 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differentially Private Image Classification from Features
Nov 24, 2022
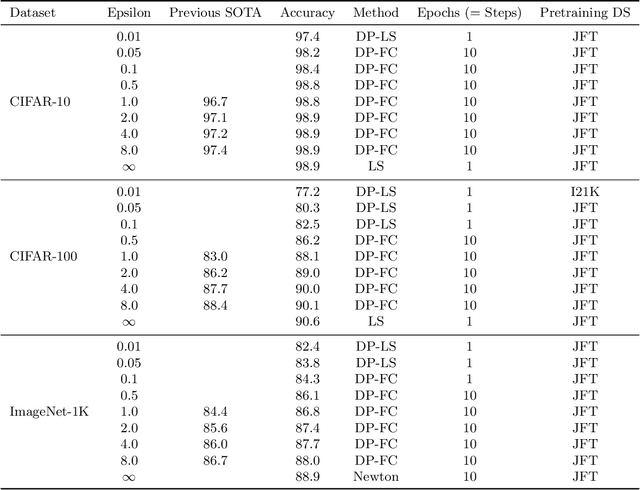
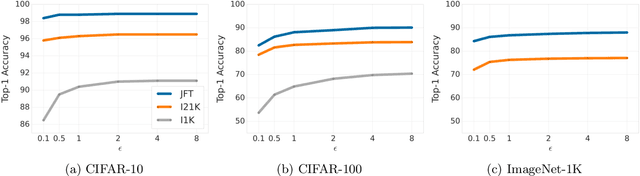
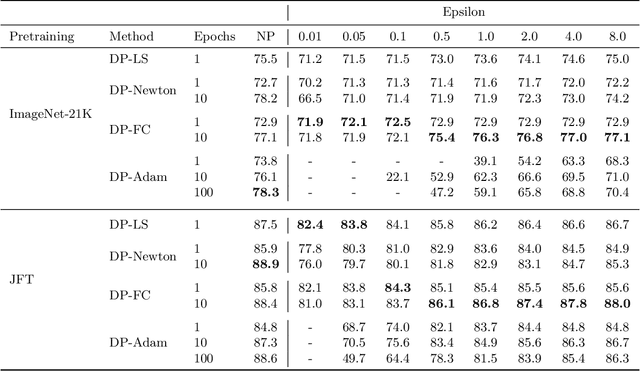
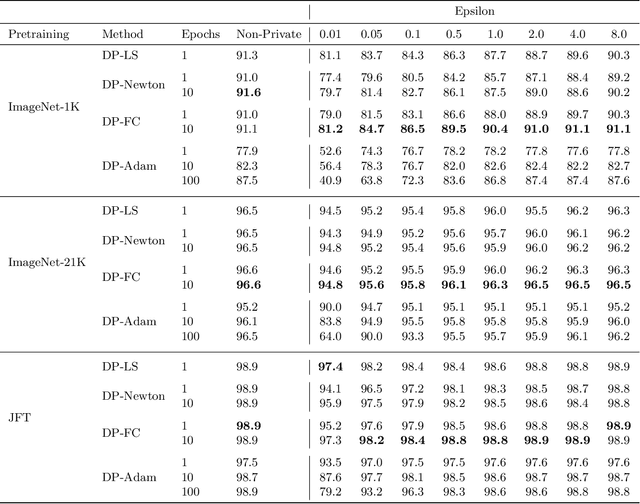
Leveraging transfer learning has recently been shown to be an effective strategy for training large models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that linear regression is much more effective than logistic regression from both privacy and computational aspects, especially at stricter epsilon values ($\epsilon < 1$). On the optimization side, we also explore using Newton's method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is effective at lower epsilons while Newton's method is effective at larger epsilon values. To combine the benefits of both, we propose a novel algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all $\epsilon$ values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of $\epsilon$ typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88\% under (8, $8 * 10^{-7}$)-DP and 84.3\% under (0.1, $8 * 10^{-7}$)-DP.
Line Graph Contrastive Learning for Link Prediction
Oct 25, 2022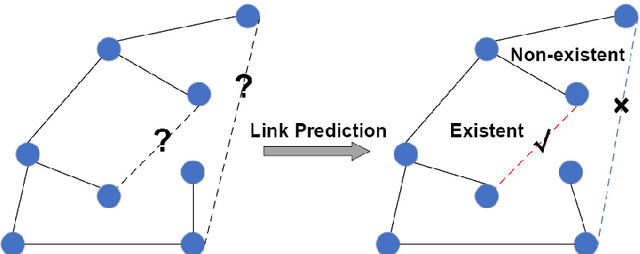
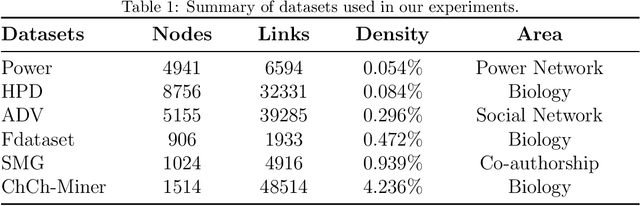
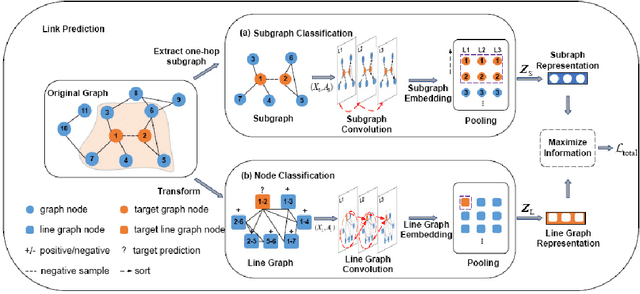
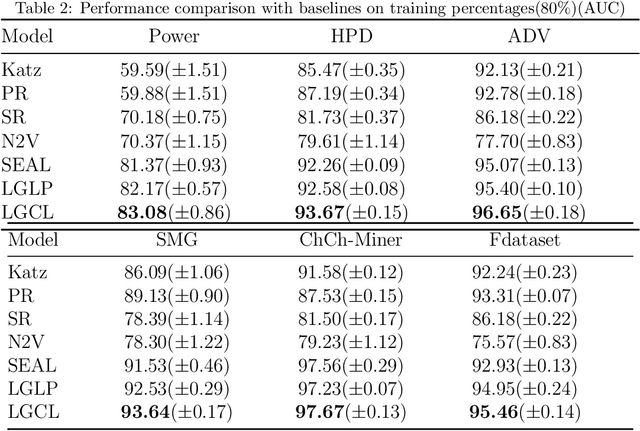
Link prediction task aims to predict the connection of two nodes in the network. Existing works mainly predict links by node pairs similarity measurements. However, if the local structure doesn't meet such measurement assumption, the algorithms' performance will deteriorate rapidly. To overcome these limitations, we propose a Line Graph Contrastive Learning (LGCL) method to obtain multiview information. Our framework obtains a subgraph view by h-hop subgraph sampling with target node pairs as the center. After transforming the sampled subgraph into a line graph, the edge embedding information is directly accessible, and the link prediction task is converted into a node classification task. Then, different graph convolution operators learn representations from double perspectives. Finally, contrastive learning is adopted to balance the subgraph representations of these perspectives via maximizing mutual information. With experiments on six public datasets, LGCL outperforms current benchmarks on link prediction tasks and shows better generalization performance and robustness.
Open Relation and Event Type Discovery with Type Abstraction
Nov 30, 2022
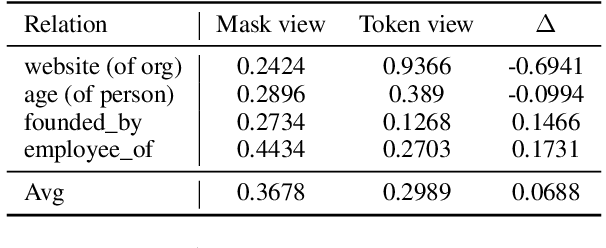
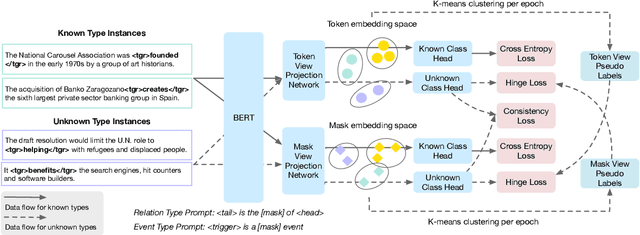
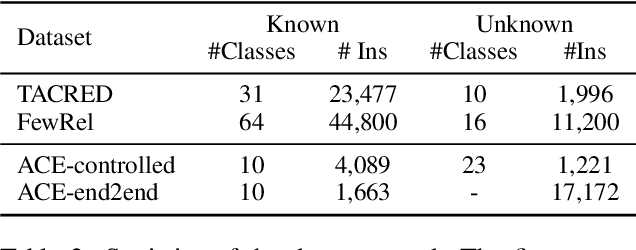
Conventional closed-world information extraction (IE) approaches rely on human ontologies to define the scope for extraction. As a result, such approaches fall short when applied to new domains. This calls for systems that can automatically infer new types from given corpora, a task which we refer to as type discovery. To tackle this problem, we introduce the idea of type abstraction, where the model is prompted to generalize and name the type. Then we use the similarity between inferred names to induce clusters. Observing that this abstraction-based representation is often complementary to the entity/trigger token representation, we set up these two representations as two views and design our model as a co-training framework. Our experiments on multiple relation extraction and event extraction datasets consistently show the advantage of our type abstraction approach. Code available at https://github.com/raspberryice/type-discovery-abs.
FretNet: Continuous-Valued Pitch Contour Streaming for Polyphonic Guitar Tablature Transcription
Dec 06, 2022
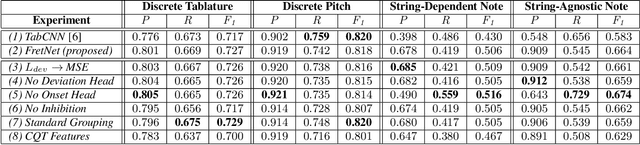
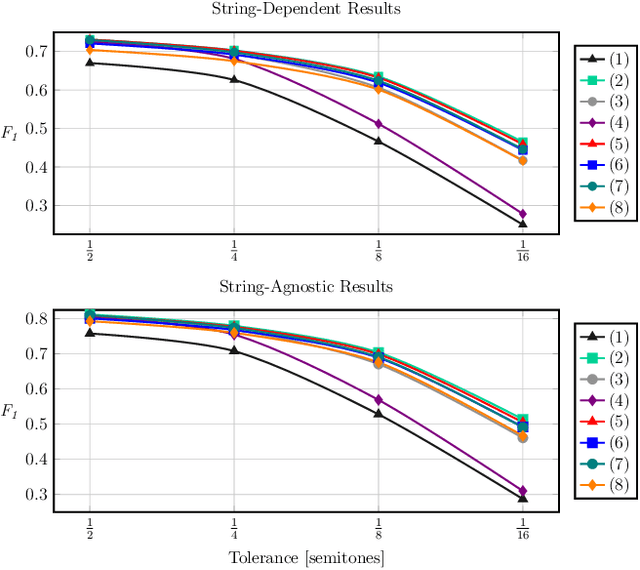
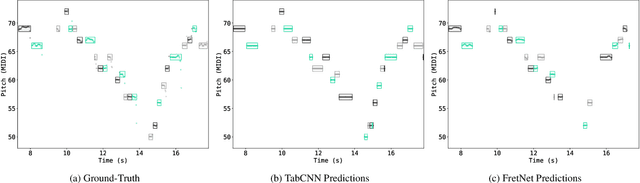
In recent years, the task of Automatic Music Transcription (AMT), whereby various attributes of music notes are estimated from audio, has received increasing attention. At the same time, the related task of Multi-Pitch Estimation (MPE) remains a challenging but necessary component of almost all AMT approaches, even if only implicitly. In the context of AMT, pitch information is typically quantized to the nominal pitches of the Western music scale. Even in more general contexts, MPE systems typically produce pitch predictions with some degree of quantization. In certain applications of AMT, such as Guitar Tablature Transcription (GTT), it is more meaningful to estimate continuous-valued pitch contours. Guitar tablature has the capacity to represent various playing techniques, some of which involve pitch modulation. Contemporary approaches to AMT do not adequately address pitch modulation, and offer only less quantization at the expense of more model complexity. In this paper, we present a GTT formulation that estimates continuous-valued pitch contours, grouping them according to their string and fret of origin. We demonstrate that for this task, the proposed method significantly improves the resolution of MPE and simultaneously yields tablature estimation results competitive with baseline models.
Neural Cell Video Synthesis via Optical-Flow Diffusion
Dec 06, 2022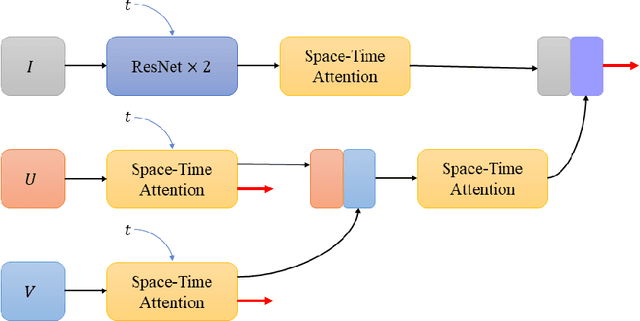
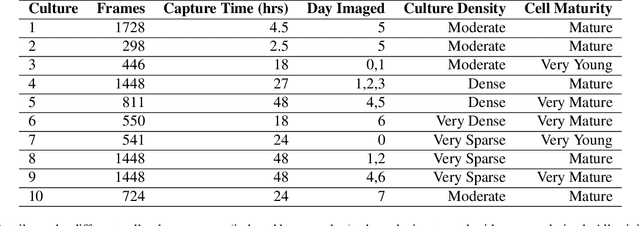
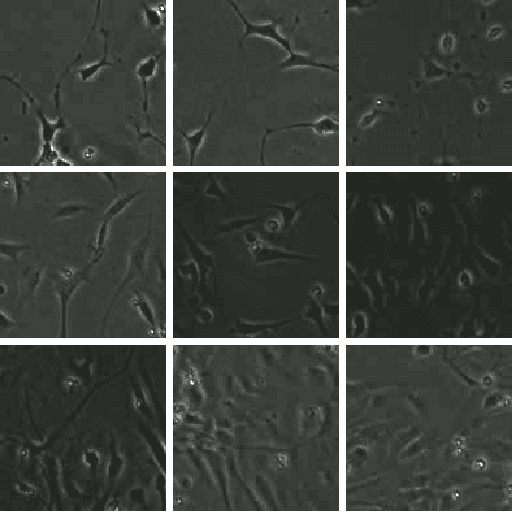

The biomedical imaging world is notorious for working with small amounts of data, frustrating state-of-the-art efforts in the computer vision and deep learning worlds. With large datasets, it is easier to make progress we have seen from the natural image distribution. It is the same with microscopy videos of neuron cells moving in a culture. This problem presents several challenges as it can be difficult to grow and maintain the culture for days, and it is expensive to acquire the materials and equipment. In this work, we explore how to alleviate this data scarcity problem by synthesizing the videos. We, therefore, take the recent work of the video diffusion model to synthesize videos of cells from our training dataset. We then analyze the model's strengths and consistent shortcomings to guide us on improving video generation to be as high-quality as possible. To improve on such a task, we propose modifying the denoising function and adding motion information (dense optical flow) so that the model has more context regarding how video frames transition over time and how each pixel changes over time.
Capturing Shape Information with Multi-Scale Topological Loss Terms for 3D Reconstruction
Mar 03, 2022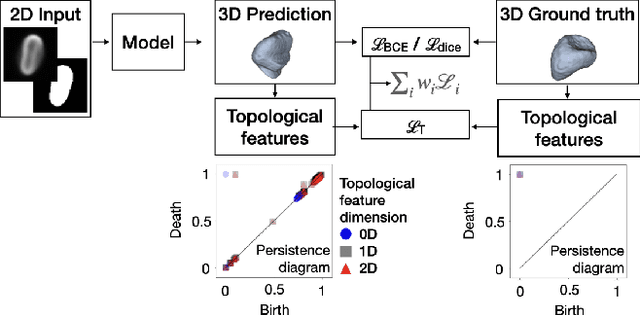
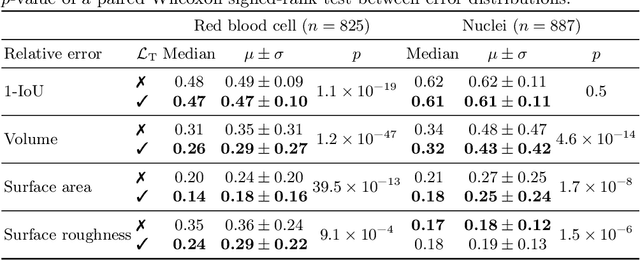
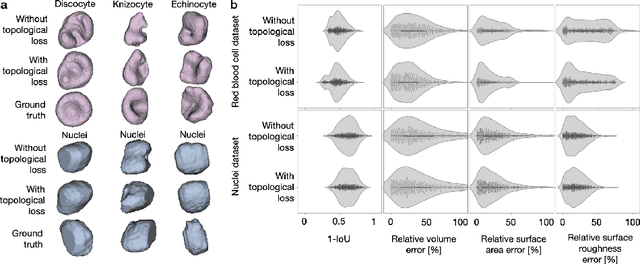
Reconstructing 3D objects from 2D images is both challenging for our brains and machine learning algorithms. To support this spatial reasoning task, contextual information about the overall shape of an object is critical. However, such information is not captured by established loss terms (e.g. Dice loss). We propose to complement geometrical shape information by including multi-scale topological features, such as connected components, cycles, and voids, in the reconstruction loss. Our method calculates topological features from 3D volumetric data based on cubical complexes and uses an optimal transport distance to guide the reconstruction process. This topology-aware loss is fully differentiable, computationally efficient, and can be added to any neural network. We demonstrate the utility of our loss by incorporating it into SHAPR, a model for predicting the 3D cell shape of individual cells based on 2D microscopy images. Using a hybrid loss that leverages both geometrical and topological information of single objects to assess their shape, we find that topological information substantially improves the quality of reconstructions, thus highlighting its ability to extract more relevant features from image datasets.
Provably Efficient Model-free RL in Leader-Follower MDP with Linear Function Approximation
Dec 15, 2022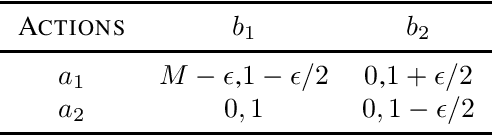
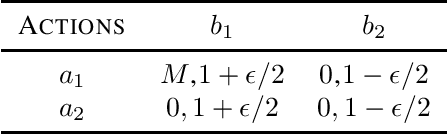
We consider a multi-agent episodic MDP setup where an agent (leader) takes action at each step of the episode followed by another agent (follower). The state evolution and rewards depend on the joint action pair of the leader and the follower. Such type of interactions can find applications in many domains such as smart grids, mechanism design, security, and policymaking. We are interested in how to learn policies for both the players with provable performance guarantee under a bandit feedback setting. We focus on a setup where both the leader and followers are {\em non-myopic}, i.e., they both seek to maximize their rewards over the entire episode and consider a linear MDP which can model continuous state-space which is very common in many RL applications. We propose a {\em model-free} RL algorithm and show that $\tilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret bounds can be achieved for both the leader and the follower, where $d$ is the dimension of the feature mapping, $H$ is the length of the episode, and $T$ is the total number of steps under the bandit feedback information setup. Thus, our result holds even when the number of states becomes infinite. The algorithm relies on {\em novel} adaptation of the LSVI-UCB algorithm. Specifically, we replace the standard greedy policy (as the best response) with the soft-max policy for both the leader and the follower. This turns out to be key in establishing uniform concentration bound for the value functions. To the best of our knowledge, this is the first sub-linear regret bound guarantee for the Markov games with non-myopic followers with function approximation.
Interpretable ML for Imbalanced Data
Dec 15, 2022
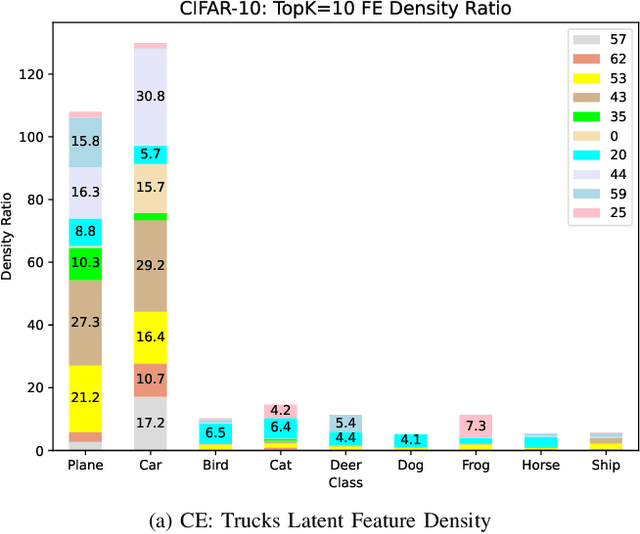


Deep learning models are being increasingly applied to imbalanced data in high stakes fields such as medicine, autonomous driving, and intelligence analysis. Imbalanced data compounds the black-box nature of deep networks because the relationships between classes may be highly skewed and unclear. This can reduce trust by model users and hamper the progress of developers of imbalanced learning algorithms. Existing methods that investigate imbalanced data complexity are geared toward binary classification, shallow learning models and low dimensional data. In addition, current eXplainable Artificial Intelligence (XAI) techniques mainly focus on converting opaque deep learning models into simpler models (e.g., decision trees) or mapping predictions for specific instances to inputs, instead of examining global data properties and complexities. Therefore, there is a need for a framework that is tailored to modern deep networks, that incorporates large, high dimensional, multi-class datasets, and uncovers data complexities commonly found in imbalanced data (e.g., class overlap, sub-concepts, and outlier instances). We propose a set of techniques that can be used by both deep learning model users to identify, visualize and understand class prototypes, sub-concepts and outlier instances; and by imbalanced learning algorithm developers to detect features and class exemplars that are key to model performance. Our framework also identifies instances that reside on the border of class decision boundaries, which can carry highly discriminative information. Unlike many existing XAI techniques which map model decisions to gray-scale pixel locations, we use saliency through back-propagation to identify and aggregate image color bands across entire classes. Our framework is publicly available at \url{https://github.com/dd1github/XAI_for_Imbalanced_Learning}
ORCa: Glossy Objects as Radiance Field Cameras
Dec 08, 2022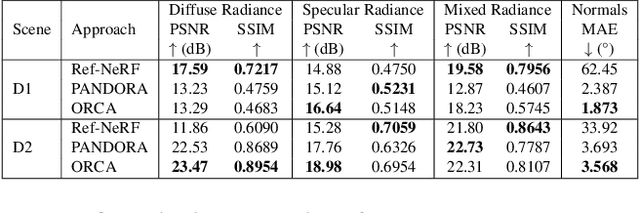
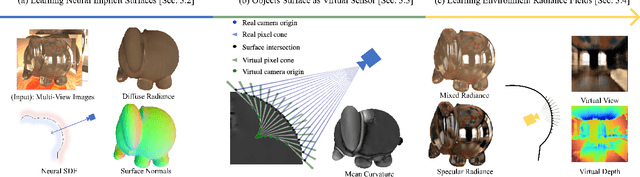
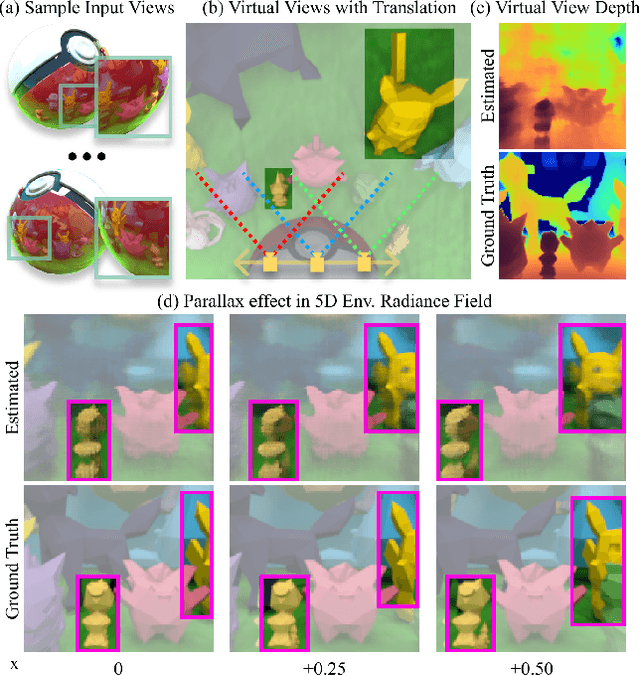
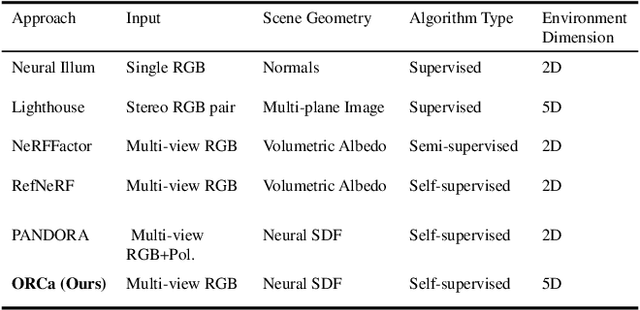
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Learning to Dub Movies via Hierarchical Prosody Models
Dec 08, 2022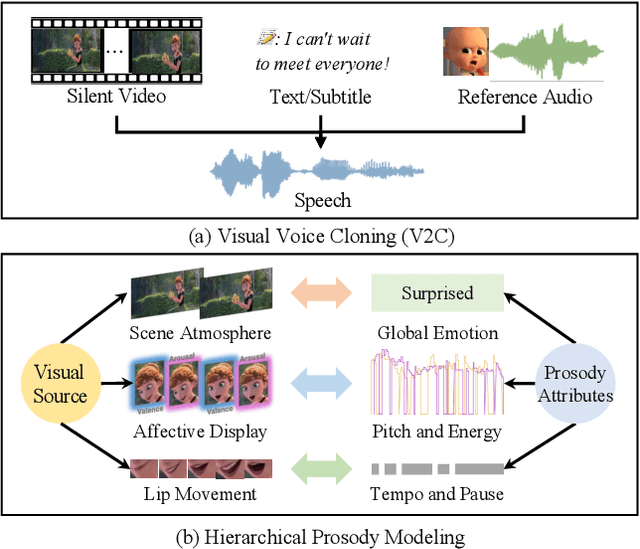
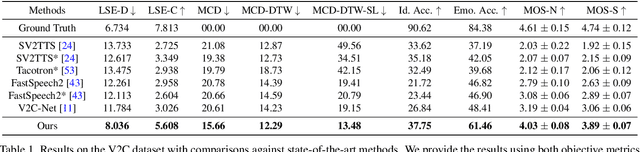
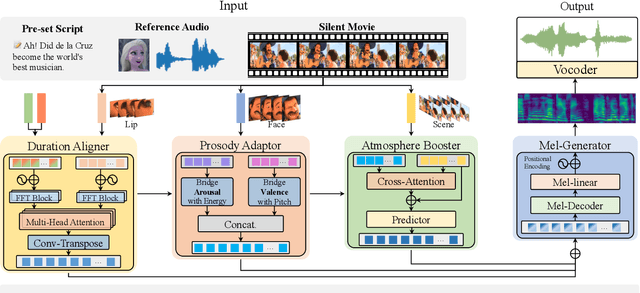
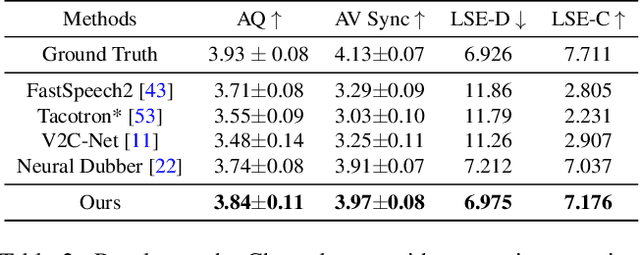
Given a piece of text, a video clip and a reference audio, the movie dubbing (also known as visual voice clone V2C) task aims to generate speeches that match the speaker's emotion presented in the video using the desired speaker voice as reference. V2C is more challenging than conventional text-to-speech tasks as it additionally requires the generated speech to exactly match the varying emotions and speaking speed presented in the video. Unlike previous works, we propose a novel movie dubbing architecture to tackle these problems via hierarchical prosody modelling, which bridges the visual information to corresponding speech prosody from three aspects: lip, face, and scene. Specifically, we align lip movement to the speech duration, and convey facial expression to speech energy and pitch via attention mechanism based on valence and arousal representations inspired by recent psychology findings. Moreover, we design an emotion booster to capture the atmosphere from global video scenes. All these embeddings together are used to generate mel-spectrogram and then convert to speech waves via existing vocoder. Extensive experimental results on the Chem and V2C benchmark datasets demonstrate the favorable performance of the proposed method. The source code and trained models will be released to the public.