of previous target contexts, we argue that the above statistical metrics ignore target context information and may assign inappropriate weights to target tokens. While one possible solution is to directly take target contexts into these statistical metrics, the target-context-aware statistical computing is extremely expensive, and the corresponding storage overhead is unrealistic. To solve the above issues, we propose a target-context-aware metric, named conditional bilingual mutual information (CBMI), which makes it feasible to supplement target context information for statistical metrics. Particularly, our CBMI can be formalized as the log quotient of the translation model probability and language model probability by decomposing the conditional joint distribution. Thus CBMI can be efficiently calculated during model training without any pre-specific statistical calculations and large storage overhead. Furthermore, we propose an effective adaptive training approach based on both the token- and sentence-level CBMI. Experimental results on WMT14 English-German and WMT19 Chinese-English tasks show our approach can significantly outperform the Transformer baseline and other related methods.
Regularized Optimal Transport Layers for Generalized Global Pooling Operations
Dec 13, 2022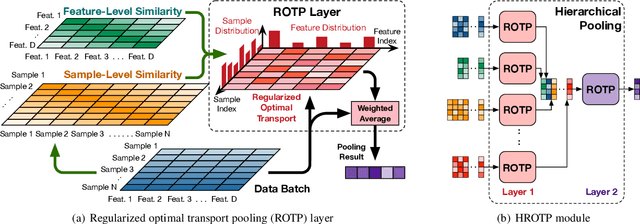
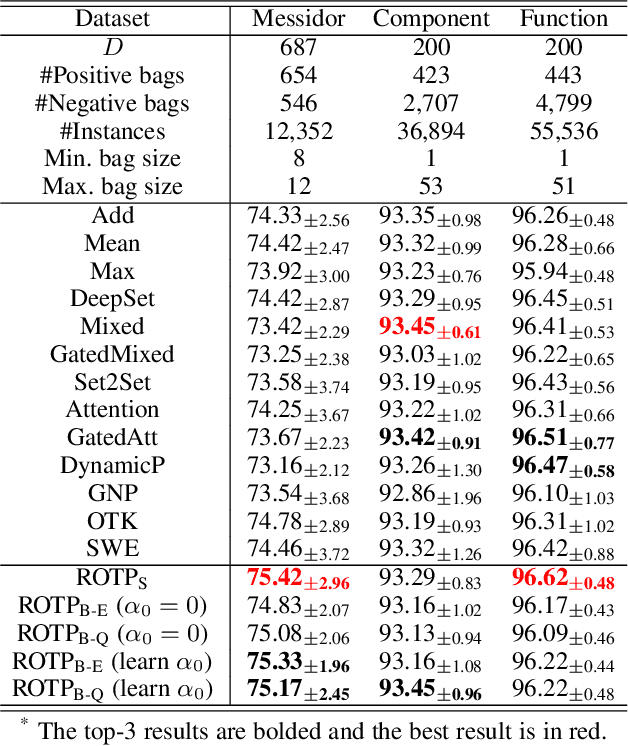
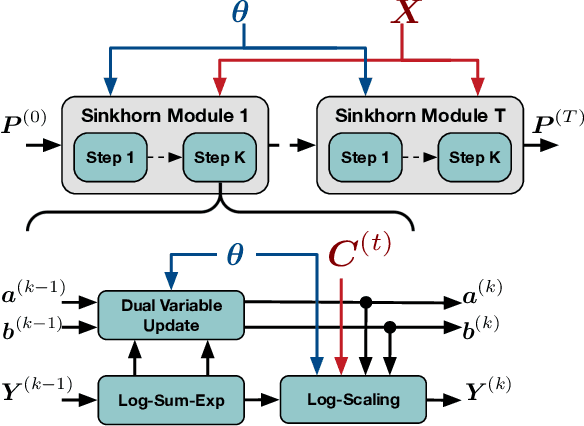
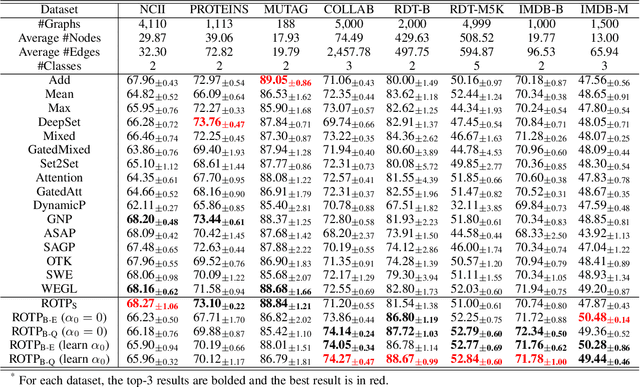
Global pooling is one of the most significant operations in many machine learning models and tasks, which works for information fusion and structured data (like sets and graphs) representation. However, without solid mathematical fundamentals, its practical implementations often depend on empirical mechanisms and thus lead to sub-optimal, even unsatisfactory performance. In this work, we develop a novel and generalized global pooling framework through the lens of optimal transport. The proposed framework is interpretable from the perspective of expectation-maximization. Essentially, it aims at learning an optimal transport across sample indices and feature dimensions, making the corresponding pooling operation maximize the conditional expectation of input data. We demonstrate that most existing pooling methods are equivalent to solving a regularized optimal transport (ROT) problem with different specializations, and more sophisticated pooling operations can be implemented by hierarchically solving multiple ROT problems. Making the parameters of the ROT problem learnable, we develop a family of regularized optimal transport pooling (ROTP) layers. We implement the ROTP layers as a new kind of deep implicit layer. Their model architectures correspond to different optimization algorithms. We test our ROTP layers in several representative set-level machine learning scenarios, including multi-instance learning (MIL), graph classification, graph set representation, and image classification. Experimental results show that applying our ROTP layers can reduce the difficulty of the design and selection of global pooling -- our ROTP layers may either imitate some existing global pooling methods or lead to some new pooling layers fitting data better. The code is available at \url{https://github.com/SDS-Lab/ROT-Pooling}.
Semantic Brain Decoding: from fMRI to conceptually similar image reconstruction of visual stimuli
Dec 13, 2022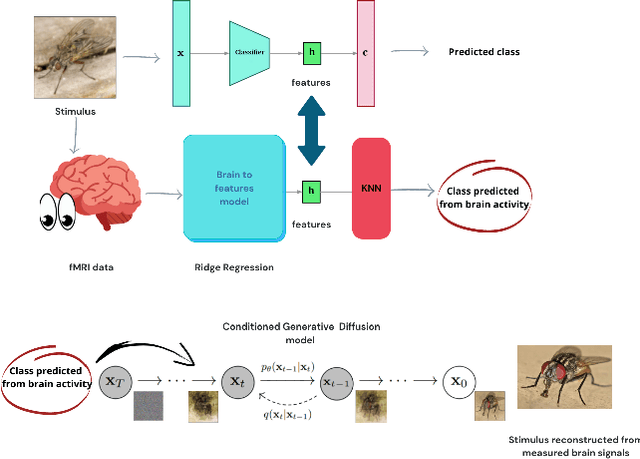
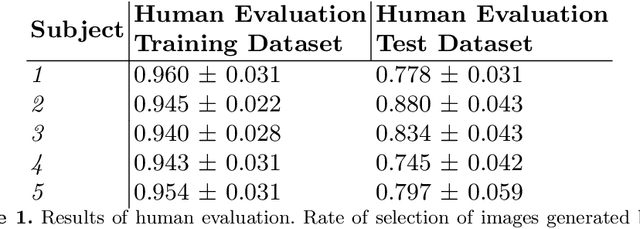
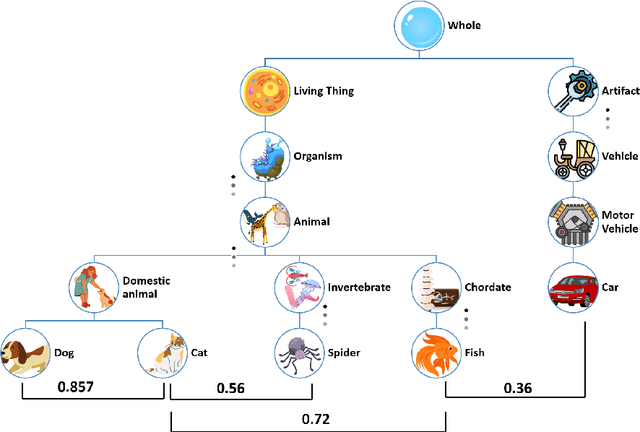

Brain decoding is a field of computational neuroscience that uses measurable brain activity to infer mental states or internal representations of perceptual inputs. Therefore, we propose a novel approach to brain decoding that also relies on semantic and contextual similarity. We employ an fMRI dataset of natural image vision and create a deep learning decoding pipeline inspired by the existence of both bottom-up and top-down processes in human vision. We train a linear brain-to-feature model to map fMRI activity features to visual stimuli features, assuming that the brain projects visual information onto a space that is homeomorphic to the latent space represented by the last convolutional layer of a pretrained convolutional neural network, which typically collects a variety of semantic features that summarize and highlight similarities and differences between concepts. These features are then categorized in the latent space using a nearest-neighbor strategy, and the results are used to condition a generative latent diffusion model to create novel images. From fMRI data only, we produce reconstructions of visual stimuli that match the original content very well on a semantic level, surpassing the state of the art in previous literature. We evaluate our work and obtain good results using a quantitative semantic metric (the Wu-Palmer similarity metric over the WordNet lexicon, which had an average value of 0.57) and perform a human evaluation experiment that resulted in correct evaluation, according to the multiplicity of human criteria in evaluating image similarity, in over 80% of the test set.