 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Entities in the Astrophysics Literature: A Comparison of Word-based and Span-based Entity Recognition Methods
Nov 24, 2022
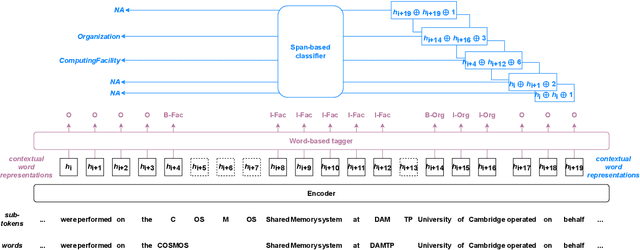
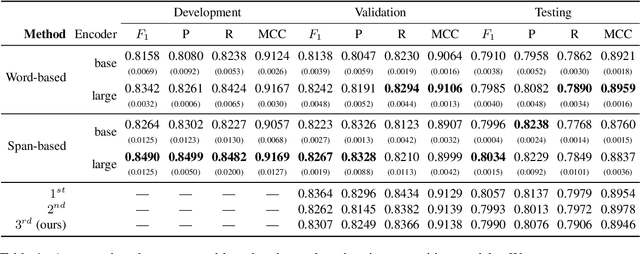
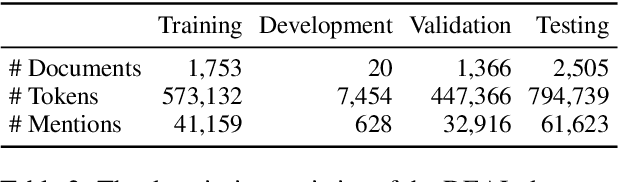
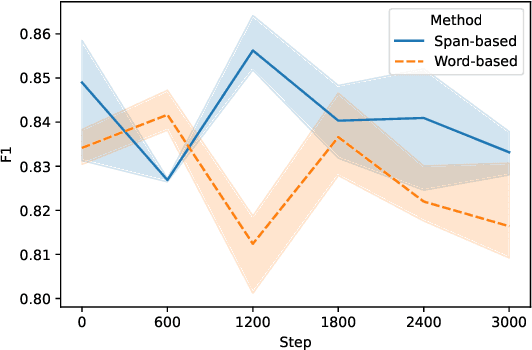
Information Extraction from scientific literature can be challenging due to the highly specialised nature of such text. We describe our entity recognition methods developed as part of the DEAL (Detecting Entities in the Astrophysics Literature) shared task. The aim of the task is to build a system that can identify Named Entities in a dataset composed by scholarly articles from astrophysics literature. We planned our participation such that it enables us to conduct an empirical comparison between word-based tagging and span-based classification methods. When evaluated on two hidden test sets provided by the organizer, our best-performing submission achieved $F_1$ scores of 0.8307 (validation phase) and 0.7990 (testing phase).
Exploiting Device and Audio Data to Tag Music with User-Aware Listening Contexts
Nov 14, 2022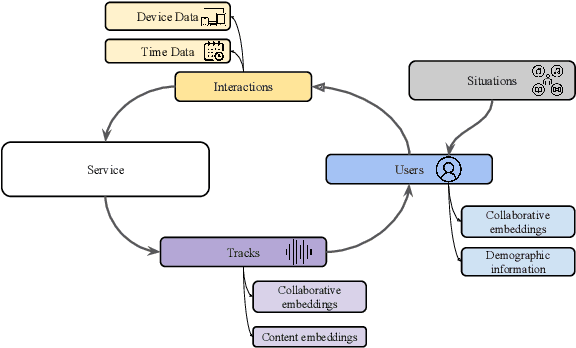

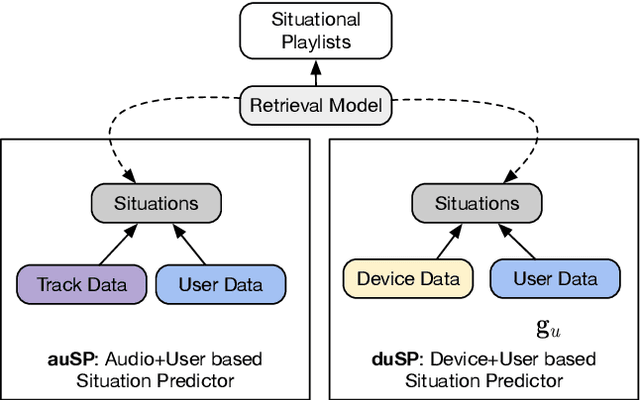
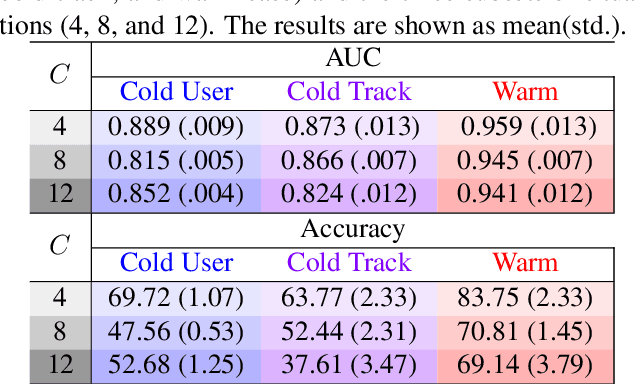
As music has become more available especially on music streaming platforms, people have started to have distinct preferences to fit to their varying listening situations, also known as context. Hence, there has been a growing interest in considering the user's situation when recommending music to users. Previous works have proposed user-aware autotaggers to infer situation-related tags from music content and user's global listening preferences. However, in a practical music retrieval system, the autotagger could be only used by assuming that the context class is explicitly provided by the user. In this work, for designing a fully automatised music retrieval system, we propose to disambiguate the user's listening information from their stream data. Namely, we propose a system which can generate a situational playlist for a user at a certain time 1) by leveraging user-aware music autotaggers, and 2) by automatically inferring the user's situation from stream data (e.g. device, network) and user's general profile information (e.g. age). Experiments show that such a context-aware personalized music retrieval system is feasible, but the performance decreases in the case of new users, new tracks or when the number of context classes increases.
Toward a Neural Semantic Parsing System for EHR Question Answering
Nov 08, 2022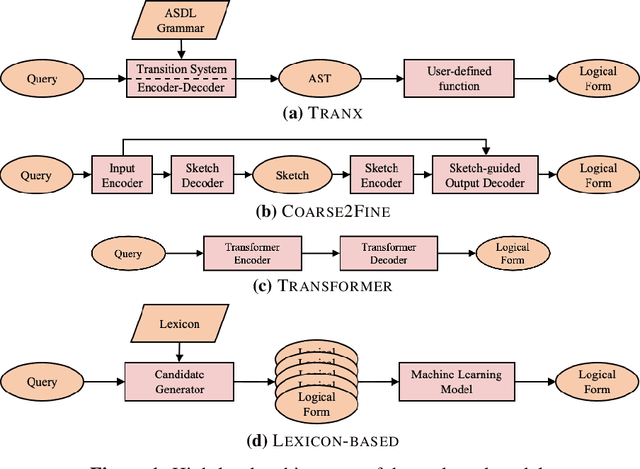
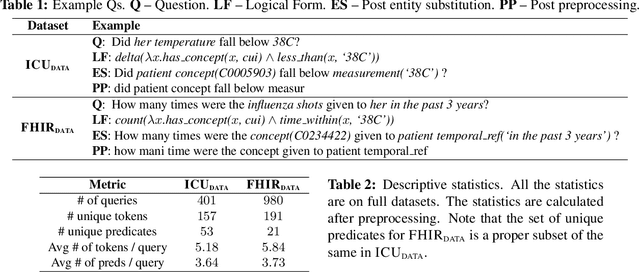
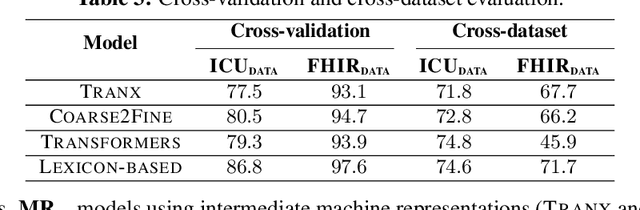
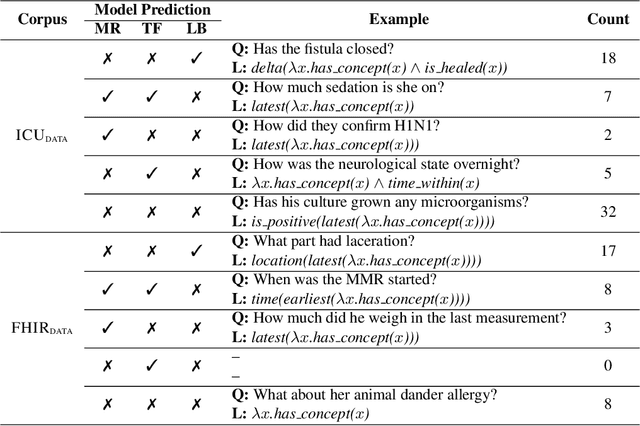
Clinical semantic parsing (SP) is an important step toward identifying the exact information need (as a machine-understandable logical form) from a natural language query aimed at retrieving information from electronic health records (EHRs). Current approaches to clinical SP are largely based on traditional machine learning and require hand-building a lexicon. The recent advancements in neural SP show a promise for building a robust and flexible semantic parser without much human effort. Thus, in this paper, we aim to systematically assess the performance of two such neural SP models for EHR question answering (QA). We found that the performance of these advanced neural models on two clinical SP datasets is promising given their ease of application and generalizability. Our error analysis surfaces the common types of errors made by these models and has the potential to inform future research into improving the performance of neural SP models for EHR QA.
Quantum Sensing Based Joint 3D Beam Training for UAV-mounted STAR-RIS Aided TeraHertz Multi-user Massive MIMO Systems
Dec 15, 2022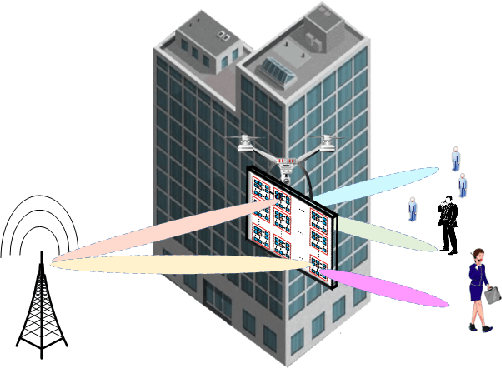
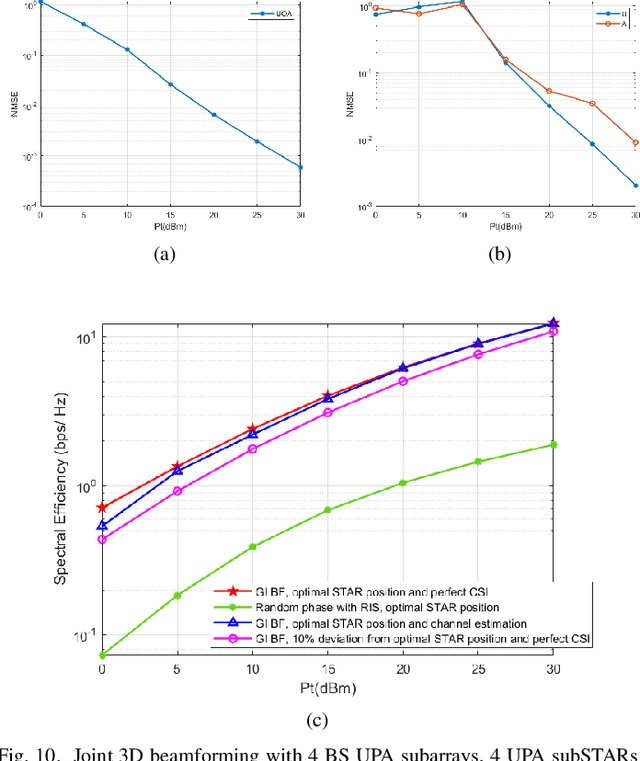
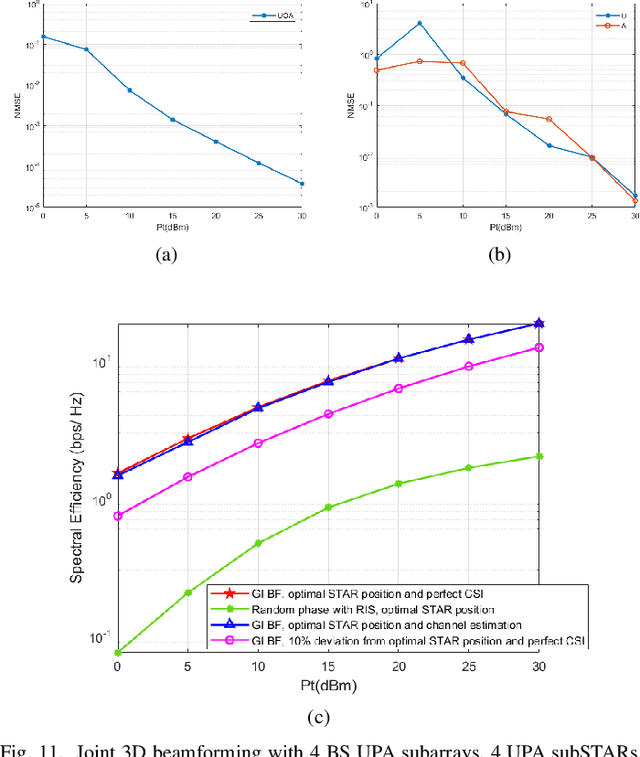
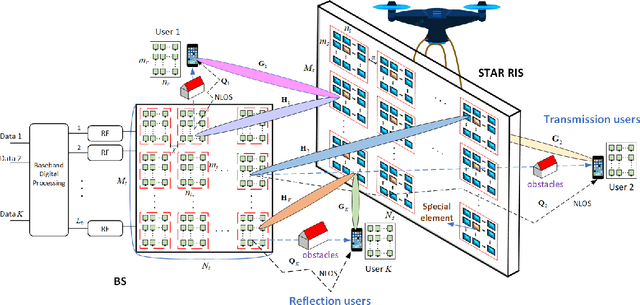
Terahertz (THz) systems are capable of supporting ultra-high data rates thanks to large bandwidth, and the potential to harness high-gain beamforming to combat high pathloss. In this paper, a novel quantum sensing (Ghost Imaging (GI)) based beam training is proposed for Simultaneously Transmitting and Reflecting Reconfigurable Intelligent Surface (STAR RIS) aided THz multi-user massive MIMO systems. We first conduct GI by surrounding 5G downlink signals to obtain 3D images of the environment including users and obstacles. Based on the information, we calculate the optimal position of the UAV-mounted STAR by the proposed algorithm. Thus the position-based beam training can be performed. To enhance the beam-forming gain, we further combine with channel estimation and propose a semi-passive structure of the STAR and ambiguity elimination scheme for separated channel estimation. Thus the ambiguity in cascaded channel estimation, which may affect optimal passive beamforming, is avoided. The optimal active and passive beamforming are then carried out and data transmission is initiated. The proposed BS sub-array and sub-STAR spatial multiplexing architecture, optimal active and passive beamforming, digital precoding, and optimal position of the UAV- mounted STAR are investigated jointly to maximize the average achievable sum rate of the users. Moreover, the cloud radio access networks (CRAN) structured 5G downlink signal is proposed for GI with enhanced resolution. The simulation results show that the proposed scheme achieves beam training and separated channel estimation efficiently, and increases the spectral efficiency dramatically compared to the case when the STAR operates with random phase.
Automatic vehicle trajectory data reconstruction at scale
Dec 15, 2022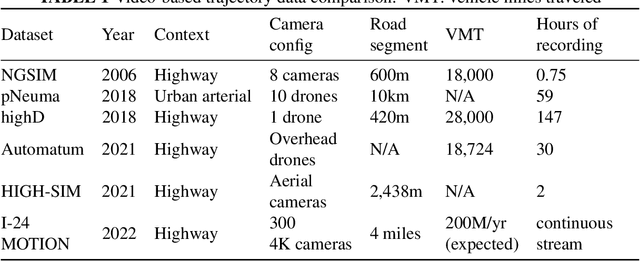
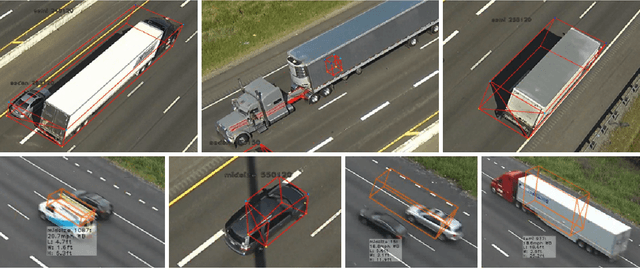
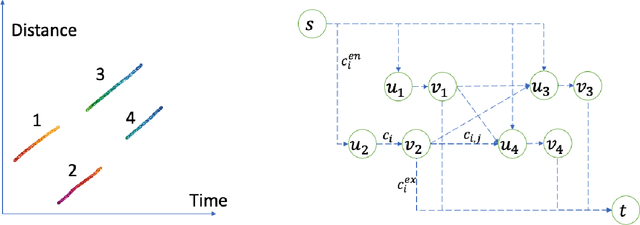

Vehicle trajectory data has received increasing research attention over the past decades. With the technological sensing improvements such as high-resolution video cameras, in-vehicle radars and lidars, abundant individual and contextual traffic data is now available. However, though the data quantity is massive, it is by itself of limited utility for traffic research because of noise and systematic sensing errors, thus necessitates proper processing to ensure data quality. We draw particular attention to extracting high-resolution vehicle trajectory data from video cameras as traffic monitoring cameras are becoming increasingly ubiquitous. We explore methods for automatic trajectory data reconciliation, given "raw" vehicle detection and tracking information from automatic video processing algorithms. We propose a pipeline including a) an online data association algorithm to match fragments that are associated to the same object (vehicle), which is formulated as a min-cost network flow problem of a graph, and b) a trajectory reconciliation method formulated as a quadratic program to enhance raw detection data. The pipeline leverages vehicle dynamics and physical constraints to associate tracked objects when they become fragmented, remove measurement noise on trajectories and impute missing data due to fragmentations. The accuracy is benchmarked on a sample of manually-labeled data, which shows that the reconciled trajectories improve the accuracy on all the tested input data for a wide range of measures. An online version of the reconciliation pipeline is implemented and will be applied in a continuous video processing system running on a camera network covering a 4-mile stretch of Interstate-24 near Nashville, Tennessee.
Cross-Link Channel Prediction for Massive IoT Networks
Dec 15, 2022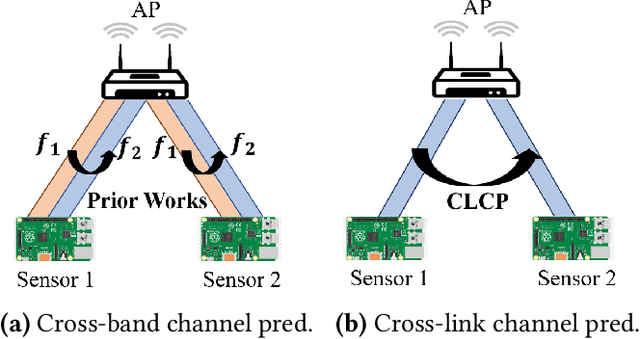
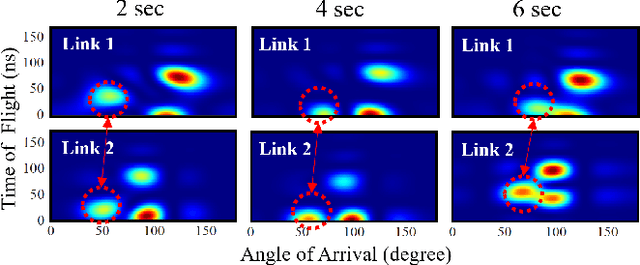
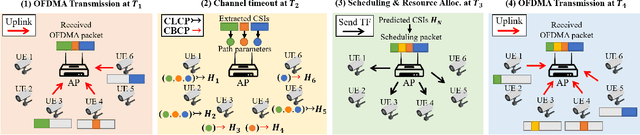
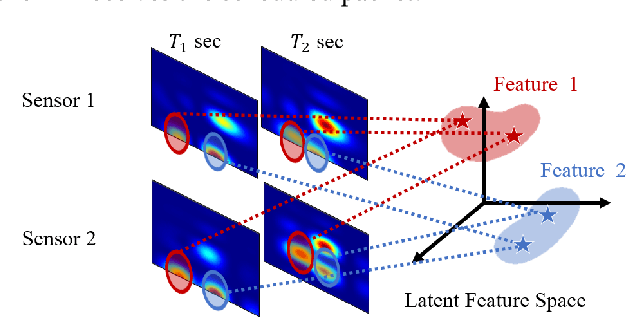
Tomorrow's massive-scale IoT sensor networks are poised to drive uplink traffic demand, especially in areas of dense deployment. To meet this demand, however, network designers leverage tools that often require accurate estimates of Channel State Information (CSI), which incurs a high overhead and thus reduces network throughput. Furthermore, the overhead generally scales with the number of clients, and so is of special concern in such massive IoT sensor networks. While prior work has used transmissions over one frequency band to predict the channel of another frequency band on the same link, this paper takes the next step in the effort to reduce CSI overhead: predict the CSI of a nearby but distinct link. We propose Cross-Link Channel Prediction (CLCP), a technique that leverages multi-view representation learning to predict the channel response of a large number of users, thereby reducing channel estimation overhead further than previously possible. CLCP's design is highly practical, exploiting channel estimates obtained from existing transmissions instead of dedicated channel sounding or extra pilot signals. We have implemented CLCP for two different Wi-Fi versions, namely 802.11n and 802.11ax, the latter being the leading candidate for future IoT networks. We evaluate CLCP in two large-scale indoor scenarios involving both line-of-sight and non-line-of-sight transmissions with up to 144 different 802.11ax users. Moreover, we measure its performance with four different channel bandwidths, from 20 MHz up to 160 MHz. Our results show that CLCP provides a 2x throughput gain over baseline 802.11ax and a 30 percent throughput gain over existing cross-band prediction algorithms.
Efficient Visual Computing with Camera RAW Snapshots
Dec 15, 2022
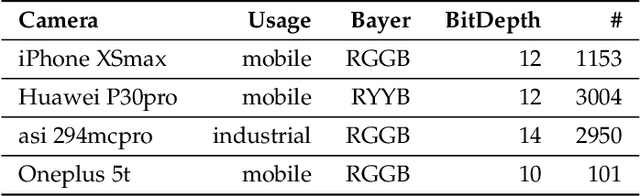

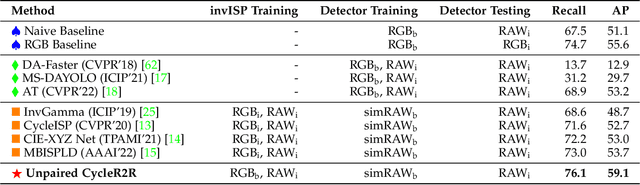
Conventional cameras capture image irradiance on a sensor and convert it to RGB images using an image signal processor (ISP). The images can then be used for photography or visual computing tasks in a variety of applications, such as public safety surveillance and autonomous driving. One can argue that since RAW images contain all the captured information, the conversion of RAW to RGB using an ISP is not necessary for visual computing. In this paper, we propose a novel $\rho$-Vision framework to perform high-level semantic understanding and low-level compression using RAW images without the ISP subsystem used for decades. Considering the scarcity of available RAW image datasets, we first develop an unpaired CycleR2R network based on unsupervised CycleGAN to train modular unrolled ISP and inverse ISP (invISP) models using unpaired RAW and RGB images. We can then flexibly generate simulated RAW images (simRAW) using any existing RGB image dataset and finetune different models originally trained for the RGB domain to process real-world camera RAW images. We demonstrate object detection and image compression capabilities in RAW-domain using RAW-domain YOLOv3 and RAW image compressor (RIC) on snapshots from various cameras. Quantitative results reveal that RAW-domain task inference provides better detection accuracy and compression compared to RGB-domain processing. Furthermore, the proposed \r{ho}-Vision generalizes across various camera sensors and different task-specific models. Additional advantages of the proposed $\rho$-Vision that eliminates the ISP are the potential reductions in computations and processing times.
Two-Server Oblivious Transfer for Quantum Messages
Nov 07, 2022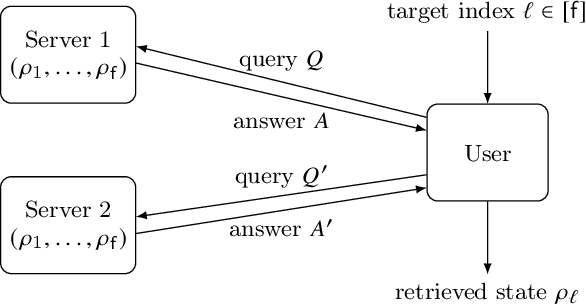
Oblivious transfer is considered as a cryptographic primitive task for quantum information processing over quantum network. Although it is possible with two servers, any existing protocol works only with classical messages. We propose two-server oblivious transfer protocols for quantum messages.
Unified Approach to Secret Sharing and Symmetric Private Information Retrieval with Colluding Servers in Quantum Systems
May 29, 2022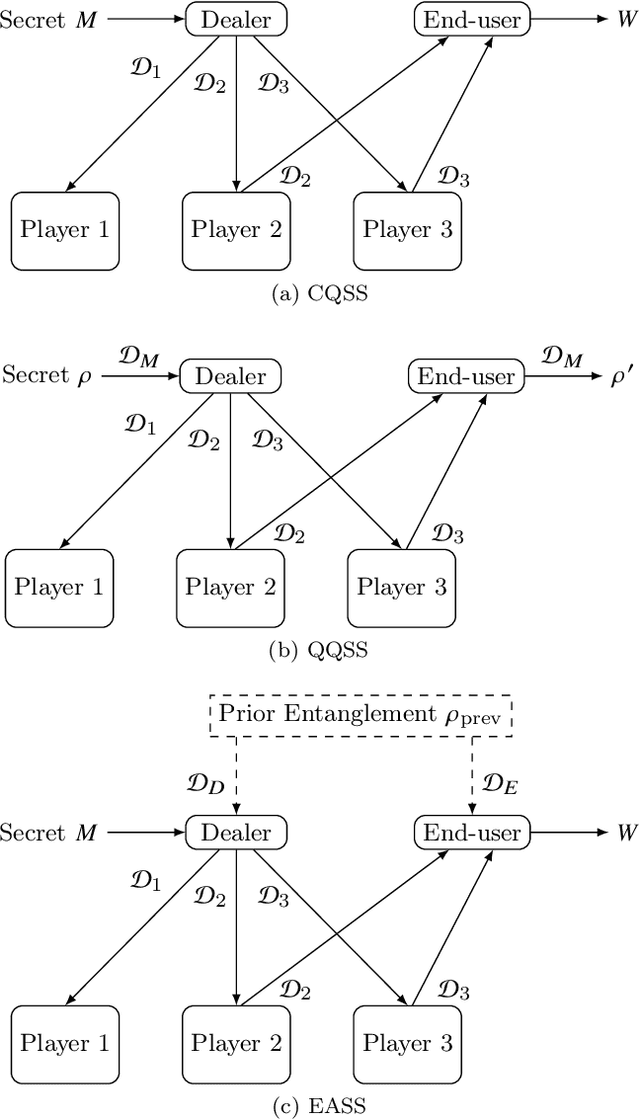
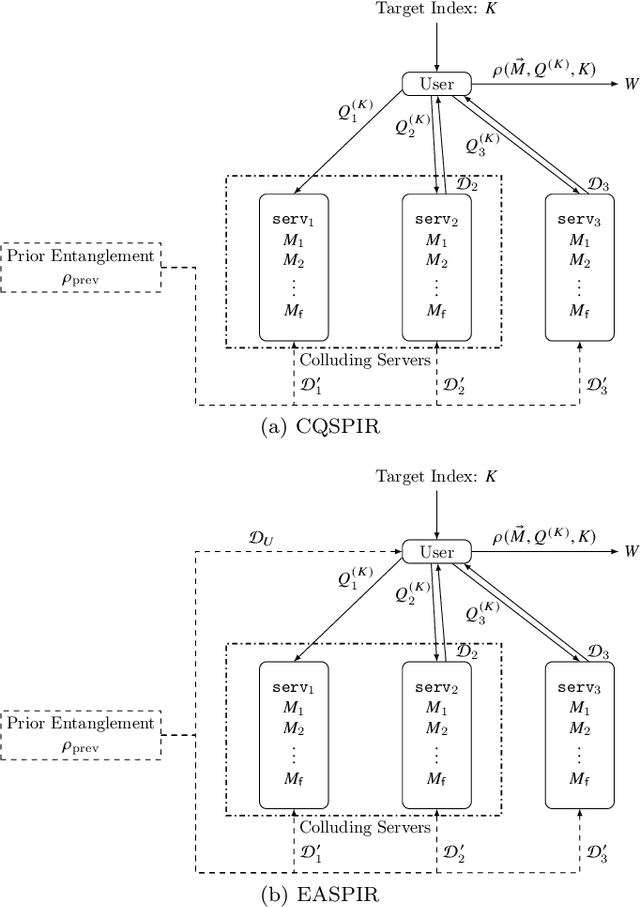
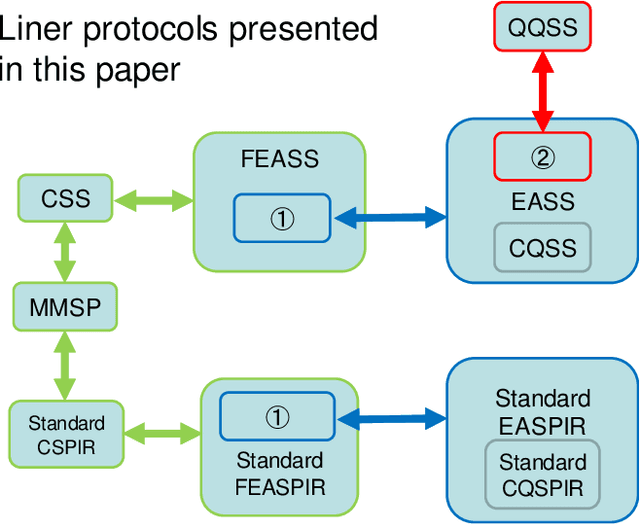
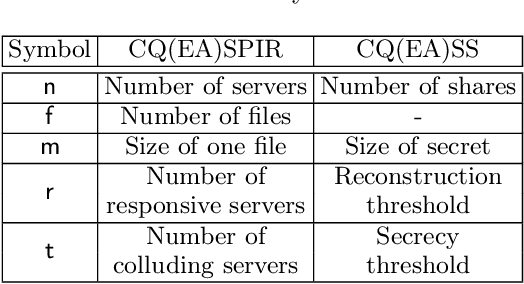
This paper unifiedly addresses two kinds of key quantum secure tasks, i.e., quantum versions of secret sharing (SS) and symmetric private information retrieval (SPIR) by using multi-target monotone span program (MMSP), which characterizes the classical linear protocols of SS and SPIR. In particular, two kinds of quantum extensions of SS are known; One is the classical-quantum (CQ) setting, in which the secret to be sent is classical information and the shares are quantum systems. The other is the quantum-quantum (QQ) setting, in which the secret to be sent is a quantum state and the shares are quantum systems. We newly introduce the third setting, i.e., the entanglement-assisted (EA) setting, which is defined by modifying the CQ setting with allowing prior entanglement between the dealer and the end-user who recovers the secret by collecting the shares. Showing that the linear version of SS with the EA setting is directly linked to MMSP, we characterize linear quantum versions of SS with the CQ ad QQ settings via MMSP. Further, we also introduce the EA setting of SPIR, which is shown to link to MMSP. In addition, we discuss the relation with the quantum version of maximum distance separable (MDS) codes.
Fair contrastive pre-training for geographic images
Nov 16, 2022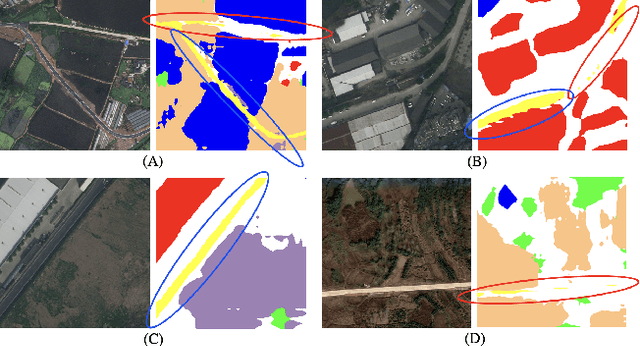
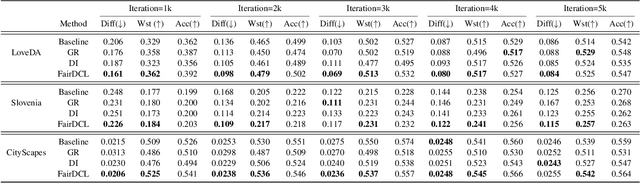
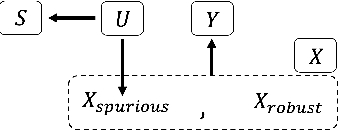
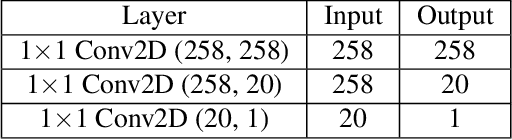
Contrastive representation learning is widely employed in visual recognition for geographic image data (remote-sensing such as satellite imagery or proximal sensing such as street-view imagery), but because of landscape heterogeneity, models can show disparate performance across spatial units. In this work, we consider fairness risks in land-cover semantic segmentation which uses pre-trained representation in contrastive self-supervised learning. We assess class distribution shifts and model prediction disparities across selected sensitive groups: urban and rural scenes for satellite image datasets and city GDP level for a street view image dataset. We propose a mutual information training objective for multi-level latent space. The objective improves feature identification by removing spurious representations of dense local features which are disparately distributed across groups. The method achieves improved fairness results and outperforms state-of-the-art methods in terms of precision-fairness trade-off. In addition, we validate that representations learnt with the proposed method include lowest sensitive information using a linear separation evaluation. This work highlights the need for specific fairness analyses in geographic images, and provides a solution that can be generalized to different self-supervised learning methods or image data. Our code is available at: https://anonymous.4open.science/r/FairDCL-1283