 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Agglomeration of Polygonal Grids using Graph Neural Networks with applications to Multigrid solvers
Oct 31, 2022
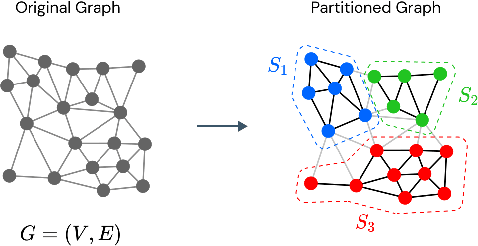
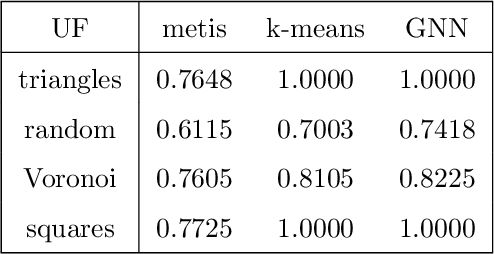
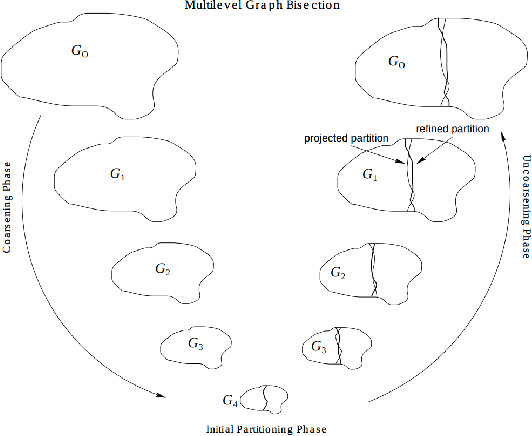
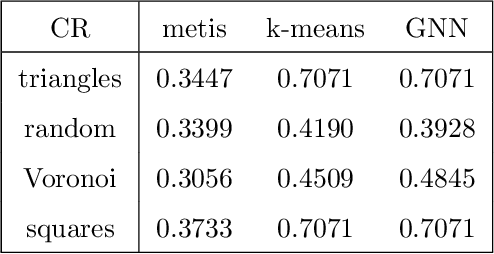
Agglomeration-based strategies are important both within adaptive refinement algorithms and to construct scalable multilevel algebraic solvers. In order to automatically perform agglomeration of polygonal grids, we propose the use of Graph Neural Networks (GNNs) to partition the connectivity graph of a computational mesh. GNNs have the advantage to process naturally and simultaneously both the graph structure of mesh and the geometrical information, such as the areas of the elements or their barycentric coordinates. This is not the case with other approaches such as METIS, a standard algorithm for graph partitioning which is meant to process only the graph information, or the k-means clustering algorithm, which can process only the geometrical information. Performance in terms of quality metrics is enhanced for Machine Learning (ML) strategies, with GNNs featuring a lower computational cost online. Such models also show a good degree of generalization when applied to more complex geometries, such as brain MRI scans, and the capability of preserving the quality of the grid. The effectiveness of these strategies is demonstrated also when applied to MultiGrid (MG) solvers in a Polygonal Discontinuous Galerkin (PolyDG) framework.
Cross-Scale Context Extracted Hashing for Fine-Grained Image Binary Encoding
Oct 14, 2022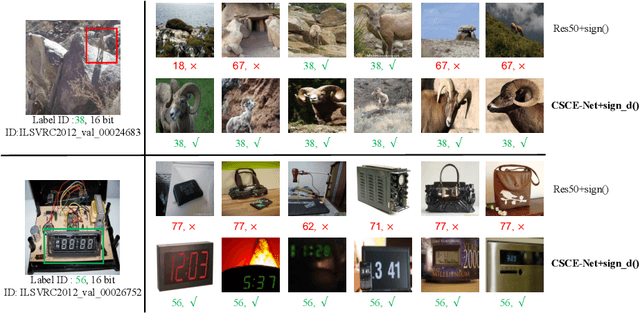
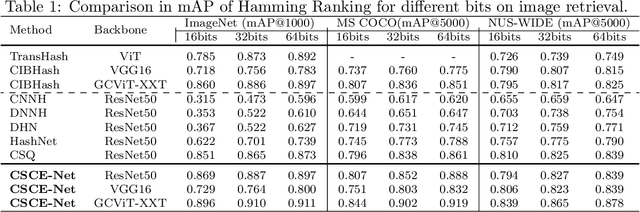
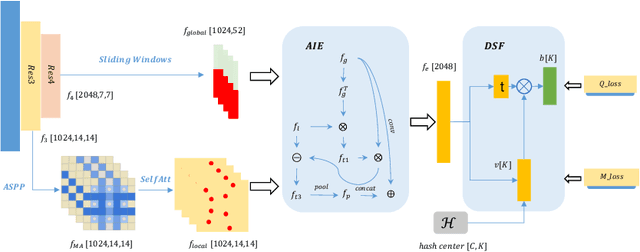
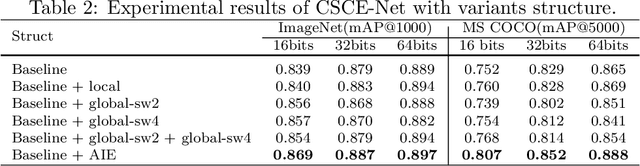
Deep hashing has been widely applied to large-scale image retrieval tasks owing to efficient computation and low storage cost by encoding high-dimensional image data into binary codes. Since binary codes do not contain as much information as float features, the essence of binary encoding is preserving the main context to guarantee retrieval quality. However, the existing hashing methods have great limitations on suppressing redundant background information and accurately encoding from Euclidean space to Hamming space by a simple sign function. In order to solve these problems, a Cross-Scale Context Extracted Hashing Network (CSCE-Net) is proposed in this paper. Firstly, we design a two-branch framework to capture fine-grained local information while maintaining high-level global semantic information. Besides, Attention guided Information Extraction module (AIE) is introduced between two branches, which suppresses areas of low context information cooperated with global sliding windows. Unlike previous methods, our CSCE-Net learns a content-related Dynamic Sign Function (DSF) to replace the original simple sign function. Therefore, the proposed CSCE-Net is context-sensitive and able to perform well on accurate image binary encoding. We further demonstrate that our CSCE-Net is superior to the existing hashing methods, which improves retrieval performance on standard benchmarks.
Channel-Aware Pretraining of Joint Encoder-Decoder Self-Supervised Model for Telephonic-Speech ASR
Nov 03, 2022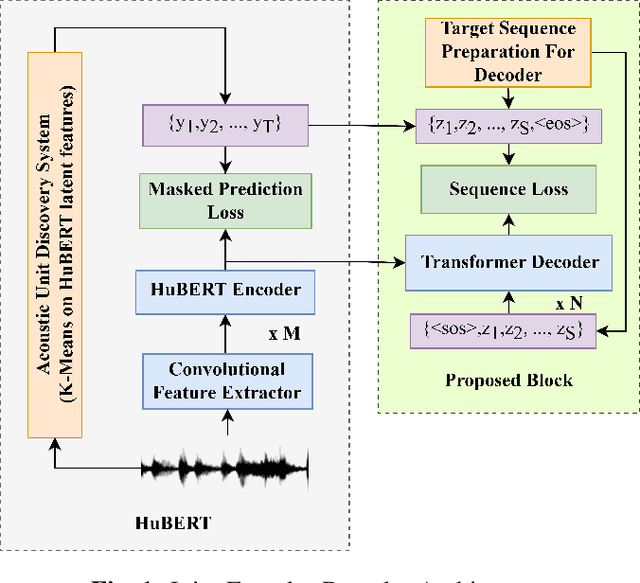
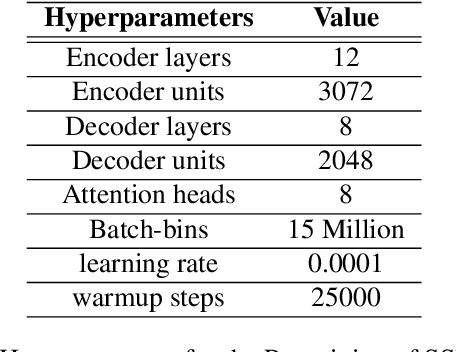
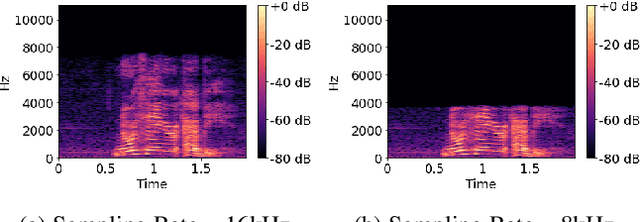
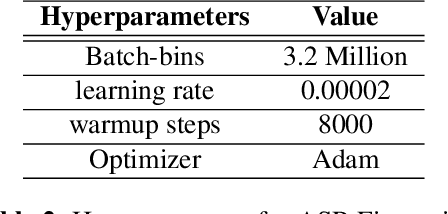
This paper proposes a novel technique to obtain better downstream ASR performance from a joint encoder-decoder self-supervised model when trained with speech pooled from two different channels (narrow and wide band). The joint encoder-decoder self-supervised model extends the HuBERT model with a Transformer decoder. HuBERT performs clustering of features and predicts the class of every input frame. In simple pooling, which is our baseline, there is no way to identify the channel information. To incorporate channel information, we have proposed non-overlapping cluster IDs for speech from different channels. Our method gives a relative improvement of ~ 5% over the joint encoder-decoder self-supervised model built with simple pooling of data, which serves as our baseline.
An Information-theoretic Method for Collaborative Distributed Learning with Limited Communication
May 13, 2022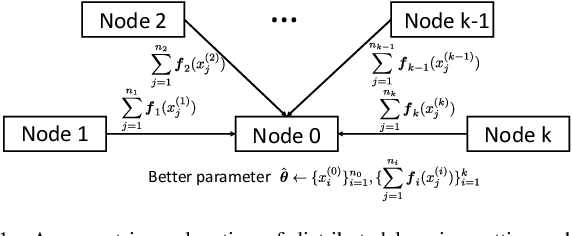
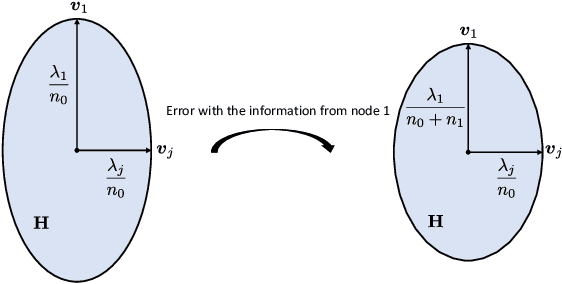

In this paper, we study the information transmission problem under the distributed learning framework, where each worker node is merely permitted to transmit a $m$-dimensional statistic to improve learning results of the target node. Specifically, we evaluate the corresponding expected population risk (EPR) under the regime of large sample sizes. We prove that the performance can be enhanced since the transmitted statistics contribute to estimating the underlying distribution under the mean square error measured by the EPR norm matrix. Accordingly, the transmitted statistics correspond to the eigenvectors of this matrix, and the desired transmission allocates these eigenvectors among the statistics such that the EPR is minimal. Moreover, we provide the analytical solution of the desired statistics for single-node and two-node transmission, where a geometrical interpretation is given to explain the eigenvector selection. For the general case, an efficient algorithm that can output the allocation solution is developed based on the node partitions.
DyRRen: A Dynamic Retriever-Reranker-Generator Model for Numerical Reasoning over Tabular and Textual Data
Nov 23, 2022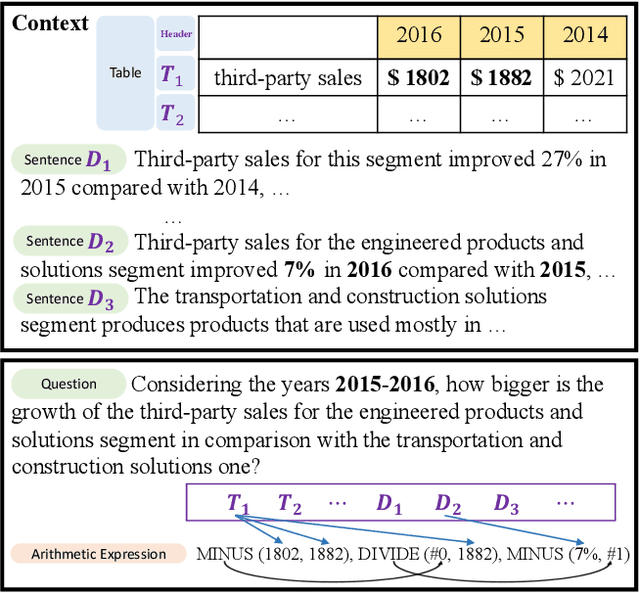
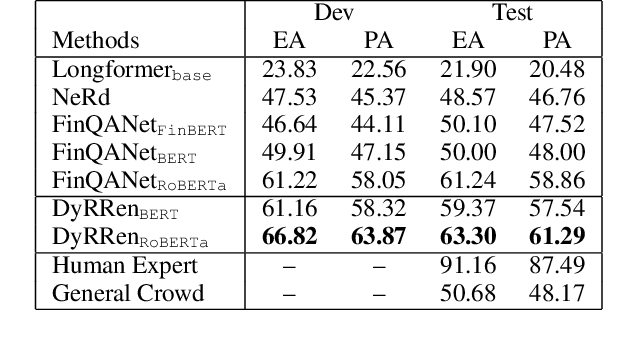
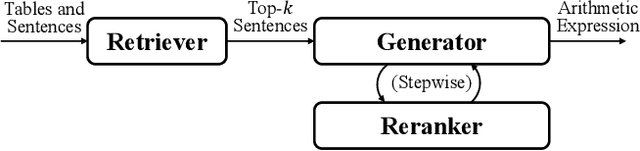
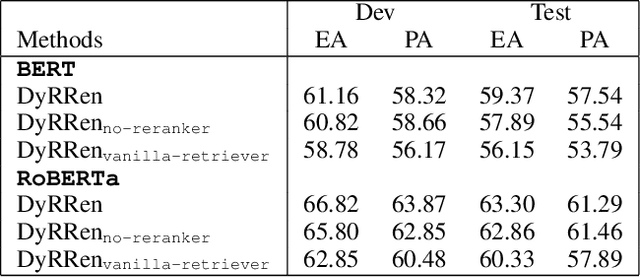
Numerical reasoning over hybrid data containing tables and long texts has recently received research attention from the AI community. To generate an executable reasoning program consisting of math and table operations to answer a question, state-of-the-art methods use a retriever-generator pipeline. However, their retrieval results are static, while different generation steps may rely on different sentences. To attend to the retrieved information that is relevant to each generation step, in this paper, we propose DyRRen, an extended retriever-reranker-generator framework where each generation step is enhanced by a dynamic reranking of retrieved sentences. It outperforms existing baselines on the FinQA dataset.
Video in 10 Bits: Few-Bit VideoQA for Efficiency and Privacy
Oct 18, 2022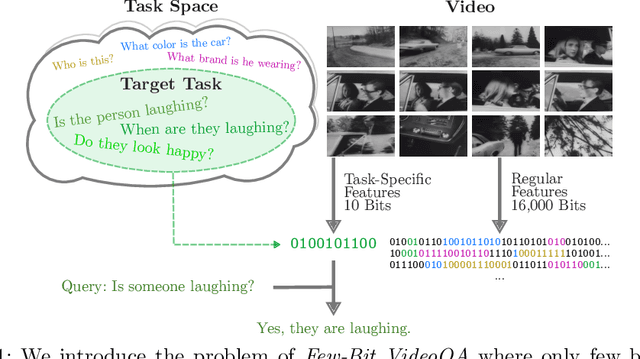

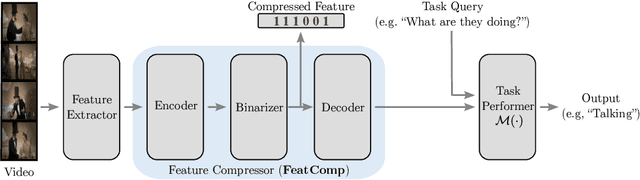
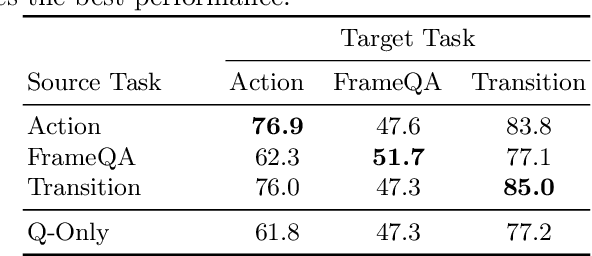
In Video Question Answering (VideoQA), answering general questions about a video requires its visual information. Yet, video often contains redundant information irrelevant to the VideoQA task. For example, if the task is only to answer questions similar to "Is someone laughing in the video?", then all other information can be discarded. This paper investigates how many bits are really needed from the video in order to do VideoQA by introducing a novel Few-Bit VideoQA problem, where the goal is to accomplish VideoQA with few bits of video information (e.g., 10 bits). We propose a simple yet effective task-specific feature compression approach to solve this problem. Specifically, we insert a lightweight Feature Compression Module (FeatComp) into a VideoQA model which learns to extract task-specific tiny features as little as 10 bits, which are optimal for answering certain types of questions. We demonstrate more than 100,000-fold storage efficiency over MPEG4-encoded videos and 1,000-fold over regular floating point features, with just 2.0-6.6% absolute loss in accuracy, which is a surprising and novel finding. Finally, we analyze what the learned tiny features capture and demonstrate that they have eliminated most of the non-task-specific information, and introduce a Bit Activation Map to visualize what information is being stored. This decreases the privacy risk of data by providing k-anonymity and robustness to feature-inversion techniques, which can influence the machine learning community, allowing us to store data with privacy guarantees while still performing the task effectively.
Mutually-Regularized Dual Collaborative Variational Auto-encoder for Recommendation Systems
Nov 21, 2022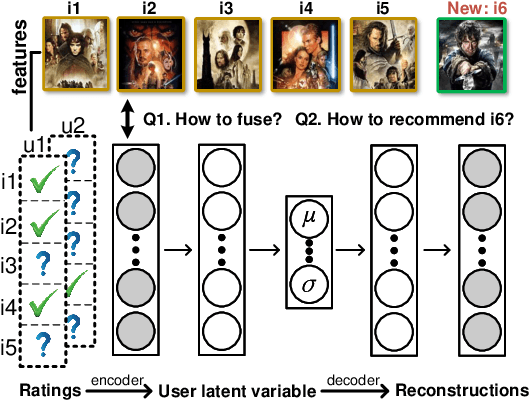
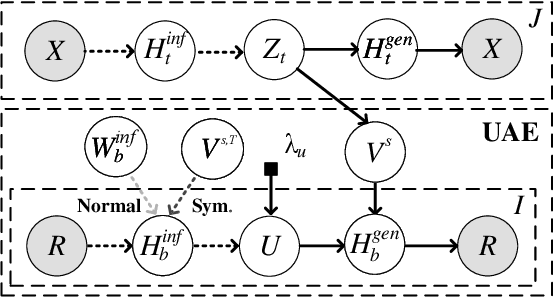
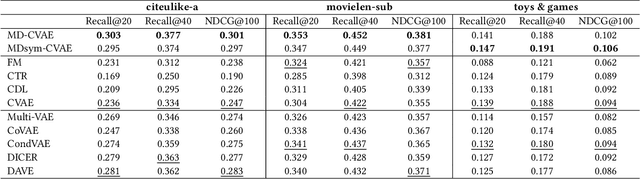
Recently, user-oriented auto-encoders (UAEs) have been widely used in recommender systems to learn semantic representations of users based on their historical ratings. However, since latent item variables are not modeled in UAE, it is difficult to utilize the widely available item content information when ratings are sparse. In addition, whenever new items arrive, we need to wait for collecting rating data for these items and retrain the UAE from scratch, which is inefficient in practice. Aiming to address the above two problems simultaneously, we propose a mutually-regularized dual collaborative variational auto-encoder (MD-CVAE) for recommendation. First, by replacing randomly initialized last layer weights of the vanilla UAE with stacked latent item embeddings, MD-CVAE integrates two heterogeneous information sources, i.e., item content and user ratings, into the same principled variational framework where the weights of UAE are regularized by item content such that convergence to a non-optima due to data sparsity can be avoided. In addition, the regularization is mutual in that user ratings can also help the dual item content module learn more recommendation-oriented item content embeddings. Finally, we propose a symmetric inference strategy for MD-CVAE where the first layer weights of the UAE encoder are tied to the latent item embeddings of the UAE decoder. Through this strategy, no retraining is required to recommend newly introduced items. Empirical studies show the effectiveness of MD-CVAE in both normal and cold-start scenarios. Codes are available at https://github.com/yaochenzhu/MD-CVAE.
API-Spector: an API-to-API Specification Recommendation Engine
Dec 14, 2022
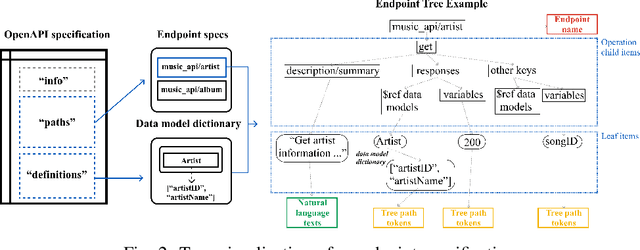
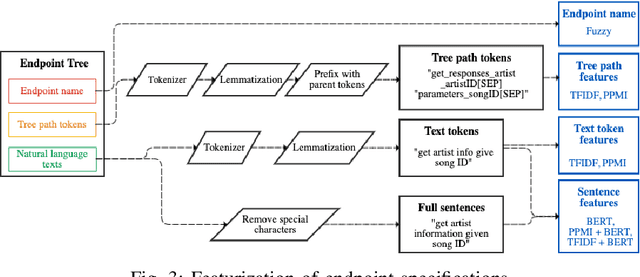
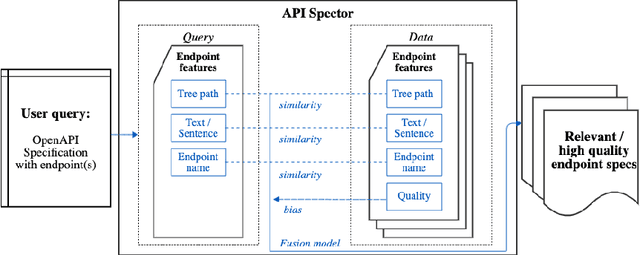
When designing a new API for a large project, developers need to make smart design choices so that their code base can grow sustainably. To ensure that new API components are well designed, developers can learn from existing API components. However, the lack of standardized method for comparing API designs makes this learning process time-consuming and difficult. To address this gap we developed the API-Spector, to the best of our knowledge one of the first API-to-API specification recommendation engines. API-Spector retrieves relevant specification components written in OpenAPI (a widely adopted language used to describe web APIs). API-Spector presents several significant contributions, including: (1) novel methods of processing and extracting key information from OpenAPI specifications, (2) innovative feature extraction techniques that are optimized for the highly technical API specification domain, and (3) a novel log-linear probabilistic model that combines multiple signals to retrieve relevant and high quality OpenAPI specification components given a query specification. We evaluate API-Spector in both quantitative and qualitative tasks and achieve an overall of 91.7% recall@1 and 56.2% F1, which surpasses baseline performance by 15.4% in recall@1 and 3.2% in F1. Overall, API-Spector will allow developers to retrieve relevant OpenAPI specification components from a public or internal database in the early stages of the API development cycle, so that they can learn from existing established examples and potentially identify redundancies in their work. It provides the guidance developers need to accelerate development process and contribute thoughtfully designed APIs that promote code maintainability and quality.
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
Apr 02, 2022
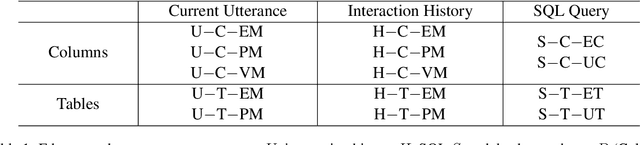
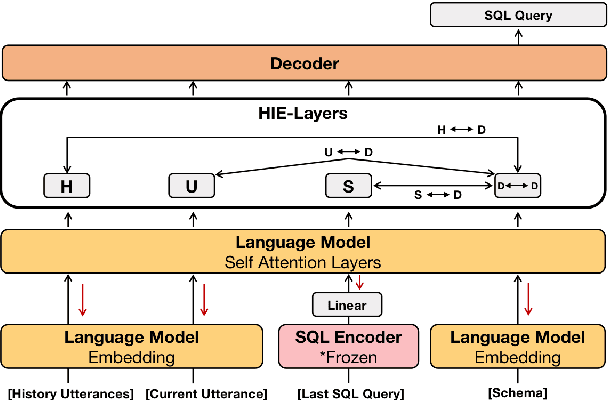

Recently, context-dependent text-to-SQL semantic parsing which translates natural language into SQL in an interaction process has attracted a lot of attention. Previous works leverage context-dependence information either from interaction history utterances or the previous predicted SQL queries but fail in taking advantage of both since of the mismatch between natural language and logic-form SQL. In this work, we propose a History Information Enhanced text-to-SQL model (HIE-SQL) to exploit context-dependence information from both history utterances and the last predicted SQL query. In view of the mismatch, we treat natural language and SQL as two modalities and propose a bimodal pre-trained model to bridge the gap between them. Besides, we design a schema-linking graph to enhance connections from utterances and the SQL query to the database schema. We show our history information enhanced methods improve the performance of HIE-SQL by a significant margin, which achieves new state-of-the-art results on the two context-dependent text-to-SQL benchmarks, the SparC and CoSQL datasets, at the writing time.
Temporal Planning with Incomplete Knowledge and Perceptual Information
Jul 20, 2022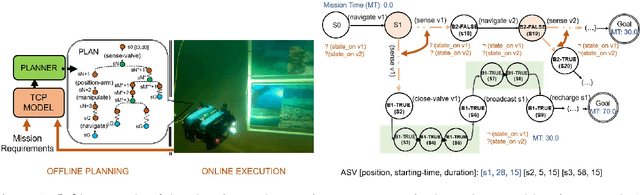
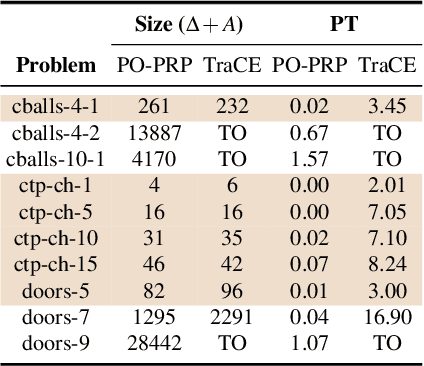

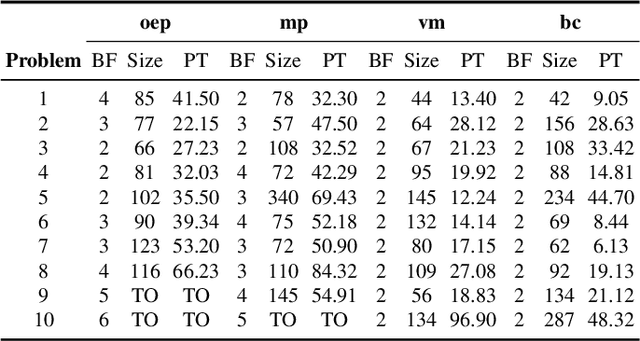
In real-world applications, the ability to reason about incomplete knowledge, sensing, temporal notions, and numeric constraints is vital. While several AI planners are capable of dealing with some of these requirements, they are mostly limited to problems with specific types of constraints. This paper presents a new planning approach that combines contingent plan construction within a temporal planning framework, offering solutions that consider numeric constraints and incomplete knowledge. We propose a small extension to the Planning Domain Definition Language (PDDL) to model (i) incomplete, (ii) knowledge sensing actions that operate over unknown propositions, and (iii) possible outcomes from non-deterministic sensing effects. We also introduce a new set of planning domains to evaluate our solver, which has shown good performance on a variety of problems.
* In Proceedings AREA 2022, arXiv:2207.09058