 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proceedings of the 2nd International Workshop on Reading Music Systems
Dec 01, 2022
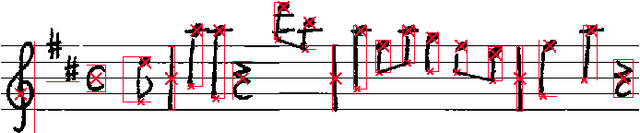


The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 2nd International Workshop on Reading Music Systems, held in Delft on the 2nd of November 2019.
Proceedings of the 3rd International Workshop on Reading Music Systems
Dec 01, 2022The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 3rd International Workshop on Reading Music Systems, held in Alicante on the 23rd of July 2021.
Fair and Green Hyperparameter Optimization via Multi-objective and Multiple Information Source Bayesian Optimization
May 18, 2022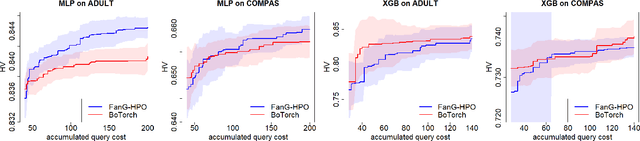

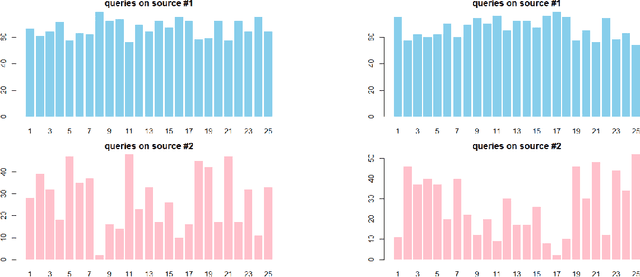

There is a consensus that focusing only on accuracy in searching for optimal machine learning models amplifies biases contained in the data, leading to unfair predictions and decision supports. Recently, multi-objective hyperparameter optimization has been proposed to search for machine learning models which offer equally Pareto-efficient trade-offs between accuracy and fairness. Although these approaches proved to be more versatile than fairness-aware machine learning algorithms -- which optimize accuracy constrained to some threshold on fairness -- they could drastically increase the energy consumption in the case of large datasets. In this paper we propose FanG-HPO, a Fair and Green Hyperparameter Optimization (HPO) approach based on both multi-objective and multiple information source Bayesian optimization. FanG-HPO uses subsets of the large dataset (aka information sources) to obtain cheap approximations of both accuracy and fairness, and multi-objective Bayesian Optimization to efficiently identify Pareto-efficient machine learning models. Experiments consider two benchmark (fairness) datasets and two machine learning algorithms (XGBoost and Multi-Layer Perceptron), and provide an assessment of FanG-HPO against both fairness-aware machine learning algorithms and hyperparameter optimization via a multi-objective single-source optimization algorithm in BoTorch, a state-of-the-art platform for Bayesian Optimization.
Location-Aware Self-Supervised Transformers
Dec 05, 2022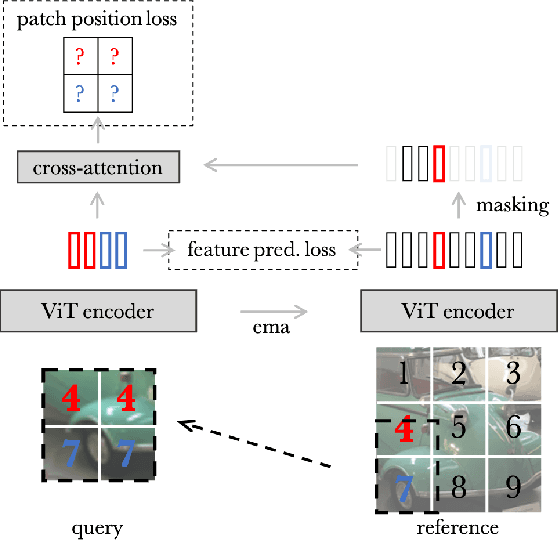
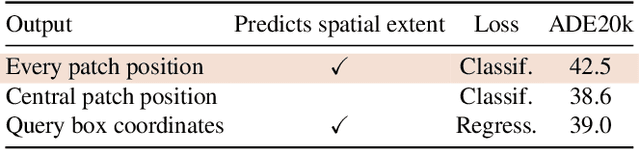
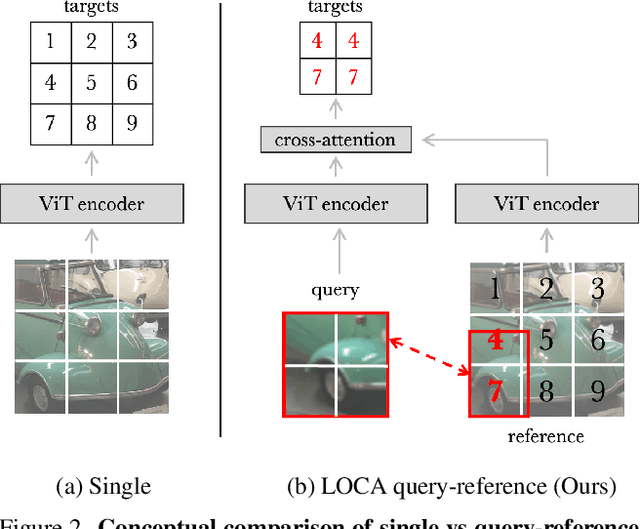
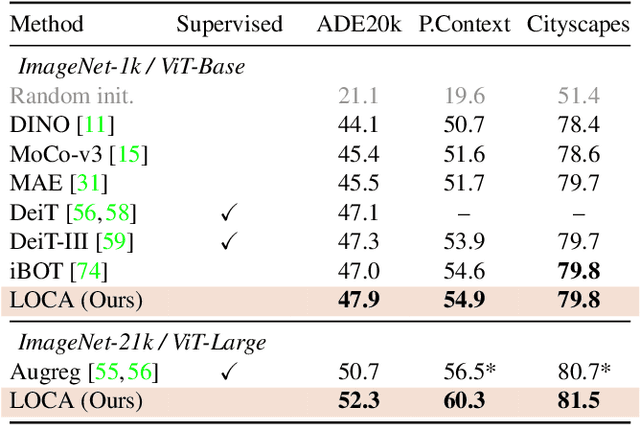
Pixel-level labels are particularly expensive to acquire. Hence, pretraining is a critical step to improve models on a task like semantic segmentation. However, prominent algorithms for pretraining neural networks use image-level objectives, e.g. image classification, image-text alignment a la CLIP, or self-supervised contrastive learning. These objectives do not model spatial information, which might be suboptimal when finetuning on downstream tasks with spatial reasoning. In this work, we propose to pretrain networks for semantic segmentation by predicting the relative location of image parts. We formulate this task as a classification problem where each patch in a query view has to predict its position relatively to another reference view. We control the difficulty of the task by masking a subset of the reference patch features visible to those of the query. Our experiments show that this location-aware (LOCA) self-supervised pretraining leads to representations that transfer competitively to several challenging semantic segmentation benchmarks.
TIDE: Time Derivative Diffusion for Deep Learning on Graphs
Dec 05, 2022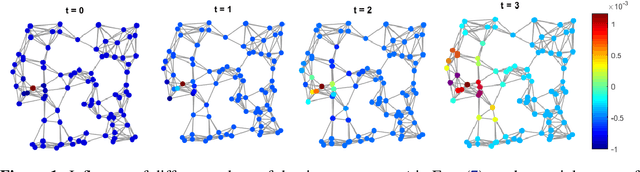
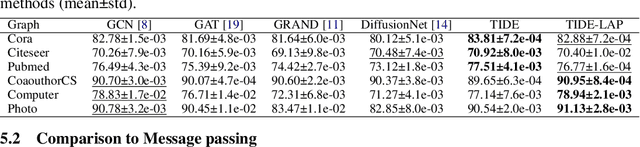
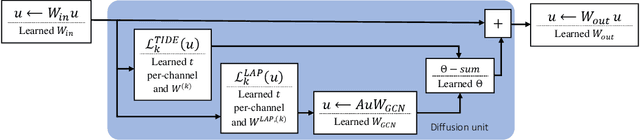
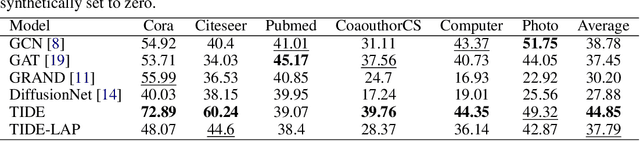
A prominent paradigm for graph neural networks is based on the message passing framework. In this framework, information communication is realized only between neighboring nodes. The challenge of approaches that use this paradigm is to ensure efficient and accurate \textit{long distance communication} between nodes, as deep convolutional networks are prone to over-smoothing. In this paper, we present a novel method based on time derivative graph diffusion (TIDE), with a learnable time parameter. Our approach allows to adapt the spatial extent of diffusion across different tasks and network channels, thus enabling medium and long-distance communication efficiently. Furthermore, we show that our architecture directly enables local message passing and thus inherits from the expressive power of local message passing approaches. We show that on widely used graph benchmarks we achieve comparable performance and on a synthetic mesh dataset we outperform state-of-the-art methods like GCN or GRAND by a significant margin.
Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Nov 14, 2022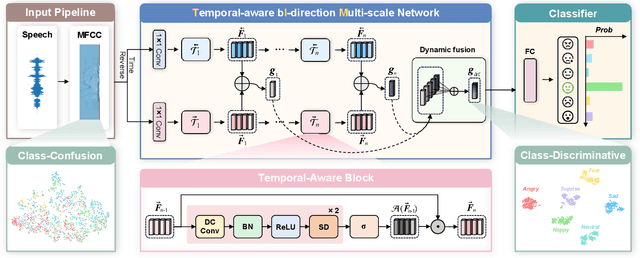
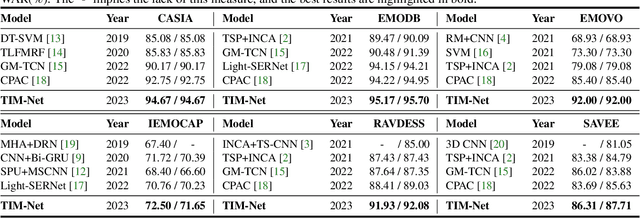


Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.
Camera Aided Reconfigurable Intelligent Surfaces: Computer Vision Based Fast Beam Selection
Nov 14, 2022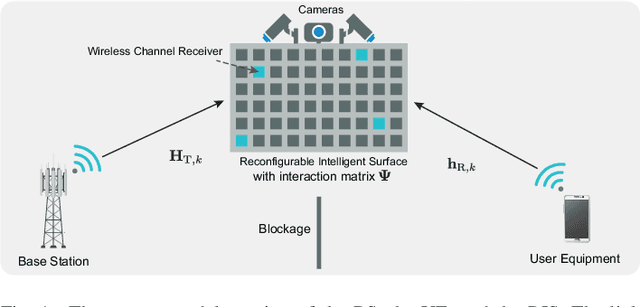
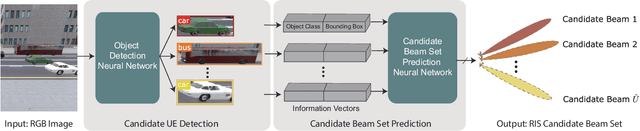
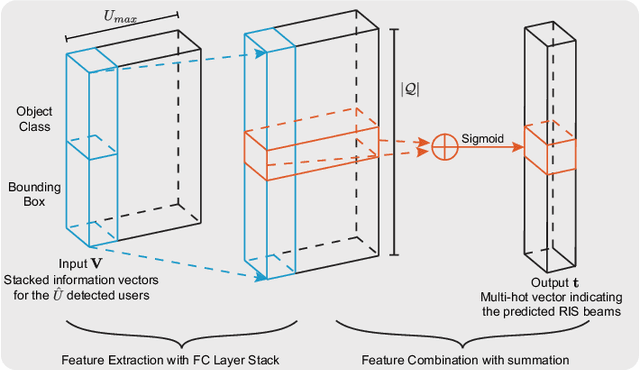
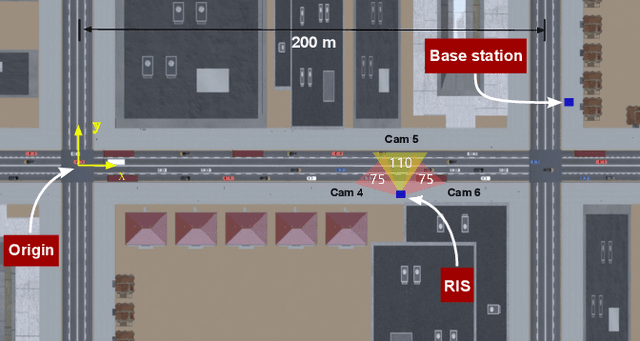
Reconfigurable intelligent surfaces (RISs) have attracted increasing interest due to their ability to improve the coverage, reliability, and energy efficiency of millimeter wave (mmWave) communication systems. However, designing the RIS beamforming typically requires large channel estimation or beam training overhead, which degrades the efficiency of these systems. In this paper, we propose to equip the RIS surfaces with visual sensors (cameras) that obtain sensing information about the surroundings and user/basestation locations, guide the RIS beam selection, and reduce the beam training overhead. We develop a machine learning (ML) framework that leverages this visual sensing information to efficiently select the optimal RIS reflection beams that reflect the signals between the basestation and mobile users. To evaluate the developed approach, we build a high-fidelity synthetic dataset that comprises co-existing wireless and visual data. Based on this dataset, the results show that the proposed vision-aided machine learning solution can accurately predict the RIS beams and achieve near-optimal achievable rate while significantly reducing the beam training overhead.
Emotion Selectable End-to-End Text-based Speech Editing
Dec 20, 2022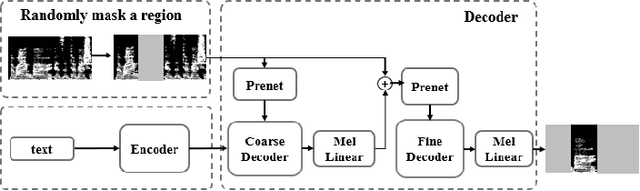
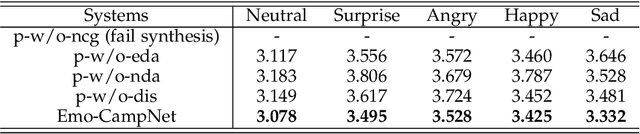
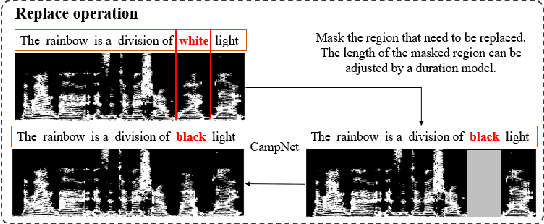
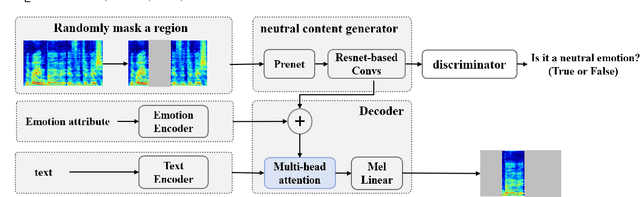
Text-based speech editing allows users to edit speech by intuitively cutting, copying, and pasting text to speed up the process of editing speech. In the previous work, CampNet (context-aware mask prediction network) is proposed to realize text-based speech editing, significantly improving the quality of edited speech. This paper aims at a new task: adding emotional effect to the editing speech during the text-based speech editing to make the generated speech more expressive. To achieve this task, we propose Emo-CampNet (emotion CampNet), which can provide the option of emotional attributes for the generated speech in text-based speech editing and has the one-shot ability to edit unseen speakers' speech. Firstly, we propose an end-to-end emotion-selectable text-based speech editing model. The key idea of the model is to control the emotion of generated speech by introducing additional emotion attributes based on the context-aware mask prediction network. Secondly, to prevent the emotion of the generated speech from being interfered by the emotional components in the original speech, a neutral content generator is proposed to remove the emotion from the original speech, which is optimized by the generative adversarial framework. Thirdly, two data augmentation methods are proposed to enrich the emotional and pronunciation information in the training set, which can enable the model to edit the unseen speaker's speech. The experimental results that 1) Emo-CampNet can effectively control the emotion of the generated speech in the process of text-based speech editing; And can edit unseen speakers' speech. 2) Detailed ablation experiments further prove the effectiveness of emotional selectivity and data augmentation methods. The demo page is available at https://hairuo55.github.io/Emo-CampNet/
Privacy-Protecting Behaviours of Risk Detection in People with Dementia using Videos
Dec 20, 2022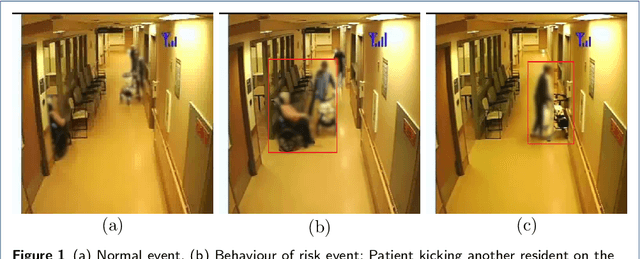
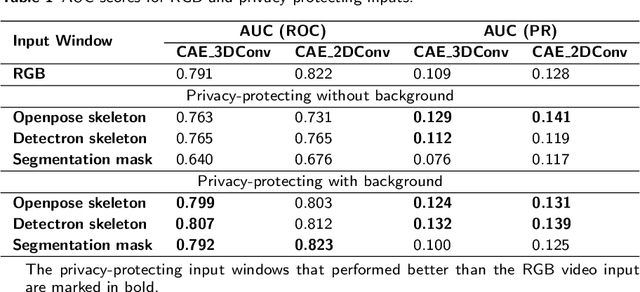


People living with dementia often exhibit behavioural and psychological symptoms of dementia that can put their and others' safety at risk. Existing video surveillance systems in long-term care facilities can be used to monitor such behaviours of risk to alert the staff to prevent potential injuries or death in some cases. However, these behaviours of risk events are heterogeneous and infrequent in comparison to normal events. Moreover, analyzing raw videos can also raise privacy concerns. In this paper, we present two novel privacy-protecting video-based anomaly detection approaches to detect behaviours of risks in people with dementia. We either extracted body pose information as skeletons and use semantic segmentation masks to replace multiple humans in the scene with their semantic boundaries. Our work differs from most existing approaches for video anomaly detection that focus on appearance-based features, which can put the privacy of a person at risk and is also susceptible to pixel-based noise, including illumination and viewing direction. We used anonymized videos of normal activities to train customized spatio-temporal convolutional autoencoders and identify behaviours of risk as anomalies. We show our results on a real-world study conducted in a dementia care unit with patients with dementia, containing approximately 21 hours of normal activities data for training and 9 hours of data containing normal and behaviours of risk events for testing. We compared our approaches with the original RGB videos and obtained an equivalent area under the receiver operating characteristic curve performance of 0.807 for the skeleton-based approach and 0.823 for the segmentation mask-based approach. This is one of the first studies to incorporate privacy for the detection of behaviours of risks in people with dementia.
Addressing the Selection Bias in Voice Assistance: Training Voice Assistance Model in Python with Equal Data Selection
Dec 20, 2022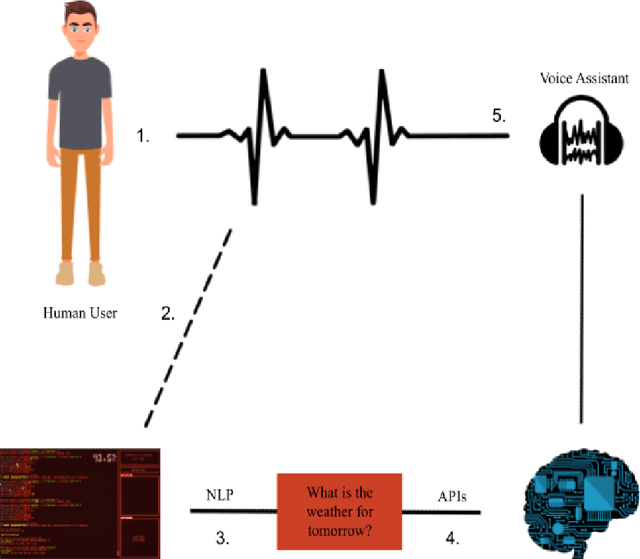
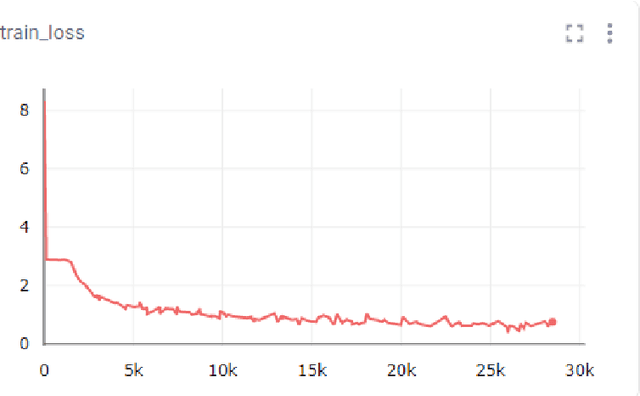
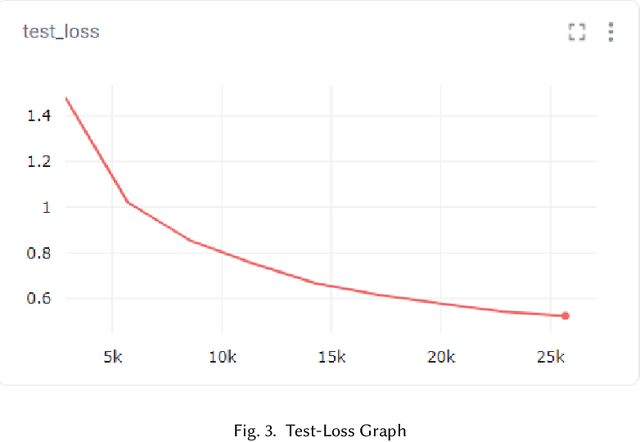
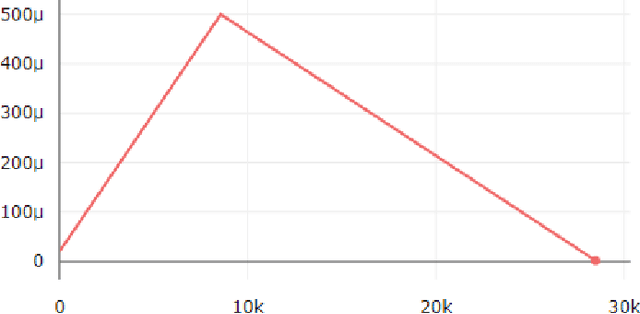
In recent times, voice assistants have become a part of our day-to-day lives, allowing information retrieval by voice synthesis, voice recognition, and natural language processing. These voice assistants can be found in many modern-day devices such as Apple, Amazon, Google, and Samsung. This project is primarily focused on Virtual Assistance in Natural Language Processing. Natural Language Processing is a form of AI that helps machines understand people and create feedback loops. This project will use deep learning to create a Voice Recognizer and use Commonvoice and data collected from the local community for model training using Google Colaboratory. After recognizing a command, the AI assistant will be able to perform the most suitable actions and then give a response. The motivation for this project comes from the race and gender bias that exists in many virtual assistants. The computer industry is primarily dominated by the male gender, and because of this, many of the products produced do not regard women. This bias has an impact on natural language processing. This project will be utilizing various open-source projects to implement machine learning algorithms and train the assistant algorithm to recognize different types of voices, accents, and dialects. Through this project, the goal to use voice data from underrepresented groups to build a voice assistant that can recognize voices regardless of gender, race, or accent. Increasing the representation of women in the computer industry is important for the future of the industry. By representing women in the initial study of voice assistants, it can be shown that females play a vital role in the development of this technology. In line with related work, this project will use first-hand data from the college population and middle-aged adults to train voice assistant to combat gender bias.