 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MNER-QG: An End-to-End MRC framework for Multimodal Named Entity Recognition with Query Grounding
Nov 27, 2022


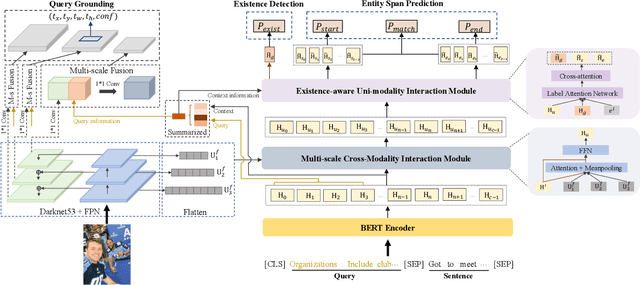
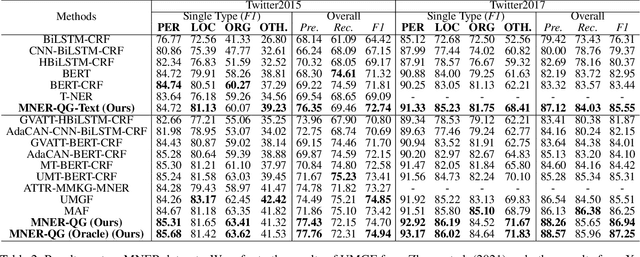
Multimodal named entity recognition (MNER) is a critical step in information extraction, which aims to detect entity spans and classify them to corresponding entity types given a sentence-image pair. Existing methods either (1) obtain named entities with coarse-grained visual clues from attention mechanisms, or (2) first detect fine-grained visual regions with toolkits and then recognize named entities. However, they suffer from improper alignment between entity types and visual regions or error propagation in the two-stage manner, which finally imports irrelevant visual information into texts. In this paper, we propose a novel end-to-end framework named MNER-QG that can simultaneously perform MRC-based multimodal named entity recognition and query grounding. Specifically, with the assistance of queries, MNER-QG can provide prior knowledge of entity types and visual regions, and further enhance representations of both texts and images. To conduct the query grounding task, we provide manual annotations and weak supervisions that are obtained via training a highly flexible visual grounding model with transfer learning. We conduct extensive experiments on two public MNER datasets, Twitter2015 and Twitter2017. Experimental results show that MNER-QG outperforms the current state-of-the-art models on the MNER task, and also improves the query grounding performance.
Robust Path Selection in Software-defined WANs using Deep Reinforcement Learning
Dec 22, 2022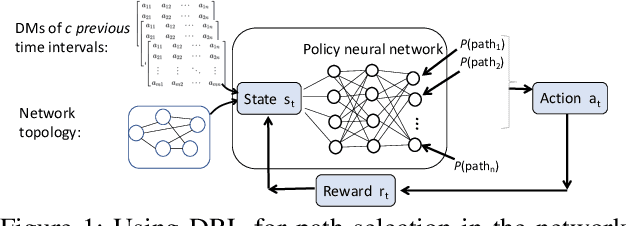
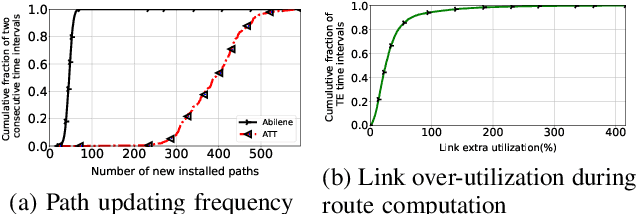
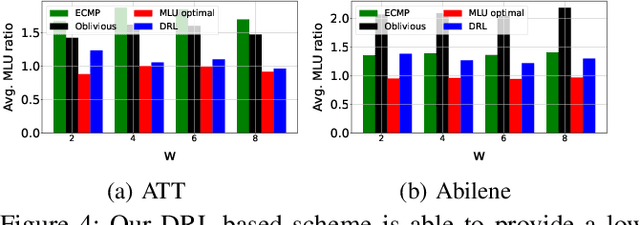
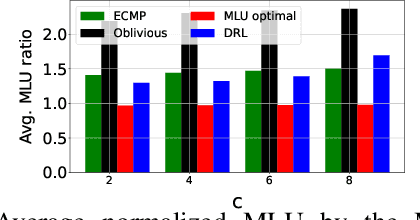
In the context of an efficient network traffic engineering process where the network continuously measures a new traffic matrix and updates the set of paths in the network, an automated process is required to quickly and efficiently identify when and what set of paths should be used. Unfortunately, the burden of finding the optimal solution for the network updating process in each given time interval is high since the computation complexity of optimization approaches using linear programming increases significantly as the size of the network increases. In this paper, we use deep reinforcement learning to derive a data-driven algorithm that does the path selection in the network considering the overhead of route computation and path updates. Our proposed scheme leverages information about past network behavior to identify a set of robust paths to be used for multiple future time intervals to avoid the overhead of updating the forwarding behavior of routers frequently. We compare the results of our approach to other traffic engineering solutions through extensive simulations across real network topologies. Our results demonstrate that our scheme fares well by a factor of 40% with respect to reducing link utilization compared to traditional TE schemes such as ECMP. Our scheme provides a slightly higher link utilization (around 25%) compared to schemes that only minimize link utilization and do not care about path updating overhead.
Dirichlet-Survival Process: Scalable Inference of Topic-Dependent Diffusion Networks
Dec 12, 2022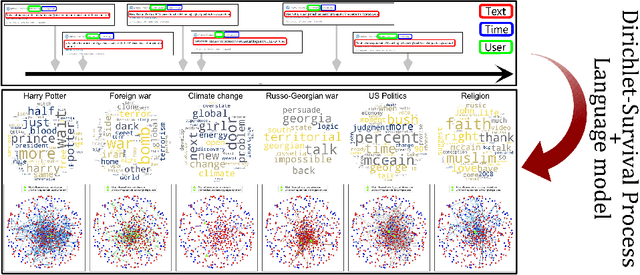
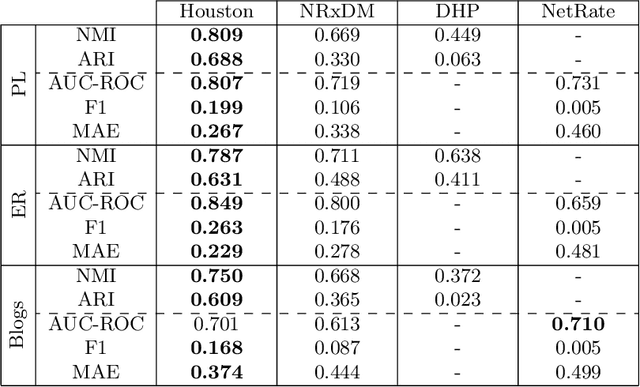
Information spread on networks can be efficiently modeled by considering three features: documents' content, time of publication relative to other publications, and position of the spreader in the network. Most previous works model up to two of those jointly, or rely on heavily parametric approaches. Building on recent Dirichlet-Point processes literature, we introduce the Houston (Hidden Online User-Topic Network) model, that jointly considers all those features in a non-parametric unsupervised framework. It infers dynamic topic-dependent underlying diffusion networks in a continuous-time setting along with said topics. It is unsupervised; it considers an unlabeled stream of triplets shaped as \textit{(time of publication, information's content, spreading entity)} as input data. Online inference is conducted using a sequential Monte-Carlo algorithm that scales linearly with the size of the dataset. Our approach yields consequent improvements over existing baselines on both cluster recovery and subnetworks inference tasks.
Original or Translated? On the Use of Parallel Data for Translation Quality Estimation
Dec 20, 2022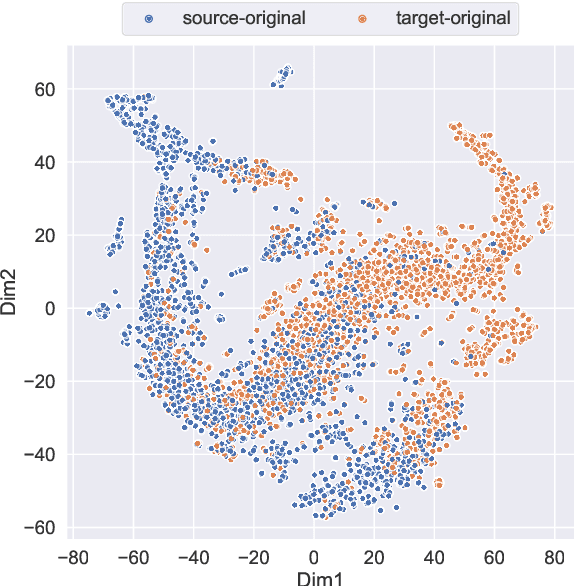
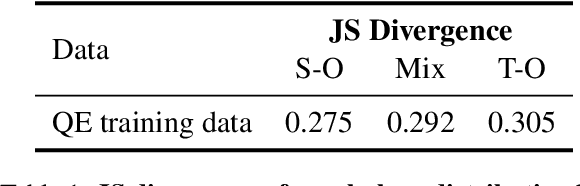
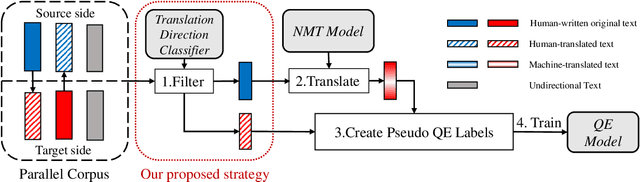
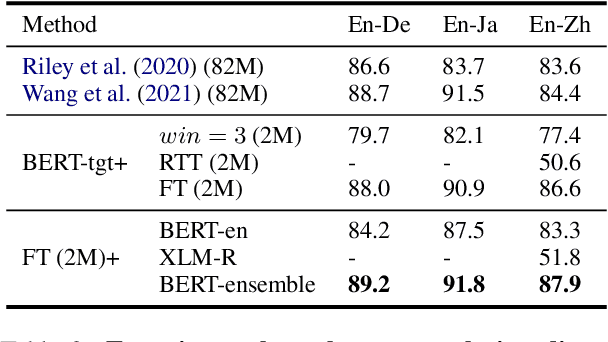
Machine Translation Quality Estimation (QE) is the task of evaluating translation output in the absence of human-written references. Due to the scarcity of human-labeled QE data, previous works attempted to utilize the abundant unlabeled parallel corpora to produce additional training data with pseudo labels. In this paper, we demonstrate a significant gap between parallel data and real QE data: for QE data, it is strictly guaranteed that the source side is original texts and the target side is translated (namely translationese). However, for parallel data, it is indiscriminate and the translationese may occur on either source or target side. We compare the impact of parallel data with different translation directions in QE data augmentation, and find that using the source-original part of parallel corpus consistently outperforms its target-original counterpart. Moreover, since the WMT corpus lacks direction information for each parallel sentence, we train a classifier to distinguish source- and target-original bitext, and carry out an analysis of their difference in both style and domain. Together, these findings suggest using source-original parallel data for QE data augmentation, which brings a relative improvement of up to 4.0% and 6.4% compared to undifferentiated data on sentence- and word-level QE tasks respectively.
Pain level and pain-related behaviour classification using GRU-based sparsely-connected RNNs
Dec 20, 2022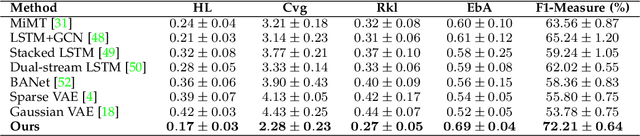
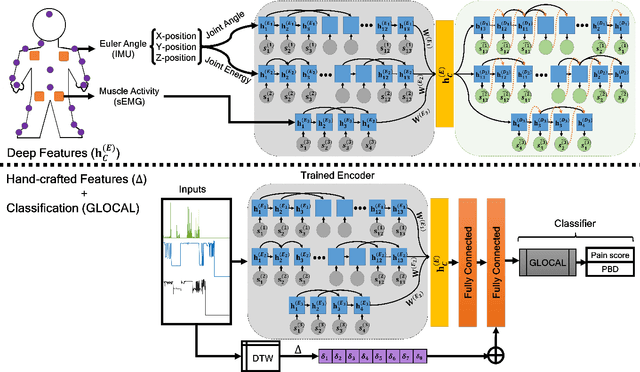
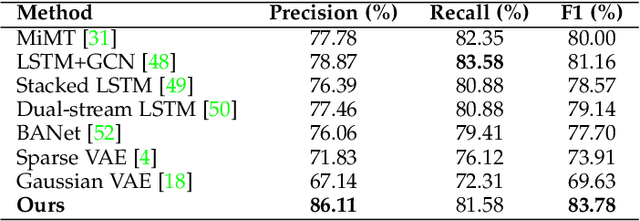
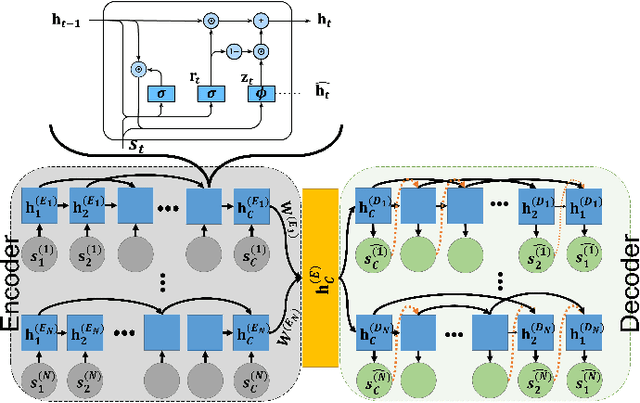
There is a growing body of studies on applying deep learning to biometrics analysis. Certain circumstances, however, could impair the objective measures and accuracy of the proposed biometric data analysis methods. For instance, people with chronic pain (CP) unconsciously adapt specific body movements to protect themselves from injury or additional pain. Because there is no dedicated benchmark database to analyse this correlation, we considered one of the specific circumstances that potentially influence a person's biometrics during daily activities in this study and classified pain level and pain-related behaviour in the EmoPain database. To achieve this, we proposed a sparsely-connected recurrent neural networks (s-RNNs) ensemble with the gated recurrent unit (GRU) that incorporates multiple autoencoders using a shared training framework. This architecture is fed by multidimensional data collected from inertial measurement unit (IMU) and surface electromyography (sEMG) sensors. Furthermore, to compensate for variations in the temporal dimension that may not be perfectly represented in the latent space of s-RNNs, we fused hand-crafted features derived from information-theoretic approaches with represented features in the shared hidden state. We conducted several experiments which indicate that the proposed method outperforms the state-of-the-art approaches in classifying both pain level and pain-related behaviour.
CultureBERT: Fine-Tuning Transformer-Based Language Models for Corporate Culture
Dec 01, 2022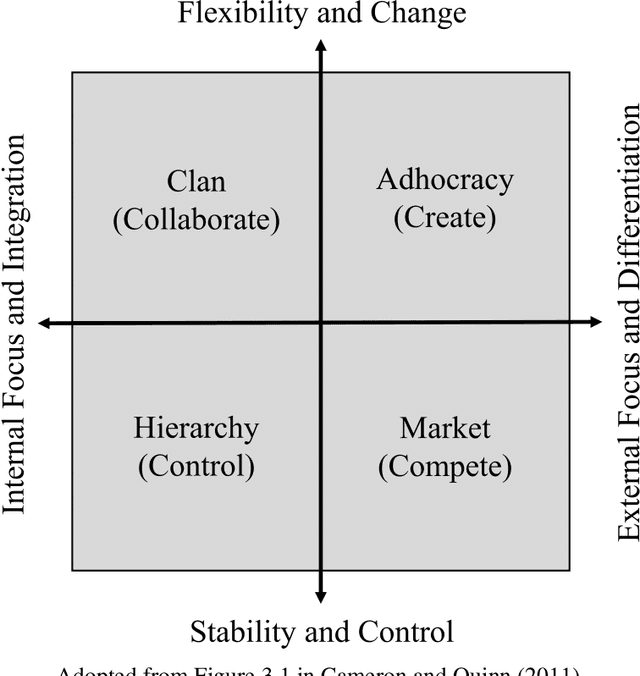
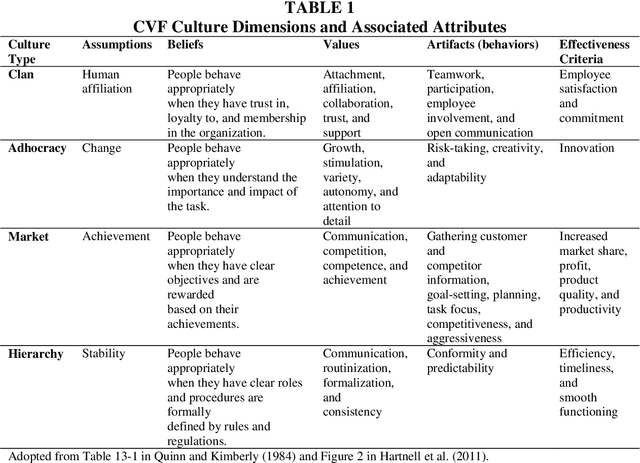
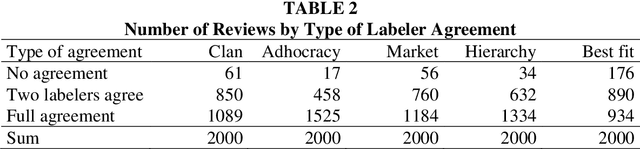

This paper introduces supervised machine learning to the literature measuring corporate culture from text documents. We compile a unique data set of employee reviews that were labeled by human evaluators with respect to the information the reviews reveal about the firms' corporate culture. Using this data set, we fine-tune state-of-the-art transformer-based language models to perform the same classification task. In out-of-sample predictions, our language models classify 16 to 28 percent points more of employee reviews in line with human evaluators than traditional approaches of text classification.
Camelira: An Arabic Multi-Dialect Morphological Disambiguator
Nov 30, 2022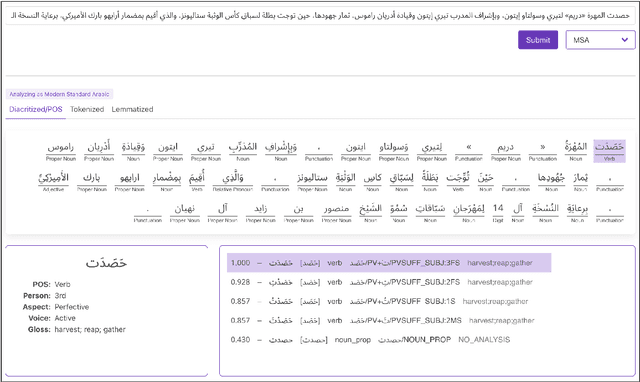
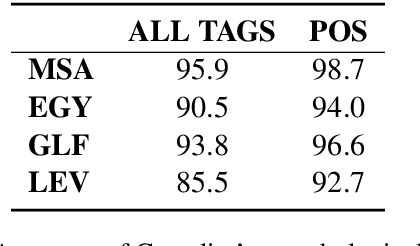
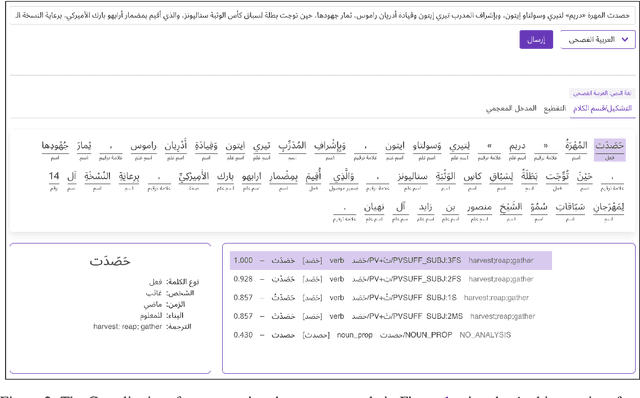

We present Camelira, a web-based Arabic multi-dialect morphological disambiguation tool that covers four major variants of Arabic: Modern Standard Arabic, Egyptian, Gulf, and Levantine. Camelira offers a user-friendly web interface that allows researchers and language learners to explore various linguistic information, such as part-of-speech, morphological features, and lemmas. Our system also provides an option to automatically choose an appropriate dialect-specific disambiguator based on the prediction of a dialect identification component. Camelira is publicly accessible at http://camelira.camel-lab.com.
Research on Domain Information Mining and Theme Evolution of Scientific Papers
Apr 18, 2022In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Cross-disciplinary research results have gradually become an emerging frontier research direction. There is a certain dependence between a large number of research results. It is difficult to effectively analyze today's scientific research results when looking at a single research field in isolation. How to effectively use the huge number of scientific papers to help researchers becomes a challenge. This paper introduces the research status at home and abroad in terms of domain information mining and topic evolution law of scientific and technological papers from three aspects: the semantic feature representation learning of scientific and technological papers, the field information mining of scientific and technological papers, and the mining and prediction of research topic evolution rules of scientific and technological papers.
Analyzing Process-Aware Information System Updates Using Digital Twins of Organizations
Mar 24, 2022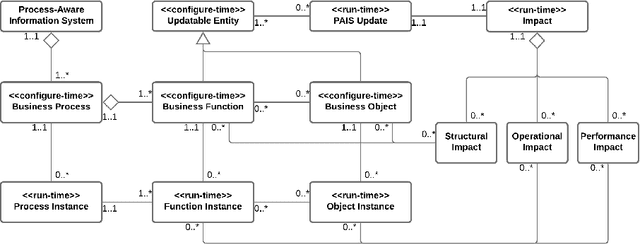
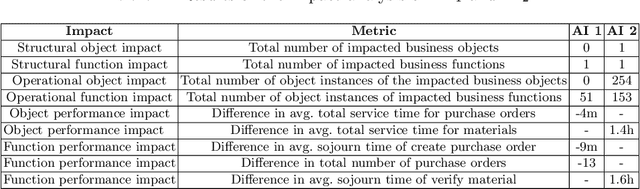

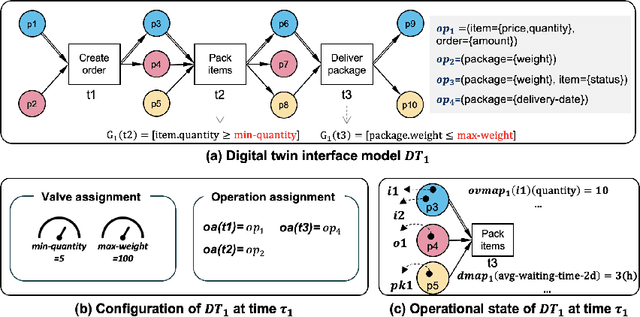
Digital transformation often entails small-scale changes to information systems supporting the execution of business processes. These changes may increase the operational frictions in process execution, which decreases the process performance. The contributions in the literature providing support to the tracking and impact analysis of small-scale changes are limited in scope and functionality. In this paper, we use the recently developed Digital Twins of Organizations (DTOs) to assess the impact of (process-aware) information systems updates. More in detail, we model the updates using the configuration of DTOs and quantitatively assess different types of impacts of information system updates (structural, operational, and performance-related). We implemented a prototype of the proposed approach. Moreover, we discuss a case study involving a standard ERP procure-to-pay business process.
Finding Inverse Document Frequency Information in BERT
Feb 24, 2022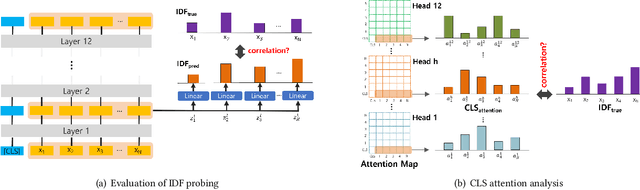

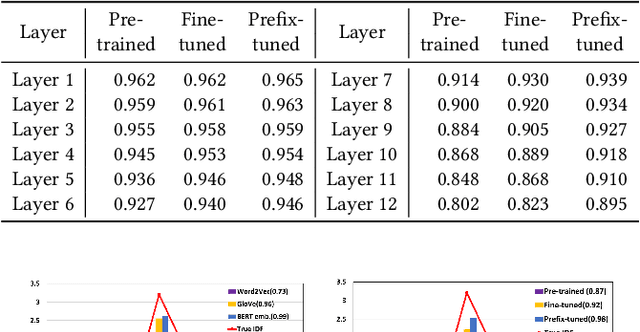
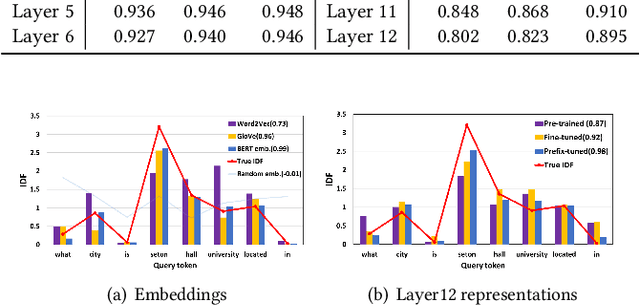
For many decades, BM25 and its variants have been the dominant document retrieval approach, where their two underlying features are Term Frequency (TF) and Inverse Document Frequency (IDF). The traditional approach, however, is being rapidly replaced by Neural Ranking Models (NRMs) that can exploit semantic features. In this work, we consider BERT-based NRMs and study if IDF information is present in the NRMs. This simple question is interesting because IDF has been indispensable for the traditional lexical matching, but global features like IDF are not explicitly learned by neural language models including BERT. We adopt linear probing as the main analysis tool because typical BERT based NRMs utilize linear or inner-product based score aggregators. We analyze input embeddings, representations of all BERT layers, and the self-attention weights of CLS. By studying MS-MARCO dataset with three BERT-based models, we show that all of them contain information that is strongly dependent on IDF.