 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated Learning Method for Preserving Privacy in Face Recognition System
Mar 08, 2024
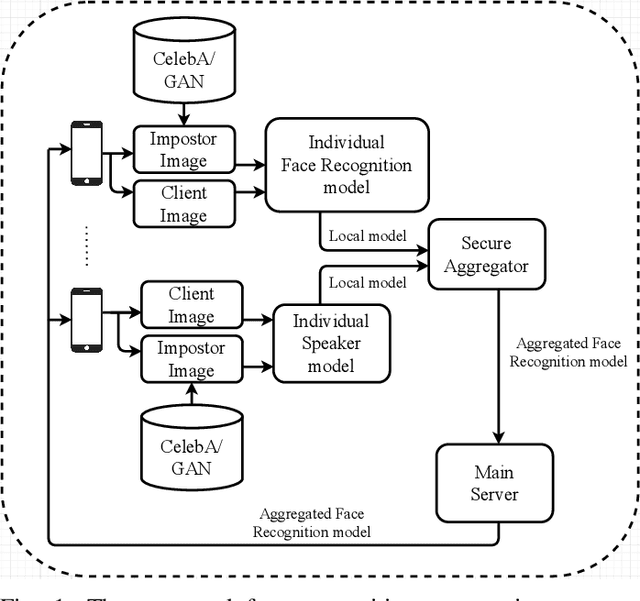
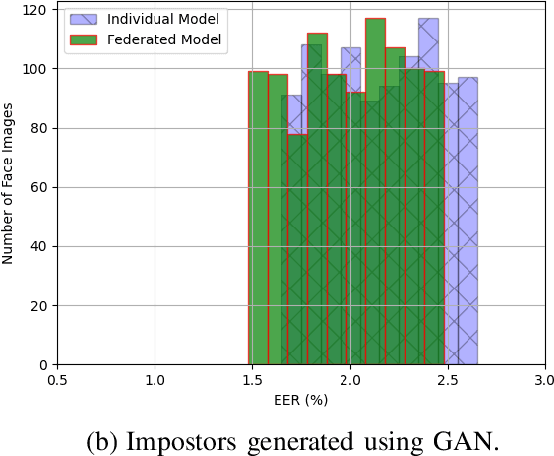
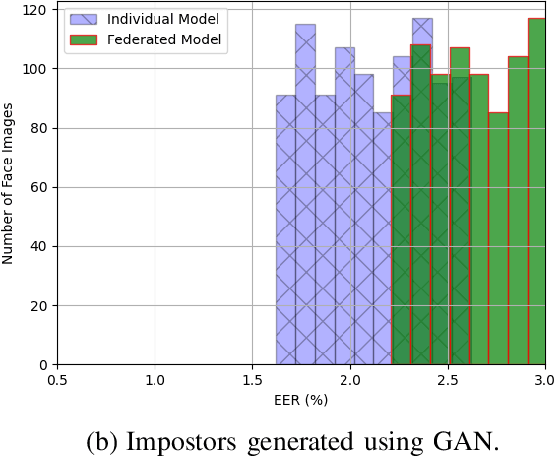
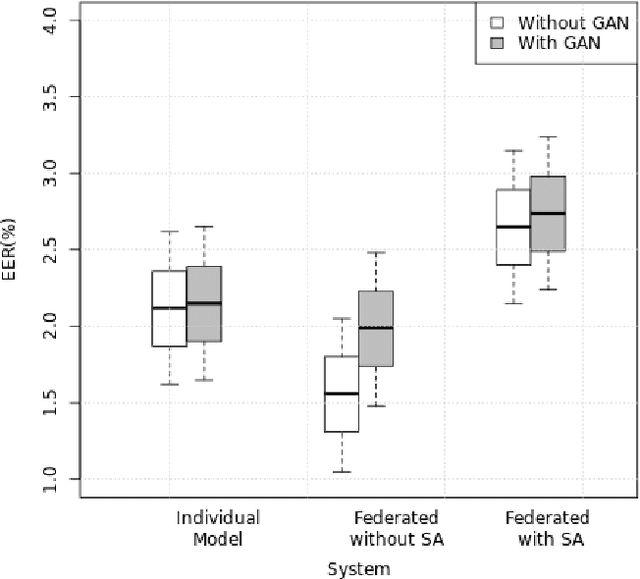
The state-of-the-art face recognition systems are typically trained on a single computer, utilizing extensive image datasets collected from various number of users. However, these datasets often contain sensitive personal information that users may hesitate to disclose. To address potential privacy concerns, we explore the application of federated learning, both with and without secure aggregators, in the context of both supervised and unsupervised face recognition systems. Federated learning facilitates the training of a shared model without necessitating the sharing of individual private data, achieving this by training models on decentralized edge devices housing the data. In our proposed system, each edge device independently trains its own model, which is subsequently transmitted either to a secure aggregator or directly to the central server. To introduce diverse data without the need for data transmission, we employ generative adversarial networks to generate imposter data at the edge. Following this, the secure aggregator or central server combines these individual models to construct a global model, which is then relayed back to the edge devices. Experimental findings based on the CelebA datasets reveal that employing federated learning in both supervised and unsupervised face recognition systems offers dual benefits. Firstly, it safeguards privacy since the original data remains on the edge devices. Secondly, the experimental results demonstrate that the aggregated model yields nearly identical performance compared to the individual models, particularly when the federated model does not utilize a secure aggregator. Hence, our results shed light on the practical challenges associated with privacy-preserving face image training, particularly in terms of the balance between privacy and accuracy.
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Mar 02, 2024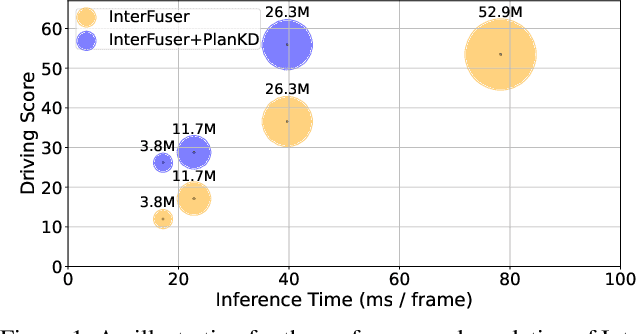
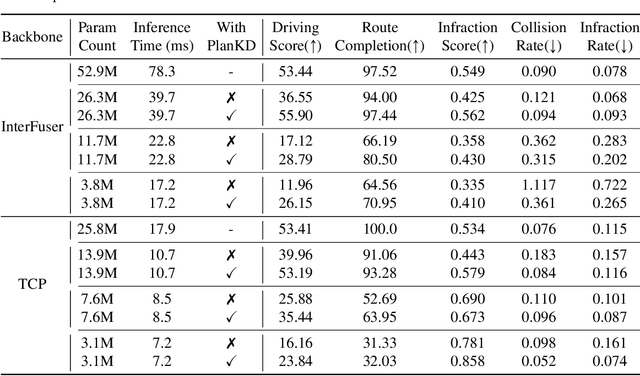
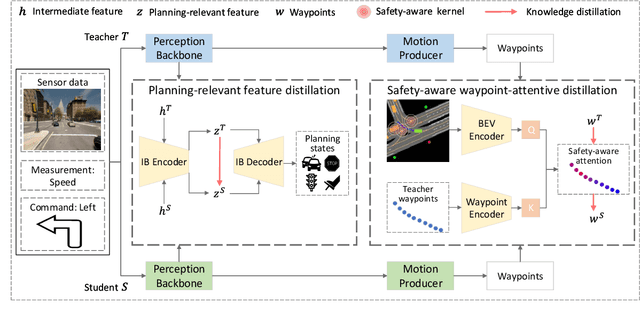
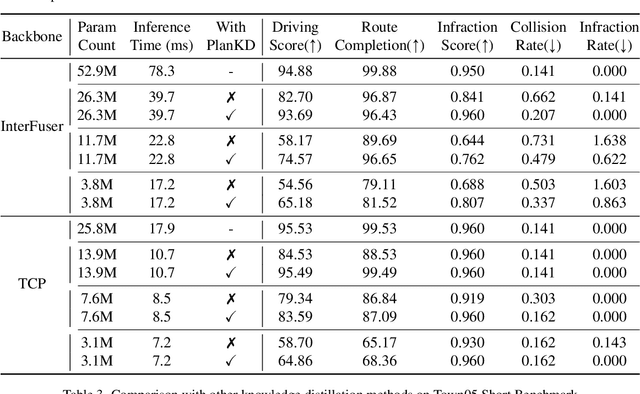
End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
Unsupervised Multilingual Dense Retrieval via Generative Pseudo Labeling
Mar 06, 2024
Dense retrieval methods have demonstrated promising performance in multilingual information retrieval, where queries and documents can be in different languages. However, dense retrievers typically require a substantial amount of paired data, which poses even greater challenges in multilingual scenarios. This paper introduces UMR, an Unsupervised Multilingual dense Retriever trained without any paired data. Our approach leverages the sequence likelihood estimation capabilities of multilingual language models to acquire pseudo labels for training dense retrievers. We propose a two-stage framework which iteratively improves the performance of multilingual dense retrievers. Experimental results on two benchmark datasets show that UMR outperforms supervised baselines, showcasing the potential of training multilingual retrievers without paired data, thereby enhancing their practicality. Our source code, data, and models are publicly available at https://github.com/MiuLab/UMR
GUIDE: Guidance-based Incremental Learning with Diffusion Models
Mar 06, 2024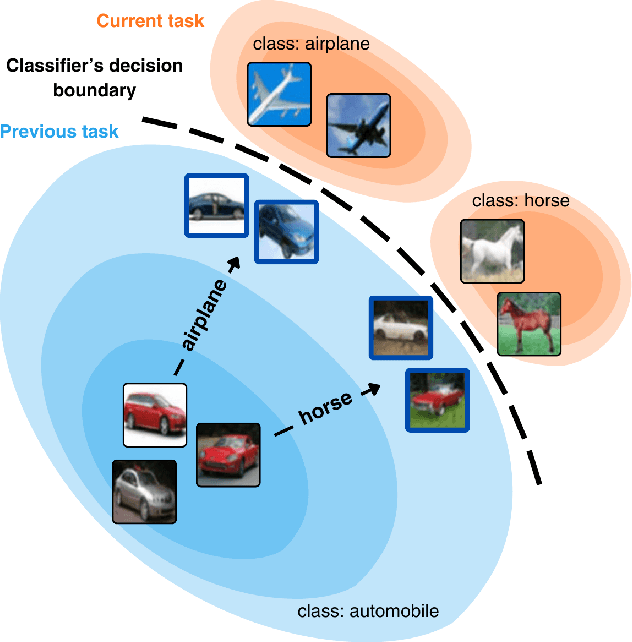
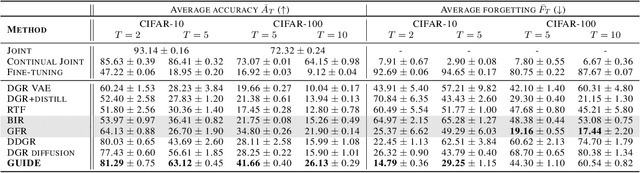

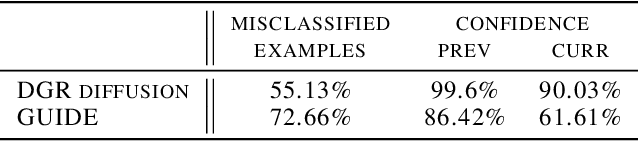
We introduce GUIDE, a novel continual learning approach that directs diffusion models to rehearse samples at risk of being forgotten. Existing generative strategies combat catastrophic forgetting by randomly sampling rehearsal examples from a generative model. Such an approach contradicts buffer-based approaches where sampling strategy plays an important role. We propose to bridge this gap by integrating diffusion models with classifier guidance techniques to produce rehearsal examples specifically targeting information forgotten by a continuously trained model. This approach enables the generation of samples from preceding task distributions, which are more likely to be misclassified in the context of recently encountered classes. Our experimental results show that GUIDE significantly reduces catastrophic forgetting, outperforming conventional random sampling approaches and surpassing recent state-of-the-art methods in continual learning with generative replay.
From Graph to Word Bag: Introducing Domain Knowledge to Confusing Charge Prediction
Mar 07, 2024
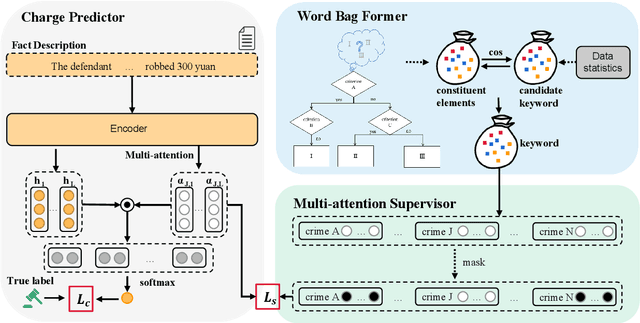
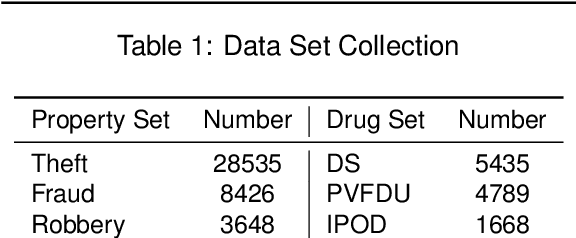
Confusing charge prediction is a challenging task in legal AI, which involves predicting confusing charges based on fact descriptions. While existing charge prediction methods have shown impressive performance, they face significant challenges when dealing with confusing charges, such as Snatch and Robbery. In the legal domain, constituent elements play a pivotal role in distinguishing confusing charges. Constituent elements are fundamental behaviors underlying criminal punishment and have subtle distinctions among charges. In this paper, we introduce a novel From Graph to Word Bag (FWGB) approach, which introduces domain knowledge regarding constituent elements to guide the model in making judgments on confusing charges, much like a judge's reasoning process. Specifically, we first construct a legal knowledge graph containing constituent elements to help select keywords for each charge, forming a word bag. Subsequently, to guide the model's attention towards the differentiating information for each charge within the context, we expand the attention mechanism and introduce a new loss function with attention supervision through words in the word bag. We construct the confusing charges dataset from real-world judicial documents. Experiments demonstrate the effectiveness of our method, especially in maintaining exceptional performance in imbalanced label distributions.
MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant
Mar 07, 2024
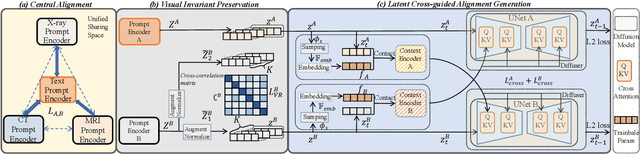

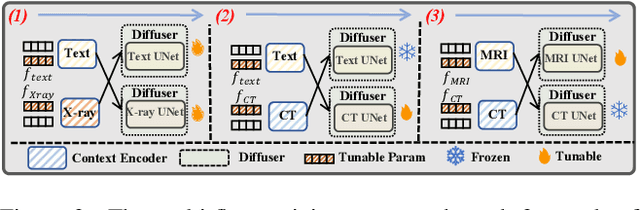
Medical generative models, acknowledged for their high-quality sample generation ability, have accelerated the fast growth of medical applications. However, recent works concentrate on separate medical generation models for distinct medical tasks and are restricted to inadequate medical multi-modal knowledge, constraining medical comprehensive diagnosis. In this paper, we propose MedM2G, a Medical Multi-Modal Generative framework, with the key innovation to align, extract, and generate medical multi-modal within a unified model. Extending beyond single or two medical modalities, we efficiently align medical multi-modal through the central alignment approach in the unified space. Significantly, our framework extracts valuable clinical knowledge by preserving the medical visual invariant of each imaging modal, thereby enhancing specific medical information for multi-modal generation. By conditioning the adaptive cross-guided parameters into the multi-flow diffusion framework, our model promotes flexible interactions among medical multi-modal for generation. MedM2G is the first medical generative model that unifies medical generation tasks of text-to-image, image-to-text, and unified generation of medical modalities (CT, MRI, X-ray). It performs 5 medical generation tasks across 10 datasets, consistently outperforming various state-of-the-art works.
Matched-filter Precoded Rate Splitting Multiple Access: A Simple and Energy-efficient Design
Mar 07, 2024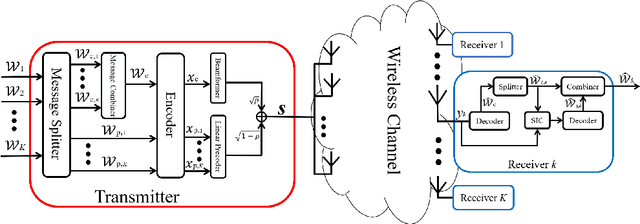
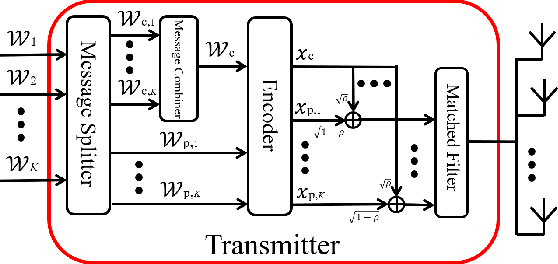
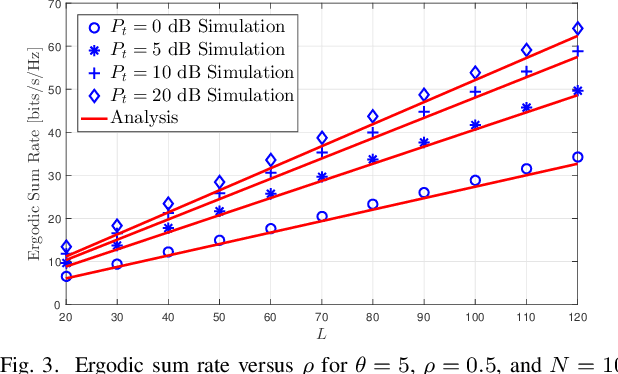
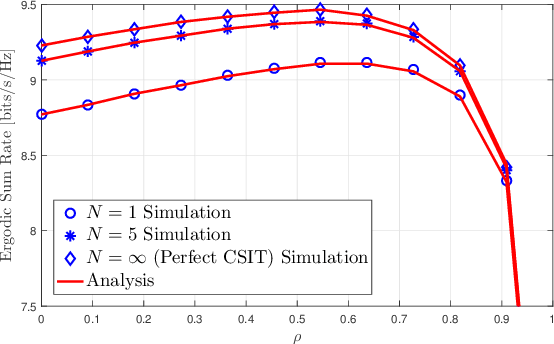
We introduce an energy-efficient downlink rate splitting multiple access (RSMA) scheme, employing a simple matched filter (MF) for precoding. We consider a transmitter equipped with multiple antennas, serving several single-antenna users at the same frequency-time resource, each with distinct message requests. Within the conventional 1-layer RSMA framework, requested messages undergo splitting into common and private streams, which are then precoded separately before transmission. In contrast, we propose a novel strategy where only an MF is employed to precode both the common and private streams in RSMA, promising significantly improved energy efficiency and reduced complexity. We demonstrate that this MF-precoded RSMA achieves the same delivery performance as conventional RSMA, where the common stream is beamformed using maximal ratio transmission (MRT) and the private streams are precoded by MF. Taking into account imperfect channel state information at the transmitter, we proceed to analyze the delivery performance of the MF-precoded RSMA. We derive the ergodic rates for decoding the common and private streams at a target user respectively in the massive MIMO regime. Finally, numerical simulations validate the accuracy of our analytical models, as well as demonstrate the advantages over conventional RSMA.
Improving Matrix Completion by Exploiting Rating Ordinality in Graph Neural Networks
Mar 07, 2024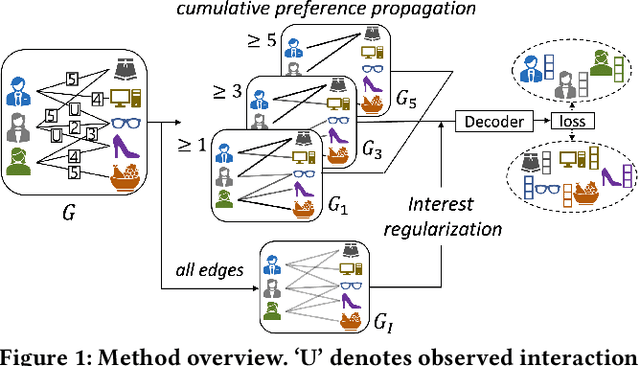
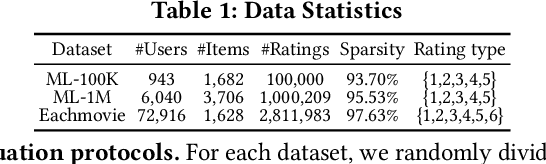
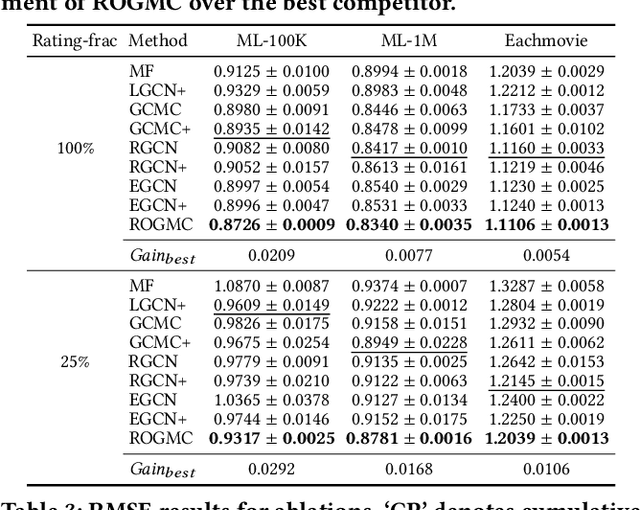
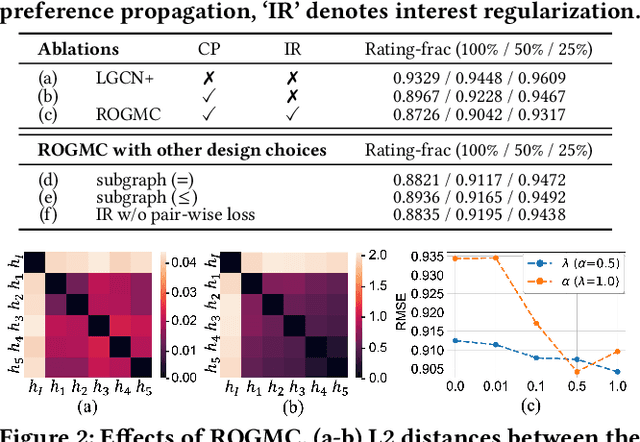
Matrix completion is an important area of research in recommender systems. Recent methods view a rating matrix as a user-item bi-partite graph with labeled edges denoting observed ratings and predict the edges between the user and item nodes by using the graph neural network (GNN). Despite their effectiveness, they treat each rating type as an independent relation type and thus cannot sufficiently consider the ordinal nature of the ratings. In this paper, we explore a new approach to exploit rating ordinality for GNN, which has not been studied well in the literature. We introduce a new method, called ROGMC, to leverage Rating Ordinality in GNN-based Matrix Completion. It uses cumulative preference propagation to directly incorporate rating ordinality in GNN's message passing, allowing for users' stronger preferences to be more emphasized based on inherent orders of rating types. This process is complemented by interest regularization which facilitates preference learning using the underlying interest information. Our extensive experiments show that ROGMC consistently outperforms the existing strategies of using rating types for GNN. We expect that our attempt to explore the feasibility of utilizing rating ordinality for GNN may stimulate further research in this direction.
Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization
Mar 07, 2024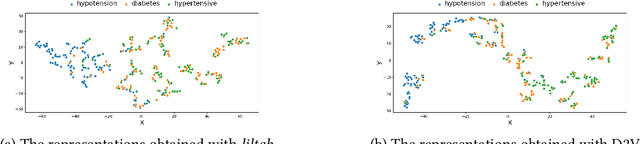
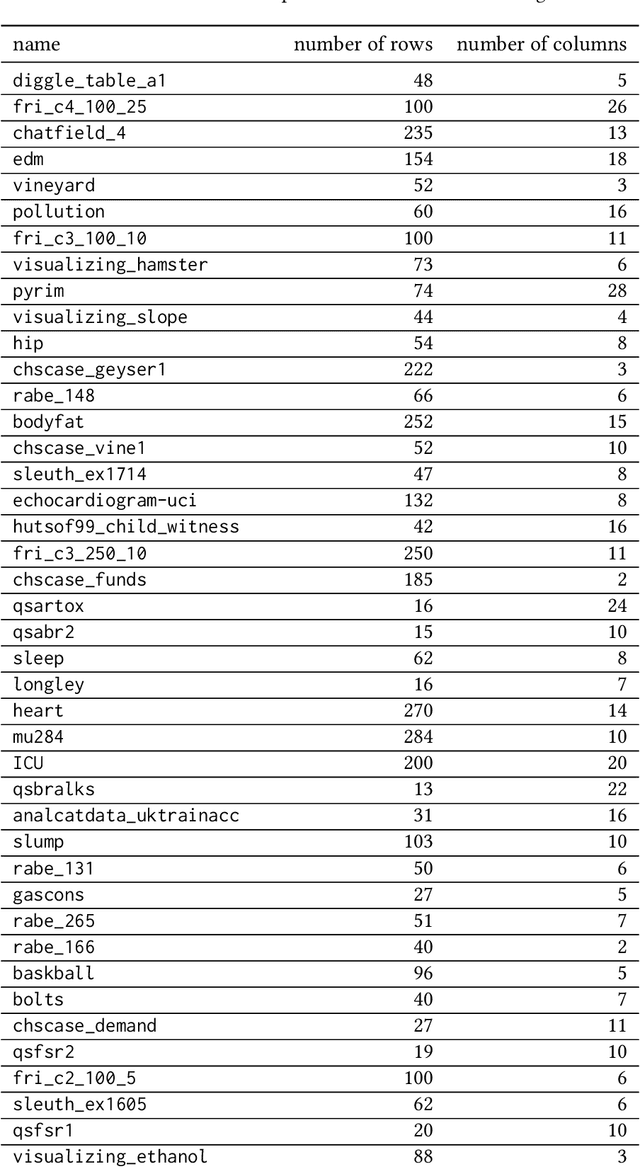

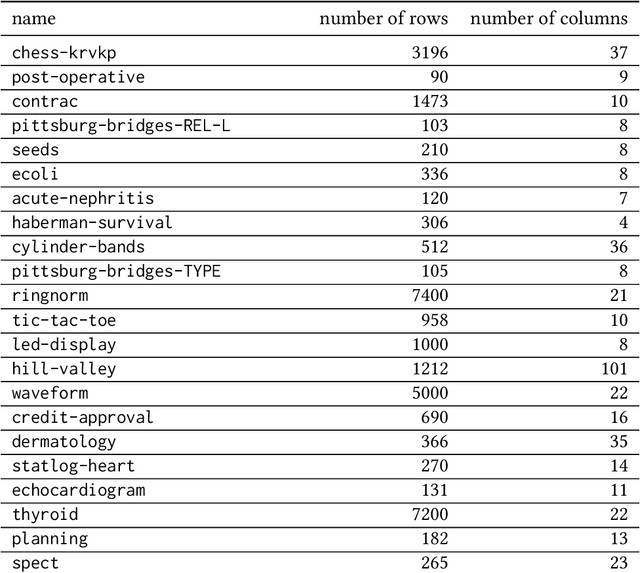
Effectively representing heterogeneous tabular datasets for meta-learning remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. Encoder-based models, such as Dataset2Vec, allow us to extract significant meta-features automatically without human intervention. This research introduces a novel encoder-based representation of tabular datasets implemented within the liltab package available on GitHub https://github.com/azoz01/liltab. Our package is based on an established model for heterogeneous tabular data proposed in [Iwata and Kumagai, 2020]. The proposed approach employs a different model for encoding feature relationships, generating alternative representations compared to existing methods like Dataset2Vec. Both of them leverage the fundamental assumption of dataset similarity learning. In this work, we evaluate Dataset2Vec and liltab on two common meta-tasks - representing entire datasets and hyperparameter optimization warm-start. However, validation on an independent metaMIMIC dataset highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction. [Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020.
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Mar 07, 2024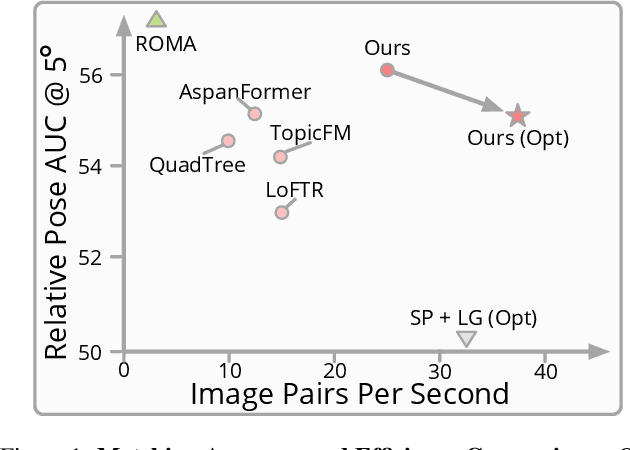
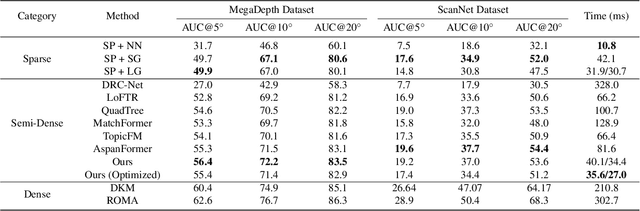
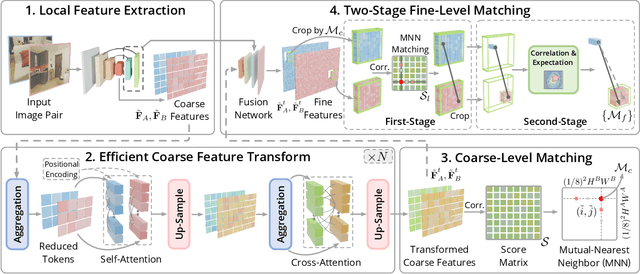
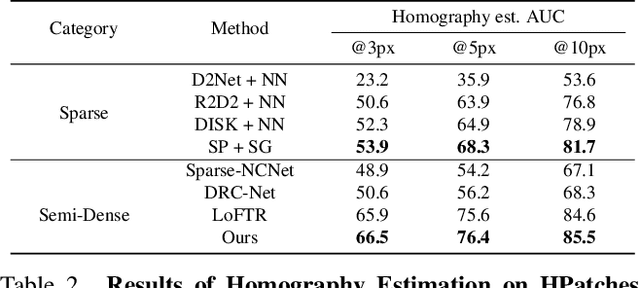
We present a novel method for efficiently producing semi-dense matches across images. Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency. We revisit its design choices and derive multiple improvements for both efficiency and accuracy. One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency. Furthermore, we find spatial variance exists in LoFTR's fine correlation module, which is adverse to matching accuracy. A novel two-stage correlation layer is proposed to achieve accurate subpixel correspondences for accuracy improvement. Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits. This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction. Project page: https://zju3dv.github.io/efficientloftr.