 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A perspective on the use of health digital twins in computational pathology
Nov 30, 2022
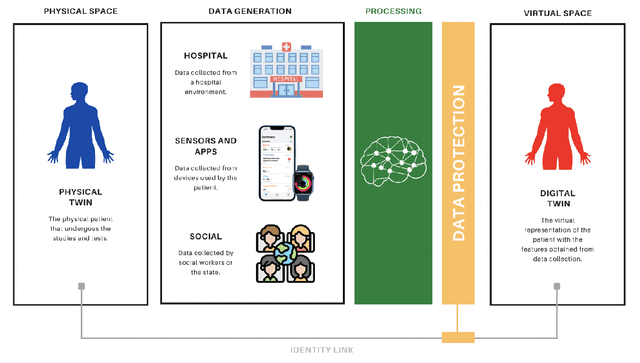
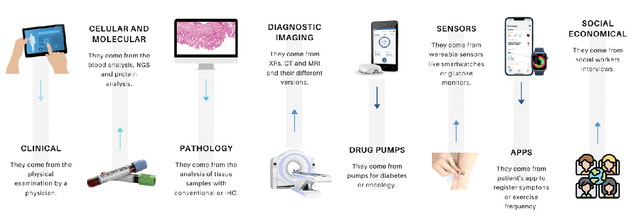
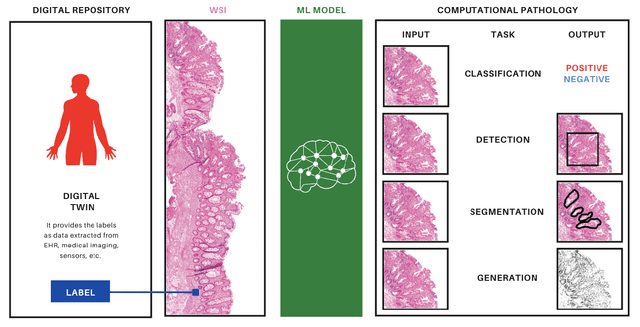
A digital health twin can be defined as a virtual model of a physical person, in this specific case, a patient. This virtual model is constituted by multidimensional data that can host from clinical, molecular and therapeutic parameters to sensor data and living conditions. Given that in computational pathology, it is very important to have the information from image donors to create computational models, the integration of digital twins in this field could be crucial. However, since these virtual entities collect sensitive data from physical people, privacy safeguards must also be considered and implemented. With these data safeguards in place, health digital twins could integrate digital clinical trials and be necessary participants in the generation of real-world evidence, which could positively change both fields.
Corn Yield Prediction based on Remotely Sensed Variables Using Variational Autoencoder and Multiple Instance Regression
Nov 23, 2022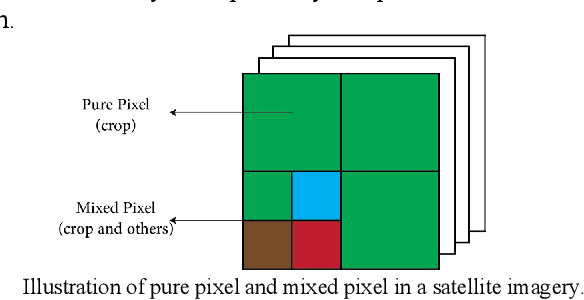
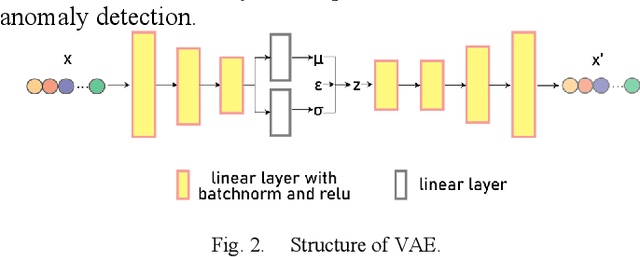
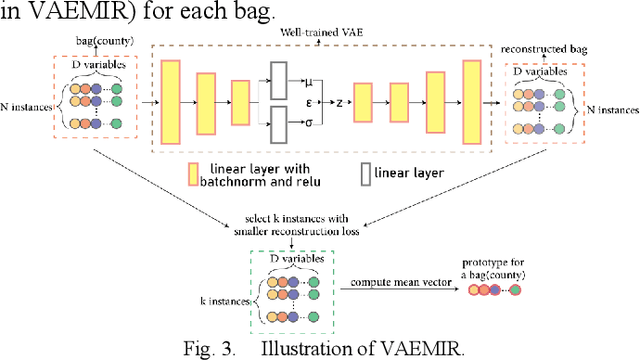
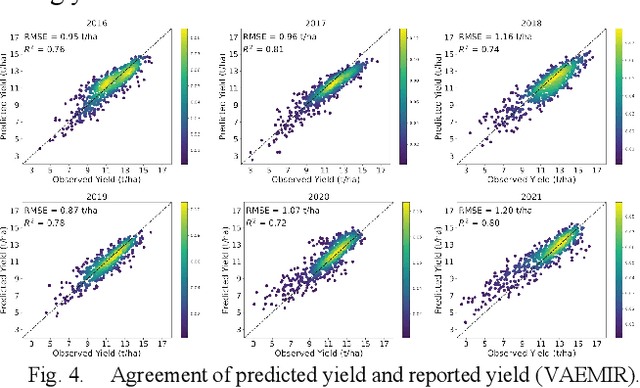
In the U.S., corn is the most produced crop and has been an essential part of the American diet. To meet the demand for supply chain management and regional food security, accurate and timely large-scale corn yield prediction is attracting more attention in precision agriculture. Recently, remote sensing technology and machine learning methods have been widely explored for crop yield prediction. Currently, most county-level yield prediction models use county-level mean variables for prediction, ignoring much detailed information. Moreover, inconsistent spatial resolution between crop area and satellite sensors results in mixed pixels, which may decrease the prediction accuracy. Only a few works have addressed the mixed pixels problem in large-scale crop yield prediction. To address the information loss and mixed pixels problem, we developed a variational autoencoder (VAE) based multiple instance regression (MIR) model for large-scaled corn yield prediction. We use all unlabeled data to train a VAE and the well-trained VAE for anomaly detection. As a preprocess method, anomaly detection can help MIR find a better representation of every bag than traditional MIR methods, thus better performing in large-scale corn yield prediction. Our experiments showed that variational autoencoder based multiple instance regression (VAEMIR) outperformed all baseline methods in large-scale corn yield prediction. Though a suitable meta parameter is required, VAEMIR shows excellent potential in feature learning and extraction for large-scale corn yield prediction.
Crosslinguistic word order variation reflects evolutionary pressures of dependency and information locality
Jun 09, 2022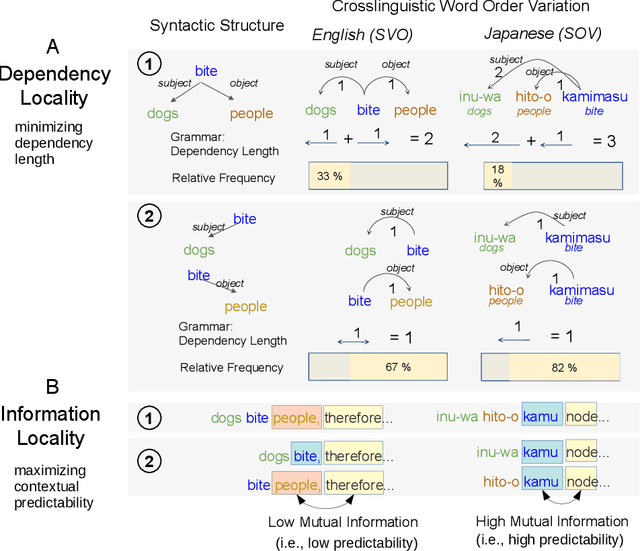
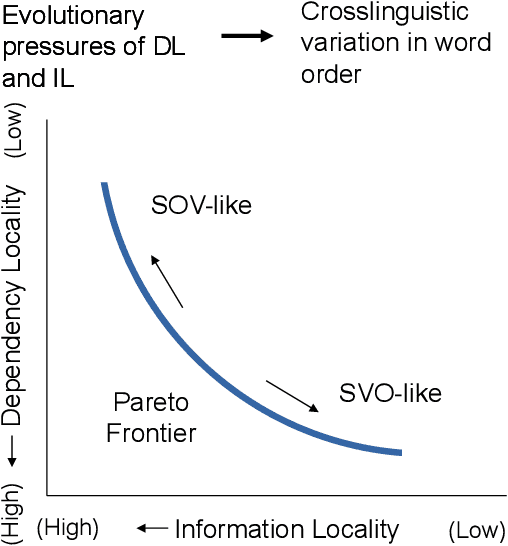
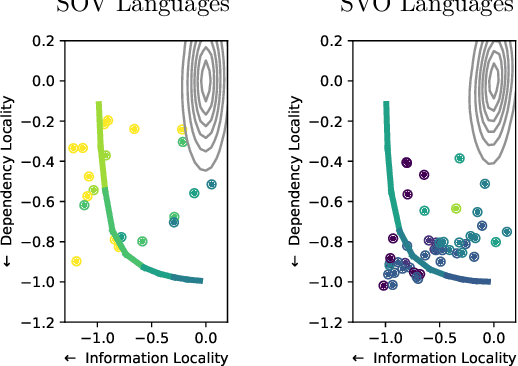
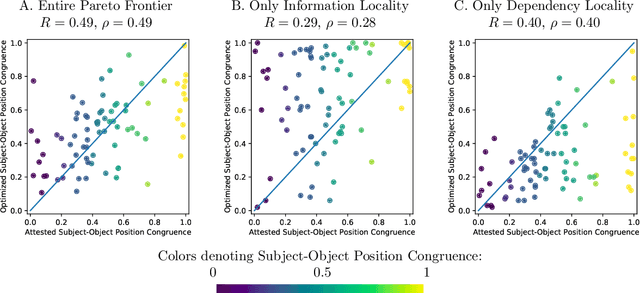
Languages vary considerably in syntactic structure. About 40% of the world's languages have subject-verb-object order, and about 40% have subject-object-verb order. Extensive work has sought to explain this word order variation across languages. However, the existing approaches are not able to explain coherently the frequency distribution and evolution of word order in individual languages. We propose that variation in word order reflects different ways of balancing competing pressures of dependency locality and information locality, whereby languages favor placing elements together when they are syntactically related or contextually informative about each other. Using data from 80 languages in 17 language families and phylogenetic modeling, we demonstrate that languages evolve to balance these pressures, such that word order change is accompanied by change in the frequency distribution of the syntactic structures which speakers communicate to maintain overall efficiency. Variability in word order thus reflects different ways in which languages resolve these evolutionary pressures. We identify relevant characteristics that result from this joint optimization, particularly the frequency with which subjects and objects are expressed together for the same verb. Our findings suggest that syntactic structure and usage across languages co-adapt to support efficient communication under limited cognitive resources.
* Preprint of peer-reviewed paper published in PNAS. Final copyedited version is available at: https://www.pnas.org/doi/10.1073/pnas.2122604119
Neural DAEs: Constrained neural networks
Nov 25, 2022
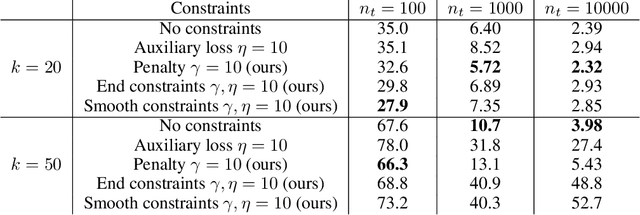
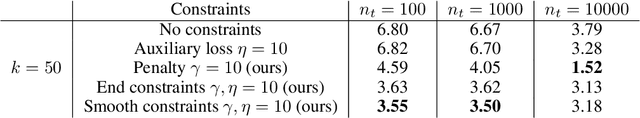
In this article we investigate the effect of explicitly adding auxiliary trajectory information to neural networks for dynamical systems. We draw inspiration from the field of differential-algebraic equations and differential equations on manifolds and implement similar methods in residual neural networks. We discuss constraints through stabilization as well as projection methods, and show when to use which method based on experiments involving simulations of multi-body pendulums and molecular dynamics scenarios. Several of our methods are easy to implement in existing code and have limited impact on training performance while giving significant boosts in terms of inference.
The Economics of Recommender Systems: Evidence from a Field Experiment on MovieLens
Nov 25, 2022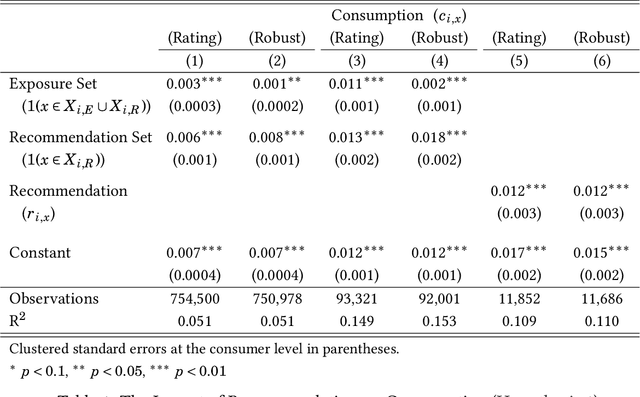
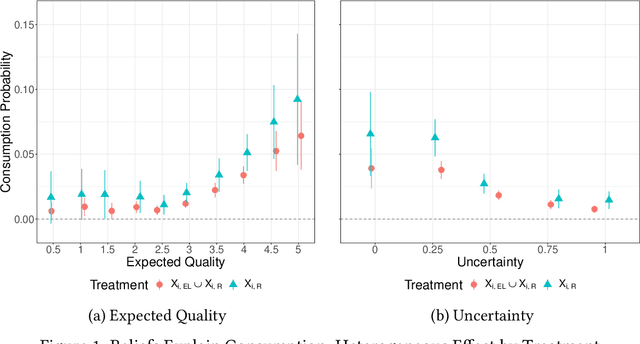
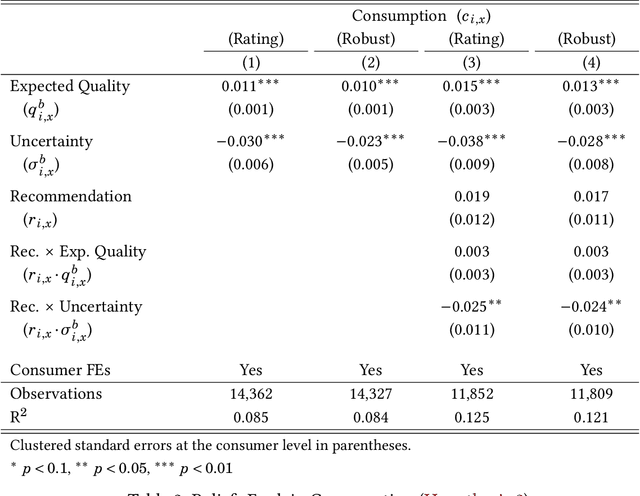
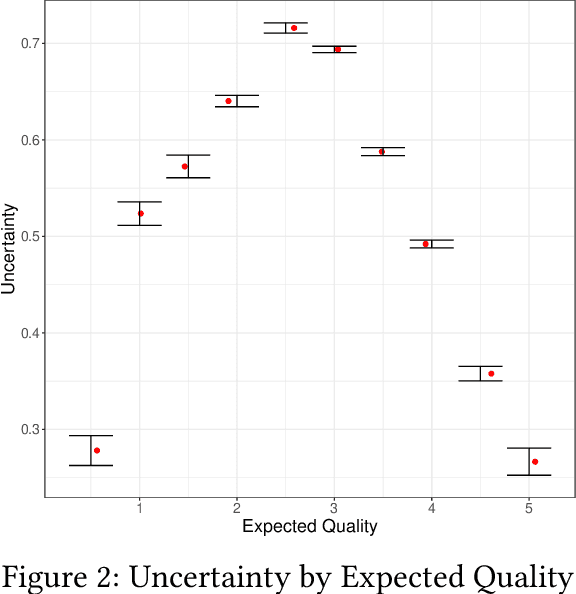
We conduct a field experiment on a movie-recommendation platform to identify if and how recommendations affect consumption. We use within-consumer randomization at the good level and elicit beliefs about unconsumed goods to disentangle exposure from informational effects. We find recommendations increase consumption beyond its role in exposing goods to consumers. We provide support for an informational mechanism: recommendations affect consumers' beliefs, which in turn explain consumption. Recommendations reduce uncertainty about goods consumers are most uncertain about and induce information acquisition. Our results highlight the importance of recommender systems' informational role when considering policies targeting these systems in online marketplaces.
Miko Team: Deep Learning Approach for Legal Question Answering in ALQAC 2022
Nov 04, 2022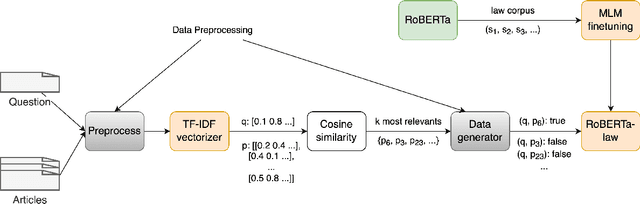
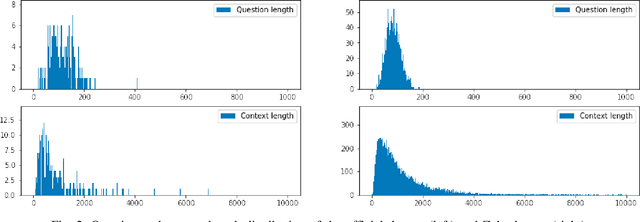

We introduce efficient deep learning-based methods for legal document processing including Legal Document Retrieval and Legal Question Answering tasks in the Automated Legal Question Answering Competition (ALQAC 2022). In this competition, we achieve 1\textsuperscript{st} place in the first task and 3\textsuperscript{rd} place in the second task. Our method is based on the XLM-RoBERTa model that is pre-trained from a large amount of unlabeled corpus before fine-tuning to the specific tasks. The experimental results showed that our method works well in legal retrieval information tasks with limited labeled data. Besides, this method can be applied to other information retrieval tasks in low-resource languages.
Contrastive Masked Autoencoders for Self-Supervised Video Hashing
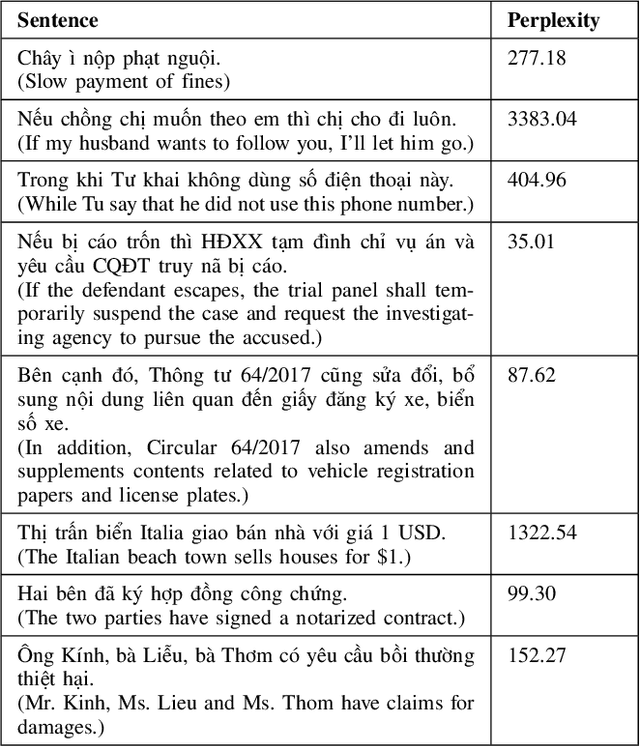
Nov 21, 2022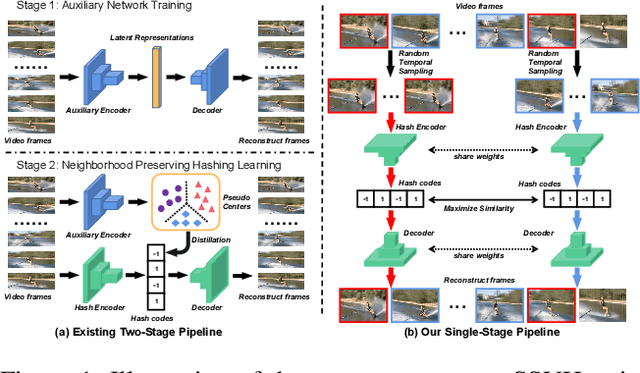

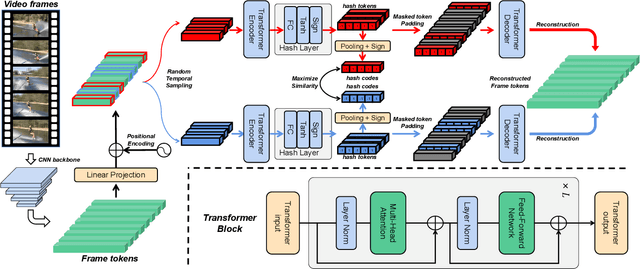
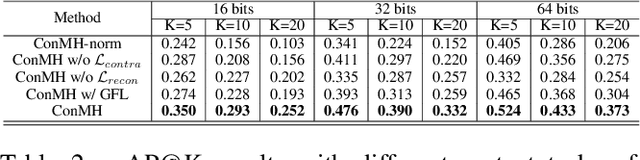
Self-Supervised Video Hashing (SSVH) models learn to generate short binary representations for videos without ground-truth supervision, facilitating large-scale video retrieval efficiency and attracting increasing research attention. The success of SSVH lies in the understanding of video content and the ability to capture the semantic relation among unlabeled videos. Typically, state-of-the-art SSVH methods consider these two points in a two-stage training pipeline, where they firstly train an auxiliary network by instance-wise mask-and-predict tasks and secondly train a hashing model to preserve the pseudo-neighborhood structure transferred from the auxiliary network. This consecutive training strategy is inflexible and also unnecessary. In this paper, we propose a simple yet effective one-stage SSVH method called ConMH, which incorporates video semantic information and video similarity relationship understanding in a single stage. To capture video semantic information for better hashing learning, we adopt an encoder-decoder structure to reconstruct the video from its temporal-masked frames. Particularly, we find that a higher masking ratio helps video understanding. Besides, we fully exploit the similarity relationship between videos by maximizing agreement between two augmented views of a video, which contributes to more discriminative and robust hash codes. Extensive experiments on three large-scale video datasets (\ie, FCVID, ActivityNet and YFCC) indicate that ConMH achieves state-of-the-art results. Code is available at https://github.com/huangmozhi9527/ConMH.
Hyperspectral Demosaicing of Snapshot Camera Images Using Deep Learning
Nov 21, 2022Spectral imaging technologies have rapidly evolved during the past decades. The recent development of single-camera-one-shot techniques for hyperspectral imaging allows multiple spectral bands to be captured simultaneously (3x3, 4x4 or 5x5 mosaic), opening up a wide range of applications. Examples include intraoperative imaging, agricultural field inspection and food quality assessment. To capture images across a wide spectrum range, i.e. to achieve high spectral resolution, the sensor design sacrifices spatial resolution. With increasing mosaic size, this effect becomes increasingly detrimental. Furthermore, demosaicing is challenging. Without incorporating edge, shape, and object information during interpolation, chromatic artifacts are likely to appear in the obtained images. Recent approaches use neural networks for demosaicing, enabling direct information extraction from image data. However, obtaining training data for these approaches poses a challenge as well. This work proposes a parallel neural network based demosaicing procedure trained on a new ground truth dataset captured in a controlled environment by a hyperspectral snapshot camera with a 4x4 mosaic pattern. The dataset is a combination of real captured scenes with images from publicly available data adapted to the 4x4 mosaic pattern. To obtain real world ground-truth data, we performed multiple camera captures with 1-pixel shifts in order to compose the entire data cube. Experiments show that the proposed network outperforms state-of-art networks.
* German Conference on Pattern Recognition (GCPR) 2022
Reference-based Image and Video Super-Resolution via C2-Matching
Dec 19, 2022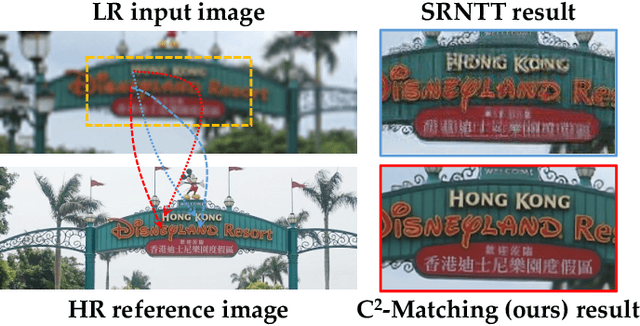
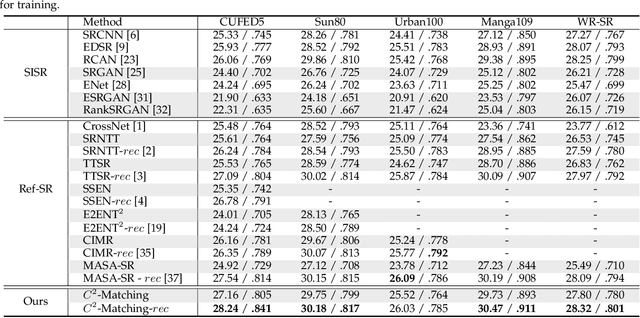
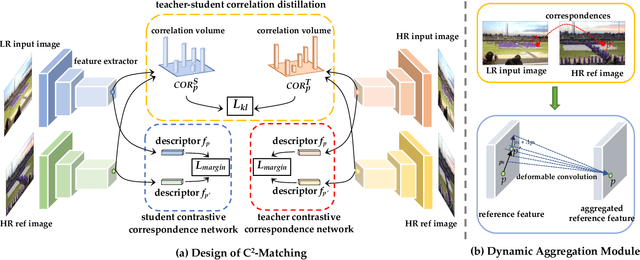
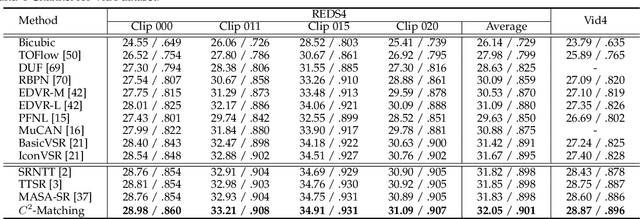
Reference-based Super-Resolution (Ref-SR) has recently emerged as a promising paradigm to enhance a low-resolution (LR) input image or video by introducing an additional high-resolution (HR) reference image. Existing Ref-SR methods mostly rely on implicit correspondence matching to borrow HR textures from reference images to compensate for the information loss in input images. However, performing local transfer is difficult because of two gaps between input and reference images: the transformation gap (e.g., scale and rotation) and the resolution gap (e.g., HR and LR). To tackle these challenges, we propose C2-Matching in this work, which performs explicit robust matching crossing transformation and resolution. 1) To bridge the transformation gap, we propose a contrastive correspondence network, which learns transformation-robust correspondences using augmented views of the input image. 2) To address the resolution gap, we adopt teacher-student correlation distillation, which distills knowledge from the easier HR-HR matching to guide the more ambiguous LR-HR matching. 3) Finally, we design a dynamic aggregation module to address the potential misalignment issue between input images and reference images. In addition, to faithfully evaluate the performance of Reference-based Image Super-Resolution under a realistic setting, we contribute the Webly-Referenced SR (WR-SR) dataset, mimicking the practical usage scenario. We also extend C2-Matching to Reference-based Video Super-Resolution task, where an image taken in a similar scene serves as the HR reference image. Extensive experiments demonstrate that our proposed C2-Matching significantly outperforms state of the arts on the standard CUFED5 benchmark and also boosts the performance of video SR by incorporating the C2-Matching component into Video SR pipelines.
Graph-based Semantical Extractive Text Analysis
Dec 19, 2022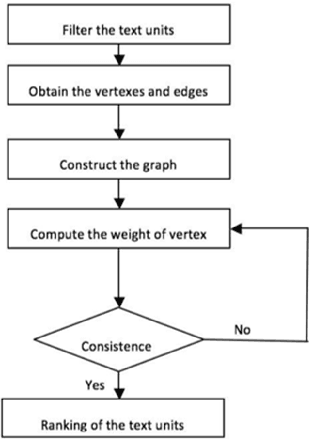
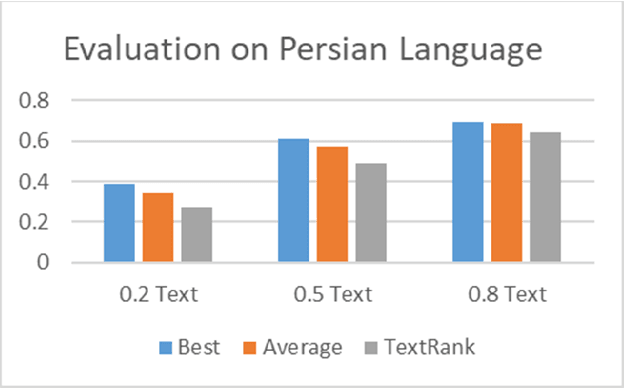

In the past few decades, there has been an explosion in the amount of available data produced from various sources with different topics. The availability of this enormous data necessitates us to adopt effective computational tools to explore the data. This leads to an intense growing interest in the research community to develop computational methods focused on processing this text data. A line of study focused on condensing the text so that we are able to get a higher level of understanding in a shorter time. The two important tasks to do this are keyword extraction and text summarization. In keyword extraction, we are interested in finding the key important words from a text. This makes us familiar with the general topic of a text. In text summarization, we are interested in producing a short-length text which includes important information about the document. The TextRank algorithm, an unsupervised learning method that is an extension of the PageRank (algorithm which is the base algorithm of Google search engine for searching pages and ranking them) has shown its efficacy in large-scale text mining, especially for text summarization and keyword extraction. this algorithm can automatically extract the important parts of a text (keywords or sentences) and declare them as the result. However, this algorithm neglects the semantic similarity between the different parts. In this work, we improved the results of the TextRank algorithm by incorporating the semantic similarity between parts of the text. Aside from keyword extraction and text summarization, we develop a topic clustering algorithm based on our framework which can be used individually or as a part of generating the summary to overcome coverage problems.