 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explaining Agent's Decision-making in a Hierarchical Reinforcement Learning Scenario
Dec 14, 2022
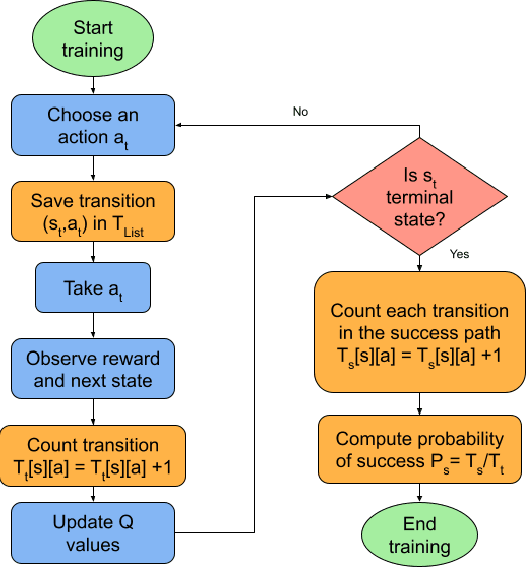
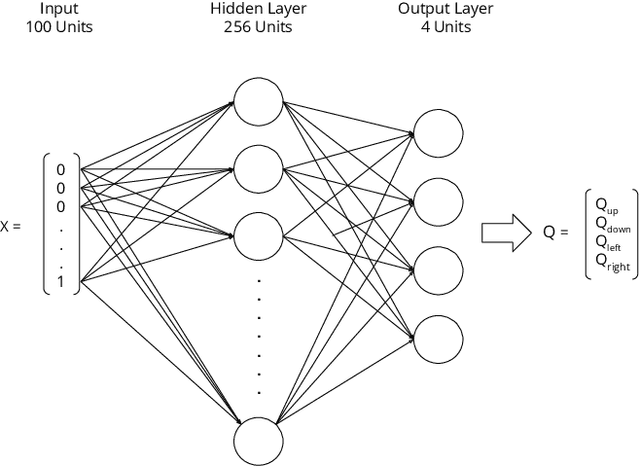
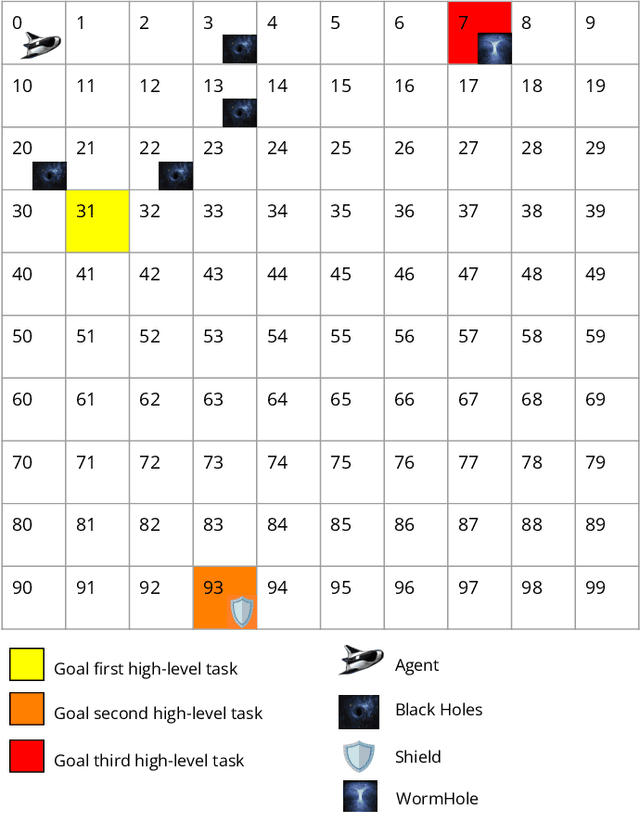
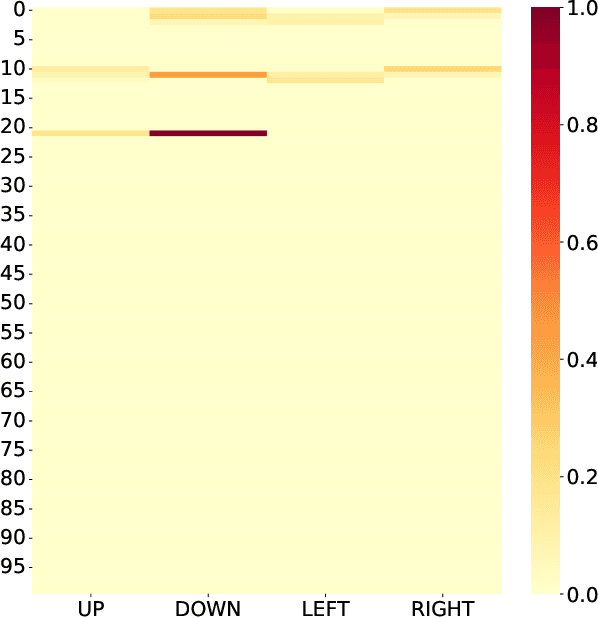
Reinforcement learning is a machine learning approach based on behavioral psychology. It is focused on learning agents that can acquire knowledge and learn to carry out new tasks by interacting with the environment. However, a problem occurs when reinforcement learning is used in critical contexts where the users of the system need to have more information and reliability for the actions executed by an agent. In this regard, explainable reinforcement learning seeks to provide to an agent in training with methods in order to explain its behavior in such a way that users with no experience in machine learning could understand the agent's behavior. One of these is the memory-based explainable reinforcement learning method that is used to compute probabilities of success for each state-action pair using an episodic memory. In this work, we propose to make use of the memory-based explainable reinforcement learning method in a hierarchical environment composed of sub-tasks that need to be first addressed to solve a more complex task. The end goal is to verify if it is possible to provide to the agent the ability to explain its actions in the global task as well as in the sub-tasks. The results obtained showed that it is possible to use the memory-based method in hierarchical environments with high-level tasks and compute the probabilities of success to be used as a basis for explaining the agent's behavior.
MA-GCL: Model Augmentation Tricks for Graph Contrastive Learning
Dec 14, 2022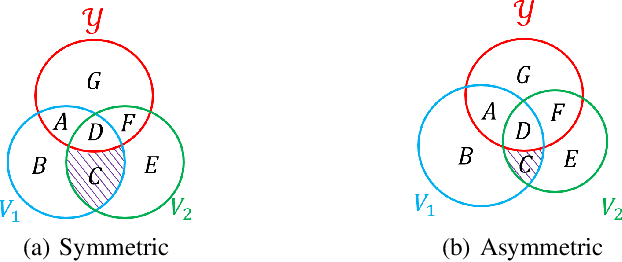
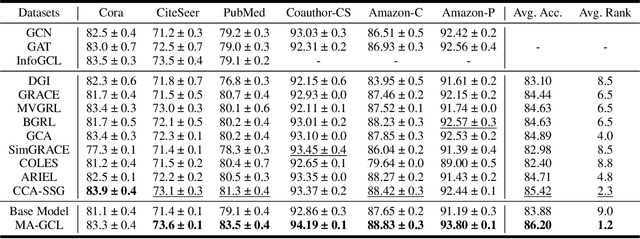
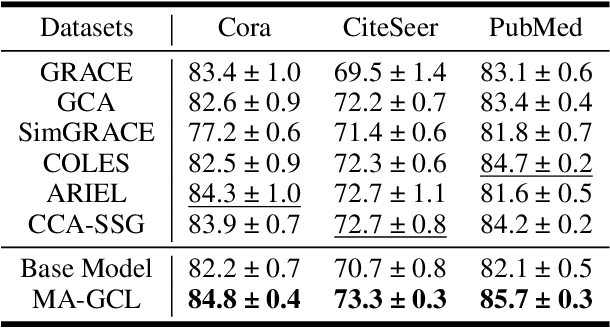
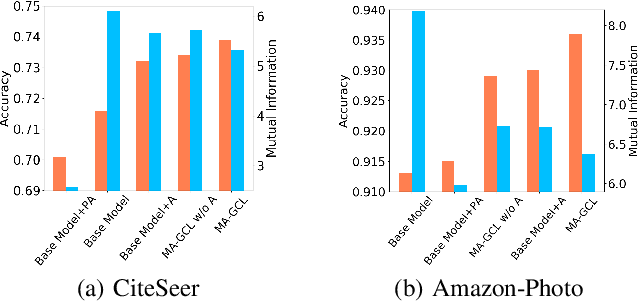
Contrastive learning (CL), which can extract the information shared between different contrastive views, has become a popular paradigm for vision representation learning. Inspired by the success in computer vision, recent work introduces CL into graph modeling, dubbed as graph contrastive learning (GCL). However, generating contrastive views in graphs is more challenging than that in images, since we have little prior knowledge on how to significantly augment a graph without changing its labels. We argue that typical data augmentation techniques (e.g., edge dropping) in GCL cannot generate diverse enough contrastive views to filter out noises. Moreover, previous GCL methods employ two view encoders with exactly the same neural architecture and tied parameters, which further harms the diversity of augmented views. To address this limitation, we propose a novel paradigm named model augmented GCL (MA-GCL), which will focus on manipulating the architectures of view encoders instead of perturbing graph inputs. Specifically, we present three easy-to-implement model augmentation tricks for GCL, namely asymmetric, random and shuffling, which can respectively help alleviate high- frequency noises, enrich training instances and bring safer augmentations. All three tricks are compatible with typical data augmentations. Experimental results show that MA-GCL can achieve state-of-the-art performance on node classification benchmarks by applying the three tricks on a simple base model. Extensive studies also validate our motivation and the effectiveness of each trick. (Code, data and appendix are available at https://github.com/GXM1141/MA-GCL. )
Leveraging Fully Observable Policies for Learning under Partial Observability
Nov 10, 2022
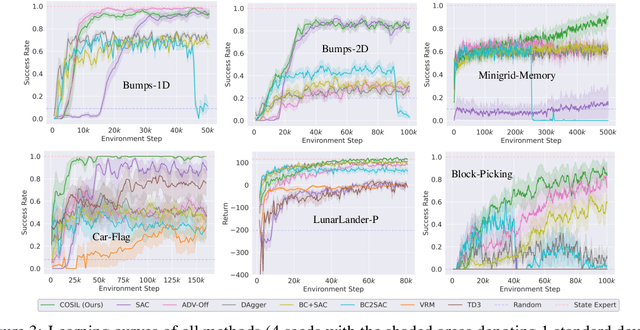
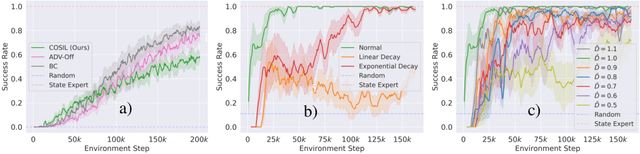
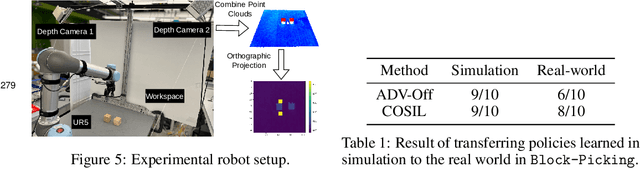
Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.
ProVe: A Pipeline for Automated Provenance Verification of Knowledge Graphs against Textual Sources
Oct 26, 2022
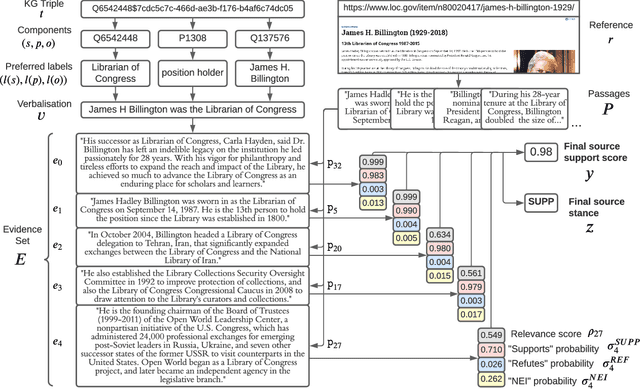
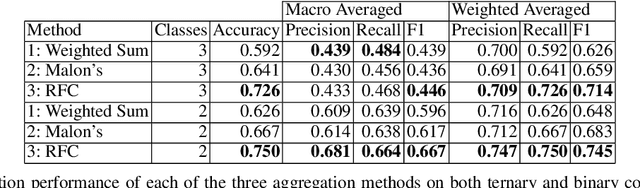
Knowledge Graphs are repositories of information that gather data from a multitude of domains and sources in the form of semantic triples, serving as a source of structured data for various crucial applications in the modern web landscape, from Wikipedia infoboxes to search engines. Such graphs mainly serve as secondary sources of information and depend on well-documented and verifiable provenance to ensure their trustworthiness and usability. However, their ability to systematically assess and assure the quality of this provenance, most crucially whether it properly supports the graph's information, relies mainly on manual processes that do not scale with size. ProVe aims at remedying this, consisting of a pipelined approach that automatically verifies whether a Knowledge Graph triple is supported by text extracted from its documented provenance. ProVe is intended to assist information curators and consists of four main steps involving rule-based methods and machine learning models: text extraction, triple verbalisation, sentence selection, and claim verification. ProVe is evaluated on a Wikidata dataset, achieving promising results overall and excellent performance on the binary classification task of detecting support from provenance, with 87.5% accuracy and 82.9% F1-macro on text-rich sources. The evaluation data and scripts used in this paper are available on GitHub and Figshare.
Reducing Language confusion for Code-switching Speech Recognition with Token-level Language Diarization
Oct 26, 2022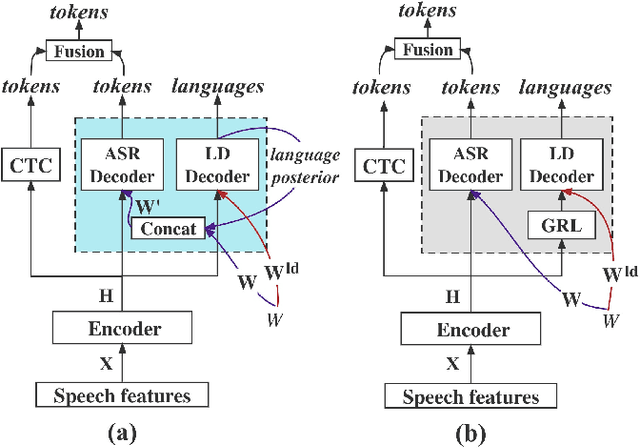
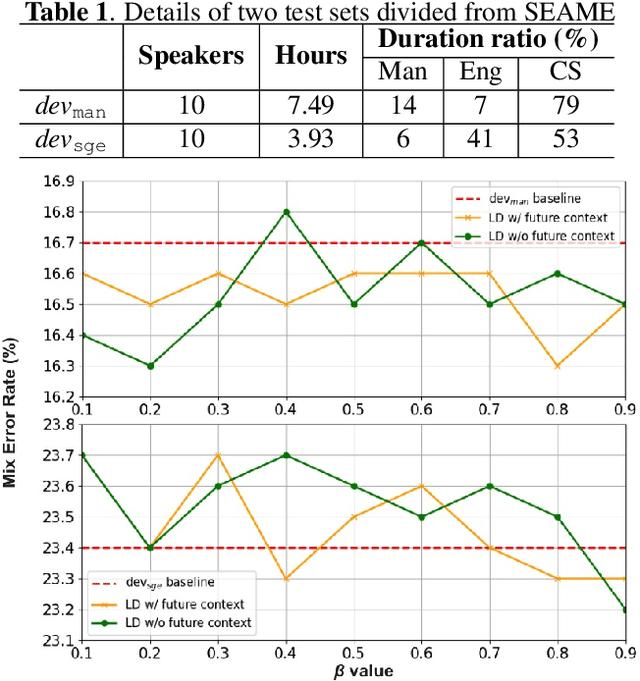
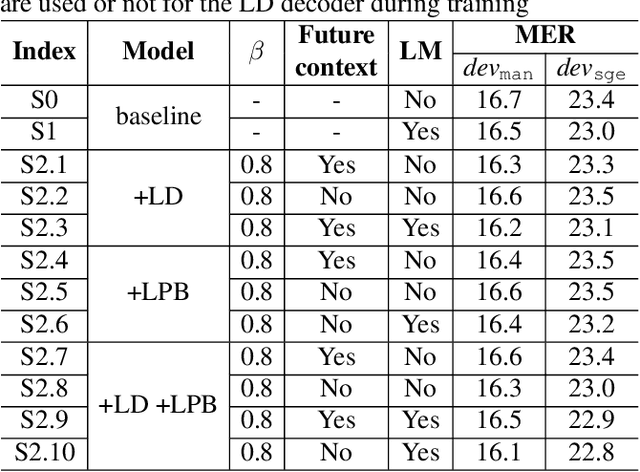
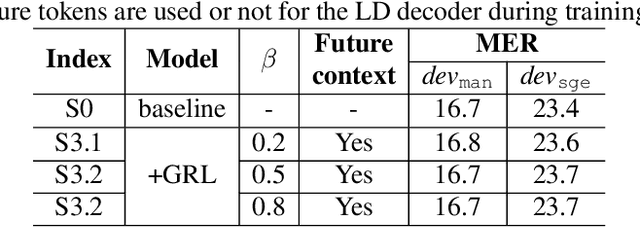
Code-switching (CS) refers to the phenomenon that languages switch within a speech signal and leads to language confusion for automatic speech recognition (ASR). This paper aims to address language confusion for improving CS-ASR from two perspectives: incorporating and disentangling language information. We incorporate language information in the CS-ASR model by dynamically biasing the model with token-level language posteriors which are outputs of a sequence-to-sequence auxiliary language diarization module. In contrast, the disentangling process reduces the difference between languages via adversarial training so as to normalize two languages. We conduct the experiments on the SEAME dataset. Compared to the baseline model, both the joint optimization with LD and the language posterior bias achieve performance improvement. The comparison of the proposed methods indicates that incorporating language information is more effective than disentangling for reducing language confusion in CS speech.
Testing for context-dependent changes in neural encoding in naturalistic experiments
Nov 17, 2022
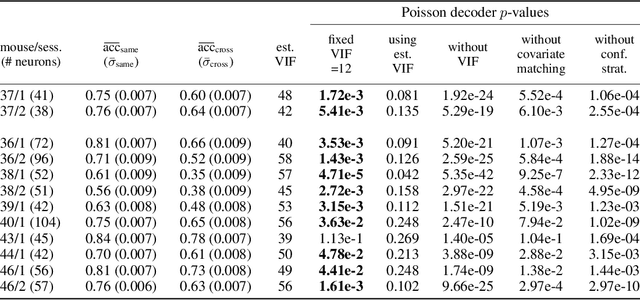
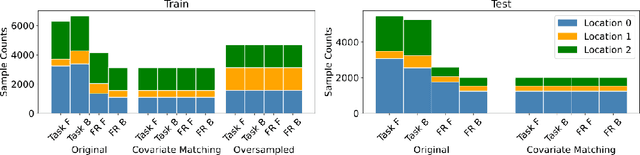
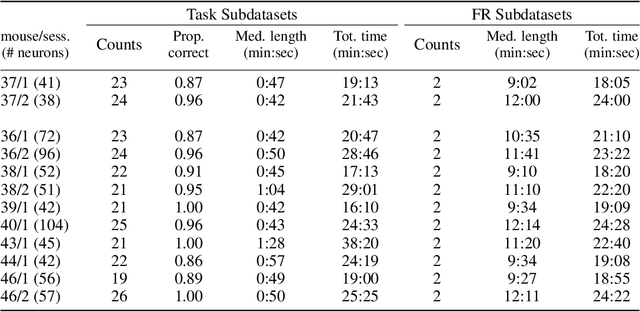
We propose a decoding-based approach to detect context effects on neural codes in longitudinal neural recording data. The approach is agnostic to how information is encoded in neural activity, and can control for a variety of possible confounding factors present in the data. We demonstrate our approach by determining whether it is possible to decode location encoding from prefrontal cortex in the mouse and, further, testing whether the encoding changes due to task engagement.
FedALA: Adaptive Local Aggregation for Personalized Federated Learning
Dec 02, 2022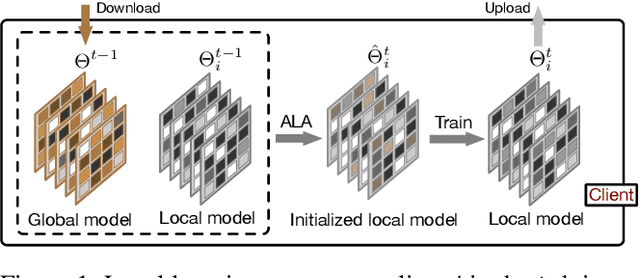

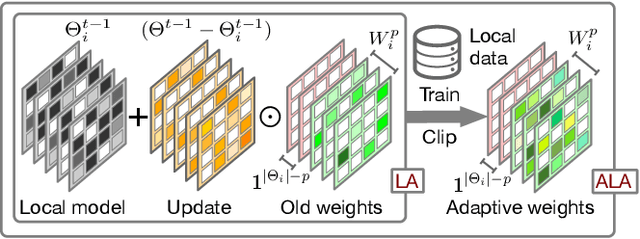
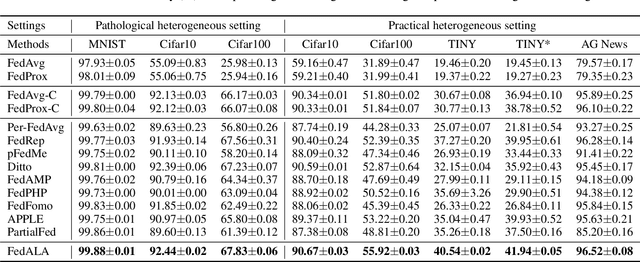
A key challenge in federated learning (FL) is the statistical heterogeneity that impairs the generalization of the global model on each client. To address this, we propose a method Federated learning with Adaptive Local Aggregation (FedALA) by capturing the desired information in the global model for client models in personalized FL. The key component of FedALA is an Adaptive Local Aggregation (ALA) module, which can adaptively aggregate the downloaded global model and local model towards the local objective on each client to initialize the local model before training in each iteration. To evaluate the effectiveness of FedALA, we conduct extensive experiments with five benchmark datasets in computer vision and natural language processing domains. FedALA outperforms eleven state-of-the-art baselines by up to 3.27% in test accuracy. Furthermore, we also apply ALA module to other federated learning methods and achieve up to 24.19% improvement in test accuracy.
GoSum: Extractive Summarization of Long Documents by Reinforcement Learning and Graph Organized discourse state
Nov 18, 2022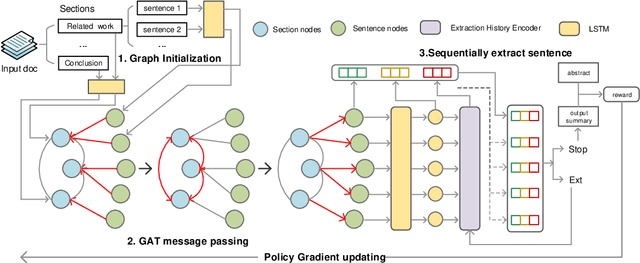

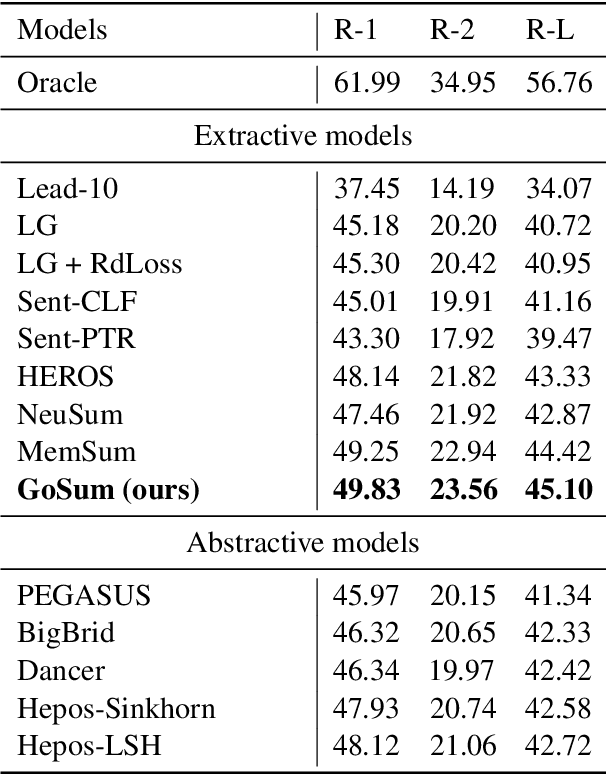
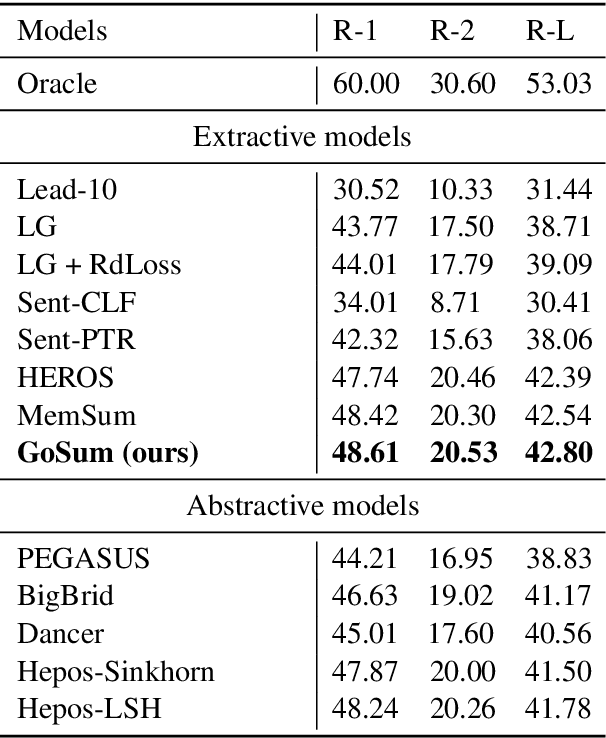
Handling long texts with structural information and excluding redundancy between summary sentences are essential in extractive document summarization. In this work, we propose GoSum, a novel reinforcement-learning-based extractive model for long-paper summarization. GoSum encodes states by building a heterogeneous graph from different discourse levels for each input document. We evaluate the model on two datasets of scientific articles summarization: PubMed and arXiv where it outperforms all extractive summarization models and most of the strong abstractive baselines.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021



Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.
Random Copolymer inverse design system orienting on Accurate discovering of Antimicrobial peptide-mimetic copolymers
Dec 08, 2022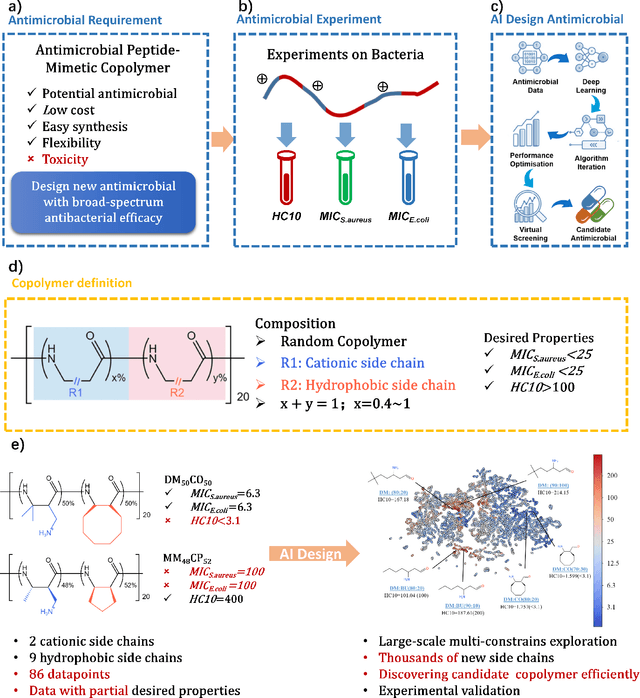
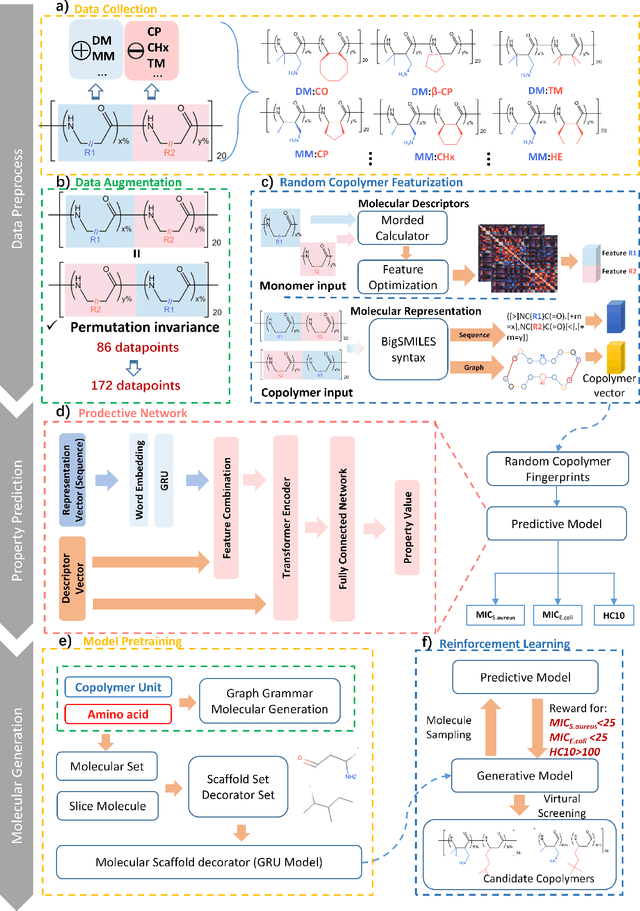
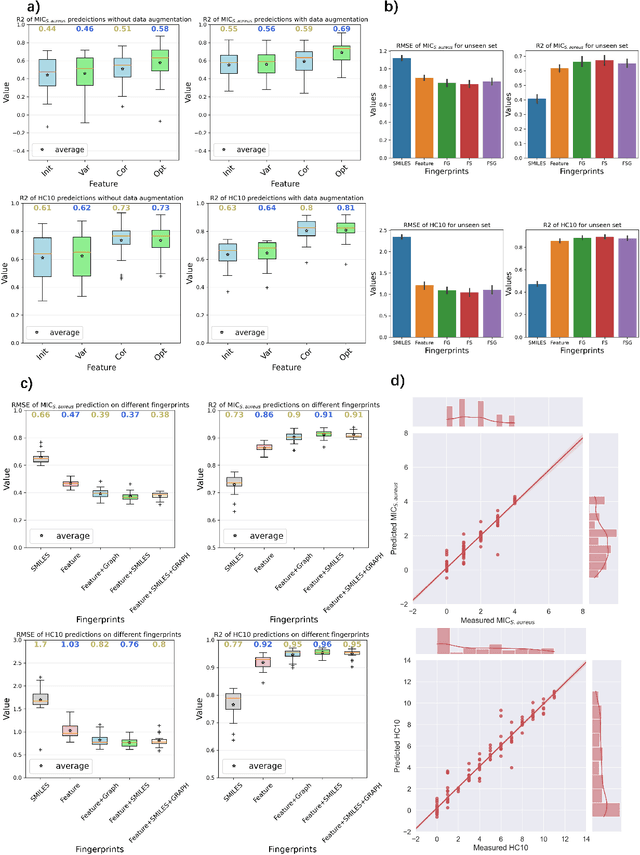
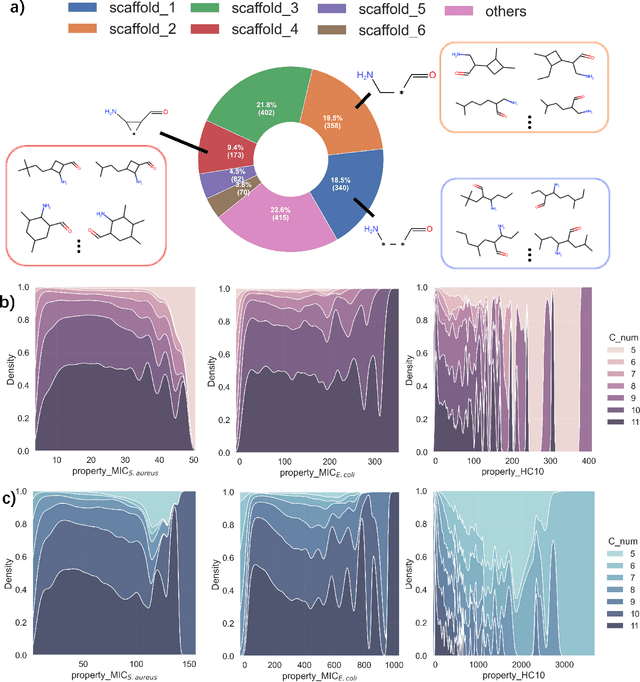
Antimicrobial resistance is one of the biggest health problem, especially in the current period of COVID-19 pandemic. Due to the unique membrane-destruction bactericidal mechanism, antimicrobial peptide-mimetic copolymers are paid more attention and it is urgent to find more potential candidates with broad-spectrum antibacterial efficacy and low toxicity. Artificial intelligence has shown significant performance on small molecule or biotech drugs, however, the higher-dimension of polymer space and the limited experimental data restrict the application of existing methods on copolymer design. Herein, we develop a universal random copolymer inverse design system via multi-model copolymer representation learning, knowledge distillation and reinforcement learning. Our system realize a high-precision antimicrobial activity prediction with few-shot data by extracting various chemical information from multi-modal copolymer representations. By pre-training a scaffold-decorator generative model via knowledge distillation, copolymer space are greatly contracted to the near space of existing data for exploration. Thus, our reinforcement learning algorithm can be adaptive for customized generation on specific scaffolds and requirements on property or structures. We apply our system on collected antimicrobial peptide-mimetic copolymers data, and we discover candidate copolymers with desired properties.