 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Retrieval in Friction Stir Welding of Aluminum Alloys by using Natural Language Processing based Algorithms
Apr 25, 2022

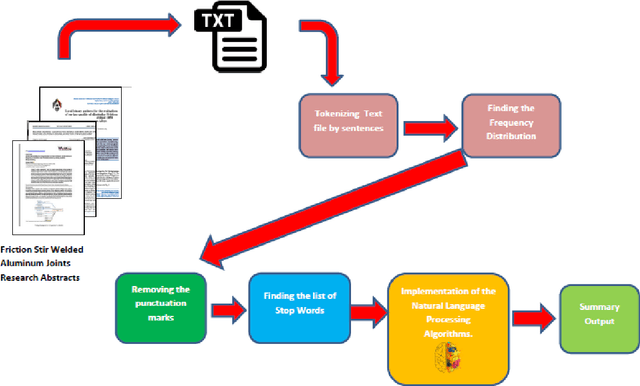
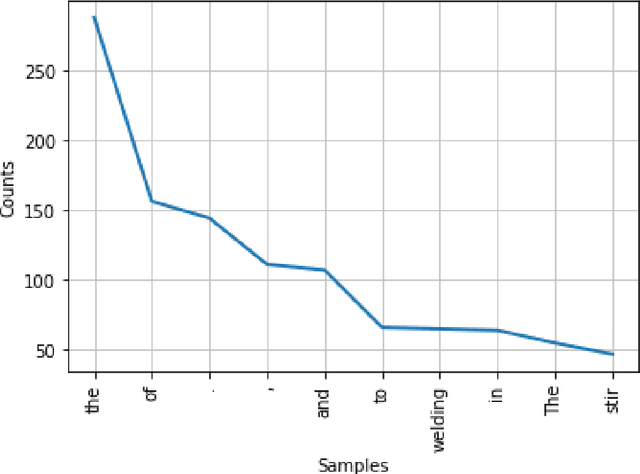
Text summarization is a technique for condensing a big piece of text into a few key elements that give a general impression of the content. When someone requires a quick and precise summary of a large amount of information, it becomes vital. If done manually, summarizing text can be costly and time-consuming. Natural Language Processing (NLP) is the sub-division of Artificial Intelligence that narrows down the gap between technology and human cognition by extracting the relevant information from the pile of data. In the present work, scientific information regarding the Friction Stir Welding of Aluminum alloys was collected from the abstract of scholarly research papers. For extracting the relevant information from these research abstracts four Natural Language Processing based algorithms i.e. Latent Semantic Analysis (LSA), Luhn Algorithm, Lex Rank Algorithm, and KL-Algorithm were used. In order to evaluate the accuracy score of these algorithms, Recall-Oriented Understudy for Gisting Evaluation (ROUGE) was used. The results showed that the Luhn Algorithm resulted in the highest f1-Score of 0.413 in comparison to other algorithms.
Alzheimer's Dementia Detection through Spontaneous Dialogue with Proactive Robotic Listeners
Nov 15, 2022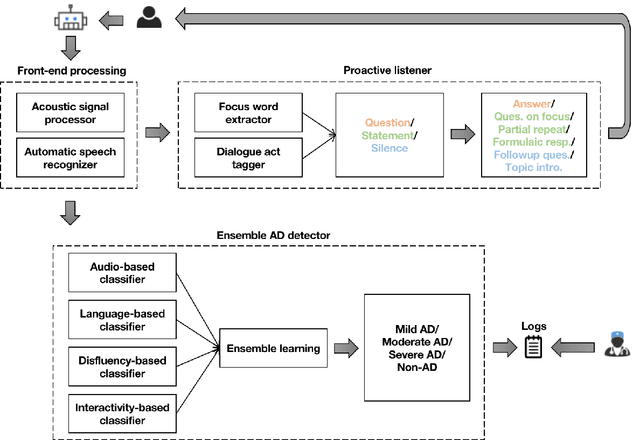
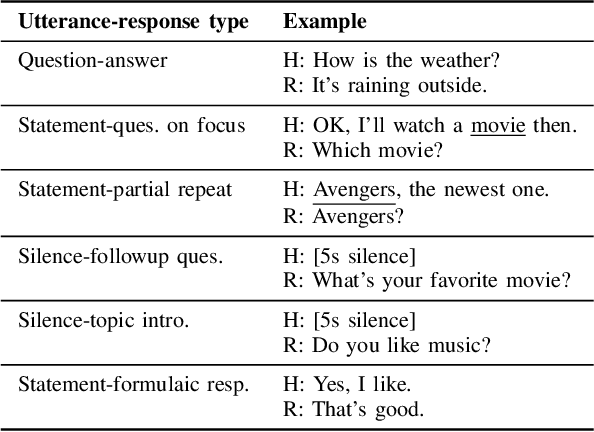
As the aging of society continues to accelerate, Alzheimer's Disease (AD) has received more and more attention from not only medical but also other fields, such as computer science, over the past decade. Since speech is considered one of the effective ways to diagnose cognitive decline, AD detection from speech has emerged as a hot topic. Nevertheless, such approaches fail to tackle several key issues: 1) AD is a complex neurocognitive disorder which means it is inappropriate to conduct AD detection using utterance information alone while ignoring dialogue information; 2) Utterances of AD patients contain many disfluencies that affect speech recognition yet are helpful to diagnosis; 3) AD patients tend to speak less, causing dialogue breakdown as the disease progresses. This fact leads to a small number of utterances, which may cause detection bias. Therefore, in this paper, we propose a novel AD detection architecture consisting of two major modules: an ensemble AD detector and a proactive listener. This architecture can be embedded in the dialogue system of conversational robots for healthcare.
GraphIX: Graph-based In silico XAI(explainable artificial intelligence) for drug repositioning from biopharmaceutical network
Dec 21, 2022Drug repositioning holds great promise because it can reduce the time and cost of new drug development. While drug repositioning can omit various R&D processes, confirming pharmacological effects on biomolecules is essential for application to new diseases. Biomedical explainability in a drug repositioning model can support appropriate insights in subsequent in-depth studies. However, the validity of the XAI methodology is still under debate, and the effectiveness of XAI in drug repositioning prediction applications remains unclear. In this study, we propose GraphIX, an explainable drug repositioning framework using biological networks, and quantitatively evaluate its explainability. GraphIX first learns the network weights and node features using a graph neural network from known drug indication and knowledge graph that consists of three types of nodes (but not given node type information): disease, drug, and protein. Analysis of the post-learning features showed that node types that were not known to the model beforehand are distinguished through the learning process based on the graph structure. From the learned weights and features, GraphIX then predicts the disease-drug association and calculates the contribution values of the nodes located in the neighborhood of the predicted disease and drug. We hypothesized that the neighboring protein node to which the model gave a high contribution is important in understanding the actual pharmacological effects. Quantitative evaluation of the validity of protein nodes' contribution using a real-world database showed that the high contribution proteins shown by GraphIX are reasonable as a mechanism of drug action. GraphIX is a framework for evidence-based drug discovery that can present to users new disease-drug associations and identify the protein important for understanding its pharmacological effects from a large and complex knowledge base.
BaIT: Barometer for Information Trustworthiness
Jun 15, 2022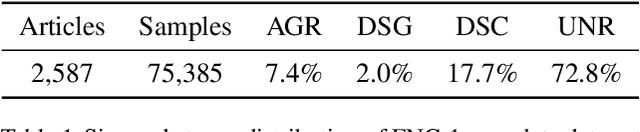
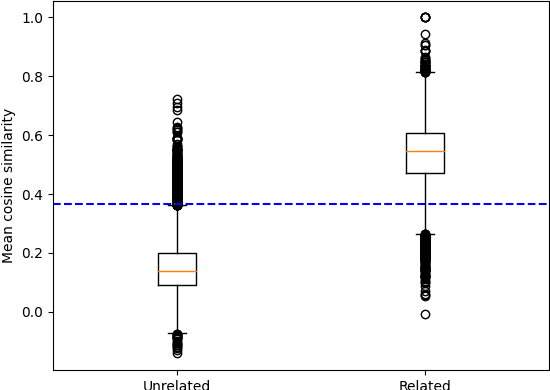
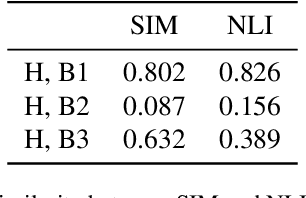
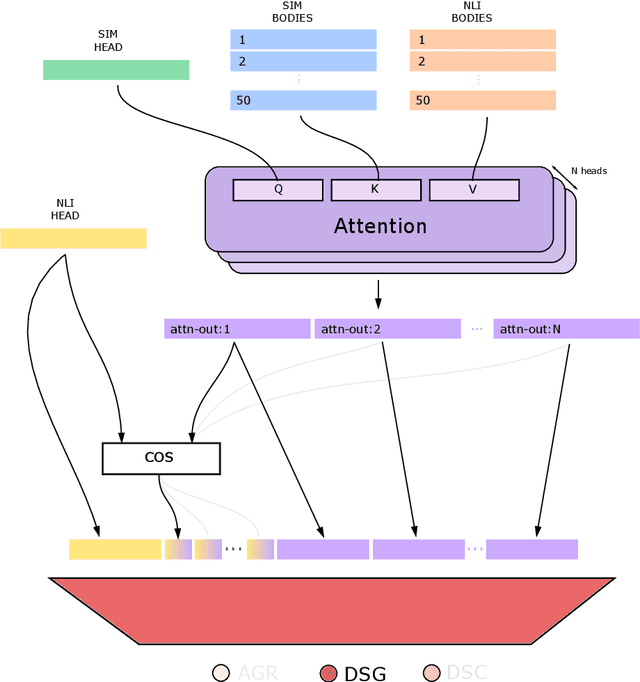
This paper presents a new approach to the FNC-1 fake news classification task which involves employing pre-trained encoder models from similar NLP tasks, namely sentence similarity and natural language inference, and two neural network architectures using this approach are proposed. Methods in data augmentation are explored as a means of tackling class imbalance in the dataset, employing common pre-existing methods and proposing a method for sample generation in the under-represented class using a novel sentence negation algorithm. Comparable overall performance with existing baselines is achieved, while significantly increasing accuracy on an under-represented but nonetheless important class for FNC-1.
Information Entropy Initialized Concrete Autoencoder for Optimal Sensor Placement and Reconstruction of Geophysical Fields
Jun 28, 2022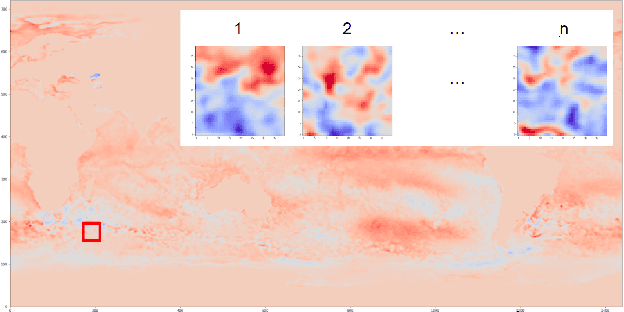
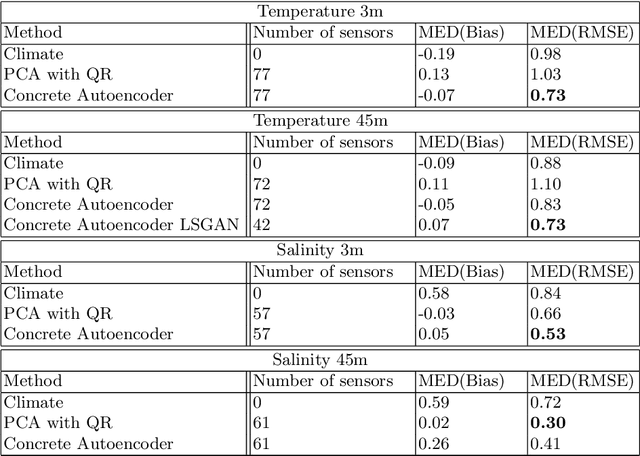
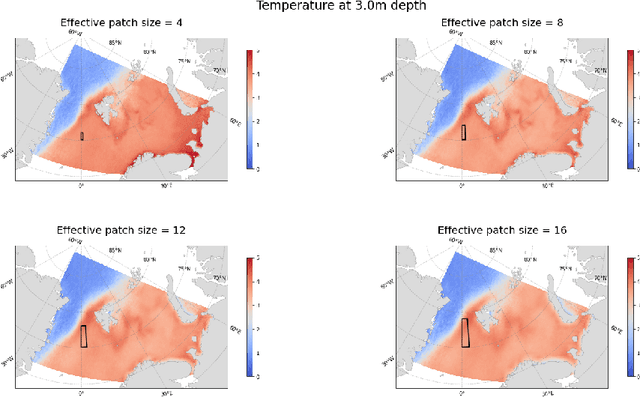
We propose a new approach to the optimal placement of sensors for the problem of reconstructing geophysical fields from sparse measurements. Our method consists of two stages. In the first stage, we estimate the variability of the physical field as a function of spatial coordinates by approximating its information entropy through the Conditional PixelCNN network. To calculate the entropy, a new ordering of a two-dimensional data array (spiral ordering) is proposed, which makes it possible to obtain the entropy of a physical field simultaneously for several spatial scales. In the second stage, the entropy of the physical field is used to initialize the distribution of optimal sensor locations. This distribution is further optimized with the Concrete Autoencoder architecture with the straight-through gradient estimator and adversarial loss to simultaneously minimize the number of sensors and maximize reconstruction accuracy. Our method scales linearly with data size, unlike commonly used Principal Component Analysis. We demonstrate our method on the two examples: (a) temperature and (b) salinity fields around the Barents Sea and the Svalbard group of islands. For these examples, we compute the reconstruction error of our method and a few baselines. We test our approach against two baselines (1) PCA with QR factorization and (2) climatology. We find out that the obtained optimal sensor locations have clear physical interpretation and correspond to the boundaries between sea currents.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022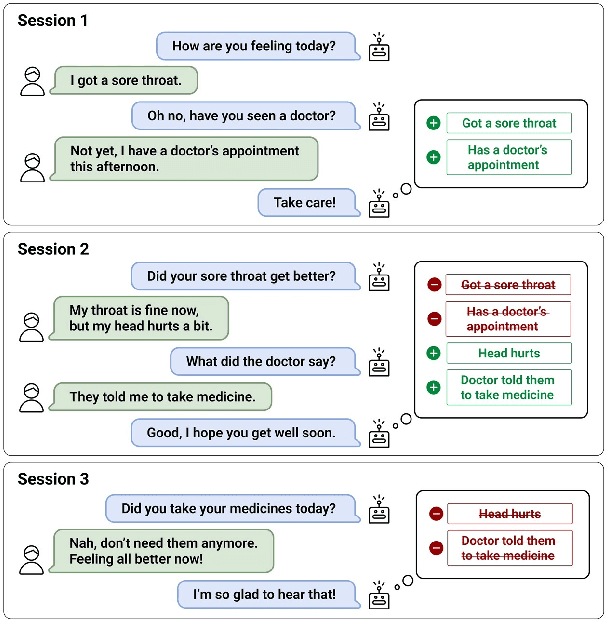
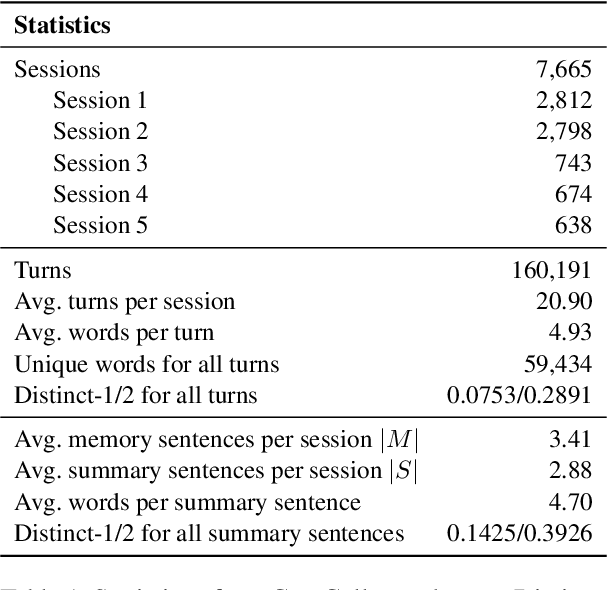
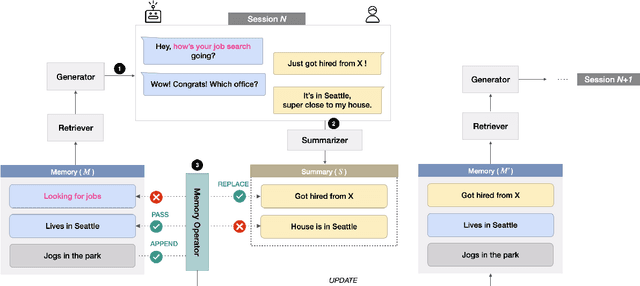
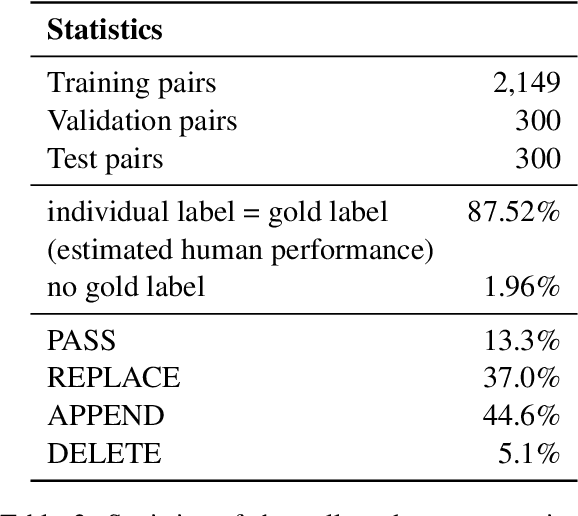
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.
Crosslinguistic word order variation reflects evolutionary pressures of dependency and information locality
Jun 09, 2022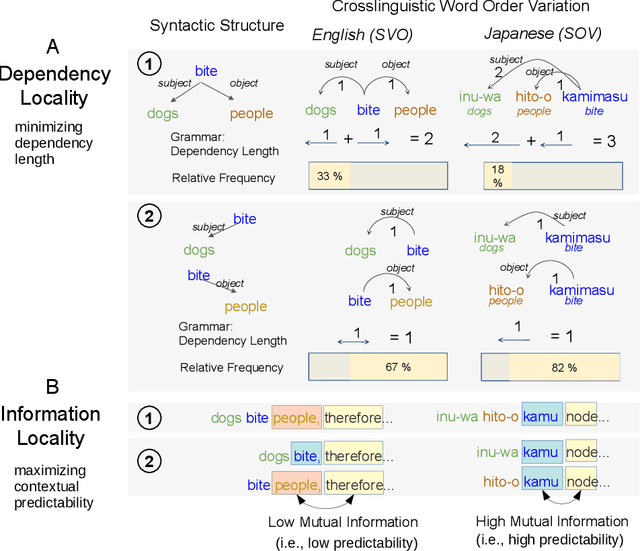
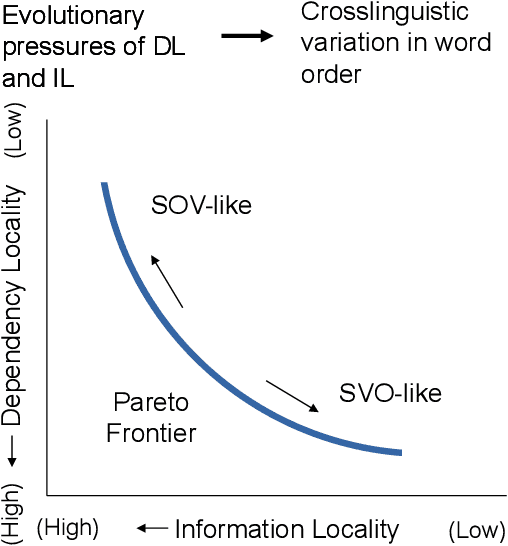
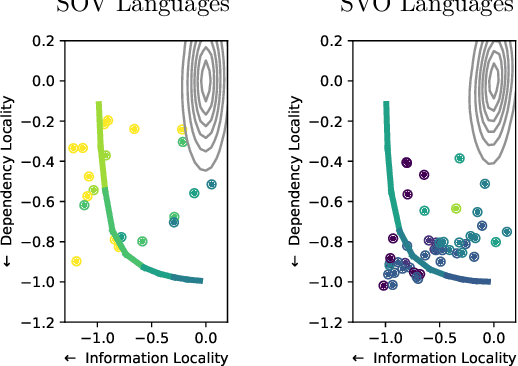
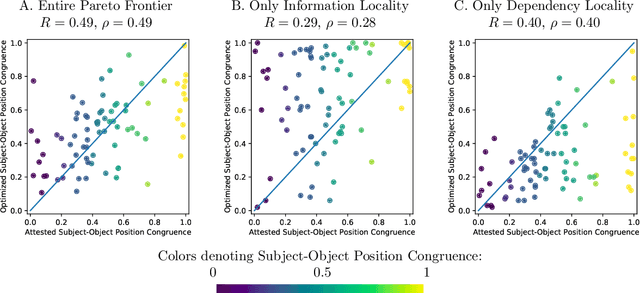
Languages vary considerably in syntactic structure. About 40% of the world's languages have subject-verb-object order, and about 40% have subject-object-verb order. Extensive work has sought to explain this word order variation across languages. However, the existing approaches are not able to explain coherently the frequency distribution and evolution of word order in individual languages. We propose that variation in word order reflects different ways of balancing competing pressures of dependency locality and information locality, whereby languages favor placing elements together when they are syntactically related or contextually informative about each other. Using data from 80 languages in 17 language families and phylogenetic modeling, we demonstrate that languages evolve to balance these pressures, such that word order change is accompanied by change in the frequency distribution of the syntactic structures which speakers communicate to maintain overall efficiency. Variability in word order thus reflects different ways in which languages resolve these evolutionary pressures. We identify relevant characteristics that result from this joint optimization, particularly the frequency with which subjects and objects are expressed together for the same verb. Our findings suggest that syntactic structure and usage across languages co-adapt to support efficient communication under limited cognitive resources.
* Preprint of peer-reviewed paper published in PNAS. Final copyedited version is available at: https://www.pnas.org/doi/10.1073/pnas.2122604119
From Points to Functions: Infinite-dimensional Representations in Diffusion Models
Oct 25, 2022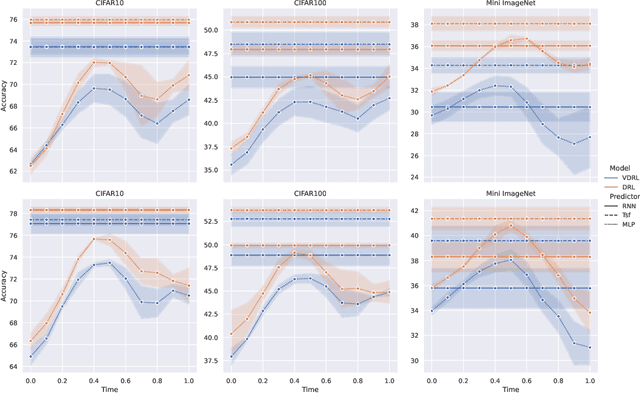
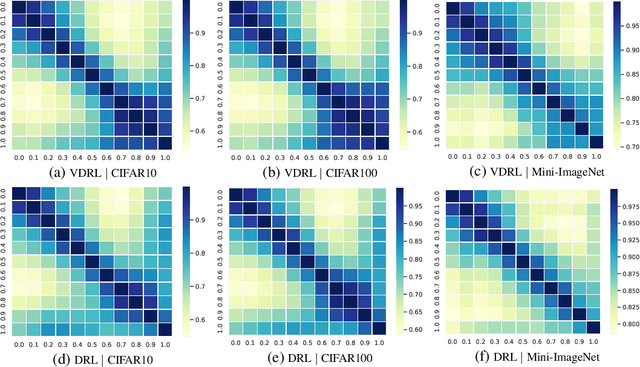
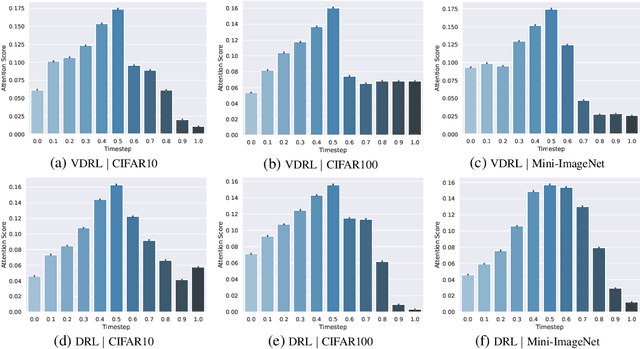
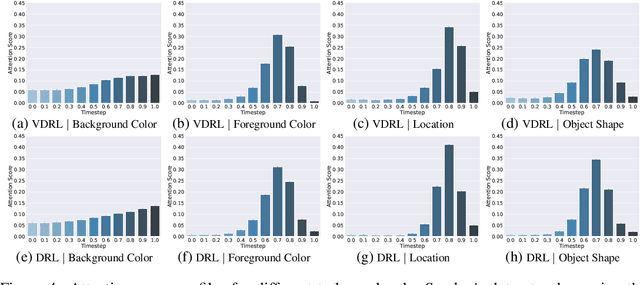
Diffusion-based generative models learn to iteratively transfer unstructured noise to a complex target distribution as opposed to Generative Adversarial Networks (GANs) or the decoder of Variational Autoencoders (VAEs) which produce samples from the target distribution in a single step. Thus, in diffusion models every sample is naturally connected to a random trajectory which is a solution to a learned stochastic differential equation (SDE). Generative models are only concerned with the final state of this trajectory that delivers samples from the desired distribution. Abstreiter et. al showed that these stochastic trajectories can be seen as continuous filters that wash out information along the way. Consequently, it is reasonable to ask if there is an intermediate time step at which the preserved information is optimal for a given downstream task. In this work, we show that a combination of information content from different time steps gives a strictly better representation for the downstream task. We introduce an attention and recurrence based modules that ``learn to mix'' information content of various time-steps such that the resultant representation leads to superior performance in downstream tasks.
Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments
Nov 25, 2022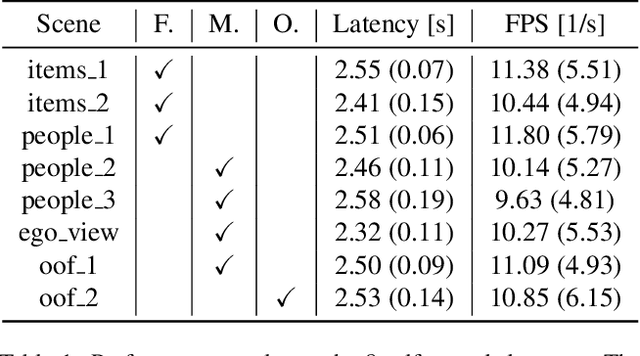
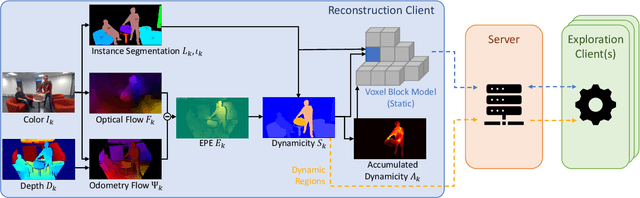
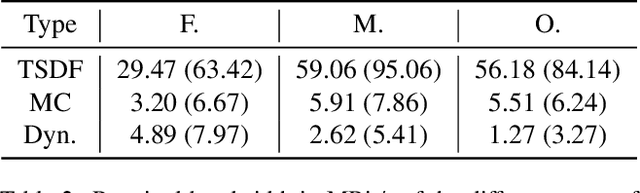

Despite the impressive progress of telepresence systems for room-scale scenes with static and dynamic scene entities, expanding their capabilities to scenarios with larger dynamic environments beyond a fixed size of a few squaremeters remains challenging. In this paper, we aim at sharing 3D live-telepresence experiences in large-scale environments beyond room scale with both static and dynamic scene entities at practical bandwidth requirements only based on light-weight scene capture with a single moving consumer-grade RGB-D camera. To this end, we present a system which is built upon a novel hybrid volumetric scene representation in terms of the combination of a voxel-based scene representation for the static contents, that not only stores the reconstructed surface geometry but also contains information about the object semantics as well as their accumulated dynamic movement over time, and a point-cloud-based representation for dynamic scene parts, where the respective separation from static parts is achieved based on semantic and instance information extracted for the input frames. With an independent yet simultaneous streaming of both static and dynamic content, where we seamlessly integrate potentially moving but currently static scene entities in the static model until they are becoming dynamic again, as well as the fusion of static and dynamic data at the remote client, our system is able to achieve VR-based live-telepresence at interactive rates. Our evaluation demonstrates the potential of our novel approach in terms of visual quality, performance, and ablation studies regarding involved design choices.
Reinforced Language Modeling for End-to-End Task Oriented Dialog
Nov 30, 2022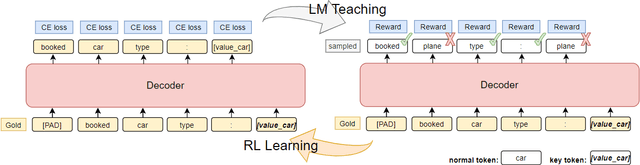
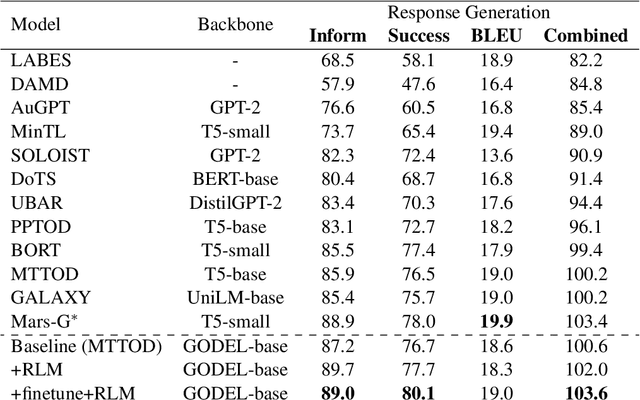
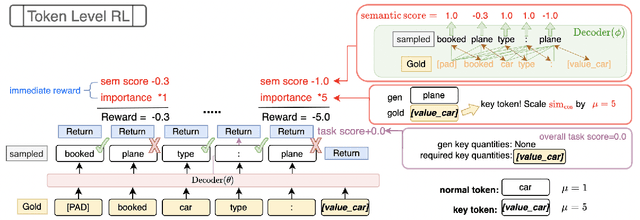

In task-oriented dialogs such as MultiWoZ (Budzianowski et al., 2018), an informative and/or successful system response needs to include necessary key information such as the phone number of a hotel. Therefore, we hypothesize that by helping the model to focus more on learning key quantities in the dialog, the model can generative more informative and helpful responses. In this paper, we propose a new training algorithm, Reinforced Language Modeling (RLM), that aims to use a fine-grained reward function and reinforcement learning to help the model focus more on generating key quantities correctly during test time. Empirical results show our proposed RLM achieves state-of-the-art performance on the inform rate, success rate, and combined score in MultiWoZ.